汉语自动分词与词性标注
- 格式:ppt
- 大小:1.21 MB
- 文档页数:117

中文分词与词性标注技术研究与应用中文分词和词性标注是自然语言处理中常用的技术方法,它们对于理解和处理中文文本具有重要的作用。
本文将对中文分词和词性标注的技术原理、研究进展以及在实际应用中的应用场景进行综述。
一、中文分词技术研究与应用中文分词是将连续的中文文本切割成具有一定语义的词语序列的过程。
中文具有词汇没有明确的边界,因此分词是中文自然语言处理的基础工作。
中文分词技术主要有基于规则的方法、基于词典的方法和基于机器学习的方法。
1.基于规则的方法基于规则的中文分词方法是根据语法规则和语言学知识设计规则,进行分词操作。
例如,按照《现代汉语词典》等标准词典进行分词,但这种方法无法处理新词、歧义和未登录词的问题,因此应用受到一定的限制。
2.基于词典的方法基于词典的中文分词方法是利用已有的大规模词典进行切分,通过查找词典中的词语来确定分词的边界。
这种方法可以处理新词的问题,但对未登录词的处理能力有所限制。
3.基于机器学习的方法基于机器学习的中文分词方法是利用机器学习算法来自动学习分词模型,将分词任务转化为一个分类问题。
常用的机器学习算法有最大熵模型、条件随机场和神经网络等。
这种方法具有较好的泛化能力,能够处理未登录词和歧义问题。
中文分词技术在很多自然语言处理任务中都起到了重要的作用。
例如,在机器翻译中,分词可以提高对齐和翻译的质量;在文本挖掘中,分词可以提取关键词和构建文本特征;在信息检索中,分词可以改善检索效果。
二、词性标注技术研究与应用词性标注是给分好词的文本中的每个词语确定一个词性的过程。
中文的词性标注涉及到名词、动词、形容词、副词等多个词性类别。
词性标注的目标是为后续的自然语言处理任务提供更精确的上下文信息。
1.基于规则的方法基于规则的词性标注方法是根据语法规则和语境信息,确定每个词语的词性。
例如,根据词语周围的上下文信息和词语的词义来判断词性。
这种方法需要大量的人工制定规则,并且对于新词的处理能力较差。

分词及词性标注在英文中,计算机能够利用词语之间的空格来辨别每一个单词词语,但是由连续中文文本组成的汉语序列,因为其词和词之间没有任何标识来进行划分,所以计算机无法方便的直接进行分词处理。
然而计算机在对语句进行处理分析的时,由于对其的处理全部是以词语作为基本语言单位的,所以对语句进行分词处理从而成为离散的词语序列便是专利设计目标提取首先要完成的内容。
面向中文语句的分词的研究在目前已经提出了十余种中文分词方法,并成功研发了若干个相关的系统组件,目前基本可以将这些方法分为以词典为基础的方法和以知识规则为基础的方法这两个类别,以词典为基础的学习方法的代表有基于最大熵的方法、基于隐马尔科夫模型的方法等,以知识规则为基础的学习方法的代表有N-最短路径方法、最少切分法和最大匹配算法等。
上述这些算法都有自己的不足之处,其中现阶段面临的问题大致有两个,其一是对未登录词识别的问题,这些词没有被中文分词词典收录,所以当这些专业词汇在词法分析时,它们的识别率通常较低,往往不会被切分出来,从而造成错误的出现;其二是歧义切分的问题,是指如果依照不同的切分方法,那么即使是切分同一个语句,最后切分出的结果也会不同。
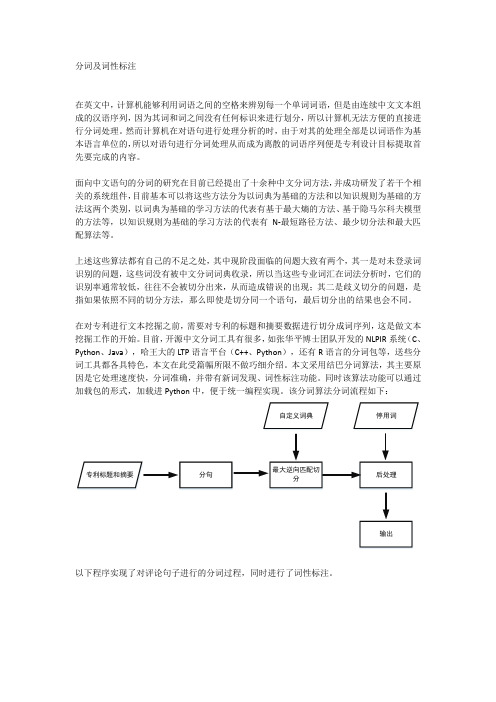
在对专利进行文本挖掘之前,需要对专利的标题和摘要数据进行切分成词序列,这是做文本挖掘工作的开始。
目前,开源中文分词工具有很多,如张华平博士团队开发的NLPIR系统(C、Python、Java),哈王大的LTP语言平台(C++、Python),还有R语言的分词包等,送些分词工具都各具特色,本文在此受篇幅所限不做巧细介绍。
本文采用结巴分词算法,其主要原因是它处理速度快,分词准确,并带有新词发现、词性标注功能。
同时该算法功能可以通过加载包的形式,加载进Python中,便于统一编程实现。
该分词算法分词流程如下:专利标题和摘要分句最大逆向匹配切分后处理输出自定义词典停用词以下程序实现了对评论句子进行的分词过程,同时进行了词性标注。

基于深度学习方法的中文分词和词性标注研究中文分词和词性标注是自然语言处理中的重要任务,其目的是将输入的连续文字序列切分成若干个有意义的词语,并为每个词语赋予其对应的语法属性。
本文将基于深度学习方法对中文分词和词性标注进行研究。
一、深度学习方法介绍深度学习是一种基于神经网络的机器学习方法,在自然语言处理领域中应用广泛。
经典的深度学习模型包括卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)、长短时记忆网络(LongShort-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)等。
在对中文分词和词性标注任务的研究中,CNN、RNN以及LSTM均被采用。
CNN主要用于序列标注任务中的特征提取,RNN及LSTM则用于序列建模任务中。
GRU是LSTM的一种简化版本,在应对大规模文本序列的过程中更为高效。
二、中文分词中文分词是将一段连续的汉字序列切分成有意义的词语。
传统的中文分词方法主要包括基于词典匹配的分词和基于统计模型的分词。
基于词典匹配的分词方法基于预先构建的词典,将待切分文本与词典进行匹配。
该方法精度较高,但需要较为完整的词典。
基于统计模型的分词方法则通过学习汉字之间的概率关系来进行分词。
该方法不依赖于完整的词典,但存在歧义问题。
深度学习方法在中文分词任务中也有较好的表现,通常采用基于序列标注的方法。
具体步骤如下:1. 以汉字为单位对输入文本进行编码;2. 使用深度学习模型进行序列标注,即对每个汉字进行标注,标记为B(词的开头)、M(词的中间)或E(词的结尾),以及S(单字成词);3. 将标注后的序列按照词语切分。
其中,深度学习模型可以采用CNN、RNN、LSTM或GRU等模型。
三、中文词性标注中文词性标注是为每个词语赋予其对应的语法属性,通常使用含有标注数据的语料库进行训练。


基于深度学习的中文自动分词与词性标注模型研究1. 引言中文自动分词与词性标注是中文文本处理和语义分析的重要基础任务。
传统方法在处理中文自动分词和词性标注时,通常采用基于规则或统计的方法,并且需要大量的特征工程。
然而,这些传统方法在处理复杂语境、歧义和未知词汇等问题时存在一定的局限性。
随着深度学习的发展,基于神经网络的自然语言处理方法在中文自动分词和词性标注任务上取得了显著的成果。
深度学习方法通过利用大规模的文本数据和端到端的学习方式,避免了传统方法中需要手动设计特征的问题,能够更好地解决复杂语境和未知词汇等挑战。
本文将重点研究基于深度学习的中文自动分词与词性标注模型,探讨这些模型在中文文本处理中的应用和效果,并对未来的研究方向进行展望。
2. 相关工作在深度学习方法应用于中文自动分词和词性标注之前,传统的方法主要基于规则或统计模型。
其中,基于规则的方法采用人工定义的规则来处理中文分词和词性标注任务,但这种方法需要大量人力投入且难以适应不同语境。
另一方面,基于统计模型的方法则依赖于大规模的语料库,通过统计和建模的方式进行分词和词性标注。
然而,这些方法在处理复杂语境和未知词汇时效果有限。
近年来,随着深度学习的兴起,基于神经网络的中文自动分词和词性标注模型逐渐成为研究热点。
其中,基于循环神经网络(RNN)的模型如BiLSTM-CRF(双向长短时记忆网络-条件随机场)模型被广泛使用并取得了令人瞩目的效果。
该模型利用LSTM单元来捕捉输入序列的上下文信息,并利用条件随机场模型来建模序列标注问题。
此外,基于注意力机制的模型如Transformer也在中文自动分词和词性标注任务中取得了优异的表现。
3. 深度学习方法在中文自动分词中的应用中文自动分词是将连续的汉字序列划分为具有独立语义的词组的任务。
传统的基于规则或统计的方法在处理未知词汇和复杂语境时存在一定的限制。
而基于深度学习的方法通过端到端的学习方式,可以更好地捕捉上下文信息,并通过大规模的语料库进行训练,从而提高分词的准确性和鲁棒性。
当代汉语文本分词、词性标注加工规范973当代汉语文本语料库分词、词性标注加工规范(草案)山西大学从1988年开始进行汉语语料库的深加工研究,首先是对原始语料进行切分和词性标注,1992年制定了《信息处理用现代汉语文本分词规范》。
经过多年研究和修改,2000年又制定出《现代汉语语料库文本分词规范》和《现代汉语语料库文本词性体系》。
这次承担973任务后制定出本规范。
本规范主要吸收了语言学家的研究成果,并兼顾各家的词性分类体系,是一套从信息处理的实际要求出发的当代汉语文本加工规范。
本加工规范适用于汉语信息处理领域,具有开放性和灵活性,以便适用于不同的中文信息处理系统。
《973当代汉语文本语料库分词、词性标注加工规范》是根据以下资料提出的。
1.《信息处理用现代汉语分词规范》,中国国家标准GB13715,1992年2.《信息处理用现代汉语词类标记规范》,中华人民共和国教育部、国家语言文字工作委员会2003年发布3.《现代汉语语料库文本分词规范》(Ver 3.0),1998年北京语言文化大学语言信息处理研究所清华大学计算机科学与技术系4.《现代汉语语料库加工规范——词语切分与词性标注》,1999年北京大学计算语言学研究所5.《信息处理用现代汉语词类标记规范》,2002年,教育部语言文字应用研究所计算语言学研究室6.《现代汉语语料库文本分词规范说明》,2000年山西大学计算机科学系山西大学计算机应用研究所7.《資讯处理用中文分词标准》,1996年,台湾计算语言学学会一、分词总则1.词语的切分规范尽可能同中国国家标准GB13715《信息处理用现代汉语分词规范》(以下简称为“分词规范”)保持一致。
本规范规定了对现代汉语真实文本(语料库)进行分词的原则及规则。
追求分词后语料的一致性(consistency)是本规范的目标之一。
2.本规范中的“分词单位”主要是词,也包括了一部分结合紧密、使用稳定的词组以及在某些特殊情况下可能出现在切分序列中的孤立的语素或非语素字。