基于信息熵的改进TFIDF特征选择算法
- 格式:pdf
- 大小:200.60 KB
- 文档页数:4

使用粗糙集理论进行特征选择的步骤和技巧在数据挖掘和机器学习领域,特征选择是一个重要的任务,它可以帮助我们从原始数据中挑选出最相关的特征,减少冗余和噪音信息,提高模型的性能和可解释性。
粗糙集理论是一种有效的特征选择方法,它基于信息熵和近似集的概念,能够在不依赖于数据分布和假设的情况下进行特征选择。
本文将介绍使用粗糙集理论进行特征选择的步骤和技巧。
1. 数据预处理在进行特征选择之前,我们需要对原始数据进行预处理。
这包括数据清洗、缺失值处理和数据标准化等步骤。
数据清洗可以帮助我们去除异常值和噪音,提高数据的质量。
缺失值处理可以通过填充或删除缺失值的方式来处理缺失数据。
数据标准化可以将不同尺度和单位的特征转化为统一的尺度,避免不同特征之间的差异对特征选择结果造成影响。
2. 构建决策表决策表是粗糙集理论中的核心概念,它由样本的特征和类别标签组成。
在构建决策表时,我们需要选择合适的特征作为决策属性和条件属性。
决策属性是我们希望预测或分类的目标属性,而条件属性是用于描述样本的特征。
选择合适的决策属性和条件属性可以提高特征选择的效果。
3. 计算属性重要性属性重要性是衡量特征对决策属性的贡献程度的指标。
在粗糙集理论中,我们可以使用信息熵和近似集来计算属性重要性。
信息熵可以衡量决策属性的不确定性,而近似集可以表示条件属性对决策属性的近似描述能力。
通过计算属性重要性,我们可以排除对决策属性影响较小的特征,提高特征选择的效率。
4. 特征约简特征约简是粗糙集理论中的一个关键步骤,它通过删除冗余和无关的特征,保留最重要的特征子集。
特征约简可以减少特征空间的维度,提高模型的训练和预测效率。
在特征约简过程中,我们可以使用启发式算法、遗传算法或模型评估方法来选择最佳的特征子集。
5. 模型训练和评估在完成特征选择后,我们可以使用选定的特征子集来训练和评估模型。
选择合适的模型和评估指标可以帮助我们判断特征选择的效果和模型的性能。
常用的模型包括决策树、支持向量机和神经网络等。






无监督特征选择算法的分析与总结特征选择是机器学习中一个重要的问题。
传统的特征选择方法往往需要预先设定一个分类器,并在此基础上进行特征选择。
无监督特征选择算法则不需要预先设定一个分类器,而是直接利用数据本身的结构进行特征选择。
本文将对几种常见的无监督特征选择算法进行分析与总结。
1. 互信息互信息是一种常用的无监督特征选择算法。
它利用信息论的概念,衡量两个随机变量之间的相关性。
对于一个特征Xi和一个类别变量Y,它们之间的互信息可以定义为:I(Xi;Y) = H(Xi) - H(Xi|Y)其中H是熵。
I(Xi;Y)越大,则代表着特征Xi和类别变量Y的相关性越强,特征Xi越有可能成为一个好的特征。
2. 基尼指数基尼指数是一个衡量数据的不纯度的指标,用于衡量一个特征对于分类的重要性。
它的计算方式如下:Gini_index = Σj p(j) (1-p(j))其中p(j)是样本中类别j的比例。
如果一个特征的基尼指数越小,则代表着它越有可能成为一个好的特征。
3. 主成分分析主成分分析是一种常见的无监督降维方法,但也可以用来进行特征选择。
它的基本思想是将原数据投影到一个低维空间中,使得投影后的数据能够最大程度地保留原始数据的信息。
主成分分析通常会根据投影后数据的可解释性(即每个主成分所占的方差)对特征进行排序,因此它也可以用作特征选择算法。
4. 随机森林随机森林是一种集成学习算法,它的基本思想是训练一组随机森林分类器,并将它们的结果合并起来得到最终的分类结果。
在每个随机森林中,它会随机选择一部分特征进行训练。
在这个过程中,随机森林算法会根据各个特征的重要性(即在随机森林中被选择的次数)对特征进行排序,因此它也可以用作特征选择算法。

简单说明决策树原理决策树是一种基于树形结构的分类和回归模型,它通过对训练数据进行学习来建立一个树形模型,用于预测新的数据。
决策树模型具有易于理解、易于实现、可处理离散和连续数据等优点,因此在机器学习领域得到了广泛应用。
一、决策树的基本概念1. 节点:决策树中的每个圆圈都称为一个节点,分为两种类型:内部节点和叶节点。
2. 内部节点:表示对特征进行测试的节点。
每个内部节点包含一个属性测试,将输入实例分配到其子节点中。
3. 叶节点:表示分类结果或输出结果。
在叶子结点处不再进行属性测试,每个叶子结点对应着一种类别或值。
4. 分支:表示从一个内部节点指向其子节点的箭头,代表了样本在该特征上取某个值时所走的路径。
5. 根节点:表示整棵决策树的起始点,在分类问题中代表所有样本都未被分类时所走的路径。
6. 深度:从根结点到当前结点所经过分支数目。
叶子结点深度为0。
7. 路径:从根结点到叶子结点所经过的所有分支构成的序列。
8. 剪枝:对决策树进行简化的过程,目的是减少模型复杂度,提高泛化能力。
二、决策树的生成1. ID3算法ID3算法是一种基于信息熵来进行特征选择的决策树生成算法。
它通过计算每个特征对训练数据集的信息增益来选择最优特征作为当前节点的属性测试。
具体步骤如下:(1)计算数据集D的信息熵H(D)。
(2)对于每个特征A,计算其对数据集D的信息增益Gain(A),并选择信息增益最大的特征作为当前节点的属性测试。
其中,信息增益定义为:Gain(A)=H(D)-H(D|A),其中H(D|A)表示在已知特征A时,数据集D中所包含的各个类别所占比例对应的熵值。
(3)将数据集按照选定属性划分为多个子集,并递归地生成子树。
(4)直到所有样本都属于同一类别或者没有更多可用特征时停止递归。
2. C4.5算法C4.5算法是ID3算法的改进版,它在选择最优特征时使用了信息增益比来解决ID3算法中存在的偏向于选择取值较多的特征的问题。
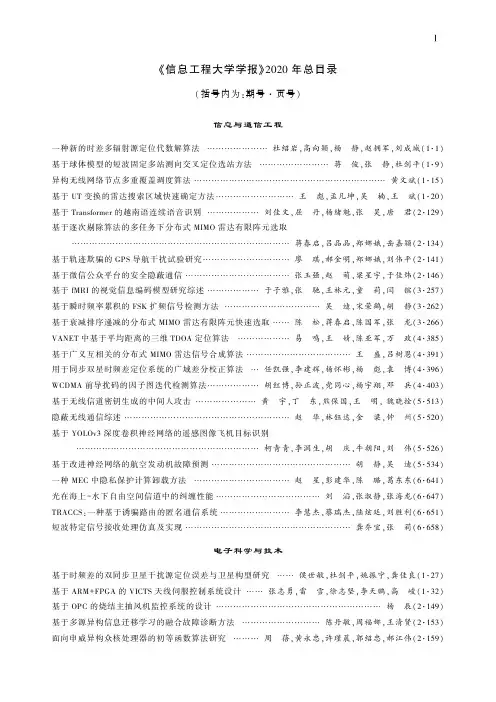
Ⅰ‘信息工程大学学报“2020年总目录(括号内为:期号㊃页号)信息与通信工程一种新的时差多辐射源定位代数解算法杜绍岩,高向颖,杨㊀静,赵拥军,刘成城(1㊃1)基于球体模型的短波固定多站测向交叉定位选站方法蒋㊀俊,张㊀静,杜剑平(1㊃9)异构无线网络节点多重覆盖调度算法黄文斌(1㊃15)基于UT变换的雷达搜索区域快速确定方法王㊀彪,孟凡坤,吴㊀楠,王㊀斌(1㊃20)基于Transformer的越南语连续语音识别刘佳文,屈㊀丹,杨绪魁,张㊀昊,唐㊀君(2㊃129)基于逐次剔除算法的多任务下分布式MIMO雷达有限阵元选取蒋春启,吕品品,郑娜娥,岳嘉颖(2㊃134)基于轨迹欺骗的GPS导航干扰试验研究廖㊀琪,郝金明,郑娜娥,刘伟平(2㊃141)基于微信公众平台的安全隐蔽通信张玉强,赵㊀萌,梁星宇,于佳炜(2㊃146)基于fMRI的视觉信息编码模型研究综述于子雅,张㊀驰,王林元,童㊀莉,闫㊀镔(3㊃257)基于瞬时频率累积的FSK扩频信号检测方法吴㊀迪,宋荣鹤,胡㊀静(3㊃262)基于衰减排序递减的分布式MIMO雷达有限阵元快速选取陈㊀松,蒋春启,陈国军,张㊀龙(3㊃266)VANET中基于平均距离的三维TDOA定位算法易㊀鸣,王㊀婧,陈亚军,万㊀政(4㊃385)基于广义互相关的分布式MIMO雷达信号合成算法王㊀盛,吕树恩(4㊃391)用于同步双星时频差定位系统的广域差分校正算法任凯强,李建辉,杨怀彬,杨㊀彪,袁㊀博(4㊃396) WCDMA前导扰码的因子图迭代检测算法胡红博,孙正波,党同心,杨宇翔,邓㊀兵(4㊃403)基于无线信道密钥生成的中间人攻击黄㊀宇,丁㊀东,熊保国,王㊀明,魏晓拴(5㊃513)隐蔽无线通信综述赵㊀华,林钰达,金㊀梁,钟㊀州(5㊃520)基于YOLOv3深度卷积神经网络的遥感图像飞机目标识别柯青青,李润生,胡㊀庆,牛朝阳,刘㊀伟(5㊃526)基于改进神经网络的航空发动机故障预测胡㊀静,吴㊀迪(5㊃534)一种MEC中隐私保护计算卸载方法赵㊀星,彭建华,陈㊀璐,葛东东(6㊃641)光在海上-水下自由空间信道中的纠缠性能刘㊀滔,张淑静,张海龙(6㊃647) TRACCS:一种基于诱骗路由的匿名通信系统李慧杰,蔡瑞杰,陆炫廷,刘胜利(6㊃651)短波特定信号接收处理仿真及实现龚乔宜,张㊀莉(6㊃658)电子科学与技术基于时频差的双同步卫星干扰源定位误差与卫星构型研究侯世敏,杜剑平,姚振宁,龚佳良(1㊃27)基于ARM+FPGA的VICTS天线伺服控制系统设计张志勇,雷㊀雪,徐志坚,李天鹏,高㊀峻(1㊃32)基于OPC的烧结主抽风机监控系统的设计杨㊀辰(2㊃149)基于多源异构信息迁移学习的融合故障诊断方法陈丹敏,周福娜,王清贤(2㊃153)面向申威异构众核处理器的初等函数算法研究周㊀蓓,黄永忠,许瑾晨,郭绍忠,郝江伟(2㊃159)Ⅱ人工智能加速体系结构综述陈正博,陈左宁(2㊃164)传播模型分析及应用研究进展段金发,邹乾友,付松涛(2㊃172)基于改进蚁群算法的短波测向限定站数灵活组网方案蒋㊀俊,张㊀静,冉晓旻(3㊃273)基于凸优化方法的室内NLOS误差抑制算法张㊀龙,任修坤,王㊀盛,张㊀伟(3㊃279)基于射频指纹的辐射源个体识别技术综述郑娜娥,王㊀盛,张靖志,左㊀宗(3㊃285)基于频偏分布的无线局域网Sybil攻击检测方法田英华,郑娜娥,张靖志,刘㊀扬(3㊃290)PCB平面电感的损耗分析郭盼盼,李建兵,吴㊀昊,林鹏飞(4㊃410)基于反向射线跟踪的单站无源定位算法吕品品,滕汉勇,董㊀鹏,孔范增(4㊃415)基于IEEE1588的时钟同步技术在分布式测量系统中的应用薛子刚,陈红涛,张文渊(4㊃422)基于同步水印嵌入区域的抗仿射变换鲁棒水印算法冯㊀柳(4㊃427)基于改进自注意力机制的说话人分割聚类袁哲菲,张连海,杨绪魁,刘㊀爽(5㊃539)基于时频图像处理的宽带特定信号检测方法孙㊀伟,彭㊀华,李天昀,许漫坤,陈㊀洋(5㊃545)一种利用信号周期性减少信息损失的数据压缩方法姚登辉,孙正波,张晓勇(5㊃552)基于DB-Net的CT图像自动化肝脏分割方法董亚兰(5㊃559)一种基于x-vector说话人特征的语音克隆方法张雅欣,张连海(6㊃664)伪随机三角形构型多面体天线罩反分析方法王晓东,周丰峻,郑㊀磊(6㊃670)基于多示例学习的语音内容分类算法许㊀薇,姚佳奇,燕继坤,欧阳喜(6㊃674)计算机科学与技术基于代码挖掘的返回值敏感型函数识别陈㊀林,刘粉林,陈㊀科,杨春芳,巩道福(1㊃36)基于扩展命题区间时序逻辑的免疫网络攻击检测模型陈茜月,庞建民(1㊃43)一种基于神经机器翻译模型的跨平台的基本块嵌入方法张啸川,孙㊀笛,庞建民,周㊀鑫(1㊃49)基于混合分析的自动化脱壳技术研究徐㊀旭(1㊃55)基于链路监控的SDN恶意流量检测与防御赵新辉,张文镔,王清贤,武泽慧(1㊃61)基于功能性最小存储再生码的数据可恢复验证方案朱㊀彧,陈㊀越,严新成,李㊀帅(1㊃68)一种基于DNA疫苗人工免疫理论的网络攻击检测方法陈茜月,庞建民(2㊃182)面向实时网络应用的虚拟网络功能部署王俊超,庞建民,隋㊀然,单㊀征(2㊃189) MSE_BLS:一种基于宽度学习系统的异常流量检测方法宋彬杰,陈欣鹏,牟轶哲,高立龙(2㊃196)基于Bert模型的框架语义角色标注方法高李政,周㊀刚,黄永忠,罗军勇,王树伟(3㊃297)基于词㊁句㊁实体协同的关键实体抽取算法刘媛媛,史佳欣,李㊀响,李涓子(3㊃304)击键动力学研究综述张㊀畅,韩继红,李福林,韦超鹏(3㊃310)语义感知的JavaScript引擎模糊测试技术研究王允超,王清贤,丁文博(3㊃316)基于相关向量机算法的研究与应用综述李㊀鑫,伊㊀鹏,江逸茗,田㊀乐,张风雨(4㊃433)面向电信网数据的ETL系统的设计与实现安㊀轲,马㊀宏,李英乐,刘树新(4㊃442)基于背景消减法的图像显著性前景目标提取研究杨㊀爽(4㊃448)P4交换机在天地一体化网络中的应用杨爱玲,邹乾友,付松涛(4㊃453)一种基于超像素分割的遥感图像道路提取方法翟银凤,王一帆(4㊃459)Ⅲ时空知识图谱的构建与应用孙一贺,于浏洋,郭志刚,陈㊀刚(4㊃464)不同监控视频条件下行人动作特征三维识别方法王彩玲(5㊃565)面向遥感影像数据的多级数字指纹模型杨㊀辉,冯义凯,车㊀森(5㊃569)基于AHP的车险客户价值评价方法研究杨㊀牧,王㊀月,尹东起,刘淑颖(5㊃574)点差分隐私下基于度序列的图生成模型㊀林子杰,张宇轩,刘文芬,胡学先(6㊃680)基于LSA模型的恶意程序识别分类方法㊀路㊀阳,彭海晖,王震宇(6㊃689)基于属性分类的工程数据线索特征挖掘方法研究㊀周㊀南(6㊃694)网络空间安全实际温度下的大气信道连续变量量子密钥分配张淑静,肖㊀晨,张海龙(1㊃76)一种基于Coded-BKW的LPN问题求解算法焦瑞朴,朱宣勇,谭㊀林(1㊃80)基于物联网的控制系统设计与实现李博文,常朝稳,高㊀宇(1㊃86)基于异构费效比的多样化编译策略可行性评估刘㊀浩,张㊀铮,陈㊀源,刘镇武,唐㊀源(2㊃200)基于信息熵与软件复杂度的软件多样性评估方法刘镇武,隋㊀然,张㊀铮,刘㊀浩(2㊃207)面向拟态云服务的异构执行体输出裁决方法普黎明,柏㊀溢,游㊀伟,李海涛(3㊃344)面向用户流量行为分析的多攻击检测孙剑文,赵㊀幸,刘胜利(3㊃352)一种针对弱监管路由设备的恶意行为检测方法刘秉楠,蔡瑞杰,尹小康,刘胜利(3㊃361)面向拟态架构的差分超时参数预测算法宋㊀克,欧阳玲,魏㊀帅,鲁晓彬(4㊃470)基于eID的电子签名系统设计与应用蔡国明,汪㊀淼,李瑞锋,王晋东,徐开勇(4㊃476)基于MILP对SPECK32循环参数安全性探究陈少真,侯泽洲,任炯炯(5㊃579)减轮CHAM算法的不可能差分分析付志新,任炯炯,陈少真(5㊃586)一种软硬件协同的拟态调度裁决器设计方法宋㊀克,欧阳玲,张文建,谭力波(5㊃593)减轮Serpent算法差分-线性分析的新结果㊀陈少真,付志新,任炯炯(6㊃699)基于无监督机器学习的网络流量分类研究综述㊀王方玉,张建辉,卜佑军,陈㊀博,孙㊀嘉(6㊃705)一种基于特征选择的网络流量异常检测方法㊀吴浩明,张㊀斌,周奕涛,廖仁杰(6㊃711)格基约化算法及其在密码分析中的应用综述㊀郑永辉,刘永杰,栾㊀鸾(6㊃719)一种基于代码注入的反漏洞挖掘方法㊀武泽慧,丁文博,袁会杰,魏㊀强,赵㊀艳(6㊃728)软件工程信息科技领域本体研究的计量分析及可视化赵颜利,李连军,丁剑飞(1㊃93)地理空间情报知识图谱构建方法概述陈晓慧,王㊀鑫,葛㊀磊,胡英男,车㊀森(1㊃101)基于改进TFIDF算法的SQL注入攻击检测方法李应博,张㊀斌(1㊃108)海量遥感数据的存储迁移策略研究赵泽亚,杨㊀迪,梁小虎,王㊀荣,金㊀雪(1㊃115)基于Bert模型的框架类型检测方法高李政,周㊀刚,罗军勇,黄永忠(2㊃214)一种新的多任务朴素贝叶斯学习方法孙立健,周㊀鋆,张维明(2㊃221)面向知识图谱构建的知识抽取技术综述于浏洋,郭志刚,陈㊀刚,席耀一(2㊃227)面向测试数据生成的遗传算法初始种群分布问题研究李志博,李清宝,张俭鸽(2㊃236)用户画像构建技术研究巨星海,周㊀刚,王㊀婧,张凤娟(2㊃242)Ⅳ基于深度学习的图像验证码识别研究石邵虎,胡学先,李志博,徐㊀震(3㊃325)基于复合距离Cartogram的网络空间信息地图可视化方法王映雪,李少梅,张鑫禄,张崇涛,王日恒(3㊃334)物联网信息安全及其智能化发展曹蓉蓉,韩全惜(3㊃340)兼顾时空特征的领导人出访事件可视分析刘建湘,刘海砚,刘一萱,李㊀佳,康㊀磊(4㊃482)一种矢量地图数据多级数字指纹算法杨㊀辉,车㊀森,曲来超(4㊃490)基于案例复盘的舆情传播控制模型研究以新浪微博为例陈㊀帅,李㊀威(4㊃495)基于新闻文本的事件可视方法研究刘海砚,李㊀佳,刘建湘,陈晓慧,程维应(5㊃601)基于词向量和概念上下文信息的本体对齐方法康世泽,吉立新,张建朋(5㊃607)基于GIS的重大疫情区域管控辅助决策问题研究谢㊀峻,万㊀萍,丁敬美,王梦苑,程艳霞(5㊃614)基于粒子群算法的去中心化商务数据共享系统设计刘亚男,倪㊀伟(5㊃622)基于开源数据的城市应急医疗能力分析与可视化㊀刘海砚,刘建湘,李道祥,程维应,陈晓慧(6㊃735)中亚语种通用语料库构建研究㊀席耀一,王小明,云建飞,高㊀鑫(6㊃741)基于大数据技术的网络资源管理系统设计㊀宋龙虎(6㊃747)基于仿射变换的量子图像加密算法㊀闫㊀玲(6㊃752)军事信息学基于BDS的 精确型 战略投送技术张倩倩,刘丽巧,高晟丽,马朝忠(1㊃120)新体制下部队基层军事体育教员岗位胜任力研究陈俊延,梁小安,蒋㊀斌(1㊃124)基于组合赋权和多层次模糊评价法的军队工程协同设计效果评估赵素丽,曹巨辉,易良廷,魏振堃(2㊃251)基于ADC方法的多个导弹发射单元作战效能分析梁㊀俊,戚振东,薛伟阳,张㊀勇(3㊃369)兵棋推演系统中的异常数据挖掘方法胡艮胜,张倩倩,马朝忠(3㊃373)基于FA-FAHP的军代表室工作质量评价方法王育辉,单志峰,张洋铭,李建涛,蔡忠义(3㊃378)陆上作战模拟中的公路运输补给建模研究胡艮胜,张㊀枣(4㊃501)排级军官岗位任职标准构建策略研究程㊀浩,付丰科,柴桌慧(4㊃505)多弹型常规导弹协同目标分配问题研究梁㊀俊,戚振东,张㊀勇(4㊃509)基于熵权与灰色关联度的武器装备体系模糊聚类分析魏东涛,刘晓东,单志峰(5㊃626) 5G技术的无人作战应用与风险探析王因传,杨君刚,张㊀娜(5㊃631)基于模糊层次分析法的防空兵部队军事训练软环境评价赵㊀杰,康兰波(5㊃636)基于AI的军校学员认知域特征分析研究㊀边建利,张建岭,牛㊀钊(6㊃762)。

互信息特征选择算法互信息特征选择算法是一种常用的特征选择方法,它可以从大量的特征中筛选出对目标变量有重要影响的特征,从而提高机器学习模型的性能。
本文将介绍互信息特征选择算法的原理、应用场景以及实现方法。
互信息是信息论中的一个概念,它用于衡量两个随机变量之间的相关性。
在特征选择中,我们可以将目标变量视为一个随机变量,将每个特征视为另一个随机变量,然后计算它们之间的互信息。
互信息越大,说明两个随机变量之间的相关性越强,也就意味着该特征对目标变量的影响越大。
具体地,互信息的计算公式如下:I(X;Y) = ∑∑p(x,y)log(p(x,y)/(p(x)p(y)))其中,X和Y分别表示两个随机变量,p(x,y)表示它们同时发生的概率,p(x)和p(y)分别表示它们单独发生的概率。
互信息的值越大,说明X和Y之间的相关性越强。
在特征选择中,我们可以将目标变量作为Y,将每个特征作为X,然后计算它们之间的互信息。
互信息越大的特征,说明它们与目标变量之间的相关性越强,也就越有可能对机器学习模型的性能产生重要影响。
因此,我们可以根据互信息的大小来选择重要的特征。
二、互信息特征选择算法的应用场景互信息特征选择算法适用于以下场景:1.特征数量较多,需要筛选出对目标变量有重要影响的特征。
2.特征之间存在一定的相关性,需要选择与目标变量相关性最强的特征。
3.需要提高机器学习模型的性能,减少过拟合的风险。
三、互信息特征选择算法的实现方法互信息特征选择算法的实现方法比较简单,可以按照以下步骤进行:1.计算每个特征与目标变量之间的互信息。
2.按照互信息的大小对特征进行排序。
3.选择互信息最大的前N个特征作为重要特征。
在实际应用中,我们可以使用Python中的sklearn库来实现互信息特征选择算法。
具体地,可以使用sklearn.feature_selection中的mutual_info_classif函数来计算每个特征与目标变量之间的互信息,然后使用numpy.argsort函数对互信息进行排序,最后选择前N个特征作为重要特征。

一种基于模糊粗糙集的快速特征选择算法张晓;杨燕燕【摘要】模糊粗糙集由于能够处理实数值数据,甚至是混合值数据中的不确定性受到人们的广泛关注,其最重要的应用之一是特征选择,相关的特征选择方法已有不少研究,但其快速的特征选择算法研究很少.实际中的数据一般含有噪声点或信息含量低的样例,如果对数据集先筛选出代表样例,再对筛选的样例集进行数据挖掘便会降低挖掘计算量.本文基于模糊粗糙集,先根据样例的模糊下近似值对样例进行筛选,然后利用筛选样例的模糊粗糙信息熵构造特征选择的评估度量,并给出相应的特征选择算法,从而降低了算法的计算复杂度.数值试验表明该快速算法具有有效性,并且对控制筛选样例个数的参数给出了建议.【期刊名称】《数据采集与处理》【年(卷),期】2019(034)003【总页数】10页(P538-547)【关键词】模糊粗糙集;样例选择;特征选择;信息熵【作者】张晓;杨燕燕【作者单位】西安理工大学应用数学系,西安,710048;清华大学自动化系,北京,100084【正文语种】中文【中图分类】TP18引言经典的粗糙集理论[1]是由波兰数学家Pawlak在1982年提出的,它是一种处理数据中的不确定性的有效工具,然而经典粗糙集只能处理符号值(名义值)的数据。
模糊粗糙集[2]作为经典粗糙集的最重要的推广之一,可以用来处理实数值甚至是混合值的数据。
目前,模糊粗糙集已经成功应用于机器学习和数据挖掘领域[3],其最受人们关注的应用之一就是特征选择(属性约简)。
关于模糊粗糙集特征选择的研究工作已存在不少[4-10],但其快速的特征选择算法的研究还很少,据作者所知,仅文献[11]在特征选择算法迭代步骤提供了加速策略,从而减少了算法的计算时间。
实际中的数据一般包含信息量较低的样例或噪声点,如果对样例进行筛选,利用筛选得到的样例进行挖掘知识将会减少计算的复杂度。
文献[12]提供了3种样例选择的启发式算法,其中之一的算法思想即选择隶属模糊正域的值不小于给定阈值的那些样例。
第45卷 第9期2023年9月系统工程与电子技术SystemsEngineeringandElectronicsVol.45 No.9September2023文章编号:1001 506X(2023)09 2831 12 网址:www.sys ele.com收稿日期:20220506;修回日期:20220809;网络优先出版日期:20221007。
网络优先出版地址:http:∥kns.cnki.net/kcms/detail/11.2422.TN.20221007.1613.006.html基金项目:科技部科技创新2030 重大项目(2020AAA0104802);国家自然科学基金(91948303);国家自然科学青年基金(61802426)资助课题 通讯作者.引用格式:李庚松,刘艺,郑奇斌,等.基于蚁狮算法的元特征选择方法[J].系统工程与电子技术,2023,45(9):2831 2842.犚犲犳犲狉犲狀犮犲犳狅狉犿犪狋:LIGS,LIUY,ZHENGQB,etal.Meta featureselectionmethodbasedonantlionoptimizationalgorithm[J].SystemsEngineeringandElectronics,2023,45(9):2831 2842.基于蚁狮算法的元特征选择方法李庚松1,刘 艺1, ,郑奇斌2,秦 伟1,李红梅2,任小广1,宋明武3(1.国防科技创新研究院,北京100071;2.军事科学院,北京100091;3.天津(滨海)人工智能创新中心,天津300457) 摘 要:为了提升基于元学习算法选择的性能,提出一种基于蚁狮算法的元特征选择方法。
首先,通过鲁棒初始化机制构建初始种群,增强所选元特征子集的鲁棒性。
其次,在个体解的搜索过程中应用动态边界策略,增加方法的种群多样性。
然后,采用混沌映射变异策略,提升方法的寻优性能,给出方法伪代码并分析时间复杂度。
一种改进的文本特征选择方法的研究与设计
许高建;路遥;胡学钢;涂立静
【期刊名称】《苏州大学学报(工科版)》
【年(卷),期】2008(028)002
【摘要】特征选择是文本挖掘技术的一个重要环节.在中文分词的基础上,通过设计一个简单的应用程序,对文本进行预处理.然后,在分析比较几种用于文本分类的特征选择方法的基础上,提出了一种基于信息增益和互信息相结合的特征选择方法.利用它对文本文档进行特征选择,抽取代表其特征的元数据或特征词条构成特征向量,降低噪音.最后通过实验来和其他几种特征选择方法作比较,分析这种方法获取文本特征的精度.
【总页数】5页(P18-22)
【作者】许高建;路遥;胡学钢;涂立静
【作者单位】安徽农业大学信息与计算机学院,安徽,合肥,230036;安徽农业大学信息与计算机学院,安徽,合肥,230036;合肥工业大学计算机与信息学院,安徽,合
肥,230009;安徽农业大学信息与计算机学院,安徽,合肥,230036
【正文语种】中文
【中图分类】TP391
【相关文献】
1.一种基于改进互信息和信息熵的文本特征选择方法 [J], 成卫青;唐旋
2.一种改进的文本特征选择方法的研究与设计 [J], 符会涛;卡米力·木衣丁
3.一种改进的文本特征选择方法的研究与设计 [J], 许高建;胡学钢;路遥;涂立静
4.一种改进的文本特征选择方法 [J], 孙凯;魏海平
5.一种改进的CHI文本特征选择方法 [J], 樊存佳;汪友生;王雨婷
因版权原因,仅展示原文概要,查看原文内容请购买。
无监督特征选择算法的分析与总结【摘要】无监督特征选择算法是一种不需要标记数据的特征选择方法,能够帮助有效提取数据中的重要特征。
本文首先介绍了无监督特征选择算法的基本概念,然后对常见的算法进行了详细分析,包括过滤法、包装法和嵌入法等。
接着对这些算法的优缺点进行了分析,指出了它们在实际应用中的一些局限性。
我们探讨了无监督特征选择算法的应用场景,包括文本分类、图像处理等领域。
我们展望了这一领域的未来发展方向,希望能够通过更加智能化的算法和技术实现更精准的特征选择。
通过本文的研究,读者能够更加深入地了解无监督特征选择算法的原理和应用,为相关领域的研究和实践提供参考。
【关键词】无监督特征选择算法、介绍、常见算法、优缺点、应用场景、未来发展方向、总结1. 引言1.1 引言特征选择是数据挖掘和机器学习中非常重要的一个环节,它可以帮助梭选择最具代表性的特征,减少数据维度,提高模型的泛化能力。
而无监督特征选择算法则是在没有标记数据的情况下进行特征选择,相比有监督特征选择算法更具挑战性。
无监督特征选择算法可以帮助排除无关紧要或冗余的特征,提高模型的效率和性能。
它们主要通过对数据的统计性质和特征之间的关联性进行分析来选择最优的特征子集。
常见的无监督特征选择算法包括基于协方差矩阵的方法、基于信息熵的方法、基于特征选择指标的方法等。
本文将介绍无监督特征选择算法的基本概念和原理,探讨各种常见算法的特点、优缺点以及在不同场景下的应用情况。
我们将对无监督特征选择算法的未来发展方向进行展望,希望可以为相关领域的研究和实践提供一些借鉴和思路。
2. 正文2.1 介绍无监督特征选择算法无监督特征选择算法是一种可以不依赖标签信息的方法,从原始数据中选取具有代表性的特征进行建模和分析的技术。
在实际应用中,由于标签信息的获取成本很高,无监督特征选择算法因其高效和便利的特点而受到越来越多的关注。
无监督特征选择算法主要包括基于过滤法、包装法和嵌入法等方法。