
幻灯片1 正态分布 第二章 第七节 一、标准正态分布的密度函数 二、标准正态分布的概率计算 三、一般正态分布的密度函数 四、正态分布的概率计算幻灯片2 正态分布的重要性正态分布是概率论中最重要的分布, 这能够由 以下情形加以说明: ⑴ 正态分布是自然界及工程技术中最常见的分布之一, 大量的随机现象都是服从或近似服从正态分布的.能够证明, 如果一个随机指标受到诸多因素的影响, 但其中任何一个因素都不起决定性作用, 则该随机指标一定服从或近似服从正态分布. 这些性质是其它 ⑵ 正态分布有许多良好的性质, 许多分布所不具备的. ⑶ 正态分布能够作为许多分布的近似分布.幻灯片3 -标准正态分布下面我们介绍一种最重要的正态分布 一、标准正态分布的密度函数若连续型随机变量X 的密度函数为定义 则称X 服从标准正态分布,
记为标准正态分布是一种特别重要的它的密度函数经常被使用, 分布。 幻灯片4 密度函数的验证 则有 ( 2) 根据反常积分的运算有能够推出 幻灯片5 标准正态分布的密度函数的性质若随机变量 , X 的密度函数为 则密度函数的性质为: 的图像称为标准正态( 高斯) 曲线幻灯片6 随机变量 由于 由图像可知, 阴影面积为概率值。对同一长度的区间 , 若这区间越靠近 其对应的曲边梯形面积越大。标准正态分布的分布规律时”中间多, 两头少” . 幻灯片7 二、标准正态分布的概率计算 1、分布函数分布函数为幻灯片8 2、标准正态分布表书末附有标准正态分布函数数值表, 有了它, 能够解决标准正态分布的概率计算.表中给的是x > 0时,①(x)的值. 幻灯片9 如果由公式得令则幻灯片10
利用Excel的NORMSDIST计算正态分布函数表1
利用Excel的NORMSDIST函数建立正态 分布表 董大钧,乔莉 沈阳理工大学应用技术学院、信息与控制分院, 辽宁抚顺113122 摘要:利用Excel办公软件特有的NORMSDIST函数可以很准确方便的建立正态分布表、查找某分位数点的正态分布概率值,极大的提高了数理统计的效率。该函数可返回指定平均值和标准偏差的正态分布函数,将其引入到统计及数据分析处理过程中,代替原有的手工查找正态分布表,除具有直观、形象、易用等特点外,更增加了动态功能,极大提高了工作效率及准确性。 关键词:Excel;正态分布;函数;统计 引言 正态分布是应用最广泛的连续概率分布,生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。例如,在生产条件不变的情况下,某种产品的张力、抗压强度、口径、长度等指标;同一种生物体的身长、体重等指标;同一种种子的重量;测量同一物体的误差;弹着点沿某一方向的偏差;某个地区的年降水量;以及理想气体分子的速度分量等等。一般来说,如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分
布。从理论上看,正态分布具有很多良好的性质,许多概率分布可以用它来近似;还有一些常用的概率分布是由它直接导出的,例如对数正态分布、t分布、F分布等。在科学研究及数理统计计算过程中,人们往往要通过某本概率统计教材附录中的正态分布表去查找,非常麻烦。若手头有计算机,并安装有Excel软件,就可以利用Excel的NORMSDIST( x )函数进行计算某分位数点的正态分布概率值,或建立一个正态分布表,准确又方便。 1 正态分布及其应用 正态分布(normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布,记为N(μ,σ2)。则其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。因其曲线呈钟形,因此人们又经常称之为钟形曲线。我们通常所说的标准正态分布是μ = 0,σ = 1的正态分布。服从正态分布的随机变量的概率规律为取与μ邻近的值的概
态密度(Density of States,简称DOS) 在DOS结果图里可以查瞧就就是导体还就就是绝缘体还就就是半导体,请问怎么瞧。理论就就是什么?或者哪位老师可以告诉我这方面得知识可以通过学习什么获得。不胜感激。 查瞧就就是导体还就就是绝缘体还就就是半导体,最好还就就是用能带图DOS得话瞧费米能级两侧得能量差 谢希德。复旦版得《固体能带论》一书中有,请参阅!另外到网上或者学校得数据库找找“第一性原理”方面得论文,里面通常会有一些计算分析。下面有一篇可以下载得:ZnO得第一性原理计算 hoffman得《固体与表面》对态密度得理解还就就是很有好处得。 下面这个就就是在版里找得,多瞧瞧吧: 如何分析第一原理得计算结果 用第一原理计算软件开展得工作,分析结果主要就就是从以下三个方面进行定性/定量得讨论:1 ?、电荷密度图(charge density); 2、能带结构(EnergyBand Structure);?3、态密度(Density ofStates,简称DOS)。??电荷密度图就就是以图得形式出现在文章中,非常直观,因此对于一般得入门级研究人员来讲不会有任何得疑问。唯一需要注意得就就就是这种分析得种种衍生形式,比如差分电荷密图(def-ormationchargedensity)与二次差分图(difference chargedensity)等等,加自旋极化得工作还可能有自旋极化电荷密度图(spin-polarizedc harge density)。所谓“差分”就就是指原子组成体系(团簇)之后电荷得重新分布,“二次”就就是指同一个体系化学成分或者几何构型改变之后电荷得重新分布,因此通过这种差分图可以很直观地瞧出体系中个原子得成键情况。通过电荷聚集(accumulation)/损失(depl etion)得具体空间分布,瞧成键得极性强弱;通过某格点附近得电荷分布形状判断成键得轨道(这个主要就就是对d轨道得分析,对于s或者p轨道得形状分析我还没有见过)。分析总电荷密度图得方法类似,不过相对而言,这种图所携带得信息量较小。?能带结构分析现在在各个领域得第一原理计算工作中用得非常普遍了。但就就是因为能带这个概念本身得抽象性,对于能带得分析就就是让初学者最感头痛得地方。关于能带理论本身,我在这篇文章中不想涉及,这里只考虑已得到得能带,如何能从里面瞧出有用得信息。首先当然可以瞧出这个体系就就是金属、半导体还就就是绝缘体。判断得标准就就是瞧费米能级与导带(也即在高对称点附近近似成开口向上得抛物线形状得能带)就就是否相交,若相交,则为金属,否则为半导体或者绝缘体。对于本征半导体,还可以瞧出就就是直接能隙还就就是间接能隙:如果导带得最低点与价带得最高点在同一个k点处,则为直接能隙,否则为间接能隙。在具体工作中,情况要复杂得多,而且各种领域中感兴趣得方面彼此相差很大,分析不可能像上述分析一样直观与普适。不过仍然可以总结出一些经验性得规律来。主要有以下几点: 1) 因为目前得计算大多采用超单胞(supercell)得形式,在一个单胞里有几十个原
一十种概率密度函数 function zhifangtu(x,m) %画数据的直方图,x表示要画的随机数,m表示所要画的条数%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% a=min(x); b=max(x); l=length(x); h=(b-a)/m; %量化x x=x/h; x=ceil(x); w=zeros(1,m); for i=1:l for j=1:m if (x(i)==j) %x(i)落在j的区间上,则w(j)加1 w(j)=w(j)+1; else continue end end end w=w/(h*l); z=a:h:(b-h); bar(z,w); title('直方图') function y=junyun(n) %0-1的均匀分布,n代表数据量,一般要大于1024 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% y=ones(1,n); x=ones(1,n); m=100000; x0=mod(ceil(m*rand(1,1)),m); x0=floor(x0/2); x0=2*x0+1; u=11; x(1)=x0; for i=1:n-1 x(i+1)=u*x(i)+0; x(i+1)=mod(x(i+1),m); x(i)=x(i)/m; end %x(n)单位化
x(n)=x(n)/m; y=x; function y=zhishu(m,n) %指数分布,m表示指数分布的参数,m不能为0.n表示数据量,n一般要大于1024 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% x=junyun(n); for i=1;n if (x(i)==0) x(i)=0.0001; else continue; end end u=log(x); y=-(1/m)*u; function y=ruili(m,n) %瑞利分布,m是瑞利分布的参数,n代表数据量,n一般要大于1024 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% x=junyun(n); for i=1:n if (x(i)==0) x(i)=0.0001; else continue; end end u=(-2)*log(x); y=m*sqrt(u); function y=weibuer(a,b,n) %韦布尔分布,a,b表示参数,b不能为0.n表示数据量,一般要大于1024 %a=1时,是指数分布 %a=2时,是瑞利分布%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% x=junyun(n); for i=1:n if (x(i)==0) x(i)=0.0001; else continue; end
正态分布 第二章 第七节 一、标准正态分布的密度函数 二、标准正态分布的概率计算 三、一般正态分布的密度函数 四、正态分布的概率计算 幻灯片2 正态分布的重要性正态分布是概率论中最重要的分布, 这可以由 以下情形加以说明: ⑴正态分布是自然界及工程技术中最常见的分布 之一, 大量的随机现象都是服从或近似服从正态分布的. 可以证明, 如果一个随机指标受到诸多因素的影响, 但其中任何一个因素都不起决定性作用, 则该随机指标 一定服从或近似服从正态分布. 这些性质是其它 ⑵正态分布有许多良好的性质, 许多分布所不具备的. ⑶正态分布可以作为许多分布的近似分布. 幻灯片3 -标准正态分布 下面我们介绍一种最重要的正态分布 一、标准正态分布的密度函数 若连续型随机变量X的密度函数为 定义 则称X服从标准正态分布, 记为 标准正态分布是一种特别重要的 它的密度函数经常被使用, 分布。 幻灯片4 密度函数的验证 则有 (2)根据反常积分的运算有 可以推出 幻灯片5 标准正态分布的密度函数的性质
,X的密度函数为 则密度函数的性质为: 的图像称为标准正态(高斯)曲线。 幻灯片6 随机变量 由于 由图像可知,阴影面积为概率值。 对同一长度的区间 ,若这区间越靠近 其对应的曲边梯形面积越大。 标准正态分布的分布规律时“中间多,两头少”. 幻灯片7 二、标准正态分布的概率计算 1、分布函数 分布函数为 幻灯片8 2、标准正态分布表 书末附有标准正态分布函数数值表,有了它,可以解决标准正态分布的概率计算. 表中给的是x > 0时, Φ(x)的值. 幻灯片9 如果 由公式得 令 则 幻灯片10 例1 解 幻灯片11 由标准正态分布的查表计算可以求得, 当X~N(0,1)时, 这说明,X 的取值几乎全部集中在[-3,3]区间内,超出这个范围的可能性仅占不到0.3%. 幻灯片12 三、一般正态分布的密度函数 如果连续型随机变量X的密度函数为 (其中 为参数) 的正态分布,记为 则随机变量X服从参数为 所确定的曲线叫 作正态(高斯)曲线. 幻灯片13
固体物理习题 一、 固体电子论基础 1. 已知金属铯的E F =1.55eV ,求每立方厘米的铯晶体中所含的平均电子数。 2. 证明:在T=0K 时,费米能级0 F E 处的能态密度为:0023)(F F E N E N =,式中N 为金属中的自由电子数。 3. 已知绝对零度时银的费米能为5.5eV ,试问在什么温度下,银的电子摩尔比热和晶格摩尔比热相等?(银的德拜温度是210K )。 4. 如果具有bcc 结构的Li 晶体的晶格常数为:5.3=a ?,计算其费 米能(0F E )、费米温度及每个价电子的平均动能。 5. 已知某种具有面心立方结构的金属中自由电子气的费米球半径为:a K F 3120)12(π= ,其中a 为晶格参数,每个原子的原子量为63.5,晶体的质量密度为33/1094.8m kg D ?=,试求:(1)该金属的原 子价?=η(2)eV E F ?0= 6. 写出三维波矢空间自由电子的量子态密度表达式。 7. 费米能随着温度的变化趋势是什么? 8.电子的比热系数、费米能附近电子的能态密度以及电子的有效质量之间的关系是什么? 9.不同的导体之间接触电势差产生的根本原因是什么? 二、 金属的电导理论 1. 已知金属铜的费米能,12.7eV E F =在273K 温度下电阻率cm ?Ω?=-81058.1ρ,求(1)铜中电子的费米速度,(2)平均自由时间τ和平均自由程Λ。 2. 证明对于具有球形费米面的金属,其电导率可以表示为: ()F F F E g v e τσ223 1= 式中e 为电子电量;F v 、F τ为费米面上电子的速度和驰豫时间(或平均自由时间);)(F E g 为费米面附近单位晶体体积的能态密度,因此
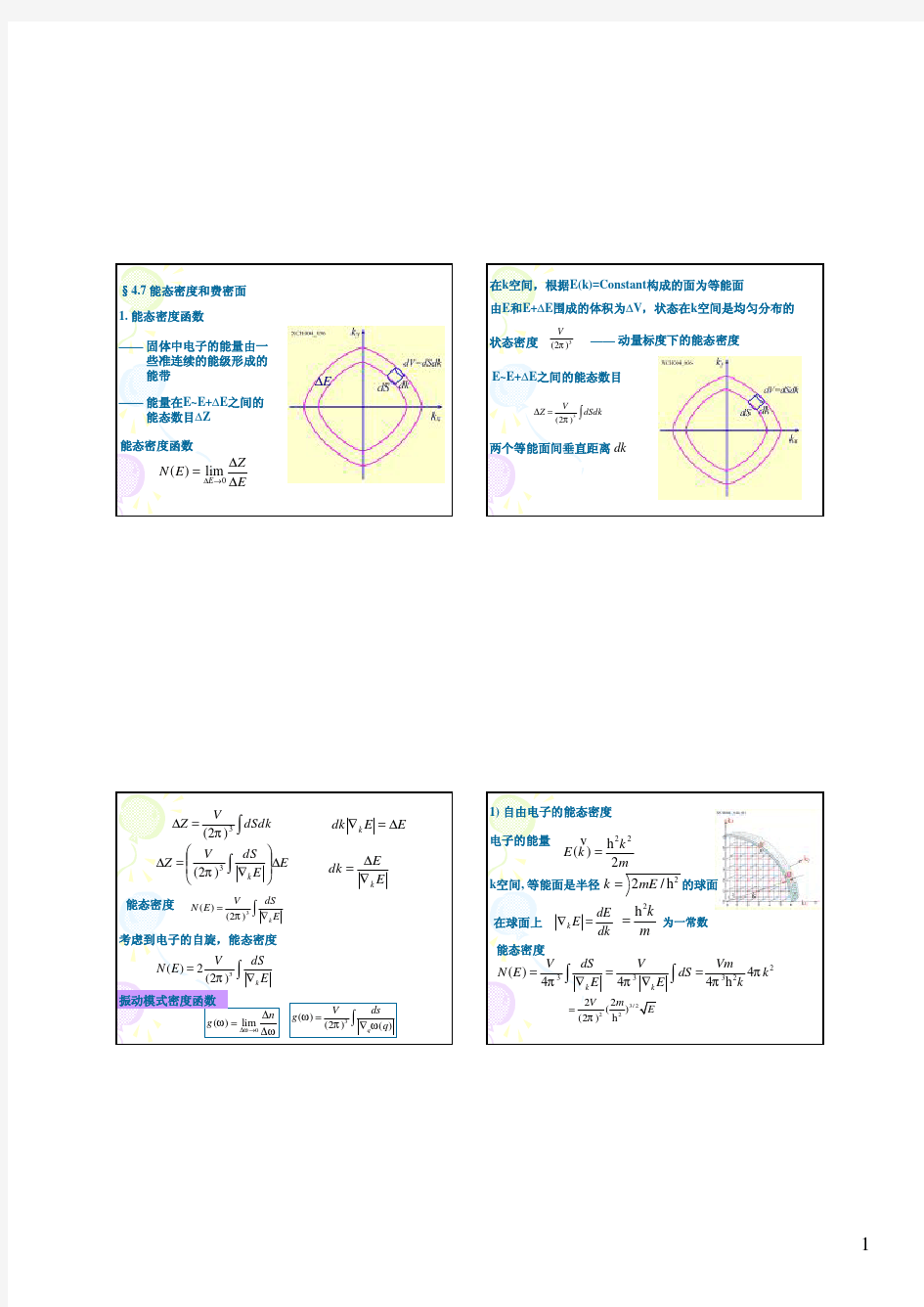
§5-7 晶体中电子的能态密度 5.7.1 带底附近的能态密度 在本章第一节中,我们已经得到自由电子的态密度N (E ), 3 212 22()4m N E V E π??= ??? h ………………………………………… …………………………………(5-7-1) 而且N(E)~E 的关系曲线已由图5-7-1给出。晶体中电子受到周期性势场的作用,其能量E(k )与波矢的关系不再是抛物线性质,因此式(5-7-1)不再适用于晶体中电子。下面以紧束缚理论的简立方结构晶格的s 态电子状态为例,分析晶体中电子态密度的知识。 由前面的紧束缚理论,我们已经得到简立方结构晶格的s 能带的E(k )形式为: ()()012cos cos cos s x y z E J J k a k a k a ε=--++k …………………………………………………(5-7-2) 其中能量极小植在Γ点k =(0, 0, 0)处,其能量为()016s E J J ε=--k ,所以在Γ点附近的能量,可以通过将()E k 展开为在k =0处的泰勒级数而得到,以2 cos 12x x =-+L ,取前两项代入,可以得到: ()()()2222222 2011123()2s x y z s x y z E J J a k k k E J a k k k ε??=---++=Γ-++ ??? k …………………(5-7-3) 在第五节,我们已经根据有效质量的定义,算得简立方晶格s 带Γ点处的有效质量为一个标量, 2 21 *02m a J =>h …………………………………………………………………………………………… (5-7-4) 代入后,可得到 ()22 * ()2s k E E m =Γ+h k …………………………………………………………………………………(5-7-5) 式(5-7-5)表明:在能带底k =0附近,等能面是球面,如果以()()s E E -Γk 及* m 分别代替自由电子的能量E 及质量m ,就可得到晶体中电子在能带底附近的能态密度函数: *312 222()4()[()()]s m N E V E E π=-Γh k ……………………………………………………………(5-7-6) 5.7.2 带顶附近的能态密度 能带顶在(,,)a a a πππ=k 的R 点处,容易知道,其能量为()016s E J J ε=-+k 。以R 点附近的 图5-7-1 自由电子能态密度
数学期望:随机变量最基本的数学特征之一。它反映随机变量平均取值的大小。又称期望或均值。它是简单算术平均的一种推广。例如某城市有10万个家庭,没有孩子的家庭有1000个,有一个孩子的家庭有9万个,有两个孩子的家庭有6000个,有3个孩子的家庭有3000个,则此城市中任一个家庭中孩子的数目是一个随机变量,记为X,它可取值0,1,2,3,其中取0的概率为0.01,取1的概率为0.9,取2的概率为0.06,取3的概率为0.03,它的数学期望为0×0.01+1×0.9+2×0.06+3×0.03等于1.11,即此城市一个家庭平均有小孩1.11个,用数学式子表示为:E(X)=1.11。 也就是说,我们用数学的方法分析了这个概率性的问题,对于每一个家庭,最有可能它家的孩子为1.11个。 可以简单的理解为求一个概率性事件的平均状况。 各种数学分布的方差是: 1、一个完全符合分布的样本 2、这个样本的方差 概率密度的概念是:某种事物发生的概率占总概率(1)的比例,越大就说明密度越大。比如某地某次考试的成绩近似服从均值为80的正态分布,即平均分是80分,由正态分布的图形知x=80时的函数值最大,即随机变量在80附近取值最密集,也即考试成绩在80分左右的人最多。 下图为概率密度函数图(F(x)应为f(x),表示概率密度):
离散型分布:二项分布、泊松分布 连续型分布:指数分布、正态分布、X2分布、t分布、F分布 抽样分布 抽样分布只与自由度,即样本含量(抽样样本含量)有关 二项分布(binomial distribution):例子抛硬币 1、重复试验(n个相同试验,每次试验两种结果,每种结果概率恒定———— 伯努利试验) 2、
能带结构和态密度图的绘制及初步分析 前几天在QQ的群中和大家聊天的时候,发现大家对能带结构和态密度比较感兴趣,我做计算已经有一年半了,有一些经验,这里写出来供大家参考参考,希望能够对初学者有所帮助,另外写的这些内容也不可能全都正确,只希望通过表达出来和大家进行交流,共同提高。 MS这个软件的功能确实是比较强,但是也有一些地方不尽如人意的地方。(也可能是我对一些结果不会分析所致,有些暂时不能解决的问题在最后一部分提出,希望大家来研究 研究,看看有没有实现的可能性)。 能带结构、态密度和布居分析是很重要的内容,在 分析能带结构和态密度的时候,往往是先作图,然后分 析。 软件本身提供的作图功能并不是很强,比如说能带结构 (只能带只能做point图和line图),不美观不说,对于 每一个能带的走势也不好观察,感觉无从下手。所以我 一般用origin作图(右图是用origin做的能带图)。能带 结构和态密度的作图过程请参考我给大家提供的动画。 接下来我们先开看看能带结构的分析和制作! 第一部分:能带结构 这个部分打算先简单的介绍一下能带的基础知识,希望能对大家有所帮助,如果对能带了解比较深入的朋友,可以跳过这个部分内容,之中不当之处请勿见笑。^_^ 第一个问题是: 1、能带是怎样形成——轨道和一维体系的能带。 这是最基本的一个问题,我们要对能带结构进行分析,首先要知道它是如何来的。其实能带是一种近似的结果(可以看成一种近似),是周期边界条件(bloch函数)下的一种近似。先来看看一个最简单的问题,非周期体系有没有能带结构?答案是没有的,大家可以试试: ①建一个周期的晶胞②选择build菜单下的symmetry子菜单下的none periodic superstructure去掉周期边界条件性③看看还能够运行吗?运行(run)按钮变灰了,不能提交作业了。这说明什么问题?这说明这个CASTEP这个模块不能计算非周期的体系,另外可以参考MS中的DMOL模块,它可以计算非周期系统,虽然可以计算周期系统,但是仍不能计算能带,大家可以试试,看看property中的band structure能不能选上,一定不能!!^_^ 从这里,我们可以得到一个结论,对于单个原子(分子、单胞)如果不加上周期边界条件,是无法获得能带结构的。所以计算小分子体系,或者采用团簇模型的朋友,这部分内容或许对你们没有帮助!那么,非周期体系的态密度能够计算吗?这应该是能够计算的,曾经开到过文献采用团簇模型,计算出态密度的(phys. Rev. 上的文章)。 那么非周期体系为什么没有能带结构呢? 看一个例子:一个H2分子有能带吗?没有,因为它没有周期边界条件,也就是说在x,y,z方向上没有重复,所以它没有能带结构。那H2分子有什么东西呢?有两个轨道,两个 1s原子轨道,或者说两个轨道能级,它们成键参考右图。 再看另外一个例子:一维无限H原子链 H H H H H H 在一维无限H原子链体系中,产生了能带。 为什么在一维无限H原子链体系中能够产生能带呢?
目录 1. 均匀分布 (1) 2. 正态分布(高斯分布) (2) 3. 指数分布 (2) 4. Beta分布(:分布) (2) 5. Gamm 分布 (3) 6. 倒Gamm分布 (4) 7. 威布尔分布(Weibull分布、韦伯分布、韦布尔分布) (5) 8. Pareto 分布 (6) 9. Cauchy分布(柯西分布、柯西-洛伦兹分布) (7) 2 10. 分布(卡方分布) (7) 8 11. t分布................................................ 9 12. F分布 ............................................... 10 13. 二项分布............................................ 10 14. 泊松分布(Poisson 分布)............................. 11 15. 对数正态分布........................................
1. 均匀分布 均匀分布X ~U(a,b)是无信息的,可作为无信息变量的先验分布。
2. 正态分布(高斯分布) 当影响一个变量的因素众多,且影响微弱、都不占据主导地位时,这个变量 很可能服从正态分布,记作 X~N (」f 2)。正态分布为方差已知的正态分布 N (*2)的参数」的共轭先验分布。 1 空 f (x ): —— e 2- J2 兀 o' E(X), Var(X) _ c 2 3. 指数分布 指数分布X ~Exp ( )是指要等到一个随机事件发生,需要经历多久时间。其 中,.0为尺度参数。指数分布的无记忆性: Plx s t|X = P{X t}。 f (X )二 y o i E(X) 一 4. Beta 分布(一:分布) f (X )二 E(X) Var(X)= (b-a)2 12 Var(X)二 1 ~2
利用Excel的NORMSDIST函数建立正态 分布表 董大钧,乔莉 沈阳理工大学应用技术学院、信息与控制分院,辽宁抚顺113122 摘要:利用Excel办公软件特有的NORMSDIST函数可以很准确方便的建立正态分布表、查找某分位数点的正态分布概率值,极大的提高了数理统计的效率。该函数可返回指定平均值和标准偏差的正态分布函数,将其引入到统计及数据分析处理过程中,代替原有的手工查找正态分布表,除具有直观、形象、易用等特点外,更增加了动态功能,极大提高了工作效率及准确性。 关键词:Excel;正态分布;函数;统计 引言 正态分布是应用最广泛的连续概率分布,生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。例如,在生产条件不变的情况下,某种产品的张力、抗压强度、口径、长度等指标;同一种生物体的身长、体重等指标;同一种种子的重量;测量同一物体的误差;弹着点沿某一方向的偏差;某个地区的年降水量;以及理想气体分子的速度分量等等。一般来说,如果一个量是由许多微小的独立随机因素影响的结果,那么就可以认为这个量具有正态分布。从理论上看,正态分布具有很多良好的性质,许多概率分布可以用它来近似;还有一些常用的概率分布是由它直接导出的,例如对数正态分布、t分布、F分布等。在科学研究及数理统计计算过程中,人们往往要通过某本概率统计教材附录中的正态分布表去查找,非常麻烦。若手头有计算机,并安装有Excel软件,就可以利用Excel的NORMSDIST( x )函数进行计算某分位数点的正态分布概率值,或建立一个正态分布表,准确又方便。 1 正态分布及其应用 正态分布(normal distribution)又名高斯分布(Gaussian distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布,记为N(μ,σ2 )。则其概率密度
如何分析第一原理的计算结果 用第一原理计算软件开展的工作,分析结果主要是从以下三个方面进行定性/定量的讨论: 1、电荷密度图(charge density); 2、能带结构(Energy Band Structure); 3、态密度(Den sity of States,简称DOS)。 电荷密度图是以图的形式出现在文章中,非常直观,因此对于一般的入门级研究人员来讲不会有任何的疑问。唯一需要注意的就是这种分析的种种衍生形式,比如差分电荷密图(d ef-ormation charge density)和二次差分图(differenee charge density)等等,加自旋极化的工作还可能有自旋极化电荷密度图(spin-polarized charge density)。所谓差分”是指原子组成体系(团簇)之后电荷的重新分布,二次”是指同一个体系化学成分或者几何构型 改变之后电荷的重新分布,因此通过这种差分图可以很直观地看出体系中个原子的成键情况。通过电荷聚集(accumulation)/损失(depletion )的具体空间分布,看成键的极性强弱;通过某格点附近的电荷分布形状判断成键的轨道(这个主要是对d轨道的分析,对于s 或者p轨道的形状分析我还没有见过)。分析总电荷密度图的方法类似,不过相对而言,这种图所携带的信息量较小。 能带结构分析现在在各个领域的第一原理计算工作中用得非常普遍了。但是因为能带这个概念本身的抽象性,对于能带的分析是让初学者最感头痛的地方。关于能带理论本身,我在这篇文章中不想涉及,这里只考虑已得到的能带,如何能从里面看出有用的信息。首先当然可以看出这个体系是金属、半导体还是绝缘体。判断的标准是看费米能级和导带(也即在高对称点附近近似成开口向上的抛物线形状的能带)是否相交,若相交,则为金属,否则
Generated by Foxit PDF Creator ? Foxit Software https://www.doczj.com/doc/c418241360.html, For evaluation only.
图 62正态分布概率密度函数的曲线 正态曲线可用方程式表示。 n 当 →∞时,可由二项分布概率函数方程推导出正态 分布曲线的方程:
fx= (61 ) () .6
式中: x—所研究的变数; fx —某一定值 x出现的函数值,一般称为概率 () 密度函数 (由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某 一区间的概率, 不能计算变量取某一值, 即某一点时的概率, 所以用 “概率密度” 一词以与概率相区分),相当于曲线 x值的纵轴高度; p—常数,等于 31 .4 19……; e— 常数,等于 2788……; μ 为总体参数,是所研究总体 5 .12 的平均数, 不同的正态总体具有不同的 μ , 但对某一定总体的 μ 是一个常数; δ 也为总体参数, 表示所研究总体的标准差, 不同的正态总体具有不同的 δ , 但对某一定总体的 δ 是一个常数。 上述公式表示随机变数 x的分布叫作正态分布, 记作 N μ ,δ2 ), “具 ( 读作 2 平均数为 μ,方差为 δ 的正态分布”。正态分布概率密度函数的曲线叫正态 曲线,形状见图 62。 (二)正态分布的特性
1、正态分布曲线是以 x μ 为对称轴,向左右两侧作对称分布。因 =
的
数值无论正负, 只要其绝对值相等, 代入公式 61 ) ( .6 所得的 fx 是相等的, () 即在平均数 μ 的左方或右方,只要距离相等,其 fx 就相等,因此其分布是 () 对称的。在正态分布下,算术平均数、中位数、众数三者合一位于 μ 点上。
统计学三大分布与正态分布的关系 [1] 张柏林 41060045 理实1002班 摘要:本文首先将介绍2χ分布,t 分布,F 分布和正态分布的定义及基本性质, 然后用理论说明2χ分布,t 分布,F 分布与正态分布的关系,并且利用数学软件MATLAB 来验证之. 1.三大分布函数[2] 1.12χ分布 2()n χ分布是一种连续型随机变量的概率分布。这个分布是由别奈梅(Benayme)、赫尔默特(Helmert)、皮尔逊分别于1858年、1876年、1900年所发现,它是由正态分布派生出来的,主要用于列联表检验。 定义:若随机变量12n ,,X X …X 相互独立,且都来自正态总体01N (,) ,则称统计量222 212n =+X X χ++…X 为服从自由度为n 的2χ分布, 记为22~()n χχ. 2χ分布的概率密度函数为 122210(;),2()200n x n x e x n f x n x --?≥??=Γ???? ,2χ分布的密度函数图形是一个只取非负值的偏态分布,如下图.
卡方分布具有如下基本性质: 性质1:22(()),(())2E n n D n n χχ==; 性质2:若221122(),()X n X n χχ==,12,X X 相互独立,则21212~()X X n n χ++; 性质3:2 n χ→∞→时,( n )正态分布; 性质4:设)(~2 2n α χχ,对给定的实数),10(<<αα称满足条 件:αχχα χα ==>?+∞ ) (2 22)()}({n dx x f n P 的点)(2 n α χ为)(2n χ分布的水平α的上侧分位数. 简称为上侧α分位数. 对不同的α与n , 分位数的值已经编制成表供查 用. 2()n χ分布的上α分位数 1.2t 分布 t 分布也称为学生分布,是由英国统计学家戈赛特在1908年“student ”的笔名 首次发表的,这个分布在数理统计中也占有重要的位置. 定义:设2 ~0~X N χ(,1),Y (n ),,X Y 相互独立,,则称统计量/T Y n = 服从自由度为n 的t 分布,记为~()T t n .
态密度计算 态密度:表示单位能量范围内所允许的电子数,也就是说电子在某一能量范围的分布情况。因为原子轨道主要是以能量的高低去划分的,所以态密度图能反映出电子在各个轨道的分布情况,反映出原子与原子之间的相互作用情况,并且还可以揭示化学键的信息。态密度有分波态密度(PDOS)和总态密度(TDOS)形式。 原则上讲,态密度可以作为能带结构的一个可视化结果。很多分析和能带的分析结果可以一一对应,很多术语也和能带分析相通。但是因为它更直观,因此在结果讨论中用得比能带分析更广泛一些。 计算过程:主要分成三步:一、结构优化;二、静态自洽计算;三、非自洽计算。 1,结构优化:原子弛豫,确定体系内每个原子位置。常用INCAR。2,静态自洽计算:(得到自洽的电荷密度CHG、CHGCAR和E-fermi,提供给下一步非自洽计算用) INCAR设置注意,ICHARG = 2 3,非自洽计算(准确计算电荷分布) INCAR设置:ISTART=1(若存在WAVECAR文件时取1);ICHARG=11(表示从CHGCAR中读入电荷分布,并且在计算中保持不变);RWIGS (或LORBIT=11(或10),这时可不设RWIGS); 计算完成时,生成DOSCAR,采用spit_dos.dl小程序把dos分开(注意vp.dl要拷到同目录下),会生成N+1个文件,DOS0为总态密度,DOS1到DOSN为N个原子的分态密度。每个分态密度共7列分布为
—能量→Sup→Sdown→Pup→Pdown→Dup→Ddown 不知道从态密度能否定性分析出来,因为态密度越尖,则电子的局域性越强, 修正版的splitdos有三个文件:vp、sumdos和split_dos.ksh INCAR设置: ISTART = 1;ICHARG = 11 LORBIT = 10 【对于PAW势,可设置LORBIT = 10,此时可不用设置RWIGS参数】或者设置RWIGS参照POTCAR
图 6-2 正态分布概率密度函数的曲线 正态曲线可用方程式表示。当n→∞时,可由二项分布概率函数方程推导出正态分布曲线的方程: f(x)= (6.16 ) 式中: x —所研究的变数; f(x) —某一定值 x 出现的函数值,一般称为概率密度函数(由于间断性分布已转变成连续性分布,因而我们只能计算变量落在某一区间的概率,不能计算变量取某一值,即某一点时的概率,所以用“概率密度”一词以与概率相区分),相当于曲线 x 值的纵轴高度; p —常数,等于 3.14 159 ……; e —常数,等于 2.71828 ……;μ为总体参数,是所研究总体的平均数,不同的正态总体具有不同的μ,但对某一定总体的μ是一个常数;δ也为总体参数,表示所研究总体的标准差,不同的正态总体具有不同的δ,但对某一定总体的δ是一个常数。 上述公式表示随机变数 x 的分布叫作正态分布,记作 N( μ , δ2 ) ,读作“具平均数为μ,方差为δ 2 的正态分布”。正态分布概率密度函数的曲线叫正态曲线,形状见图 6-2 。 (二)正态分布的特性 1 、正态分布曲线是以 x= μ为对称轴,向左右两侧作对称分布。因的数值无论正负,只要其绝对值相等,代入公式( 6.16 )所得的 f(x) 是相等的,即在平均数μ的左方或右方,只要距离相等,其 f(x) 就相等,因此其分布是对称的。在正态分布下,算术平均数、中位数、众数三者合一位于μ点上。
2 、正态分布曲线有一个高峰。随机变数 x 的取值范围为( - ∞,+ ∞ ),在( - ∞ ,μ)正态曲线随 x 的增大而上升,;当 x= μ时, f(x) 最大;在(μ,+ ∞ )曲线随 x 的增大而下降。 3 、正态曲线在︱x-μ︱=1 δ处有拐点。曲线向左右两侧伸展,当x →± ∞ 时,f(x) →0 ,但 f(x) 值恒不等于零,曲线是以 x 轴为渐进线,所以曲线全距从 -∞到+ ∞。 4 、正态曲线是由μ和δ两个参数来确定的,其中μ确定曲线在 x 轴上的位置 [ 图 6-3] ,δ确定它的变异程度 [ 图 6-4] 。μ和δ不同时,就会有不同的曲线位置和变异程度。所以,正态分布曲线不只是一条曲线,而是一系列曲线。任何一条特定的正态曲线只有在其μ和δ确定以后才能确定。 5 、正态分布曲线是二项分布的极限曲线,二项分布的总概率等于 1 ,正态分布与 x 轴之间的总概率(所研究总体的全部变量出现的概率总和)或总面积也应该是等于 1 。而变量 x 出现在任两个定值 x1到x2(x1≠x2)之间的概率,等于这两个定值之间的面积占总面积的成数或百分比。正态曲线的任何两个定值间的概率或面积,完全由曲线的μ和δ确定。常用的理论面积或概率如下: 区间μ ± 1 δ面积或概率 =0.6826 μ ± 2 δ =0.9545 μ ± 3 δ=0.9973 μ± 1.960δ=0.9500 μ ±2.576 δ =0.9900
目录 1.均匀分布 (1) 2.正态分布(高斯分布) (2) 3.指数分布 (2) 4.Beta分布(β分布) (2) 5.Gamma分布 (3) 6.倒Gamma分布 (4) 7.威布尔分布(Weibull分布、韦伯分布、韦布尔分布) (5) 8.Pareto分布 (6) 9.Cauchy分布(柯西分布、柯西-洛伦兹分布) (7) χ分布(卡方分布) (7) 10.2 11.t分布 (8) 12.F分布 (9) 13.二项分布 (10) 14.泊松分布(Poisson分布) (10) 15.对数正态分布 (11) 1.均匀分布 均匀分布~(,) X U a b是无信息的,可作为无信息变量的先验分布。
1()f x b a = - ()2 a b E X += 2 ()()12 b a Var X -= 2. 正态分布(高斯分布) 当影响一个变量的因素众多,且影响微弱、都不占据主导地位时,这个变量很可能服从正态分布,记作2~(,)X N μσ。正态分布为方差已知的正态分布 2(,)N μσ的参数μ的共轭先验分布。 22 ()2()x f x μσ-- = ()E X μ= 2()Var X σ= 3. 指数分布 指数分布~()X Exp λ是指要等到一个随机事件发生,需要经历多久时间。其中0λ>为尺度参数。指数分布的无记忆性:{}|{}P X s t X s P X t >+>=>。 (),0 x f x e x λλ-=> 1 ()E X λ = 2 1 ()Var X λ = 4. Beta 分布(β分布)
Beta 分布记为~(,)X Be a b ,其中Beta(1,1)等于均匀分布,其概率密度函数可凸也可凹。如果二项分布(,)B n p 中的参数p 的先验分布取(,)Beta a b ,实验数据(事件A 发生y 次,非事件A 发生n-y 次),则p 的后验分布(,)Beta a y b n y ++-,即Beta 分布为二项分布(,)B n p 的参数p 的共轭先验分布。 10 ()x t x t e dt ∞--Γ=? 1 1()()(1)()() a b a b f x x x a b --Γ+= -ΓΓ ()a E X a b = + 2 ()()(1) ab Var X a b a b = +++ 5. Gamma 分布 Gamma 分布即为多个独立且相同分布的指数分布变量的和的分布,解决的
4 3 2 1 -1 -4 -2 2 4 2 1专题:正态分布 例:(1)已知随机变量X 服从二项分布,且E (X )=2.4,V (X )=1.44,则二项分布的参数n ,p 的值为 A .n=4,p=0.6 B .n=6,p=0.4 C .n=8,p=0.3 D .n=24,p=0.1 答案:B 。解析:()4.2==np X E ,()44.1)1(=-=p np X V 。 (2)正态曲线下、横轴上,从均数到∞+的面积为( )。 A .95% B .50% C .97.5% D .不能确定(与标准差的大小有关) 答案:B 。解析:由正态曲线的特点知。 (3)某班有48名同学,一次考试后的数学成绩服从正态分布,平均分为80,标准差为10,理论上说在80分到90分的人数是 ( ) A 32 B 16 C 8 D 20 答案:B 。解析:数学成绩是X —N(80,102), 8080 9080(8090)(01)0.3413,480.34131610 10P X P Z P Z --??≤≤=≤≤=≤≤≈?≈ ???。 (4)从1,2,3,4,5这五个数中任取两个数,这两个数之积的数学期望为___________ 。 答案:8.5。解析:设两数之积为X , X 2 3 4 5 6 8 10 12 15 20 P 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1 0.1 ∴E(X)=8.5. (5)如图,两个正态分布曲线图: 1为)(1 ,1x σμ?,2为)(22x σμ?, 则1μ 2μ,1σ 2σ(填大于,小于) 答案:<,>。解析:由正态密度曲线图象的特征知。 【课内练习】 1.标准正态分布的均数与标准差分别为( )。 A .0与1 B .1与0 C .0与0 D .1与1 答案:A 。解析:由标准正态分布的定义知。 2.正态分布有两个参数μ与σ,( )相应的正态曲线的形状越扁平。 A .μ越大 B .μ越小 C .σ越大 D .σ越小 答案: C 。解析:由正态密度曲线图象的特征知。 3.已在n 个数据n x x x ,,,21 ,那么() ∑=-n i i x x n 1 21是指 A .σ B .μ C .2σ D .2 μ( ) 答案:C 。解析:由方差的统计定义知。 4.设),(~p n B ξ,()12=ξE ,()4D ξ=,则n 的值是 。 答案:4。解析:()12==np E ξ,()(1)4D np p ξ=-= 5.对某个数学题,甲解出的概率为2 3 ,乙解出的概率为34,两人独立解题。记X 为解出该题的人数,则E (X )= 。 答案:1712。解析:11121145(0),(1),3412343412 P X P X ==?===?+?=231 (2)342P X ==?=。
正态分布的概率密度函数的推导 An interesting question was posed in a Statistics assignment which was to show that the standard normal distribution was valid - ie the integral from negative infinity to infinity equated to one and in doing so showed the derivation of the part of the normal pdf. A friend of mine and I decided to try to derive the normal pdf and the thinking went along the lines of the central limit theorem which states that the mean of any probability distribution becomes normal as the number of trials increases. The derivation of this is well known.but we asked ourselves how the normal distribution was first achieved.There is another 'normal' derivation which is the binomial approximation and it is through this direction that we wondered how to derive the normal distribution from the binomial as n gets large. So the general approach we will take is to take a binomial distribution, then increase the number of samples n. (提出一个有趣的问题是在统计分配,这是表明,标准正态分布是有效的- 即从负无穷到正无穷的积分等同于一个,并在这样做表明推导了部分正常的PDF 。 我,我的一个朋友决定尝试推导出正常的PDF和沿中心极限定理指出,任何概率分布的均值作为试验增加的正常思维。 这个推导是众所周知的。但我们问自己如何正态分布首次实现。有另一种“正常”的推导,这是二项式近似和它是通过这个方向,我们想知道如何从二项式正态分布为n变大。 因此,我们将采取的一般方法是一个二项分布,再增加样本N.的数量)