
试验名称:萧山经济增长对外贸出口影响的eviews试
验报告
一、试验目的:
使用eviews3.1软件建立一元线性回归模型,估计模型参数,进行模型分析,过程中熟悉eviews3.1软件相有关操作、牢记相关原理,并且利用模型解决实际问题。
二、试验解决问题
这里我选取了经济开放的杭州市萧山区,用GDP表示经济发展水平,分析1989年至2008年萧山生产总值与出口额,判断二者间是否存在显著的联系。
三、试验步骤与分析
1、确立模型
为了分析1988年至2008年萧山生产总值与出口额之间的关系,拟设萧山出口额为被解释变量EX,萧山年生产总值为解释变量Y,出口额为解释变量EX,由此建立一元线性回归模型。
?LnEX=α+βLnGDP+ μ
2、数据搜集
源数据中出口额以美元为单位,这里将出口额按照当年平均汇率转换为以人民币为单位,与生产总值单位保持一致。
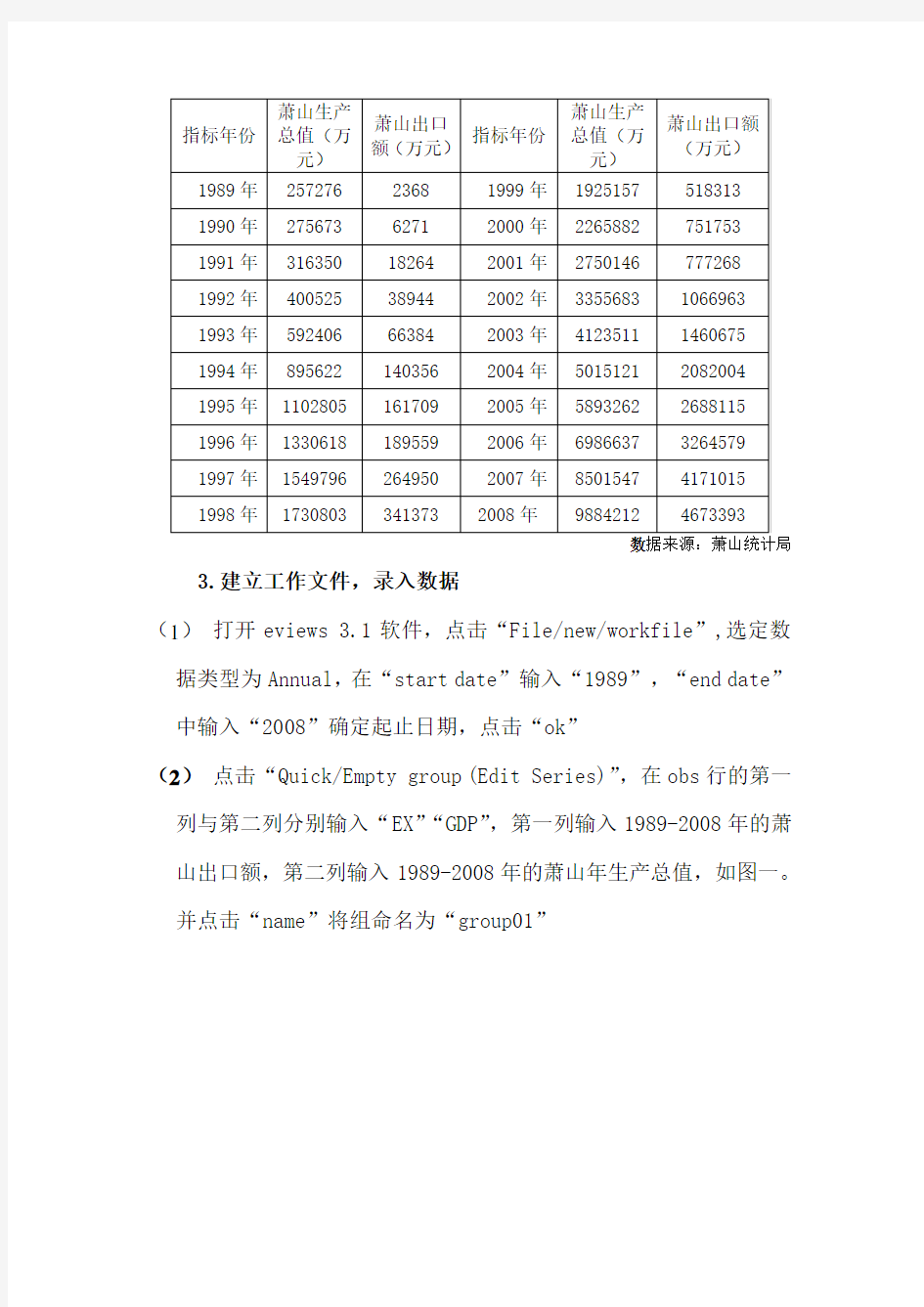
指标年份萧山生产
总值(万
元)
萧山出口
额(万元)
指标年份
萧山生产
总值(万
元)
萧山出口额
(万元)
1989年257276 2368 1999年1925157 518313
1990年275673 6271 2000年2265882 751753
1991年316350 18264 2001年2750146 777268
1992年400525 38944 2002年3355683 1066963
1993年592406 66384 2003年4123511 1460675
1994年895622 140356 2004年5015121 2082004
1995年1102805 161709 2005年5893262 2688115
1996年1330618 189559 2006年6986637 3264579
1997年1549796 264950 2007年8501547 4171015
1998年1730803 341373 2008年9884212 4673393
数据来源:萧山统计局
3.建立工作文件,录入数据
(1)打开eviews 3.1软件,点击“File/new/workfile”,选定数据类型为Annual,在“start date”输入“1989”,“end date”
中输入“2008”确定起止日期,点击“ok”
(2)点击“Quick/Empty group(Edit Series)”,在obs行的第一列与第二列分别输入“EX”“GDP”,第一列输入1989-2008年的萧山出口额,第二列输入1989-2008年的萧山年生产总值,如图一。
并点击“name”将组命名为“group01”
图一
4、对GDP、EX作图分析
点击“view/ Multiple Graphs/line”,得到EX与GDP的曲线图。
图二
点击“view/ Multiple Graphs/XY line”得到下图。
图三
Xy line图中,横坐标表示表示EX出口额,纵坐标表示GDP生产总值,从图中曲线的形状分析,EX与GDP的线性关系较强,有继续分析的意义。
5、描述性统计
(1)、打开对象“EX”,点击“view/Descriptive statistics/Histogram and stats”,可得到EX的描述性统计量。
EX的描述性统计。
均值(mean)为1134213。
中位数(median)为429843。
最大值(maximum)为4673393、最小值(minimum)为2368,可知EX序列数据跨度大。
标准差(std.dev)为1463811,说明Y序列数据离散程度大。
偏度(skewness)为1.301566,说明Y序列分布有长的右拖尾。
峰度(kurtosis)为3.385321,可知Y序列分布的凸起情况大于正态分布;
Jarque-Bera检验:H0:EX样本服从正态分布,H1:EX样本不服从正态分布,P=0.055837> 0.05,接受原假设,Y序列数据服从正态分布。
图四
(2)、打开对象“GDP”,点击“view/Descriptive statistics/Histogram and stats”,可得到GDP的描述性统计量。
图五
从图五中得知以下统计量。
均值(mean)为2957652。
中位数(median)为1827980。
最大值(maximum)为9884212、最小值(minimum)为257276,可知GDP序列数据跨度大。
标准差(std.dev)为2886654,说明GDP序列数据离散程度大。
偏度(skewness)为1.101958,说明GDP序列分布有长的右拖尾。
峰度(kurtosis)为3.092726,可知GDP序列分布的凸起情况略大于正态分布。
Jarque-Bera检验:H0:GDP样本服从正态分布,H1:GDP样本不服从正态分布。P=0.131673>0.05,接受原假设,GDP序列数据服从正态分布。
6、估计模型参数
点击“quick/estimate equation”,选择最小二乘法,在跳出的窗口中输入“LOG(EX) C LOG(GDP)”,让EX的对数对常数项和GDP的对数进行回归。结果如下。
图六
图六中得出的LnGDP的系数β的估计值为1.825093,常数项α的估计值为-13.58382,代入可以得到如下一元线性回归模型。
LnEX = -13.58382 + 1.825093LnGDP
(-10.54696)(20.41258)
R2 =0.958590 ADR=0.956289
括号内是T统计值。
7、所得模型的检验
(1)、经济意义检验。
在该模型中,LnGDP前的参数估计量为正,意味着GDP越大即经济发展水平越高,出口额就越大,符合原有理论以及现实经济行为。经济意义检验通过。
(2)、统计检验
①拟合优度检验。从图六可以得到可决系数R2为0.958590,ADR为
0.956289,说明样本点与回归直线拟合的很好。
②变量的显著性检验(使用T检验、F检验)。
T检验:设原假设H0:β=0,备择假设H1:β≠0,从图六中可以得到Prob(t-statistic)=0.0000<0.05,拒绝原假设,说明在总体中GDP对EX的影响是显著的。
F检验:设原假设H0:β=0,备择假设H1:β≠0,从图六中可以得到Prob(F-statistic)=0.0000<0.05,说明总体的线性关系也是显著的。
结论:T检验、F检验通过。
(3)、计量经济学检验
这里我选用的数据属于时间序列数据,这种数据容易产生序列相关问题,在这里我用杜宾法检验。
杜宾法中,对μt = ρμt-1 + εt,原假设为ρ= 0,备择假设为ρ≠0,检验仪器为
从最小二乘估计得出的表中可以看到D.W.=0.500897,通过查表得知在5%的显著性水平且n=20、k=2的情况下d L =1.20,du=1.41, 0 结论:模型LnEX = -13.58382 + 1.825093LnGDP 存在正序列相关问题。 8、自相关问题的解决 使用Cochrane-Orcutt 二阶段迭代法 (1)点击“quick/estimate equation ”, 选择最小二乘法,在跳出的窗口中输入“LOG(EX) C LOG(GDP) AR(1)”,显示结果如下。 ∑∑==--= n t t n t t t e e e W D 122 21 ~)~~(. . LnEX = -7.756501 + 1.438620 LnGDP +0.574091AR(1) (-4.268444)(11.97726) (6.626776) R2 =0.995071 ADR=0.994455 D.W.=1.690313 括号中为T统计值 分析:常数项的 T检验中,Prob(t-statistic)=0.0006<0.05,LOG(GDP)和AR(1)的T检验中,Prob(t-statistic)=0.0000<0.05,说明这些参数都是显著的。 D.W.= 1.690313 。通过查表得知在5%的显著性水平且n=20、k=3的情况下d L=1.10,du=1.54 。du <1.690313<4-du . 结论:该模型很好的拟合了样本,参数显著性检验通过,且解决了原来的自相关问题。 (2)点击“quick/estimate equation”,选择最小二乘法,在跳出的窗口中输入“LOG(EX) C LOG(GDP) AR(1) AR(2)”,显示结果如下。 LnEX = -9.938304 + 1.581804 LnGDP +0.651521 AR(1) - 0.233520AR(2) (-9.807518) (23.21918) (3.094754) (-1.746924) R2 =0.995758 ADR=0.994849 D.W.=1.898759 括号中为T统计值 分析:常数项与LOG(GDP)的T检验中,Prob(t-statistic)=0.0000<0.05,AR(1)的T检验中,Prob(t-statistic)=0.0079<0.05,说明这三个参数都是显著的。 但是AR(2)的T检验中,Prob(t-statistic)=0.1025>0.05,这个参数并不显著。 D.W.= 1.898759。通过查表得知在5%的显著性水平且n=20、k=3的情况下d L=1.10,du=1.54 。du <1.898759<4-du . 结论:新添加的AR(2)显著性检验并未通过,但是解决了原来的自相关问题。 9、最终确定模型 综上所述,最终确定的模型为 LnEX = -7.756501 + 1.438620 LnGDP +0.574091AR(1) 该模型不仅与样本的拟合程度高,而且不存在自相关问题,具有对显示经济现象进行解释与预测的意义。 经济分析:InGDP的系数为正,说明经济发展水平的提高的确可以增加出口额,而这与现实经济现象也是一致的。 统计分析:R2 =0.995071,说明模型很好地拟合了样本,所有参数的Prob(t-statistic) <0.05,说明显著性检验通过,D.W.= 1.898759, du <1.898759<4-du,说明模型不存在自相关问题。 五、不足之处 1、对eviews软件的使用并不得心应手 2、分析地不够专业,特别是经济分析 3、数据比较陈旧,使得模型不能很好的解释现在的经济现象 2011.8.15 H09800202 经济学09(2)班高佳玲 附件二:实验报告格式(首页) 山东轻工业学院实验报告成绩 课程名称计量经济学指导教师实验日期 2013.5.18 院(系)商学院会计系专业班级会计实验地点实验楼二机房 学生姓名学号同组人无 实验项目名称异方差的检验 一、实验目的和要求 1、理解异方差的含义后果、 2、学会异方差的检验与加权最小二乘法要求熟悉基本操作步骤,读懂各项上机榆出结果 的含义并进行分析 3、掌握异方差性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操 作方法 4、练习检查和克服模型的异方差的操作方法。 5、掌握异方差性的检验及处理方法 6、用图示法、斯皮尔曼法、戈德菲尔德、white验证法,验证该模型是否存在异方差 二、实验原理 1、异方差的检验出消除方法 2、运用EVIEWS软件及普通最小二乘法进行模型估计 3、检验模型的异方差性并对其进行调整 三、主要仪器设备、试剂或材料 Eviews软件、课本教材、电脑 四、实验方法与步骤 一、准备工作。建立工作文件,并输入数据,用普通最小二乘法估计方程(操作步骤 与方法同前),得到残差序列。 1、CREATE U 1 31 回车 2、DATA Y X 回车 输入数据 obs Y X 1 264 8777 2 105 9210 3 90 9954 4 131 10508 5 122 10979 6 10 7 11912 7 406 12747 8 503 13499 9 431 14269 10 588 15522 11 898 16730 12 950 17663 13 779 18575 14 819 19635 15 1222 21163 16 1702 22880 17 1578 24127 18 1654 25604 19 1400 26500 20 1829 26760 21 2200 28300 22 2017 27430 23 2105 29560 24 1600 28150 25 2250 32100 26 2420 32500 27 2570 35250 28 1720 33500 29 1900 36000 30 2100 36200 31 2800 38200 3、LS Y C X 回车 用最小二乘法进行估计出现 Dependent Variable: Y Method: Least Squares Date: 05/18/13 Time: 11:19 Sample: 1 31 Included observations: 31 Variable Coefficien t Std. Error t-Statistic Prob. 实验四虚拟变量 【实验目的】 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。 【实验内容】 试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立 【实验步骤】 1、相关图分析 根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异, 因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 2、构造虚拟变量 构造虚拟变量 1D (DATA D1),并生成新变量序列: GENR XD=X*D1 3、估计虚拟变量模型 LS Y C X D1 XD 得到估计结果: 我国城镇居民彩电需求函数的估计结果为: XD D X Y 009.0873.31012.0611.571-++=∧ (16.25) (9.03) (8.32) (-6.59) 366,066.1..,9937.02===F e s R 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。 低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: X Y 012.0611.57+=∧ 中高收入家庭: X X Y 003.0484.89)009.0012.0()873.31611.57(+=-++=∧ 由此可见我国城镇居民家庭现阶段彩电消费需求的特点: 对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。 计量经济学E v i e w s多重共线性实验报告 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT 实验报告课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 四、预备知识:最小二乘法估计的原理、t检验、F检验、2R值。 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据 资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ () 录入数据,得到图。 2.2.1)采用OLS 估计参数 在主界面命令框栏中输入 ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。 由此可见,该模型的可决系数为,修正的可决系数为,模型拟和很好,F 统计量为,回归方程整体上显着。 可是其中的lnX3、lnX4、lnX6对lnY 影响不显着,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。所以这样的回归结果并不理想。 3、多重共线性模型的识别 第4章图形和统计量分析 EViews 软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法 和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且 可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统 计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图 (Line)、散点图 (Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。 下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗 口或序列组对象窗口,选择对象窗口工具栏中的“ View ” | “Graph ”选项。选择的对象 类型不同,将弹出不同的窗口。如果在序列对象窗口下选择" View ” | “Graph ”选项, 将弹出如图4-1所示的界面。 55 HTTiF ar.sDoo Aii 7^nnnl 图4-1 序列窗口下图形对象的生成 此时“ Graph ”弹出的菜单中有 6种图形可供选择。“ Line ”表示生成的是折线图, 如图4-2所示,其横轴表示时间或序列的顺序, 纵轴表示序列对象观测值的大小。 “Area ” 5“ Edl Lint lar SpLfet Sf MAM L Sjilii 1 Lina TB1 rvurkfile. FM . .T&li tleA TOTiFJ 1 2OD3M12 □ — 亍 0* PtEizJ bjjeit | 中口严 i.G P~rt Ware I ee 二已 | Det-auk 《计量经济学》实训报告 实训项目名称异方差的检验及修正 实训时间 2011年12月13日 实训地点 班级 学号 姓名 实训(实践) 报告 实训名称异方差的检验及修正 一、实训目的 深刻理解异方差性的实质、异方差出现的原因、异方差的出现对模型的不良影响(即异方差的后果),掌握估计和检验异方差性的基本思想和修正异方差的若干方法;能够运用所学的知识处理模型中的出现的异方差问题,并要求初步掌握用EViews处理异方差的基本操作方法。 二、实训要求 使用教材第五章的数据做异方差的图形法检验、Goldfeld-Quanadt检验与White检验,使用WLS法对异方差进行修正。 三、实训内容 1、用图示法、戈德菲尔德、white验证法,验证该模型是否存在异方差。 2、用加权最小二乘法消除异方差。 四、实训步骤 练习题5.8数据1998年我国重要制造业销售收入和销售利润的数据 Y—销售利润,x—销售收入 1. 用OLS方法估计参数,建立回归模型:ls y c x 回归结果如下: Y=12.036+0.1044x; S = (19.5178) (0.00844) T= (0.6167) (12.3667) R^2=0.8547 S.E.=56.9037 2.检验是否存在异方差 (1) 图形检验:残差图形scat x e2 结果表明: 残差平方e2对解释变量的x的散点图主要分布在图形的下方,大致看出残差平方随X 的变动呈增大的趋势,因此,模型很可能出现异方差。 (2)戈德菲尔德-夸特检验 首先,对变量进行排序,在这个题目中,我选择递增型排序,这是y与x将以x按递增型排序。 然后构造子样本区间,建立回归模型。在本题目中,n=28,删除中间的1/4,的观测值,即大约8个观测值,剩余部分平分得两个样本区间:1—10和19-28,他们的样本个数均为10。 用OLS方法得到前10个数的样本结果(ls y c x): 用OLS方法得到后10个数的样本结果(ls y c x): 大连海事大学 实验报告 实验名称:计量经济学软件应用 专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月 一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。二、实验环境 WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。 三、实验模型建立与分析 案例1: 我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况 (1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下: Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20 Variable Coeffici ent Std. Error t-Statisti c Prob.?? C691.0225113.3920 6.0941040.0000 AVGDP0.3527700.00490871.880540.0000 R-squared0.996528????Mean dependent var7351.300 Adjusted R-squared0.996335????S.D. dependent var4828.765 S.E. of regression292.3118????Akaike info criterion14.28816 Sum squared resid1538032.????Schwarz criterion14.38773 Log likelihood -140.881 6 ????Hannan-Quinn criter.14.30760 F-statistic5166.811????Durbin-Watson stat0.403709 Prob(F-statistic)0.000000 由上表可知财政收入随国内生产总值变化的一元线性回归方程为: e v i e w s图像及结果分 析 EViews图像及结果分析 EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。选择的对象类型不同,将弹出不同的窗口。如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。 图4-1 序列窗口下图形对象的生成 此时“Graph”弹出的菜单中有6种图形可供选择。“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。 收集于网络,如有侵权请联系管理员删除 收集于网络,如有侵权请联系管理员删除 图4-2 “Line ”折线图 “Bar ”表示为条形图,用条状的高度表示观测值的大小。“Spike ”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。“Seasonal Stacked Line ”表示生成的是季节性堆叠图,“Seasonal Split Line ”表示生成的是季节性分割线。 如果在序列组(群)对象窗口下选择“View ”|“Graph ”选项,将弹出如图4-3所示的界面。这里有 9种图形可供选择。其前4种与上面讲述的相同。 图4-3 序列组(群)窗口下图对象的生成 其中,“Scatter ” 表示生成散点图。在“Scatter ”弹出的菜单中有5个选项,分别是“Simple Scatter ”(简单散点图)、“Scatter with Regression ”(带有回归线的散点图)、“Scatter with Nearest Neighbor Fit ”(近邻匹配散点图)、“Scatter with Kernel Fit ”(核心匹配散点图)、“XY Pairs ”(XY 成对散点图)。当序列组中包含两个序列对象时,第一个序列对象的观测值构成散点图的横坐标,第二个序列对象的观测值构成散点图的纵坐标,如图4-4所示。当 实验报告2 实验目的:掌握异方差的检验及处理方法。 实验容:检验家庭人均纯收入与家庭生活消费支出可能存在的异方差性。有关数据如下:其中,收入为X,家庭生活消费支出为Y。 地区家庭人均 纯收入 家庭生活 消费支出地区 家庭人均 纯收入 家庭生活 消费支出 北京9439.63 6399.27 湖北3997.48 3090 天津7010.06 3538.31 湖南3904.2 3377.38 河北4293.43 2786.77 广东5624.04 4202.32 山西3665.66 2682.57 广西3224.05 2747.47 3953.1 3256.15 海南3791.37 2556.56 辽宁4773.43 3368.16 重庆3509.29 2526.7 吉林4191.34 3065.44 四川3546.69 2747.27 4132.29 3117.44 贵州2373.99 1913.71 上海10144.62 8844.88 云南2634.09 2637.18 江苏6561.01 4786.15 西藏2788.2 2217.62 浙江8265.15 6801.6 陕西2644.69 2559.59 安徽3556.27 2754.04 甘肃2328.92 2017.21 福建5467.08 4053.47 青海2683.78 2446.5 江西4044.7 2994.49 宁夏3180.84 2528.76 山东4985.34 3621.57 新疆3182.97 2350.58 河南3851.6 2676.41 实验步骤如下: 一、建立有关模型分析异方差检验如下。 方法一、图示法。(两种) (一)、x y 相关分析 从图中可以看出,随着收入的增加,家庭生活消费支出不断的提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 建立模型: 1、从图中可以看出,x y不是简单的线性关系。建立线性回归方程如下, LS Y C X 第4章图形和统计量分析 EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。选择的对象类型不同,将弹出不同的窗口。如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。 . . 图4-1 序列窗口下图形对象的生成 此时“Graph”弹出的菜单中有6种图形可供选择。“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。 图4-2 “Line”折线图 “Bar”表示为条形图,用条状的高度表示观测值的大小。“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。 如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。这里有9种图形可供选择。其前4种与上面讲述的相同。 图4-3 序列组(群)窗口下图对象的生成 计量经济学实验报告 多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到30.0亿人次,同比增长13.6%,国内旅游收入2.3万亿元,同比增长19.1%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β1X 1 +β2X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元 江西农业大学经济贸易学院学生实验报告 课程名称:计量经济学 专业班级:经济1201班 姓名: 学号: 指导教师:徐冬梅 职称:讲师 实验日期: 2014.12.11 学生实验报告 一、实验目的及要求 1、目的 会使用EVIEWS对计量经济模型进行分析 2、内容及要求 (1)对经典线形回归模型进行参数估计、参数的检验与区间估计,对模型总体进行显著性检验; (2)异方差的检验及其处理; (3)自相关的检验及其处理; (4)多重共线性检验及其处理; 二、仪器用具 三、实验方法与步骤 (一)数据的输入、描述及其图形处理; (二)方程的估计; (三)参数的检验、违背经典假定的检验; (四)模型的处理与预测 四、实验结果与数据处理 实验一:中国城镇居民人均消费支出模型 数据散点图: 通过Eviews 估计参数方程 回归方程: Dependent Variable: Y Method: Least Squares Date: 11/27/14 Time: 15:02 Sample: 1 31 Included observations: 31 Variable Coefficien t Std. Error t-Statistic Prob. X 1.359477 0.043302 31.39525 0.0000 C -57.90655 377.7595 -0.153289 0.8792 R-squared 0.971419 Mean dependent var 11363.69 Adjusted R-squared 0.970433 S.D. dependent var 3294.469 S.E. of regression 566.4812 Akaike info criterion 15.57911 Sum squared resid 9306127. Schwarz criterion 15.67162 Log likelihood -239.4761 F-statistic 985.6616 Durbin-Watson stat 1.294974 Prob(F-statistic) 0.000000 5000 10000 15000 20000 25000 6000 800010000120001400016000 X Y EVIEWS实验报告 专业:金融学 班级:10907 学号:1090723 姓名:侯文隽 一、选题 自1949年新中国成立以后,我国国债发行基本分为两个阶段:20世纪50年代是第一阶段,为了支援人民解放战争,恢复和发展经济,我国先后发行过人民胜利折实公债和国家经济建设公债。80年代以来是第二阶段,进入20世纪80年代以后,随着改革开放的不断深入,我国国民收入分配格局发生了变化,国债的发行量也逐年扩大。本次实验出发点是根据1980-2005年的国债规模和可能的相关因素进行分析,同时达到掌握使用EVIEWS进行经济问题分析的目的。二、建立模型 影响国债规模的因素是多方面的、多层次的,我们暂且不去考虑微观上国债的管理水平与结构、筹资成本、期限安排、偿还方式等因素,因为这些因素的影响是个别的,并且难以计量。所以从宏观经济角度出发,引入财政赤字、国内生产总值(GDP)、年还本付息支出等指标,并建立多元线性回归模型。以国债发行量作为被解释变量Y,财政赤字、GDP、还本付息支出作为解释变量分别用X1、X2、X3表示。建立模型如下: Y=b0+b1*X1+b2*X2+b3*X3 三、数据来源 下表列出了1980-2005年间历年国债发行规模及各相关因素的具体数据表1 单位:亿元 (来源于中国统计年鉴2006,1980-2005年数据) 四、实验结果 通过普通最小二乘法对变量进行回归估计,得到结果如下: Dependent Variable: Y Method: Least Squares Date: 10/02/11 Time: 13:09 Sample: 1980 2005 Included observations: 26 Variable Coefficient Std. Error t-Statistic Prob. C -82.30505 63.20978 X1 0.816282 0.075733 X2 0.671558 0.414988 X3 0.980645 0.160403 R-squared 0.994963 Mean dependent var 2015.208 Adjusted R-squared 0.994276 S.D. dependent var 2355.453 S.E. of regression 178.2087 Akaike info criterion 13.34443 Sum squared resid 698683.5 Schwarz criterion 13.53798 Log likelihood -169.4775 F-statistic Durbin-Watson stat 1.141533 Prob(F-statistic) Y=-82.3051+0.8163X1+0.6716X2+0.9806X3 五、模型检验 1、从回归估计的结果看,可决系数R2=0.9949,模型拟合较好。方程的显著性检 验中F的伴随概率等于0,小于0.05,说明所有的待估参数不全为零,方程总体上的线性关系是显著成立的。在变量的显著性检验中,X1和X3的t检 1. Eviews 基础 1.1. Eviews 简介 Eviews :Econometric Views (经济计量视图),是美国QMS 公司(Quantitative Micro Software Co.,网址为https://www.doczj.com/doc/d42628876.html, )开发的运行于Windows 环境下的经济计量分析软件。Eviews 是应用较为广泛的经济计量分析软件——MicroTSP 的Windows 版本,它引入了全新的面向对象概念,通过操作对象实现各种计量分析功能。 Eviews 软件功能很强,能够处理以时间序列为主的多种类型数据,进行包括描述统计、回归分析、传统时间序列分析等基本数据分析以及建立条件异方差、向量自回归等复杂的计量经济模型。 1.2. Eviews 的启动、主界面和退出 1.2.1. Eviews 的启动 单击Windows 的【开始】按钮,选择【程序】选项中的【Eviews 】,单击其中的【Eviews 】;或者在相应目录下用鼠标双击 启动Eviews 5程序,进入主窗 口。如图1.1所示: 图 1.1 菜单栏 命令窗口 工作区 状态栏 路径 1.2.2.Eviews窗口介绍 标题栏 Eviews窗口的顶部是标题栏,标题栏左边是控制框;右边是控制按钮,有【最小化】、【最大化(或还原)】、【关闭】三个按钮。 菜单栏 标题栏下面是菜单栏。菜单栏中排列着按照功能划分的9个主菜单选项,用鼠标单击任意选项会出现不同的下拉菜单,显示该部分的具体功能。9个主菜单选项提供的主要功能如下: 【File】有关文件(工作文件、数据库、Eviews程序等)的常规操作,如文件的建立(New)、打开(Open)、保存(Save/Save As)、关闭(Close)、导入(Import)、导出(Export)、打印(Print)、运行程序(Run)等;选择下拉菜单中的Exit将退出Eviews软件。 【Edit】通常情况下只提供复制功能(下拉菜单中只有Cut、Copy项被激活),应与粘贴(Paste)配合使用;对某些特定窗口,如查看模型估计结果的表达式时,可对窗口中的内容进行剪切(Cut)、删除(Delete)、查找(Find)、替换(Replace)等操作,选择Undo表示撤销上步操作。 【Objects】提供关于对象的基本操作。包括建立新对象(New Objects)、从数据库获取/更新对象(Fetch/Update from DB)、重命名(Rename)、删除(Delete)。 【View】和【Procs】二者的下拉菜单项目随当前窗口不同而改变,功能也随之变化,主要涉及变量的多种查看方式和运算过程。我们将在以后的实验中针对具体问题进行具体介绍。 【Quick】下拉菜单主要提供一些简单常规用法的快速进入方式。如改变样本范围(Sample)、生成新序列(Generate Series)、显示对象(Show)、作图(Graph)、生成新组(Empty Group)以及序列和组的描述统计量、新建方程和V AR。 【Options】系统参数设定选项。与一般应用软件相同,Eviews运行过程中的各种状态,如窗口的显示模式、字体、图像、电子表格等都有默认的格式,用户可以根据需要选择Options下拉菜单中的项目对一些默认格式进行修改。 【Windows】提供多种在打开窗口种进行切换的方式,以及关闭所有对象(Close All Objects)或关闭所有窗口(Close All)。 【Help】Eviews的帮助选项。选择Eviews Help Topics按照索引或目录方式在所有帮助信息种查找所需项目。下拉菜单还提供分类查询方式,包括对象(Object)、命令(Command)、函数(Function)、矩阵与字符串(Matrix&String)、程序(Programming)等五个方面。 命令窗口 菜单栏下面是命令窗口(Command Windows),窗口内闪烁的“︱”是光标。 实验一 EVIEWS中时间序列相关函数操作 【实验目的】熟悉Eviews的操作:菜单方式,命令方式; 练习并掌握与时间序列分析相关的函数操作。 掌握时间序列的白噪声检验 【实验内容】 一、复习EViews软件的常用菜单方式和命令方式; 二、各种常用差分函数表达式以及确定性趋势模型拟合; 三、时间序列的自相关和偏自相关图与函数; 四、时间序列的白噪声检验 【实验步骤】 复习:EViews软件的常用菜单方式和命令方式; (一)创建工作文件 ⒈菜单方式 启动EViews软件之后,进入EViews主窗口 在主菜单上依次点击File/New/Workfile,即选择新建对象的类型为工作文件,将弹出一个对话框,由用户选择数据的时间频率(frequency)、起始期和终止期。选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日期,然后点击OK按钮,将在EViews软件的主显示窗口显示相应的工作文件窗口。 工作文件窗口是EViews的子窗口,工作文件一开始其中就包含了两个对象,一个是系数向量C(保存估计系数用),另一个是残差序列RESID(实际值与拟合值之差)。 ⒉命令方式 在EViews软件的命令窗口中直接键入CREATE命令,也可以建立工作文件。命令格式为:CREATE 时间频率类型起始期终止期 则菜单方式过程可写为:CREATE A 1985 1998 (二)输入Y、X的数据 ⒈DATA命令方式 在EViews软件的命令窗口键入DATA命令,命令格式为: DATA <序列名1> <序列名2>…<序列名n> 本例中可在命令窗口键入如下命令: DATA Y X .. . … . 第4章图形和统计量分析 EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。选择的对象类型不同,将弹出不同的窗口。如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。 图4-1 序列窗口下图形对象的生成 此时“Graph”弹出的菜单中有6种图形可供选择。“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。 图4-2 “Line”折线图 “Bar”表示为条形图,用条状的高度表示观测值的大小。“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。 如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。这里有9种图形可供选择。其前4种与上面讲述的相同。 实验题目:多元线性回归、异方差、多重共线性 实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。 实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。 实验步骤: 1.建立出口货物总额计量经济模型: 错误!未找到引用源。(3.1) 1.1建立工作文件并录入数据,得到图1 图1 在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据 表。点”view/graph/line/ok”,形成线性图2。 图2 1.2对(3.1)采用OLS估计参数 在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。 图 3 根据图3中的数据,得到模型(3.1)的估计结果为 (8638.216)(0.012799)(9.776181) t=(-2.110573) (10.58454) (1.928512) 错误!未找到引用源。错误!未找到引用源。F=522.0976 从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。但当错误!未找到引用源。=0.05时,错误!未找到引用源。=错误!未找到引用源。2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。 2.多重共线性模型的识别 2.1计算解释变量x2、x3的简单相关系数矩阵。 点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。 相关系数矩阵 图4 由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。 2.2多重共线性模型的修正 EViews图像及结果分析 EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。选择的对象类型不同,将弹出不同的窗口。如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。 图4-1 序列窗口下图形对象的生成 此时“Graph”弹出的菜单中有6种图形可供选择。“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。 图4-2 “Line”折线图 “Bar”表示为条形图,用条状的高度表示观测值的大小。“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。 如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。这里有9种图形可供选择。其前4种与上面讲述的相同。 图4-3 序列组(群)窗口下图对象的生成 其中,“Scatter”表示生成散点图。在“Scatter”弹出的菜单中有5个选项,分别是“Simple Scatter”(简单散点图)、“Scatter with Regression”(带有回归线的散点图)、“Scatter with Nearest Neighbor Fit”(近邻匹配散点图)、“Scatter with Kernel Fit”(核心匹配散点图)、“XY Pairs”(XY成对散点图)。当序列组中包含两个序列对象时,第一个序列对象的观测值构成散点图的横坐标,第二个序列对象的观测值构成散点图的纵坐标,如图4-4所示。当序列组中有三个以上的序列对象时,第一个序列对象构成散点图的横坐标,其余序列对象构成散点图的纵坐标。 实验报告 课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期:2014 年05 月11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 R值。 四、预备知识:最小二乘法估计的原理、t检验、F检验、2 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据 资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98 至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ (2.1) 2.1录入数据,得到图。异方差实验报告
Eviews虚拟变量实验报告
计量经济学Eviews多重共线性实验报告
eviews图像及结果分析
异方差实验报告
计量经济学eviews实验报告
eviews图像及结果分析教学提纲
计量经济学异方差实验报告材料二
eviews图像及结果分析报告
计量经济学多元线性回归、多重共线性、异方差实验报告概要
Eviews实验报告
EVIEWS实验报告1
计量实验一Eviews入门操作讲解
实验一EVIEWS中时间的序列相关函数操作
eviews图像及结果分析
多元线性回归实验报告
eviews图像及结果分析
计量经济学Eviews多重共线性实验报告
相关主题
文本预览