第十一章一元线性回归
11.1从某一行业中随机抽取12家企业,所得产量与生产费用的数据如下:
要求:
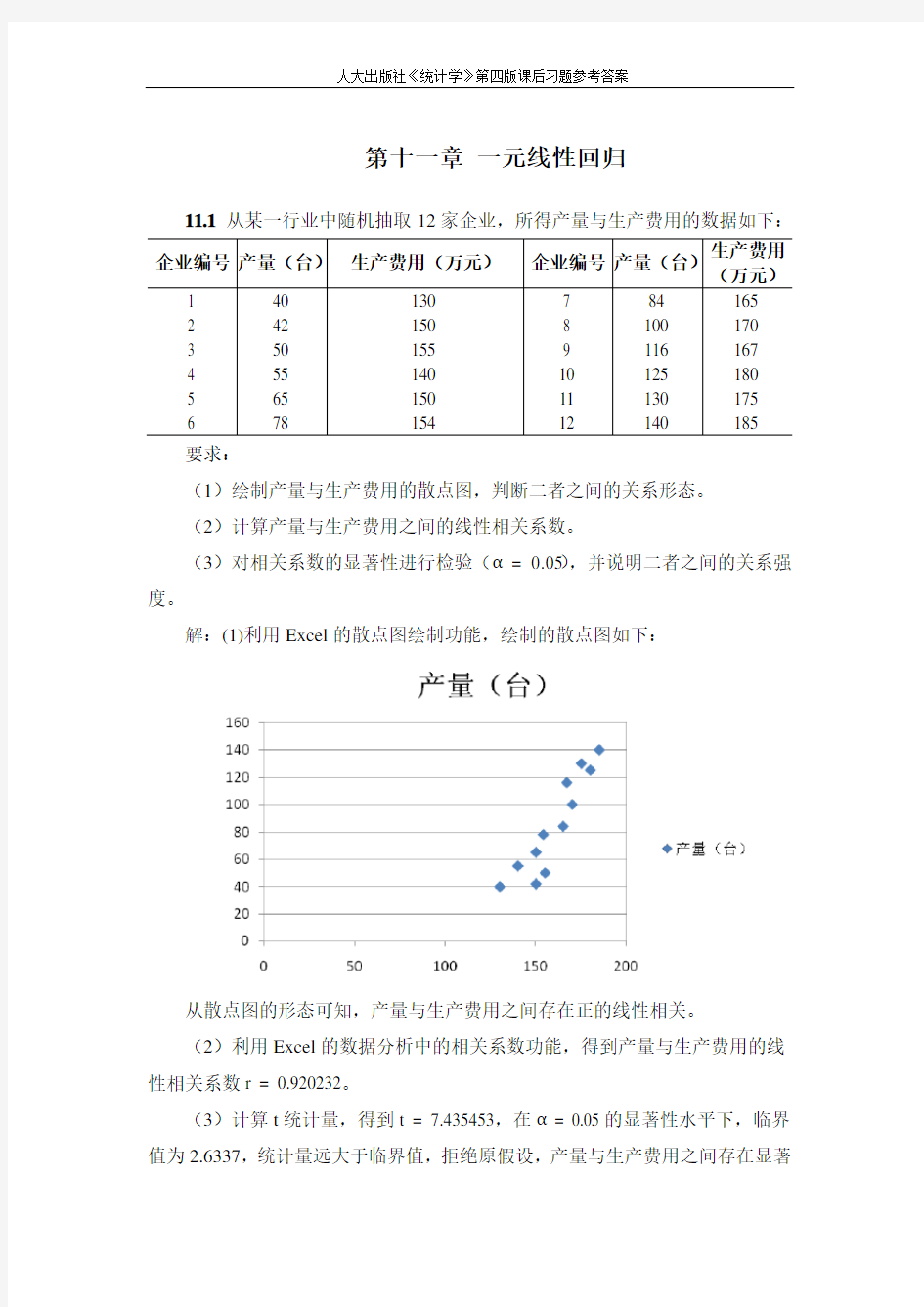
(1)绘制产量与生产费用的散点图,判断二者之间的关系形态。
(2)计算产量与生产费用之间的线性相关系数。
(3)对相关系数的显著性进行检验(α = 0.05),并说明二者之间的关系强度。
解:(1)利用Excel的散点图绘制功能,绘制的散点图如下:
从散点图的形态可知,产量与生产费用之间存在正的线性相关。
(2)利用Excel的数据分析中的相关系数功能,得到产量与生产费用的线性相关系数r = 0.920232。
(3)计算t统计量,得到t = 7.435453,在α = 0.05的显著性水平下,临界值为2.6337,统计量远大于临界值,拒绝原假设,产量与生产费用之间存在显著
的正线性相关关系。r大于0.8,高度相关。
11.2 学生在期末考试之前用于复习的时间(单位:h)和考试分数(单位:分)之间是否有关系?为研究这一问题,以为研究者抽取了由8名学生构成的一个随机样本,得到的数据如下:
要求:
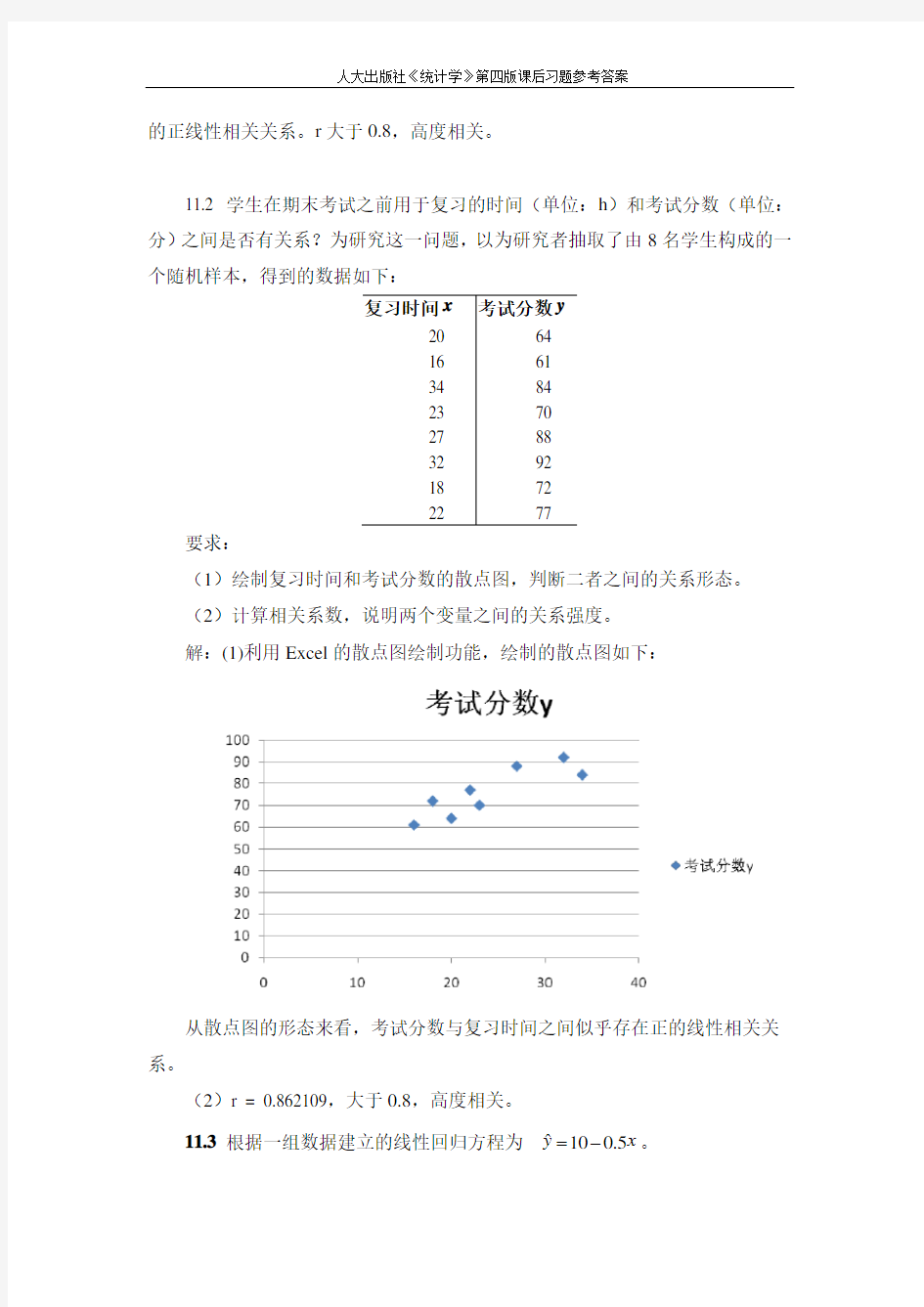
(1)绘制复习时间和考试分数的散点图,判断二者之间的关系形态。
(2)计算相关系数,说明两个变量之间的关系强度。
解:(1)利用Excel的散点图绘制功能,绘制的散点图如下:
从散点图的形态来看,考试分数与复习时间之间似乎存在正的线性相关关系。
(2)r = 0.862109,大于0.8,高度相关。
11.3根据一组数据建立的线性回归方程为?100.5
=-。
y x
要求:
?β的意义。
(1)解释截距
?β意义。
(2)解释斜率
1
(3)计算当x = 6时的E(y)。
解:(1)在回归模型中,一般不能对截距项赋予意义。
?β的意义为:当x增加1时,y减小0.5。
(2)斜率
1
(3)当x = 6时,E(y) = 10 – 0.5 * 6 = 7。
11.4 设SSR = 36,SSE = 4,n = 18。
要求:
(1)计算判定系数R2并解释其意义。
(2)计算估计标准误差s e并解释其意义。
解:SST = SSR+SSE = 36+4 = 40,
R2 = SSR / SST = 36 /40 = 0.9,意义为自变量可解释因变量变异的90%,自因变量与自变量之间存在很高的线性相关关系。
s== 0.5,这是随机项的标准误差的估计值。
(2)
e
11.5一家物流公司的管理人员想研究货物的运送距离和运送时间的关系,因此,他抽出了公司最近10辆卡车运货记录的随机样本,得到运送距离(单位:km)和运送时间(单位:天)的数据如下:
要求:
(1)绘制运送距离和运送时间的散点图,判断二者之间的关系形态。 (2)计算线性相关系数,说明两个变量之间的关系强度。
(3)利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 解:
(1)利用Excel 绘制散点图,如下:
从散点图的形态来看,运送时间和运送距离之间存在正的线性相关关系。 (2)计算的相关系数为0.9489,这是一个很高的相关系数。
(3)用OLS 方法估计得到模型参数为0?β= 0.118129,1?β= 0.003585, 回归方程为:运送时间 = 0.118129 + 0.003*运送距离,意义为:运送距离每增加1km ,运送时间增加0.003383天,即0.086小时。
11.6 下面是7个地区2000年的人均国内生产总值(GDP )和人均消费水平的统计数据:
地区 人均GDP (元)
人均消费水平(元)
北京
22460 7326 辽宁 11226 4490 上海 34547 11546 江西 4851 2396 河南 5444 2208 贵州
2662
1608
陕西 4549 2035
要求:
(1)人均GDP 作自变量,人均消费水平左因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(α = 0.05)。
(6)如果某地区的人均GDP 为5000元,预测其人均消费水平。 (7)求人均GDP 为5000元时,人均消费水平95%的置信区间和预测区间。 解:
(1)利用Excel 绘制的散点图如下:
从散点图来看,人均消费水平与人均GDP 之间存在很强的正线性相关关系。 (2)r = 0.998,高度相关。
(3)用OLS 方法估计得到模型参数为0?β= 734.69,1
?β= 0.308,回归方程为:
人均消费水平 = 734.69 + 0.308*人均GDP ,
意义为:人均GDP 每增加1元,人均消费水平增加0.31元,此值即为经济学中的边际消费倾向。这里截距可解释为人均GDP 为0时,居民的消费支出为734元/年,即经济学中的自发支出。
(4)判定系数R 2 = 0.996,人均消费水平变异的99%可由人均GDP 来解释。 (5)这是一个一元线性回归模型,只需要检验斜率系数的显著性即可。斜率系数的t 统计量
1?0.308/0.0085=36.49e
t s β==, 显著性水平为0.05,自由度为7-2=5,临界值为3.16,统计量远大于临界值,是高度显著的。
(6)将人均GDP 代入到估计的回归方程,计算得到人均消费水平的期望值为2278元。
(7)查表得2(72) 2.570582t α-=,点估计值为2278元,标准误差为247.3035, 人均消费水平95%的置信区间为
22782278287.27±=± 即(1990.73,2565.27)。
而人均消费水平95%的预测区间为
22782278697.21±=± 即区间(1580.79,2975.21),对个别值的预测精确度比对总体均值的预测低。
11.7 随机抽取10家航空公司,对其最近一年的航班正点率和顾客投诉次数进行了调查,所得数据如下:
要求:
(1)绘制散点图,说明二者之间的关系形态。
(2)用航班正点率左自变量,顾客投诉次数左因变量,求出估计的回归方程,并解释回归系数的意义。
(3)检验回归系数的限制性(α=0.05)。
(4)如果航班正点率为80%,估计顾客投诉次数。
(5)求航班正点率为80%时,顾客投诉次数95%的置信区间和预测区间。 解:(1)散点图如下。
从散点图的形态来看,航班正点率与顾客投诉次数之间有负的线性相关关系。
(2)用Excel 回归分析,得到估计的回归方程如下:
=430.1892 4.70062*-顾客投诉次数航班正点率
斜率系数为-4.70062,表示航班正点率提高1个百分点,顾客投诉次数减少4.7次。符号为负,与理论相符。截距系数一般不赋予意义。
(3)一元回归只要检验斜率系数的显著性即可。斜率西数的t 统计量为
1? 4.70062/0.947894= 4.95902e
t s β==-- 相应的P 值为0.001108,小于0.05,t 统计量是显著的。
(4)由估计的回归方程,得到果航班正点率为80%,估计顾客投诉次数为 430.1892 - 4.70062*80 = 54.1396(次)
(5)查表得
2(102) 2.306004
t
α
-=,点估计值为54.1396元,标准误差为18.887,故置信区间为
54.139616.47989
±±
即区间(37.6597,70.61949)。
而预测区间为
54.139646.56756
±±
即区间(7.57204,100.7071)
11.8下面是20个城市写字楼由出租率和每平方米月租金的数据。
设月租金为自变量,出租率为因变量,用Excel进行回归,并对结果进行解释和分析。
解:回归分析结果如下:
SUMMARY OUTPUT
回归统计
Multiple R 0.7950
8
R Square 0.6321
51
Adjusted R Square 0.6117
15
标准误差2.6858
19
观测值20方差分析
df SS MS F
Significa nce F
回归分析1223.1
403
223.1
403
30.93
318
2.8E-05
残差18129.8
452
7.213
622
总计19352.9 855
Coeffi cients
标准
误差
t Stat
P-val
ue
Lower
95%
Upper
95%
下限
95.0%
Intercept 49.317
68
3.805
016
12.96
123
1.45E
-10
41.32364
57.31
172
41.323
64
X Variable 10.2492
23
0.044
81
5.561
761
2.8E-
05
0.15508
0.343
365
0.1550
8
结果分析如下:
(1)斜率系数的t统计量在95%的显著性水平下是高度显著的,斜率系数等于0.2492,表示每平方米月租金提高1元,出租率将提高0.2492个百分点。
(2)判断系数R2等于6321,表示出租率的变异可由月租金解释63.21%。判断系数不算很高,可能还有其它的变量影响出租率。
11.9 某汽车生产商欲了解广告费用(x)对销售量(y)的影响,收集了过
去12年的有关数据。通过计算得到下面的有关结果:
方差分析表
参数估计表
要求:
(1)完成上面的方差分析表。
(2)汽车销售量的变差中有多少是由广告费用的变动引起的? (3)销售量与广告费用之间的相关系数是多少? (4)写出估计的回归方程并解释回归系数的实际意义。 (5)检验线性关系的显著性(α=0.05)。
解:(1)此为一元线性回归,由自由度可知,样本容量n = (11+1)=12。由此可计算各自由度和SS 。进而计算各均方误,最后计算出F 统计量(MSR/MSE )。结果如下:
方差分析表
(2)计算判断系数,
21602708.6
R =
0.97551642866.67
SSR SST ==
表明销售量的变异有97.55%是由广告费用的变东引起的。
(3)一元线性回归模型中,相关系数等于判断系数的平方根,即r =0.9877。 (4)根据估计得到的模型参数,回归方程如下:
?363.68911.420211i i y
x =+ 表示广告费用增加1单位,销售量将平均增加1.42单位。
(5)由参数估计表可知,斜率系数的t 统计量等于19.97749,这是一个在显著性水平0.05下高度显著的统计量。
11.10 根据下面的数据建立回归方程,计算残差,判断系数R 2,估计标准误差s e ,并分析回归方程的拟合优度。
8 36 19 56 12 44 5
21
第十一章一元线性回归 11.1从某一行业中随机抽取12家企业,所得产量与生产费用的数据如下: 要求: (1)绘制产量与生产费用的散点图,判断二者之间的关系形态。 (2)计算产量与生产费用之间的线性相关系数。 (3)对相关系数的显著性进行检验(α = 0.05),并说明二者之间的关系强度。 解:(1)利用Excel的散点图绘制功能,绘制的散点图如下: 从散点图的形态可知,产量与生产费用之间存在正的线性相关。 (2)利用Excel的数据分析中的相关系数功能,得到产量与生产费用的线性相关系数r = 0.920232。 (3)计算t统计量,得到t = 7.435453,在α = 0.05的显著性水平下,临界值为2.6337,统计量远大于临界值,拒绝原假设,产量与生产费用之间存在显著
的正线性相关关系。r大于0.8,高度相关。 11.2 学生在期末考试之前用于复习的时间(单位:h)和考试分数(单位:分)之间是否有关系?为研究这一问题,以为研究者抽取了由8名学生构成的一个随机样本,得到的数据如下: 要求: (1)绘制复习时间和考试分数的散点图,判断二者之间的关系形态。 (2)计算相关系数,说明两个变量之间的关系强度。 解:(1)利用Excel的散点图绘制功能,绘制的散点图如下: 从散点图的形态来看,考试分数与复习时间之间似乎存在正的线性相关关系。 (2)r = 0.862109,大于0.8,高度相关。 11.3根据一组数据建立的线性回归方程为?100.5 =-。 y x
要求: ?β的意义。 (1)解释截距 ?β意义。 (2)解释斜率 1 (3)计算当x = 6时的E(y)。 解:(1)在回归模型中,一般不能对截距项赋予意义。 ?β的意义为:当x增加1时,y减小0.5。 (2)斜率 1 (3)当x = 6时,E(y) = 10 – 0.5 * 6 = 7。 11.4 设SSR = 36,SSE = 4,n = 18。 要求: (1)计算判定系数R2并解释其意义。 (2)计算估计标准误差s e并解释其意义。 解:SST = SSR+SSE = 36+4 = 40, R2 = SSR / SST = 36 /40 = 0.9,意义为自变量可解释因变量变异的90%,自因变量与自变量之间存在很高的线性相关关系。 s== 0.5,这是随机项的标准误差的估计值。 (2) e 11.5一家物流公司的管理人员想研究货物的运送距离和运送时间的关系,因此,他抽出了公司最近10辆卡车运货记录的随机样本,得到运送距离(单位:km)和运送时间(单位:天)的数据如下:
计量经济学第三章、经典单方程计量经济学模型:多元线性回归模型
第三章、经典单方程计量经济学模型:多元线性 回归模型 一、内容提要 本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。 本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。 本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。这里需要注
意各回归参数的具体经济含义。 本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。它们仍以估计无约束模型与受约束模型为基础,但以最大似然原理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2χ分布为检验统计量的分布特征。非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。 二、典型例题分析 例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为 . 10+ 36 + = - .0 .0 medu fedu sibs edu210 131 .0 094
一元线性回归分析的结果解释 1.基本描述性统计量 分析:上表是描述性统计量的结果,显示了变量y和x的均数(Mean)、标准差(Std. Deviation)和例数(N)。 2.相关系数 分析:上表是相关系数的结果。从表中可以看出,Pearson相关系数为0.749,单尾显著性检验的概率p值为0.003,小于0.05,所以体重和肺活量之间具有较强的相关性。 3.引入或剔除变量表
分析:上表显示回归分析的方法以及变量被剔除或引入的信息。表中显示回归方法是用强迫引入法引入变量x的。对于一元线性回归问题,由于只有一个自变量,所以此表意义不大。 4.模型摘要 分析:上表是模型摘要。表中显示两变量的相关系数(R)为0.749,判定系数(R Square)为0.562,调整判定系数(Adjusted R Square)为0.518,估计值的标准误差(Std. Error of the Estimate)为0.28775。 5.方差分析表 分析:上表是回归分析的方差分析表(ANOVA)。从表中可以看出,回归的均方(Regression Mean Square)为1.061,剩余的均方(Residual Mean Square)为0.083,F检验统计量的观察值为12.817,相应的概率p 值为0.005,小于0.05,可以认为变量x和y之间存在线性关系。
6.回归系数 分析:上表给出线性回归方程中的参数(Coefficients)和常数项(Constant)的估计值,其中常数项系数为0(注:若精确到小数点后6位,那么应该是0.000413),回归系数为0.059,线性回归参数的标准误差(Std. Error)为0.016,标准化回归系数(Beta)为0.749,回归系数T检验的t统计量观察值为3.580,T检验的概率p值为0.005,小于0.05,所以可以认为回归系数有显著意义。由此可得线性回归方程为: y=0.000413+0.059x 7.回归诊断 分析:上表是对全部观察单位进行回归诊断(Casewise Diagnostics-all cases)的结果显示。从表中可以看出每一例的标准
第十一章一元线性回归练习题答案 二.填空题 1. 不能;因为该相关系数为样本计算出的相关系数,它的大小受样本数据波动的影响,它是否显著尚需 检验;t 检验; 2. 图1;不能;因为图1反映的是线性相关关系,图2反映的是非线性性相关关系,相关系数只能反映 线性相关变量间的相关性的强弱,不能反映非线性相关性的强弱。 三.计算题 1.(1) SSR 的自由度是1,SSE 的自由度是18。 (2)2418 /6080220/1/==-= SSE SSR F (3)判定系数%14.57140 802 === SST SSR R 在y 的总变差中,由57.14%的变差是由于x 的变动说引起的。 (4)7559.05714.02-=-=-=R r 相关系数为-0.7559。 (5)线性关系显著和:线性关系不显著 和y x y x H 10H : 因为414.424=>=αF F ,所以拒绝原假设,x 与y 之间的线性关系显著。 2.(1) 方差分析表 df SS MS F Significance F 回归分析 1 425 425 85 0.017 残差 15 75 5 - - 总计 16 500 - - - (2)判定系数%8585.0500 425 2 ==== SST SSR R 表明在维护费用的变差中,有85%的变差可由使用年限来解释。 (3)9220.085.02===R r 二者相关系数为0.9220,属于高度相关 (4) x y 248.1388.6?+= 分布;显著。 的自由度为t n r n r t 2);12 ||2 ---=
回归系数为1.248,表示每增加一个单位的产量,该行业的生产费用将平均增长1.248个单位。 (5)线性关系显著性检验: 线性关系显著 :生产费用和产量之间性关系不显著生产费用和产量之间线10:H H 因为Significance F=0.017<05.0=α,所以线性关系显著。 (6) 348.3120248.1388.6248.1388.6?==?++=x y 当产量为10时,生产费用为31.348万元。
第五章回归分析 §1.回归分析的数学模型 1.1.线性统计模型 1.线性回归方程 从一个简单的例子谈起。个人的消费水平Y与他的收入水平X间的关系,大体上可以描述:收入水平高,一般消费水平也高。但Y 和X绝不是简单的线性关系,这从常识便能判别;而且也不是一种确定的数学关系,两个收入水平完全一样的个人,他们的消费水平可能有很大的差异。比较合理的看法是:个人的消费水平Y是一个随机变量,从平均的意义上看,应与收入水平成正比。因此,我们可以给出以下模型: Y = b0 + b1X +ε (1) 其中b0,b1是待定常数,ε是随机变量,且有E(ε)=0,这样就能保证 E(Y) = b0 + b1X (2) 即从平均意义上Y和X线性相关。等式(2)称为变量Y对于变量X的线性回归方程。一般情况下,一个随机变量Y与变量X1,X2,…,X p有关系
Y = b0 + b1X1 + b2X2 + … + b p X p +ε (3) 随机变量ε的期望E(ε)=0,即有: E(Y) = b0+ b1X1 + b2X2+ … + b p X p (4) 从平均意义上,Y与X1,X2,…,X p呈线性关系。(4)式称为变量Y对于变量X1,X2,…,X p的线性回归方程,p=1时,称方程是一元的;p≥2时,称方程是多元的;b0,b1,…,b p称为回归系数。 2.统计模型的假设 设变量Y与X1,X2,…,X p之间有关系(3),对(X1,X2,…,X p,Y)做n 次观察,得到一个容量为n的样本:(x i1,x i2, …,x i p,y i)i=1,2,…,n,按(4)式给出的关系,这些样本观察值应有: y1= b0+ b1x11+ b2x12 + … + b p x1p+ε1 y2= b0+ b1x21+ b2x22 + … + b p x2p+ε2 (5) ………………………………… y n= b0+ b1x n1+ b2x n2 + … + b p x n p+εn 其中的εi, i=1,2,…,n是随机误差,出于数学上推导的需要,假设:1)E(εi)=0,i=1,2,…,n.即观察结果没有系统误差; 2)Var(εi)=σ2,i=1,2,…,n.这个性质叫做方差齐性;
第三章 一元线性回归模型 一、预备知识 (一)相关概念 对于一个双变量总体),(i i x y ,若由基础理论,变量x 和变量y 之间存在因果关系,或x 的变异可用来解释y 的变异。为检验两变量间因果关系是否存在、度量自变量x 对因变量y 影响的强弱与显著性以及利用解释变量x 去预测因变量 y ,引入一元回归分析这一工具。 将给定i x 条件下i y 的均值 i i i x x y E 10)|(ββ+= (3.1) 定义为总体回归函数(Population Regression Function,PRF )。定义 )|(i i i x y E y -为误差项(error term ),记为i μ,即)|(i i i i x y E y -=μ,这样i i i i x y E y μ+=)|(,或 i i i x y μββ++=10 (3.2) (3.2)式称为总体回归模型或者随机总体回归函数。其中,x 称为解释变量(explanatory variable )或自变量(independent variable );y 称为被解释变量(explained variable )或因变量(dependent variable );误差项μ解释了因变量的变动中不能完全被自变量所解释的部分。误差项的构成包括以下四个部分: (1)未纳入模型变量的影响 (2)数据的测量误差 (3)基础理论方程具有与回归方程不同的函数形式,比如自变量与因变量之间可能是非线性关系 (4)纯随机和不可预料的事件。 在总体回归模型(3.2)中参数10,ββ是未知的,i μ是不可观察的,统计计量分析的目标之一就是估计模型的未知参数。给定一组随机样本 n i y x i i ,,2,1),,( =,对(3.1)式进行估计,若10,),|(ββi i x y E 的估计量分别记为^ 1^ 0^ ,,ββi y ,则定义3.3式为样本回归函数 i i x y ^ 1^ 0^ ββ+= (n i ,,2,1 =) (3.3) 注意,样本回归函数随着样本的不同而不同,也就是说^ 1^ 0,ββ是随机变量,它们的随机性是由于i y 的随机性(同一个i x 可能对应不同的i y )与x 的变异共同引起的。定义^ i i y y -为残差项(residual term ),记为i e ,即^ i i i y y e -=,这样 i i i e y y +=^ ,或 i i i e x y ++=^ 1^0ββ (n i ,,2,1 =) (3.4)
4.4 在本章开始的“引子”提出的“国内生产总值增加会减少财政收入吗?”的例子中,如果所采用的数据如表4.11所示 表4.11 1978-2011年财政收入及其影响因素数据 (资料来源:《中国统计年鉴2008》,中国统计出版社2008年版)
试分析:为什么会出现本章开始时所得到的异常结果?怎样解决所出现的问题? 【练习题4.4参考解答】 建议学生自己独立完成 由于模型存在严重的多重共线性,导致模型的回归系数不稳定,且回归系数的符号与相关图的分析不一致。 一、财政收入理论模型建立 由经济理论可知,一个国家或地区的经济发展是财政收入的来源,经济发展水平越高或者经济总量越大的地区,财政收入就越有充足的來源,一般地衡量一国的经济发展水平我们采用国内生产总值反映,故国内生产总值是影响财政收入的一个因素;税收是财政收入的主要形式,税收规模越大, 财政收入越多,税收收入是影响财政收入的一个重要因素;由以支定收财政理论可知,财政支出是政府为提供公共产品和服务,满足社会共同需要而进行的财政资金的支付,财政支出水平越高,政府提供公共产品与服务越多,需要的财政收入也越多,从这一角度而言,财政支出也是影响财政收入的一个因素。下列的相关图分析也说明了这一点。利用eviews 软件分别输入相关图命令: scat czzc czsr scat gdp czsr scat ssze czsr 得财政支出与财政收入、国内生产总值与财政收入、税收收入与财政收入的相关图,如图一所示: 图一 变量之间的相关图 由相关图可知,财政支出、国内生产总值、税收收入分别与财政收入之间呈现出一种正的线性关系,综上所述,初步将财政收入理论模型定为线性回归模型: t t t t t u ssze GDP czzc czsr +++=4321ββββ+ 其中,czsr 表示财政收入、czzc 表示财政支出、GDP 表示国内生产总值、ssze 表示税
第10章 简单线性回归分析 思考与练习参考答案 一、最佳选择题 1.如果两样本的相关系数21r r =,样本量21n n =,那么( D )。 A. 回归系数21b b = B .回归系数12b b < C. 回归系数21b b > D .t 统计量11r b t t = E. 以上均错 2.如果相关系数r =1,则一定有( C )。 A .总SS =残差SS B .残差SS =回归 SS C .总SS =回归SS D .总SS >回归SS E. 回归MS =残差MS 3.记ρ为总体相关系数,r 为样本相关系数,b 为样本回归系数,下列( D )正确。 A .ρ=0时,r =0 B .|r |>0时,b >0 C .r >0时,b <0 D .r <0时,b <0 E. |r |=1时,b =1 4.如果相关系数r =0,则一定有( D )。 A .简单线性回归的截距等于0 B .简单线性回归的截距等于Y 或X C .简单线性回归的残差SS 等于0 D .简单线性回归的残差SS 等于SS 总 E .简单线性回归的总SS 等于0 5.用最小二乘法确定直线回归方程的含义是( B )。 A .各观测点距直线的纵向距离相等 B .各观测点距直线的纵向距离平方和最小 C .各观测点距直线的垂直距离相等 D .各观测点距直线的垂直距离平方和最小 E .各观测点距直线的纵向距离等于零 二、思考题 1.简述简单线性回归分析的基本步骤。 答:① 绘制散点图,考察是否有线性趋势及可疑的异常点;② 估计回归系数;③ 对总体回归系数或回归方程进行假设检验;④ 列出回归方程,绘制回归直线;⑤ 统计应用。 2.简述线性回归分析与线性相关的区别与联系。
第11章一元线性回归 1.具有相关关系的两个变量的特点是() A.一个变量的取值不能由另一个变量唯一确定 B.一个变量的取值由另一个变量唯一确定 C.一个变量的取值增大时,另一个变量的取值也一定增大 D.一个变量的取值增大时,另一个变量的取值肯定变小 2.下面的各问题中,哪个不是相关分析要解决的问题() A.判断变量之间是否存在关系 B.判断一个变量数值的变化对另一个变量的影响 C.描述变量之间的关系强度 D.判断样本所反映的变量之间的关系能否代表总体变量之间的关系 3.下面的假定中,哪个属于相关分析中的假定()
A.两个变量之间是非线性关系 B.两个变量都是随机变量 C.自变量是随机变量,因变量不是随机变量 D.一个变量的数值增大,另一个变量的数值也应增大 4.如果变量之间的关系近似地表现为一条直线,则称两个变量之间为()A.正线性相关关系 B.负线性相关关系 C.线性相关关系 D.非线性相关关系 5.如果一个变量的取值完全依赖于另一个变量,各观测点落在一条直线上,称为两个变量之间为() A.完全相关关系 B.正线性相关关系 C.非线性相关关系 D.负线性相关关系 6.下面的陈述哪一个是错误的() A.相关系数是度量两个变量之间线性关系强度的统计量
B.相关系数是一个随机变量 C.相关系数的绝对值不会大于1 D.相关系数不会取负值 7.如果相关系数r=0,则表明两个变量之间() A.相关程度很低 B.不存在任何关系 C.不存在线性相关关系 D.存在非线性相关关系 8.在回归分析中,被预测或被解释的变量称为() A.自变量 B.因变量 C.随机变量 D.非随机变量 9.在回归分析中,描述因变量y如何依赖于自变量x和误差项的方程称为()A.回归方程 B.估计的回归方程 C.回归模型 D.经验回归方程 中,ε反映的是10. 在一元回归模型ε β β+ + y =x 1
所属章节: 第五章相关分析与回归分析 1■在线性相关中,若两个变量的变动方向相反,一个变量的数值增加,另一个变量数值随之减少,或一个变量的数值减少,另一个变量的数值随之增加,则称为()。 答案: 负相关。干扰项: 正相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答: 本题的正确答案为: 负相关。 2■在线性相关中,若两个变量的变动方向相同,一个变量的数值增加,另一个变量数值随之增加,或一个变量的数值减少,另一个变量的数值随之减少,则称为()。 答案: 正相关。干扰项: 负相关。干扰项: 完全相关。干扰项: 非线性相关。 提示与解答:
本题的正确答案为: 正相关。 3■下面的xx中哪一个是错误的()。 答案: 相关系数不会取负值。干扰项: 相关系数是度量两个变量之间线性关系强度的统计量。干扰项: 相关系数是一个随机变量。干扰项: 相关系数的绝对值不会大于1。 提示与解答: 本题的正确答案为: 相关系数不会取负值。 4■下面的xx中哪一个是错误的()。 答案: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 干扰项: 相关系数显著性检验的原假设是: 总体中两个变量不存在相关关系。 干扰项: 回归分析中回归系数的显著性检验的原假设是:
所检验的回归系数的真值为0。 干扰项: 回归分析中多元线性回归方程的整体显著性检验的原假设是: 自变量前的偏回归系数的真值同时为0。 提示与解答: 本题的正确答案为: 回归分析中回归系数的显著性检验的原假设是: 所检验的回归系数的真值不为0。 5■根据你的判断,下面的相关系数值哪一个是错误的()。 答案: 1.25。干扰项:-0.86。干扰项: 0.78。干扰项:0。 提示与解答: 本题的正确答案为: 1.25。 6■下面关于相关系数的陈述中哪一个是错误的()。 答案: 数值越大说明两个变量之间的关系越强,数值越小说明两个变量之间的关系越弱。 干扰项:
如何用Excel做数据线性拟合和回归分析 我们已经知道在Excel自带的数据库中已有线性拟合工具,但是它还稍显单薄,今天我们来尝试使用较为专业的拟合工具来对此类数据进行处理。 在数据分析中,对于成对成组数据的拟合是经常遇到的,涉及到的任务有线性描述,趋势预测和残差分析等等。很多专业读者遇见此类问题时往往寻求专业软件,比如在化工中经常用到的Origin和数学中常见的MATLAB等等。它们虽很专业,但其实使用Excel 就完全够用了。我们已经知道在Excel自带的数据库中已有线性拟合工具,但是它还稍显单薄,今天我们来尝试使用较为专业的拟合工具来对此类数据进行处理。 注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘支持下加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项 实例某溶液浓度正比对应于色谱仪器中的峰面积,现欲建立不同浓度下对应峰面积的标准曲线以供测试未知样品的实际浓度。已知8组对应数据,建立标准曲线,并且对此曲线进行评价,给出残差等分析数据。 这是一个很典型的线性拟合问题,手工计算就是采用最小二乘法求出拟合直线的待定参数,同时可以得出R的值,也就是相关系数的大小。在Excel中,可以采用先绘图再添加趋势线的方法完成前两步的要求。 选择成对的数据列,将它们使用“X、Y散点图”制成散点图。
在数据点上单击右键,选择“添加趋势线”-“线性”,并在选项标签中要求给出公式和相关系数等,可以得到拟合的直线。 拟合的直线是y=15620x+6606.1,R2的值为0.9994。 因为R2>0.99,所以这是一个线性特征非常明显的实验模型,即说明拟合直线能够以大于99.99%地解释、涵盖了实测数据,具有很好的一般性,可以作为标准工作曲线用于其他未知浓度溶液的测量。 为了进一步使用更多的指标来描述这一个模型,我们使用数据分析中的“回归”工具来详细分析这组数据。 在选项卡中显然详细多了,注意选择X、Y对应的数据列。“常数为零”就是指明该模型是严格的正比例模型,本例确实是这样,因为在浓度为零时相应峰面积肯定为零。先前得出的回归方程虽然拟合程度相当高,但是在x=0时,仍然有对应的数值,这显然是一个可笑的结论。所以我们选择“常数为零”。 “回归”工具为我们提供了三张图,分别是残差图、线性拟合图和正态概率图。重点来看残差图和线性拟合图。 在线性拟合图中可以看到,不但有根据要求生成的数据点,而且还有经过拟和处理的预测数据点,拟合直线的参数会在数据表格中详细显示。本实例旨在提供更多信息以起到抛砖引玉的作用,由于涉及到过多的专业术语,请各位读者根据实际,在具体使用
第4章违背基本假设的情况 思考与练习参考答案 4.1 试举例说明产生异方差的原因。 答:例4.1:截面资料下研究居民家庭的储蓄行为 Y i=β0+β1X i+εi 其中:Y i表示第i个家庭的储蓄额,X i表示第i个家庭的可支配收入。 由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以εi的方差呈现单调递增型变化。 例4.2:以某一行业的企业为样本建立企业生产函数模型 Y i=A iβ1K iβ2L iβ3eεi 被解释变量:产出量Y,解释变量:资本K、劳动L、技术A,那么每个企业所处的外部环境对产出量的影响被包含在随机误差项中。由于每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。这时,随机误差项ε的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。 4.2 异方差带来的后果有哪些? 答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果: 1、参数估计量非有效 2、变量的显著性检验失去意义 3、回归方程的应用效果极不理想 总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。 4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。 答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差
的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。 加权最小二乘法的方法: 4.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。 答:运用加权最小二乘法消除多元线性回归中异方差性的思想与一元线性回归的类似。多元线性回归加权最小二乘法是在平方和中加入一个适当的权数i w ,以调整各项在平方和中的作用,加权最小二乘的离差平方和为: ∑=----=n i ip p i i i p w x x y w Q 1211010)( ),,,(ββββββ (2) 加权最小二乘估计就是寻找参数p βββ,,,10 的估计值pw w w βββ?,,?,?10 使式(2)的离差平方和w Q 达极小。所得加权最小二乘经验回归方程记做 22011 1 ???()()N N w i i i i i i i i Q w y y w y x ββ===-=--∑∑22 __ 1 _ 2 _ _ 02 222 ()() ?()?1 11 1 ,i i N w i i i w i w i w w w w w kx i i i i m i i i m i w x x y y x x y x w kx x kx w x σβββσσ==---=-= = ===∑∑1N i =1 1表示=或
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除)
第11章一元线性回归(相关与回归)学习指导 一、本章基本知识梳理 基本知识点 含义或公式 相关关系 客观现象之间确实存在的、但在数量表现上不是严格对应的依存关系。 函数关系 客观现象之间确实存在的、而且数量表现上是严格对应的依存关系。 因果关系 有相关关系的现象中能够明确其中一种现象(变量)是引起另一种现象(变量)变化的原因,另一种现象是这种现象变化的结果。起影响作用的现象(变量)称为“自变量”;而受自变量影响发生变动的现象(变量)称为“因变量”。 因果关系?相关关系,但相关关系中还包括互为因果关系的情况。 相关关系的种类 按涉及变量多少分为单相关、复相关;按相关方向分为正相关、负相关;按 相关形态分为线性相关、非线性相关等。 线性(直线) 相关系数 简称相关系数,反映具有直线相关关系的两个变量关系的密切程度。 () () ∑∑∑∑∑∑∑ - - -= = 2 2 2 2 y y n x x n y x xy n S S S r y x xy 相关系数的 显著性检验 ——t 检验 ()(). 2;,212:0 :,0:0 2 02 2 1 H n t t H n t t r n r t H H ,拒绝 不能拒绝 检验统计量-?-?--= ≠=α α ρρ 回归方程中的 参数β0和β1 为回归直线的截距、起始值,表示在没有自变量x 的影响(即x =0)时, 其他各种因素对因变量y 的平均影响; β1为回归系数、斜率,表示自变量x 每变动一个单位,因变量y 的平均变动 量。 β1的最小平方估计:∑∑∑∑∑ ?? ? ??--= 2 2 1 x x n y x xy n β 估计标准误差 反映因变量实际值与其估计值之间的平均差异程度,表明其估计值对实际值的代表性强弱。其值越大,实际值与估计值之间的平均差异程度越大,估计值的代表性越差。 ()代替。用大样本条件下,分母可 ;n n y y S e 2 ?2 --= ∑ 总离差平方和S S T 反映因变量的n 个观察值与其均值的总离差。 回归离差平方和S S R 反映自变量x 的变化对因变量y 取值变化的影响;或者说,是由于x 与y 之间的线性关系引起的y 取值的变化,也称为可解释的平方和。 残差平方和(剩余)S S E 反映除x 以外的其他因素对y 取值的影响,也称为不可解释的平方和或残差平方和。
第三章 一元线性回归 一元线性回归分析的对象是两个变量的单向因果关系,模型的核心是两变量线性函数,分析方法是回归分析。一元线性回归是经典计量经济分析的基础。 第一节 一元线性回归模型 一、变量间的统计关系 社会经济现象之间的相互联系和制约是社会经济的普遍规律。在一定的条件下,一些因素推动或制约另外一些与之联系的因素发生变化。这种状况表明在经济现象的内部和外部联系中存在着一定的因果关系,人们往往利用这种因果关系来制定有关的经济政策,以指导、控制社会经济活动的发展。而认识和掌握客观经济规律就要探求经济现象间经济变量的变化规律。 互有联系的经济变量之间的紧密程度各不相同,一种极端的情况是一个变量能完全决 定另一个变量的变化。比如:工业企业的原材料消耗金额用y 表示,生产量用1x 表示,单位产量消耗用2x 表示,原材料价格用3x 表示,则有:123y x x x =。这里,y 与123,,x x x ,是一种确定的函数关系。 然而,现实世界中,还有不少情况是两个变量之间有着密切的联系,但它们并没有密切到由一个可以完全确定另一个的程度。 例如:某种高档费品的销售量与城镇居民的收入;粮食产量与施肥量之间的关系;储蓄额与居民的收入密切相关。 从图示上可以大致看出这两种关系的区别:一种是对应点完全落到一条函数曲线上;另一种是并不完全落在曲线上,而有的点在曲线上,有的点在曲线的两边。对于后者这种不能用精确的函数关系来描述的关系正是计量经济学研究的重要内容。 二、一元线性回归模型 1.模型的建立 一个例子,见教材66页: 总体回归模型:01i i i Y X ββε=++ 理解:(1)误差的随机性使得Y 和X 之间呈现一种随机的因果关系;(2)Y i 的取值由两部分组成,一类是系统内影响,一类是系统外影响。 样本回归直线:01i i Y X ββ=+ 样本回归模型:01i i i Y X e ββ=++ 2.模型的假设 (1) 误差项i ε的数学期望无论I 取什么值都是零。 (2) 误差项i ε的方差为常数2 σ (3) 误差项i ε对于I 的取值不同,不相关。 (4) 解释变量X 是确定性的变量,而非随机变量。 (5) 误差项i ε服从正态分布。
第十一章一元线性回归练习题 一. 选择题 1.具有相关关系的两个变量的特点是( ) A .一个变量的取值不能由另一个变量唯一确定 B .一个变量的取值由另一个变量唯一确定 C .一个变量的取值增大时另一个变量的取值也一定增大 D .一个变量的取值增大时另一个变量的取值肯定变小 2.下面的各问题中,哪个不是相关分析要解决的问题 A .判断变量之间是否存在关系 B .判断一个变量数值的变化对另一个变量的影响 C .描述变量之间的关系强度 D.判断样本所反映的变量之间的关系能否代表总体变量之间的关系 3.根据下面的散点图,可以判断两个变量之间存在( ) A. 正线性相关关系 B. 负线性相关关系 C. 非线性关系 D. 函数关系 4.下面的陈述哪一个是错误的( ) A.相关关系是度量两个变量之间线性关系强度的统计量 B .相关系数是一个随机变量 C .相关系数的绝对值不会大于1 D .相关系数不会取负值 5.根据你的判断,下面的相关系数取值哪一个是错误的( ) A. -0.86 B. 0.78 C. 1.25 D. 0 6.如果相关系数r=0,则表明两个变量之间( ) A.相关程度很低 B. 不存在任何关系 C .不存在线性相关关系 D.存在非线性关系 7. 下列不属于相关关系的现象是( ) A. 银行的年利息率与贷款总额 B.居民收入与储蓄存款 C.电视机的产量与鸡蛋产量 D.某种商品的销售额与销售价格 8.设产品产量与产品单位成本之间的线性相关系数为-0.87,这说明二者之间存在着( ) A. 高度相关 B.中度相关 C.低度相关 D.极弱相关 9.在回归分析中,被预测或被解释的变量称为( ) A.自变量 B.因变量 C.随机变量 D.非随机变量 10. 对两变量的散点图拟合最好的回归线,必须满足一个基本的条件是( ) A. 2?()y y ∑-最小 B. 2 )(y y ∑-最大 C. 2?()y y ∑-最大 D. 2 )(?y y ∑-最小 11. 下列哪个不属于一元回归中的基本假定( ) A.误差项i ε服从正态分布 B. 误差项i ε的期望值为0
第三章 K 元线性回归模型 一、填空题 1. 对于模型i ik k i i i u X X X Y +++++=ββββΛ22110,i=1,2,…,n ,一般经验认为,满足模型估计的基本要求的样本容量为_ _ 2. 对于总体线性回归模型i i i i i u X X X Y ++++=3322110ββββ,运用最小二乘法欲得到参数估计量,所要求的最小样本容量n 应满足 或至少_________。 3. 多元线性计量经济学模型的矩阵形式 ,对应的样本线性回归模型的矩阵形式 ,模型的最小二乘参数估计量 及其方差估计量 。 4. 总平方和可以分解为 回归平方和 和 残差平方和 ,可决系数为 。 5. 多元回归方程中每个解释变量的系数β(偏回归系数),指解释变量变化一个单位引起的被解释变量平均变化 β 个单位。 6. 线性模型的含义,就变量而言,指的是回归模型变量的 ;就参数而言,指的是回归模型中参数的 。通常线性回归模型指的是 。 二、问答题 1. 什么是多元回归模型?它与一元、二元回归模型有何区别? 2. 极大似然法(maximum likehood )的原理是什么? 3. 什么是拟合优度(R 2)检验?有什么作用? 指对样本回归直线与样本观测值之间的拟合程度的检验。 4. 可决系数R 2低的可能的原因是什么? 5. 多元回归的判断系数R 2具有什么性质?运用R 2时应注意什么问题? 6. 多元线性回归模型的基本假设是什么?试说明在证明最小二乘估计量的无偏性和有 效性的过程中,哪些基本假设起了作用? 7. 说明区间估计的含义。 三、实践题 1.下表给出三变量模型的回归结果: 方差来源 平方和(SS ) 自由度(d.f.) 均方差(MSS) 回归平方和(ESS) 65965 3 21988.33 残差平方和(RSS) 77 11 7 总平方和(TSS) 66042 14 4717.48
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open;
2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent (因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise. 进入如下界面:
2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue. 3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.
一、邹式检验(突变点检验、稳定性检验) 1.突变点检验 1985—2002年中国家用汽车拥有量(t y ,万辆)与城镇居民家庭人均可支配收入(t x ,元),数据见表6.1。 表6.1 中国家用汽车拥有量(t y )与城镇居民家庭人均可支配收入(t x )数据 年份 t y (万辆) t x (元) 年份 t y (万辆) t x (元) 1985 28.49 739.1 1994 205.42 3496.2 1986 34.71 899.6 1995 249.96 4283 1987 42.29 1002.2 1996 289.67 4838.9 1988 60.42 1181.4 1997 358.36 5160.3 1989 73.12 1375.7 1998 423.65 5425.1 1990 81.62 1510.2 1999 533.88 5854 1991 96.04 1700.6 2000 625.33 6280 1992 118.2 2026.6 2001 770.78 6859.6 1993 155.77 2577.4 2002 968.98 7702.8 下图是关于t y 和t x 的散点图: 从上图可以看出,1996年是一个突变点,当城镇居民家庭人均可支配收入突破
4838.9元之后,城镇居民家庭购买家用汽车的能力大大提高。现在用邹突变点检验法检验1996年是不是一个突变点。 H0:两个字样本(1985—1995年,1996—2002年)相对应的模型回归参数相等H1:备择假设是两个子样本对应的回归参数不等。 在1985—2002年样本范围内做回归。 在回归结果中作如下步骤(邹氏检验): 1、Chow 模型稳定性检验(lrtest) 用似然比作chow检验,chow检验的零假设:无结构变化,小概率发生结果变化 * 估计前阶段模型 * 估计后阶段模型
实验报告 金融系金融学专业级班 实验人:实验地点:实验日期: 实验题目:进行相应的分析,揭示某地区住宅建筑面积与建造单位成本间的关系 实验目的:掌握最小二乘法的基本方法,熟练运用Eviews软件的一元线性回归的操作,并能够对结果进行相应的分析。 实验内容:实验采用了建筑地编号为1号至12号的数据,通过模型设计、估计参数、检验统计量、回归预测四个步骤对数据进行相关分析。 实验步骤: 一、模型设定 1.建立工作文件。双击eviews,点击File/New/Workfile,在出现的对话框中选择数据 频率,因为该例题中为截面数据,所以选择unstructured/undated,在observations 中设定变量个数,这里输入12。 图1 2.输入数据。在eviews 命令框中输入data X Y,回车出现group窗口数据编辑框,在
对应的X,Y下输入数据,这里我们可以直接将excel中被蓝笔选中的部分用cirl+c 复制,在窗口数据编辑框中1所对应的框中用cirl+v粘贴数据。 图2 3.作X与Y的相关图形。为了初步分析建筑面积(X)与建造单位成本(Y)的关系, 可以作以X为横坐标、以Y为纵坐标的散点图。方法是同时选中工作文件中的对象X和Y,双击得X和Y的数据表,点View/Graph/scatter,在File lines中选择Regressions line/ok(其中Regressions line为趋势线)。得到如图3所示的散点图。 图3 散点图
从散点图可以看出建造单位成本随着建筑面积的增加而降低,近似于线性关系,为分析建造单位成本随建筑面积变动的数量规律性,可以考虑建立如下的简单线性回归模型: 二、估计参数 假定所建模型及其中的随机扰动项满足各项古典假定,可以用OLS法估计其 参数。Eviews软件估计参数的方法如下: 在eviews命令框中键入LS Y C X,按回车,即出现回归结果。 Eviews的回归结果如图4所示。 图4 回归结果 可用规范的形式将参数估计和检验结果写为: (19.2645)(4.8098) t=(95.7969)(-13.3443) 0.9468 F=178.0715 n=12