编译原理(清华大学第2版)课后习题答案
- 格式:doc
- 大小:711.50 KB
- 文档页数:37

第一章1.典型的编译程序在逻辑功能上由哪几部分组成?答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。
2. 实现编译程序的主要方法有哪些?答:主要有:转换法、移植法、自展法、自动生成法。
3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式?答:编译法、解释法。
4. 编译方式和解释方式的根本区别是什么?答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快;解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。
第二章1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关系如何?答:1)0型文法、1型文法、2型文法、3型文法。
2)2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。
答:Z→SME | BS→1|2|3|4|5|6|7|8|9M→ε | D | MDD→0|SB→2|4|6|8E→0|B3. 设文法G为:N→ D|NDD→ 0|1|2|3|4|5|6|7|8|9请给出句子123、301和75431的最右推导和最左推导。
答:N⇒ND⇒N3⇒ND3⇒N23⇒D23⇒123N⇒ND⇒NDD⇒DDD⇒1DD⇒12D⇒123N⇒ND⇒N1⇒ND1⇒N01⇒D01⇒301N⇒ND⇒NDD⇒DDD⇒3DD⇒30D⇒301N⇒ND⇒N1⇒ND1⇒N31⇒ND31⇒N431⇒ND431⇒N5431⇒D5431⇒75431N⇒ND⇒NDD⇒NDDD⇒NDDDD⇒DDDDD⇒7DDDD⇒75DDD⇒754DD⇒7543D⇒75431 4. 证明文法S→iSeS|iS| i是二义性文法。
答:对于句型iiSeS存在两个不同的最左推导:S⇒iSeS⇒iiSesS⇒iS⇒iiSeS所以该文法是二义性文法。

C语言程序设计习题与上机指南第二版课后答案(牛志成著) 清华大学C语言程序设计习题与上机指南(牛志成编)答案。
第一章 C语言概述参考答案一、1.C 2.B3.C4.D5.D6.B7.A8.A9.B10.A二、1、函数 2、位 3、分号 4、main 5、{ } 6、换行 7、注释 8、函数首部、函数体9、main 10、编辑、编译、连接、运行三、1.错2.错3.对4.对5.对6.对7.错 8.对四、1、#include <stdio.h>/*包含头文件,为了使用printf和scanf语句,注意句末无分号*/ void main(){printf(“* * * * * * * * * * * \n”); /*\n的作用相当于回车*/printf(“ I am a student.\n”);printf(“* * * * * * * * * * * \n”);}2、#include <stdio.h>void main(){ int a,b;printf(“Please input a,b:\n”);sca nf(“%d,%d”,&a,&b); /*注意输入两个数之间用逗号分隔*/if(a>b) printf(“%d”,a);else printf(“%d”,b);}3、#include <stdio.h>void main(){int a,b,c,max;printf(“Please input a,b,c:\n”);scanf(“%d,%d,%d”,&a,&b,&c);max=a;if(a<b) max=b; /*max用于保存a,b中比较大的数*/ if(max<c) max=c; /*将a,b中较大的数再和c比较* / printf(“The largest number is %d”,max);}第二章数据与运算参考答案一、1.B 2.D3.D4.A5.C6.B7.C8.B9.A10.A11.D12.A13.B14.A 15.C二、1、8 2、28 3、5 4、0 5、double 6、8 ,107、12 8、D 9、52 10、25,21,37 11、4812、20 200.000000 14、9,11,9,10 15、11.50 13、aa口bb口口口cc口口口口口口abcA口N三、1.错 2.对3.对4.错5.错6.对7.错8.错9.错10.对四、1、1)第1步:(int)(x+y)=(int)(7.2)=7第2步:a%3*7%2/4=7%3*7%2/4=1*7%2/4=1/4=0第3步:x+0=x=2.5(计算机显示为2.500000)1、2)第1步:(float)(a+b)/2=(float)(2+3)/2=(float)(5)/2=5.0/2=2.5 第2步:(int)x%(int)y=(int)(3.5)%(int)(2.5)=3%2=1第3步:2.5+1=3.5(计算机显示为3.500000)2、1)(a=a+a=12+12=24)2、2)(a=a-2=12-2=10)2、3)(a=a*(2+3)=12*5=60)2、4) (a=a/(a+a)=12/24=0,注意a是整型)2、5) 已知n的值等于5 a=0 2、6)(从右向左解开:a=a*a=144;a=a-a=0;a=a+a=0) 五、编程题1、参考答案:#include <stdio.h>void main(){char c1=’C’,c2=’h’,c3=’i’,c4=’n’,c5=’a’;c1=c1+4;c2=c2+4;c3=c3+4;c4=c4+4;c5=c5+4;printf(“password is %c%c%c%c%c\n”,c1,c2,c3,c4,c5);}运行结果:password is Glmre也可以用循环和数组: #include <stdio.h>void main(){char c[]={“China”};printf(“password is “); for(int i=0;i<=4,i++)printf(“%c”,c[i]+=4);printf(“\n”);}2、参考答案:#include <stdio.h>void main(){char c1=97,c2=98;printf(“%d, %d\n”,c1,c2);printf(“%c,%c\n”,c1,c2); }3、参考答案:#include <stdio.h>#include <math.h>void main(){ double a, b, c, total, average, square, squareroot; printf("请输入三个双精度实数:");scanf("%lf%lf%lf", &a, &b, &c);total = a + b + c;average = total/3.0;square = a*a + b*b + c*c;squareroot = sqrt(square);printf("三个数的和=%-15.3f,三个数的平均值=%-15.3f\n", total, average);printf("三个数的平方和x=%.3f,x的平方根=%.3f\n", square, squareroot);}运行结果:请输入三个双精度实数:1.23 4.56 7.89三个数的和=13.680 ,三个数的平均值=4.560三个数的平方和x=84.559,x的平方根=9.196 4、参考答案:#include <stdio.h>#include <math.h>void main(){ float a, b, c, k, area;printf("请输入三角形三条边的边长:");scanf("%f%f%f", &a, &b, &c); /*由键盘输入三角形三边边长*/if ((a+b <= c) || (a+c <= b) || (b+c <= a)){ printf("您输入的三条边无法构成三角形。


第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiE EFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。


第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。

编译原理第二版答案
编译原理是计算机科学中非常重要的一个领域,它涉及到编程语言的设计、编
译器的构建以及程序的执行过程。
《编译原理(第二版)》是一本经典的教材,它系统地介绍了编译原理的基本概念、理论和实践,对于理解编译原理具有重要的指导意义。
在学习这本教材的过程中,很多同学都会遇到一些问题,尤其是对于习题的答案。
本文将对《编译原理(第二版)》中的习题答案进行详细解析,希望能够帮助大家更好地理解和掌握编译原理的知识。
1. 介绍编译原理的基本概念和原理,包括词法分析、语法分析、语义分析、中
间代码生成、代码优化和目标代码生成等内容。
2. 解析《编译原理(第二版)》中的习题答案,包括对于词法分析、语法分析、语义分析等各个方面的习题进行逐一分析和解答。
3. 提供一些编译原理相关的案例分析,帮助读者更好地理解编译原理的理论和
实践。
4. 总结编译原理学习中的常见问题和解决方法,为读者提供一些学习建议和学
习技巧。
5. 展望编译原理的未来发展方向,介绍一些最新的研究成果和应用领域,为读
者打开编译原理的新视野。
通过本文的阅读,读者将能够全面了解《编译原理(第二版)》中的习题答案,深入理解编译原理的基本概念和原理,掌握编译原理的核心知识和技术,为今后的学习和工作打下坚实的基础。
希望本文能够对大家的学习和研究有所帮助,欢迎大家阅读和参考。

1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产生式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( }求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)算符优先关系表a ∧( ) , #a ·> ·> ·> ∧·> ·> ·> ( <·<·<·=·<·) ·> ·> ·>, <·<·<··> ·># <·<·<·=·因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(3)a ∧( ) ,F 1 1 1 11 1g 1 1 1 11 1f 2 2 1 3 2g 2 2 2 1 2f 3 3 1 3 3g 4 4 4 1 2f 3 3 1 3 3g 4 4 4 1 2(4)栈优先关系当前符号剩余输入串移进或规约#<·( a,a)#移进#( <· a,a)# 移进# (a ·> , a)# #(T <·, a)# #(T,<· a )# #(T,a ·> ) # #(T,T ·> ) # #(T =·) # #(T) ·> ##T =·#4.扩展后的文法S’→#S# S→S;G S→G G→G(T)G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( } FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( } FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }构造算符优先关系表; ( ) a + # ;·> <··> <··> ·> ( <·<·=·<·<·) ·> ·> ·> ·> ·> a ·> ·> ·> ·> ·> + <·<··> <··># <·<·<·=·因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)分析a;(a+a)栈优先关系当前符号剩余输入串移进或规约##a #T #T;#T;(<··><·<·<·a;;(a;(a+a)#(a+a)#(a+a)#a+a)#+a)#移进规约移进移进移进#T;(T #T;(T +#T;(T +a#T;(T +T#T;(T #T;(T)#T;T #T <·<··>·>=··>·>=·+a)))###a)#)####移进移进规约规约移进规约规约接受分析a;(a+a)栈优先关系当前符号剩余输入串移进或规约##(#(a #(T #(T+<·<··><·<·(a++aa+a)#+a)#a)#移进移进规约移进移进#(T+T #(T#(T)#T ·>=··>=·))##)####规约移进规约接受(4)不能用最右推导推导出上面的两个句子。

第七章
习题7.2.6 :C语言函数f的定义如下:
Int f(int x, *py, **ppz){
**ppz +=1;*py +=2;x +=3; return x+*py+**ppz;
}
变量a是一个指向b的指针;变量b是一个指向c的指针,而c是一个当前值为4的整数变量。
如果我们调用f(c,b,a),返回值是什么?
答:x是传值,而b和c是传地址方式;由函数定义可以得到:b=&c,a=&b, 而**a=**a+1=c+1=5 => c=5; *b=*b+2=c+2=7 =>c=7,**a=7;c=c+3=4+3=7
所以调用f(c,b,a)返回值是7+7+ 7=21
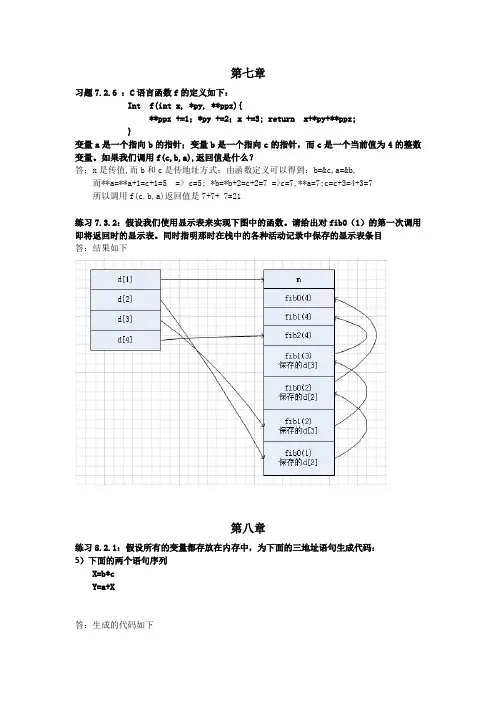
练习7.3.2:假设我们使用显示表来实现下图中的函数。
请给出对fib0(1)的第一次调用即将返回时的显示表。
同时指明那时在栈中的各种活动记录中保存的显示表条目
答:结果如下
第八章
练习8.2.1:假设所有的变量都存放在内存中,为下面的三地址语句生成代码:
5)下面的两个语句序列
X=b*c
Y=a+X
答:生成的代码如下
练习8.5.1:为下面的基本块构造构造DAG
d=b*c
e=a+b
b=b*c
a=e-d
答:DAG如下
练习8.6.1:为下面的每个C语言赋值语句生成三地址代码1)x=a+b*c
答:生成的三地址代码如下。

编译原理第二章-课后题答案本页仅作为文档封面,使用时可以删除This document is for reference only-rar21year.March第二章3.何谓“标志符”,何谓“名字”,两者的区别是什么答:标志符是一个没有意义的字符序列,而名字却有明确的意义和属性。
4.令+、*和↑代表加、乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值。
(1)优先顺序(从高到低)为+、*和↑,同级优先采用左结合。
(2)优先顺序为↑、+、*,同级优先采用右结合。
答:(1)1+1*2↑2*1↑2=2*2↑2*1↑2=4↑2*1↑2=4↑2↑2=16↑2=256(2)1+1*2↑2*1↑2=1+1*2↑2*1=1+1*4*1=2*4*1=2*4=86.令文法G6为N-〉D|NDD-〉0|1|2|3|4|5|6|7|8|9(1)G6的语言L(G6)是什么(2)给出句子0127、34、568的最左推导和最右推导。
答:(1)由0到9的数字所组成的长度至少为1的字符串。
即:L(G6)={d n|n≧1,d∈{0,1,…,9}}(2)0127的最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>01270127的最右推导:N=>ND=>N7=>ND7=>N27=>ND27=>N127=>D127=>0127(其他略)7.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
答:G(S):S->+N|-NN->ABC|CC->1|3|5|7|9A->C|2|4|6|8B->BB|0|A|ε[注]:可以有其他答案。
[常见的错误]:N->2N+1原因在于没有理解形式语言的表示法,而使用了数学表达式。
8.令文法为E->T|E+T|E-TT->F|T*F|T/FF->(E)|i(1)给出i+i*i、i*(i+i)的最左推导和最右推导。
编译原理龙书第二版课后答案【篇一:编译原理习题答案,1-8 章龙书第二版7.8 章】6 :c 语言函数 f 的定义如下:int f(int x, *py, **ppz){**ppz +=1 ; *py +=2 ;x +=3; return x+*py+**ppz;}变量 a 是一个指向 b 的指针;变量 b 是一个指向 c 的指针,而 c 是一个当前值为 4 的整数变量。
如果我们调用 f(c,b,a), 返回值是什么?答: x 是传值 ,而 b 和 c 是传地址方式;由函数定义可以得到: b=c,a=b, 而**a=**a+1=c+1=5 = c=5; *b=*b+2=c+2=7 =c=7,**a=7;c=c+3=4+3=7所以调用 f(c,b,a) 返回值是 7+7+ 7=21练习7.3.2 :假设我们使用显示表来实现下图中的函数。
请给出对fib0 (1)的第一次调用即将返回时的显示表。
同时指明那时在栈中的各种活动记录中保存的显示表条目答:结果如下第八章练习 8.2.1 :假设所有的变量都存放在内存中,为下面的三地址语句生成代码:5)下面的两个语句序列x=b*cy=a+x答:生成的代码如下练习 8.5.1 :为下面的基本块构造构造dagd=b*ce=a+bb=b*ca=e-d答: dag 如下练习 8.6.1 :为下面的每个 c 语言赋值语句生成三地址代码1)x=a+b*c答:生成的三地址代码如下【篇二:编译原理龙书第二版第4章】.1:考虑上下文无关文法: s-s s +|s s *|a 以及串 aa + a* (1) 给出这个串的一个最左推导 s - s s * - s s + s * - a s + s * - a a + s * - aa+a*(3)给出这个串的一棵语法分析树习题 4.3.1 :下面是一个只包含符号 a 和 b 的正则表达式的文法。
它使用 +替代表示并运算的符号 |,以避免和文法中作为元符号使用的竖线相混淆: rexpr? rexpr + rterm | rterm rterm?rterm rfactor |rfactor rfactor? rfactor * | rprimary rprimary?a | b 1)对这个文法提取公因子2)提取公因子的变换使这个文法适用于自顶向下的语法分析技术吗?3)提取公因子之后,原文法中消除左递归 4) 得到的文法适用于自顶向下的语法分析吗?解1)提取左公因子之后的文法变为rexpr? rexpr + rterm | rterm rterm?rterm rfactor |rfactor rfactor? rfactor * | rprimary rprimary?a | b2)不可以,文法中存在左递归,而自顶向下技术不适合左递归文法3)消除左递归后的文法rexpr - rterm rexpr’rexpr rterm ’-+ rterm rexpr’|? rterm- rfactor rterm’ rterm-rfactor’’ |? rfactor- rprimay rfactor’ rfactor-*rfactor’’ |? rprimary- a| b4)该文法无左递归,适合于自顶向下的语法分析习题 4.4.1 :为下面的每一个文法设计一个预测分析器,并给出预测分析表。
第2章习题2-1 设有字母表A1 ={a,b,c,…,z},A2 ={0,1,…,9},试回答下列问题:(1) 字母表A1上长度为2的符号串有多少个?(2) 集合A1A2含有多少个元素?(3) 列出集合A1(A1∪A2)*中的全部长度不大于3的符号串。
2-2 试分别构造产生下列语言的文法:(1){a n b n|n≥0};(2){a n b m c p|n,m,p≥0};(3){a n#b n|n≥0}∪{c n#d n|n≥0};(4){w#w r# | w∈{0,1}*,w r是w的逆序排列 };(5)任何不是以0打头的所有奇整数所组成的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
2-3 试描述由下列文法所产生的语言的特点:(1)S→10S0S→aA A→bA A→a(2)S→SS S→1A0A→1A0A→ε(3)S→1A S→B0A→1A A→CB→B0B→C C→1C0C→ε(4)S→aSS S→a2-4 试证明文法S→AB|DC A→aA|a B→bBc|bc C→cC|c D→aDb|ab为二义性文法。
2-5 对于下列的文法S→AB|c A→bA|a B→aSb|c试给出句子bbaacb的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
2-6 化简下列各个文法(1) S→aABS|bCACd A→bAB|cSA|cCC B→bAB|cSB C→cS|c(2) S→aAB|E A→dDA|e B→bE|fC→c AB|dSD|a D→eA E→fA|g(3) S→ac|bA A→c BC B→SA C→bC|d2-7 消除下列文法中的ε-产生式(1) S→aAS|b A→cS|ε(2) S→aAA A→bAc|dAe|ε2-8 消除下列文法中的无用产生式和单产生式(1) S→aB|BC A→aA|c|aDb B→DB|C C→b D→B(2) S→SA|SB|A A→B|(S)|( ) B→[S]|[ ](3) E→E+T|T T→T*F|F F→P↑F|P P→(E)|i第2章习题答案2-1 答:(1) 26*26=676(2) 26*10=260(3) {a,b,c,...,z, a0,a1,...,a9, aa,...,az,...,zz, a00,a01,...,zzz},共有26+26*36+26*36*36=34658个2-2 解:(1) 对应文法为G(S)=({S},{a,b},{ S→ε| aSb },S)(2) 对应文法为G(S)=({S,X,Y},{a,b,c},{S→aS|X,X→bX|Y,Y→cY|ε },S)(3)对应文法为G(S)=({S,X,Y},{a,b,c,d,#}, {S→X,S→Y,X→aXb|#, Y→cYd|# },S)(4) G(S)=({S,W,R},{0,1,#}, {S→W#, W→0W0|1W1|# },S)(5) G(S)=({S,A,B,I,J},{0,1,2,3,4,5,6,7,8,9},{S→J|IBJ,B→0B|IB|ε, I→J|2|4|6|8, J→1|3|5|7|9},S)(6)对应文法为S→0A|1B|ε,A→0S|1C,B→0C|1S,C→1A|0B2-3 解:(1) 本文法构成的语言集为:L(G)={(10)n ab m a0n|n,m≥0}。
1、已知文法:A → aAd|aAb|ξ判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串 #ab# 给出分析过程。
解:(0) A’→ A(1)A → aAd(2) A → aAb(3) A →ξ构造该文法的活前缀DFA:由上图可知该文法是SLR(1)文法。
构造SLR(1)的分析表:3、考虑文法:S →AS|b A→SA|aFollow(A) = first(S) = {b}+first(A)= {a,b}(1)列出这个文法的所有LR(0)项目(2)按(1)列出的项目构造识别这个文法活前缀的NFA,把这个NFA确定化为DFA,说明这个DFA的所有状态全体构成这个文法的LR(0)规范族。
(3)这个文法是SLR的吗?若是,构造出它的SLR分析表。
(4)这个文法是LALR或LR(1)的吗?解:(0)S’→S (1)S→AS (2)S→b (3)A→SA (4)A→a(1)列出所有LR(0)项目:S’→·S S→·b A→·a S’→ S· S→b· A→a·S →·AS A→·SAS →A·S A→S·AS →AS· A→SA·(3)构造该文法的活前缀NFA:由上可知:I1 I3 I5 中存在着移进和归约冲突在I1中含项目:S’→ S·归约项 Follow(S’)={#}A →·a 移进项 Follow(S’)∩{a}=∮S →·b 移进项 Follow(S’)∩{b}=∮在I3中含项目:A →SA·归约项 Follow(A)={a,b}S →·b 移进项 Follow(A) ∩ {b}≠∮A →·a 移进项 Follow(A) ∩ {a}≠∮在I5中含项目:S →AS·归约项 Follow(S)={#,a,b}A →·a 移进项 Follow(S) ∩ {a}≠∮S →·b 移进项 Follow(S) ∩ {b }≠∮由此可知,I3、I5的移进与归约冲突不能解决,所以这个文法不是SLR (1)文法。
第三章N=>D=> {0,1,2,3,4,5,6,7,8,9}N=>ND=>NDDL={a |a(0|1|3..|9)n且 n>=1}(0|1|3..|9)n且 n>=1{ab,}a nb n n>=1第6题.(1) <表达式> => <项> => <因子> => i(2) <表达式> => <项> => <因子> => (<表达式>) => (<项>)=> (<因子>)=>(i)(3) <表达式> => <项> => <项>*<因子> => <因子>*<因子> =i*i(4) <表达式> => <表达式> + <项> => <项>+<项> => <项>*<因子>+<项>=> <因子>*<因子>+<项> => <因子>*<因子>+<因子> = i*i+i (5) <表达式> => <表达式>+<项>=><项>+<项> => <因子>+<项>=i+<项> => i+<因子> => i+(<表达式>) => i+(<表达式>+<项>)=> i+(<因子>+<因子>)=> i+(i+i)(6) <表达式> => <表达式>+<项> => <项>+<项> => <因子>+<项> => i+<项> => i+<项>*<因子> => i+<因子>*<因子> = i+i*i第7题第9题语法树ss s* s s+aa a推导: S=>SS*=>SS+S*=>aa+a*11. 推导:E=>E+T=>E+T*F语法树:E+T*短语: T*F E+T*F直接短语: T*F句柄: T*F12.<E><E> <T> <POP>短语:<T><F><MOP> <E><T><F><MOP><POP>直接短语:<T><F><MOP>句柄: <T><F><MOP>13.(1)最左推导:S => ABS => aBS =>aSBBS => aBBS=> abBS => abbS => abbAa => abbaa 最右推导:S => ABS => ABAa => ABaa => ASBBaa=> ASBbaa => ASbbaa => Abbaa => a1b1b2a2a3 (2) 文法:S → ABSS → AaS →εA → aB → b(3) 短语:a1 , b1 , b2, a2 , , bb , aa , abbaa,直接短语: a1 , b1 , b2, a2 , ,句柄:a114 (1)S → ABA → aAb | εB → aBb | ε(2)S → 1S0S → AA → 0A1 |ε第四章1. 1. 构造下列正规式相应的DFA(1)1(0|1)*101NFA(2) 1(1010*|1(010)*1)*0NFA(3)NFA(4)NFAb其中0 表示初态,*表示终态用0,1,2,3,4,5分别代替{X} {Z} {X,Z} {Y} {X,Y} {X,Y,Z} 得DFA状态图为:3.解:构造DFA矩阵表示构造DFA的矩阵表示其中表示初态,*表示终态替换后的矩阵4.(1)解构造状态转换矩阵:{2,3} {0,1}{2,3}a={0,3}{2},{3},{0,1}{0,1}a={1,1} {0,1}b={2,2}(2)解:首先把M的状态分为两组:终态组{0},和非终态组{1,2,3,4,5} 此时G=( {0},{1,2,3,4,5} ) {1,2,3,4,5}a={1,3,0,5}{1,2,3,4,5}b={4,3,2,5}由于{4}a={0} {1,2,3,5}a={1,3,5}因此应将{1,2,3,4,5}划分为{4},{1,2,3,5}G=({0}{4}{1,2,3,5}){1,2,3,5}a={1,3,5}{1,2,3,5}b={4,3,2}因为{1,5}b={4} {23}b={2,3}所以应将{1,2,3,5}划分为{1,5}{2,3}G=({0}{1,5}{2,3}{4}){1,5}a={1,5} {1,5}b={4} 所以{1,5} 不用再划分{2,3}a={1,3} {2,3}b={3,2}因为 {2}a={1} {3}a={3} 所以{2,3}应划分为{2}{3}所以化简后为G=( {0},{2},{3},{4},{1,5})7.去除多余产生式后,构造NFA如下确定化,构造DFA 矩阵G={(0,1,3,4,6),(2,5)} {0,1,3,4,6}a={1,3}{0,1,3,4,6}b={2,3,4,5,6}所以将{0,1,3,4,6}划分为 {0,4,6}{1,3} G={(0,4,6),(1,3),(2,5)}{0,4,6}b={3,6,4} 所以 划分为{0},{4,6} G={(0),(4,6),(1,3),(2,5)}不能再划分,分别用 0,4,1,2代表各状态,构造DFA 状态转换图如下;b8.代入得S = 0(1S|1)| 1(0S|0) = 01(S|ε) | 10(S|ε) = (01|10)(S|ε)= (01|10)S | (01|10)= (01|10)*(01|10)构造NFA由NFA可得正规式为(01|10)*(01|10)=(01|10)+9.状态转换函数不是全函数,增加死状态8,G={(1,2,3,4,5,8),(6,7)}(1,2,3,4,5,8)a=(3,4,8) (3,4)应分出(1,2,3,4,5,8)b=(2,6,7,8)(1,2,3,4,5,8)c=(3,8)(1,2,3,4,5,8)d=(3,8)所以应将(1,2,3,4,5,8)分为(1,2,5,8), (3,4)G={(1,2,5,8),(3,4),(6,7)}(1,2,5,8)a=(3,4,8) 8应分出(1,2,5,8)b=(2,8)(1,2,5,8)c=(8)(1,2,5,8)d=(8)G={(1,2,5),(8),(3,4),(6,7)}(1,2,5)a=(3,4,8) 5应分出G={(1,2), (3,4),5, (6,7) ,(8) }去掉死状态8,最终结果为 (1,2) (3,4) 5,(6,7) 以1,3,5,6代替,最简DFA为b正规式:b*a(da|c)*bb*第五章1.S->a | ^ |( T )T -> T , S | S(a,(a,a))S => ( T ) => ( T , S ) => ( S , S ) => ( a , S) => ( a, ( T )) =>(a , ( T , S ) ) => (a , ( S , S )) => (a , ( a , a ) ) S=>(T) => (T,S) => (S,S) => ( ( T ) , S ) => ( ( T , S ) , S ) => ( ( T , S , S ) , S ) => ( ( S , S , S ) , S )=> ( ( ( T ) , S , S ) , S ) => ( ( ( T , S ) , S , S ) , S ) =>( ( ( S , S ) , S , S ) , S ) => ( ( ( a , S ) , S , S ) , S ) => ( ( ( a , a ) , S , S ) , S ) => ( ( ( a , a ) , ^ , S ) , S ) => ( ( ( a , a ) , ^ , ( T ) ) , S )=> ( ( ( a , a ) , ^ , ( S ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , a )S->a | ^ |( T )T -> T , ST -> S消除直接左递归:S->a | ^ |( T )T -> S T’T’ -> , S T’ | ξSELECT ( S->a) = {a}SELECT ( S->^) = {^}SELECT ( S->( T ) ) = { ( }SELECT ( T -> S T’) = { a , ^ , ( }SELECT ( T’ -> , S T’ ) = { , }SELECT ( T’ ->ξ) = FOLLOW ( T’ ) = FOLLOW ( T ) = { )}构造预测分析表分析符号串( a , a )#分析栈剩余输入串所用产生式#S ( a , a) # S -> ( T )# ) T ( ( a , a) # ( 匹配# ) T a , a ) # T -> S T’# ) T’ S a , a ) # S -> a# ) T’ a a , a ) # a 匹配# ) T’,a) # T’ -> , S T’# ) T’ S , , a ) # , 匹配# ) T’ S a ) # S->a# ) T’ a a ) # a匹配# ) T’) # T’ ->ξ# ) ) # )匹配# # 接受2.E->TE’E’->+E E’->ξT->FT’T’->T T’->ξF->PF’F’->*F’F’->ξP->(E) P->a P->b P->∧SELECT(E->TE’)=FIRST(TE’)=FIRST(T)= {(,a,b,^)SELECT(E’->+E)={+}SELECT(E’->ε)=FOLLOW(E’)= {#,)}SELECT(T->FT’)=FIRST(F)= {(,a,b,^}SELECT(T’ —>T)=FIRST(T)= {(,a,b,^)SELECT(T’->ε)=FOLLOW(T’)= {+,#,)}SELECT(F ->P F’)=FIRST(F)= {(,a,b,^}SELECT(F’->*F’)={*}SELECT(F’->ε)=FOLLOW(F’)= {(,a,b,^,+,#,)}3. S->MH S->a H->Lso H->ξK->dML K->ξL->eHf M->K M->bLM FIRST ( S ) =FIRST(MH)= FIRST ( M ) ∪FIRST ( H ) ∪{ξ} ∪{a}= {a, d , b , e ,ξ} FIRST( H ) = FIRST ( L ) ∪{ξ}= { e , ξ}FIRST( K ) = { d , ξ}FIRST( M ) = FIRST ( K ) ∪{ b } = { d , b ,ξ}FOLLOW ( S ) = { # , o }FOLLOW ( H ) = FOLLOW ( S ) ∪{ f } = { f , # , o }FOLLOW ( K ) = FOLLOW ( M ) = { e , # , o }FOLLOW ( L ) ={ FIRST ( S ) –{ξ} } ∪{o} ∪FOLLOW ( K )∪{ FIRST ( M ) –{ξ} } ∪FOLLOW ( M )= {a, d , b , e , # , o }FOLLOW ( M ) ={ FIRST ( H ) –{ξ} } ∪FOLLOW ( S )∪{ FIRST ( L ) –{ξ} } = { e , # , o }SELECT ( S-> M H) = ( FIRST ( M H) –{ξ} ) ∪FOLLOW ( S )= ( FIRST( M ) ∪FIRST ( H ) –{ξ} ) ∪FOLLOW ( S )= { d , b , e , # , o }SELECT ( S-> a ) = { a }SELECT ( H->L S o ) = FIRST(L S o) = { e }SELECT ( H ->ξ) = FOLLOW ( H ) = { f , # , o }SELECT ( K-> d M L ) = { d }SELECT ( K->ξ) = FOLLOW ( K ) = { e , # , o }SELECT ( L-> e H f ) = { e }SELECT ( M->K ) = ( FIRST( K ) –{ξ} ) ∪FOLLOW ( M ) = {d,e , # , o }SELECT ( M -> b L M )= { b }4 . 文法含有左公因式,变为S->C $ { b, a }C-> b A { b }C-> a B { a }A -> b A A { b }A-> a A’ { a }A’-> ξ{ $ , a, b }A’-> C { a , b }B->a B B { a }B -> b B’ { b }B’->ξ{ $ , a , b }B’-> C { a, b }5. <程序> --- S <语句表>――A <语句>――B <无条件语句>――C <条件语句>――D <如果语句>――E<如果子句> --FS->begin A end S->begin A end { begin }A-> B A-> B A’ { a , if }A-> A ; B A’-> ; B A’ { ; }A’->ξ{ end }B-> C B-> C { a } B-> D B-> D { if }C-> a C-> a { a }D-> E D-> E D’ { if }D-> E else B D’-> else B { else }D’->ξ{; , end } E-> FC E-> FC { if }F-> if b then F-> if b then { if }非终结符是否为空S-否A-否A’-是B-否C-否D-否D’-是E-否F-否FIRST(S) = { begin }FIRST(A) = FIRST(B) ∪FIRST(A’) ∪{ξ} = {a , if , ; , ξ} FIRST(A’) ={ ; , ξ}FIRST(B) = FIRST(C) ∪FIRST(D) ={ a , if }FIRST(C) = {a}FIRST(D) = FIRST(E)= { if }FIRSR(D’) = {else , ξ}FIRST(E) = FIRST(F) = { if }FIRST(F) = { if }FOLLOW(S) = {# }FOLLOW(A) = {end}FOLLOW(A’) = { end }FOLLOW(B) = {; , end }FOLLOW (C) = {; , end , else }FOLLOW(D) = {; , end }FOLLOW( D’ ) = { ; , end }FOLLOW(E) = { else , ; end }FOLLOW(F) = { a }S A A’ B C D D’ E F if then else begin end a b ;6. 1.(1) S -> A | B(2) A -> aA|a(3)B -> bB |b提取(2),(3)左公因子(1) S -> A | B(2) A -> aA’(3) A’-> A|ξ(4) B -> bB’(5) B’-> B |ξ2.(1) S->AB(2) A->Ba|ξ(3) B->Db|D(4) D-> d|ξ提取(3)左公因子(1) S->AB(2) A->Ba|ξ(3) B->DB’(4) B’->b|ξ(5) D-> d|ξ3.(1) S->aAaB | bAbB(2) A-> S| db(3) B->bB|a4(1)S->i|(E)(2)E->E+S|E-S|S提取(2)左公因子(1)S->i|(E)(2)E->SE’(3)E’->+SE’|-SE’ |ξ5(1)S->SaA | bB(2)A->aB|c(3)B->Bb|d消除(1)(3)直接左递归(1)S->bBS’(2)S’->aAS’|ξ(3)A->aB | c(4) B -> dB’(5)B’->bB’|ξ6.(1) M->MaH | H(2) H->b(M) | (M) |b消除(1)直接左递归,提取(2)左公因子(1)M-> HM’(2)M’-> aHM’ |ξ(3)H->bH’ | ( M )(4)H’->(M) |ξ7. (1)1)A->baB2)A->ξ3)B->Abb4)B->a将1)、2)式代入3)式1)A->baB2)A->ξ3)B->baBbb4)B->bb5)B->a提取3)、4)式左公因子1)A->baB2)A->ξ3)B->bB’4)B’->aBbb | b5)B->a(3)1)S->Aa2)S->b3)A->SB4)B->ab将3)式代入1)式1)S->SBa2)S->b3)A->SB4)B->ab消除1)式直接左递归1)S->bS’2)S’->BaS’ |ξ3)S->b4)A->SB5)B->ab删除多余产生式4)1)S->bS’2)S’->BaS’ |ξ3)S->b4)B->ab(5)1)S->Ab2)S->Ba3)A->aA4)A->a提取3)4)左公因子1)S->Ab2)S->Ba3)A->aA’4)A’-> A |ξ5)B->a将3)代入1)5)代入21)S->aA’b2)S->aa3)A->aA’4)A’-> A |ξ5)B->a提取1)2)左公因子1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξ5)B->a删除多余产生式5)1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξA A’S’S将3)代入4)1)S-> aS’2)S’->A’b | a3)A->aA ’4)A’-> aA’ |ξ将4)代入2)1)S-> aS’2)S’->aA’b3)S’->a4)S’->b5)A->aA ’6)A’-> aA’ |ξ对2)3)提取左公因子1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b5)A->aA ’6)A’-> aA’ |ξ删除多余产生式5)1)S->aS’3)S’’->A’b|ξ4)S’->b5)A’-> aA’ |ξ第六章1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产生式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }= { a ∧ ( }FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( }求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)算符优先关系表因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(3)a ∧( ) , #F 1 1 1 1 1 1g 1 1 1 1 1 1f 2 2 1 3 2 1g 2 2 2 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1f 3 3 1 3 3 1g 4 4 4 1 2 1(4)#<·( a,a)# 移进#( <· a ,a)# 移进# (a ·> , a)# 规约#(T <·, a)# 移进#(T,<· a )# 移进#(T,a ·> ) # 规约#(T,T ·> ) # 规约#(T =·) # 移进#(T) ·> #规约#T =·#接受4.扩展后的文法S’→#S# S→S;G S→G G→G(T) G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( }FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( }FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = { )} ∪LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)分析a;(a+a)不能用最右推导推导出上面的两个句子。