地类编码表
- 格式:doc
- 大小:68.50 KB
- 文档页数:4


编码名称
编码名称编码名称
编码名称1
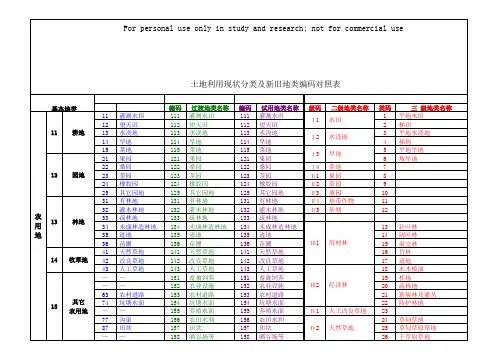
011水田10
101铁路用地012水浇地102公路用地013旱地103街巷用地2
021果园104农村道路022茶园105机场用地023其它园地106港口码头用地3
031有林地107管道运输用地032灌木林地11
111河流水面033其它林地112湖泊水面4
041天然牧草地113水库水面042人工牧草地114坑塘水面043其它草地115沿海滩涂5
051批发零售用地116内陆滩涂052住宿餐饮用地117沟渠053商务金融用地118水工建筑用地054
其它商服用地119冰川及永久积雪
061工业用地12
121空闲地062采矿用地122设施农用地
063
仓储用地123田坎7071城镇住宅用地124盐碱地072农村宅基地125沼泽地8
081机关团体用地126沙地082新闻出版用地127
裸地
083
科教用地20
084医卫慈善用地085文体娱乐用地201城市086公共设施用地202建制镇087公园与绿地203村庄088风景名胜设施用
地
204采矿用地091军事设施用地205
风景名胜及特殊用地
092
使领馆用地9
093监教场所用地094宗教用地095
殡葬用地
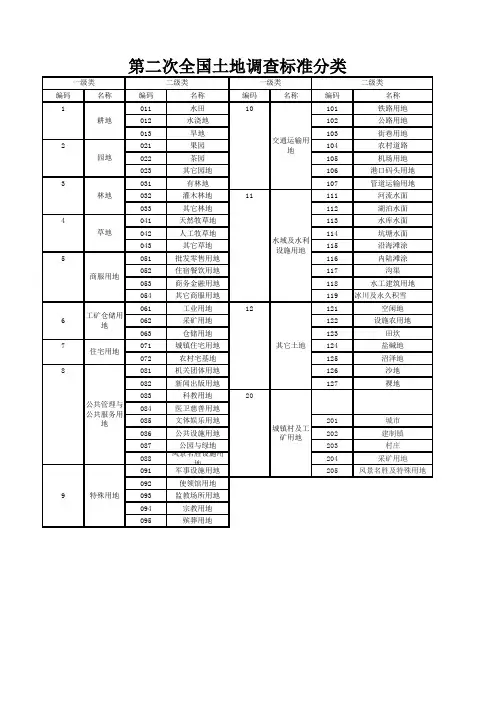
一级类
二级类
林地
草地
商服用地第二次全国土地调查标准分类
城镇村及工矿用地
一级类二级类
耕地
园地
特殊用地
交通运输用
地
水域及水利设施用地
其它土地
6工矿仓储用
地
公共管理与公共服务用
地
住宅用地。


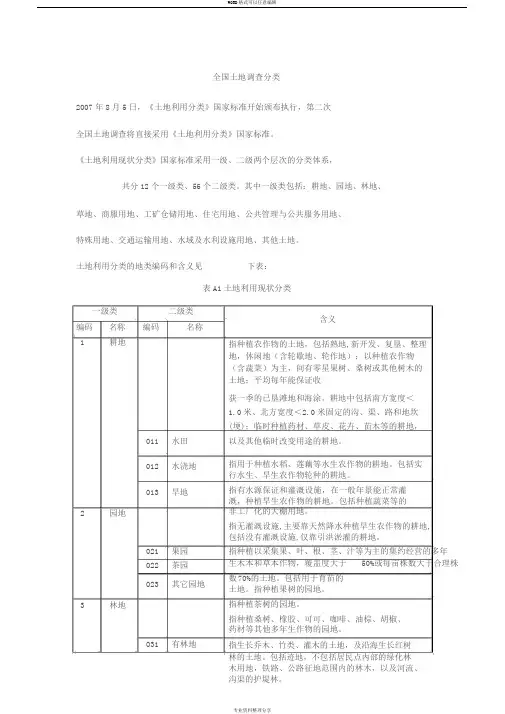
全国土地调查分类2007年8月5日,《土地利用分类》国家标准开始颁布执行,第二次全国土地调查将直接采用《土地利用分类》国家标准。
《土地利用现状分类》国家标准采用一级、二级两个层次的分类体系,共分12个一级类、56个二级类。
其中一级类包括:耕地、园地、林地、草地、商服用地、工矿仓储用地、住宅用地、公共管理与公共服务用地、特殊用地、交通运输用地、水域及水利设施用地、其他土地。
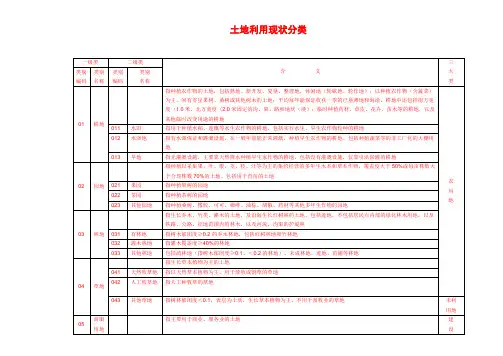
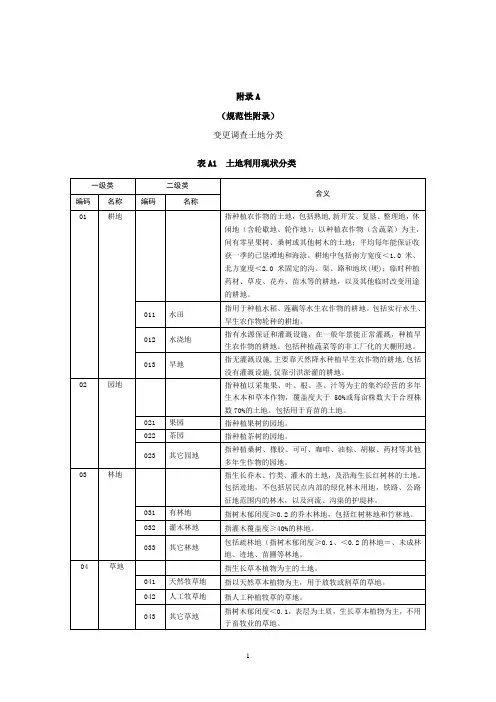
土地利用分类的地类编码和含义见下表:表A1土地利用现状分类一级类二级类编码名称编码名称1耕地011 水田012 水浇地013 旱地2园地021 果园022 茶园023 其它园地3林地031 有林地含义指种植农作物的土地,包括熟地,新开发、复垦、整理地,休闲地(含轮歇地、轮作地);以种植农作物(含蔬菜)为主,间有零星果树、桑树或其他树木的土地;平均每年能保证收获一季的已垦滩地和海涂。
耕地中包括南方宽度<1.0米、北方宽度<2.0米固定的沟、渠、路和地坎(埂);临时种植药材、草皮、花卉、苗木等的耕地,以及其他临时改变用途的耕地。
指用于种植水稻、莲藕等水生农作物的耕地。
包括实行水生、旱生农作物轮种的耕地。
指有水源保证和灌溉设施,在一般年景能正常灌溉,种植旱生农作物的耕地。
包括种植蔬菜等的非工厂化的大棚用地。
指无灌溉设施,主要靠天然降水种植旱生农作物的耕地,包括没有灌溉设施,仅靠引洪淤灌的耕地。
指种植以采集果、叶、根、茎、汁等为主的集约经营的多年生木本和草本作物,覆盖度大于50%或每亩株数大于合理株数70%的土地。
包括用于育苗的土地。
指种植果树的园地。
指种植茶树的园地。
指种植桑树、橡胶、可可、咖啡、油棕、胡椒、药材等其他多年生作物的园地。
指生长乔木、竹类、灌木的土地,及沿海生长红树林的土地。
包括迹地,不包括居民点内部的绿化林木用地,铁路、公路征地范围内的林木,以及河流、沟渠的护堤林。
指树木郁闭度≥0.2的乔木林地,包括红树林地和竹林地。

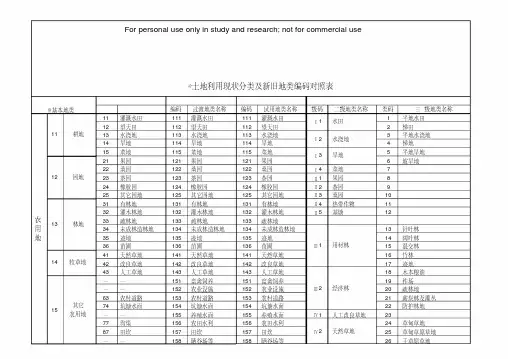
土地利用现状分类地类编码Company number:【WTUT-WT88Y-W8BBGB-BWYTT-19998】01——耕地10——交通运输用地011:水田 101:铁路用地012:水浇地 102:公路用地013:旱地 103:街巷用地02——园地 104:农村道路021:果园 105:机场用地022:茶园 106:港口码头用地023:其它园地 107:管道运输用地03——林地11——水域及水利设施用地031:有林地 111:河流水面032:灌木林地 112:湖泊水面033:其它林地 113:水库水面04——草地 114:坑塘水面041:天然牧草地 115:沿海滩涂042:人工牧草地 116:内陆滩涂043:其它草地 117:沟渠05——商服用地 118:水工建筑用地051:批发零售用地 119:冰川及永久积雪052:住宿餐饮用地 12——其它土地053:商务金融用地 121:空闲地054:其它商服用地 122:设施农用地06——工矿仓储用地 123:田坎061:工业用地 124:盐碱地062:采矿用地 125:沼泽地063:仓储用地 126:沙地07——住宅用地 127:裸地071:城镇住宅072:农村宅基地08——公共管理与公共服务用地081:机关团体用地082:新闻出版用地083:科教用地084:医卫慈善用地085:文体娱乐用地086:公共设施用地087:公园与绿地088:风景名胜设施用地09——特殊用地091:军事设施用地092:使领馆用地093:监教场所用地094:宗教用地095:殡葬用地。
地类编码对照表地类编码对照表是用于标识和分类地表覆盖类型的一种工具。
它将地表覆盖类型进行编码,并提供了对照表,使人们可以快速准确地理解每个编码所代表的地表特征。
地类编码对照表在地理信息系统(GIS)和土地利用规划等领域中被广泛使用。
地类编码对照表的设计和使用旨在统一和系统地描述和分类地表覆盖类型。
通过给每个地表覆盖类型分配一个唯一的编码,地类编码对照表使得不同用户在不同地理位置之间可以共享和交换地表覆盖信息。
这样,地表覆盖类型不同的地方在进行数据交流和分析时就可以得到一致和可比的结果。
地类编码对照表一般包括两个主要部分:编码和对照表。
编码通常由数字和字母组成,每个编码代表一种地表覆盖类型。
对照表则提供了每个编码所代表的地表特征的详细说明。
对照表中的信息可以包括地表覆盖类型的名称、定义、特征描述、典型的出现条件、相关示例等。
通过对照表,用户可以快速了解和理解每个地表覆盖类型所代表的含义和特征。
地类编码对照表的使用可以帮助用户更好地理解和分析地表覆盖数据。
例如,在一个土地利用规划项目中,可以使用地类编码对照表对不同地块的地表覆盖类型进行编码和分类。
这样,不同的地表覆盖类型就可以被统一标识和描述,便于进一步的数据分析和决策支持。
地类编码对照表的制定需要考虑到地理环境的多样性和变化性。
不同地区的地表覆盖类型可能会有差异,因此,在制定地类编码对照表时需要考虑到这些差异,以保证地表覆盖类型的描述和分类是准确和有效的。
地类编码对照表的设计还需要考虑到扩展性和更新性。
由于地表覆盖类型可能会随着时间的推移而发生变化,所以地类编码对照表应该具备扩展性和更新性,以便可以适应新的地表覆盖类型的出现和描述。
总之,地类编码对照表是一种用于标识和分类地表覆盖类型的工具。
它可以帮助用户统一和系统地描述和理解地表覆盖数据,便于数据交流和分析。
地类编码对照表的设计和使用需要考虑到地理环境的差异性和变化性,并具备扩展性和更新性。
通过使用地类编码对照表,可以更好地利用地表覆盖数据进行土地利用规划、资源管理、环境保护等工作,提高决策的准确性和效率。
d、n、x、b,以居民房屋坐北朝南为基准方向,分别对应房
d、x、n、b表示其连线或
tgjdxg,同理类推置记在byg前面,连线方向记在byg后面,如单杆变压器,变压器在电杆的北边,电杆高为bbygn,同理类推;Ø双线沟渠、单线沟渠以及一些道路通往某处就到头了,则记为
**ltou;Ø水稻田、旱地、荒地、果园等记不住地物名称,可注记在高程点上,记为h
后四个方向;Ø电力杆、通讯杆、田埂、沟渠等点名后面直接加d、x、n、b表示其连线或线沟渠、双线田埂等双线形地物,为了区别同一处两边的点,以东、南、西、北来区别,面,如:nxsxgnbx表示该双线沟渠通往南北西三个方向,而该点是位于南北流向的西侧,且是东西流向的起点;Ø以同一点表示不同地物,如:双线沟渠的边点与河岸线的点
tgjdxg,同理类推
byg后面,如单杆变压器,变压器在电杆的北边,电杆高
h
gygnbrdd表示高压杆南北接高压线,东接地;Ø该套
连线方向记在byg后面,如单杆变压器,变压器在电杆的北边,电杆高压线往南连,则记推;Ø双线沟渠、单线沟渠以及一些道路通往某处就到头了,则记为sxgtou、dxgtou、、旱地、荒地、果园等记不住地物名称,可注记在高程点上,记为hsdt、hcd、hbhd、
力杆、通讯杆、田埂、沟渠等点名后面直接加d、x、n、b表示其连线或通往的方向;Ø双等双线形地物,为了区别同一处两边的点,以东、南、西、北来区别,记在sxg或sxtg前表示该双线沟渠通往南北西三个方向,而该点是位于南北流向的西侧,东西流向的南的起点;Ø以同一点表示不同地物,如:双线沟渠的边点与河岸线的点是同一点,则记为
记在rd。