实验二数字特征中的统计计算
- 格式:doc
- 大小:211.00 KB
- 文档页数:5

实验一常用计算方法及描述统计量分析1.引言描述统计量是统计学中常用的数据分析方法。
通过统计样本数据的各种特征指标,可以对总体数据的一些性质进行分析和描述。
本实验主要介绍几种常用的计算方法及描述统计量分析。
2.均值均值是描述数据集中趋势的一个重要统计量。
一组数据的均值可以通过将所有观察值相加,然后除以观察值的总数来计算。
均值可以用来描述一个数据集的集中趋势,通常用符号μ来表示。
3.中位数中位数是将一组有序数据划分为较小和较大两部分的值,位于中间位置的值。
对于一个有序的数据集,中位数就是位于中间位置的数值。
如果数据集的观察值个数是奇数,则中位数是排在中间的值;如果数据集的观察值个数是偶数,中位数是排在中间两个值的平均值。
4.众数众数是数据集中出现频率最高的数值。
一个数据集可以有一个或多个众数。
众数可以用来描述数据集中出现频率最高的数值,通常用符号Mo 表示。
5.极差极差是描述数据集分散程度的一个统计量。
它是数据集中最大值与最小值的差别。
极差可以用来描述数据集的波动性,如果极差较大,说明数据分散程度较大。
6.方差方差是描述数据集分散程度的一个统计量。
方差是数据与其均值之间差异的平均平方值。
方差可以用来描述数据集的波动性,如果方差较大,说明数据分散程度较大。
7.标准差标准差是描述数据集分散程度的一个统计量。
标准差是方差的平方根,用符号σ来表示。
标准差可以用来描述数据集的波动性,如果标准差较大,说明数据分散程度较大。
8.相关系数相关系数是描述两个变量之间关系强度的一个统计量。
相关系数的取值范围在-1到1之间,当相关系数为正时,表示两个变量正相关,当相关系数为负时,表示两个变量负相关。
相关系数可以用来描述两个变量之间的关联程度。
9.回归分析回归分析是一种描述和预测变量之间关系的方法。
回归分析可以用来研究因变量与自变量之间的关系,并通过建立回归方程对因变量进行预测和解释。
10.结论通过实验一的学习,我们了解了常用的计算方法及描述统计量分析。

实验二用DFT及FFT进行谱分析实验二将使用DFT(离散傅里叶变换)和FFT(快速傅里叶变换)进行谱分析。
在谱分析中,我们将探索如何将时域信号转换为频域信号,并观察信号的频谱特征。
首先,我们需要了解DFT和FFT的基本概念。
DFT是一种将时域信号分解为频域信号的数学方法。
它将一个离散时间序列的N个样本转换为具有N个频率点的频率谱。
DFT在信号处理和谱分析中被广泛应用,但它的计算复杂度为O(N^2)。
为了解决DFT的计算复杂度问题,Cooley和Tukey提出了FFT算法,它是一种使用分治策略的快速计算DFT的方法。
FFT算法的计算复杂度为O(NlogN),使得谱分析在实际应用中更加可行。
在实验中,我们将使用Python编程语言和NumPy库来实现DFT和FFT,并进行信号的谱分析。
首先,我们需要生成一个具有不同频率成分的合成信号。
我们可以使用NumPy的arange函数生成一组时间点,然后使用sin函数生成不同频率的正弦波信号。
接下来,我们将实现DFT函数。
DFT将时域信号作为输入,并返回频域信号。
DFT的公式可以表示为:X(k) = Σ(x(n) * exp(-i*2πkn/N))其中,X(k)是频域信号的第k个频率点,x(n)是时域信号的第n个样本,N是信号的长度。
我们将使用循环计算DFT,但这种方法的计算复杂度为O(N^2)。
因此,我们将在实验过程中进行一些优化。
接下来,我们将实现FFT函数。
FFT函数将时域信号作为输入,并返回频域信号。
可以使用Cooley-Tukey的分治算法来快速计算FFT。
FFT的基本思想是将一个长度为N的信号分解为两个长度为N/2的子信号,然后逐步地将子信号分解为更小的子信号。
最后,将所有子信号重新组合以得到频域信号。
实验中,我们将使用递归的方式实现FFT算法。
首先,我们将信号分解为两个子信号,然后对每个子信号进行FFT计算。
最后,将两个子信号的FFT结果重新组合以得到频域信号。

随机信号分析实验报告——基于MATLAB语言姓名:_班级:_学号:专业:目录实验一随机序列的产生及数字特征估计 (2)实验目的 (2)实验原理 (2)实验内容及实验结果 (3)实验小结 (6)实验二随机过程的模拟与数字特征 (7)实验目的 (7)实验原理 (7)实验内容及实验结果 (8)实验小结 (11)实验三随机过程通过线性系统的分析 (12)实验目的 (12)实验原理 (12)实验内容及实验结果 (13)实验小结 (17)实验四窄带随机过程的产生及其性能测试 (18)实验目的 (18)实验原理 (18)实验内容及实验结果 (18)实验小结 (23)实验总结 (23)实验一随机序列的产生及数字特征估计实验目的1.学习和掌握随机数的产生方法。
2.实现随机序列的数字特征估计。
实验原理1.随机数的产生随机数指的是各种不同分布随机变量的抽样序列(样本值序列)。
进行随机信号仿真分析时,需要模拟产生各种分布的随机数。
在计算机仿真时,通常利用数学方法产生随机数,这种随机数称为伪随机数。
伪随机数是按照一定的计算公式产生的,这个公式称为随机数发生器。
伪随机数本质上不是随机的,而且存在周期性,但是如果计算公式选择适当,所产生的数据看似随机的,与真正的随机数具有相近的统计特性,可以作为随机数使用。
(0,1)均匀分布随机数是最最基本、最简单的随机数。
(0,1)均匀分布指的是在[0,1]区间上的均匀分布, U(0,1)。
即实际应用中有许多现成的随机数发生器可以用于产生(0,1)均匀分布随机数,通常采用的方法为线性同余法,公式如下:,序列为产生的(0,1)均匀分布随机数。
定理1.1若随机变量X 具有连续分布函数,而R 为(0,1)均匀分布随机变量,则有2.MATLAB中产生随机序列的函数(1)(0,1)均匀分布的随机序列函数:rand用法:x = rand(m,n)功能:产生m×n 的均匀分布随机数矩阵。
(2)正态分布的随机序列函数:randn用法:x = randn(m,n)功能:产生m×n 的标准正态分布随机数矩阵。

实验项目一:数据整理中的统计计算一、实验要求:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组,能以此方式独立完成相关作业。
二、实验重点:了解数据整理的概念和内容。
掌握不同类型的统计图表。
三、实验难点:不同类型的统计图表四、实验要求:0、本实验课程要求学生已修《计算机应用基础》或类似课程。
此条为整门课程所要求,以后不再赘述。
1、已学习教材相关内容,理解数据整理中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。
2、准备好一个统计分组问题及相应数据(可用本实验导引所提供问题与数据)。
3、以Excel文件形式提交实验报告(含:实验过程记录、疑难问题发现与解决记录(可选))。
此条为所有实验所要求,恕不赘述。
五、实验内容:1、在一批灯泡中随机抽取50只,测试其使用寿命,原始数据如下(单位:小时):700 716 728 719 685709 691 684 705 718706 715 712 722 691708 690 692 707 701708 729 694 681 695685 706 661 735 665668 710 693 697 674658 698 666 696 698706 692 691 747 699682 698 700 710 722进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、曲线图)。
要求:(1)用MIN和MAX函数找出最小值和最大值,以50为组距,确定每组范围;(2)进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、曲线图)。
3、温州市1978-2005年GDP(亿元)如下表要求:(1)作出趋势图(折线图或X-Y散点图);(2)用“添加趋势线”方法,找出一个最好的方程;(3)预测2006年、2007年温州市GDP。
4、书P140,6.4六、实验步骤与结果:1、实验项目二:数字特征的统计计算一、实验要求:学会使用Excel计算各种数字特征,能以此方式独立完成相关作业。

《生物医学信号处理》实习报告
图1谱分析
图2数字特征曲线图
图3概率密度分布图
总结
1.由图1得幅度谱跟功率谱左右对称。
心电图E C G频率主要集中在0-30H z,幅度在10u v-5m v,90%的心电信号频谱能量集中在0.25-35H z之间。
M A T L A B中m e a n求算术平均值。
2.由图3得r a n d函数产生的数组元素服从均匀分布;r a n d n函数产生的
数组元素服从正态分布。
思考题:
1.心电序列的概率密度函数接近什么分布?
答:心电序列的概率密度函数接近正态分布。
2.两个随机序列产生函数的区别?
答:r a n d函数产生的数组元素服从均匀分布;
r a n d n函数产生的数组元素服从正态分布。
实习报告分数:
指导教师:。

临床试验的统计学设计与数据分析临床试验是评估医疗干预措施效果的重要手段,而统计学则为临床试验提供了有效的设计和数据分析方法。
本文将探讨临床试验的统计学设计与数据分析,旨在帮助读者更好地理解和应用统计学在临床试验中的重要性。
一、临床试验的统计学设计在进行临床试验之前,统计学的合理设计是确保研究结果具有可靠性和可推广性的关键。
以下是几种常用的临床试验统计学设计方法:1. 随机化设计:随机化设计是为了减小选择偏倚,使得研究组和对照组在一些重要特征上具有相似性。
通常采用随机数字表或随机数字生成软件进行随机分组,确保试验组和对照组的分配是完全随机的。
2. 平行设计与交叉设计:在平行设计中,患者被随机分配到试验组和对照组,各组接受相应的干预;而在交叉设计中,同一患者在不同时间接受不同的干预。
两种设计各有优劣,需要根据具体研究目的和可操作性选择合适的设计方式。
3. 盲法设计:盲法设计是为了减小观察误差和认知误差的影响,提高试验结果的可信度。
常见的盲法设计有单盲设计、双盲设计和三盲设计。
单盲设计是指研究人员或研究对象之一不知道实验组和对照组的分组情况;双盲设计是指研究人员和研究对象都不知道实验组和对照组的分组情况;三盲设计是指研究人员、研究对象和数据分析人员都不知道实验组和对照组的分组情况。
二、临床试验的数据分析临床试验进行完后,需要进行数据分析来得出结论。
以下是几种常用的临床试验数据分析方法:1. 描述性统计分析:描述性统计分析是对试验数据的分布进行概括和描述,并计算得出相应的统计量,如均值、中位数、标准差等。
通过描述性统计分析,我们可以对试验数据的特征有一个整体了解。
2. 推断统计分析:推断统计分析是通过从样本中获取的信息,推断总体的参数或判断两个或多个总体之间的差异是否显著。
常用的推断统计方法包括t检验、方差分析、非参数检验等。
3. 生存分析:生存分析是研究个体从某一初始状态到达某一特定事件发生的时间的统计方法。

数字特征、参数估计、假设检验的关系与意义摘要:本文从随机变量的数字特征参数估计、假设检验的定义,联系,区别以及三者的实际应用意义进行了阐释,明确了刻画随机变量实验的基本量度,以及实验之前的各种假设,对假设合理性的检验关键词:随机变量实验,定义,实际意义,假设检验Digital feature, parameter estimation, hypothesis testingand the relationship between the significanceAbstract: T his paper estimates, from the digital characteristic parameters of random variable definition, hypothesis testing, and three practical application significance are explained, and clarifies the basic metric characterizations of random variable experiment, as well as various hypothesis before the experiment to test the hypothesis, the rationalityKeywords:random variable experiment, practical significance, definition, hypothesis testing1数字特征、参数估计、假设检验的定义1.1数字特征数字特征是用来刻划随机变量在某些方面的重要特征,它包括期望、方差、标准差、协方差、相关系数等数字特征的概念.1数学期望的定义:设离散型随机变量X的概率函数为 P (X=x i )=pi i = 1,2, …若级数∑∞=1iiipx绝对收敛,则称此级数的和为随机变量X的数学期望.简称期望或均值.2方差及标准差的定义:设X是一随机变量,且EX存在,若E(X–EX)2存在,则称E(X–EX)2是X的方差。

数据的收集、整理与显示统计数据的收集、整理与显示是统计分析的基础和初步,其中涉及到抽样方法的选择,数据的筛选、排序,数据的分类和分组以及频数分布的制作等。
本章主要介绍如何使用Excel 进行相应处理,其中第一节统计数据的收集,介绍“抽样”工具的使用;第二节数据的预处理,介绍“筛选”、“排位和百分比排位”工具的使用;第三节品质数据的整理与显示,介绍如何使用“直方图”工具制作品质型数据的频数分布;第四节数值型数据的整理与显示,介绍如何使用“直方图”工具制作数值型数据的频数分布以及多变量数据的雷达图制作。
第一节统计数据的收集数据的处理是数据整理的先前步骤,是在对数据分类或分组之前所做的必要处理,包括数据的审核、筛选、排序等。
本节主要介绍Excel中筛选和排序功能的使用。
一、数据筛选数据筛选包括两方面内容:一是将某些不符合要求的数据或有明显错误的数据予以剔除;二是将符合某种特定条件的数据筛选出来,对不符合特定条件的数据予以剔除。
下面举例说明Excel进行数据筛选的过程。
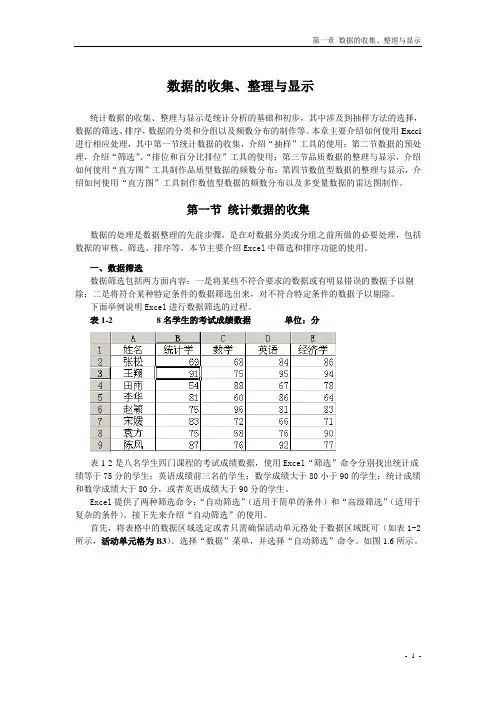
表1-28名学生的考试成绩数据单位:分表1-2是八名学生四门课程的考试成绩数据,使用Excel“筛选”命令分别找出统计成绩等于75分的学生;英语成绩前三名的学生;数学成绩大于80小于90的学生;统计成绩和数学成绩大于80分,或者英语成绩大于90分的学生。
Excel提供了两种筛选命令:“自动筛选”(适用于简单的条件)和“高级筛选”(适用于复杂的条件)。
接下先来介绍“自动筛选”的使用。
首先,将表格中的数据区域选定或者只需确保活动单元格处于数据区域既可(如表1-2所示,活动单元格为B3)。
选择“数据”菜单,并选择“自动筛选”命令。
如图1.6所示。
图1.6从“数据”菜单中选择“筛选自动”这时会在第一行(列标题)出现下拉箭头,用鼠标点击箭头会出现如下结果,如图 1.7所示。
图1.7“自动筛选”命令图1.8统计成绩75分的学生图1.9英语成绩前三名的学生图1.10数学成绩大于80小于90的学生要筛选出统计学成绩为75分的学生,可选择75,得到图1.8的结果;要筛选出英语成绩最高的前三名学生,可在英语成绩下拉箭头选项中选择“前10个”,并在对话框中输入“3”,得到如图1.9所示结果。

统计学实验报告姓名:学号:班级:成绩:一、实验步骤总结成绩:(一)数据的搜集与整理1.实验一:数据的收集与整理实验步骤:一、统计数据的整理(一)数据的预处理1、数据的编码及录入(1)数据的编码(2)数据的录入2、数据的审核与筛选3、数据的排序(二)数据的整理对数据进行整理的主要方式是统计分组,并形成频数分布。
既可以使用函数FREQUENCE进行统计分组,也可以借助直方图工具进行统计分组。
二、统计数据的描述(一)运用函数法进行统计描述常用的统计函数函数名称函数功能Average 计算指定序列算数平均数Geomean 计算数据区域的几何平均数Harmean 计算数据区域的调和平均数Median 计算给定数据集合的中位数Mode 计算给定数据集合的众数Max 计算最大值Min 计算最小值Quartile 计算四分位点Stdev 计算样本的标准差Stdevp 计算总体的标准差Var 计算样本的方差Varp 计算总体的方差在Excel中有一组求标准差的函数,一个是求样本标准差的函数Stdev,另一个是求总体标准差的函数Stdevp。
Stdev与Stdevp的不同是:其根号下的分式的分母不是N,而是N-1。
此外,还有两个对包含逻辑值和字符串的数列样本标准差和总体标准差的函数,分别是Stdeva和Stdevpa。
(二)运用“描述统计”工具进行数据描述“描述统计”工具可以生成以下统计指标,按从上到下的顺序为:平均值、标准误差、中位数、众数、样本标准差、样本方差、峰度值、偏度值、级差、最小值、最大值、样本总和、样本个数和一定显著水平下总体均值的置信区间。
三、长期趋势和季节变动测定(一)直线趋势的测定1、移动平均法测定直线趋势2、最小二乘法测定直线趋势(二)曲线趋势的测定(三)季节变动测定1、月(季)平均法2、移动平均趋势剔除法测地归纳季节变动实验数据:2.实验二:实验步骤:描述数据的图表方法(1)熟练掌握Excel 2003的统计制表功能(2)熟练掌握Excel 2003的统计制图功能(3)掌握各种统计图、表的功能,并能准确的根据不同对象的特点加以应用实验数据:二、实验心得报告成绩:(一)心得体会16个课时的课以来,在老师的帮助下,我进行了系统的统计学操作实验,加深了对统计学各方面只是以及对EXCEL操作软件的应用了解,同时能更好的把实践与理论相结合。

混合型随机变量数字特征的计算混合型随机变量是概率论与数理统计中的重要概念,它具有一些特殊的数字特征。
本文将讨论混合型随机变量的数字特征,包括期望、方差和协方差等,以帮助读者更好地理解和应用这些概念。
一、期望期望是描述随机变量平均取值的数字特征,它反映了随机变量的集中趋势。
对于混合型随机变量而言,其期望可以通过对各个组成部分的加权平均来计算。
其中,加权系数是各个组成部分的概率。
二、方差方差是描述随机变量取值分散程度的数字特征,它衡量了随机变量与其期望之间的偏离程度。
对于混合型随机变量而言,其方差可以通过对各个组成部分的加权平均来计算。
其中,加权系数是各个组成部分的概率。
三、协方差协方差是描述两个随机变量相关程度的数字特征,它反映了两个随机变量的变化趋势是否一致。
对于混合型随机变量而言,其协方差可以通过对各个组成部分的加权平均来计算。
其中,加权系数是各个组成部分的概率。
四、条件期望条件期望是描述在给定条件下随机变量的平均取值的数字特征,它反映了在给定条件下随机变量的集中趋势。
对于混合型随机变量而言,其条件期望可以通过对各个组成部分的加权平均来计算。
其中,加权系数是各个组成部分的条件概率。
以上是混合型随机变量的一些常见数字特征。
在实际应用中,我们可以利用这些特征来描述和分析各种随机现象,从而更好地理解和预测随机变量的行为。
需要注意的是,在计算混合型随机变量的数字特征时,我们需要明确各个组成部分的概率或条件概率。
这些概率可以通过实验数据或经验分布来估计,也可以通过概率模型来计算。
无论采用何种方法,我们都需要保证计算的准确性和可靠性。
混合型随机变量的数字特征还可以用于推断和假设检验等统计推断问题。
通过比较观测值与期望值、方差等数字特征,我们可以判断随机变量是否服从特定的概率分布,从而进行参数估计和假设检验。
混合型随机变量的数字特征是概率论与数理统计中的重要概念,它们可以帮助我们描述和分析各种随机现象。
在实际应用中,我们可以利用这些特征来研究随机变量的行为,从而做出合理的决策和预测。
数据分析及优化设计实验指导书(实验报告)实验名称描述性分析实验实验目的1、熟练掌握利用MATLAB软件计算均值、方差、协方差、相关系数、标准差与变异系数、偏度与峰度、中位数、分位数、三均值、四分位极差与极差。
2、熟练掌握jbtest与kstest关于一维数据的正态性检验。
3、掌握统计作图方法。
4、掌握多维数据的数字特征与相关矩阵的处理方法。
实验题答案实验一:1998年到2020年,我国汽车产量相关统计数据如表所示,解决以下问题:1)计算各项指标的平均值、标准差、变异系数、三均值、偏度与峰度;对数据进行读取,并计算各个指标的平均值、标准差、变异系数、三均值、偏度与峰度,代码如下:1.A=xlsread('第二章数据 experiment2_1.xlsx');=["生产产量(万吨)","金属切削机床产量(万台)","汽车产量(万辆)"]3.M=mean(A); %计算各指标(即各列)的均值4.SD=std(A); %计算各指标标准差5.V=SD./abs(M); %计算各指标变异系数6.SM=[0.25,0.5,0.25]*prctile(A,[25;50;75]); %计算各指标(即各列)的三均值7.pd=skewness(A,0); %计算每列数据的偏度8.fd=kurtosis(A,0)-3; %计算每列数据的峰度9.OUT=["数据名称",NAME;"平均值",M;"标准差",SD;"变异系数",V;"三均值",SM;"偏度",pd;"峰度",fd]在编辑器中输入代码,并保存为.m文件,在命令行窗口中输出各个计算结果如下图所示:2)各项指标是否服从正态分布?若服从正态分布,计算概率为1%时的生铁产量、金属切削机床产量及汽车产量;若不服从正态分布,利用Box-Cox 变换将数据进行变换,对变换后的数据进行相应的分析;对各项指标进行JB检验、KS检验和改进KS检验(即Lilliefors检验),并结合QQ图进行分析判断各项对应指标是否服从正态分布,Matlab中代码如下:1.%%-------------------------------绘图-------------------------------%%2.a1=A(:,[1]); %生铁产量(万吨)3.a2=A(:,[2]); %金属切削机床产量(万台)4.a3=A(:,[3]); %汽车产量(万辆)5.subplot(1,3,1),qqplot(a1),title('生铁产量');6.subplot(1,3,2),qqplot(a2),title('金属切削机床产量');7.subplot(1,3,3),qqplot(a3),title('汽车产量');8.h1=jbtest(X); %JB检验9.h2=kstest(X); %KS检验10.h3=lillietest(X); %改进KS检验11.H=[h1;h2;h3];各列指标检验结果如下:可以看出,生铁产量、金属切削机床产量、汽车产量三项指标都满足h1=0,h2=1,h3=0,表示JB检验和Lilliefors检验支持生铁产量、金属切削机床产量、汽车产量三项指标都服从正态分布,KS检验不支持生铁产量、金属切削机床产量、汽车产量三项指标服从正态分布。
统计学名词解释及公式公司内部编号:(GOOD-TMMT-MMUT-UUPTY-UUYY-DTTI-第1章统计与统计数据一、学习指导统计学是处理和分析数据的方法和技术,它几乎被应用到所有的学科检验领域。
本章首先介绍统计学的含义和应用领域,然后介绍统计数据的类型及其来源,最后介绍统计中常用的一些基本概念。
本章各节的主要内容和学习要点如下表所示。
概念:统计学,描述统计,推断统计。
统计在工商管理中的应用。
统计的其他应用领域。
概念:分类数据,顺序数据,数值型数据。
不同数据的特点。
概念:观测数据,实验数据。
概念:截面数据,时间序列数据。
统计数据的间接来源。
二手数据的特点。
概念:抽样调查,普查。
数据的间接来源。
数据的收集方法。
调查方案的内容。
概念。
抽样误差,非抽样误差。
统计数据的质量。
概念:总体,样本。
概念:参数,统计量。
概念:变量,分类变量,顺序变量,数值型变量,连续型变量,离散型变量。
二、主要术语1.统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。
2.描述统计:研究数据收集、处理和描述的统计学分支。
3.推断统计:研究如何利用样本数据来推断总体特征的统计学分支。
4.分类数据:只能归于某一类别的非数字型数据。
5.顺序数据:只能归于某一有序类别的非数字型数据。
6.数值型数据:按数字尺度测量的观察值。
7.观测数据:通过调查或观测而收集到的数据。
8.实验数据:在实验中控制实验对象而收集到的数据。
9.截面数据:在相同或近似相同的时间点上收集的数据。
10.时间序列数据:在不同时间上收集到的数据。
11.抽样调查:从总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推断总体特征的数据收集方法。
12.普查:为特定目的而专门组织的全面调查。
13.总体:包含所研究的全部个体(数据)的集合。
14.样本:从总体中抽取的一部分元素的集合。
15.样本容量:也称样本量,是构成样本的元素数目。
16.参数:用来描述总体特征的概括性数字度量。
统计特征教案幼儿园一、教学目标1.了解统计特征的意义,掌握统计特征的计算方法。
2.学会如何使用统计特征描述数据分布的特点。
3.培养幼儿的观察能力和分析能力。
二、教学内容与步骤第一节:统计特征的概念和意义1.引入统计特征的概念及其意义;2.让幼儿体验不同物品(如颜色、形状)数量的不同,并描述不同物品数量的感受;3.通过幼儿的描述引出统计特征的重要性。
第二节:常见统计特征的计算方法1.介绍常见的统计特征,如均值、中位数、众数、极差等;2.通过具体的量化数据例子,向幼儿介绍统计特征的计算方法和含义;3.让幼儿分组进行实际操作,自主计算并比较不同统计特征的差异。
第三节:使用统计特征描述数据分布的特点1.让幼儿观察某类物品数量的实际数据,并通过探究数据分布的不同特点,引出使用统计特征描述数据分布的必要性;2.通过幼儿自身的统计数据,教授如何使用统计特征描述数据分布的特点;3.鼓励幼儿分析数据的特点,从中获取更多信息。
三、教学方法1.通过引导、探究和交流的方式促进幼儿的学习;2.以实例为主,结合实际幼儿生活和学习情境,让幼儿更加易于理解;3.创设不同形式的互动环节(如图片观察,小组对话等),增强幼儿的参与度和兴趣;4.尊重幼儿的学习兴趣和发展需求,鼓励幼儿自主实践。
四、教学评估1.通过幼儿的计算结果,检查关于统计特征计算方法的掌握情况;2.观察幼儿在描述数据分布特点时所使用的统计特征的正确率和准确性;3.通过互动游戏等形式,评估幼儿对于数据分析的兴趣和能力。
五、教学反思本教案针对幼儿园小班(4-5岁)的学生,通过引导幼儿观察、探究、动手等多种形式,使幼儿乐于学习并掌握了统计特征的相关知识和技能。
同时,通过对幼儿所使用的统计特征的正确性和准确性的评估,及时发现幼儿的问题,针对性加强教学。
这样的教学方式充分尊重了幼儿的学习兴趣和发展需求,以及培养幼儿的观察能力和分析能力,对于幼儿的综合素质提高具有一定的促进作用。
课程设计(实验)报告书题目统计学实验报告
专业电子商务
班级15级一班
学生姓名郭瑾仪
学号2015261023
指导教师白斌飞
实验二数字特征的统计计算
一、项目名称
数字特征中的统计计算
二、实验目的
学会使用Excel计算各种数字特征,能以此方式独立完成相关作业。
三、实验要求
1、已学习教材相关内容,理解数字特征中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。
2、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。
四、实验内容和操作步骤
(一)实验内容一:用Excel中的工作表函数计算分组资料的数字特征
1、问题与数据
某地区农民家庭按人均收入分组的分组数据资料如下:
计算家庭人均收入的中位数,均值,标准差。
2、操作步骤(如图2-1所示)
(1)绘制计算表框架,且输入分组数据:分组,频率,组限。
(2)用各种常用公式或函数在计算表中计算其他各栏。
公式如下:
累积频率:(略);
组中值:{(D4︰D10+E4︰E10)/2}
组距:{= E4︰E10 - D4︰D10}
x i×f i:{=F4︰F10*B4︰B10}
x i2×f i:{=POWER(F4︰F10,2)*B4︰B10}
3.计算中位数,均值,标准差。
公式如下:
中位数:D7+(B11/2-C6)/B7*G7
均值:SUM(H4︰H10)
标准差:SQRT(I11-POWER(H11,2))
(二)实验内容二:用“描述统计”工具处理原始资料
1、问题与数据
从某校所有参加一次英语考试的学生中,随机抽取30名学生记录其考试成绩,结果如下:
89 88 76 99 74 87 73 67 82 60
92 67 56 87 74 64 54 64 74 87
72 67 81 66 73 82 76 73 77 89
试用“描述统计”工具计算该样本的各描述统计特征。
2、操作步骤:
(1)于A1︰A30单元格区域中输入样本数据。
(2)从“工具”菜单中选择“数据分析”项;在所弹出的“数据分析”对话框的“分析工具”列表中选择“描述统计”工具
(3)单击“数据分析”对话框的“确定”按钮,弹出“描述统计”对话框。
(4)确定对话框中各选项。
(5)单击“描述统计”对话框的“确定”按钮。
其中:
“中值”即“中位数”; “模式”即“众数”; “区域”即“极差”;
“样本方差”即21n S -;
“标准偏差”即1n S -; “峰值”,EXCEL 工作表函数为KURT ,其计算公式为:
4
213(1)(1)(2)(3)(1)(2)(3)i n n x x n n n n n n n S -⎧⎫-⎛⎫⎪⎪-+-⎨⎬ ⎪-----⎪⎪⎝⎭⎩⎭
∑
“偏斜度”,EXCEL 工作表函数为SKEW ,其计算公式为:3
1(1)(2)i n x x n
n n S -⎛⎫-
⎪--⎝⎭
∑ “置信度”
,其计算公式为:(1,
)2
t n α
-。