netfilter 架构分析
- 格式:doc
- 大小:191.00 KB
- 文档页数:10


本文由我司收集整编,推荐下载,如有疑问,请与我司联系Linux netfilter 学习笔记之三ip层netfilter的table、rule、match、
target结构分析
2014/06/22 4306
上一节分析了ip层hook回调函数的注册以及调用流程,本节我们就开始分析每一个模块的具体实现。
工欲善其事必先利其器,一个功能模块的代码实现与其数据结构的设计有很大的关系,因此我们本节主要是分析table、rule、match、target相关的数据结构,争取本节能把数据结构的定义以及数据结构之间的关系分析明了。
1. table、rule、match、target等相关数据结构分析在分析table、rule、match、target之前,先把它们之间的联系图贴出来,看了这个图以后,我们基本上就知道xt_table里rule、match、target之间的关联了。
总体框架图
对于一个xt_table表,通过其private指针,指向了xt_table_info结构,而xt_table_info中的entries指针数组的每一个指针成员指向xt_table表在相应cpu中的rule的首地址。
一个表中的所有rule在一个连续的内存块中,让所有rule在一个连续的内存块中,使对rule规则的遍历寻址成为了可能,因为一个规则相对于下一个规则并没有使用链表的形式连接在一起。
而一个完整的rule规则,包括了ipt_entry、ipt_entry_match、ipt_standard_target 组成(其实ipt_entry就代表了一个规则,通过ipt_entry- elems即可找到该规则对应的match)。
下面我们一一分析上图提到的数据结构。
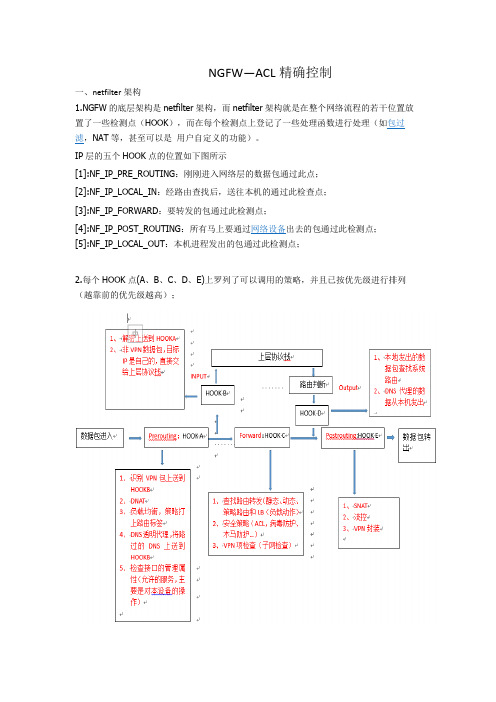
NGFW—ACL精确控制一、netfilter架构1.NGFW的底层架构是netfilter架构,而netfilter架构就是在整个网络流程的若干位置放置了一些检测点(HOOK),而在每个检测点上登记了一些处理函数进行处理(如包过滤,NAT 等,甚至可以是用户自定义的功能)。
IP层的五个HOOK点的位置如下图所示[1]:NF_IP_PRE_ROUTING:刚刚进入网络层的数据包通过此点;[2]:NF_IP_LOCAL_IN:经路由查找后,送往本机的通过此检查点;[3]:NF_IP_FORWARD:要转发的包通过此检测点;[4]:NF_IP_POST_ROUTING:所有马上要通过网络设备出去的包通过此检测点;[5]:NF_IP_LOCAL_OUT:本机进程发出的包通过此检测点;2.每个HOOK点(A、B、C、D、E)上罗列了可以调用的策略,并且已按优先级进行排列(越靠前的优先级越高);需求:防火墙犹如放置在边界的一堵墙,作用是保护内网,隔离外网。
防火墙中内置了很多的关卡,比如:NAT、路由、ACL、流控等策略,数据包进入防火墙后就会经过这些关卡,只要任何一道关卡出现问题,数据包就无法再继续转发;为了发挥防火墙的最大功效,对每道关卡都要精确配置;要实现安全策略(ACL)的细化控制,就必须要知道需要ACL控制的流量在经过ACL控制点的时候源地址,目的地址,甚至端口分别是什么,而影响数据流量的主要要素是NAT策略、VPN策略,下面分析VPN策略和NAT策略对数据的影响以及ACL的配置。
一、IPSEC数据NGFW处理(IPSEC处理)1.分支VPN数据包处理:数据包进入—HOOKA—HOOKC(路由查找、ACL过滤)---HOOKE(VPN封装)注意点:(1)放通的流量也是私网到私网(2)做分支IPSEC策略时,进行NAT排除,放通流量是私网到私网2.总部vpn数据包处理:数据包进入—HOOKA(判断)—HOOKB(解密)---HOOKA---HOOKC(路由、ACL)---HOOKE注意点: (1)放通的流量应该是私网到私网的流量(2)做IPSEC策略时,进行NAT排除,放通流量是私网到私网二、SSL(客户端)数据NGFW处理(SSL处理)总部SSL数据包处理:数据包进入—HOOKA(判断)—HOOKB(解密)---HOOKA---HOOKC(路由、ACL)---HOOKE(SNAT)注意点:(1)在做总部ACL时放通的流量应该是下发地址到服务器资源的流量(2)下发地址如果是内网不存在的地址,就要进行地址伪装,地址伪装实质就是进行了SNAT,将下发的地址转换成内网接口的地址三、非VPN数据,NGFW执行转发动作(内网数据访问互联网)1.数据包由总部内网发出(SNAT):数据包进入—HOOKA—HOOKC(路由查找、ACL过滤)---HOOKE(SNAT)注意点:放通流量是私网到公网的流量,回来的流量不需要放通,因为防火墙有记录会话的功能2.数据包主动从外网发起(DNAT)收到数据包时:数据包回来流量/外网主动发起:—HOOKA(DNAT)—HOOKC(路由查找、ACL 过滤)---HOOKE注意点:放通流量是放通外网对内网的流量,内网放回的流量不需要放通,因为防火墙有记录会话的功能四、内部用户用公网IP访问内部服务器(双向NAT)数据包进入到设备:—HOOKA(DNAT)—HOOKC(路由查找、ACL过滤)---HOOKE (SNAT)注意点:放通流量是放通私网对私网的流量五、非VPN数据,就是交给NGFW设备数据包进入—HOOKA—HOOKB注意点:并没有经过NGFW的ACL过滤,所以无需放通流量六、非VPN数据,从本设备发出数据包发出—HOOKD—HOOKE注意点:并没有经过NGFW的ACL过滤,所以无需放通流量。

Linux下基于netfilter的防火墙性能的分析和研究的开题报告一、研究背景和意义网络安全一直是当前信息化社会的重要话题,保障网络安全显得越来越重要。
防火墙技术是网络安全的重要组成部分。
在计算机网络中,防火墙(Firewall)是一种网络安全设施,它对进出网络的数据进行过滤,阻止攻击者对系统进行攻击,同时防止内部用户对系统进行有害的操作。
防火墙技术通过监控和过滤网络数据流来保护网络安全,通过限制数据流的进出方式,其可以控制流入和流出网络的数据流来达到安全过滤的目的。
当前,Linux下很多的防火墙都是基于Netfilter的实现, Netfilter 是 Linux 内核提供的一种网络数据包过滤框架,它可以用来实现包过滤、地址转换、访问控制等功能,并且提供了一个灵活的用户态接口,可以让应用程序方便地对处理数据包进行扩展。
由于其具有灵活性和可扩展性,越来越多的防火墙和路由器厂商采用 Netfilter 框架来实现各种网络安全和路由实现。
本文旨在分析和研究 Linux 下基于Netfilter的防火墙的性能表现,以期为防火墙技术的发展和优化提供参考。
二、研究内容本研究的主要内容如下:1. Netfilter 框架简介:介绍Netfilter框架的工作原理及其在Linux操作系统中的实现方式。
2. Linux 下基于Netfilter的防火墙架构和实现:阐述Linux下基于Netfilter的防火墙的设计和实现策略,详细讨论其实现机制和原理。
3. 性能评估和测试:使用开源性能测试工具进行测试,考察Linux下基于Netfilter的防火墙对网络性能的影响,同时也对其CPU、内存和I/O等方面做进一步的性能测试。
4. 性能优化:根据测试结果,提出一些性能优化方案,以提高Linux下基于Netfilter的防火墙在实际应用中的性能表现。
5. 结论和展望:总结研究结果,给出研究结论,并对未来的研究方向作出展望。

一、Netfilter/IPTables框架简介Netfilter/IPTables是继2.0.x的IPfwadm、2.2.x的IPchains之后,新一代的Linux防火墙。
Netfilter采用模块化设计,具有良好的可扩展性,其重要工具模块IPTables连接到Netfilter 的架构中,并允许使用者对数据报进行过滤、地址转换等处理操作。
Netfilter提供了一个框架,将对网络的直接干涉降到最低,并允许规定接口将其它包处理代码以模块的形式添加到内核中,具有极强的灵活性。
二、Netfilter总体架构Netfilter主要通过表、链实现规则,可以这么说,Netfilter是表的容器,表是链的容器,链是规则的容器,最终形成对数据报处理规则的实现。
Netfilter的通用框架不依赖于具体的协议,而是为每种网络协议定义一套HOOK函数,这些HOOK函数在数据报经过协议栈的几个关键点时被调用,这样这些模块就有机会检查、修改、丢弃该数据报及指示Netfilter将该数据报传入用户空间的队列。
Netfilter定义了五大HOOK,分别是:NF_IP_PRE_ROUTING、NF_IP_LOCAL_IN、NF_IP_FORWARD、NF_IP_LOCAL_OUT、NF_IP_POST_ROUTING.,每个HOOK对应一个操作链,分别是:PREROUTING 、INPUT 、FORWARD 、OUTPUT 、POSTROUTING。
数据报在进入系统,进行IP校验以后,首先经过第一个HOOK函数NF_IP_PRE_ROUTING时行处理;然后就进入路由代码,其决定该数据报需要转发还是发给本机;若数据报是发给本机,则该数据经过HOOK函数NF_IP_LOCAL_IN处理以后传递给上层协议; 若该数据报应该被转发则它被NF_IP_FORWARD处理;经过转发的数据报经过最后一个HOOK函数NF_IP_POST_ROUTING.处理以后,再传输到网络上。

netfilter 机制netfilter 是Linux 操作系统中用于实现网络数据包过滤和修改的核心机制。
本文将介绍netfilter 机制的基本原理和功能,以及它在网络安全和网络管理中的应用。
netfilter 是Linux 内核中的一个网络数据包处理框架,它允许用户空间程序通过注册钩子函数来拦截、过滤和修改网络数据包。
netfilter 的核心组件是iptables,它是一个用户空间的命令行工具,用于配置netfilter 规则。
iptables 可以根据网络数据包的源IP地址、目标IP地址、协议类型、端口等信息来过滤和处理数据包。
netfilter 的工作原理是将网络数据包交给注册的钩子函数进行处理。
钩子函数根据预先设定的规则来判断数据包的命运,可以选择将数据包丢弃、修改数据包的目标地址或端口,或者将数据包传递给下一个钩子函数。
钩子函数的执行顺序由netfilter 链决定,每个链都包含多个钩子函数,钩子函数按照预定的顺序执行。
netfilter 提供了多个预定义的链,包括INPUT、FORWARD 和OUTPUT 等链。
INPUT 链用于处理目标地址是本机的数据包,FORWARD 链用于处理转发的数据包,OUTPUT 链用于处理源地址是本机的数据包。
用户可以在这些链上注册自定义的钩子函数,实现特定的数据包处理逻辑。
netfilter 还支持使用扩展模块来增加更多的功能。
扩展模块可以提供额外的匹配条件和动作,使用户能够更灵活地配置netfilter 规则。
常用的扩展模块包括 conntrack、nat 和 mangle 等。
netfilter 在网络安全中扮演着重要的角色。
通过配置适当的规则,可以实现防火墙功能,对不符合规则的数据包进行过滤,从而保护网络安全。
例如,可以配置规则来禁止特定的IP地址访问某个端口,或者限制某个服务的连接数。
netfilter 还可以用于网络管理。
通过配置规则,可以实现网络地址转换(NAT)功能,将内部网络的私有IP地址映射为公共IP地址,从而实现内网和外网的通信。
netfilter架构分析Netfilter 架构分析--基于Linux 3.2.0一、全局图在文件net/netfilter/core.c中定义了一全局变量nf_hooks,用于记录钩子点。
nf_hooks第一维代表协议数,第二维代表钩子数。
struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS]__read_mostly;二、钩子函数(hook)与过滤规则表(xt_table)前面已经提到,钩子函数与过滤规则的管理是通过全局变量nf_hooks来实现的,那么,什么时候会调用钩子函数呢?钩子函数又是如何利用已经注册好的过滤规则的呢?在Linux内核中定义了网络数据包的流动方向,数据包被网卡捕获后,它在内核网络子系统里的传输路径是:pre-routing→route(in or forward)→(out)→post-routing。
在netfilter上注册的钩子函数如下所示(这些钩子函数按它们被调用的顺序排列):--->PRE------>[ROUTE]--->FWD---------->POST------>Conntrack | Mangle ^ MangleMangle | Filter | NAT (Src)NAT (Dst) | | Conntrack(QDisc) | [ROUTE]v |IN Filter OUT Conntrack| Conntrack ^ Mangle| Mangle | NAT (Dst)v | Filter共有五个位置设置了钩子点,PRE、IN、FWD、OUT、POST。
钩子函数被注册到相应位置之后,它们就会那里等待数据包的到来,在接收数据包的地方,钩子函数被调用,数据包先由钩子函数捕获,进行处理,然后再转发或者丢弃。
钩子函数的声明:include/linux/netfilter.htypedef unsigned int nf_hookfn(unsigned int hooknum,struct sk_buff *skb,const struct net_device *in,const struct net_device *out,int (*okfn)(struct sk_buff *));从上面已经知道了过滤规则的使用是由钩子函数来实现的,那么,什么时候、在什三、规则的管理一条规则由三个结构体管理:i pt_entry、ipt_entry_match(其中的xt_match)、ipt_entry_target(其中的xt_target)。
Netfilter框架目录1网络通信1.1网络通信的基本模型1.2协议栈底层机制2 Netfilter2.1Netfilter介绍2.2钩子函数返回值2.3 hook点2.4 协议栈切入Netfilter框架3 Netfilter的实现方式3.1 nf_hooks[][]结构3.2 nf_hook_ops3.3 增加新的钩子函数3.4 基于源接口的数据包过滤钩子函数4 iptables防火墙内核模块4.1 iptables4.2 Netfilter框架防火墙iptables hook函数分类4.3 iptables基础4.4 iptables命令格式5连接跟踪机制5.1.重要数据结构5.2重要函数5.3链接跟踪建立的三条路径5.4 IP层接收和发送数据包进入连接跟踪钩子函数的入口5.5连接跟踪的流程分析1网络通信1.1网络通信的基本模型在数据的发送过程中,从上至下依次是“加头”的过程,每到达一层数据就被会加上该层的头部;与此同时,接受数据方就是个“剥头”的过程,从网卡收上包来之后,在往协议栈的上层传递过程中依次剥去每层的头部,最终到达用户那儿的就是裸数据了。
1.2协议栈底层机制“栈”模式底层机制基本就是像下面这个样子:对于收到的每个数据包,都从“A”点进来,经过路由判决,如果是发送给本机的就经过“B”点,然后往协议栈的上层继续传递;否则,如果该数据包的目的地是不本机,那么就经过“C”点,然后顺着“E”点将该包转发出去。
对于发送的每个数据包,首先也有一个路由判决,以确定该包是从哪个接口出去,然后经过“D”点,最后也是顺着“E”点将该包发送出去。
协议栈五个关键点A,B,C,D和E就是我们Netfilter大展拳脚的地方了。
2 Netfilter2.1 Netfilter介绍Netfilter是Linux 2.4.x引入的一个子系统,它作为一个通用的、抽象的框架,提供一整套的hook函数的管理机制,使得诸如数据包过滤、网络地址转换(NAT)和基于协议类型的连接跟踪成为了可能。
Netfilter 架构分析--基于Linux 3.2.0
一、全局图
在文件net/netfilter/core.c中定义了一全局变量nf_hooks,用于记录钩子点。
nf_hooks第一维代表协议数,第二维代表钩子数。
struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS] __read_mostly;
二、钩子函数(hook)与过滤规则表(xt_table)
前面已经提到,钩子函数与过滤规则的管理是通过全局变量nf_hooks来实现的,那么,什么时候会调用钩子函数呢?钩子函数又是如何利用已经注册好的过滤规则的呢?
在Linux内核中定义了网络数据包的流动方向,数据包被网卡捕获后,它在内核网络子系统里的传输路径是:pre-routing→route(in or forward)→(out)→post-routing。
在netfilter上注册的钩子函数如下所示(这些钩子函数按它们被调用的顺序排列):
--->PRE------>[ROUTE]--->FWD---------->POST------>
Conntrack | Mangle ^ Mangle
Mangle | Filter | NAT (Src)
NAT (Dst) | | Conntrack
(QDisc) | [ROUTE]
v |
IN Filter OUT Conntrack
| Conntrack ^ Mangle
| Mangle | NAT (Dst)
v | Filter
共有五个位置设置了钩子点,PRE、IN、FWD、OUT、POST。
钩子函数被注册到相应位置之后,它们就会那里等待数据包的到来,在接收数据包的地方,钩子函数被调用,数据包先由钩子函数捕获,进行处理,然后再转发或者丢弃。
钩子函数的声明:include/linux/netfilter.h
typedef unsigned int nf_hookfn(unsigned int hooknum,
struct sk_buff *skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *));
从上面已经知道了过滤规则的使用是由钩子函数来实现的,那么,什么时候、在什
三、规则的管理
一条规则由三个结构体管理:
i pt_entry、ipt_entry_match(其中的xt_match)、ipt_entry_target(其中的xt_target)。
在文件net/netfilter/x_tables.c中定义了一个全局变量xt:
struct xt_af {
struct mutex mutex;
struct list_head match;
struct list_head target;。
};
static struct xt_af *xt;
其中的match管理xt_match,target管理xt_target,在2.6.25以后的Linux版本里少了对xt_table的管理,那么,xt_table哪里去了呢?根据xt_table的注册函数xt_register_table()发现,xt_table已交由struct net管理了。
在文件include/net/net_namespace.h中定义了net结构体:
struct net {。
#ifdef CONFIG_NETFILTER
struct netns_xt xt;。
#endif。
};
在文件include/net/netns/x_tables.h中定义了netns_xt结构体:
struct netns_xt {
struct list_head tables[NFPROTO_NUMPROTO];。
};
就是通过上面这个tables变量来管理xt_table的。
下图展现了这种规则管理的层次关系:
匹配xt_match与动作xt_target的管理:
定义一维全局变量static struct xt_af *xt;
规则表xt_table的管理:
四、ip table内建的filter表
定义在文件net/ipv4/netfilter/iptable_filter.c中
xt_table表:
static const struct xt_table packet_filter = {
.name = "filter",//规则表默认的名字
.valid_hooks = FILTER_VALID_HOOKS,//定义了三个钩子点IN/FORWARD/OUT .me = THIS_MODULE,
.af = NFPROTO_IPV4,//协议
.priority = NF_IP_PRI_FILTER,//优先级
};
per network 操作:
static struct pernet_operations iptable_filter_net_ops = {
.init = iptable_filter_net_init,
.exit = iptable_filter_net_exit,
};
初始化filter表:
static int __init iptable_filter_init(void)
{。
/* 注册pernet_operations */
ret = register_pernet_subsys(&iptable_filter_net_ops);
if (ret < 0)
return ret;
/* 注册hooks */
filter_ops = xt_hook_link(&packet_filter, iptable_filter_hook);。
}
五、内核空间与用户空间的通信
ip table是一个基于netfilter框架的网络数据包过滤工具,用户态下发的过滤规则通过套接字操作结构体struct nf_sockopt_ops里的相关系统调用使该规则能被内核识别,并更新过滤规则表。
六、参考文献
1、Linux netfilter Hacking HOWTO
2、Netfilter 框架图形化概要分析
by shenguanghui,shenghxscc@2006-02-24
3、iptables内核框架和应用层iptables命令图形化概要分析
by shenguanghui shenghxscc@2006-02-24
4、sk_buff_head 图形化简介
by shenguanghui(shenghxscc@)
5、网络代码分析第二部分――网络子系统在IP层的收发过程剖析
R.wen (rwen2012@)
6、洞悉linux下的Netfilter&iptables
/uid-23069658-id-3160506.html
7、Netfilter实现机制分析
2008-12 唐文tangwen1123@。