贝叶斯分类器经典讲解解析
- 格式:ppt
- 大小:1.95 MB
- 文档页数:38

贝叶斯分类器的实现与应用近年来,机器学习技术在各个领域都有着广泛的应用。
其中,贝叶斯分类器是一种常用且有效的分类方法。
本文将介绍贝叶斯分类器的原理、实现方法以及应用。
一、贝叶斯分类器原理贝叶斯分类器是一种概率分类器,它基于贝叶斯定理和条件概率理论,通过统计样本之间的相似度,确定样本所属分类的概率大小,从而进行分类的过程。
贝叶斯定理的公式为:P(A|B) = P(B|A) × P(A) / P(B)其中,P(A|B) 表示在已知 B 的条件下,事件 A 发生的概率;P(B|A) 表示在已知 A 的条件下,事件 B 发生的概率;P(A) 和 P(B) 分别表示事件 A 和事件 B 的概率。
在分类问题中,假设有 m 个不同的分类,每个分类对应一个先验概率 P(Yi),表示在未知样本类别的情况下,已知样本属于第 i 个分类的概率。
对于一个新的样本 x,通过求解以下公式,可以得出它属于每个分类的后验概率 P(Yi|X):P(Yi|X) = P(X|Yi) × P(Yi) / P(X)其中,P(X|Yi) 表示样本 X 在已知分类 Yi 的条件下出现的概率。
在贝叶斯分类器中,我们假设所有特征之间是独立的,即条件概率 P(X|Yi) 可以表示为各个特征条件概率的乘积,即:P(X|Yi) = P(X1|Yi) × P(X2|Yi) × ... × P(Xn|Yi)其中,X1、X2、...、Xn 分别表示样本 X 的 n 个特征。
最终,将所有分类对应的后验概率进行比较,找出概率最大的那个分类作为样本的分类结果。
二、贝叶斯分类器实现贝叶斯分类器的实现包括两个部分:模型参数计算和分类器实现。
1. 模型参数计算模型参数计算是贝叶斯分类器的关键步骤,它决定了分类器的分类性能。
在参数计算阶段,需要对每个分类的先验概率以及每个特征在每个分类下的条件概率进行估计。
先验概率可以通过样本集中每个分类的样本数量计算得到。
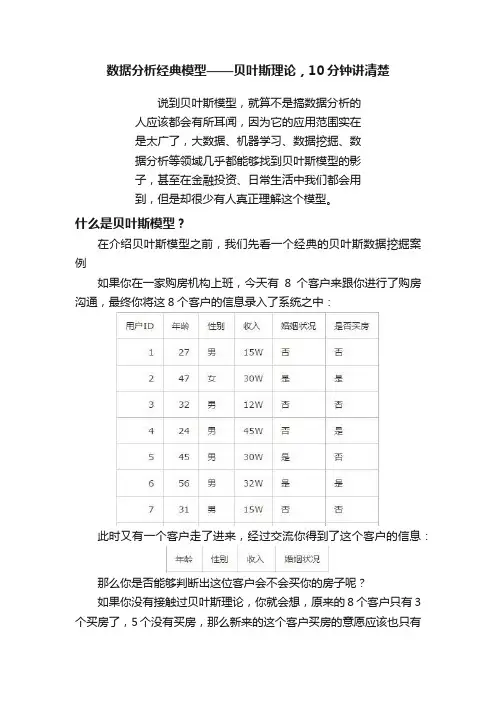
数据分析经典模型——贝叶斯理论,10分钟讲清楚说到贝叶斯模型,就算不是搞数据分析的人应该都会有所耳闻,因为它的应用范围实在是太广了,大数据、机器学习、数据挖掘、数据分析等领域几乎都能够找到贝叶斯模型的影子,甚至在金融投资、日常生活中我们都会用到,但是却很少有人真正理解这个模型。
什么是贝叶斯模型?在介绍贝叶斯模型之前,我们先看一个经典的贝叶斯数据挖掘案例如果你在一家购房机构上班,今天有8个客户来跟你进行了购房沟通,最终你将这8个客户的信息录入了系统之中:此时又有一个客户走了进来,经过交流你得到了这个客户的信息:那么你是否能够判断出这位客户会不会买你的房子呢?如果你没有接触过贝叶斯理论,你就会想,原来的8个客户只有3个买房了,5个没有买房,那么新来的这个客户买房的意愿应该也只有3/8 。
这代表了传统的频率主义理论,就跟抛硬币一样,抛了100次,50次都是正面,那么就可以得出硬币正面朝上的概率永远是50%,这个数值是固定不会改变的。
例子里的8个客户就相当于8次重复试验,其结果基本上代表了之后所有重复试验的结果,也就是之后所有客户买房的几率基本都是3/8 。
但此时你又觉得似乎有些不对,不同的客户有着不同的条件,其买房概率是不相同的,怎么能用一个趋向结果代表所有的客户呢?对了!这就是贝叶斯理论的思想,简单点讲就是要在已知条件的前提下,先设定一个假设,然后通过先验实验来更新这个概率,每个不同的实验都会带来不同的概率,这就是贝叶斯公式:按照这个公式,我们就可以完美解决上面的这个例子:先找出“年龄”、“性别”、“收入”、“婚姻状况”这四个维度中买房和不买房的概率:年龄P(b1|a1) :30-40买房的概率是1/3P(b1|a2) : 30-40没买房的概率是2/5收入P(b2|a1) --- 20-40买房的概率是2/3P(b2|a2) --- 20-40没买房的概率是2/5婚姻状况P(b3|a1) --- 未婚买房的概率是1/3P(b3|a2) --- 未婚没买房的概率是3/5性别:P(b4|a1) --- 女性买房的概率是1/3P(b4|a2) --- 女性没买房的概率是1/5OK,现在将所有的数据代入到贝叶斯公式中整合:新用户买房的统计概率为P(b|a1)P(a1)=0.33*0.66*0.33*0.33*3/8=0.0089新用户不会买房的统计概率为P(b|a2)P(a2)=0.4*0.4*0.6*0.2*5/8=0.012所以可以得出结论:新用户不买房的概率更大一些。


贝叶斯分类器一、朴素贝叶斯分类器原理目标:计算(|)j P C t 。
分析:由于数据t 是一个新的数据,(|)j P C t 无法在训练数据集中统计出来。
因此需要转换。
根据概率论中的贝叶斯定理(|)()(|)()P B A P A P A B P B =将(|)j P C t 的计算转换为: (|)()(|)()j j j P t C P C P C t P t = (1)其中,()j P C 表示类C j 在整个数据空间中的出现概率,可以在训练集中统计出来(即用C j 在训练数据集中出现的频率()j F C 来作为概率()j P C 。
但(|)j PtC 和()P t 仍然不能统计出来。
首先,对于(|)j P t C ,它表示在类j C 中出现数据t 的概率。
根据“属性独立性假设”,即对于属于类j C 的所有数据,它们个各属性出现某个值的概率是相互独立的。
如,判断一个干部是否是“好干部”(分类)时,其属性“生活作风=好”的概率(P(生活作风=好|好干部))与“工作态度=好”的概率(P(工作态度=好|好干部))是独立的,没有潜在的相互关联。
换句话说,一个好干部,其生活作风的好坏与其工作态度的好坏完全无关。
我们知道这并不能反映真实的情况,因而说是一种“假设”。
使用该假设来分类的方法称为“朴素贝叶斯分类”。
根据上述假设,类j C 中出现数据t 的概率等于其中出现t 的各属性值的概率的乘积。
即: (|)(|)j k j k P t C P t C =∏(2)其中,k t 是数据t 的第k 个属性值。
其次,对于公式(1)中的()P t ,即数据t 在整个数据空间中出现的概率,等于它在各分类中出现概率的总和,即:()(|)j j P t P t C =∑ (3)其中,各(|)j P t C 的计算就采用公式(2)。
这样,将(2)代入(1),并综合公式(3)后,我们得到: (|)()(|),(|)(|)(|)j j j j j j k j k P t C P C P C t P t C P t C P t C ⎧=⎪⎪⎨⎪=⎪⎩∑∏其中: (4)公式(4)就是我们最终用于判断数据t 分类的方法。



第三讲贝叶斯分类器线性分类器可以实现线性可分的类别之间的分类决策,其形式简单,分类决策快速。
但在许多模式识别的实际问题中,两个类的样本之间并没有明确的分类决策边界,线性分类器(包括广义线性分类器)无法完成分类任务,此时需要采用其它有效的分类方法。
贝叶斯分类器就是另一种非常常见和实用的统计模式识别方法。
一、 贝叶斯分类1、逆概率推理Inverse Probabilistic Reasoning推理是从已知的条件(Conditions),得出某个结论(Conclusions)的过程。
推理可分为确定性(Certainty)推理和概率推理。
所谓确定性推理是指类似如下的推理过程:如条件B存在,就一定会有结果A。
现在已知条件B存在,可以得出结论是结果A一定也存在。
“如果考试作弊,该科成绩就一定是0分。
”这就是一条确定性推理。
而概率推理(Probabilistic Reasoning)是不确定性推理,它的推理形式可以表示为:如条件B存在,则结果A发生的概率为P(A|B)。
P(A|B)也称为结果A 发生的条件概率(Conditional Probability)。
“如果考前未复习,该科成绩有50%的可能性不及格。
”这就是一条概率推理。
需要说明的是:真正的确定性推理在真实世界中并不存在。
即使条件概率P(A|B)为1,条件B存在,也不意味着结果A就确定一定会发生。
通常情况下,条件概率从大量实践中得来,它是一种经验数据的总结,但对于我们判别事物和预测未来没有太大的直接作用。
我们更关注的是如果我们发现了某个结果(或者某种现象),那么造成这种结果的原因有多大可能存在?这就是逆概率推理的含义。
即:如条件B存在,则结果A存在的概率为P(A|B)。
现在发现结果A出现了,求结果B存在的概率P(B|A)是多少?例如:如果已知地震前出现“地震云”的概率,现在发现了地震云,那么会发生地震的概率是多少?再如:如果已知脑瘤病人出现头痛的概率,有一位患者头痛,他得脑瘤的概率是多少?解决这种逆概率推理问题的理论就是以贝叶斯公式为基础的贝叶斯理论。


标题:深度剖析朴素贝叶斯分类器中的拉普拉斯平滑一、概述朴素贝叶斯分类器是一种经典的概率模型,常用于文本分类、垃圾邮件过滤等领域。
在朴素贝叶斯分类器中,拉普拉斯平滑是一种常用的平滑技术,用于解决零概率值的问题。
本文将深入剖析朴素贝叶斯分类器中的拉普拉斯平滑的原理和应用,帮助读者更好地理解这一技术。
二、朴素贝叶斯分类器简介1. 朴素贝叶斯分类器的基本原理朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,其基本原理是通过已知的数据计算各个特征在不同类别下的条件概率,然后利用这些概率进行分类预测。
朴素贝叶斯分类器假设所有特征都是独立的,即给定类别下特征之间是条件独立的。
2. 朴素贝叶斯分类器的应用朴素贝叶斯分类器在文本分类、垃圾邮件过滤、情感分析等领域有着广泛的应用。
其简单、高效的特点使其成为机器学习领域中的经典算法之一。
三、拉普拉斯平滑的原理1. 拉普拉斯平滑的概念在朴素贝叶斯分类器中,当某个特征在某个类别下没有出现过时,其条件概率为0,这将导致整个概率的乘积为0,从而影响到分类的准确性。
为了解决这一问题,引入了拉普拉斯平滑。
拉普拉斯平滑通过给概率分布增加一个很小的偏移量,来避免出现零概率值。
2. 拉普拉斯平滑的计算公式设特征的取值个数为N,在某个类别下特征取值为xi的样本数量为ni,类别样本总数为m。
拉普拉斯平滑的计算公式为:P(xi|C) = (ni + 1) / (m + N)四、拉普拉斯平滑的应用1. 拉普拉斯平滑在朴素贝叶斯分类器中的应用在朴素贝叶斯分类器中,拉普拉斯平滑常常被用来解决零概率值的问题。
通过拉普拉斯平滑,可以有效地平衡已知特征与未知特征之间的概率关系,提高分类器的准确性。
2. 拉普拉斯平滑的优缺点拉普拉斯平滑能够有效地避免零概率值的问题,提高了模型的稳定性和鲁棒性。
但是,在特征空间较大时,拉普拉斯平滑会导致概率的偏移,影响分类的准确性。
五、拉普拉斯平滑的改进1. 改进的拉普拉斯平滑算法为了克服传统拉普拉斯平滑的缺点,近年来提出了一些改进的拉普拉斯平滑算法,如修正的拉普拉斯平滑、Bayesian平滑等。

贝叶斯分类器应用实例贝叶斯分类器是一种常用的机器学习算法,其基本原理是根据已有的训练数据,通过统计学方法预测新数据的类别。
贝叶斯分类器的应用非常广泛,其中包括垃圾邮件过滤、情感分析、文本分类等。
在本文中,我将详细介绍贝叶斯分类器在垃圾邮件过滤和情感分析上的应用实例,并介绍其原理和实现步骤。
一、垃圾邮件过滤垃圾邮件过滤是贝叶斯分类器的经典应用之一。
在垃圾邮件过滤中,贝叶斯分类器被用来预测一封邮件是垃圾邮件还是正常邮件。
其原理是根据已有的标记为垃圾邮件或正常邮件的训练数据,计算出某个词语在垃圾邮件和正常邮件中出现的概率,并据此预测新邮件的类别。
具体实现步骤如下:1.收集和准备数据集:需要收集足够数量的已标记为垃圾邮件和正常邮件的数据集,并对其进行预处理,如去除停用词、标点符号等。
2.计算词频:统计每个词语在垃圾邮件和正常邮件中的出现次数,并计算其在两类邮件中的概率。
3.计算条件概率:根据已有的训练数据,计算每个词语在垃圾邮件和正常邮件中的条件概率。
4.计算先验概率:根据已有的训练数据,计算垃圾邮件和正常邮件的先验概率。
5.计算后验概率:根据贝叶斯公式,计算新邮件在垃圾邮件和正常邮件中的后验概率。
6.预测结果:将新邮件归类为垃圾邮件或正常邮件,取后验概率较高的类别。
通过以上步骤,我们可以实现一个简单的垃圾邮件过滤器。
在实际应用中,可以根据需要进行改进,如考虑词语的权重、使用更复杂的模型等。
二、情感分析情感分析是另一个贝叶斯分类器常用的应用领域。
在情感分析中,贝叶斯分类器被用来预测文本的情感倾向,如正面、负面或中性。
具体实现步骤如下:1.收集和准备数据集:需要收集足够数量的已标记为正面、负面或中性的文本数据集,并对其进行预处理,如分词、去除停用词等。
2.计算词频:统计每个词语在正面、负面和中性文本中的出现次数,并计算其在三类文本中的概率。
3.计算条件概率:根据已有的训练数据,计算每个词语在正面、负面和中性文本中的条件概率。