新版时间序列习题(含答案)-新版.pdf
- 格式:pdf
- 大小:55.31 KB
- 文档页数:7


《时间序列》练习题及解答一、单项选择题从下列各题所给的4个备选答案中选出1个正确答案,并将其编号(A、B、C、D)填入题干后面的括号内。
1、构成时间数列的两个基本要素是()。
A、主词和宾词B、变量和次数C、时间和指标数值D、时间和次数2、最基本的时间数列是()。
A、时点数列B、绝对数数列C、相对数数列D、平均数数列3、时间数列中,各项指标数值可以相加的是()。
A、相对数数列B、时期数列C、平均数数列D、时点数列4、时间数列中的发展水平()。
A、只能是总量指标B、只能是相对指标C、只能是平均指标D、上述三种指标均可以5、对时间数列进行动态分析的基础指标是()。
A、发展水平B、平均发展水平C、发展速度D、平均发展速度6、由间断时点数列计算序时平均数,其假定条件是研究现象在相邻两个时点之间的变动为()。
A、连续的B、间断的C、稳定的D、均匀的7、序时平均数与一般平均数的共同点是()。
A、两者均是反映同一总体的一般水平B、都是反映现象的一般水平C、两者均可消除现象波动的影响D、共同反映同质总体在不同时间上的一般水平8、时间序列最基本的速度指标是()。
A、发展速度B、平均发展速度C、增长速度D、平均增长速度9、根据采用的对比基期不同,发展速度有()。
A、环比发展速度与定基发展速度B、环比发展速度与累积发展速度C、逐期发展速度与累积发展速度D、累积发展速度与定基发展速度10、如果时间序列逐期增长量大体相等,则宜配合()。
A、直线模型B、抛物线模型C、曲线模型D、指数曲线模型11、某商场第二季度商品零售额资料如下:A、100%124%104%108.6%3++=B、506278108.6% 506278100%124%104%++=++C、506278100%124%104%92.1% 506278++=++D、50100%62124%78104%109.5%506278⨯+⨯+⨯=++12、增长速度的计算公式为()。

计算题:34323*22562584*22582603*22602502*2250254++++++++++=a = (人计算(1)第一季度该店平均每月商品销售额(2)第一季度平均销售员人数(3)第一季度平均每个销售员的销售额 (4)第一季度平均每月每个销售员的销售额 解:(1)商品销售额为时期总量指标时间序列,4月不属一季度,该数据无用3280350300++=a = (万元)(2) 销售员人数是时点总量指标时间序列,间断间隔相等,用首尾折半法,4月初人数相当于3月末人数,这个数据有用32424045240+++=b = (人) (3)32424045240280350300+++++==平均人数一季度销售额c = (万元/人) (4)3324240452403028350300c d =+++++==平均人数一季度月平均销售额 = (万元/人)要求:(1)根据表中资料 ,计算并填制表中空白栏指标(2)计算该地财政收入的这几年的年平均发展水平、年平均增长水平(水平法)和平均增长速度(几何平均法)(3)超过平均增长速度的年份有哪些年?解:注意平均时项数的确定,写计量单位,我以下省略了单位1430%02.193*430116430%02.193*4307%02.193*4304554301)26n 0010-=-=-='-=-=∆+++=+++=a a V V n a a n a a a a n n n ((3)填全表中各年的环比增长速度,和年平均增长速度进行比较即可4. 某地1980~1990年间(以1979年为基期:a0),地区生产总值以平均 每年25%的速度增长(平均增长速度),而1991~2000年间地区生产总值以平均每年30%的速度增长(平均增长速度),2001~2012年间地区生产总值以平均每年18%的速度增长,则1980~2012年间,该地区的生产总值平均每年的增长速度是多少?(重点:正确确定时间段长短)解:注意是以1979年为基期,经过33年发展到2012年,求这段时间的平均增长速度1%118*%130*%125133121011-=-='V V5. 某地1980年的人口是120万人,1981~2000年间人口平均增长率为1.2%,之后下降到1%,按此增长率到2008年人口会达到多少?如果要求到2012年人口控制在170万以内,则2008年以后人口的增长速度应控制在什么范围内? 解:1)2(%101*%2.101*)140812*******-='==V V V a a a a ((1)分别用最小平方法的普通法和简捷法配合直线方程,并预测2010年该企业产值 (2)比较两种方法得出的结果有无异同。
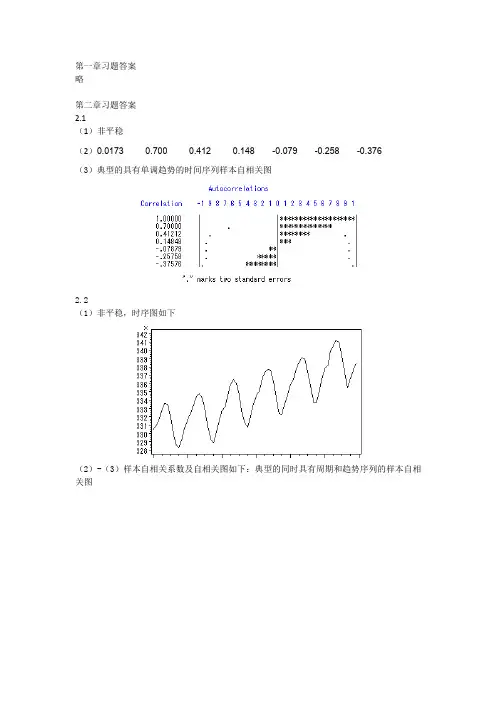
第一章习题答案略第二章习题答案2.1(1)非平稳(2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376(3)典型的具有单调趋势的时间序列样本自相关图2.2(1)非平稳,时序图如下(2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图2.3(1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118(2)平稳序列(3)白噪声序列2.4,序列LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。
显著性水平=0.05不能视为纯随机序列。
2.5(1)时序图与样本自相关图如下(2) 非平稳 (3)非纯随机 2.6(1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机第三章习题答案3.1 ()0t E x =,21() 1.9610.7t Var x ==-,220.70.49ρ==,220φ= 3.2 1715φ=,2115φ=3.3 ()0t E x =,10.15() 1.98(10.15)(10.80.15)(10.80.15)t Var x +==--+++10.80.7010.15ρ==+,210.80.150.41ρρ=-=,3210.80.150.22ρρρ=-=1110.70φρ==,2220.15φφ==-,330φ=3.4 10c -<<, 1121,1,2k k k c c k ρρρρ--⎧=⎪-⎨⎪=+≥⎩3.5 证明:该序列的特征方程为:32--c 0c λλλ+=,解该特征方程得三个特征根:11λ=,2c λ=3c λ=-无论c 取什么值,该方程都有一个特征根在单位圆上,所以该序列一定是非平稳序列。

第八章时间数列分析一、单项选择题1. 时间序列与变量数列()A都是根据时间顺序排列的B都是根据变量值大小排列的C前者是根据时间顺序排列的,后者是根据变量值大小排列的D前者是根据变量值大小排列的,后者是根据时间顺序排列的C2.时间序列中,数值大小与时间长短有直接关系的是()A平均数时间序列B3.发展速度属于(A比例相对数B时期序列C时点序列D相对数时间序列)B比较相对数C动态相对数D强度相对数C4. 计算发展速度的分母是()A报告期水平B基期水平C实际水平D计划水平B5. 某车间月初工人人数资料如下:则该车间上半年的平均人数约为()A 296 人B 292 人C 295 人D 300 人C6. 某地区某年9月末的人口数为150万人,10月末的人口数为150. 2万人,该地区10月的人口平均数为()A 150万人B 150 . 2万人C 150 . 1万人D 无法确定C7. 由一个9项的时间序列可以计算的环比发展速度()A有8个B有9个C有10个D有7个A8. 采用几何平均法计算平均发展速度的依据是()A各年环比发展速度之积等于总速度B各年环比发展速度之和等于总速度C各年环比增长速度之积等于总速度D各年环比增长速度之和等于总速度A9. 某企业的科技投入,2010年比2005年增长了58. 6%,则该企业2006—2010年间科技投入的平均发展速度为()A 558.6%B 5158.6%C 658.6%D 6158.6%B10. 根据牧区每个月初的牲畜存栏数计算全牧区半年的牲畜平均存栏数,采用的公式是()A简单平均法B几何平均法C加权序时平均法D首末折半法D11. 在测定长期趋势的方法中,可以形成数学模型的是()A时距扩大法B移动平均法C最小平方法D季节指数法12. 动态数列中,每个指标数值相加有意义的是( )。
A. 时期数列B. 时点数列C. 相对数数列D. 平均数数列 A13. 按几何平均法计算的平均发展速度侧重于考察现象的( ) A. 期末发展水平 B. 期初发展水平 C •中间各项发展水平D.整个时期各发展水平的总和14. 累计增长量与其相应的各逐期增长量的关系表现为( )A. 累计增长量等于相应各逐期增长量之和 B •累计增长量等于相应各逐期增长量之差 C. 累计增长量等于相应各逐期增长量之积 D. 累计增长量等于相应各逐期增长量之商 A15. 已知某地区 2010 年的粮食产量比 2000 年增长了 1 倍,比 2005 年增长了 0.5 倍,那么 2005 年粮食产量比 2000 年增长了( )。

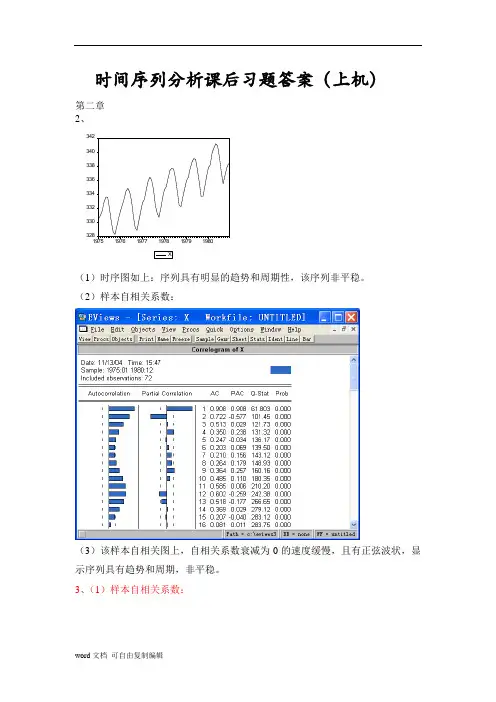
时间序列分析课后习题答案(上机)第二章2、342340338336334332330328197519761977197819791980X(1)时序图如上:序列具有明显的趋势和周期性,该序列非平稳。
(2)样本自相关系数:(3)该样本自相关图上,自相关系数衰减为0的速度缓慢,且有正弦波状,显示序列具有趋势和周期,非平稳。
3、(1)样本自相关系数:(2)序列平稳。
(3)因Q统计量对应的概率均大于0.05,故接受该序列为白噪声的假设,即序列为村随机序列。
5、(1)时序图和样本自相关图:3503002502001501005000:0100:0701:0101:0702:0102:0703:0103:07X(2)序列具有明显的周期性,非平稳。
(3)序列的Q统计量对应的概率均小于0.05,该序列是非白噪声的。
6、(1)根据样本相关图可知:该序列是非平稳,非白噪声的。
(2)对该序列进行差分运算:1--=t t t x x y {t y }的样本相关图:该序列平稳,非白噪声。
第三章:17、(1)结论:序列平稳,非白噪声。
(2)拟合MA(2) model:Variable Coefficient Std. Error t-Statistic Prob.C 80.40568 4.630308 17.36508 0.0000MA(1) 0.336783 0.114610 2.938519 0.0047MA(2) 0.343877 0.116874 2.942297 0.0046 R-squared 0.171979 Mean dependent var 80.29524 Adjusted R-squared 0.144379 S.D. dependent var 23.71981 S.E. of regression 21.94078 Akaike info criterion 9.061019 Sum squared resid 28883.87 Schwarz criterion 9.163073 Log likelihood -282.4221 F-statistic 6.230976 Durbin-Watson stat 2.072640 Prob(F-statistic) 0.003477 Inverted MA Roots -.17+.56i -.17 -.56iResidual tests(3)拟合AR(2)model:Variable Coefficient Std. Error t-Statistic Prob.C 79.71956 5.442613 14.64729 0.0000AR(1) 0.258624 0.128810 2.007794 0.0493AR(2) 0.227469 0.125114 1.818102 0.0742 R-squared 0.154672 Mean dependent var 79.50492 Adjusted R-squared 0.125522 S.D. dependent var 23.35053 S.E. of regression 21.83590 Akaike info criterion 9.052918 Sum squared resid 27654.79 Schwarz criterion 9.156731 Log likelihood -273.1140 F-statistic 5.306195 Durbin-Watson stat 1.939572 Prob(F-statistic) 0.007651 Inverted AR Roots .62 -.36Residual tests:(4) 拟合ARMA(2,1)model:Variable Coefficient Std. Error t-Statistic Prob.C 79.17503 4.082908 19.39183 0.0000AR(1) -0.586834 0.118000 -4.973170 0.0000AR(2) 0.376120 0.082091 4.581756 0.0000R-squared 0.338419 Mean dependent var 79.50492 Adjusted R-squared 0.303599 S.D. dependent var 23.35053 S.E. of regression 19.48617 Akaike info criterion 8.840611 Sum squared resid 21643.51 Schwarz criterion 8.979029 Log likelihood -265.6386 F-statistic 9.719104Durbin-Watson stat 1.963688 Prob(F-statistic) 0.000028 Inverted AR Roots .39 -.97Inverted MA Roots -1.11Estimated MA process is noninvertible残差检验:(5)拟合ARMA(1,(2))model:C 79.52100 4.621910 17.20523 0.0000AR(1) 0.270506 0.125606 2.153603 0.0354R-squared 0.157273 Mean dependent var 79.55161 Adjusted R-squared 0.128706 S.D. dependent var 23.16126 S.E. of regression 21.61946 Akaike info criterion 9.032242 Sum squared resid 27576.65 Schwarz criterion 9.135167 Log likelihood -276.9995 F-statistic 5.505386Inverted AR Roots .27残差检验:(6)优化model AIC SCMA(2) 9.06109.1631AR(2) 9.05299.1567ARMA(2,1) 8.84068.9790ARMA(1,(2)) 9.03229.1352根据SC准则,最优模型为ARMA(2,1)模型。
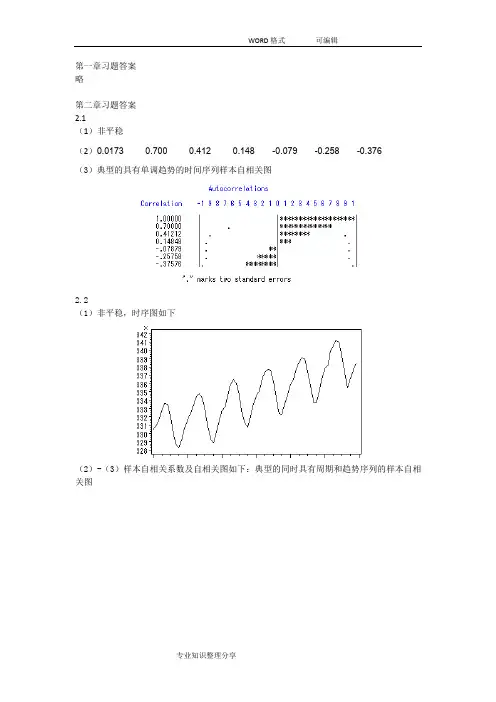
第一章习题答案略第二章习题答案2.1(1)非平稳(2)0.0173 0.700 0.412 0.148 -0.079 -0.258 -0.376(3)典型的具有单调趋势的时间序列样本自相关图2.2(1)非平稳,时序图如下(2)-(3)样本自相关系数及自相关图如下:典型的同时具有周期和趋势序列的样本自相关图2.3(1)自相关系数为:0.2023 0.013 0.042 -0.043 -0.179 -0.251 -0.094 0.0248 -0.068 -0.072 0.014 0.109 0.217 0.316 0.0070 -0.025 0.075 -0.141 -0.204 -0.245 0.066 0.0062 -0.139 -0.034 0.206 -0.010 0.080 0.118(2)平稳序列(3)白噪声序列2.4,序列LB=4.83,LB统计量对应的分位点为0.9634,P值为0.0363。
显著性水平=0.05不能视为纯随机序列。
2.5(1)时序图与样本自相关图如下(2) 非平稳 (3)非纯随机 2.6(1)平稳,非纯随机序列(拟合模型参考:ARMA(1,2)) (2)差分序列平稳,非纯随机第三章习题答案3.1 ()0t E x =,21() 1.9610.7t Var x ==-,220.70.49ρ==,220φ= 3.2 1715φ=,2115φ=3.3 ()0t E x =,10.15() 1.98(10.15)(10.80.15)(10.80.15)t Var x +==--+++10.80.7010.15ρ==+,210.80.150.41ρρ=-=,3210.80.150.22ρρρ=-=1110.70φρ==,2220.15φφ==-,330φ=3.4 10c -<<, 1121,1,2k k k c c k ρρρρ--⎧=⎪-⎨⎪=+≥⎩3.5 证明:该序列的特征方程为:32--c 0c λλλ+=,解该特征方程得三个特征根:11λ=,2c λ=3c λ=-无论c 取什么值,该方程都有一个特征根在单位圆上,所以该序列一定是非平稳序列。

时间序列分析习题答案时间序列分析习题答案时间序列分析是一种广泛应用于统计学和经济学领域的方法,用于研究随时间变化的数据。
通过对时间序列数据的建模和分析,我们可以揭示数据背后的规律和趋势,从而进行预测和决策。
下面我将给出一些时间序列分析习题的答案,希望能对大家的学习和理解有所帮助。
1. 什么是时间序列?时间序列是按照时间顺序排列的一系列数据观测值。
它可以是连续的,比如每天的股票价格,也可以是离散的,比如每个月的销售额。
时间序列分析的目标是通过对这些数据的分析和建模,揭示数据背后的规律和趋势。
2. 时间序列分析的步骤是什么?时间序列分析一般包括以下几个步骤:- 数据收集:收集并整理时间序列数据,确保数据的准确性和完整性。
- 数据可视化:通过绘制时间序列图,观察数据的趋势、季节性和周期性等特征。
- 数据平稳性检验:通过统计检验方法,判断时间序列数据是否平稳。
如果不平稳,需要进行差分处理。
- 模型选择:根据数据的特征和目标,选择适合的时间序列模型,比如ARIMA模型、季节性ARIMA模型等。
- 模型拟合:利用选定的模型,对时间序列数据进行拟合和参数估计。
- 模型诊断:对拟合的模型进行诊断,检验模型的残差序列是否符合模型假设。
- 模型预测:利用已拟合的模型,对未来的数据进行预测。
3. 如何判断时间序列数据的平稳性?平稳性是时间序列分析的基本假设之一,它要求时间序列的均值、方差和自相关函数在时间上都是常数。
常用的平稳性检验方法有:- 绘制时间序列图:观察数据是否具有明显的趋势、季节性和周期性。
- 平稳性统计检验:常用的统计检验方法有ADF检验、KPSS检验等。
这些检验方法的原理是基于单位根检验,判断序列是否存在单位根,从而判断序列的平稳性。
4. 如何选择适合的时间序列模型?选择适合的时间序列模型需要考虑数据的特征和目标。
常用的时间序列模型有:- AR模型:自回归模型,利用过去的观测值对当前值进行预测。
- MA模型:移动平均模型,利用过去的白噪声误差对当前值进行预测。

时间序列分析习题与答案单选题:b日寸冋序列与变童数列()A都是根据时间顺序排列的B都是根据变量值大<1曲E列的C前者是根据时间顺序排列的,后者是根据变量值大小排列的D前者是根据变量值大小排列的,后者是根据时间顺序排列的2. 时间序列中,数值犬小与时间长短有直接关系的是()A平均数时间序列B时期序列C时点序D相对数时间序3. 发展速度属于〔)A比例相对数B比较相对数C动态相叉擞D强度相艮擞4. 计算发展速度的分母是()為报告期水平B基朗水平C实际水平D计划水平则该车间上半年的平均人数约为()A 2先人B 292人C295人 D 300人6. 某地区某年9月末的人□数为1刃万人,10月末的人口数为150, 2万人,该地区10月的人口平均数为()A150万人B150- 2万人C150- 1万人D无法确定7. 由一个9项的时间序列可以计算的环比发展逸度()A有8个B有9个C有10个D有了个&采用几何平均法计算平均发展速度的腹据是()A各年环比发展速度之积等于总速度B各年环比发展速度之和等于总速度C各年环比増长速度之积等干总速度D各年环比增长速度之和等干总速度9.某企业的科技投3,2000年比1995年増长了58. 6%,贝腹企业1996~2000年间科技投入的平均发展速度为])A 讥&6%B V15&6%C V5S-6%D 化&6%10.在测走长期趋势的方袪中.可以形成数学模型的是()A时距扩大搓B移动平均铉C最小平方袪D季节指数法1,C 2. B 3. C 4. B 5,C 6. C 7. A 8. A 9. B10. C判断题I, 时问洋列中的发展水平都是统计绝対数"(}2一相対数时闾序列屮的数值相加没村实阴意义.()3”由两个时期序列的对应项相对比而产生的新序列仍然足时期序列亠()4. 由丁-时点序列和时期序列都是绝对数时问序列,所以,它们的特点是相同的「()5•时期序列有连续时期序列和间斯时期序列两种■.()氣发展速度可以为负值。

时间序列分析习题解答(2):上课展⽰的典型题由于本答案由少部分⼈完成,难免存在错误,如有不同意见欢迎在评论区提出。
第⼀题⼀、已知零均值平稳序列{X t}的⾃协⽅差函数为γ0=1,γ±1=ρ,γk=0,|k|≥2.计算{X t}的偏相关系数a1,1,a2,2。
计算最佳线性预测L(X3|X2),L(X3|X2,X1)。
计算预测的均⽅误差E[X3−L(X3|X2)]2,E[X3−L(X3|X2,X1)]2。
证明:ρ应满⾜|ρ|≤1 2。
若ρ=0.4,计算{X t}的谱密度函数,给出{X t}所满⾜的模型。
解:(1)由Yule-Walker⽅程,a1,1=γ1/γ0=ρ,1ρρ1a2,1a2,2=ρ,解得a2,2=−ρ2 1−ρ2.(2)由预测⽅程,有L(X3|X2)=ρX2。
设L(X3|X2,X1)=a2X2+a1X1,则1ρρ1a1a2=ρ,a1=−ρ21−ρ2,a2=ρ1−ρ2.所以L(X3|X2,X1)=−ρ2X1+ρX21−ρ2.(3)预测的均⽅误差是E(X3−ρX2)2=(1+ρ2)γ0−2ργ1=1−ρ2,E X3−−ρ2X1+ρX21−ρ22=(1−ρ2)2+ρ4+ρ2(1−ρ2)2−2ρρ3+ρ(1−ρ2)(1−ρ2)2 =2ρ4−3ρ2+1(1−ρ2)2=1−2ρ21−ρ2.(4)由于{X t}的⾃协⽅差函数1后截尾,所以它是⼀个MA(1)模型,即存在b≤1,⽩噪声εt∼WN(0,σ2)使得X t=εt+bεt−1.于是γ0=(1+b2)σ2=1,γ1=bσ2=ρ,所以ρ(b)=b1+b2,在b∈[−1,1]上ρ(b)是单调的,所以−12≤ρ(−1)≤ρ≤ρ(1)=12.(5)由谱密度反演公式,容易得到[][][][][][]()[][]Processing math: 49%f(λ)=12π[1+0.8cosλ]=12π451+cosλ+14=(2/√5)22π1+12(e iλ)2.所以X t=εt+12εt−1,{εt}∼WN0,45.第⼆题⼆、设零均值平稳序列{X t}的⾃协⽅差函数满⾜γk=187×25|k|,k≠0,k∈Z.当γ0取何值时,该序列为AR(1)序列?说明理由并给出相应的模型。
第六章动态数列-、判斷题若将某地区社会商品库存额按时间先后顺序排列,此种动态数二、1.列属于时期数列。
()定基发展速度反映了现象在一定时期内发展的总速度,环比发三、2.展速度反映了现象比前一期的增长程度。
()平均增长速度不是根据各期环比增长速度直接求得的,而是根四、3.据平均发展速度计算的。
()•用水平法计算的平均发展速度只取决于最初发展水平和最末发五、4展水平,与中间各期发展水平无关。
()平均发展速度是环比发展速度的平均数,也是一种序时平均六、5.数。
()1> X 2、X 3、J 4、V 5. Vo七、单项选择题•根据时期数列计算序时平均数应采用()。
八、1几何平均法 B.加权算术平均法C.简单九、 A.算术平均法 D.首末折半法十、2•下列数列中哪一个属于动态数列()。
十-、 A.学生按学习成绩分组形成的数列 B.工业企业按地区分组形成的数列十二、 C.职工按工资水平高低排列形成的数列 D.出口额按时间先后顺序排列形成的数列十三、3.已知某企业1月、2月、3月、4月的平均职工人数分别为190人、195人、193人和201人。
则该企业一季度的平均职工人数的计算方法为()。
十四、心(190+195+193+201)4B.190+195 + 1933十五.(190/2)+195+193 + (201/2) 、[190/2)+195+193+(201/2)C・D・ ---------------------------------4-1 44.说明现象在较长时期内发展的总速度的指标是()。
A、环比发展速度 B.平均发展速度 C.定基发展速度 D.环比增长速度5•已知各期环比增长速度为2%、5%、8%和7%,则相应的定基增长速度的计算方法为()。
A.(102%X105%X108%X107%) -100%B.102%X105%X108%X107%C.2%X5%X8%X7%D.(2%X5%X8%X7%) -100%6•定基增长速度与环比增长速度的关系是()。
人大王燕时间序列课后习题答案Document number:BGCG-0857-BTDO-0089-2022人大时间序列课后习题答案第二章P341、(1)因为序列具有明显的趋势,所以序列非平稳。
(2)样本自相关系数: ∑∑=-=+---≅=nt tkn t k t t k x xx x x x k 121)())(()0()(ˆγγρ5.10)2021(20111=+++==∑= n t t x n x =-=∑=2201)(201)0(x x t t γ35=--=+=∑))((191)1(1191x x x x t t t γ=--=+=∑))((181)2(2181x x x x t t t γ=--=+=∑))((171)3(3171x x x x t t t γγ(4)= γ(5)= γ(6)= 1ρ=() 2ρ=() 3ρ=() 4ρ=() 5ρ=() 6ρ=() 注:括号内的结果为近似公式所计算。
(3)样本自相关图:Autocorrelati Partial AC PAC Q-|*******| |*******|. |***** | . *| . |2. |**** | . *| . |3. |*** | . *| . |4. |**. | . *| . |5. |* . | . *| . |6. | . | . *| . |7. *| . | . *| . |8. *| . | . *| . |9.**| . | . *| . |10.**| . | . *| . |11***| . | . *| . |12该图的自相关系数衰减为0的速度缓慢,可认为非平稳。
4、∑=⎪⎪⎭⎫ ⎝⎛-+=mk k k n n n LB 12ˆ)2(ρLB(6)=1.6747 LB(12)= 205.0χ(6)= 205.0χ(12)=显然,LB 统计量小于对应的临界值,该序列为纯随机序列。
第三章P971、解:)()(*7.0)(1t t t E x E x E ε+=-0)()7.01(=-t x E 0)(=t x E t t x ε=-)B 7.01(t t t B B B x εε)7.07.01()7.01(221 +++=-=-229608.149.011)(εεσσ=-=t x Var49.00212==ρφρ 022=φ2、解:对于AR (2)模型:⎩⎨⎧=+=+==+=+=-3.05.02110211212112011φρφρφρφρρφφρφρφρ 解得:⎩⎨⎧==15/115/721φφ3、解:根据该AR(2)模型的形式,易得:0)(=t x E 原模型可变为:t t t t x x x ε+-=--2115.08.02212122)1)(1)(1(1)(σφφφφφφ-+--+-=t x Var2)15.08.01)(15.08.01)(15.01()15.01(σ+++--+==2σ⎪⎩⎪⎨⎧=+==+==-=2209.04066.06957.0)1/(1221302112211ρφρφρρφρφρφφρ ⎪⎩⎪⎨⎧=-====015.06957.033222111φφφρφ4、解:原模型可变形为:t t x cB B ε=--)1(2由其平稳域判别条件知:当1||2<φ,112<+φφ且112<-φφ时,模型平稳。