三因素实验设计
- 格式:doc
- 大小:1.67 MB
- 文档页数:27


三因素实验设计例子
1. 嘿,想想看选礼物这件事!比如说你要给朋友选个生日礼物,这就是个三因素实验设计呀!礼物的类型、价格、品牌是不是就是那三个因素呢?不同的组合会有不同的效果哦!
2. 再比如说找工作,工作的行业、公司规模、薪资待遇,这不就是三个关键因素嘛!这就像是在搭积木,每一块的选择都好重要呀!
3. 吃一顿美食也可以这样想呀!餐厅的氛围、菜品的口味、服务的质量,妈呀,这三个因素决定了你这顿饭吃得开不开心呢,对吧?
4. 买衣服的时候呢,款式、颜色、材质,这三个因素会让你纠结好久,就好像在走迷宫一样,得好好琢磨呢!
5. 装修房子更是啦!风格、预算、材料,哇,这可真是个大工程,每个因素都不能马虎呀!
6. 旅游选目的地也一样哦!景点好不好玩、花费高不高、交通方不方便,这简直就是在做一场重大的决策嘛!
7. 选一部电影看也可以这样分析呀!类型、演员、评分,难道不是这三个重要因素影响你的选择吗?
8. 甚至谈恋爱也有类似的地方呀!对方的性格、长相、三观,哎呀,这三样可得好好考虑呢!
结论:生活中好多事情都可以用三因素实验设计来分析,是不是很有趣呀!。
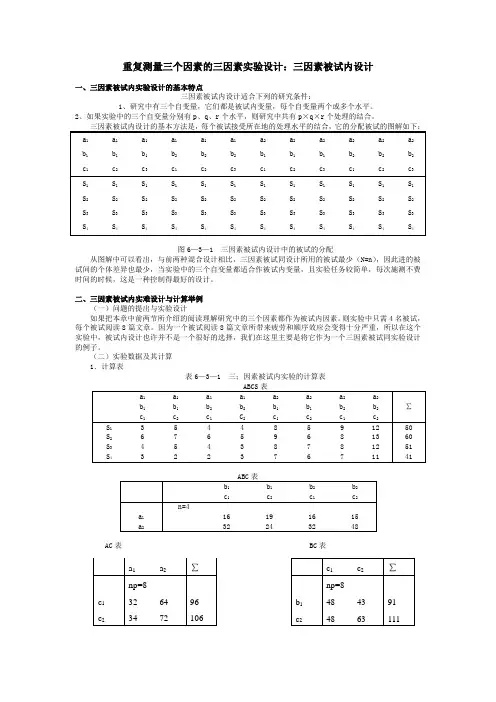
重复测量三个因素的三因素实验设计:三因素被试内设计一、三因素被试内实验设计的基本特点三因素被试内设计适合下列的研究条件:1、研究中有三个自变量,它们都是被试内变量,每个自变量两个或多个水平。
2、如果实验中的三个自变量分别有p 、q 、r 个水平,则研究中共有p ×q ×r 个处理的结合。
图6—3—1 三因素被试内设计中的被试的分配从图解中可以看出,与前两种混合设计相比,三因素被试同设计所用的被试最少(N=n ),因此进的被试间的个体差异也最少,当实验中的三个自变量都适合作被试内变量,且实验任务较简单,每次施测不费时间的时候,这是一种控制得最好的设计。
二、三因素被试内实难设计与计算举例(一)问题的提出与实验设计如果把本章中前两节所介绍的阅读理解研究中的三个因素都作为被试内因素。
则实验中只需4名被试,每个被试阅读8篇文章。
因为一个被试阅读8篇文章所带来疲劳和顺序效应会变得十分严重,所以在这个实验中,被试内设计也许并不是一个很好的选择,我们在这里主要是将它作为一个三因素被试同实验设计的例子。
(二)实验数据及其计算 1.计算表表6—3—1 三;因素被试内实验的计算表AC 表 BC 表111136202.00p q n rijkli j k l Y=====++=∑∑∑∑221111(202)[](4)(2)(2)(2)p q n r ijkl i j k l Y Y npqr ====⎛⎫⎪⎝⎭==∑∑∑∑=1275.1252221111[](3)(6)p q n rijkli j k l YABCS ======++∑∑∑∑=1544.0002221111(66)(136)[]1428.250(4)(2)(2)(4)(2)(2)q n r ijkl p i k l j Y A nqr ====⎛⎫⎪⎝⎭==+=∑∑∑∑ 2221111(91)(111)[]1287.625(4)(2)(2)(4)(2)(2)p n r ijkl p i j l k Y B npr ====⎛⎫⎪⎝⎭==+=∑∑∑∑ ACS 表 BCS 表2221111(96)(106)[]1278.250(4)(2)(2)(4)(2)(2)p q n ijkl ri j k l Y C nqr ====⎛⎫ ⎪⎝⎭==+=∑∑∑∑ 2221111(35)(56)[]1465.250(4)(2)(4)(2)n r ijkl p q i l j k Y AB nr ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(32)(34)[]1432.500(4)(2)(4)(2)q n ijkl p r i l j l Y AC nq ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(48)(48)[]1303.250(4)(2)(4)(2)p n ijkl q ri j k l Y BC np ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(16)(32)[]1506.50044n ijkl p q r i j k l Y ABC n ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(50)(60)[]1297.750(2)(2)(2)(2)(2)(2)p q r ijkl nj k l i Y S pqr ====⎛⎫ ⎪⎝⎭==++=∑∑∑∑2221111(8)(13)[]1496.00022r ijkl p q nl i j k Y ABS r ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(7)(12)[]1463.00022q ijkl p n r k i j l Y ACS q ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(11)(15)[]1329.00022p ijkl q n rj i k l Y BCS p ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(16)(24)[]1456.500(2)(2)(2)(2)q r ijkl n r k l i j Y AS qr ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(21)(28)[]1312.000(2)(2)(2)(2)p r ijkl q nj l i k Y BS pr ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(24)(29)[]1301.000(2)(2)(2)(2)p q ijkl n rj k i l Y CS pq ====⎛⎫⎪⎝⎭==++=∑∑∑∑3.平方和的分解与计算(1)平方和的分解模式SS总变异=SS被试间SS被试内=SS被试间+(SSA+SS A×被试+SSB+SS B×被试+SSC+SS C×被试+SSAB+SS A×B×被试+SSAC+SS A×C×被试+SSBC+SS B×C×被试+SSABC+SS A×B×C×被试)(2)平方和的计算SS总变异=[ABCS]-[Y]=268.875SS被试间=[S]-[Y]=22.625SS被试内=SS总变异-SS被试间=246.250SSA=[A]-[Y]=153.125SS A×被试=[AS]-[Y]-SS补试间-SSA=5.625SSB=[B]-[Y]=12.500SS B×被试=[BS]-[Y]-SS被试间-SSB=1.750SSC=[C]-[Y]=3.125SS C×被试=[CS]-[Y]-SS被试间-SSC=0.125SSAB=[AB]-[Y]-SSA-SSB=24.500SS A×B×被试=[ABS]-[Y]-SS被试间-SSA-SSB-SSAB-SS A×被试-SS B×被试=0.750SSAC=[AC]-[Y]-SSA-SSC=1.125SS A×C×被试=[ACS]-[Y]-SS被试间-SSA-SSC-SSAC-SS A×被试-SS C×被试=2.125SSBC=[BC]-[Y]-SSB-SSC=12.500SS B×C×被试=[BCS]-[Y]-SS被试间-SSB-SSC-SSBC-SS B×被试-SS C×被试=1.250SSABC=[ABC]-[Y]-SSA-SSB-SSC-SSAB-SSAC-SSBC=24.500SS A×B×C×被试=SS被试内-SSA-SS A×被试-SSB-SS B×被试-SSC-SS C×被试-SSAB-SS A×B×被试-SSAC-SS A×C×被试-SSBC-SS B×C×被试-SSABC=3.250在表6-3-2中的方差分析结果表明,三个被试内因素——生字密度(A因素)F p=<、文章类型(B因素)((1,3)21.43,.05)=<、平均句长(C因素)F p((1,3)81.67,.01)=<的主效应都是显著的,AC的交互作用是不是显著的F p((1,3)75.00,.01)=<,其余交互作用((1,3)98.00,.01)=<、AB F pF p((1,3) 1.59,.05)ABC F p=<、((1,3)22.62,.05)=<都是显著的。

实验设计的“三要素“完善的实验设计方案具备以下要素:实验所需的人力、物力和时间资源;对实验数据的收集、整理、分析等有一套规范的规定和正确的方法。
而其中准确把握统计研究设计的“三要素和六原则”,是科学实验设计的核心。
一、实验设计的“三要素”1、实验对象:实验所用的材料即为实验对象。
如用小鼠做实验,小鼠就是本次实验的实验对象,或称为受试对象。
实验对象选择的合适与否直接关系到实验实施的难度,以及别人对实验新颖性和创新性的评价。
一个完整的实验设计中所需实验材料的总数称为样本含量。
较好根据特定的设计类型估计出较合适的样本含量。
样本过大或过小都有弊端。
2、实验因素:所有影响实验结果的条件都称为影响因素,实验研究的目的不同,对实验的要求也不同。
影响因素有客观与主观,主要与次要因素之分。
研究者希望通过研究设计进行有计划的安排,从而能够科学地考察其作用大小的因素称为实验因素(如药物的种类、剂量、浓度、作用时间等);对评价实验因素作用大小有一定干扰性且研究者并不想考察的因素称为区组因素或称重要的非实验因素(如动物的窝别、体重等);其他未加控制的许多因素的综合作用统称为实验误差。
较好通过一些预实验,初步筛选实验因素并确定取哪些水平较合适,以免实验设计过于复杂,实验难以完成。
3、实验效应:实验因素取不同水平时在实验单位上所产生的反应称为实验效应。
实验效应是反映实验因素作用强弱的标志,它必须通过具体的指标来体现。
要结合专业知识,尽可能多地选用客观性强的指标,在仪器和试剂允许的条件下,应尽可能多选用特异性强、灵敏度高、准确可靠的客观指标。
对一些半客观(比如读pH试纸上的数值)或主观指标(对一些定性指标的判断上),一定要事先规定读取数值的严格标准,只有这样才能准确地分析自己的实验结果,从而也大大提高了自己实验结果的可信度。
二、实验设计的“六原则”1、随机原则:即运用“随机数字表”实现随机化;运用“随机排列表”实现随机化;运用计算机产生“伪随机数”实现随机化。


毕业论文实验设计的三大要素和四个原则一般来说,应具备以下条件:人力、物力和时间满足设计要求;实验设计的三要素和四原则均符合专业和统计学要求;重要的实验因素和观测指标没有遗漏,并做了合理安排;重要的非实验因素(包括可能产生的各种偏性)都得到了很有效的预防和控制;研究过程中可能出现的各种情况都已考虑在内,并有相应的对策和严格的质量控抗对操作方法、实验数据的收集、整理、分析等均有一套规范的规定和正确的方法。
而其中准确把握统计研究设计的三要素和四原则,无疑是其设计方案科学严谨的象征。
毕业论文实验设计的三大要素:实验设计三要素应着重考虑:一、受试对象的种类问题。
这里面包含以下几种情形:l、一般医学科研常用动物、离体标本或人体内取得的某些样本作为受试对象;2、新药的临床前试验一般用动物作为受试对象;3.新药的临床试验阶段一般用人作为受试对象。
新药临床试验一般分为4期,在1期临床试验阶段,通常用健康志愿者作为受试对象;而在其他各期临床试验阶段,常用患特定疾病的患者作为受试对象。
选择什么样的患者,应有严格的规定。
二、实验因素。
实验研究的目的不同,对实验的要求也不同。
若在整个实验过程中影响观察结果的因素很多,就必须结合专业知识,对众多的因素做全面分析,必要时做一些预实验,区分哪些是重要的实验因素,哪些是重要的非重要的实验因素,以便选用合适的实验设计方法妥善安排这些因素。
水平选取的过于密集,实验次数就会增多,许多相邻的水平对结果的影响十分接近,不仅不利于研究目的的实现,而且将会浪费人力、物力和时间;反之,该因素的不同水平对结果的影响规律不能真实地反映出来,易于得出错误的结论。
在缺乏经验的前提下,应进行必要的预实验或借助他人的经验,选取较为合适的若干个水平。
所谓质量因素,就是因素水平的取值是定性的,如药物的种类、处理方法的种类等。
应结合实际情况和具体条件,选取质最因素的水平,千万不能不顾客观条件而盲目选取。
三、实验效应。

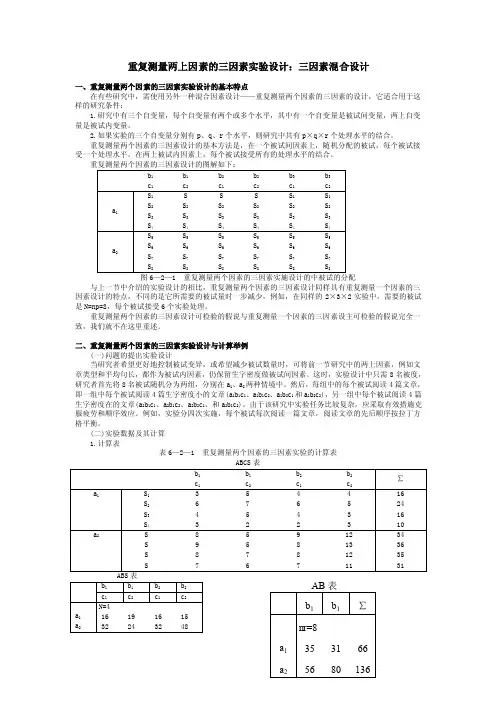
重复测量两上因素的三因素实验设计:三因素混合设计一、重复测量两个因素的三因素实验设计的基本特点在有些研究中,需使用另外一种混合因素设计——重复测量两个因素的三因素的设计,它适合用于这样的研究条件:1.研究中有三个自变量,每个自变量有两个或多个水平,其中有一个自变量是被试间变量,两上自变量是被试内变量。
2.如果实验的三个自变量分别有p 、q 、r 个水平,则研究中共有p ×q ×r 个处理水平的结合。
重复测量两个因素的三因素设计的基本方法是,在一个被试间因素上,随机分配的被试,每个被试接受一个处理水平。
在两上被试内因素上,每个被试接受所有的处理水平的结合。
与上一节中介绍的实验设计的相比,重复测量两个因素的三因素设计同样具有重复测量一个因素的三因素设计的特点,不同的是它所需要的被试量时一步减少,例如,在同样的2×3×2实验中,需要的被试是N=np=8,每个被试接受6个实验处理。
重复测量两个因素的三因素设计可检验的假说与重复测量一个因素的三因素设主可检验的假说完全一致,我们就不在这里重述。
二、重复测量两个因素的三因素实验设计与计算举例(一)问题的提出实验设计当研究者希望更好地控制被试变异,或希望减少被试数量时,可将前一节研究中的两上因素,例如文章类型和平均句长,都作为被试内因素,仍保留生字密度做被试间因素。
这时,实验设计中只需8名被度,研究者首先将8名被试随机分为两组,分别在a 1、a 2两种情境中。
然后,每组中的每个被试阅读4篇文章,即一组中每个被试阅读4篇生字密度小的文章(a 1b 1c 1、a 1b1c 2、a 1b 2c 1和a 1b 2c 2),另一组中每个被试阅读4篇生字密度在的文章(a 2b 1c 1、a 2b 1c 2、a 2b 2c 1、和a 2b 1c 2)。
由于该研究中实验任务比较复杂,应采取有效措施克服疲劳和顺序效应。
例如,实验分四次实施,每个被试每次阅读一篇文章,阅读文章的先后顺序按拉丁方格平衡。

实验设计的三要素和六原则众所周知,科研工作者在进行医药方面的科学研究之前,需要制定完善的统计研究设计方案,那么什么样的设计方案才称得上是完善的呢? 一般来说,完善的设计方案需具备以下几个条件:实验所需的人力、物力和时间资源;实验设计的“三要素”和“六原则”均符合专业和统计学要求,对实验数据的收集、整理、分析等有一套规范的规定和正确的方法。
而其中准确把握统计研究设计的“三要素和六原则”,是科学实验设计的核心。
一、实验设计的“三要素”1) 实验对象。
实验所用的材料即为实验对象。
实验对象选择的合适与否直接关系到实验实施的难度,以及别人对实验新颖性和创新性的评价。
一个完整的实验设计中所需实验材料的总数称为样本含量。
最好根据特定的设计类型估计出较合适的样本含量。
样本过大或过小都有弊端。
2) 实验因素。
所有影响实验结果的条件都称为影响因素,实验研究的目的不同,对实验的要求也不同。
影响因素有客观与主观,主要与次要因素之分。
研究者希望通过研究设计进行有计划的安排,从而能够科学地考察其作用大小的因素称为实验因素(如药物的种类、剂量、浓度、作用时间等);对评价实验因素作用大小有一定干扰性且研究者并不想考察的因素称为区组因素或称重要的非实验因素;其他未加控制的许多因素的综合作用统称为实验误差。
最好通过一些预实验,初步筛选实验因素并确定取哪些水平较合适,以免实验设计过于复杂,实验难以完成。
3) 实验效应。
实验因素取不同水平时在实验单位上所产生的反应称为实验效应。
实验效应是反映实验因素作用强弱的标志,它必须通过具体的指标来体现。
要结合专业知识,尽可能多地选用客观性强的指标,在仪器和试剂允许的条件下,应尽可能多选用特异性强、灵敏度高、准确可靠的客观指标。
对一些半客观(比如读pH试纸上的数值)或主观指标(对一些定性指标的判断上),一定要事先规定读取数值的严格标准,只有这样才能准确地分析自己的实验结果,从而也大大提高了自己实验结果的可信度。

三因素混合水平正交试验设计1. 什么是三因素混合水平正交试验设计?好家伙,提到“三因素混合水平正交试验设计”,听起来就像是一门深奥的科学,其实,它就像做菜一样,有点复杂,但其实也没那么吓人。
简单来说,这是一种科学的实验设计方法,主要用来研究多个因素对结果的影响。
就像你在调配一杯饮料,水、糖、柠檬三种成分的比例不同,最终的味道也会截然不同。
这里的“三因素”就是这三种成分,而“混合水平”则是指不同的比例。
正交试验就是为了找到一个最优组合,让你喝到最佳口感。
1.1 为什么要用这种设计?你可能会问,为什么不直接试一试,反正也不算难嘛?嘿,听我说,这就像我们在考试之前不复习一样,结果往往是惨不忍睹。
用正交试验设计,可以有效减少试验次数,提高效率,帮你快速找到最优解。
想象一下,如果你有八个不同的口味,而你想尝试每一种搭配,那简直是要你命啊!但如果用正交试验设计,选出几个关键的组合,快速找出最佳搭配,那就轻松多了。
1.2 具体怎么做?实施这个试验设计可不复杂,首先得确定你要研究的三个因素,比如说温度、时间和材料的配比。
然后,给每个因素设置几个水平。
比如,温度可以设为低、中、高;时间可以设为短、中、长;材料的配比可以设为少、中、多。
这样一来,咱们就有了一个清晰的试验框架。
接着,使用正交表来安排试验。
这就好比在选一场比赛的阵容,你不可能把所有的球员都上场,得挑出最有可能赢的组合。
正交表会帮你排出一个高效的试验顺序,确保每个因素的不同水平都能被试到。
2. 试验结果分析试完试验之后,结果就像一块拼图,得慢慢把它拼起来。
我们要统计每组试验的结果,然后分析哪种组合最有效。
这里就需要用到一些统计学的工具,比如方差分析。
这一步就像在做一份成绩单,看看谁是班里的“学霸”,哪个组合表现最好。
通过这种方式,我们不仅能看到结果,还能找到影响结果的关键因素。
2.1 结果可视化别忘了,把结果用图表展示出来,这样更直观。
数据就像一串串数字,光看不出啥,画成图就一目了然了。

临床实验设计三要素科研的基本要素包括处理因素、受试对象和实验效应。
如用某种传统西药或中成药治疗缺铁性贫血病人,观察比较两组病人血红蛋白的上升趋势,该研究中所用的两种药物称为处理因素,缺铁性贫血病人称为受试对象,血红蛋白称为实验效应。
如何正确选择三大要素是科研中专业设计的关键问题。
科研的基本要素包括处理因素、受试对象和实验效应。
如用某种传统西药或中成药治疗缺铁性贫血病人,观察比较两组病人血红蛋白的上升趋势,该研究中所用的两种药物称为处理因素,缺铁性贫血病人称为受试对象,血红蛋白称为实验效应。
如何正确选择三大要素是科研中专业设计的关键问题。
1 处理因素(受试因素) 通常指由外界施加于受试对象的因素,包括生物的、化学的、物理的或内外环境的。
但是生物本身的某些特征(如性别、年龄、民族、遗传特性、心理因素等)也可作为处理因素来进行观察。
因此,研究者应正确、恰当地确定处理因素。
一般应注意以下几点:①抓住实验研究中的主要因素。
研究中的主要因素是按以往研究基础上(本人或他人)提出的某些假设和要求来决定的。
一次实验涉及的处理因素不宜太多,否则会使分组增多,受试对象的例数增多,在实施中难以控制误差。
然而,处理因素过少,又难以提高实验的广度和深度。
因此,需根据研究目的的需要与实施的可能来确定带有关键性的因素。
②找出非处理因素。
除了确定的处理因素以外,凡是影响实验结果的其他因素都称为非处理因素,所产生的混杂效应也影响了处理因素产生的效应对比和分析,这些非处理因素又称混杂因素。
例如上述两种不同药物治疗缺铁性贫血病人的试验,非处理因素可能有年龄、性别、营养状况等。
如果两组病人的年龄、性别、营养等构成不一,则可能影响药物疗效的比较。
因此设计时便设法控制这些非处理因素,只有这样才能消除它们的干扰作用,减小实验误差。
③处理因素必须标准化。
处理因素的强度、频率、持续时间与施加方法等,都要通过查阅文献和预备试验找出各自的最适条件,然后订出有关规定和制度,并使之相对固定,否则会影响试验结果的评价。
三因素三水平正交试验1. 介绍在实验设计中,正交试验是一种常用的方法,用于确定最佳的实验参数组合,并减少因素交互效应的影响。
而三因素三水平正交试验是其中一种常见的正交试验设计,用于研究三个因素对实验结果的影响。
本文将介绍三因素三水平正交试验的基本概念、优势和步骤,并提供一个示例,以帮助读者更好地理解和应用这种试验设计。
2. 正交试验的基本概念正交试验是一种多因素实验设计的方法,旨在通过控制因素的水平和组合,来研究它们对特定结果的影响。
正交试验设计有助于确定最佳的实验参数,并消除因素之间的交互效应,从而提高实验结果的可靠性。
在三因素三水平正交试验中,有三个因素被考虑,并对每个因素设定了三个水平。
这种设计允许研究人员观察每个因素在不同水平下对实验结果的影响,并确定最佳的因素组合。
3. 三因素三水平正交试验的优势三因素三水平正交试验相比其他试验设计方法具有以下几个优势:3.1. 有效地探索因素影响三因素三水平正交试验设计使得研究人员能够在相对较少的试验次数下,对多个因素的影响进行全面的探索。
通过设置不同的水平组合,可以快速确定每个因素对实验结果的主要影响。
3.2. 消除因素交互效应正交试验设计的一个主要优势是能够减少因素之间的交互效应。
交互效应指的是因素之间相互作用导致的实验结果不稳定性。
通过精确控制因素的水平和组合,正交试验设计可以有效地减少这种交互效应的影响,使得实验结果更加可靠。
3.3. 省时省力三因素三水平正交试验设计不仅能够减少试验次数,还能够减少实验过程中的工作量和成本。
通过精确控制因素的水平和组合,可以快速收集到有意义的实验数据,并减少不必要的重复实验。
4. 三因素三水平正交试验的步骤下面是进行三因素三水平正交试验的基本步骤:4.1. 确定因素和水平首先,确定三个要研究的因素,并为每个因素确定三个水平。
确保选择的因素和水平与研究目标一致。
4.2. 构建正交试验表根据确定的因素和水平,构建正交试验表。
实验设计中的三因素设计实验是科学研究的基础,而实验设计的质量则直接关系到实验结果的可靠性和有效性。
在实验设计中,考虑各种因素的影响是非常重要的。
其中,三因素设计就是一种应用广泛的实验设计方法。
本文将从三因素设计的概念、方法和优点三个方面来进行探讨。
概念三因素设计是一种同时考虑三种不同因素对结果影响的实验设计方法,这三种因素可以是任何可以量化的变量,比如温度、时间、pH、浓度、压力等等。
三因素设计的核心是将多个因素进行组合,来实现对实验结果的全面考虑。
例如,当我们研究某种材料的耐高温性时,我们可以将温度、时间和材料类别这三个因素进行设计。
我们可以将温度设置在600℃、800℃、1000℃这三个不同的水平,时间设置在1小时、2小时、3小时这三个不同的水平,材料类别设置为A、B、C这三种不同的类型,并对这27种不同的情况进行对比实验,从而评价出不同因素对结果的影响,以及不同因素之间的相互作用关系。
方法三因素设计的主要思路是:将三个不同的因素划分为若干个不同的水平,再将不同的水平进行组合。
在实验中,要求不同水平的因素单独改变,而其他因素保持不变。
因此,三因素设计的实验过程中需要对实验现场进行分组和编码等操作,并考虑到实验的可重复性、可操作性等方面的问题。
此外,三因素设计还需要进行统计分析,以得出实验结果对因素的响应特征和相互作用关系等有价值的信息。
具体地,三因素设计可以采用两种实验方针,分别是“正交实验设计”和“非正交实验设计”。
正交实验设计通常是在确定好三个因素及其各自水平的范围后,采用正交表的方法套用,不同水平的组合就是正交组合,这样可以避免因素之间的混淆作用,使得实验结果更加准确和可靠。
正交实验设计可以区分出哪些因素是重要的,哪些因素是不重要的,进而为深入探究因素间的相互关系提供了很好的基础。
非正交实验设计则可以更加灵活地设置因素和水平,进而探索实验系统的更多潜在信息。
在非正交实验设计中,研究者可以自由选择因素和水平,并设置相应的实验方案和实验装置,比如可以采用全因素对每因素进行实验方式,也可以采用定量因素水平对每因素根据不同水平量化等方式。
三因素实验设计对三因素重复测量实验设计进行数据处理一、三因素完全随机实验设计数据处理过程:1、打开SPSS软件,点击Data View ,进入数据输入窗口,将原始数据输入SPSS 表格区域;2、在菜单栏中选择分析→一般线性模型→单变量;3、因变量Dependent Variable方框中放入记忆成绩(JY),固定变量(Fixed Factor(s))方框中,放入自变量记忆策略、有无干扰和材料类型;4、点击选项(Options)按钮,选择Descriptive statistics,对数据进行描述性统计;选择Homogeneity tests,进行方差齐性检验;5.结果分析:描述性统计量因变量:记忆成绩记忆策略有无干扰材料类型均值标准偏差N联想策略dimension2无干扰实物图片5图形图片5总计10有干扰实物图片5图形图片.894435总计10总计实物图片10图形图片10总计20复述策略dimension2无干扰实物图片5图形图片5总计10有干扰实物图片5图形图片.836665总计10总计实物图片10图形图片10总计20总计dimen 无干扰实物图片10图形图片10总计20有干扰实物图片10图形图片10s i o n 2总计20总计实物图片20图形图片20总计40被试间变量效应检验结果:A、B、C的主效应均极显着(P<);AB 交互效应显着;AC 交互效应极显着;BC 交互效应不显着;ABC 交互效应极显着。
对于二阶与三阶交互效应显着的,还需进行简单效应与简单简单效应检验。
主体间效应的检验因变量:记忆成绩源III 型平方和df均方F Sig.校正模型7.000截距1.000 A1.000 B1.000 C1.001 A * B1.037A * C1.007B * C1.146 A * B * C1.002误差32总计40校正的总计39主体间效应的检验因变量:记忆成绩源III 型平方和df均方F Sig.校正模型7.000截距1.000 A1.000 B1.000 C1.001 A * B1.037A * C1.007B * C1.146 A * B * C1.002误差32总计40校正的总计39a. R 方 = .852(调整 R 方 = .819)简单效应检验:在主对话框中,单击Paste按钮,SPSS会把原先的全部操作转换成语句并粘贴到新打开的程序语句窗口中,在命令语句中加入EMMEANS引导的语句;结果:当被试使用联想策略进行记忆时,无干扰条件的记忆成绩极显着优于有干扰条件的记忆成绩;当被试使用复述策略进行记忆时,无干扰条件的记忆成绩也极显着优于有干扰条件的记忆成绩。
当被试使用联想策略进行记忆时,实物图片的记忆成绩极显着优于图形图片的记忆成绩;当被试使用复述策略进行记忆时,实物图片与图形图片的记忆成绩无显着差异。
简单简单效应检验:结果:所以a,b,c有显着差异。
二、重复测量一个因素的三因素混合实验设计数据处理过程:1.Data View ,进入数据输入窗口,将原始数据输入SPSS表格区域2.Analyze → General Linear Model → Repeated Measures(在菜单栏中选择分析→一般线性模型→重复变量)3.在定义被试内变量(Within-Subject Factor Name)的方框中,设置被试内变量标记类型,在定义其水平(Number of Level)的对框中,输入3,表示有两个水平,然后按填加(Add)钮。
4.按定义键(Define),返回重复测量主对话框,将b1、b2、b3选入被试内变量(Winthin-Subjects Variables)方框中,将a、c选入被试间变量框中。
5.点击选项Options,进行如下操作:①将被试内变量b(三个水平)键入到右边的方框中,采用[LSD(none)]法进行多重比较,②选择Descriptive statistics命令,对数据进行描述性统计。
选择Homogeneity tests进行方差齐性检验。
6.单击continue选项,返回主对话框,点击OK,执行程序。
7.结果:一元方差分析:标记类型主效应显着,F=,P=;句长类型主效应检验,因其满足球形假设,故参见每项检验的第一行SphericityAssumed的结果,即,F=,P=.000,表明b变量主效应极其显着;a与b的交互效应检验。
因其满足球形假设,故参见标准一元方差分析的结果,即F=,P=.001,表明a与b的交互效应极显着。
多重比较:长句与中句之间差异极其显着(P=);长句与短句之间差异极其显着(P=);中句与短句之间差异也极其显着(P=)。
描述性统计量有无干扰显示时间均值标准偏差N实物图片dimension1无干扰dimension230秒.95743415秒4总计8有干扰dimension230秒.95743415秒4总计8总计dimension230秒815秒8总计16数字图片dimension1无干扰dimension230秒415秒4总计8有干扰dimension230秒415秒4总计8总计di30秒8me ns io n215秒8总计16符号图片dimension1无干扰dimension230秒.81650415秒4总计8有干扰dimension230秒.95743415秒.957434总计8总计dimension230秒.83452815秒8总计16协方差矩阵等同性的 Box 检验aBox 的 MF.749 df118 df2Sig..760检验零假设,即观测到的因变量的协方差矩阵在所有组中均相等。
a. 设计 : 截距 + a + c + a * c主体内设计: b多变量检验b效应值F假设 df误差 df Sig.b Pillai 的跟踪.803.000Wilks 的Lambda.197.000Hotelling 的跟踪.000Roy 的最大根.000 b * a Pillai 的跟踪.822.000c Greenhouse-Geisser.000 Huynh-Feldt.000下限.001误差(b)采用的球形度24 Greenhouse-GeisserHuynh-Feldt下限简单效应检验:结果:无标记的情况下,各句子类型之间不存在显着性差异,F=,P=;有标记的情况下,各句子类型之间存在极显着性差异,F=,P=。
三、重复测量两个因素的三因素混合实验设计数据处理过程:1.打开SPSS软件,点击Data View数据视图,进入数据输入窗口,将原始数据输入SPSS表格区域;2.在菜单栏中选择分析→一般线性模型→重复度量;3.分别定义两个被试内变量名及其水平数,点击“定义”;4、将b1c1、b1c2、b2c1、b2c2、b3c1、b3c2选入被试内变量(Winthin-Subjects Variables)方框中,将a选入被试间变量框中;5、点击选项Options,然后将被试内变量b(三个水平)键入到右边的方框中,采用LSD(none)法进行多重比较,并选择描述统计和方差齐性检验,点击继续,再点击确定输出结果;6.结果:描述性统计结果:描述性统计量有无干扰均值标准偏差Nb1c1dimension1无干扰.925828有干扰.834528总计16b1c2dim 无干扰8有干扰8nsion1Box’s方差齐性结果:P=>,所以各组数据方差齐性。
协方差矩阵等同性的 Box 检验aBox 的 MFdf121 df2Sig..395检验零假设,即观测到的因变量的协方差矩阵在所有组中均相等。
a. 设计 : 截距 + a主体内设计: b + c + b * c多变量检验:因为P=0<,所以B的主效应极显着;而且P=0<,BA的交互作用极显着;同理可知:C的主效应极显着,CA的交互效应不显着,BCA的三阶交互效球形假设检验:被试内变量球形假设检验,由于c变量只有两个水平,所以不a. 可用于调整显着性平均检验的自由度。
在"主体内效应检验"表格中显示修正后的检验。
b. 设计 : 截距 + a主体内设计: b + c + b * cLevene’s方差齐性检验结果:因为P>,各组因变量方差齐性。
误差方差等同性的 Levene 检验aF df1df2Sig.b1c1.168114.688 b1c2.009114.926 b2c1.152114.702 b2c2.453114.512 b3c1.399114.538 b3c2.610114.448检验零假设,即在所有组中因变量的误差方差均相等。
a. 设计 : 截距 + a主体内设计: b + c + b * c被试间变量效应:因为P=0<,A的主效应极显着。
主体间效应的检验度量:MEASURE_1转换的变量:平均值源III 型平方和df均方F Sig.截距1.000 a1.000误差14b因素的多重比较结果:实物图片的记忆成绩显着优于数字图片和符号图片,数成对比较度量:MEASURE_1(I) b(J) b均值差值(I-J)标准误差差分的 95% 置信区间a下限上限12.781*.163.000.4313*.257.00021*.163.0003*.220.00031*.257.0002*.220.000基于估算边际均值*. 均值差值在 .05 级别上较显着。
a. 对多个比较的调整:最不显着差别(相当于未作调整)。
进行简单效应检验:因为BA交互效应显着,需进行简单效应检验;程序语句:结果截图:b*a描述性统计结果b*a配对比较结果进行简单简单效应检验:BCA三阶交互效应显着,还需进行简单简单效应检验。
程序语句:在a水平下b*c交互效应配对比结果四、三因素重复测量实验设计数据处理过程:1.打开SPSS软件,点击Data View ,进入数据输入窗口,将原始数据输入SPSS 表格区域;2.在菜单栏中选择分析→一般线性模型→重复变量;3.在定义被试内变量(Within-Subject Factor Name)的方框中,设置被试内变量标记类型,在定义其水平(Number of Level)的对框中,输入3,表示有两个水平,然后按填加(Add)钮。
4.将a1b3c1、a1b3c2、a2b1c1、a2b1c2、a2b2c1、a2b2c2、a2b3c1、a2b3c2等选入被试内变量(Winthin-Subjects Variables)方框中,将a选入被试间变量框中;5.点击选项Options,然后将被试内变量b(三个水平)键入到右边的方框中,采用LSD(none)法进行多重比较,并选择描述统计和方差齐性检验,点击继续,再点击确定输出结果;6.结果:3个自变量之间两两都有显着差异,3者之间也有显着差异。