属性数据分析第五章课后答案
- 格式:doc
- 大小:215.50 KB
- 文档页数:7

第一章数据库系统概述选择题1实体-联系模型中,属性是指(C)A.客观存在的事物B.事物的具体描述C.事物的某一特征D.某一具体事件2对于现实世界中事物的特征,在E-R模型中使用(A)A属性描述B关键字描述C二维表格描述D实体描述3假设一个书店用这样一组属性描述图书(书号,书名,作者,出版社,出版日期),可以作为“键”的属性是(A)A书号B书名C作者D出版社4一名作家与他所出版过的书籍之间的联系类型是(B)A一对一B一对多C多对多D都不是5若无法确定哪个属性为某实体的键,则(A)A该实体没有键B必须增加一个属性作为该实体的键C取一个外关键字作为实体的键D该实体的所有属性构成键填空题1对于现实世界中事物的特征在E-R模型中使用属性进行描述2确定属性的两条基本原则是不可分和无关联3在描述实体集的所有属性中,可以唯一的标识每个实体的属性称为键4实体集之间联系的三种类型分别是1:1 、1:n 、和m:n5数据的完整性是指数据的正确性、有效性、相容性、和一致性简答题一、简述数据库的设计步骤答:1需求分析:对需要使用数据库系统来进行管理的现实世界中对象的业务流程、业务规则和所涉及的数据进行调查、分析和研究,充分理解现实世界中的实际问题和需求。
分析的策略:自下而上——静态需求、自上而下——动态需求2数据库概念设计:数据库概念设计是在需求分析的基础上,建立概念数据模型,用概念模型描述实际问题所涉及的数据及数据之间的联系。
3数据库逻辑设计:数据库逻辑设计是根据概念数据模型建立逻辑数据模型,逻辑数据模型是一种面向数据库系统的数据模型。
4数据库实现:依据关系模型,在数据库管理系统环境中建立数据库。
二、数据库的功能答:1提供数据定义语言,允许使用者建立新的数据库并建立数据的逻辑结构2提供数据查询语言3提供数据操纵语言4支持大量数据存储5控制并发访问三、数据库的特点答:1数据结构化。
2数据高度共享、低冗余度、易扩充3数据独立4数据由数据库管理系统统一管理和控制:(1)数据安全性(2)数据完整性(3)并发控制(4)数据库恢复第二章关系模型和关系数据库选择题1把E-R模型转换为关系模型时,A实体(“一”方)和B实体(“多”方)之间一对多联系在关系模型中是通过(A)来实现的A将A关系的关键字放入B关系中B建立新的关键字C建立新的联系D建立新的实体2关系S和关系R集合运算的结果中既包含S中元组也包含R中元组,但不包含重复元组,这种集合运算称为(A)A并运算B交运算C差运算D积运算3设有关系R1和R2,经过关系运算得到结果S,则S是一个(D)A字段B记录C数据库D关系4关系数据操作的基础是关系代数。
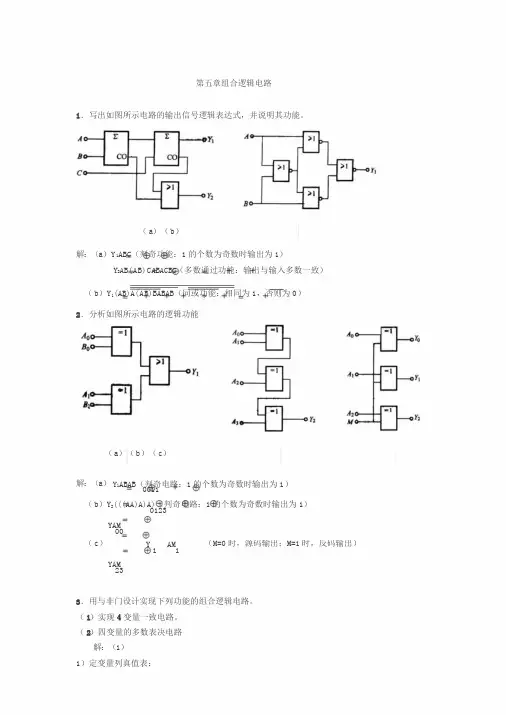
第五章组合逻辑电路1.写出如图所示电路的输出信号逻辑表达式,并说明其功能。
(a)(b)解:(a)Y1ABC(判奇功能:1的个数为奇数时输出为1)Y2AB(AB)CABACBC(多数通过功能:输出与输入多数一致)(b)Y1(AB)A(AB)BABAB(同或功能:相同为1,否则为0)2.分析如图所示电路的逻辑功能(a)(b)(c)解:(a)Y1ABAB(判奇电路:1的个数为奇数时输出为1)0011(b)Y2(((AA)A)A)(判奇电路:1的个数为奇数时输出为1)0123YAM00(c)Y1 A M1(M=0时,源码输出;M=1时,反码输出)YAM233.用与非门设计实现下列功能的组合逻辑电路。
(1)实现4变量一致电路。
(2)四变量的多数表决电路解:(1)1)定变量列真值表:ABCDYABCDY0000110000000101001000100101000011010110010*******010*******011001110001110111112)列函数表达式:YABCDABC D ABCDABCD3)用与非门组电路(2)输入变量A、B、C、D,有3个或3个以上为1时输出为1,输人为其他状态时输出为0。
1)列真值表2)些表达式3)用与非门组电路4.有一水箱由大、小两台水泵ML和Ms供水,如图所示。
水箱中设置了3个水位检测元件A、B、C,如图(a)所示。
水面低于检测元件时,检测元件给出高电平;水面高于检测元件时,检测元件给出低电平。
现要求当水位超过C点时水泵停止工作;水位低于C点而高于B点时Ms单独工作;水位低于B点而高于A点时ML单独工作;水位低于A点时ML和Ms同时工作。
试用门电路设计一个控制两台水泵的逻辑电路,要求电路尽量简单。
解:(1)根据要求列真值表(b)(b)(a)(2)真值表中×对应的输入项为约束项,利用卡诺图化简(c)(d)(c)(d)(e)得:MABCsMBL(ML、M S的1状态表示工作,0状态表示停止)(3)画逻辑图(e)5.某医院有—、二、三、四号病室4间,每室设有呼叫按钮,同时在护士值班室内对应地装有一号、二号、三号、四号4个指示灯。

数据的分析全章教案(原创)第一章:数据与信息1.1 数据的概念引入:通过现实生活中的实例,让学生感受数据的存在。
讲解:数据的定义、数据的来源、数据的形式。
练习:学生举例说明数据的含义。
1.2 数据的特点引入:讨论数据的属性,如大小、数量、分类等。
讲解:数据的属性、数据的特点、数据的类型。
练习:学生分析一组数据的特点。
第二章:数据的收集与整理2.1 数据的收集引入:解释数据收集的重要性,举例说明。
讲解:数据收集的方法、数据收集的工具。
练习:学生设计一个数据收集的计划。
2.2 数据的整理引入:强调数据整理的必要性,展示整理前后的对比。
讲解:数据整理的步骤、数据整理的方法。
练习:学生实践数据整理的过程。
第三章:数据的描述与展示3.1 数据的描述引入:通过实例说明数据描述的作用。
讲解:数据描述的方法、数据描述的指标。
练习:学生运用数据描述的方法。
3.2 数据的展示引入:展示不同形式的data visualization,强调其优势。
讲解:data visualization 的类型、data visualization 的工具。
练习:学生制作一个简单的data visualization。
第四章:数据的处理与分析4.1 数据的处理引入:讨论数据处理的目的,如去除重复、筛选等。
讲解:数据处理的方法、数据处理的工具。
练习:学生应用数据处理的方法。
4.2 数据的分析引入:解释数据分析的目标,如找出趋势、关联等。
讲解:数据分析的方法、数据分析的工具。
练习:学生实践数据分析的过程。
第五章:数据的应用5.1 数据在决策中的应用引入:讨论数据在决策中的重要性,举例说明。
讲解:数据在决策中的应用、数据在决策中的限制。
练习:学生分析一个实际问题,运用数据进行决策。
5.2 数据在其他领域的应用引入:展示数据在其他领域的应用,如医学、金融等。
讲解:数据在其他领域的应用、数据在其他领域的潜力。
练习:学生探索数据在其他领域的潜在应用。

第一章引论1. 计算机网络的发展可划分为几个阶段?每个阶段各有何特点?答:计算机网络的发展主要分为一下四个阶段:1)以单计算机为中心的联机系统-缺点,主机负荷重,通信线路利用率低,结构属集中控制方式,可靠性低2)计算机-计算机网络-是网络概念最全,设备最多的一种形式3)体系结构标准化网络4)Internet时代-是人类有工业社会向信息社会发展的重要标志,简单实用,高效传输,有满足不同服务的网络传输要求3. 计算机网络由哪些部分组成,什么是通信子网和资源子网?试述这种层次结构观的特点以及各层的作用是什么?答:通信控制处理机构成的通信子网是网络的内层,或骨架层,是网络的重要组成部分。
网上主机负责数据处理,是计算机网络资源的拥有者,它们组成了网络的资源子网,是网络的外层,通信子网为资源子网提供信息传输服务,资源子网上用户间的通信是建立在通信子网的基础上。
没有通信子网,网络不能工作,而没有资源子网,通信子网的传输也失去了意义,两者合起来组成了统一的资源共享的两层网络。
将通信子络的规模进一步扩大,使之变成社会公有的数据通信网,5. 一个完整的计算机网络的定义应包含哪些内容?答:1.物理结构:通过通信线路、通信设备将地理上分散的计算机连成一个整体2.逻辑结构:在网络协议控制下进行信息传输3.主要目的:资源共享9. 局域网、城域网与广域网的主要特征是什么?答:这三种网络主要是按照网络覆盖的地理范围来划分的:1)广域网(远程网)WAN (Wide Area Network):广域网的作用范围一般为几十到几千公里。
2)局域网LAN(Local Area Network):局域网的作用范围通常为几米到几十公里。
3)城域网MAN(Metropolitan Area Network):城域网的作用范围在WAN与LAN之间,其运行方式为LAN相似。
13. 计算机网络与分布式计算机系统之间的区别与联系是什么?答:两者在物理结构上是非常类似的,但是软件上有很大的差异。

第五章思考与练习答案一、单项选择题1. A(算术平均数)、H(调和平均数)和G(几何平均数)的关系是:( D )A、A≤G≤H;B、G≤H≤A;C、H≤A≤G;D、H≤G≤A2.位置平均数包括( D )A、算术平均数;B、调和平均数;C、几何平均数;D、中位数、众数3.若标志总量是由各单位标志值直接总和得来的,则计算平均指标的形式是( A )A、算术平均数;B、调和平均数;C、几何平均数;D、中位数4.平均数的含义是指( A )A、总体各单位不同标志值的一般水平;B、总体各单位某一标志值的一般水平;C、总体某一单位不同标志值的一般水平;D、总体某一单位某一标志值的一般水平5.计算和应用平均数的基本原则是( C )A、可比性;B、目的性;C、同质性;D、统一性6.由组距数列计算算术平均数时,用组中值代表组内变量值的一般水平,假定条件是( C )。
A.各组的次数相等 B.组中值取整数C.各组内变量值不同的总体单位在组内是均匀分布的D.同一组内不同的总体单位的变量值相等7.已知3个水果店香蕉的单价和销售额,则计算3个水果店香蕉的平均价格应采用( C )A.简单算术平均数 B.加权算术平均数 C.加权调和平均数 D.几何平均数8.如果统计资料经过分组,并形成了组距分配数列,则全距的计算方法是( D )A.全距=最大组中值—最小组中值B.全距=最大变量值—最小变量值C.全距=最大标志值—最小标志值D.全距=最大组上限—最小组下限9.已知两个总体平均数不等,但标准差相等,则( A )。
A.平均数大的,代表性大 B.平均数小的,代表性大C.平均数大的,代表性小 D.以上都不对10.某企业2006年职工平均工资为5000元,标准差为100元,2007年平均工资增长了20%,标准差增大到150元。
职工平均工资的相对变异( A )。
A、增大B、减小C、不变D、不能比较二、多项选择题1.不受极值影响的平均指标有( BC )A、算术平均数;B、众数;C、中位数;D、调和平均数;E、几何平均数2.标志变动度( BCDE )A、是反映总体各单位标志值差别大小程度的指标;B、是评价平均数代表性高低的依据;C、是反映社会生产的均衡性或协调性的指标;D、是反映社会经济活动过程的均衡性或协调性的指标;E、可以用来反映产品质量的稳定程度。

r语言与统计分析第五章课后答案第五章5.1设总体某是用无线电测距仪测量距离的误差,它服从(α,β)上的均匀分布,在200次测量中,误差为某i的次数有ni次:某i:3579111315171921Ni:21161526221421221825求α,β的矩法估计值α=u-β=u+程序代码:某=eq(3,21,by=2)y=c(21,16,15,26,22,14,21,22,18,25)u=rep(某,y)u1=mean(u)=var(u)1=qrt()a=u1-qrt(3)某1b=u1+qrt(3)某1b=u1+qrt(3)某1得出结果:a=2.217379b=22.402625.2为检验某自来水消毒设备的效果,现从消毒后的水中随机抽取50L,化验每升水中大肠杆菌的个数(假设1L水中大肠杆菌的个数服从泊松分布),其化验结果如下表所示:试问平均每升水中大肠杆菌个数为多少时,才能使上述情况的概率达到最大大肠杆菌数/L:0123456水的升数:1720222100γ=u是最大似然估计程序代码:a=eq(0,6,by=1)b=c(17,20,10,2,1,0,0)c=a某bd=mean(c)得出结果:d=7.1428575.3已知某种木材的横纹抗压力服从正态分布,现对十个试件做横纹抗压力试验,得数据如下:482493457471510446435418394469(1)求u的置信水平为0.95的置信区间程序代码:某=c(482493457471510446435418394469)t.tet(某)得出结果:data:某t=6.2668,df=9,p-value=0.0001467alternativehypothei:truemeaninotequalto095percentconfidenceinterval:7.66829916.331701ampleetimate:meanof某12由答案可得:u的置信水平为0.95的置信区间[7.66829916.331701](2)求σ的置信水平为0.90的置信区间程序代码:chiq.var.tet<-function(某,var,alpha,alternative="two.ided"){ option(digit=4)reult<-lit()n<-length(某)v<-var(某)reult$var<-vchi2<-(n-1)某v/varreult$chi2<-chi2p<-pchiq(chi2,n-1)reult$p.value<-pif(alternative=="le")reult$p.value<-pchaiq(chi2,n-1,loer.tail=F)eleif(alternative=="two.ider")reult$p.value<-2某min(pchaiq(chi2,n-1),pchaiq(chi2,n-1,lower.tail=F))reult$conf.int<-c((n-1)某v/qchiq(alpha/2,df=n-1,lower.tail=F),(n-1)某v/qchiq(alpha/2,df=n-1,lower.tail=T))reult}某<-c(482,493,457,471,510,446,435,418,394,469)y=var(某)chiq.var.tet(某,0.048^2,0.10,alternative="two.ide")得出结果:$conf.int:659.83357.0由答案可得:σ的置信水平为0.90的置信区间[659.83357.0]5.4某卷烟厂生产两种卷烟A和B现分别对两种香烟的尼古丁含量进行6次试验,结果如下:A:252823262922B:282330352127若香烟的尼古丁含量服从正态分布(1)问两种卷烟中尼古丁含量的方差是否相等(通过区间估计考察)(2)试求两种香烟的尼古丁平均含量差的95%置信区间程序代码:某=c(25,28,23,26,29,22)Y=c(28,23,30,35,21,27)Var.tet(某,y)data:某andyF=0.2992,numdf=5,denomdf=5,p-value=0.2115alternativehypothei:trueratioofvarianceinotequalto195percentconfidenceinterval:0.041872.13821ampleetimate:ratioofvariance0.2992由答案可得:其方差不相等,方差区间为[0.041872.13821](2)5.5比较两个小麦品种的产量,选择24块条件相似地实验条,采用相同的耕作方法做实验,结果播种甲品种的12块实验田的单位面积产量和播种乙品种的12块试验田的单位面积产量分别为:A:628583510554612523530615573603334564B:535433398470567480498560503426338547假定每个品种的单位面积产量服从正态分布,甲品种产量的方差为2140,乙品种产量的方差为3250,试求这两个品种平均面积产量差的置信水平为0.95的置信上限和置信水平为0.90的置信下限。

第五章统计学课后答案第十章一、选择题1.某企业计划要求本月每万元产值能源消耗率指标比去年同期下降5%,实际降低了2.5%,则该项计划的计划完成百分比为( D )。
A. 50.0% B 97.4% C. 97.6% D. 102.6%2.下列指标中属于强度相对指标的是( A )。
A.产值利润率B.基尼系数C.恩格尔系数D.人均消费支出3. 下列指标中属于狭义指数的是( A )。
A.某地区本月社会商品零售量为上月的110%B.某地区本月能源消耗总量为上月的110%C.某地区本月居民收入总额为上月的110%D.某地区本月居民生活用水价格为上月的110%4.若为了纯粹反映价格变化而不受销售量结构变动的影响,计算价格总指数时应该选择的计算公式是( A )。
A.拉氏指数B.帕氏指数C.马埃指数D.理想指数5. 与帕氏质量指标综合指数之间存在变形关系的调和平均指数的权数应是( B )。
A. q0p0B. q1p1C. q1p0D. q0p16. 为了说明两个地区居民消费水平之间的差异程度,有关指数的计算最好采用( C )。
A.拉氏指数B.帕氏指数C.马埃指数D.理想指数7. 同样数量的货币,今年购买的商品数量比去年减少了4%,那么可推断物价指数为( D )。
A. 4.0%B. 104%C. 4.2%D. 104.2%8.某公司报告期新职工人数比重大幅度上升,为了准确反映全公司职工劳动效率的真实变化,需要编制有关劳动生产率变化的(B )。
A.总平均数指数B.组平均数指数C.结构影响指数D.数量指标综合指数9.某地区报告年按可比价格计算的工业总产值为基年工业总产值的110%,这个指数是一个( C)。
A. 总产值指数B.价格指数C. 工业生产指数D.静态指数10.我国深证100指数将基期价格水平定为1000。
若某周末收盘指数显示为1122,此前一周末收盘指数显示为1100,即表示此周末收盘时股价整体水平比一周前上涨了( A )。


第五章 异方差性一、判断题1. 在异方差的情况下,通常预测失效。
( T )2. 当模型存在异方差时,普通最小二乘法是有偏的。
( F )3. 存在异方差时,可以用广义差分法进行补救。
(F )4. 存在异方差时,普通最小二乘法会低估参数估计量的方差。
(F )5. 如果回归模型遗漏一个重要变量,则OLS 残差必定表现出明显的趋势。
( T ) 二、单项选择题1.Goldfeld-Quandt 方法用于检验( A )A.异方差性B.自相关性C.随机解释变量D.多重共线性 2.在异方差性情况下,常用的估计方法是( D )A.一阶差分法B.广义差分法C.工具变量法D.加权最小二乘法 3.White 检验方法主要用于检验( A )A.异方差性B.自相关性C.随机解释变量D.多重共线性 4.下列哪种方法不是检验异方差的方法( D )A.戈德菲尔特——匡特检验B.怀特检验C.戈里瑟检验D.方差膨胀因子检验 5.加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即( B )A.重视大误差的作用,轻视小误差的作用B.重视小误差的作用,轻视大误差的作用C.重视小误差和大误差的作用D.轻视小误差和大误差的作用 6.如果戈里瑟检验表明,普通最小二乘估计结果的残差与有显著的形式的相关关系(满足线性模型的全部经典假设),则用加权最小二乘法估计模型参数时,权数应为( B ) A. B.C. D.7.设回归模型为,其中()2i2i x u Var σ=,则b 的最有效估计量为( D )A. B.C. D. ∑=ii x y n 1b ˆ8.容易产生异方差的数据是( C )A. 时间序列数据B.平均数据C.横截面数据D.年度数据9.假设回归模型为i i i u X Y ++=βα,其中()2i 2i X u Var σ=,则使用加权最小二乘法估计模i e i x i i i v x e +=28715.0i v i x 21i x i x 1ix 1i i i u bx y +=∑∑=2ˆxxy b 22)(ˆ∑∑∑∑∑--=x x n y x xy n b xyb=ˆ型时,应将模型变换为( C )。

第一章习题答案1.1 选择题1. A2. C3. C4. B5. C6. A7. C8. B9. D 10. A 11. D 12. A 13. A 1.2 填空题数据数据的逻辑独立性数据的物理独立性层次数据模型,网状数据模型,关系数据模型能按照人们的要求真实地表示和模拟现实世界、容易被人们理解、容易在计算机上实现实体、记录属性、字段码域一对一、一对多、多对多E-R模型E-R模型层次模型、网状模型、关系模型数据操作、完整性约束矩形、菱形、椭圆形层次模型、一对多网状模型关系模型关系外模式、模式、内模式三级模式、两级映像外模式、模式、内模式数据、程序数据逻辑、数据物理DBMS(数据库管理系统)、DBA(数据库管理员)1.4 综合题2.(注:各实体的属性省略了)3.第二章习题答案1.1 单项选择题1. C2. A3. B4. C5. C6. D7. A8. B1.2 填空题集合2. 能唯一标识一个实体的属性系编号,学号,系编号关系,元组,属性关系模型,关系,实体,实体间的联系投影1.4 综合题1. πsno(σcno=’2’(SC))2. πsno(σcname=’信息系统’(SCCOURSE))3. πsno,SNAME,SAGE(STUDENT)第三章习题答案1.1select * from jobs1.2select emp_id,fname+'-'+lname as 'Name' from employee1.3select emp_id,fname+'-'+lname as 'Name',Year(getdate())-Year(hire_date) as 'worke time' from employee order by 'worke time'2.1select * from employee where fname like 'f%'2.2select * from employee where job_id='11'2.3select emp_id,fname+'-'+lname as 'Name', Year(getdate())-Year(hire_date) as worketimefrom employeewhere (Year(getdate())-Year(hire_date)) >5order by worketime2.4select * from employee where cast(job_id as integer)>=5 and cast(job_id as integer)<=82.5select * from employee where fname='Maria'2.6select * from employee where fname like '%sh%' or lname like '%sh%'3.1select * from sales where ord_date <'1993-1-1'4.1select distinct bh, zyh from stu_info wherebh in(select bh from stu_infogroup by (bh)having count(*)>30 and count(*)<40)order by bh或者是select bh,zyh from stu_infogroup by zyh,bhhaving count(bh)>30 and count(bh)<40order by bh4.2select * from gbanwhere bh like '计%'4.3select * from gfiedwhere zym like '%管理%'4.4select xh,xm,zym,stu_info.bh,rxsj from stu_info,gfied,gban where nl>23and stu_info.zyh=gfied.zyh and stu_info.bh=gban.bh4.5select zyh,count(*) from gbanwhere xsh='03'group by zyh第四章习题答案4.1 单项选择题:B2、A3、C4、A5、A6、C7、C8、D9、B10、A11、C(或B,即书上121页例题中from的写法)12、A13、C14、C15、C4.2 填空题:drop tablealter table add <列名或约束条件>with check option基本表基本表distinct group by roder by数据定义数据操纵数据控制distinctlike % _自含式嵌入式10、order by asc desc4.3 综合题1、SELECT XH, XM, ZYM, BH, RXSJFROM STU_INFO, GFIEDWHERE STU_INFO.ZYH = GFIED.ZYH AND NL > 23 AND XBM = '男'2、SELECT ZYM 专业名, count(*) 人数FROM STU_INFO, GFIEDWHERE STU_INFO.XSH = '03' AND STU_INFO.ZYH = GFIED.ZYHGROUP BY ZYM注意:该题目中给出的条件XSH = '03'中的03代表的是“控制科学与工程”学院,信息学院的代码是12,大家可根据具体情况来做该题。

数据结构总复习第一部分课后习题第一章课后习题P16 1、2、5、6、9第三章课后习题P66 2、3第四章课后习题P88 1第五章课后习题P102 1、2第六章课后习题P134-135 1、3、16、18完成P137 实验二构造哈夫曼编码第七章课后习题P177 1、2、4、8、10第二部分综合习题一、单项选择题1.如果在数据结构中每个数据元素只可能有一个直接前驱,但可以有多个直接后继,则该结构是(C )A. 栈B. 队列C. 树D. 图2.下面程序段的时间复杂度为(B )for (i=0; i<m; i++)for (j=0; j<n; j++)A[i][j]=i*j;A. O (m2)B. O (n2)C. O (m*n)D. O (m+n)3.在头指针为head的非空单循环链表中,指针p指向尾结点,下列关系成立的是( A )A. p->next==headB. p->next->next==headC. p->next==NULLD. p==head4.若以S和X分别表示进栈和退栈操作,则对初始状态为空的栈可以进行的栈操作系列是( D )A. SXSSXXXXB. SXXSXSSXC. SXSXXSSXD. SSSXXSXX5.两个字符串相等的条件是(D )A. 串的长度相等B. 含有相同的字符集C. 都是非空串D. 串的长度相等且对应的字符相同6.已知一棵含50个结点的二叉树中只有一个叶子结点,则该树中度为1的结点个数为( D )A. 0B. 1C. 48D. 497.算法分析的目的是:(C )(A)找出数据结构的合理性(B)研究算法中输入和输出的关系(C)分析算法的效率以求改进(D)分析算法的易懂性和文档性8.用链表表示线性表的优点是:( C )(A)便于随机存取(B)花费的存储空间比顺序表少(C)便于插入和删除(D)数据元素的物理顺序与逻辑顺序相同9.在数组表示的循环队列中,front、rear分别为队列的头、尾指针,maxsize为数组的最大长度,队满的条件是:( D )(A)front=rear (B)rear=maxsize(C)rear=front (D)(rear+1)%maxsize=front10.若已知一棵二叉树先序序列为ABCDEFG,中序序列为CBDAEGF,则其后序序列为:( A )(A)CDBGFEA (B)CDBFGEA(C)CDBAGFE (D)BCDAGFE11.执行下列程序段,执行S的次数(S这段程序的时间复杂度)是:(D )for(int i=1;i<=n;i++)for(int j=1;j<=i;j++)S;(A)n2 (B)n2/2 (C)n(n+1) (D)n(n+1)/212.以下数据结构中哪一个是非线性结构的是:( D )(A)队列(B)栈(C)线性表(D)图13.设有6个结点的无向图,该图至少有多少条边才能确保是一个连通图:(A )(A)5 (B)6 (C)7 (D)814.树形结构数据元素之间的关系是:( C )(A)一对一关系(B)多对多关系(C)一对多关系(D)多对一关系15.一个栈的入栈序列是a,b,c,d,e,则栈的不可能的输出序列是:( C )(A)edcba (B)decba (C)dceab (D)abcde16.静态查找和动态查找的根本区别在于:(B )(A)它们的逻辑结构不一样(B)施加在其上的操作不同(C)所包含的数据元素的类型不一样(D)存储的实现不一样17.关键路径是AOE网中:(A )(A)从源点到终点的最长路径(B)从源点到终点的最短路径(C)最长的回路(D)最短的回路18.采用折半查找方法进行查找,数据文件为,且限于;(A )(A)有序表顺序存储结构(B)有序表链式存储结构(C)随机表顺序存储结构(D)随机表链式存储结构19.一个高度为h的完全二叉树共有n个结点,其中m个叶子结点,则下列式子成立的是( D )(A)n=h+m (B)h+m=2n (C)m=h-1 (D)n=2m-120.下列说法中不正确的是:(C )(A)数组时一种线性结构(B)数组是一种定长的线性结构(C)除了插入和删除操作外,数组的基本操作还有存取、修改、检索和排序等(D)数组的基本操作有存取、修改、检索和排序等,没有插入与删除操作21.设无向图G有n个顶点e条边,则该无向图中所有顶点的度之和为:( D )(A)n (B)e (C)2n (D)2e22.对下面的无向图进行广度优先搜索后所得到的顶点访问序列,正确的是:(A )(A)ABDEFC (B)ABFEDC (C)ADCBEF (D)ADCBFE23.若某线性表中最常用的操作是取第i 个元素和找第i个元素的前趋元素,则采用( D )存储方式最节省时间。
第一章1.什么是数据?什么是数据管理?答:数据是用于承载信息的物理符号,是信息的具体表现形式。
数据管理是利用计算机硬件和软件技术对数据进行有效的收集、存储、处理和应用的过程。
4.什么是数据库管理系统?它的主要功能是什么?答:数据库管理系统是用于建立、管理和维护数据库的大型系统软件。
主要功能是1)数据定义功能2)数据操纵功能3)数据库运行管理功能4)数据库的建立和维护功能5)数据库的传输功能。
5.数据库系统包括哪几个主要组成部分?各部分的功能是什么?画出整个数据库系统的层次结构图。
答:数据库系统包括数据库、数据库管理系统、6.试述数据库系统的三级模式结构及每级模式结构的作用。
答:数据库的三级模式是指逻辑模式、外模式(子模式)、内模式(物理模式)。
逻辑模式是对数据库中数据的整体逻辑结构和特征的描述。
外模式是对各个用户或程序所涉及到的数据的逻辑结构和数据特征的描述。
内模式是数据的内部表示或底层描述。
作用:逻辑模式是系统为了减小数据冗余、实现数据共享的目标,并对所有用户的数据进行综合抽象而得到的统一的全局数据视图。
通过外模式,可以方便用户使用和增强数据的安全性。
通过设计内模式,可以将系统的模式(全局逻辑模式)组织成最优的物理模式,以提高数据的存取效率。
改善系统的性能指标。
7.DBA指的是什么?它的主要职责是什么?答:DBA: 是“数据库管理员”的简称,是数据库系统中的高级用户,全面负责数据库系统的管理、维护、正常使用等工作。
主要职责:1)参与数据库设计的全过程,决定数据库的结构和内容。
2)决定数据库的存储结构和存取策略,已获得较高的存取效率和存储空间利用率。
3)帮助终端用户使用数据库系统。
4)控制和监控用户对数据库的存取访问,维护数据库的安全性。
5)监督控制数据库的使用和运行,负责定义和实施适当的数据库备份和恢复策略。
6)改进和重组重构数据库,负责监视和分析系统的性能。
9.解释实体、属性、实体键、实体集、实体型、实体联系类型、记录、数据项、字段、记录型、文件、实体模型、数据模型的含义。
《统计分析与S P S S的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
属性数据分析第五章课后答案属性数据分析第五章课后作业6.为了解男性和女性对两种类型的饮料的偏好有没有差异,分别在年青人和老年人中作调查。
调查数据如下:偏好饮料A偏好饮料B年青人 男性 37 26 女性 11 23 老年人男性 30 43 女性3111试分析这批数据,关于男性和女性对这两种类型的饮料的偏好有没有差异的问题,你有什么看法?为什么? 解:(1)数据压缩分析首先将上表中不同年龄段的数据合并在一起压缩成二维2×2列联表1.1,合起来看,分析男性和女性对这两种类型的饮料的偏好有没有差异?表1.1 “性别×偏好饮料”列联表偏好饮料A 偏好饮料B 合计 偏好A 比例 偏好B 比例男性 67 69 136 49.26% 50.74% 女性42 34 7655.26% 44.74%二维2×2列联表独立检验的似然比检验统计量Λ-ln 2的值为0.7032,p 值为05.04017.0)7032.0)1((2>=≥=χP p ,不应拒绝原假设,即认为“偏好类型”与“性别”无关。
(2)数据分层分析其次,按年龄段分层,得到如下三维2×2×2列联表1.2,分开来看,男性和女性对这两种类型的饮料的偏好有没有差异?表1.2 三维2×2×2列联表偏好饮料A 偏好饮料B 合计偏好A 比例偏好B 比例年青人男性37 26 63 58.73% 41.27% 女性11 23 3432.35%67.65%老年人男性 30 43 73 41.10% 58.90% 女性 31 11 42 73.81% 26.19%在上述数据中,分别对两个年龄段(即年青人和老年人)进行饮料偏好的调查,在“年青人”年龄段,男性中偏好饮料A 占58.73%,偏好饮料B 占41.27%;女性中偏好饮料A 占58.73%,偏好饮料B 占41.27%,我们可以得出在这个年龄段,男性和女性对这两种类型的饮料的偏好有一定的差异。
同理,在“老年人”年龄段,也有一定的差异。
(3)条件独立性检验为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令C 表示年龄段,1C 表示年青人,2C 表示老年人;D 表示性别,1D 表示男性,2D 表示女性;E 表示偏好饮料的类型,1E 表示偏好饮料A ,2E 表示偏好饮料B 。
欲检验的原假设为:C 给定后D 和E 条件独立。
按年龄段分层后得到的两个四格表,以及它们的似然比检验统计量Λ-ln 2的值如下:1C 层 2C 层822.11ln 2=Λ-248.6ln 2=Λ-条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,其值为07.18822.11248.6ln 2=+=Λ-由于2===t c r ,所以条件独立性检验的似然比检验统计量的渐近2χ分布的自由度为2)1)(1(=--t c r ,也就是上面这2个四格表的渐近2χ分布的自由度的和。
由于p 值50.00011916)07.18)2((2=≥χP 很小,所以认为条件独立性不成立,即在年龄段给定的条件下,男性和女性对两种类型的饮料的偏好是有差异的。
1E 2E合计1D37 26 632D11 23 34 合计48 49 971E 2E合计1D30 43 732D31 11 42合计61 54 115(4)产生偏差的原因a、在(1)中,将不同年龄段的数据压缩在一起合起来后分析发现男性和女性在对两种类型的饮料的偏好上是没有差异的。
但将数据以不同的年龄段分层后并分别分析发现男性和女性在对两种类型的饮料的偏好上是有一定差异的。
合起来看和分开来看的结果不同。
b、由此看来,年龄段在此次调查中属于混杂因素。
由于不同年龄段的人对饮料的选择也会有差异,例如现在的年青人偏好喝一些像可口可乐,美年达等这样的碳酸饮料,而老年人则偏好喝一些红茶,绿茶等这样的非碳酸饮料,在调查中,“老年人”年龄段共有115人,所占比例大,从而使整个结果就倾向于老年人的观点,即使得混杂因素“年龄段”起到一定的干扰作用,从而导致整个调查结果产生了偏差。
8.某工厂有三个车间。
车间主任分别为王、张和李。
过去的一年里,该工厂产品的质量情况总结如下:车间主任产品类别产品质量情况产品总数合格产品数不合格产品数王内销2368 131 2499 外销123 81 204张内销293 3 296 外销1247 255 1502李内销307 12 319 外销359 75 434王主任将内销和外销产品合并在一起,然后计算各个车间的不合格率。
计算结果如下:主任产品质量情况不合格率合格产品数不合格产品数王2491 212 7.84%张1540 258 14.35%李666 87 11.55%王主任说,我负责的车间生产情况最好,其次是李主任负责的车间,最差的是张主任负责的车间。
这样的比较是不是有偏比较?为什么?解:不是,有偏比较是指将数据压缩后合起来看与分层后分开来看得出的结果不一致时所产生的偏差,而此题只是将数据压缩起来后相互间比较,因此这样的比较不是有偏比较。
具体分析如下:由题知,分析车间主任与产品的质量情况之间的关系,则本题是以产品类别为层,以车间主任为行,产品的质量情况为列进行相关分析。
(1)数据压缩分析首先将上表中不同产品类别的数据合并在一起压缩成二维3×2列联表2.1,合起来看,分析车间主任与产品的质量情况两者之间的关系?表2.1 “车间主任×产品质量”列联表主任产品质量情况不合格率合格产品数不合格产品数王2491 212 7.84%张1540 258 14.35%李666 87 11.55%可计算出该表独立性检验的似然比检验统计量Λ-ln2的值为48.612,p值为)612.48)2((2≈≥=χPp。
应该拒绝原假设,即认为车间主任与产品的质量情况两者是有一定相关性的。
(2)数据分层分析其次,按产品类别分层,得到如下三维2×3×2列联表2.2,分开来看,分析车间主任与产品的质量情况两者之间的关系?表1.2 三维2×2×2列联表产品类别车间主任产品的质量情况不合格率合格产品数不合格产品数内销王2368 131 5.24% 张293 3 1.01% 李307 12 3.76%外销王 123 81 39.71% 张 1247 255 16.98% 李 359 75 17.28%在上述数据中,分别对两个产品类别(即内销和外销)进行分析,在“内销”类别中,王姓主任车间的产品不合格率最高,即车间生产情况最差,张姓主任车间的不合格率最低,即车间生产情况最好;在“外销”类别中,王姓主任车间的产品不合格率最高,即车间生产情况最差,张姓和李姓主任车间生产情况差不多。
(3)条件独立性检验为验证上述得出的结果是否可靠,我们可以做以下的条件独立性检验。
即由题意,可令A 表示产品类别,1A 表示内销,2A 表示外销;B 表示车间主任,1B 表示王姓主任,2B 表示张姓主任,3B 表示李姓主任;C 表示产品的质量情况,1C 表示合格产品数,2C 表示不合格产品数。
欲检验的原假设为:A 给定后B 和C 条件独立。
按产品类别分层后得到的两张表格,以及它们的似然比检验统计量Λ-ln 2的值如下:1A 层1C 2C合计 1B2368 131 2499 2B 2933296 3B307 12319合计 2968 146 3114 289.15ln 2=Λ- 2A 层1C 2C合计 1B123 81 2042B 12472551502 3B359 75434合计 1729 411 2140684.51ln 2=Λ-条件独立性检验问题的似然比检验统计量是这两个似然比检验统计量的和,其值为973.66684.51289.15ln 2=+=Λ-由于3,2===r t c ,所以条件独立性检验的似然比检验统计量的渐近2χ分布的自由度为3)1)(1(=--t c r ,也就是上面这2个表格的渐近2χ分布的自由度的和。
由于p 值0)973.66)3((2≈≥χP 很小,所以认为条件独立性不成立,即在产品类别给定的条件下,车间主任与产品的质量情况两者是有一定相关性的。
(4)结论在(1)中,将不同产品类别的数据压缩在一起合起来后分析发现车间主任与产品的质量情况两者是有一定相关性的;在(2)中,将数据以不同的产品类别分层后分析发现车间主任与产品的质量情况两者也是有一定相关性的。
即合起来看和分开来看的结果相同。
据我们所知,有偏比较是指将数据压缩后合起来看与分层后分开来看得出的结果不一致时所产生的偏差,而此题合起来看和分开来看的结果都是相同的。
因此此题若是分析车间主任与产品的质量情况两者之间的相关关系的话,则该题是无偏的,即不均有有偏性,无法进行有偏比较。