习题3(第三章关联规则挖掘)
- 格式:docx
- 大小:73.73 KB
- 文档页数:2

数据挖掘考试题目——关联分析知识讲解数据挖掘考试题目——关联分析一、10个选择1.以下属于关联分析的是()A.CPU性能预测B.购物篮分析C.自动判断鸢尾花类别D.股票趋势建模2.维克托?迈尔-舍恩伯格在《大数据时代:生活、工作与思维的大变革》一书中,持续强调了一个观点:大数据时代的到来,使我们无法人为地去发现数据中的奥妙,与此同时,我们更应该注重数据中的相关关系,而不是因果关系。
其中,数据之间的相关关系可以通过以下哪个算法直接挖掘()A.K-means B.Bayes NetworkC.C4.5 D.Apriori3.置信度(confidence)是衡量兴趣度度量()的指标。
A.简洁性B.确定性C.实用性D.新颖性4.Apriori算法的加速过程依赖于以下哪个策略()A.抽样B.剪枝C.缓冲D.并行5.以下哪个会降低Apriori算法的挖掘效率()A.支持度阈值增大B.项数减少C.事务数减少D.减小硬盘读写速率6.Apriori算法使用到以下哪些东东()A.格结构、有向无环图B.二叉树、哈希树C.格结构、哈希树D.多叉树、有向无环图7.非频繁模式()A.其置信度小于阈值B.令人不感兴趣C.包含负模式和负相关模式D.对异常数据项敏感8.对频繁项集、频繁闭项集、极大频繁项集的关系描述正确的是()[注:分别以1、2、3代表之]A.3可以还原出无损的1 B.2可以还原出无损的1C.3与2是完全等价的D.2与1是完全等价的9.Hash tree在Apriori算法中所起的作用是()A.存储数据B.查找C.加速查找D.剪枝10.以下不属于数据挖掘软件的是()A.SPSS Modeler B.WekaC.Apache Spark D.Knime二、10个填空1.关联分析中表示关联关系的方法主要有:和。
2.关联规则的评价度量主要有:和。
3.关联规则挖掘的算法主要有:和。
4.购物篮分析中,数据是以的形式呈现。
5.一个项集满足最小支持度,我们称之为。


习题一:1。
讨论是否每个以下活动是一个数据挖掘的任务。
(a)将公司的客户根据他们的性别。
不。
这是一个简单的数据库查询。
(b)将公司的客户根据他们的盈利能力。
不。
这是一个会计计算,紧随其后的是应用程序一个阈值。
然而,预测的盈利能力客户将数据挖掘。
(c)计算一个公司的总销售额。
不。
再次,这是简单的会计。
(d)排序一个学生数据库基于学生身份证号码。
不。
再一次,这是一个简单的数据库查询。
(e)预测结果掷双骰子(公平)。
不。
因为模具是公平的,这是一个概率计算。
如果死是不公平的,我们需要估计的概率每个结果的数据,那么这是更像的问题认为数据挖掘。
然而,在这种特定的情况下,解决方案这个问题是由数学家很长时间前,因此,我们不会认为它是数据挖掘。
(f)预测未来股价的公司使用历史记录。
是的。
我们将尝试创建一个模型,该模型可以预测连续价值的股票价格。
这是一个的例子数据挖掘领域称为预测模型。
我们可以使用回归建模,尽管在许多领域的研究者开发了各种各样的技术来预测时间吗系列。
(g)监测病人的心率异常。
是的。
我们可以建立一个模型,心脏的正常行为率和不同寻常的心行为发生时发出警报。
这将涉及到数据挖掘的区域称为异常检测。
这也可以被认为是一个分类问题如果我们有正常和异常的心行为的例子。
(h)监测地震活动的地震波。
是的。
在本例中,我们将构建一个不同类型的模型地震波与地震相关的活动和行为提高警报当其中一个不同类型的地震活动被观察到。
这是数据挖掘领域的一个例子被称为分类。
(i)提取声波的频率。
不。
这是信号处理。
2.假设你被录用,作为一个互联网数据挖掘咨询顾问搜索引擎公司。
描述数据挖掘可以帮助公司通过给具体的例子如何技术,如聚类,分类、关联规则挖掘和异常检测可以应用。
答:以下是可能的答案的例子。
•聚类可以把结果与类似的主题用户在一个更简洁的形式,例如通过报告集群中的十大最频繁的词语。
•分类可以将结果分配给预定义的类别等“体育”、“政治”,等等。
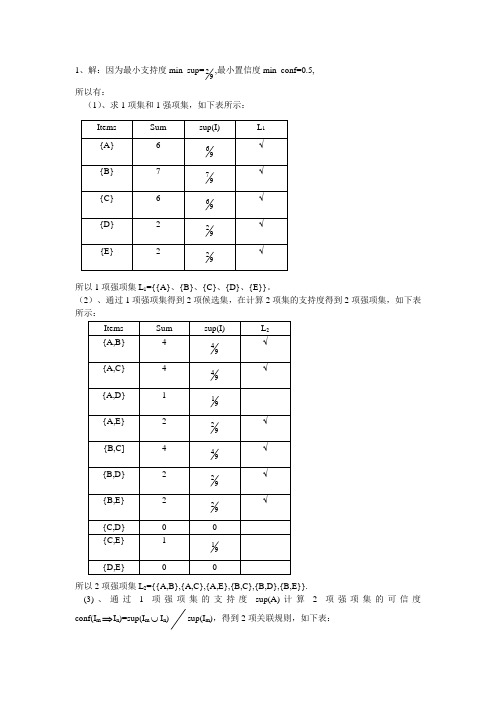
1、解:因为最小支持度min_sup=92,最小置信度min_conf=0.5,所以有: (1)、求1项集和1强项集,如下表所示:所以1项强项集L 1={{A}、{B}、{C}、{D}、{E}}。
(2)、通过1项强项集得到2项候选集,在计算2项集的支持度得到2项强项集,如下表所示:所以2项强项集L 2={{A,B},{A,C},{A,E},{B,C},{B,D},{B,E}}.(3)、通过1项强项集的支持度sup(A)计算2项强项集的可信度conf(I m ⇒I n )=sup(I m ⋃I n )sup(I m ),得到2项关联规则,如下表:Items Sum sup(I)L 1 {A} 6 96 √ {B}7 97√ {C} 6 96√ {D} 2 92√ {E}292√Items Sum sup(I) L 2{A,B} 4 94√ {A,C} 4 94√ {A,D} 1 91{A,E} 2 92√ {B,C] 4 94√ {B,D} 2 92√ {B,E} 2 92√ {C,D} 0 0{C,E} 1 91 {D,E} 0 0产生的2项关联规则为:I(A)⇒I(B); I(A)⇒I(C); I(B)⇒I(C)。
(4)、通过2项强项集得到3项候选集,再计算3项集的支持度得到3项强项集,如下表所示:所以3项强项集L 3={{A,B,C},{A,B,E}}。
(5)、计算3项强项集的可信度,得到3项关联规则,如下表所示:Items sup(I m ⋃I n )sup(I m )sup(I n )conf(I m ⇒I n ) 2项关联规则{A,B} 94 96 97 64 √ {A,C} 94969664 √ {A,E} 92969262 {B,C} 94979674 √ {B,D} 92979272 {B,E}92979272Items Sum sup(I m ⋃I n ⋃I p ) L 3{A,B,C} 2 92 √ {A,B,D} 1 91{A,B,E} 2 92 √ {A,C,E} 1 91 {B,C,E} 1 91 Items I m I n sup(I m )conf(I m ⇒I n )2项关联规则如上表所示,产生的关联规则为:I(A,B)⇒I(C), I(A,C)⇒I(B), I(B ,C)⇒I(A) I(E)⇒I(A,B), I(A,B)⇒I(E), I(A,E)⇒I(B) I(B,E)⇒I(A)(6)、由3项强项集L 3={{A,B,C},{A,B,E}},可知4项强项集只有一个{A,B,C,,E}因而可知,无4项强项集,即无4向关联规则。

1、数据仓库就是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合。
2、元数据是描述数据仓库内数据的结构和建立方法的数据,它为访问数据仓库提供了一个信息目录,根据数据用途的不同可将数据仓库的元数据分为技术元数据和业务元数据两类。
3、数据处理通常分成两大类:联机事务处理和联机分析处理。
4、多维分析是指以“维”形式组织起来的数据(多维数据集)采取切片、切块、钻取和旋转等各种分析动作,以求剖析数据,使拥护能从不同角度、不同侧面观察数据仓库中的数据,从而深入理解多维数据集中的信息。
5、ROLAP是基于关系数据库的OLAP实现,而MOLAP是基于多维数据结构组织的OLAP实现。
6、数据仓库按照其开发过程,其关键环节包括数据抽取、数据存储于管理和数据表现等。
7、数据仓库系统的体系结构根据应用需求的不同,可以分为以下4种类型:两层架构、独立型数据集合、以来型数据结合和操作型数据存储和逻辑型数据集中和实时数据仓库.8、操作型数据存储实际上是一个集成的、面向主题的、可更新的、当前值的(但是可“挥发”的)、企业级的、详细的数据库,也叫运营数据存储.9、“实时数据仓库”以为着源数据系统、决策支持服务和仓库仓库之间以一个接近实时的速度交换数据和业务规则。
10、从应用的角度看,数据仓库的发展演变可以归纳为5个阶段:以报表为主、以分析为主、以预测模型为主、以运营导向为主和以实时数据仓库和自动决策为主。
1、调和数据是存储在企业级数据仓库和操作型数据存储中的数据。
2、抽取、转换、加载过程的目的是为决策支持应用提供一个单一的、权威数据源。
因此,我们要求ETL过程产生的数据(即调和数据层)是详细的、历史的、规范的、可理解的、即时的和质量可控制的。
3、数据抽取的两个常见类型是静态抽取和增量抽取。
静态抽取用于最初填充数据仓库,增量抽取用于进行数据仓库的维护。
4、粒度是对数据仓库中数据的综合程度高低的一个衡量。
粒度越小,细节程度越高,综合程度越低,回答查询的种类越多.5、使用星型模式可以从一定程度上提高查询效率。
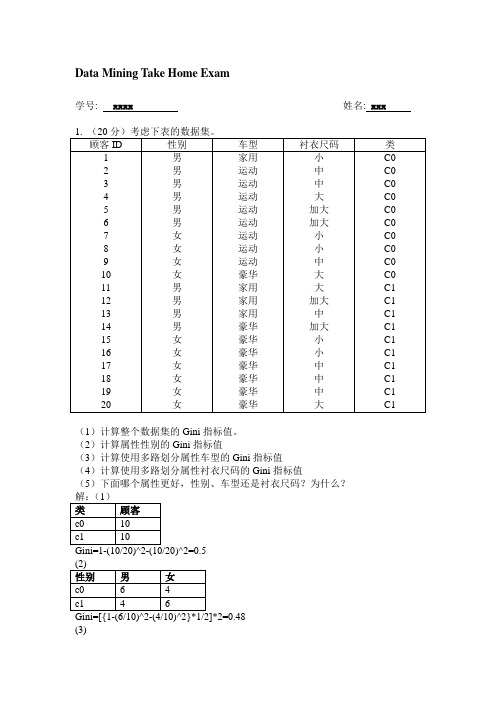
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?(3)=26/160=0.1625]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. ((1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0.8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)> anova(ls1)Df Sum Sq Mean Sq F value Pr(>F)x1 1 10021.2 10021.2 62.038 0.0001007 ***x2 1 4030.9 4030.9 24.954 0.0015735 **Residuals 7 1130.7 161.5> ls2<-lm(y~x2+x1)> anova(ls2)Df Sum Sq Mean Sq F value Pr(>F)x2 1 3363.4 3363.4 20.822 0.002595 **x1 1 10688.7 10688.7 66.170 8.193e-05 ***Residuals 7 1130.7 161.5(1)用F检验来检验以下假设(α = 0.05)H0: β1 = 0H a: β1≠ 0计算检验统计量;是否拒绝零假设,为什么?(2)用F检验来检验以下假设(α = 0.05)H0: β2 = 0H a: β2≠ 0计算检验统计量;是否拒绝零假设,为什么?(3)用F检验来检验以下假设(α = 0.05)H0: β1 = β2 = 0H a: β1和β2 并不都等于零计算检验统计量;是否拒绝零假设,为什么?解:(1)根据第一个输出结果F=62.083>F(2,7)=4.74,p<0.05,所以可以拒绝原假设,即得到不等于0。
机器学习数据挖掘练习题一、基础理论题1. 请简述机器学习的基本任务。
2. 数据挖掘的主要步骤包括哪些?3. 什么是监督学习?请举例说明。
4. 无监督学习与监督学习的区别是什么?5. 简述决策树的基本原理。
6. 支持向量机(SVM)的基本思想是什么?7. 请解释什么是过拟合,并说明如何避免过拟合。
8. 简述Kmeans算法的步骤。
9. 请阐述Apriori算法的原理。
10. 什么是关联规则挖掘?请举例说明。
二、算法应用题1. 使用线性回归模型预测房价,请列出可能影响房价的特征。
2. 对于一个分类问题,如何选择合适的评估指标?3. 如何使用KNN算法进行手写数字识别?4. 请简述如何使用朴素贝叶斯分类器进行垃圾邮件过滤。
5. 利用决策树实现客户流失预测,请列出可能影响客户流失的特征。
6. 如何使用支持向量机(SVM)进行文本分类?7. 请阐述如何使用随机森林算法进行股票预测。
8. 使用Kmeans算法对一组数据进行聚类,请描述聚类结果的评价指标。
9. 利用Apriori算法挖掘超市购物篮数据中的频繁项集和关联规则。
10. 请简述如何使用PageRank算法对网页进行排序。
三、编程实践题1. 编写Python代码实现线性回归算法。
2. 使用Python实现KNN算法,并对鸢尾花数据集进行分类。
3. 编写Python代码实现决策树算法,并对西瓜数据集进行分类。
5. 使用Python实现Kmeans算法,并对一组数据进行聚类。
6. 编写Python代码实现Apriori算法,挖掘超市购物篮数据中的频繁项集和关联规则。
7. 请使用Python实现一个简单的推荐系统(如基于用户的协同过滤)。
8. 利用Python实现一个文本分类器,对新闻数据进行分类。
9. 编写Python代码实现一个简单的神经网络,并进行手写数字识别。
10. 使用Python实现一个基于时间的序列预测模型,如ARIMA模型。
四、案例分析题1. 分析某电商平台的用户评论数据,提取关键特征,并对其进行情感分析。
数据挖掘考试题目——关联分析一、10个选择1.以下属于关联分析的是()A.CPU性能预测B.购物篮分析C.自动判断鸢尾花类别D.股票趋势建模2.维克托▪迈尔-舍恩伯格在《大数据时代:生活、工作与思维的大变革》一书中,持续强调了一个观点:大数据时代的到来,使我们无法人为地去发现数据中的奥妙,与此同时,我们更应该注重数据中的相关关系,而不是因果关系。
其中,数据之间的相关关系可以通过以下哪个算法直接挖掘()A.K-means B.Bayes NetworkC.C4.5 D.Apriori3.置信度(confidence)是衡量兴趣度度量()的指标。
A.简洁性B.确定性C.实用性D.新颖性4.Apriori算法的加速过程依赖于以下哪个策略()A.抽样B.剪枝C.缓冲D.并行5.以下哪个会降低Apriori算法的挖掘效率()A.支持度阈值增大B.项数减少C.事务数减少D.减小硬盘读写速率6.Apriori算法使用到以下哪些东东()A.格结构、有向无环图B.二叉树、哈希树C.格结构、哈希树D.多叉树、有向无环图7.非频繁模式()A.其置信度小于阈值B.令人不感兴趣C.包含负模式和负相关模式D.对异常数据项敏感8.对频繁项集、频繁闭项集、极大频繁项集的关系描述正确的是()[注:分别以1、2、3代表之]A.3可以还原出无损的1 B.2可以还原出无损的1C.3与2是完全等价的D.2与1是完全等价的9.Hash tree在Apriori算法中所起的作用是()A.存储数据B.查找C.加速查找D.剪枝10.以下不属于数据挖掘软件的是()A.SPSS Modeler B.WekaC.Apache Spark D.Knime二、10个填空1.关联分析中表示关联关系的方法主要有:和。
2.关联规则的评价度量主要有:和。
3.关联规则挖掘的算法主要有:和。
4.购物篮分析中,数据是以的形式呈现。
5.一个项集满足最小支持度,我们称之为。
习题3(第三章 关联规则挖掘) 1.
给出一个小例子表明强关联规则中的项实际上可能是负相关的。
2.
对于下面的每个问题,提供一个与市场有关的关联规则的例子,并描述这种关联规则是否是人们感兴趣的。
(a) 一个具有高支持度和高置信度的关联规则; (b) 一个具有理论上高支持度但低置信度的关联规则; (c) 一个具有低支持度和低置信度的关联规则; (d) 一个具有支持度但是高置信度的关联规则; 3.
假定大型事务数据库DB 的频繁项集已经存储,讨论:如果新的事务集∆DB 加入,在相同的最小支持度阈值下,如何有效的挖掘全局关联规则? 4.
考虑下面的频繁-3项集的集合: {1,2,3},{1,2,4},{1,2,5},{1,3,4},{1,3,5},{2,3,4},{2,3,5},{3,4,5} 假定数据集中只有5个项。
(a) 列出采用F K-1ⅹF 1合并策略,由候选产生过程得到的所有候选4-项集。
(b) 列出由Apriori 算法的候选产生过程得到的所有候选4-项集。
(c) 列出Apriori 算法候选剪枝步骤后剩下的所有候选4-项集。
5.
(a) 在item_category 粒度(例如,item 可以是“Milk ”),对于下面的规则模板:
∀X ∈transaction,buys(X,item 1)∧buys(X,item 2)⟹buys(X,item 3) [s,c]
对最大的k ,列出频繁k 项集和包含最大的k 项集的所有强关联规则(包含它们的支持度s 和置信度c)。
(b) 在brand-item_category 粒度(例如,item i 可以是“Sunset-Milk ”),对于下面的规则
模板:
∀X ∈customer,buys(X,item 1)∧buys(X,item 2)⟹buys(X,item 3)
对最大的k ,列出频繁k 项集(但不输出任何规则)。
6. 假设一个大型商店具有分布在4个站点的事务数据库。
每个成员数据库中的事务具有相
同的格式T j :{ i 1,…,i m };其中,T j 是事务标识符,而i k (1≤i ≤k )是事务中购买的商品的标识符。
提出一个有效的算法,挖掘全局关联规则(不考虑多层关联)。
你可以给出算法的要点。
算法不必将所有的数据移到一个站点,并且不造成过度的网络通信开销。
7. 关联规则常常产生大量规则。
讨论可以用来减少所产生规则的数量并且仍然保留大部分
有趣规则的有效方法。
8. 下面的相依表汇总了超级市场的事务数据。
其中,hot dogs 表示包含热狗的事务,
hot dogs ̅̅̅̅̅̅̅̅̅̅̅表示不包含热狗的事务,hamburgers 表示包含汉堡包的事务, hamburgers ̅̅̅̅̅̅̅̅̅̅̅̅̅̅̅̅表示
(a)25%,最
小置信度阀值50%,该关联规则是强关联规则吗?
(b)根据给定的数据,买hot dogs独立于买humburgers吗?如果不是,二者之间存在何
种相关关系。
9.Apriori算法用一个hash树数据结构有效地计算候选项集的支持度,考虑下面的候选3-
项集的hash树,
(a)现有一个事务包含(1,3,4,5,8),当寻找该事务的候选项集时,哪些叶子节点将被访
问?
采用(a)中找到的叶子节点确定包含在事务{1,3,4,5,8}中的候选项集。
10.证明从包含d个项的数据集提取的可能规则总数是:
R=3d-2d+1+1
提示:首先,计算创建形成规则左部项集的方法数;然后,对每个选定为规则左部的k 项集,计算选择剩下的d-k个项形成规则右部的方法数。