
第十三章 药动学数据的曲线拟合以及常用软件
计算药动学参数,是药代动力学进一步应用的基础。如何测定有关的动力学参数呢?常用的方法是:首先在用药后的若干不同时间,采取血样(或尿样),测定其血药浓度值或尿中药量(这些数值称为实测值或观察值,用C i 表示),这样就有了药物浓度经时曲线数据;然后,依据半对数坐标图,选定一种模型方程
(是时间t 的曲线函数)计算理论估算值(用i C )表示),按照观察值和理论估算值之
差的平方和(即残差平方和)或加权残差平方和(均用Re 表示)最小的原则,采用适当的算法,求出有关的动力学参数。这种方法,在数学上称为曲线拟合(fitting a curve)。由于所采用的线性药代动力学的模型方程是多指数项之和的函数形式,并且是所含动力学参数的非线性函数,所以这种曲线拟合方法称为非线性最小二乘法。
一、最小二乘法的一般原理
设y 是变量x 的函数,含有m 个待定参数a 1,a 2,…,a m 。记为
y =f (x ;a 1,a 2,…,a m ) 若对x 和y 作n 次观察,测得观察值(x 1,y 1),(x 2,y 2),…,(x n ,y n )。根据这样一组二维数据,即平面上的若干点,要求确定这个一元函数y =f (x ;a 1,a 2,…,a m );(i=1,2,…,n),即一条曲线,使这些点与曲线总体来说尽量接近。并使y
的观察值y i 与理论估算值=i y )f (x i ;a 1,a 2,…,a m )
;(i=1,2,…,m)的误差平方和,即残差平方和21
()n e i i i y y ==?∑)2121((,,,,)n i i m i y f x a a a ==?…∑R )i 取得最小值,
或者加权残差平方和21()/n e i i i R y y w ==?∑)2121
((,,,,))/n i i m i i y f x a a a w ==?…∑ 取得
最小值。其中w i 称为权重系数,在后面的段落会详细讲解。这时Re 有时候也称为目标函数。这就是数据拟合成曲线的思想,简称为曲线拟合。曲线拟合的目的是根据实验获得的数据去建立因变量和自变量之间有效的函数关系,这个函数关系对于药动学来讲就是通过房室模型推导出来的药时曲线公式。根据观察值求出待 311
定参数(因而也就确定了曲线y =f (x ;a 1,a 2,…,a m ))的问题。我们称f (x ;a 1,a 2,…,a m )为拟合函数。特别地,当f 为x 的线性函数时,则称为直线拟合(或直线回归)。
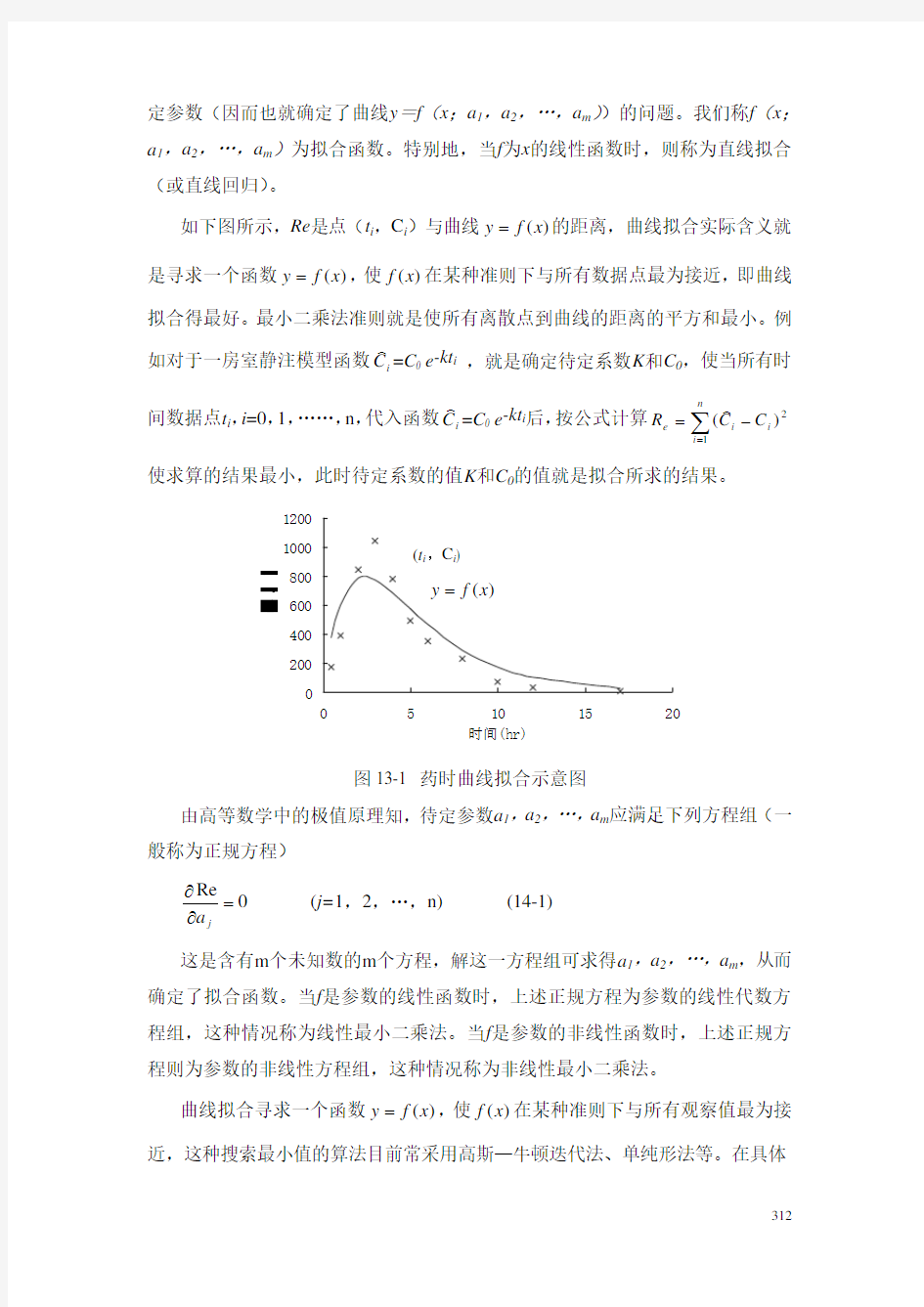
如下图所示,Re 是点(t i ,C i )与曲线)(x f y =的距离,曲线拟合实际含义就是寻求一个函数,使在某种准则下与所有数据点最为接近,即曲线拟合得最好。最小二乘法准则就是使所有离散点到曲线的距离的平方和最小。例
如对于一房室静注模型函数)(x f y =)(x f i C )=C 0 e -kt i ,就是确定待定系数K 和C 0,使当所有时
间数据点t i ,i =0,1,……,n ,代入函数i C )=C 0 e -kt i 后,按公式计算使求算的结果最小,此时待定系数的值K 和C ∑=?=n i i i e C C R 1
2
)()0的值就是拟合所求的结果。 度g m l
图13-1 药时曲线拟合示意图
由高等数学中的极值原理知,待定参数a 1,a 2,…,a m 应满足下列方程组(一般称为正规方程)
0Re =??j
a (j=1,2,…,n) (14-1) 这是含有m 个未知数的m 个方程,解这一方程组可求得a 1,a 2,…,a m ,从而确定了拟合函数。当f 是参数的线性函数时,上述正规方程为参数的线性代数方程组,这种情况称为线性最小二乘法。当f 是参数的非线性函数时,上述正规方程则为参数的非线性方程组,这种情况称为非线性最小二乘法。
曲线拟合寻求一个函数,使在某种准则下与所有观察值最为接近,这种搜索最小值的算法目前常采用高斯—牛顿迭代法、单纯形法等。在具体)(x f y =)(x f 312
计算时,有时候采用简化方法—对数回归法或残数法,将非线性方程转化为线性方程,计算虽然比较简单,但计算的误差往往比较大,同时手工计算比较费时费力。目前经常采用高斯—牛顿迭代法、单纯形法等算法编制成计算机程序,当数据比较符合理论情况时,能够比简化计算方法计算出更精确、合理的动力学参数。
二、非线性最小二乘法算法的比较
1、经典高斯—牛顿迭代法以及改进方法—哈特莱方法(Levenberg-Hartley法)、阻
尼最小二乘法
高斯—牛顿迭代法将目标函数(Re)在待定药动学参数初值(a1,a2,…,a m)附近的微分方程用泰勒级数的一次项展开,得正规方程组,采用列主元高斯消元法解出该方程组,就可计算得理论上使得目标函数(Re)最小的最佳药动学参数。
该方法的优点:在某种程度上,按最佳梯度方向搜索,效果较好,虽对初值有一定的依赖性,但依赖程度远远低于其他类型的方法,如单纯形法。所以开始运算时往往收敛较快,运算时间短,这是此方法的突出优点。
缺点:由于泰勒展开中丢弃了高次项等等的原因,使得此法往往不能精确收敛,甚至会引起发散,不能求出解。基于这个缺点,对于经典高斯—牛顿迭代法进行了种种的改进,如哈特莱方法、阻尼最小二乘法等等,可以有效地改进拟合发散的缺点,但还是不能完全避免。
2、单纯形法
本方法是一种多维搜索的直接方法,不需要计算目标函数的导数。通过对n 维空间的n+1个点(它们构成一个初始单纯形)上的函数值进行比较,去掉其中函数值最大的点,代之以新的点,从而构成一个新的单纯形。这样,通过多次迭代逐步逼近极小点。
单纯形法的优点是:原理简单,避免了求导运算以及解正规方程组等步骤,从而不会有经典高斯—牛顿迭代法以及改进方法固有的缺点,基本不会发散。缺点是:收敛速度慢,初值依赖性较大,有陷入局部最小值的弊端,一般不单独使用,有人主张用高斯—牛顿迭代法求出大致的结果,再采用单纯形法作局部区域的精确搜索寻优。
三、估算药代动力学参数中的若干问题
313
1、如何选择模型
在曲线拟合时,需要事先选择合适的药动学模型方程再来进行拟合。也就是说同一组数据可以选择不同的药动学模型方程进行拟合(亦即拟合函数),那么如何选择和确定适当的模型呢?一种简单和直观的方法,就是根据实测的血药浓度的对数值对时间作图(称为对数浓度一时间散点图),作粗略的直观的分析。当散点图的分布比较有规则地反映出某一种单指数或多指数态势时,可确定出相应的房室数。但是,在许多情形下,散点图的分布往往似有多指数态势,或者多指数态势不明显,这时就要从中加以挑选。
选择房室数的方法,最常采用赤池信息判据最小准则AIC(Akaike’s Information Criterion)。
假设观测数据点数为n,拟合函数中所含待定参数的个数为m,拟合所得残差平方和(或加权残差平方和)为Re,
∑=?
=
n
i
i i
e
c c
R
1
2
) ();则
AIC=n ln(Re)+2 m (14-2) 赤池提出按AIC值最小的准则来挑选模型。就是说,在几种预定的模型中,较佳的模型其AIC值最小。根据这一准则,我们就可以对几种不同的房室模型分别进行曲线拟合,算出各自的Re和AIC值,比较AIC值的大小,然后选AIC 值最小的房室,作为优选的模型。另外,根据这一准则,我们对同一模型,在用不同的计算方法作曲线拟合时,AIC值最小的那种方法,算得的参数较为精确;不过这时AIC值最小就相当于Re值最小,因此,只要比较Re值的大小即可。
从公式看,AIC值的大小主要和两个因素有关,一个是Re,一个是待定参数个数。不同的房室模型,其待定参数不一样。例如,一房室静注,待定参数为K 和Vd两个参数,对数浓度一时间散点图为直线;二房室静注,待定参数为A、B、α、β四个参数,对数浓度一时间散点图有一个拐点的两根直线。模型中房室个数越多,待定参数越多,拟合函数越复杂,曲线包含的拐点越多,拟合时Re值就会越低。如果仅仅采用Re作为模型选择依据,非常复杂的多房室模型其Re值往往会更低,产生所谓过拟合现象。AIC值兼顾了模型房室个数和Re两个因素,既使得Re值低,同时又限制了复杂函数的使用,增加了拟合函数的实用
314
价值。从实用角度看,房室模型的房室个数不易超过3个。
在选取模型时要特别注意,房室模型中房室的划分具有相对性。当实验数据比较准确和充分时,可以将药物在体内分布的较小的速度差异区分开来,从而可以将体内分成更多的房室;但是当实验数据比较少或者误差较大时,药物在体内的速度差异就无法区分,只能将机体分成较少的房室或仅单一的中央室。由于上述原因,有可能同一种药物,在不同的文献报道中有不同的房室模型,要理解和容忍这种房室划分的相对性。
2、权重系数
曲线拟合采用的目标函数是Re ,Re 值越小,曲线拟合效果越好。但是,在实验观察值中,高、低血药浓度值相差较大时,Re 值的大小往往过分取决于高浓度
的观察值,而忽视了低浓度值的观测作用。例如,同样是||i i c c )?=0.5的差值,
对于100ng/ml 相对误差很小,对于1ng/ml 相对误差就很大,所以不能把高低浓度的差值等同看待。这时候就需要采用权重系数的方法,即在加权的情况下,求
加权残差平方和的最小值问题。其中W i n
i i i e w c c R /)(12∑=?=)i 称为权重系数。
权重系数最常采用的是:
W i =1/C 2i
则加权残差平方和为
21Re ∑=?????????=n i i i i C C C ) (13-3)
即为相对误差平方和最小。
当W i =1,就是不进行权重。有时候W i =1/C i ,权重介于1和1/C 2之间。至于选择何种权重系数,目前仍然在讨论之中,没有统一的方法,需要根据不同的情况进行具体的分析。需要强调的是,不同的权重系数的Re 值和AIC 值没有可比性。
四、曲线拟合的影响因素
在应用计算机程序进行曲线拟合,估算药动学参数时,影响拟合效果的因素很多,主要有以下几个因素:
1.实验设计问题
药时曲线的采样点数和浓度检测的准确性显著地影响着模型的识别和拟合 315
的质量,因而采样时间点和采样点个数的设计是成功进行拟合的第一步。原则上以较少的采样,尽可能获取血药浓度经时曲线的变化形态信息,如峰时间、峰浓度、拐点、变化趋势等。在曲线变化大的地方,应多采样,在曲线变化小的范围内,则少采样。但是,由于个体差异以及其他因素的存在,可能药时曲线的拐点等位置不一样,所以只能尽量做到符合以上原则。另外经验证明,对于m个参数的模型,采样点个数n至少为2m+1,例如二房室口服有5个待定参数,测11个点以上比较可靠。n≤m是不可行的,否则残差的自由度为n-m-1为-1,不符合统计学要求。事实上,国家药品审评机构的指导原则中明确表明药时曲线采样点个数不得少于11个,一般我们进行药时曲线的点数设计时都会超过11个。
2.样品浓度测定的准确性
目前国家药品审评机构对于体内生物样品检测有比较明确的指导原则,其中明文规定,对于生物样品检测,高、中浓度的检测相对误差必须在±15%以内,低浓度必须在20%以内。由于实验误差的存在,曲线拟合时权重系数的选取必须考虑。如果低浓度样品测试比较准确,就要采取权重拟合,反之普通拟合。对于半衰期等参数,更多地取决于药时曲线末端相的下降速率。样品检测的准确性显著地影响到这类参数的拟合。
3.收敛精度的选取
收敛精度的选取,通常采用由大到小逐步修正的办法,即起初精度可以取得大些,视其计算结果是否满意(残差平方和或加权残差平方和,是否可明显减少;观察值与估算值之间的相关系数,是否可明显增大等),再决定是否提高精度(将精度值取小)。在继续拟合时,应选前一次结果作为初值。
4.初值选择和拟合取值范围问题
目前所采用的非线性最小二乘法的算法都面临一个初值如何选取的问题。初值选得好,迭代次数少,收敛速度快,所得结果也相对理想。初值选取一般首先参考文献上的资料或者以往的经验,也可以应用残数法的计算结果作为初值。但是无论初值如何选取,也还是存在初值依赖性的问题。
初值依赖性是指随着初值选取的不同,拟合所得药动学参数也会随之变化。下图是一个实际的利用单纯形法拟合药动学参数过程中目标函数Re值的分布图。
316
该例为口服一房室模型,有三个待定参数:Ka;Dose*F/V,Ke。在Ka=0.3时,罗列Dose*F/V和Ke两个参数在一定范围内的所有对应组合情况下的Re值;从图中可以看到颜色越深,Re值越小;低于某一限度的Re值区域为一个不规则的长条状。寻优过程中,当参数组合点到达最深的区域的边缘1就可以终止拟合。由图可见,随着起始位置不同,从三个方向开始拟合,所到达的目标值并不是归结为一个点,而是三个点,在Re值最小区域的边缘,这就存在药动学参数拟合的初值依赖性。
改变Ka值,可以绘出一系列图,通过多媒体动画技术,将这些图叠加在一起依次出现,依据Re值最小这个标准,就可以找出一个最佳的三个待定参数的组合范围,使得Re值最小。选取该组合范围的中点,就可以避免初值依赖性。但是随着待定参数数目的增加,待定参数的组合数呈几何级数增长,大大增加计算工作量,获得所需结果就仅仅成为理论上的可能了。
另外,由图1可见,参数Dose*F/V的取值在小于0没有实际意义的情况下,Re值依然很小,说明了数据拟合寻优过程中必须限定取值范围,否则拟合出来的数据没有实际意义。
图13-2 拟合中的初值依赖性
1此处的最深区域为Re值最小,但是真正的拟合收敛条件应该为Re值变化率最小,并不是Re值最小。Re变化率最小和Re最小的区域虽然不一致,但是也同样是一个不规则区域。
317
初值依赖现象不仅仅在单纯形法模型嵌合中存在,其他任何寻优法中都存在,关键在于药物浓度-时间双指数或多指数曲线本身就存在两个或多个最优解。下面表1中的两组一房室模型参数能产生出如图2所示的完全一样的药时曲线。这两组参数的区别仅仅在于Ka和Ke的大小不同,表观分布容积不同。也就是说,如果Ka和Ke大小不能确定,同一组药时数据会有两组同样最优的药动学参数组合。一般情况下Ka>Ke,所以同一组药时数据最优解只有一组药动学参数组合。但是,对于缓控释制剂、特殊释放制剂,就不可能仅仅通过本身口服后的数据来区分吸收指数项和消除指数项,从而来进行吸收解析。这就是吸收解析的时候最好要同时进行静脉给药实验的原因——能够确切地知道药物的消除相的情况。但是,当药物静脉给药和口服给药消除情况不一致的时候,哪怕进行静脉注射也无法进行口服药物的吸收解析,例如口服给药存在肠肝循环,首过效应强等等的情况。
图13-3 多指数曲线存在两个最优解
100
F(%) 100
口服给药剂量(mg)973 973
0.52
Ka(h-1) 2.5
k(h-1) 0.52
2.5
34
V(l) 163
318
五、目前常用计算机药动学数据拟合程序
目前国内外药动学计算软件比较多。国外比较著名的软件有WinNonlin、Kinetica等,国内比较著名的软件有3p87(3p97)、PKBP—N1、BAPP、DAS等。
(一)WinNonlin 软件
WinNonlin为美国Pharsight公司产品,是目前国外应用最广泛的软件,界面友好,功能强大,与其他软、硬件有很好的兼容性。WinNonlin 有标准版、专业版、企业版等三个版本,标准版中包含了药动学与药效学分析的各种工具,专业版和企业版较标准版增加了几个模块,主要用于商业用途。
目前WinNonlin软件最新版本为4.1,其主要功能如下:1、房室模型分析(PK Fitting,Compartmental Analysis),包括19种模型库,支持用户自定义模型;寻优算法包括Nelder Mead simplex,Gauss-Newton (Levenberg Hartly),Gauss-Newton (Hartly)法,权重方式包括1/obs,1/obs*obs,1/calc,1/calc*calc,初值的设定包括了上下限;模型确认标准包括Akaike,Schwarz,CV,SEM等。2、非房室模型分析(Non Compartmental Analysis),包括各种给药途径,还支持末端相半衰期图解求算,支持参数个体和群体设定,可计算稳态数据参数。3、等效性检验,包括平均等效性、群体等效性、个体等效性(ABE、PBE、IBE)。4、PK-PD数据分析,支持PK、PD分步分析和PK-PD统一嵌合的大模型分析,但是尚不支持群体的PK-PD分析。5、提供了“工具箱”(toolbox)功能及帮助功能:非参数重叠法( nonparametric superposition),用来预测多剂量用药后达到稳态的血药浓度;半房室模型法(semicompartmental modeling),用来估算给定时间和血浆浓度的效应地点浓度。6、数据输入输出支持格式众多,包括ASCII、Excel、SAS?、Transport、Oracle、Watson、ODBC-Treiber等,有非常良好的兼容性;输出的图表能形象化地显示数据,可进行编辑修改。7、提供了一定的数据描述统计功能。
下面两幅图片分别为WinNonlin软件使用过程中模型选择和模型拟合初值输入。
319
图13-4 WinNonlin软件使用过程中模型选择对话框
图13-5 WinNonlin软件使用过程中模型拟合中初值输入对话框
(二)BAPP软件
BAPP软件是由中国药科大学药代中心编写的生物利用度数据处理通用软件(BioAvailability Program Package),专门用于生物利用度研究和生物等效性评价数
320
据处理,最大的特点是在EXCEL的基础上进行二次开发,不但具有EXCEL强大、方便的常用数据处理能力,而且具有强大的专业数据分析能力。目前版本为2.3,其主要功能如下:
图13-6 BAPP软件功能
其中全程自动处理功能提供了全球首创的“傻瓜”操作模式,所有表格、图表、药动学数据处理、等效性检验结果自动转移到WORD中,并且自动排版,可以直接用到用户的实验报告中,并且支持数据缺失,支持低于检测限的数据,支持剂量不一致。
321
图13-7 BAPP软件全程处理功能对话框
另外还支持如下单独功能:
1)在Excel中添加了额外的药动学计算函数,其中包括AUC、MRT、AUMC、t1/2等,支持数据缺失,能将其自动删除后计算。
2)生物等效性检验,支持三交叉试验设计。
3)药代动力学参数的拟合,主要采用改良单纯形法和Gauss-Newton (Levenberg Hartly)法对血药浓度—时间数据进行寻优拟合,找到最小残差平方和,给出血药浓度预报值和一系列药动学参数,并进行作图。
4)权重直线回归,能同时给出不权重(权重因子为1)、权重因子为1/y、权重因子为1/y2三种权重回归结果。
5)自动作图,包括五种生物利用度研究报告中的常用作图模式,并将图形自动拷贝到WORD中。
6)缓释制剂体内外相关性分析。
7)Tmax非参数检验,支持三交叉试验设计。
BAPP软件2002年4月通过了国内著名药动学软件专家组成的评审委员会的审评,目前国内开展生物利用度研究和生物等效性评价的单位中有较广泛的应用。
国内外还有大量的优秀软件,国外如Kinetica,国内如DAS,功能也非常强大,应用也比较广泛,用户选择余地很大。对于药动学软件,通过本章的介绍,我们应该知道即便使用了权威的软件,如果忽视了模型的前提和假设,所得结果也是错误的,所以数据分析处理过程中千万不能迷信软件,轻视对药动学基本概念的掌握。
参考文献:
1.金有豫,药理学(第五版),人民卫生出版社,2001
2.王贤才主译.临床药物大典,青岛出版社,1994
3.吴钟琪、周宏灏、许树梧。全科医学临床药物学,科学出版社,2001
4.戴得哉.临床药理学,中国医药科技出版社,2002
5.Osbourne R,Joel S,Trew D,and Slenvin Morphine and metabolite behavior after different routes of morphine administration.Demonstration of the importance of the active metabolite morphine-6-glucuronide,Clin.Pharmacol.Ther.,1990,47:12-19
6. 谢海棠黄晓晖孙瑞元中国临床药理学与治疗学 2001,6 (4)289~292
322
一、课程设计题目: 对于函数 x e x x f --=)( 从00=x 开始,取步长1.0=h 的20个数据点,求五次最小二乘拟合多项式 5522105)()()()(x x a x x a x x a a x P -++-+-+= 其中 ∑ ===19 95.020 i i x x 二、原理分析 (1)最小二乘法的提法 当数据量大且由实验提供时,不宜要求近似曲线)(x y φ=严格地经过所有数据点),(i i y x ,亦即不应要求拟合函数)(x ?在i x 处的偏差(又称残差) i i i y x -=)(φδ (i=1,2,…,m) 都严格的等于零,但是,为了使近似曲线能尽量反应所给数据点的变化趋势,要求偏差i δ适当的小还是必要的,达到这一目标的途径很多,例如,可以通过使最大偏差i δmax 最小来实现,也可以通过使偏差绝对值之和∑i i δ最小来实 现……,考虑到计算方便等因素,通常用使得偏差平方和∑i i 2δ最小(成为最小 二乘原则)来实现。 按最小二乘原则选择近似函数的方法称为最小二乘法。 用最小二乘法求近似函数的问题可以归结为:对于给定数据),(i i y x (i=1,2,…,m),要求在某个函数类Φ中寻求一个函数)(x * ?,使 [][]2 1 )(2 1 * )()(mi n ∑∑=Φ∈=-=-m i i i x m i i i y x y x ??? (1-1) 其中)(x ?为函数类Φ中任意函数。 (1)确定函数类Φ,即确定)(x ?的形式。这不是一个单纯的数学问题,还与其他领域的一些专业知识有关。在数学上,通常的做法是将数据点),(i i y x 描
曲线拟合 求二次拟合多项式 解:(一)最小二乘法MA TLAB编程: function p=least_squar(x,y,n,w) if nargin<4 w=1 end if nargin<3 n=1 end m=length(y); X=ones(1,m) if m<=n error end for i=1:n X=[(x.^i);X] end A=X*diag(w)*X';b=X*(w.*y)';p=(A\b)' 输入: x=[1 3 5 6 7 8 9 10]; y=[10 5 2 1 1 2 3 4] p=least_squar(x,y,2) 运行得: p = 0.2763 -3.6800 13.4320 故所求多项式为:s(x)=13.432-3.68x+0.27632x (二)正交多项式拟合MATLAB编程: function p=least_squar2(x,y,n,w) if nargin<4 w=1; end if nargin<3 n=1; end m=length(x); X=ones(1,m); if m<=n error end for i=1:n X=[x.^i;X]; end A=zeros(1,n+1);
A(1,n+1)=1; a=zeros(1,n+1); z=zeros(1,n+1); for i=1:n phi=A(i,:)*X;t=sum(w.*phi.*phi); b=-sum(w.*phi.*x.*phi)/t a(i)=sum(w.*y.*phi)/t; if i==1 c=0;else c=-t/t1; end t1=t for j=1:n z(j)=A(i,j+1); end z(n+1)=0 if i==1 z=z+b*A(i,:); else z=z+b*A(i,:)+c*A(i-1,:); end A=[A;z]; end phi=A(n+1,:)*X;t=sum(w.*phi.*phi); a(n+1)=sum(w.*y.*phi)/t; p=a*A; 输入: x=[1 3 5 6 7 8 9 10]; y=[10 5 2 1 1 2 3 4]; p=least_squar2(x,y,2) 运行得: b = -6.1250 t1 = 8 z = 0 1 0 b = -4.9328 t1 = 64.8750 z = 1.0000 -6.1250 0 p = 0.2763 -3.6800 13.4320 故所求多项式为:s(x)=13.432-3.68x+0.27632x
课题八曲线拟合的最小二乘法 实验目标: 在某冶炼过程中,通过实验检测得到含碳量与时间关系的数据如下,试求含碳量y与时间t #include 2010a版本曲线拟合工具箱 一、单一变量的曲线逼近 Matlab有一个功能强大的曲线拟合工具箱cftool ,使用方便,能实现多种类型的线性、非线性曲线拟合。下面结合我使用的Matlab R2007b 来简单介绍如何使用这个工具箱。 假设我们要拟合的函数形式是y=A*x*x + B*x, 且A>0,B>0。 1、在主命令输入数据: x=233.8:0.5:238.8; y=[235.148 235.218 235.287 235.357 235.383 235.419 235.456 235.49 235.503 235.508 235.536]; 2、启动曲线拟合工具箱 cftool(x,y) 3、进入曲线拟合工具箱界面“Curve Fitting tool” 如图 (1)利用X data和Y data的下拉菜单读入数据x,y,可在Fit name修改数据集名,这时会自动画出数据集的曲线图; (2)在红色区域选择拟合曲线类型 工具箱提供的拟合类型有: ?Custom Equations:用户自定义的函数类型 ?Exponential:指数逼近,有2种类型,a*exp(b*x) 、a*exp(b*x) + c*exp(d*x) ?Fourier:傅立叶逼近,有7种类型,基础型是a0 + a1*cos(x*w) + b1*sin(x*w) ?Gaussian:高斯逼近,有8种类型,基础型是a1*exp(-((x-b1)/c1)^2) ?Interpolant:插值逼近,有4种类型,linear、nearest neighbor、cubicspline、shape-preserving ?Polynomial:多形式逼近,有9种类型,linear ~、quadratic ~、cubic ~、4-9th degree~ ?Power:幂逼近,有2种类型,a*x^b 、a*x^b + c ?Rational:有理数逼近,分子、分母共有的类型是linear ~、quadratic ~、cubic ~、4-5th degree~;此外,分子还包括constant型 ?Smoothing Spline:平滑逼近(翻译的不大恰当,不好意思) ?Sum of Sin Functions:正弦曲线逼近,有8种类型,基础型是a1*sin(b1*x + c1) ?Weibull:只有一种,a*b*x^(b-1)*exp(-a*x^b) 在results一栏看结果 Boltzmann 函数曲线拟合的Lisp 程序 1 原程序在计算机中,将以下原代码写入记事本中并保存文件名为“bzlm.lsp” (setq smx (lambda ( / k wi a1 a2 b1 b2 c1 c2 sx) (setq wi (mapcar '(lambda ( x / ) (expt 2.718282 (/ (- x m3) m4))) xi) k 0 a1 (apply '+ (mapcar '(lambda ( y / w) (setq w (nth k wi) k (1+ k)) (/ y (+ 1 w))) yi)) k 0 a2 (apply '+ (mapcar '(lambda ( y / w) (setq w (nth k wi) k (1+ k)) (/ (* y w) (+ 1 w))) yi)) b1 (apply '+ (mapcar '(lambda ( w / ) (/ 1 (expt (+ 1 w) 2))) wi)) b2 (apply '+ (mapcar '(lambda ( w / ) (/ w (expt (+ 1 w) 2))) wi)) c1 b2 c2 (apply '+ (mapcar '(lambda ( w / ) (expt (/ w (+ 1 w)) 2)) wi)) m1 (/ (- (* a1 c2) (* a2 c1)) (- (* b1 c2) (* b2 c1))) m2 (/ (- (* b1 a2) (* b2 a1)) (- (* b1 c2) (* b2 c1))) k 0 sx (apply '+ (mapcar '(lambda ( x / y w) (setq w (nth k wi) y (nth k yi) k (1+ k)) (expt (- y (+ (/ (- m1 m2) (+ 1 w)) m2)) 2)) xi)) ) (if (car s_min) (if (< sx (car s_min)) (setq s_min (list sx m1 m2 m3 m4)) nil) (setq s_min (list sx m1 m2 m3 m4))) ) ) (setq mmc (lambda (range / m1 m2 s_min m3 m4 rm3 rm4 tm4 q3 q4) (setq rm3 (abs range) rm4 rm3 q3 rm3 q4 rm4 m3 0 m4 0) (repeat 5 (setq rm3 (+ m3 q3) m3 (- m3 q3) rm4 (+ m4 q4) m4 (- m4 q4) tm4 m4 q3 (* q3 0.1) q4 (* q4 0.1)) (while (<= m3 rm3) (while (<= m4 rm4) (if (>= m4 1) (smx)) (setq m4 (+ m4 q4))) (setq m3 (+ m3 q3) m4 tm4) ) (setq m3 (nth 3 s_min) m4 (last s_min)) ) s_min ) ) (setq cy (lambda ( / m1 m2 m3 m4) (if sc (progn (setq m1 (nth 1 sc) m2 (nth 2 sc) m3 (nth 3 sc) m4 (nth 4 sc) yc (+ (/ (- m1 m2) (+ 1 (expt 2.718282 (/ (- xc m3) m4)))) m2) ) (set_tile "cy" (vl-princ-to-string yc)) )))) (setq cx (lambda ( / m1 m2 m3 m4 tm) (if sc (progn (setq m1 (nth 1 sc) m2 (nth 2 sc) m3 (nth 3 sc) m4 (nth 4 sc)) (if (and (< y m2) (> (setq tm (- (/ (- m1 m2) (- yc m2)) 1)) 0)) (progn (setq xc (+ m3 (* m4 (log tm)))) MATLAB曲线拟合 一、单一变量的曲线逼近 Matlab有一个功能强大的曲线拟合工具箱cftool ,使用方便,能实现多种类型的线性、非线性曲线拟合。下面结合我使用的Matlab R2007b 来简单介绍如何使用这个工具箱。 假设我们要拟合的函数形式是y=A*x*x + B*x, 且A>0,B>0 。 1、在命令行输入数据: 》x=[110.3323 148.7328 178.064 202.8258033 224.7105 244.5711 262.908 280.0447 296.204 311.5475]; 》y=[5 10 15 20 25 30 35 40 45 50]; 2、启动曲线拟合工具箱 》cftool 3、进入曲线拟合工具箱界面“Curve Fitting tool” (1)点击“Data”按钮,弹出“Data”窗口; (2)利用X data和Y data的下拉菜单读入数据x,y,可修改数据集名“Data set name”,然后点击“Create data set”按钮,退出“Data”窗口,返回工具箱界面,这时会自动画出数据集的曲线图; (3)点击“Fitting”按钮,弹出“Fitting”窗口; (4)点击“New fit”按钮,可修改拟合项目名称“Fit name”,通过“Data set”下拉菜单选择数据集,然后通过下拉菜单“Type of fit”选择拟合曲线的类型,工具箱提供的拟合类型有: Custom Equations:用户自定义的函数类型 Exponential:指数逼近,有2种类型,a*exp(b*x) 、a*exp(b*x) + c*exp(d*x) Fourier:傅立叶逼近,有7种类型,基础型是a0 + a1*cos(x*w) + b1*sin(x*w) Gaussian:高斯逼近,有8种类型,基础型是a1*exp(-((x-b1)/c1)^2) Interpolant:插值逼近,有4种类型,linear、nearest neighbor、cubic spline、shape-preserving Polynomial:多形式逼近,有9种类型,linear ~、quadratic ~、cubic ~、4-9th degree ~ Power:幂逼近,有2种类型,a*x^b 、a*x^b + c Rational:有理数逼近,分子、分母共有的类型是linear ~、quadratic ~、cubic ~、4-5th degree ~;此外,分子还包括constant型Smoothing Spline:平滑逼近(翻译的不大恰当,不好意思) Sum of Sin Functions:正弦曲线逼近,有8种类型,基础型是 a1*sin(b1*x + c1) Weibull:只有一种,a*b*x^(b-1)*exp(-a*x^b) 选择好所需的拟合曲线类型及其子类型,并进行相关设置: ——如果是非自定义的类型,根据实际需要点击“Fit options”按钮, 药物动力学习题 一、名词解释 1.药物动力学;2.隔室模型;3.单室模型;4.外周室;5.二室模型; 6.三室模型;7.AIC判据;8.混杂参数;9.稳态血药浓度;10.负荷剂量; 11.维持剂量;12.坪幅;13.达坪分数;14.平蚜稳态血药浓度; 15.蓄积系数;16.波动度;17.波动百分数:18.血药浓度变化率 19.生物利用度;20.绝对生物利用度;21.相对生物利用度;22.生物等效性;23.延迟商 二、单项选择题 1.最常用的药物动力学模型是 A.隔室模型 B.药动一药效结合模型 C.非线性药物动力学模型 D.统计矩模型 E.生理药物动力学模型 2.药物动力学是研究药物在体内的哪一种变化规律 A.药物排泄随时间的变化 B.药物药效随时间的变化 C.药物毒性随时间的变化 D.体内药量随时间的变化 E.药物体内分布随时间的变化 3.关于药物动力学的叙述,错误的是 A.药物动力学在探讨人体生理及病理状态对药物体内过程的影响中具有重要的作用 B.药物动力学对指导新药设计、优化给药方案、改进剂型等都发挥了重大作用 C.药物动力学是采用动力学的原理和数学的处理方法,推测体内药物浓度随时 间的变化 D.药物动力学是研究体内药量随时间变化规律的科学 E.药物动力学只能定性地描述药物的体内过程,要达到定量的目标还需很长的 路要走 4.反映药物转运速率快慢的参数是 A.肾小球滤过率B.肾清除率 C.速率常数D.分布容积 E.药时曲线下面积 5.关于药物生物半衰期的叙述,正确的是 A.具一级动力学特征的药物,其生物半衰期与剂量有关 B.代谢快、排泄快的药物,生物半衰期短 C.药物的生物半衰期与给药途径有关 D.药物的生物半衰期与释药速率有关 E.药物的生物半衰期与药物的吸收速率有关 6.通常情况下与药理效应关系最为密切的指标是 A.给药剂量 B.尿药浓度 C.血药浓度 D.唾液中药物浓度 E.粪便中药物浓度 7.关于表观分布容积的叙述,正确的有 A.表观分布容积最大不能超过总体液 B.无生理学意义 C.表观分布容积是指体内药物的真实容积 D.可用来评价药物的靶向分布 E.表观分布容积一般小于血液体积 8.某药物的组织结合率很高,因此该药物 A.半衰期长 B.半衰期短 C.表观分布容积小 ^ #include<> #include<> void nihe(); void gs(); void main() { int i,j,m,n; float o[50]; \ float x[50] , y[50] ,a[50][50]; printf("输入数据节点数 n = ",n); scanf("%d",&n); for( i=1;i<=n;i++) { printf(" i = %d\n",i); } printf("各节点的数据 x[i] \n"); 、 for(i=1;i<=n;i++) { printf("x[%d] = ",i); scanf("%f",&x[i]); } printf("各节点的数据 y[i] \n"); for(i=1;i<=n;i++) { ¥ printf("y[%d] = ",i); scanf("%f",&y[i]); } printf("\n"); printf("拟合的多项式次数 m = ", m); scanf("%d",&m); ¥ } void nihe(float x[50], float y[50], int m ,int n) { int i,j,k=0,c=1,w=1; float f,a[50][50] , o[50];; ~ do { f=0; for(i=1;i<=n;i++) { f=f+pow( x[i] , k)*pow( x[i] , k); } … a[c][c]=f ; a[c+1][c-1]=f; a[c-1][c+1]=f; c++; k++; }while(k<=m); , k=1;c=1; do { f=0; for(i=1;i<=n;i++) { f=f+pow( x[i] , k); } * a[c+1][c]=f; a[c][c+1]=f; c++; k++; k++; }while(k<=m+1); ) k=0;c=1; do { f=0; for(i=1;i<=n;i++) 药物代谢动力学的研究 摘要:超高效液相色谱(UPLC)和PBPK模型在药物代谢动力学研究发挥的重要的作用。UPLC是一种柱效高、发展前景好的液相色谱技术,是一种基于机制的数学模型;PBPK用于模拟化学物质在体内的分布代谢更方面对药物动力学的研究。药物代谢动力学的更深研究在药物研发中起到了重要意义及作用。 关键词:药物代谢动力学 UPLC PBPK模型药物研发 Abstract: the high performance liquid chromatography (UPLC) and PBPK model in the study of the pharmacokinetic play an important role. UPLC is a column efficiency high, the prospects of the development of good performance liquid chromatography, is based on a mathematical model of the mechanism; PBPK used for simulation of the chemical substances in the body of metabolic distributed more medicine dynamics research. The pharmacokinetic deeper in drug development research has important significance and role. Keywords: Pharmacokinetic UPLC PBPK model Drug development 前言:动力学的基本理论和方法已经渗透到生物药剂学,药物治疗学,临床药理学及毒理学等多学科领域中。药物代谢动力学是应用数学处理方法,定量描述药物及其他外源性物质在体内的动态变化规律,研究机体对药物吸收、分布、代谢和排泄等的处置以及所产生的药理学和毒理学意义;并且探讨药物代谢转化途径,确证代谢产物结构,研究代谢产物的药效或毒性;提供药物效应和毒性的靶器官,阐明药效或毒性的物质基础,弄清药物疗效和毒性与药物浓度的关系[1]。 1、药物动力学的研究进展 1.1 群体药物动力学 群体药物动力学是研究药物动力学群体参数的估算,药物动力学参数群体值不仅是临床用药所必需,而且有可能成为新药评价的一个必备参数。药物动力学参数群体值的估算有两种方法,一种是传统的二步法,另一种是近年来发展的一步法。后者亦名Nonmen程序法,它把药物动力学参数在患者身上的自身变异及患者间的变异全估算在内。根据变异值的大小也可预估一些生理、病理因素对药物动力学参数的影响。因而更具优越性,在个体化给药中,Nonmen常与Bayesian反馈法结合使用。 1.2 时辰药物动力学 时辰药物动力学是指同一剂量在l天内不同时间给予时药物处置出现显著变异。如多数脂溶性药物的吸收,清晨比傍晚吸收更佳,另外象单硝酸异山梨酯在清晨服用时所导致的体位性低血压最为明显,同时达峰时间也较其他时间给药为短。一些疾病并非1天24小时机体均需要同等水平的药物,如心脏病患者在凌晨发病较多,若制成脉冲式给药,可产生预防作用;相反,如药物浓度始终维持在同一水平却容易带来耐药性,例如硝酸甘油和许多抗菌素类药物;再如只有当血浆中糖分较高时才需要较高的胰岛素。人们开始研究能够自动感知血糖水平,以调节胰岛素释放速率的智能给药装置。 药物动力学模型 一般说来,一种药物要发挥其治疗疾病得作用,必须进入血液,随着血流到达作用部位。药物从给药部位进入血液循环得过程称为药物得吸收,而借助于血液循环往体内各脏器组织转运得过程称为药物得分布。 药物进入体内以后,有得以厡型发挥作用,并以厡型经肾脏排出体外;有得则发生化学结构得改变--称为药物得代谢。代谢产物可能具有药理活性,可能没有药理活性。不论就是厡型药物或其代谢产物,最终都就是经过一定得途径(如肾脏、胆道、呼吸器官、唾液腺、汗腺等)离开机体,这一过程称为药物得排泄。有时,把代谢与排泄统称为消除。 药物动力学(Pharmacokinetics)就就是研究药物、毒物及其代谢物在体内得吸收、分布、代谢及排除过程得定量规律得科学。它就是介于数学与药理学之间得一门新兴得边缘学科。自从20世纪30年代Teorell为药物动力学奠定基础以来,由于药物分析技术得进步与电子计算机得使用,药物动力学在理论与应用两方面都获得迅速得发展。至今,药物动力学仍在不断地向深度与广度发展。药物动力学得研究方法一般有房室分析;矩分析;非线性药物动力学模型;生理药物动力学模型;药物药效学模型。下面我们仅就房室分析作一简单介绍。 为了揭示药物在体内吸收、分布、代谢及排泄过程得定量规律,通常从给药后得一系列时间(t) 采取血样,测定血(常为血浆,有时为血清或全血)中得药物浓度( C );然后对血药浓度——时间数据数据(C ——t数据)进行分析。 一一室模型 最简单得房室模型就是一室模型。采用一室模型,意味着可以近似地把机体瞧成一个动力学单元,它适用于给药后,药物瞬间分布到血液、其它体液及各器官、组织中,并达成动态平衡得情况。下面得图(一)表示几种常见得给药途径下得一室模型,其中C代表在给药后时间t 得血药浓度,V代表房室得容积,常称为药物得表观分布容积,K代表药物得一级消除速率常数,故消除速率与体内药量成正比,D代表所给刘剂量。 图(a)表示快速静脉注射一个剂量D,由于就是快速,且药物直接从静脉输入,故吸收过程可略而不计;图(b)表示以恒定得速率K,静脉滴注一个剂量D;若滴注所需时间为丅,则K=D/丅。图(c)表示口服或肌肉注射一个剂量D,由于存在吸收过程,故图中分别用F与 K代表吸收分 数与一级吸收速率常数。 1、快速静脉注射 在图(a)中所示一室模型得情况下,设在时间t,体内药物量为x,则按一级消除得假设,体内药量减少速率与当时得药量成正比,故有下列方程: dx Kt dt(5、1) 快速静脉注射恒速静脉滴注口服或肌肉注射 K F 0K 《药物代谢动力学》 一、单选题(共 20 道试题,共 20 分。) V 1. 关于试验动物的选择,以下哪些说法不正确?()B A. 首选动物尽可能与药效学和毒理学研究一致 B. 尽量在清醒状态下试验 C. 药物代谢动力学研究必须从同一动物多次采样 D. 创新性的药物应选用两种或两种以上的动物,一种为啮齿类动物,另一种为非啮齿类动物 E. 建议首选非啮齿类动物 满分:1 分 2. 普萘洛尔口服吸收良好,但经过肝脏后,只有30%的药物达到体循环,以致血药浓度较低,下列哪 种说法较合适?()C A. 药物活性低 B. 药物效价强度低 C. 生物利用度低 D. 化疗指数低 E. 药物排泄快 满分:1 分 3. 某弱碱性药在pH 5.0时,它的非解离部分为90.9%,该药的pKa接近哪个数值?()C A. 2 B. 3 C. 4 D. 5 E. 6 满分:1 分 4. 某药物在口服和静注相同剂量后的药时曲线下面积相等,表明:()A A. 口服吸收完全 B. 口服药物受首关效应影响 C. 口服吸收慢 D. 属于一室分布模型 E. 口服的生物利用度低 满分:1 分 5. 影响药物在体内分布的因素有:()E A. 药物的理化性质和局部器官的血流量 B. 各种细胞膜屏障 C. 药物与血浆蛋白的结合率 D. 体液pH和药物的解离度 E. 所有这些 满分:1 分 6. SFDA推荐的首选的生物等效性的评价方法为:()C A. 体外研究法 B. 体内研究法 C. 药动学评价方法 D. 药效学评价方法 E. 临床比较试验法 满分:1 分 7. 关于临床前药物代谢动力学血药浓度时间曲线的消除相采样点哪个不符合要求?()D A. 3 B. 4 C. 5 D. 6 E. 7 满分:1 分 8. 静脉注射2g某磺胺药,其血药浓度为100mg/L,经计算其表观分布容积为:()D A. 0.05L B. 2L C. 5L D. 20L E. 200L 满分:1 分 9. Ⅰ期临床药物代谢动力学试验时,下列的哪条是错误的?()E A. 目的是探讨药物在人体的体内过程的动态变化 B. 受试者原则上男性和女性兼有 C. 年龄在18~45岁为宜 D. 要签署知情同意书 E. 一般选择适应证患者进行 满分:1 分 10. 在酸性尿液中弱碱性药物:()B A. 解离多,再吸收多,排泄慢 B. 解离多,再吸收多,排泄快 生物药剂学与药物动力学习题 一、单项选择题 1.以下关于生物药剂学的描述,正确的是 A.剂型因素是指片剂、胶囊剂、丸剂和溶液剂等药物的不同剂型 B.药物产品所产生的疗效主要与药物本身的化学结构有关C.药物效应包括药物的疗效、副作用和毒性 D.改善难溶性药物的溶出速率主要是药剂学的研究内容 2. K+、单糖、氨基酸等生命必需物质通过生物膜的转运方式是A.被动扩散 B.膜xx转运 C.主动转运D.促进扩散 E.膜动转运 3.以下哪条不是主动转运的特点 A.逆浓度梯度转运 B.无结构特异性和部住特异性 C.消耗能量D.需要载体参与 E.饱和现象 4.胞饮作用的特点是 A.有部位特异性 B.需要载体 C.不需要消耗机体能量D.逆浓度梯度转运 E.以上都是 5.药物的主要吸收部位是 A.胃B.小肠 C.大肠D.直肠 E.均是 6.药物的表观分布容积是指 A.人体总体积B.人体的体液总体积 C.游离药物量与血药浓度之比D.体内药量与血药浓度之比E.体内药物分布的实际容积 7.当药物与蛋白结合率较大时,则 A.血浆中游离药物浓度也高 B.药物难以透过血管壁向组织分布 C.可以通过肾小球滤过 D.可以经肝脏代谢 E.药物跨血脑屏障分布较多 8.药物在体内以原形不可逆消失的过程,该过程是 A.吸收 B.分布 C.代谢 D.排泄 E.转运 9.药物除了肾排泄以外的最主要排泄途径是 A.胆汁 B.汗腺C.唾液腺 D.泪腺E。呼吸系统 10.可以用来测定肾小球滤过率的药物是 A.青霉素 B.链霉素C.菊粉 D.葡萄糖 E.乙醇 11.肠肝循环发生在哪一排泄中 A.肾排泄B.胆汁排泄C.乳汁排泄 D.肺部排泄 E.汗腺排泄 12.最常用的药物动力学模型是 A.隔室模型 B.药动一药效结合模型 C.非线性药物动力学模型 D.统计矩模型 E.生理药物动力学模型 13.药物动力学是研究药物在体内的哪一种变化规律 A.药物排泄随时间的变化 扩展Excel的功能 XLfit是一个可在Microsoft? Excel操作环境下使用的强大曲线拟合和数据分析工具。作为一款同类产品中绝无仅有的应用程序,Xlfit提供一系列可供选择的分析和计算工具,包括各种拟合和统计模型、增强结果的可视化处理和预览功能-- --一切都可在Excel环境下实现。 XLfit contains XLfit包含一个强大的统计引擎,能为用户生成线性和非线性曲线、平稳结果、统计分析、结果值权重,以及显示误差线。这款功能强大的Microsoft?Excel配套工具可为2D和3D图表提供快速地数据分析和关键的拟合信息功能。此外,您还可轻松导出绘制成图的数据,以用于外部演示文稿和文档。 视图效果更佳 全新版本的XLfit桌面能让用户全面查看可操作和分析的所有潜在拟合项目和工作表。 为什么选择XLfit? ?与Excel的整合 它是一款同类产品中绝无仅有的应用程序,能够在Microsoft Excel环境下提供强大的曲线 拟合和统计分析功能。 ?交互式图表类型 通过使用可轻松访问的上下文相关菜单和即时预览更改来编辑图表,然后将其应用至工作 表中。 ?质量保证 独立验证,让用户对结果更有信心。 ?完善的数学工具箱 standard综合模型库(如PA2)将快速结果的生成、整体拟合、自动异常值的拒绝、敲入/ 敲出功能全部作为标准功能。 ?轻松迁移 XLfit的最新版本可与此前的Xlfit第4版本兼容,从而能够轻松实现单个或批量工作表迁移。 点击式编辑 Excel用户也将 发现,他们凭直觉就会使用Xlfit 了。XLfit 向导的三个步骤将自始 至终指导用户完成整个曲线拟合 过程,而完全交互式图表和拟合设 计器则让您可以立即编辑图表数 据和显示方式。 完全交互式预览 XLfit推出后,设计器界面 已经过重新设计,使访问 更轻松,操作更简易。在 将图表输出至工作表之 前,您可使用配备的预览 窗格来选择应用或放弃 图表编辑。对应用性能和 先前版本升级过程的改 进也增强了XLfit用户的 使用体验。 灵活的格式设置 全新XLfit图表设计器可让您 自定义图表外观的方方面面。 例如,您可以修改: ?图表背景和边框 ?轴的样式、刻度和原点 曲线样式和颜色 第十三章 药动学数据的曲线拟合以及常用软件 计算药动学参数,是药代动力学进一步应用的基础。如何测定有关的动力学参数呢?常用的方法是:首先在用药后的若干不同时间,采取血样(或尿样),测定其血药浓度值或尿中药量(这些数值称为实测值或观察值,用C i 表示),这样就有了药物浓度经时曲线数据;然后,依据半对数坐标图,选定一种模型方程 (是时间t 的曲线函数)计算理论估算值(用i C )表示),按照观察值和理论估算值之 差的平方和(即残差平方和)或加权残差平方和(均用Re 表示)最小的原则,采用适当的算法,求出有关的动力学参数。这种方法,在数学上称为曲线拟合(fitting a curve)。由于所采用的线性药代动力学的模型方程是多指数项之和的函数形式,并且是所含动力学参数的非线性函数,所以这种曲线拟合方法称为非线性最小二乘法。 一、最小二乘法的一般原理 设y 是变量x 的函数,含有m 个待定参数a 1,a 2,…,a m 。记为 y =f (x ;a 1,a 2,…,a m ) 若对x 和y 作n 次观察,测得观察值(x 1,y 1),(x 2,y 2),…,(x n ,y n )。根据这样一组二维数据,即平面上的若干点,要求确定这个一元函数y =f (x ;a 1,a 2,…,a m );(i=1,2,…,n),即一条曲线,使这些点与曲线总体来说尽量接近。并使y 的观察值y i 与理论估算值=i y )f (x i ;a 1,a 2,…,a m ) ;(i=1,2,…,m)的误差平方和,即残差平方和21 ()n e i i i y y ==?∑)2121((,,,,)n i i m i y f x a a a ==?…∑R )i 取得最小值, 或者加权残差平方和21()/n e i i i R y y w ==?∑)2121 ((,,,,))/n i i m i i y f x a a a w ==?…∑ 取得 最小值。其中w i 称为权重系数,在后面的段落会详细讲解。这时Re 有时候也称为目标函数。这就是数据拟合成曲线的思想,简称为曲线拟合。曲线拟合的目的是根据实验获得的数据去建立因变量和自变量之间有效的函数关系,这个函数关系对于药动学来讲就是通过房室模型推导出来的药时曲线公式。根据观察值求出待 311 药物代谢动力学 一、最佳选择题 1、决定药物每天用药次数的主要因素是 A、吸收快慢 B、作用强弱 C、体内分布速度D体内转化速度E、体内消除速度 2、药时曲线下面积代表 A、药物血浆半衰期 B、药物的分布容积 C、药物吸收速度 D、药物排泄量 E、生物利用度 3、需要维持药物有效血浓度时,正确的恒定给药间隔时间是 A、每4h给药一次 B、每6h给药一次 C、每8h给药一次 D、每12h给药一次 E、每隔一个半衰期给药一次 4、以近似血浆半衰期的时间间隔给药,为迅速达到稳态血浓度,可以首次剂量 A、增加半倍 B、增加1倍 C、增加2倍 D、增加3倍 E、增加4倍 5、某药的半衰期是7h,如果按每次0.3g, —天给药3次,达到稳态血药浓度所需时间是 A、5?10h B、10?16h C、17?23h D、24 ?28h E、28 ?36h 6、按一级动力学消除的药物,按一定时间间隔连续给予一定剂量,达到稳态血药浓度时间长短决定于 A、剂量大小 B、给药次数 C、吸收速率常数 D、表观分布容积E消除速率常数 7、恒量恒速给药最后形成的血药浓度为 A、有效血浓度 B、稳态血药浓度 C、峰浓度 D、阈浓度 E、中毒浓度 8、药物吸收到达血浆稳态浓度时意味着 A、药物作用最强 B、药物吸收过程已完成 C、药物消除过程正开始 D、药物的吸收速度与消除速率达到平衡 E、药物在体内分布达到平衡 9、按一级动力学消除的药物有关稳态血药浓度的描述中错误的是 A、增加剂量能升高稳态血药浓度 B、剂量大小可影响稳态血药浓度到达时间 C、首次剂量加倍,按原间隔给药可迅速达稳态血药浓度 D、定时恒量给药必须经4?6个半衰期才可达稳态血药浓度 E、定时恒量给药达稳态血药浓度的时间与清除率有关 10、按一级动力学消除的药物,其消除半衰期 A、与用药剂量有关 B、与给药途径有关 C、与血浆浓度有关 D、与给药次数有关 E、与上述因素均无关 11、某药按一级动力学消除,其血浆半衰期与消除速率常数k 的关系为 A、0.693/k B、k/0.693 C、2.303/k D、k/2.303 E、k/2 血浆药物浓度 12、对血浆半衰期(一级动力学)的理解,不正确的是 A、是血浆药物浓度下降一半的时间 B、能反映体内药量的消除速度 C、依据其可调节给药间隔时间 D、其长短与原血浆浓度有关 E、一次给药后经4?5个半衰期就基本消除 13、静脉注射1g某药,其血药浓度为10mg/ dl,其表观分布容积为 A、0.05 L B、2L C、5L D、10L E、20L 14、在体内药量相等时,Vd 小的药物比Vd 大的药物 A、血浆浓度较低 B、血浆蛋白结合较少 C、血浆浓度较高 D、生物利用度较小 E、能达到的治疗效果较强 15、下列叙述中,哪一项与表观分布容积(Vd)的概念不符 A、Vd 是指体内药物达动态平衡时,体内药量与血药浓度的比值 发布日期2007-11-01 栏目化药药物评价>>综合评价 标题群体药代动力学(译文) 作者康彩练 部门 正文内容 审评四部七室康彩练审校 I.前言 本指南是对药品开发过程中群体药代动力学的应用制定建议,目的是帮助确定在人群亚组中药品安全性和疗 效的差异。它概述了应当用群体药代动力学解决的科学问题和管理问题。本指南讨论了什么时候要进行群体 药代动力学研究和/或分析;讨论了如何设计和实施群体药代动力学研究;讨论了如何处理和分析群体药代动 力学数据;讨论了可以使用什么样的模型验证方法;讨论了针对计划申报给FDA的群体药代动力学报告,怎 样提供恰当的文件。虽然本行业指南中的内容是针对群体药代动力学,但是其中讨论的原则也同样适用于群 体药效学研究和群体毒代动力学研究2。 由于对药品在人群亚组中的安全性和疗效的分析是药品开发和管理中一个发展迅速的领域,所以在整个药品 开发过程中,鼓励主办者和FDA审评人员经常沟通。 制药行业科学家和FDA长期以来一直对群体药代动力学/药效学在人群亚组中药品安全性和疗效分析方面的 应用感兴趣[1]。在FDA的其他指南文件(包括“进行药品临床评价时一般要考虑的问题”(General Considerations for the Clinical Evaluation of Drugs) (FDA 77-3040))中和在国际协调会议(ICH)指南(包 括“E4支持药品注册的剂量-效应资料”(E4 Dose-Response Information to Support Drug Registration)和“E7 支持特殊人群的研究:老年医学”(E7 St udies in Support of Special Populations: Geriatrics))中,对这个主 题制定了参考标准3。这些指南文件支持使用特殊的数据收集方法和分析方法,例如群体药代动力学方法(群 体PK方法),作为药品开发中药代动力学评价的一部分。 1本指南由药品评审和研究中心(CDER)医药政策协调委员会临床药理学部群体药代动力学工作组与食品 药品监督管理局生物制品评审和研究中心(CBER)合作编写。本指南文件反映了当前FDA对药品评价中的 群体药代动力学的考虑。它不给任何人也不代表任何人创造或赋予任何权力,也不约束FDA或公众。如果其 他措施满足适用法令、法规或两者的要求,那么也可采用其他措施。 概念 最小二乘法多项式曲线拟合,根据给定的m个点,并不要求这条曲线精确地经过这些点,而是曲线y=f(x)的近似曲线y= φ(x)。 原理 [原理部分由个人根据互联网上的资料进行总结,希望对大家能有用] 给定数据点pi(xi,yi),其中i=1,2,…,m。求近似曲线y= φ(x)。并且使得近似曲线与y=f(x)的偏差最小。近似曲线在点pi处的偏差δi= φ(xi)-y,i=1,2,...,m。 常见的曲线拟合方法: 1.使偏差绝对值之和最小 2.使偏差绝对值最大的最小 3.使偏差平方和最小 按偏差平方和最小的原则选取拟合曲线,并且采取二项式方程为拟合曲线的方法,称为最小二乘法。 推导过程: 1. 设拟合多项式为: 2. 各点到这条曲线的距离之和,即偏差平方和如下: 3. 为了求得符合条件的a值,对等式右边求ai偏导数,因而我们得到了: ....... 4. 将等式左边进行一下化简,然后应该可以得到下面的等式: ....... 5. 把这些等式表示成矩阵的形式,就可以得到下面的矩阵: 6. 将这个范德蒙得矩阵化简后可得到: 7. 也就是说X*A=Y,那么A = (X'*X)-1*X'*Y,便得到了系数矩阵A,同时,我们也就得到了拟合曲线。 实现 运行前提: 1. Python运行环境与编辑环境; 2. Matplotlib.pyplot图形库,可用于快速绘制2D图表,与matlab中的plot 命令类似,而且用法也基本相同。 代码: [python]view plain copy 1.# coding=utf-8 2. 3.''''' 4.作者:Jairus Chan 5.程序:多项式曲线拟合算法 6.''' 7.import matplotlib.pyplot as plt 8.import math 9.import numpy 10.import random 11. 12.fig = plt.figure() 13.ax = fig.add_subplot(111) 14. 15.#阶数为9阶 16.order=9 17. 18.#生成曲线上的各个点 19.x = numpy.arange(-1,1,0.02) 20.y = [((a*a-1)*(a*a-1)*(a*a-1)+0.5)*numpy.sin(a*2) for a in x] 21.#ax.plot(x,y,color='r',linestyle='-',marker='') 22.#,label="(a*a-1)*(a*a-1)*(a*a-1)+0.5" 23. 24.#生成的曲线上的各个点偏移一下,并放入到xa,ya中去 25.i=0 26.xa=[] 27.ya=[] 28.for xx in x: 29. yy=y[i] 30. d=float(random.randint(60,140))/100 31.#ax.plot([xx*d],[yy*d],color='m',linestyle='',marker='.') 32. i+=1 33. xa.append(xx*d) 34. ya.append(yy*d) 35. 36.'''''for i in range(0,5): 37. xx=float(random.randint(-100,100))/100 38. yy=float(random.randint(-60,60))/100 39. xa.append(xx) 40. ya.append(yy)''' 41. 42.ax.plot(xa,ya,color='m',linestyle='',marker='.') 43. 44. 45.#进行曲线拟合 46.matA=[] 47.for i in range(0,order+1):matlab曲线拟合2010a演示
Boltzmann 函数曲线拟合的 Lisp 程序
Matlab曲线拟合及工具箱简介
药物动力学复习题及答案
曲线拟合C语言程序
药物代谢动力学的研究
药物动力学模型 数学建模
最新整理《药物代谢动力学》教程文件
生物药剂学与药代动力学
Excel里的曲线拟合工具-- XLFit
第十三章 曲线拟合以及常用的药代动力学软件
药物代谢动力学(20201101084331)
群体药代动力学解读
python曲线拟合原理代码
相关主题
文本预览