基于关键词的主题网络爬虫
- 格式:pdf
- 大小:102.73 KB
- 文档页数:1
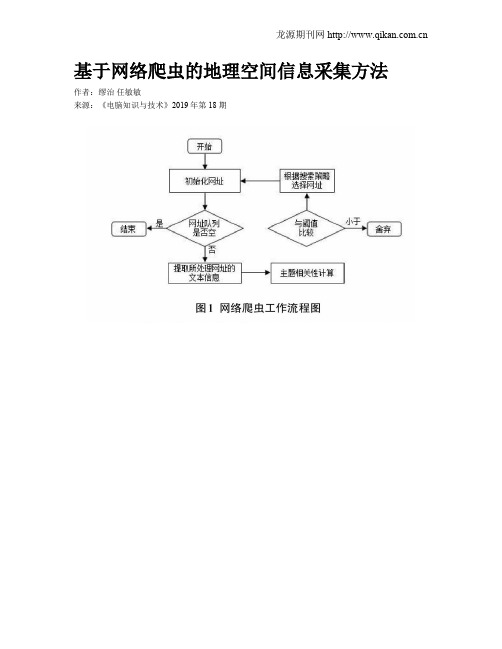
基于网络爬虫的地理空间信息采集方法作者:缪治任敏敏来源:《电脑知识与技术》2019年第18期摘要:在网络爬虫的地理空间信息的采集方法上,也就是说在网络的环境下对地理空间信息进行获取和相关资料的搜集工作,对于地理空间信息的研究具有十分重要的作用,是地理空间研究领域获取信息最为重要的途径之一。
在网络空间下对数据的主题信息的采集工作是进行地理空间信息采集的重要工作内容,是地理空间信息进行研究最基本的根据之一。
数据网络中,对于地理空间信息的采集具有以下几个特点:一是数据采集主题的门类比较多,采集的方法各种各样,数据的格式也是千差万别,对于如何快速、准确、高效地获取地理空间信息来说是一个复杂的问题。
关键词:信息采集;网络爬虫;地理空间;采集方法中图分类号:TP311; ; ; ; 文献标识码:A文章编号:1009-3044(2019)18-0009-02Abstract: In terms of the collection method of Geospatial information of web spiders, that is to say, the acquisition of Geospatial Information and the collection of relevant data in the network environment play a very important role in the research of Geospatial information, and is one of the most important ways to obtain information in the field of Geospatial Information. The collection of the subject information of the data in the network space is an important work of Geospatial information collection and is one of the most basic bases of Geospatial information research. In the data network, the collection of Geospatial information has the following characteristics: first, the subject of data collection is more categories, collection methods are various, the format of data is also varied, for how to quickly, accurately and efficiently obtain Geospatial information is acomplex problem.Key words: information collection; web spider; geographic space; collection method隨着互联网技术的迅猛发展,信息化的社会发展已经进入了大数据的发展时代,人们可以通过信息的采集发现用户的喜好,进而进行精准化的营销活动。





论文关键词检索方法归纳
关键词检索方法是指通过识别文本中的关键词来进行检索的方法。
根
据不同的需求和文本特点,可以使用的关键词检索方法有以下几种:
1.自然语言处理:利用自然语言处理技术,通过文本的词汇、语义、
句法等特征来提取关键词,如基于词频统计的方法、基于TF-IDF(词频-
逆向文件频率)的方法等。
2.机器学习方法:利用机器学习算法,训练模型来识别关键词,如基
于朴素贝叶斯分类器、支持向量机等。
3.网络爬虫方法:通过抓取互联网上的页面,提取其中的关键词信息。
4.领域专业词汇提取方法:针对特定领域,利用该领域的专业词汇库
或专门的词汇提取工具,从文本中提取相关的关键词。
5.知识图谱方法:利用知识图谱构建和知识表示方法,从文本中提取
出与知识图谱相关的关键词。
综上所述,关键词检索方法可以根据具体需求和文本特点选择合适的
方法,也可以结合多种方法来进行关键词的提取和检索。
28个python爬⾍项⽬,看完这些你离爬⾍⾼⼿就不远了互联⽹的数据爆炸式的增长,⽽利⽤ Python 爬⾍我们可以获取⼤量有价值的数据:1.爬取数据,进⾏市场调研和商业分析爬取知乎优质答案,筛选各话题下最优质的内容;抓取房产⽹站买卖信息,分析房价变化趋势、做不同区域的房价分析;爬取招聘⽹站职位信息,分析各⾏业⼈才需求情况及薪资⽔平。
2.作为机器学习、数据挖掘的原始数据⽐如你要做⼀个推荐系统,那么你可以去爬取更多维度的数据,做出更好的模型。
3.爬取优质的资源:图⽚、⽂本、视频爬取商品(店铺)评论以及各种图⽚⽹站,获得图⽚资源以及评论⽂本数据。
掌握正确的⽅法,在短时间内做到能够爬取主流⽹站的数据,其实⾮常容易实现。
但建议你从⼀开始就要有⼀个具体的⽬标,在⽬标的驱动下,你的学习才会更加精准和⾼效。
这⾥给你⼀条平滑的、零基础快速⼊门的学习路径:1.了解爬⾍的基本原理及过程2.Requests+Xpath 实现通⽤爬⾍套路3.了解⾮结构化数据的存储4.应对特殊⽹站的反爬⾍措施5.Scrapy 与 MongoDB,进阶分布式下⾯给⼤家展⽰⼀些爬⾍项⽬:有些项⽬可能⽐较⽼了,不能⽤了,⼤家可以参考⼀下,重要的是⼀个思路,借鉴前⼈的⼀些经验,希望能帮到⼤家(1)微信公众号爬⾍地址:https:///Chyroc/WechatSogou基于搜狗微信搜索的微信公众号爬⾍接⼝,可以扩展成基于搜狗搜索的爬⾍,返回结果是列表,每⼀项均是公众号具体信息字典。
(2)⾖瓣读书爬⾍地址:https:///lanbing510/DouBanSpider可以爬下⾖瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中,可⽅便⼤家筛选搜罗,⽐如筛选评价⼈数>1000的⾼分书籍;可依据不同的主题存储到Excel不同的Sheet ,采⽤User Agent伪装为浏览器进⾏爬取,并加⼊随机延时来更好的模仿浏览器⾏为,避免爬⾍被封。
基于聚焦搜索引擎的课程资料库建设初探摘要以我校本科学生自主实验室建设项目为基础,分析了聚焦搜索引擎在课程资料库建设实践方面的可行性。
重点是以聚焦搜索引擎为工具,从网络上抓取课程资料库需求资料,形成完备的、具备可持续更新的课程资料数据库,适应学科发展和知识更新。
关键词聚焦搜索引擎网络爬虫实验室建设一、引言互联网的使用已经渗入到社会的各个层面,特别是教育领域,为高等院校的本科教学提供了庞大的信息资源,但要从这么大的资源库中寻找到自己需要的内容却是非常难。
高校师生经常会使用像google、baidu等搜索引擎来帮助寻找自己要的资源。
但其超大规模的分布式数据源、异构的数据及信息的检索质量不高等问题造成用户很难找到真实要用的信息,使其无法直接为高校师生提供资源服务。
为了解决这一问题,本文探究了一种基于聚焦搜索引擎的课程资源库建设方案,为高校师生提供课程信息资源的检索服务。
二、聚焦搜索引擎实现策略聚焦搜索引擎是实现基于主题的信息采集功能的核心组成部分,一般由爬行队列、网络连接器、主题模型、内容相关度分析以及链接相关度分析等功能模块组成。
其中,爬行队列是由一系列主题相关度较高的url组成。
爬行队列在聚焦搜索引擎进行主题搜索之初是由种子站点组成,这些种子站点可以由该行业领域的专家给出,也可以借助一些权威网站自动生成。
在搜索过程开始之后,系统发现新的url,并根据主题相关度对其排序后补充到爬行队列中。
网络连接器则根据爬行队列中的url,与网络建立连接后以下载其所指页面内容。
主题模型由主题建模方法来实现。
主题词法是常用的主题建模方法;关键词法以一组特征关键词来表示主题内容,包括用户需求主题,以及文档内容主图。
一个关键词可以是单个的词、短语、包括权重语种等属性。
内容相关度分析是指系统对经过内容特征提取后的网页数据进行分析,判定网页内容与指定主题相关度如何,过滤无关页面,保留相关度达到阈值的网页。
链接相关度分析是指系统对从网页中提取的超链信息进行测算,得出每个url所指页面与指定主题的相关度,将符合主题度要求的url加入到爬行队列中并对其进行爬行优先度排序,以保证相关度高的页面优先被检索到。
科技信息 博士・专家论坛 网络爬虫技术的发展趁势 北京交通大学通信与信息系统北京市重点实验室 蔡笑伦 [摘要】搜索引擎不断的发展,人们的需求也在不断的提高,网络信息搜索已经成为人们每天都要进行的内容。如何使搜索引擎能 时刻满足人们的需求,我们需要找到一种方法。本文介绍了搜索引擎的分类及工作原理,阐述了网络爬虫技术的搜索策略,展望新
一代搜索引擎的发展趋势。 [关键词]网络爬虫 策略搜索引擎
网络快速发展的今天,互联网承载着海量的信息,能够准确快速的 提取我们所需要的信息是现在的挑战。传统的搜索引擎有Yahoo, Google,百度等,这些检索信息的工具是人们每天访问互联网的必经之 路。但是,这些传统性搜索引擎存在着局限性,它不能全面的准确的找 到所需要的信息,也会使一些和需求无关的内容一起搜索到。严重的降 低了使用这些信息的效率,所以说提高检索信息的速度和质量是一个 专业搜索引擎主要的研究内容。 1.搜索引擎的研究 1.1搜索引擎的分类 搜索引擎按其工作方式可分为三种,分别是全文搜索引擎,目录索 引类搜索引擎和元搜索引擎。 (1)全文搜索引擎 全文搜索引擎是最常用搜索引擎,大家最熟悉的就是国外的代表 C.ogle,和国内的代表百度。它们通常都是提取各个网站的网页文字存 放在建立的数据库中,检索与用户查询条件匹配的相关记录,然后按其 自己设定的排列顺序将结果返回给用户。 从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥 有自己的检索程序,它们拥有自己的网页数据库,搜索到得内容直接从 自身的数据库中调用,如Google和百度;另一种则是租用其他引擎的数 据库,但是,是按自定的格式排列搜索结果,如Lycos引擎。 (2)目录索引型搜索引擎 目录索引,就是将网站分类,然后存放在相应的目录里,用户在查 询所需要的内容时有两种选择一种是关键词搜索,另一种是按分类目 录一层一层的查找。据信息关联程度排列,只不过其中人为因素要多一 些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先 后以关键词搜索,返回的结果跟搜索引擎一样,也是按自定顺序决定。 目录索引只能说有搜索功能,但仅仅是按目录分类的网站链接列 表。用户完全可以不用进行关键词查询,仅靠分类目录也可找到需要的 信息。目录索引型搜索引擎中最具代表性的是Yahoo(雅虎)。其他著名 的还有LookSmart、About等。国内的搜狐、新浪、网易搜索也都属于这一 类。 (3)元搜索引擎 当用户在进行查询时。元搜索引擎可以同时在其他多个引擎上进 行搜索,将检索结果进行统一处理,并将结果以统一的格式返回给用 户。正因为如此,这类搜索引擎的优点是返回结果的信息量更全面,但 是缺点就是无用的信息太多不能准确的找到用户需要的结果。 具有代表性的元搜索引擎有Dogpile、InfoSpace、Vivisimo等,中文元 搜索引擎中著名的有搜星搜索引擎。 在搜索结果排列方面,不同的元搜索引擎有不同的结果排列的方 式。如Dogpile,就直接按来源引擎排列搜索结果,如Vivisimo,是按自定 的规则将结果重新进行排列。 1.2搜索引擎的工作原理 搜索引擎主要是对用户要求的信息进行自动信息搜集,这个功能 共分为两种:一种是定期搜索,即每隔一段时间搜索引擎主动派出 “Spider”程序,目的是对一定IP地址范围内的互联网站进行检索,如果 一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据 库;另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址, 搜索引擎在一定时间内定向向你的网站派出蜘蛛程序,扫描你的网站 并将有关信息存人数据库,以备用户查询。 如果用户以关键词查询所需要的信息时,搜索引擎会在数据库中 进行搜寻,如果找到与用户要求内容相匹配的网站时,搜索引擎通常根 据网页中关键词的匹配程度,出现的位置/频次,链接质量等特殊的算 法计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将 用户所需要的内容反馈给用户。 2.网络爬虫 2.1通用网络爬虫和聚焦网络爬虫的工作原理 网络爬虫是搜索引擎的重要组成部分,它是一个自动提取网页的 程序,为搜索引擎从网上下载网页。 传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放人队 列,直到满足系统的一定停止条件。 与传统爬虫相比,聚焦爬虫的工作流程则较为复杂,需要根据一定 的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入 等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择 下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件
基于Python的网络爬虫系统的设计与实现
摘要
互联网技术的成熟和网络招聘方式的兴起使得大学生越来越倾向于选择互联网行业就业。
为了帮助人们了解招聘状况并提供求职指导,本文利用数据挖掘技术挖掘了拉勾网的招聘数据,设计实现了一个数据分析系统,提供清晰的数据展示和洞察。
该系统具备数据获取、导入、处理、分析和可视化展示等关键功能。
通过网络爬虫技术从拉勾网获取职位信息,经过数据导入和处理,系统运用聚类、关键词提取和关联规则挖掘等算法进行数据分析,提供热门职位、技能关键词和相关规则的分析结果。
系统采用Python开发语言和Django框架进行实现。
通过网络爬虫获取职位信息,并通过数据导入和处理模块对数据进行清洗和预处理。
系统运用聚类、关键词提取和关联规则挖掘算法进行数据分析,最后利用可视化库实现数据的直观展示。
关键词:网络爬虫;数据分析;关键词提取;关联规则挖掘;可视化展示
1。
ELECTRONICS WORLD·技术交流
基-3=荚键词g-3重题网络爬密
南京航空航天大学周 萍
【摘要】通常来说,用户从搜索引擎获取的网页中,大部分都是不符合特定需求的,只有一小部分才是想要的结果。网络爬虫在搜索引擎中
扮演着重要的角色,起着关键性的作用。本文主要讲述了基于关键词的网络爬虫,通过使用相关性决策机制和本体的知识来设计出最合适的
爬虫抓取路径。和传统的网络爬虫相比较,本文设计的爬虫具有最优性,并通过高准确性来提高搜索效率。
【关键词】网络爬虫;基于特定主题的网络爬虫;本体;关键词;知识路径
0引言
网络爬虫主要下载主题相关的网页或者满足用户需求的特定网
页,而不是像传统的搜索引擎那样下载整个Web网页库。因此,主
题爬虫的基本要求是选择那些满足用户需求的网页。链接分析算法 和网页排序算法一样,通常根据URLs的相关性和搜索策略对URLs 进行排序,然后优先下载那些特定网页。 本文提出了基于关键词的主题网络爬虫算法,该算法是根据优 先级和领域本体找出网页的URLs。此外,知识路径在寻找主题相 关网页中也发挥着重要的作用。 网络爬虫是搜索引擎的重要模块。在传统的网络爬虫中,将种 子URL作为爬虫工作的初始URL。在分析了种子URL的网页内容之 后,爬虫开始下载网页,然后抽取出所有的超链接,并把这些链接 存储到uRL队列中,递归执行上述过程,直到获得了相关结果。 网络爬虫的关键问题就是从web中只下载重要的网页,然后分 析这些网页中uRL的优先级,并根据优先级放到uRL队列中的合适 位置。网路爬虫的两大问题如下所示: (1)计算爬虫抓取的网页 的优先级; (2)设计爬虫抓取网页的爬行策略。 1基于关键词的主题网络爬虫算法 1.1背景 如今网络的规模越来越大,信息的更新率变快。网络拥有大量的 数据信息,所以爬虫需要根据URL的优先级来下载满足需求的网页。 爬虫根据领域知识下载一小部分网页,这些网页的大部分内容 是主题相关的,因此没有必要从网上下载所有的网页。网页内容的 主题重要度主要取决于链接和被访问量。因此,很有必要提出一个 可靠的爬虫算法。 1.2爬虫算法的研究设计及具体步骤 爬虫算法的基本步骤是将URLs种子队列作为输入,然后重复 执行分布式的步骤。从地址列表中取出某个地址,确认该地址的主 机名,然后将网页翻译成对应的文档信息,接着抽取出其中的超链 接。对于每一个被抽取的链接,检查它们的绝对地址,并把它们添 加到uRLs的列表中,前提是它们之前没有被访问过。该算法规则 需要一个组件来存储下载的URLs队列。 此外,还需要将主机地址解析成以下三部分: (1)一部分用 来下载文档; (2)一部分用来从超文本标记语言中抽取超链接: (3)一部分用来判断该地址之前是否被访问过。 本文设计的爬虫算法主要分六步,具体步骤如下所示: (1)选 择一个URL种子作为算法的输入; (2)构造本体知识树,并找出知 识路径: (3)下载初始输入URL对应的网页; (4)从下载的网页中 抽取出超链接内容,并把它们插入到URL队列中; (5)挖掘更多的 主题相关的URL,下载该URL对应的网页,并从中抽取出超链接, 最后把这些超链接插入到URL队列中; (6)重复上述步骤,获得 更多的主题相关的结果。 2实验结果以及讨论 验。实验中,软件系统和硬件环境是不变的。分别比较网络爬虫的 关键词有本体和没有本体这两种情况。 实验中用到的参数是:Depth for looking out=2;Number of thread=5;Initial seed=1;Seed universal resource locator is=http:// 、)l .google.corn;Concept in ontology=Java。 基于相同的软件系统和硬件环境,实验获得的结果如表2.1所示:
表2.1两种爬虫系统的比较
2_2本体和知识路径
本体是结构信息的其中一项技术,它也叫树或者图。本体将
信息系统进行分层设置,分层的结构是一个有向无环图(directed
acyclic graph,DAG)。参考本体根据不同的关联关系设置了“is a”,
“has ’,“part of’。本体被用来构造信息和过滤信息。
假设本体结构如图2.1所示,其中包括不同的结点以及相互之
间的联系,这些联系代表了结点之间的关系。
本体结构类似于Google网页目录的分层目录结构。假如寻找
‘'java”,知识路径是:Branch.>computer.>programming.>iava。爬
虫根据这条URL开始抓取网页,初始的URL种子是:http://www.
google.corn。在下载网页之后,从页面内容中寻找可用的链接(比
如u1.U2……Un),然后把这些链接加入到uRL队列中。这些链
接U1,U2……Un需要被检查是否和关键词相匹配,爬虫的知识路
径就是由这些关键词组成的。第二条URL是:http://www.google.
corn/references/computer.html,其中包含关键词“computer”,和图
的第一层级的结点相匹配。第三条URL是:http://www.google.com/
references/computer/programming.html第四条URL是:http://www.
google.com/references/computer/programming/java.html
上述算法不能通过“art”或者其他分支来找到目标节点‘'java”
因为父母结点“Computer'’和‘'java”相关。
3结论
相较于其他网络爬虫来说,使用基于关键词的主题网络爬虫的
优点是智能性、高效性、不需要关联性反馈。本文提出的爬虫算法
减少了爬虫抓取网页的数量,因此爬虫抓取的时间变少,这是因为
爬虫只下载主题相关的网页。主题网络爬虫的目的就是获取主题
相关的网页,舍弃主题无关的网页。本文设计了基于最佳知识路径
的爬虫的本体,本体通过关联决策机制来获取网页。和传统的爬虫
相比较,本文提出的爬虫具有如下优势: (1)从下载的网页中获
取URLs的数目变少; (2)爬虫的抓取时间变少。
电子tl|界·179·