编译原理课后习题答案-清华大学-第二版
- 格式:pdf
- 大小:3.31 MB
- 文档页数:167

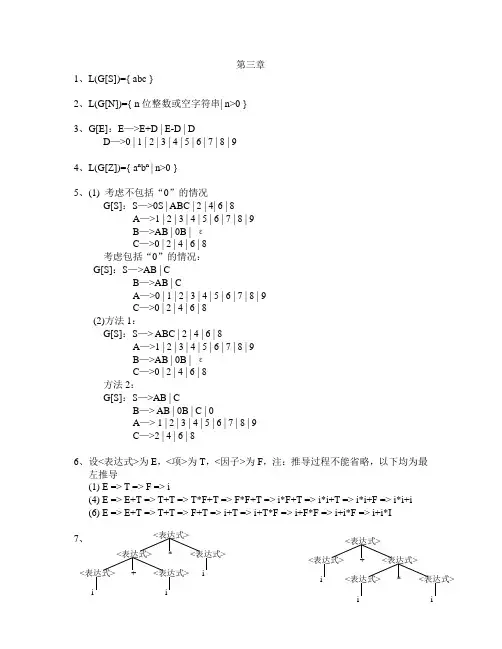
第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc 最左推导2:S => aB => abc 9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S=> ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T =>E+T*F ,所以E+T*F 是句型。
![最新编译原理[张素琴]第2版-答案-清华大学出版社](https://uimg.taocdn.com/9a1aa71ef242336c1eb95ea5.webp)
《编译原理》课后习题第 1 章引论第1 题解释下列术语:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。


Lw.《编译原理》课后习题答案第一章第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
盛威网()专业的计算机学习网站1《编译原理》课后习题答案第一章目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。

《编译原理》课后习题答案第一章第 4 题对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、代码生成)报告的。
(1) else 没有匹配的if(2)数组下标越界(3)使用的函数没有定义(4)在数中出现非数字字符答案:(1)语法分析(2)语义分析(3)语法分析(4)词法分析《编译原理》课后习题答案第三章第1 题文法G=({A,B,S},{a,b,c},P,S)其中P 为:S→Ac|aBA→abB→bc写出L(G[S])的全部元素。
答案:L(G[S])={abc}第2 题文法G[N]为:N→D|NDD→0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?答案:G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D或者:允许0 开头的非负整数?第3题为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:G[S]:S->S+D|S-D|DD->0|1|2|3|4|5|6|7|8|9第4 题已知文法G[Z]:Z→aZb|ab写出L(G[Z])的全部元素。
答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={anbn|n>=1}第5 题写一文法,使其语言是偶正整数的集合。
要求:(1) 允许0 打头;(2)不允许0 打头。
答案:(1)允许0 开头的偶正整数集合的文法E→NT|DT→NT|DN→D|1|3|5|7|9D→0|2|4|6|8(2)不允许0 开头的偶正整数集合的文法E→NT|DT→FT|GN→D|1|3|5|7|9D→2|4|6|8F→N|0G→D|0第6 题已知文法G:<表达式>::=<项>|<表达式>+<项><项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i试给出下述表达式的推导及语法树。

《编译原理》课后习题答案第一章第?1?章引论第?1?题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)?编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)?源程序:源语言编写的程序称为源程序。
(3)?目标程序:目标语言书写的程序称为目标程序。
(4)?编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)?后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)?遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第?2?题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含?8?个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。

第1 章引论第1 题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。

第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc 最左推导2:S => aB => abc 9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S=> ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T =>E+T*F ,所以E+T*F 是句型。

第三章N=>D=> {0,1,2,3,4,5,6,7,8,9}N=>ND=>NDDL={a |a(0|1|3..|9)n且 n>=1}(0|1|3..|9)n且 n>=1{ab,}a nb n n>=1第6题.(1) <表达式> => <项>=><因子>=>i(2) <表达式> => <项>=><因子>=>(<表达式>)=>(<项>)=>(<因子>)=>(i)(3) <表达式> =><项>=><项>*<因子>=><因子>*<因子>=i*i(4) <表达式> => <表达式>+<项>=><项>+<项>=><项>*<因子>+<项>=><因子>*<因子>+<项>=><因子>*<因子>+<因子>=i*i+i (5) <表达式> => <表达式>+<项>=><项>+<项> => <因子>+<项>=i+<项> =>i+<因子> => i+(<表达式>)=> i+(<表达式>+<项>)=> i+(<因子>+<因子>)=>i+(i+i)(6) <表达式> => <表达式>+<项>=><项>+<项> => <因子>+<项>=>i+<项> =>i+<项>*<因子>=>i+<因子>*<因子>=i+i*i第7题第9题语法树ss s* s s+aa a推导: S=>SS*=>SS+S*=>aa+a* 11. 推导:E=>E+T=>E+T*F语法树:E+T*短语: T*F E+T*F直接短语: T*F句柄: T*F12.<E><E> <T> <POP>短语:<T><F><MOP> <E><T><F><MOP><POP>直接短语:<T><F><MOP>句柄: <T><F><MOP>13.(1)最左推导:S => ABS => aBS =>aSBBS => aBBS=> abBS => abbS => abbAa => abbaa 最右推导:S => ABS => ABAa => ABaa => ASBBaa=> ASBbaa => ASbbaa => Abbaa => a1b1b2a2a3 (2) 文法:S → ABSS → AaS →εA → aB → b(3) 短语:a1 , b1 , b2, a2 , , bb , aa , abbaa,直接短语: a1 , b1 , b2, a2 , ,句柄:a114 (1)S → ABA → aAb | εB → aBb | ε(2)S → 1S0S → AA →0A1 |ε第四章1. 1. 构造下列正规式相应的DFA(1)1(0|1)*101NFA(2) 1(1010*|1(010)*1)*0NFA(3)NFA(4)NFA2.解:构造DFA 矩阵表示b其中0表示初态,*表示终态用0,1,2,3,4,5分别代替{X} {Z} {X,Z} {Y} {X,Y} {X,Y,Z} 得DFA状态图为:3.解:构造DFA矩阵表示构造DFA的矩阵表示其中表示初态,*表示终态替换后的矩阵4.(1)解构造状态转换矩阵:{2,3} {0,1}{2,3}a={0,3}{2},{3},{0,1}{0,1}a={1,1} {0,1}b={2,2}(2)解:首先把M的状态分为两组:终态组{0},和非终态组{1,2,3,4,5} 此时G=( {0},{1,2,3,4,5} ) {1,2,3,4,5}a={1,3,0,5}{1,2,3,4,5}b={4,3,2,5}由于{4}a={0} {1,2,3,5}a={1,3,5}因此应将{1,2,3,4,5}划分为{4},{1,2,3,5}G=({0}{4}{1,2,3,5}){1,2,3,5}a={1,3,5}{1,2,3,5}b={4,3,2}因为{1,5}b={4} {23}b={2,3}所以应将{1,2,3,5}划分为{1,5}{2,3}G=({0}{1,5}{2,3}{4}){1,5}a={1,5} {1,5}b={4} 所以{1,5} 不用再划分{2,3}a={1,3} {2,3}b={3,2}因为 {2}a={1} {3}a={3} 所以{2,3}应划分为{2}{3}所以化简后为G=( {0},{2},{3},{4},{1,5})7.去除多余产生式后,构造NFA如下确定化,构造DFA 矩阵G={(0,1,3,4,6),(2,5)} {0,1,3,4,6}a={1,3}{0,1,3,4,6}b={2,3,4,5,6}所以将{0,1,3,4,6}划分为 {0,4,6}{1,3} G={(0,4,6),(1,3),(2,5)}{0,4,6}b={3,6,4} 所以 划分为{0},{4,6} G={(0),(4,6),(1,3),(2,5)}不能再划分,分别用 0,4,1,2代表各状态,构造DFA 状态转换图如下;b8.代入得S = 0(1S|1)| 1(0S|0) = 01(S|ε) | 10(S|ε) = (01|10)(S|ε)= (01|10)S | (01|10)= (01|10)*(01|10)构造NFA由NFA可得正规式为(01|10)*(01|10)=(01|10)+9.状态转换函数不是全函数,增加死状态8,G={(1,2,3,4,5,8),(6,7)}(1,2,3,4,5,8)a=(3,4,8) (3,4)应分出(1,2,3,4,5,8)b=(2,6,7,8)(1,2,3,4,5,8)c=(3,8)(1,2,3,4,5,8)d=(3,8)所以应将(1,2,3,4,5,8)分为(1,2,5,8), (3,4)G={(1,2,5,8),(3,4),(6,7)}(1,2,5,8)a=(3,4,8) 8应分出(1,2,5,8)b=(2,8)(1,2,5,8)c=(8)(1,2,5,8)d=(8)G={(1,2,5),(8),(3,4),(6,7)}(1,2,5)a=(3,4,8) 5应分出G={(1,2), (3,4),5, (6,7) ,(8) }去掉死状态8,最终结果为 (1,2) (3,4) 5,(6,7) 以1,3,5,6代替,最简DFA为b正规式:b*a(da|c)*bb*第五章1.S->a | ^ |( T )T -> T , S | S(a,(a,a))S => ( T ) => ( T , S ) => ( S , S ) => ( a , S) => ( a, ( T )) =>(a , ( T , S ) ) => (a , ( S , S )) => (a , ( a , a ) )S=>(T) => (T,S) => (S,S) => ( ( T ) , S ) => ( ( T , S ) , S ) => ( ( T , S , S ) , S ) => ( ( S , S , S ) , S )=> ( ( ( T ) , S , S ) , S ) => ( ( ( T , S ) , S , S ) , S ) =>( ( ( S , S ) , S , S ) , S ) => ( ( ( a , S ) , S , S ) , S )=> ( ( ( a , a ) , S , S ) , S ) => ( ( ( a , a ) , ^ , S ) , S ) => ( ( ( a , a ) , ^ , ( T ) ) , S )=> ( ( ( a , a ) , ^ , ( S ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , S ) => ( ( ( a , a ) , ^ , ( a ) ) , a )S->a | ^ |( T )T -> T , ST -> S消除直接左递归:S->a | ^ |( T )T -> S T’T’-> , S T’ | ξSELECT ( S->a) = {a}SELECT ( S->^) = {^}SELECT ( S->( T ) ) = { ( }SELECT ( T -> S T’) = { a , ^ , ( }SELECT ( T’-> , S T’ ) = { , }SELECT ( T’->ξ) = FOLLOW ( T’ ) = FOLLOW ( T ) = { ) }构造预测分析表分析符号串( a , a )#分析栈剩余输入串所用产生式#S ( a , a) # S -> ( T )# ) T ( ( a , a) # ( 匹配# ) T a , a ) # T -> S T’# ) T’ S a , a ) # S -> a# ) T’ a a , a ) #a 匹配# ) T’,a) #T’-> , S T’# ) T’ S ,, a ) #, 匹配# ) T’ Sa ) #S->a# ) T’ aa ) #a匹配# ) T’) #T’ ->ξ# )) #)匹配##接受2.E->TE’ E’->+E E’->ξ T->FT’ T’->T T’->ξ F->PF’ F’->*F’ F’->ξP->(E) P->a P->b P->∧SELECT(E’->+E)={+}SELECT(E’->ε)=FOLLOW(E’)= {#,)}SELECT(T->FT’)=FIRST(F)= {(,a,b,^}SELECT(T’ —>T)=FIRST(T)= {(,a,b,^)SELECT(T’->ε)=FOLLOW(T’)= {+,#,)}SELECT(F ->PF’)=FIRST(F)= {(,a,b,^}SELECT(F’->*F’)={*}SELECT(F’->ε)=FOLLOW(F’)= {(,a,b,^,+,#,)}3. S->MH S->a H->Lso H->ξ K->dML K->ξ L->eHf M->K M->bLMFIRST ( S ) =FIRST(MH)= FIRST ( M ) ∪ FIRST ( H ) ∪ {ξ} ∪ {a}= {a, d , b , e ,ξ} FIRST( H ) = FIRST ( L ) ∪ {ξ}= { e , ξ}FIRST( K ) = { d , ξ}FIRST( M ) = FIRST ( K ) ∪ { b } = { d , b ,ξ}FOLLOW ( S ) = { # , o }FOLLOW ( H ) = FOLLOW ( S ) ∪ { f } = { f , # , o }FOLLOW ( K ) = FOLLOW ( M ) = { e , # , o }FOLLOW ( L ) ={ FIRST ( S ) –{ξ} } ∪{o} ∪ FOLLOW ( K )∪ { FIRST ( M ) –{ξ} } ∪ FOLLOW ( M )= {a, d , b , e , # , o }FOLLOW ( M ) ={ FIRST ( H ) –{ξ} } ∪ FOLLOW ( S )∪{ FIRST ( L ) –{ξ} } = { e , # , o }SELECT ( S-> M H) = ( FIRST ( M H) –{ξ} ) ∪ FOLLOW ( S )= ( FIRST( M ) ∪ FIRST ( H ) –{ξ} ) ∪ FOLLOW ( S )= { d , b , e , # , o }SELECT ( S-> a ) = { a }SELECT ( H->L S o ) = FIRST(L S o) = { e }SELECT ( H ->ξ) = FOLLOW ( H ) = { f , # , o }SELECT ( K-> d M L ) = { d }SELECT ( K->ξ ) = FOLLOW ( K ) = { e , # , o }SELECT ( L-> e H f ) = { e }SELECT ( M->K ) = ( FIRST( K ) –{ξ} ) ∪ FOLLOW ( M ) = {d, e , # , o }SELECT ( M -> b L M )= { b }4 . 文法含有左公因式,变为S->C $ { b, a }C-> b A { b }C-> a B { a }A -> b A A { b }A-> a A’ { a }A’-> ξ { $ , a, b }A’-> C { a , b }B->a B B { a }B -> b B’ { b }B’->ξ { $ , a , b }B’-> C { a, b }5. <程序> --- S <语句表>――A <语句>――B <无条件语句>――C <条件语句>――D <如果语句>――E<如果子句> --FS->begin A endS->begin A end { begin }A-> B A-> B A’ { a , if }A-> A ; B A’-> ; B A’ { ; }A’->ξ { end }B-> C B-> C { a }B-> DB-> D { if }C-> aC-> a { a }D-> ED-> E D’ { if }D-> E else BD’-> else B { else }D’->ξ {; , end }E-> FC E-> FC{ if }F-> if b then F-> if b then { if }非终结符是否为空S-否 A-否 A’-是 B-否 C-否 D-否 D’-是 E-否 F-否FIRST(S) = { begin }FIRST(A) = FIRST(B) ∪ FIRST(A’) ∪ {ξ} = {a , if , ; , ξ}FIRST(A’) ={ ; , ξ}FIRST(B) = FIRST(C) ∪ FIRST(D) ={ a , if }FIRST(C) = {a}FIRST(D) = FIRST(E)= { if }FIRSR(D’) = {else , ξ}FIRST(E) = FIRST(F) = { if }FIRST(F) = { if }FOLLOW(S) = {# }FOLLOW(A) = {end}FOLLOW(A’) = { end }FOLLOW(B) = {; , end }FOLLOW (C) = {; , end , else }FOLLOW(D) = {; , end }FOLLOW( D’ ) = { ; , end }FOLLOW(E) = { else , ; end }FOLLOW(F) = { a }S A A’ B C D D’ E F if then else begin end a b ;6. 1.(1) S -> A | B(2) A -> aA|a(3)B -> bB |b提取(2),(3)左公因子(1) S -> A | B(2) A -> aA’(3) A’-> A|ξ(4) B -> bB’(5) B’-> B |ξ2.(1) S->AB(2) A->Ba|ξ(3) B->Db|D(4) D-> d|ξ提取(3)左公因子(1) S->AB(2) A->Ba|ξ(3) B->DB’(4) B’->b|ξ(5) D-> d|ξ3.(1) S->aAaB | bAbB(2) A-> S| db(3) B->bB|a4(1)S->i|(E)(2)E->E+S|E-S|S提取(2)左公因子.(1)S->i|(E)(2)E->SE’(3)E’->+SE’|-SE’ |ξ5(1)S->SaA | bB(2)A->aB|c(3)B->Bb|d消除(1)(3)直接左递归(1)S->bBS’(2)S’->aAS’|ξ(3)A->aB | c(4) B -> dB’(5)B’->bB’|ξ6.(1) M->MaH | H(2) H->b(M) | (M) |b消除(1)直接左递归,提取(2)左公因子(1)M-> HM’(2)M’-> aHM’ |ξ(3)H->bH’ | ( M )(4)H’->(M) |ξ7. (1)1)A->baB2)A->ξ3)B->Abb4)B->a将1)、2)式代入3)式1)A->baB2)A->ξ3)B->baBbb4)B->bb5)B->a提取3)、4)式左公因子1)A->baB2)A->ξ3)B->bB’4)B’->aBbb | b5)B->a(3)1)S->Aa2)S->b3)A->SB4)B->ab.将3)式代入1)式1)S->SBa2)S->b3)A->SB4)B->ab消除1)式直接左递归1)S->bS’2)S’->BaS’ |ξ3)S->b4)A->SB5)B->ab删除多余产生式4)1)S->bS’2)S’->BaS’ |ξ3)S->b4)B->ab(5)1)S->Ab2)S->Ba3)A->aA4)A->a5)B->a提取3) 4)左公因子1)S->Ab2)S->Ba3)A->aA’4)A’-> A |ξ5)B->a将3)代入1) 5)代入21)S->aA’b2)S->aa3)A->aA’4)A’-> A |ξ5)B->a提取1) 2)左公因子1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξ5)B->a删除多余产生式5)1)S-> aS’2)S’->A’b | a3)A->aA’4)A’-> A |ξA A’ S’ S将3)代入4)1)S-> aS’2)S’->A’b | a3)A->aA ’4)A’-> aA’ |ξ将4)代入2)1)S-> aS’2)S’->aA’b3)S’->a4)S’->b5)A->aA ’6)A’-> aA’ |ξ对2)3)提取左公因子1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b5)A->aA ’6)A’-> aA’ |ξ删除多余产生式5)1)S->aS’2)S’->aS’’3)S’’->A’b|ξ4)S’->b5)A’-> aA’ |ξ第六章1S → a | ∧ | ( T )T → T , S | S解:(1) 增加辅助产生式 S’→#S#求 FIRSTVT集FIRSTVT(S’)= {#}FIRSTVT(S)= {a ∧ ( }= { a ∧ ( }FIRSTVT (T) = {,} ∪ FIRSTVT( S ) = { , a ∧ ( } 求 LASTVT集LASTVT(S’)= { # }LASTVT(S)= { a ∧ )}LASTVT (T) = { , a ∧ )}(2)算符优先关系表(3)a ∧(),#F 1 1 1 1 1 1g 1 1 1 1 1 1f22132 1g22212 1f33133 1g44412 1f33133 1g44412 1(4)栈优先关系当前符号剩余输入串移进或规约# <· ( a,a)# 移进#( <· a ,a)# 移进# (a·>,a)# 规约#(T <· , a)#移进#(T,<·a)#移进#(T,a·>) #规约#(T,T·>)# 规约#(T=· )#移进#(T) ·> #规约#T=·#接受4.扩展后的文法S’→#S# S→S;G S→G G→G(T) G→H H→a H→(S)T→T+S T→S(1)FIRSTVT(S)={;}∪FIRSTVT(G) = {; , a , ( }FIRSTVT(G)={ ( }∪FIRSTVT(H) = {a , ( }FIRSTCT(H)={a , ( }FIRSTVT(T) = {+} ∪FIRSTVT(S) = {+ , ; , a , ( }LASTVT(S) = {;} ∪LASTVT(G) = { ; , a , )}LASTVT(G) = {)}∪ LASTVT(H) = { a , )}LASTVT(H) = {a, )}LASTVT(T) = {+ } ∪LASTVT(S) = {+ , ; , a , ) }构造算符优先关系表因为任意两终结符之间至多只有一种优先关系成立,所以是算符优先文法(2)句型a(T+S);H;(S)的短语有:a(T+S);H;(S) a(T+S);H a(T+S) a T+S (S) H直接短语有: a T+S H (S)句柄: a素短语:a T+S (S)最左素短语:a(3)分析a;(a+a)分析a;(a+a)(4)不能用最右推导推导出上面的两个句子。
《编译原理》课后习题答案第一章第4题对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、代码生成)报告的。
(1)else 没有匹配的if(2)数组下标越界(3)使用的函数没有定义(4)在数中出现非数字字符答案:(1)语法分析(2)语义分析(3)语法分析(4)词法分析《编译原理》课后习题答案第三章第1题文法G=({A,B,S},{a,b,c},P,S)其中P 为:S→Ac|aBA→abB→bc写出L(G[S])的全部元素。
答案:L(G[S])={abc}第2题文法G[N]为:N→D|NDD→0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?答案:G[N]的语言是V+。
V={0,1,2,3,4,5,6,7,8,9}N=>ND=>NDD.... =>NDDDD...D=>D......D或者:允许0开头的非负整数?第3题为只包含数字、加号和减号的表达式,例如9-2+5,3-1,7等构造一个文法。
答案:G[S]:S->S+D|S-D|DD->0|1|2|3|4|5|6|7|8|9第4题已知文法G[Z]:Z→aZb|ab写出L(G[Z])的全部元素。
答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbbL(G[Z])={anbn|n>=1}第5题写一文法,使其语言是偶正整数的集合。
要求:(1)允许0打头;(2)不允许0打头。
答案:(1)允许0开头的偶正整数集合的文法E→NT|DT→NT|DN→D|1|3|5|7|9D→0|2|4|6|8(2)不允许0开头的偶正整数集合的文法E→NT|DT→FT|GN→D|1|3|5|7|9D→2|4|6|8F→N|0G→D|0第6题已知文法G:<表达式>::=<项>|<表达式>+<项> <项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i试给出下述表达式的推导及语法树。
《编译原理》课后习题答案第一章第1章引论第1题解释下列术语:(1)编译程序(2)源程序(3)目标程序(4)编译程序的前端(5)后端(6)遍答案:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)源程序:源语言编写的程序称为源程序。
(3)目标程序:目标语言书写的程序称为目标程序。
(4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
(6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。
第2题一个典型的编译程序通常由哪些部分组成各部分的主要功能是什么并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含8个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下。
词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。