单倍型
- 格式:ppt
- 大小:6.46 MB
- 文档页数:12

目录 [隐藏]∙ 1 树形图∙ 2 单倍型类群A 和 B∙ 3 有M168 (CT)变异的单倍型类群 ∙ 4 单倍型类群 F (G, H & IJK) ∙ 5 单倍型类群 K (M9) ∙ 6 单倍型类群 NO (M214) ∙ 7 单倍型类群 P (M45) ∙ 8 单倍型类群在欧洲的时间发展 ∙ 9 同见 ∙ 10参考文献 ∙11 外部链接[编辑]树形图单倍型类群 S [编辑]单倍型类群A 和B单倍型类群A是非洲人的子单倍型类群,现代的所有单倍型类群起源点。
BT是单倍型类群A的分支。
它有两个主要谱系,单倍型类群B和CT。
定义突变分离CT(除A和B的所有单倍型类群)为M168和M294。
这些突变早于“走出非洲”的迁移。
DE突变的定义可能发生在非洲东北部,大约65,000年前。
[1] P143突变定义了单倍型类群CF。
可能发生在那时,将现代人类带至亚洲南部海岸。
亚, 密克罗尼西亚, 和玻利尼西亚▪单倍型类群C3分布▪单倍型类群D2 (M55, M57, M64。
1, M179, P12, P37。
1, P41。
1 (M359。
1), 12f2。
2)▪单倍型类群D3 (P47)▪单倍型类群E(Y-DNA)分布单倍群F和其后代分布▪单倍型类群F*分布于南部印度, 斯里兰卡, 云南, 朝鲜半岛▪单倍型类群G分布▪单倍型类群G2c1▪单倍型类群H分布45000年前分离▪单倍型类群I分布岛 I2B1 (m223)主要分布于西部, 中部,和北欧。
▪单倍型类群J分布▪单倍型类群L (M20) 分布于南亚, 中亚, 西南亚,地中海▪单倍型类群T分布单倍型类群O分布单倍型类群Q分布Q被定义由SNP M242。
认为出现在大约35000-40000年前的中亚。
单倍型类群Q的亚类型和定义变异,根据2008 ISOGG树[4]在下文提供。
ss4 bp, rs41352448, 不出现在ISOGG 2008树因为STR。

Haplogroup R1b (Y-DNA)在人类遗传学,单倍群r1b是最经常发生的Y染色体单倍型类群在西欧,部分中央欧亚大陆(例如巴什基尔[ 3 ]),并在撒哈拉以南非洲中部(例如在乍得和喀麦隆)。
r1b也是目前在较低频率的整个东欧,西亚,中亚,和部分南亚和北非。
由于欧洲移民也达到高频率在美洲和澳大利亚。
而西欧主要是由r1b1a2(r-m269)分支的r1b,chadic-speaking非洲地区为主的分公司称为r1b1c(r-v88)。
这些代表了非常成功的“树枝”在一个更大的“家庭树”。
“r1b”,“r1b1”,等等都是“进化”或家庭树的名字解释分支的家谱r1b。
例如r1b1a 和r1b1b将分支r1b1降,从一个共同祖先。
这意味着,这些名称可以改变的新发现。
替代道路命名单倍群是指单核苷酸多态性突变用于定义和确定,例如“r-m343”相当于“r1b单倍群。
”r1b是换句话说,现在确定存在的单核苷酸多态性(单核苷酸多态性)基因突变m343,这是发现在2004。
[ 4]从2002至2005,r1b的定义存在的单核苷酸多态性的命名系统。
标准化命名如上所述,使用系统发育或突变系统,首次提出在2002染色体的财团。
2002之前,今天的单倍群r1b有一些名字在不同的命名系统,如hg1和eu18。
[ 5]2002后,一个重大更新的系统发育命名你的概念车是在2008的karafet等人。
它考虑了新发现的分支,可以明确界定的单核苷酸多态性突变,其中包括一些变化的理解,r1b的家谱。
[ 1]2008以来已成为越来越需要参考的经常更新的网站列出了isogg。
[ 2]也在2002之前,主要的基因签名的基础上标记比其他的单核苷酸多态性是公认的。
在西欧,单倍型被称为大西洋模态单倍型被认为是最常见的威尔逊等人。
[ 6]甚至更早的研究采用限制性片段长度多态性基因分型确定不同的单体型在现在所称的r1b1b2。
在欧洲东南部和亚洲西南部(例如巴尔干地区,格鲁吉亚和土耳其)“单倍型35”或“ht35”被认为是一种常见的形式,r1b1b2,而在西欧的“单倍型15”或“ht15”为主的频率。

变异性分析中不管怎样划分种群都是需要选取核心单倍型变异性分析中的核心单倍型选择随着人类种群研究的逐渐深入,越来越多的人开始涉足变异性分析领域。
在这个领域中,我们需要对不同的种群进行比较,以了解它们之间的差异和相似之处。
然而,在进行变异性分析时,选择核心单倍型是至关重要的,因为这将直接影响到我们的结果和结论。
本文将讨论为什么不管怎样划分种群都是需要选取核心单倍型。
什么是核心单倍型?核心单倍型指的是在种群中频率最高的单倍型或基因型。
在分析种群的变异性时,核心单倍型通常被用作参考基准,因为它代表了该种群中的主要基因型。
根据种群大小和复杂性的不同,核心单倍型的选择可能存在挑战和争议。
为什么需要选择核心单倍型?在进行变异性分析时,通常需要对某个区域的基因进行测序,以确定基因型。
这个区域可以是人类基因组的一小部分,也可以是完整的染色体。
随着频率更高的基因型的发现,核心单倍型往往会变化。
如果不选择核心单倍型,则很难进行种群比较,因为不同的基因型数量和类型可能会相互影响,导致结果的误差和混淆。
因此,核心单倍型选择在变异性分析中是非常重要的。
为什么不管怎样划分种群都是需要选择核心单倍型?在变异性分析中,我们通常需要进行种群分组,以便对比不同种群间的遗传差异。
这种分组可以基于地理位置、性别、种族、年龄等诸多因素进行。
无论该种群如何划分,都需要在每个种群中选择核心单倍型,以确保结果的一致性和精度。
如果没有选择核心单倍型,可能会导致以下问题:1.种群比较的不一致性由于不同的基因型数量和类型,不同种群之间可能会出现误差和混淆,导致结果不可靠。
2.数量有限的数据集如果数据集过小,则有可能无法选择出频率最高的基因型作为核心单倍型,这将使得结果不准确。
3.数据集数量不平衡如果一个数据集中有一些异常值或不同种群的数据不平衡,那么选择核心单倍型就更加困难。
为了解决这些问题,我们需要在变异性分析中始终选择核心单倍型,并以它为基准进行种群比较。


120猪业科学 SWINE INDUSTRY SCIENCE 2017年34卷第08期遗传改良GENETIC IMPROVEMENT 北京顺鑫农业小店种猪分公司协办单倍型分析及其在全基因组关联分析中的研究进展宋志芳,于国升,邢荷岩,芦春莲,曹洪战*(河北农业大学动物科技学院,河北 保定 071000)基金项目:河北省科技计划项目“深县猪新品系的选育”(15226301D)作者简介:宋志芳(1992-),女,硕士研究生,研究方向为动物遗传育种,E-mail :187********@ 通讯作者:曹洪战(1970-),男,教授,博士,硕士、博士研究生导师,研究方向为养猪生产,动物遗传育种与繁殖,E-mail:chz516@如果要分析某基因中单个位点与动植物复杂疾病或性状的关联程度,产生的结果可能是可靠的[1]。
对某区域内多个位点组成的单倍型块与疾病或性状进行分析,才可能找到与之相关的遗传标记,进而发掘相关的候选基因[2]。
单倍型分析已经成为连锁不平衡分析和寻找重要基因等的工具。
可以通过多种方式和途径进行单倍型的构建及其频率的获得,比如对染色体进行测序、遗传标记结合家系信息进行连锁分析和通过软件计算群体的单倍型频率等[3]。
通过候选基因法和连锁不平衡法可以确定与研究对象相关的单核苷酸多态,但前者需要全基因组测序,成本高。
在对SNP 芯片数据与性状进行GWAS 分析时,单倍型分析是其中重要的一环,获得与疾病或性状显著相关的SNPs 后,判断位点间的连锁程度,并计算每个单倍型的频率及其与疾病或性状相关性的P 值,找到全基因组内是否存在单倍型。
在关联分析中,应该有效利用SNP 信息,找到更多与动植物疾病或性状相关的可靠SNP位点,进行疾病治疗和动植物育种。
1 单倍型分析的有关概念1.1 单倍型(haplotype)单倍型指在同一染色体上或一定区域内若干个决定同一性状的且紧密连锁的SNPs,具有统计学关联性,可以是两个基因座或整条染色体。

如何利用dnasp软件计算单倍型多样性,PAUP软件构建MP树1、利用BioEdit和Clustalx对所有需要构建系统进化树的个体进行序列比对2、将Clustalx比对结果中的*.aln文件利用BioEdit打开,在其中删除clustal cons文件,这时候有一行“*******”消失,将该文件转存为*.fst格式文件。
3、用dnasp软件打开该文件,弹出对话框选择关闭,然后选择analysis→DNApolymorphism,弹出对话框看一下序列长度对不对,然后点击OK,在弹出的对话框中的Number of Haplotypes,后面对应的数值即为单倍型多样性,Standard Deviation of Haplotype diversity后面对应为SD(标准差)值。
在该对话框中Nucleotidy diversity即为核苷酸多样性。
注:单倍型多样性即指在某一个种群或几个种群中存在差异序列的数量。
4、用dnasp软件打开该文件,弹出对话框选择关闭,然后选择Genetate→HaplotypeDate file,弹出对话框看一下序列长度对不对,然后点击OK,在弹出的对话框中输入保存的路径和文件名(注意不要修改扩展名),点击确定,在弹出的对话框中给出了单倍型数量和每个单倍型中包含的样本信息,在后续处理中每个单倍型只需选择一个样本。
5、用dnasp软件打开该文件,弹出对话框选择关闭,然后选择Overview→polymorphismdate,弹出对话框看一下序列长度对不对,然后点击OK,里面有单倍型多样性和核苷酸多样性信息。
6、由于PAUP并不识别该格式软件,因此需要利用dnasp软件将其转存为*.nex格式,方法如下,用dnasp软件打比对后的*.fat格式文件,在菜单中选择file→save/export date as→NEXUS file format,命名,选择路径。
7、打开PAUP软件,打开刚才利用dnasp转存的文件。


stacks 基础:SNP 、基因座、等位基因、基因型、单倍型的概念相关系列第⼀期请戳:stacks 拆包RAD-seq 过程中 process_radtags 没有⾃⼰需要的限制性内切酶怎么办?在stacks 运⾏完毕后,会有*.alleles.tsv.gz, *.snp.tsv.gz, *.matchs.tsv.gz 等结果⽂件⽣成,如果对SNP 、基因座(locus)、等位基因(alleles)、基因型(genotype)和单倍型(haplotypes)的概念没有深刻的理解的话,要读懂这些结果⽂件是⾮常困难的,本⽂将以解析这些概念为切⼊点,解读stacks 产⽣的结果⽂件。
SNPsnp 的定义是单核苷酸多态性(single nucleotide polymorphism),SNP 所表现的多态性只涉及到单个碱基的变异,这种变异可由单个碱基的转换(transition)或颠换(transversion)所引起,如图1所⽰,也可由碱基的插⼊或缺失所致。
但通常所说的SNP 并不包括后两种情况。
图1.SNP (灰⾊表⽰男性的X 染⾊体,蓝⾊表⽰男性的Y 染⾊体)打开stacks 产⽣的结果⽂件GZ1.tags.tsv.gz ,这是ustacks 运⾏结束后⽣成的,原⽂件内容截取部分如下:[bash]# less GZ1.tags.tsv.gz# ustacks version 2.2; generated on 2020-12-31 21:57:221 2 consensus AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTCATCCCTA 1 2 modelOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOUUUUUOOUUUUUOOOEEOEOOOUUUUUUU 1 2 primary 0 282_7_2116_32106_32390/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTNNNNCCTNNNNTGTCTGATTTTCATCCCTA 1 2 primary 0 282_7_2116_32136_32408/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTNNNNCCTNNNNTGTCTGATTTTCATCCCTA 1 2 primary 0 282_7_2218_1834_36346/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTNNNNCCTNNNNTGTCTGATTTTCATCCCTA 1 2 primary 1 236_6_1105_23206_10679/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTNNNNNNNN 1 2 primary 1 236_6_2211_23409_10187/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTNNNNNNNN 1 2 primary 1 282_7_1207_5792_18063/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTNNNNNNNN 1 2 primary 1 282_7_1207_8166_18450/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTNNNNNNNN 1 2 primary 1 282_7_1207_5558_18537/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTNNNNNNNN 1 2 primary 1 282_7_1217_3112_55262/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTNNNNNNNN 1 2 primary 1 282_7_1217_2869_55965/1AATTAGGAAGGATTGGTCGACGAAATATGAACCGAAGACTGAACCTTGATATACCCCATAACAATACATTTTTGTTACCACGAGACATATTGGCAGCCGCTGATCATTTGATTGGACTTAAATTGTTTCCTGTTAGGTCAAAATTTNNNNNNNN为了⽅便观察,我们把⽬光聚焦到后半段:1 2 consensus AAATTGTTTCCTGTTAGGTCAAAATTTCATCCCTA 1 2 model OOOOOUUUUUOOUUUUUOOOEEOEOOOUUUUUUUU 1 2 primary 0 AAATTNNNNCCTNNNNTGTCTGATTTTCATCCCTA 1 2 primary 0 AAATTNNNNCCTNNNNTGTCTGATTTTCATCCCTA 1 2 primary 0 AAATTNNNNCCTNNNNTGTCTGATTTTCATCCCTA 1 2 primary 1 AAATTGTTTCCTGTTAGGTCAAAATTTCNNNNNNN 1 2 primary 1 AAATTGTTTCCTGTTAGGTCAAAATTTCNNNNNNN 1 2 primary 1 AAATTGTTTCCTGTTAGGTCAAAATTTCNNNNNNN 1 2 primary 1 AAATTGTTTCCTGTTAGGTCAAAATTTCNNNNNNN 1 2 primary 1 AAATTGTTTCCTGTTAGGTCAAAATTTCNNNNNNN 1 2 primary 1 AAATTGTTTCCTGTTAGGTCAAAATTTGNNNNNNN 1 2 primary 1 AAATTGTTTCCTGTTAGGTCAAAATTTGNNNNNNN第⼀⾏是consensus ,是由样本的多个locus 形成的⼀致性序列,第⼆⾏是model ,表明在形成⼀致性序列的时候,每个位点的⼀致性状况,O 代表完全⼀致,U 代表Unknown ,E 代表SNP 位点。

单倍型数据分析在人类遗传链研究中的应用第一章:前言人类DNA由数百万碱基对组成,其中部分常常会因为基因重组而被重新排列形成新的单倍型序列。
单倍型描述了一个个体所拥有的某一段DNA的序列排列方式。
单倍型数据分析可以帮助研究人类遗传链的演化历程,并且在研究疾病的遗传基础方面具有重要价值。
第二章:单倍型数据分析的基本概念单倍型数据分析是利用生物信息学技术对人体的基因重组信息进行深入分析,以揭示人类DNA序列的演化和遗传遗产的分布情况。
单倍型是指一条染色体上一段基因的不同排列方式,每个人都拥有多个单倍型。
单倍型标记的 SNP 是指在基因组上常见的广泛多态性的细小变异。
单倍型标记的基因型数据定义为单个N个SNP位点信号的组合。
第三章:单倍型数据分析的实现方法单倍型数据分析的实现方法主要包括分子生物学实验和对得到的数据进行信息学处理两部分。
分子生物学实验主要包括样本提取、测序、SNP筛选和单倍型分析等。
对单倍型数据进行信息学处理时,需要建立一个样本的基因型数据信息库,根据基因型数据计算不同样本之间的单倍型差异,使用遗传学和数学模型对遗传链的演化历程进行分析。
第四章:单倍型数据分析在人类演化历程研究中的应用单倍型的研究在人类演化史的研究中具有重要意义。
人类演化的历程可以通过对全球不同地区的单倍组型数据进行比较和分析来研究,以此来揭示人类群体的遗传多样性。
这些研究已经揭示出来人类在不同地理区域的演化历程和人类迁徙的历史。
例如,可以用单倍型数据对非洲裔美国人和韩国人进行DNA比较,发现它们之间有明显的遗传差异,可以对人类大规模迁徙提供新的证据。
第五章:单倍型数据分析在疾病遗传基础研究中的应用单倍型数据分析同样可以应用于人类疾病的研究。
通过对单倍型数据的分析,可以揭示某些基因与某些疾病的关系,例如单倍型分析发现 15q11-13 这个区域可能存在与自闭症的关联。
同时,对疾病的遗传因素进行研究也是单倍型数据分析的重要应用之一。
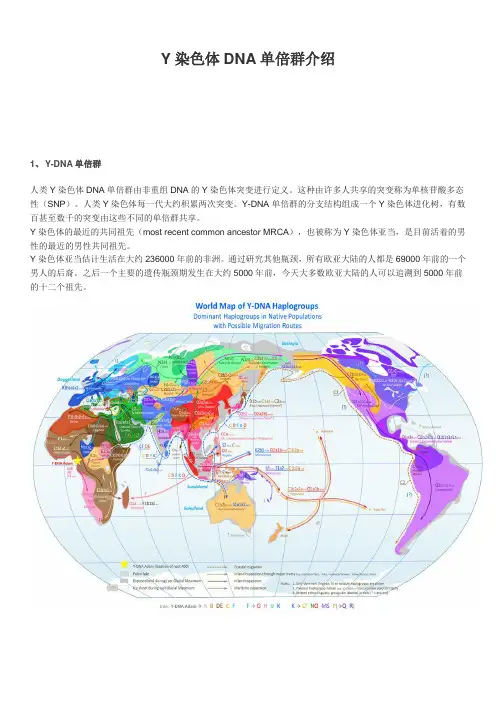
Y染色体DNA单倍群介绍1、Y-DNA单倍群人类Y染色体DNA单倍群由非重组DNA的Y染色体突变进行定义。
这种由许多人共享的突变称为单核苷酸多态性(SNP)。
人类Y染色体每一代大约积累两次突变。
Y-DNA单倍群的分支结构组成一个Y染色体进化树,有数百甚至数千的突变由这些不同的单倍群共享。
Y染色体的最近的共同祖先(most recent common ancestor MRCA),也被称为Y染色体亚当,是目前活着的男性的最近的男性共同祖先。
Y染色体亚当估计生活在大约236000年前的非洲。
通过研究其他瓶颈,所有欧亚大陆的人都是69000年前的一个男人的后裔。
之后一个主要的遗传瓶颈期发生在大约5000年前,今天大多数欧亚大陆的人可以追溯到5000年前的十二个祖先。
Y-DNA单倍群进化树单倍群 A & B 单倍群 A(M91)单倍群A是所有单倍群起源点。
现代所有单倍群都是单倍群A的后代,稀疏分布在非洲,主要集中在西南部的科伊桑人和尼罗河谷东北部人群。
单倍群 BT (M42,M94,M139,M299)约55000年前分,BT是单倍群A的分支单倍群B(M60)单倍群B主要分布于非洲,主要集中于俾格米人群。
详细树形图:见B单倍群文件夹单倍群 CT (P143)标识单倍群 CT的突变标记是M168和M294.包含单倍群D、E、C、F,可能88000年前在亚洲或非洲出现。
单倍群 C (M130)历史起源:C单倍群携带M130突变,来源于CF单倍群。
中国境内的C单倍群主要是C2(携带M217突变),占中国总人口比例大约为5%—10%。
其下游又可分为南北两大支,北支C2b(携带F1396突变),主要分布于蒙古族和满族等民族;南支C2c(携带F1067突变),几乎遍及全中国。
详细树形图:见C单倍群文件夹Haplogroup C (M130, M216) 分布在亚洲、大洋洲和北美等o Haplogroup C1 (F3393/Z1426)▪Haplogroup C1a (CTS11043)▪Haplogroup C1a1 (M8, M105, M131) 日本低频分布▪Haplogroup C1a2 (V20) 欧洲和尼泊尔低频分布▪Haplogroup C1b (F1370, Z16480)▪Haplogroup C1b1 (AM00694/K281)▪Haplogroup C1b1a (B66/Z16458)▪Haplogroup C1b1a1 (M356) 印度低频分布, 阿拉伯半岛和中国北部▪Haplogroup C1b2 (B477/Z31885)▪Haplogroup C1b2a (M38) 分布在印度尼西亚,新几内亚岛,美拉尼西亚,密克罗尼西亚,和玻利尼西亚▪Haplogroup C1b2b (M347, P309) 澳洲土著o Haplogroup C2 (M217, P44) 分布在欧亚大陆和北美,特别是在蒙古人,哈萨克人,通古斯人,西伯利亚人,和Na-Dené-speaking语民族单倍群DE(M1,M145,M203)约65000年前分离单倍群D (M174)详细树形图:见D单倍群文件夹∙Haplogroup D (M174) 分布在日本、中国(特别分布于西藏)和安达曼岛o D1 (CTS11577)▪D1a (Z27276, Z27283, Z29263)▪Haplogroup D1a1 (M15) 主要分布在西藏、羌族、彝族和苗瑶语人群▪Haplogroup D1a2 (P99) 主要分布在西藏、羌族、纳西族、突厥部落▪Haplogroup D1b (M55, M57, M64.1, M179, P12, P37.1, P41.1 (M359.1), 12f2.2) 主要在日本o D2 (L1366, L1378, M226.2) 菲律宾、麦克坦岛Haplogroup E (M96)详细树形图:见E倍群文件夹∙Haplogroup E (M40, M96) 分布在非洲、中东和欧洲o Haplogroup E1 (P147)▪Haplogroup E1a (M33, M132) 旧称E1▪Haplogroup E1b (P177)▪Haplogroup E1b1 (P2, DYS391p); 旧称E3▪Haplogroup E1b1a (V38) 非洲尼日尔-刚果语人群; 旧称E3a▪Haplogroup E1b1b (M215) 非洲之角,北非、中东和欧洲地中海地区; 旧称E3bo Haplogroup E2 (M75)Haplogroup F (M89)单倍群F和后代迁徙图单倍群F和后代构成了目前世界人口的90%,几乎都分布在撒哈拉以南非洲地区之外。

从单倍型结构检测人类基因组近期的正选择检测人群中最近发生的自然选择对于研究人类历史和医学具有深远的意义。
这里我们介绍一个通过分析人群中长范围的单倍型来检测最近正选择的基因印记的框架。
首先我们在感兴趣的基因座识别单倍型(核心单倍型)。
然后我们通过其与该基因座不同距离的等位基因联系的衰减评估每个核心单倍型的年龄,即通过扩展单倍型纯合性(EHH)进行测定。
具有异常高的EHH和高人群频率的核心单倍型表明,在自然中性进化下,一种突变在人类基因库中上升的速度快于预期。
我们应用这种方法研究了两个携带涉及抗疟疾能力的寻常变异型的基因上的选择,G6PD和CD40配体。
在这两个基因座上,携带假设的保护性突变的核心单倍型凸现出来并显示出重要的选择证据。
一般来说,该方法可以用于扫描整个基因组,以寻找近期正选择的证据。
人类近代史的特点是巨大的环境变化和涌现的选择性媒介。
大约10,000年前新石器时代开始时,人类培育植物和驯化动物导致人群密度的增长。
人类面临着新的传染病、新的食物来源和新的文化环境的传播。
因此,过去的10,000年成为了人类生物学史上最有意义的一段时间,也可能是许多重要的基因适应和疾病抵抗力出现的时间。
我们试图设计一种强大的方法来检测最近的选择。
我们的方法主要基于等位基因的频率与其附近连锁不平衡(LD)程度之间的关系。
(LD通常指两个等位基因间的联系。
这里我们用它来测量一个基因座的单个等位基因与不同距离处的多个基因座等位基因之间的联系。
)在中性进化下,新的变异型需要一段很长的时间才能达到人群中较高的频率,而且在此期间,变异型附近的LD会由于重组大幅度地衰减。
结果,常见等位基因通常是老的并只有短范围的LD。
很少的等位基因可能是年轻的也可能是老的,因此可能具有长或者短范围的LD。
但是正选择的关键特征是它能引起等位基因频率在足够短的时间内异常快速的增长,以至于重组并未能充分打破这些选择突变发生处的单倍型。
因此一个正自然选择的标志就是一个等位基因在其人类频率下具有异常长范围的LD。