时间序列分析模型实例
- 格式:ppt
- 大小:823.00 KB
- 文档页数:61

Eviews时间序列分析实例时间序列是市场预测中经常涉及的一类数据形式,本书第七章对它进行了比较详细的介绍。
通过第七章的学习,读者了解了什么是时间序列,并接触到有关时间序列分析方法的原理和一些分析实例。
本节的主要内容是说明如何使用Eviews软件进行分析。
一、指数平滑法实例所谓指数平滑实际就是对历史数据的加权平均。
它可以用于任何一种没有明显函数规律,但确实存在某种前后关联的时间序列的短期预测。
由于其他很多分析方法都不具有这种特点,指数平滑法在时间序列预测中仍然占据着相当重要的位置。
(-)一次指数平滑一次指数平滑又称单指数平滑。
它最突出的优点是方法非常简单,甚至只要样本末期的平滑值,就可以得到预测结果。
一次指数平滑的特点是:能够跟踪数据变化。
这一特点所有指数都具有。
预测过程中添加最新的样本数据后,新数据应取代老数据的地位,老数据会逐渐居于次要的地位,直至被淘汰。
这样,预测值总是反映最新的数据结构。
一次指数平滑有局限性。
第一,预测值不能反映趋势变动、季节波动等有规律的变动;第二,这种方法多适用于短期预测,而不适合作中长期的预测;第三,由于预测值是历史数据的均值,因此与实际序列的变化相比有滞后现象。
指数平滑预测是否理想,很大程度上取决于平滑系数。
Eviews提供两种确定指数平滑系数的方法:自动给定和人工确定。
选择自动给定,系统将按照预测误差平方和最小原则自动确定系数。
如果系数接近1,说明该序列近似纯随机序列,这时最新的观测值就是最理想的预测值。
出于预测的考虑,有时系统给定的系数不是很理想,用户需要自己指定平滑系数值。
平滑系数取什么值比较合适呢?一般来说,如果序列变化比较平缓,平滑系数值应该比较小,比如小于0.l;如果序列变化比较剧烈,平滑系数值可以取得大一些,如0.3~0.5。
若平滑系数值大于0.5才能跟上序列的变化,表明序列有很强的趋势,不能采用一次指数平滑进行预测。
〔例1〕某企业食盐销售量预测。
现在拥有最近连续30个月份的历史资料(见表l),试预测下一月份销售量。


多元时间序列模型实例1. 引言1.1 背景介绍多元时间序列模型是现代经济学中重要的分析工具,它能够有效地捕捉多个经济变量之间的互动关系和动态演变规律。
在实际应用中,多元时间序列模型被广泛运用于宏观经济预测、货币政策制定、金融风险管理等领域。
随着经济全球化和金融市场的不断发展,经济变量之间的关联性不断增强,传统的单变量时间序列模型已无法满足复杂的分析需求。
多元时间序列模型的研究和应用变得尤为重要。
本文将重点讨论VAR模型和VECM模型两种典型的多元时间序列模型,分析它们的原理、优缺点以及应用范围。
通过实例分析,我们将探讨这两种模型在实际经济数据中的应用效果和结果。
并对研究过程中的局限性进行分析,为未来研究提出展望。
通过深入探讨和研究多元时间序列模型,我们可以更好地理解经济变量之间的内在联系,为经济政策制定和风险管理提供更为准确和可靠的参考依据。
1.2 研究意义多元时间序列模型在经济学、金融学、环境科学等领域具有重要的应用价值。
通过对多元时间序列数据的建模分析,可以帮助研究者更好地理解变量之间的关系和内在规律,预测未来的发展走势,制定有效的政策和决策,促进经济社会的可持续发展。
多元时间序列模型可以用来分析经济系统中不同变量之间的相互影响和作用机制。
通过构建VAR模型和VECM模型,可以揭示变量之间的联动关系,帮助研究者更好地理解经济系统内部的运行机制,从而为制定政策提供科学依据。
多元时间序列模型还可以用来预测未来的发展趋势。
基于对历史数据的建模分析,可以得出一定的预测结果,为政府、企业和个人提供决策参考,减少不确定性因素的影响,提高决策的准确性和效益。
多元时间序列模型的研究具有重要的实践意义和理论意义,对于推动经济社会的发展和提高决策的科学性都具有重要的意义。
本文将通过实例分析,探讨多元时间序列模型在实际中的应用效果和局限性,为相关研究提供参考和借鉴。
1.3 研究对象研究对象是指在本研究中所关注和研究的主体或对象。


基于VAR模型的我国房地产市场与汇率波动的因果关系————VAR模型实验第一部分实验分析目的及方法现选取人民币对美元汇率以及商品房房价作为变量构建VAR模型。
对于不满足单位根检验的序列采取对数化或差分处理,使其成为平稳序列再进行模型的拟合。
对于商品房房价这一变量,由于全国各省市差异较大,故此处采用全国房地产开发业综合景气指数这一变量。
此外,为了消除春节假期不固定因素带来的影响,增强数据的可比性,按照国家统计制度,从2012年起,不单独对1月份统计数据进行调查,1-2月份数据一起调查,一起发布。
所以国房景气指数p这一序列缺少每年一月份的相关数据,属于非随机、不可忽略缺失,在此采用平均值填充的方法,补足数据。
第二部分实验样本2.1数据来源数据来源于中经网统计数据库。
具体数据见附录表。
2.2所选数据变量由于我国于2005年7月实行第二次汇改,此次汇改以市场供求为基础、参考一篮子货币进行调节、有管理的浮动汇率制度取代了过去人民币汇率长达10年的紧盯美元的固定汇率体制。
故本实验拟选取2005年07月到2014年10月我国以月为单位的数据。
,用以上两个变量来构建VAR模型,并利用该模型进行分析预测。
第四部分模型构建4.1判断序列的平稳性4.1.1汇率E序列首先绘制出E的折线图,结果如下图:图4.1 汇率E的曲线图从图中可以看出,汇率E序列较强的趋势性,由此可以初步判断该序列是非平稳的。
为了减少m的变动趋势以及异方差性,先对m进行对数化处理,记为lm,其时序图如下:图4.2 lm的曲线图对数化后的趋势性减弱,但仍存在一定的趋势性,下面对lm进行一阶差分处理,去除趋势性,得到新变量dlm,观察dlm的曲线图。
图4.3 DLE的曲线图从图中可以看出,dle序列的趋势性基本已经消除,且新变量dle基本围绕0上下波动,因此选择形式为y t=y t-1+u t进行单位根检验:表4.1 单位根输出结果Null Hypothesis: DLE has a unit rootExogenous: ConstantLag Length: 2 (Automatic - based on SIC, maxlag=12)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -3.031673 0.0351Test critical values: 1% level -3.4919285% level -2.88841110% level -2.581176*MacKinnon (1996) one-sided p-values.Augmented Dickey-Fuller Test EquationDependent Variable: D(DLE)Method: Least SquaresDate: 11/15/14 Time: 20:20Sample (adjusted): 2005M11 2014M10Included observations: 108 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.DLE(-1) -0.353005 0.116439 -3.031673 0.0031 D(DLE(-1)) -0.502730 0.115417 -4.355768 0.0000 D(DLE(-2)) -0.311531 0.093265 -3.340258 0.0012C -0.000888 0.000470 -1.887592 0.0619R-squared 0.450240 Mean dependent var 1.15E-05 Adjusted R-squared 0.434382 S.D. dependent var 0.005058S.E. of regression 0.003804 Akaike infocriterion -8.269046 Sum squared resid 0.001505 Schwarz criterion -8.169708Log likelihood 450.5285 Hannan-Quinncriter. -8.228768F-statistic 28.39119 Durbin-Watson stat 2.061613Prob(F-statistic) 0.000000单位根统计量ADF=-3.031673小于临界值,且P为0.0351,因此该序列不是单位根过程,即该序列是平稳序列。


时间序列分析xx年xx月xx日CATALOGUE目录•时间序列分析简介•时间序列数据的预处理•时间序列模型的构建•时间序列模型的评估与优化•时间序列分析的应用场景与实例•时间序列分析的未来发展与挑战01时间序列分析简介时间序列分析是一种统计学方法,用于研究具有时间顺序的数据,以揭示其内在的规律性和预测未来的趋势。
时间序列数据通常表现为历史数据序列,可以用于预测未来,从而帮助决策者做出更好的决策。
定义与概念1时间序列分析的用途与重要性23通过分析时间序列数据,可以预测未来的趋势和变化,从而提前做好准备和规划。
预测未来趋势时间序列分析可以识别出异常情况或突发事件,从而及时采取措施应对。
识别异常情况通过预测未来需求,时间序列分析可以帮助决策者优化资源配置,提高效率和降低成本。
优化资源配置数据收集和处理收集和处理时间序列数据,包括数据清洗、缺失值填充等预处理工作。
通过图表等方式将数据呈现出来,以便更好地观察和分析数据。
根据数据的特点和需求选择合适的模型,并建立模型以拟合数据。
对模型进行评估和优化,以提高模型的预测能力和准确性。
利用训练好的模型对未来进行预测,并给出预测结果和建议。
时间序列分析的基本步骤数据可视化模型评估与优化预测未来趋势模型选择与建立02时间序列数据的预处理03数据格式转换根据分析需求,将数据转换为合适的格式,如将日期转换为时间戳或将多个变量合并为一个数据集。
数据清洗与整理01缺失值处理对于缺失的数据,需要选择合适的处理方法,如插值、删除或忽略。
02异常值处理异常值可能会对分析结果产生不良影响,应进行识别和处理,如平滑处理或直接删除。
季节性调整通过去除时间序列数据中的季节性因素,以揭示趋势和循环成分。
趋势分析对时间序列数据的长期变化进行分析,以识别增长或下降的趋势。
季节性调整与趋势分析数据转换为改善数据的质量和稳定性,可对数据进行转换,如对数转换或平方根转换。
平滑处理为减少数据中的随机波动和噪声,可采用平滑技术,如移动平均法或低通滤波器。
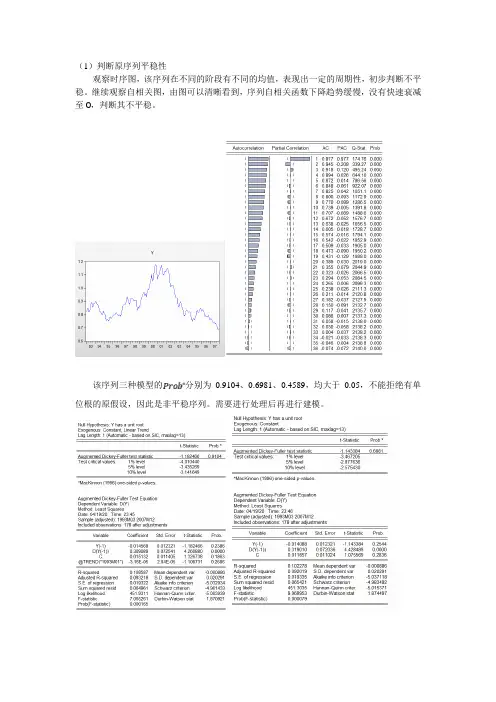
(1)判断原序列平稳性观察时序图,该序列在不同的阶段有不同的均值,表现出一定的周期性,初步判断不平稳。
继续观察自相关图,由图可以清晰看到,序列自相关函数下降趋势缓慢,没有快速衰减至0,判断其不平稳。
该序列三种模型的分别为0.9104、0.6981、0.4589,均大于0.05,不能拒绝有单位根的原假设,因此是非平稳序列。
需要进行处理后再进行建模。
(2)差分序列平稳性检验对原序列进行一次差分,再对其进行平稳性检验。
观察其时序图,该序列的时序图都表现出围绕其水平均值不断波动的过程,没有明显的趋势或周期性,粗略估计是平稳时间序列。
再观察其自相关函数图。
自相关系数快速衰减到0,在虚线范围内波动,没有明显的波动、发散,判断为平稳序列。
模型3与模型2的伴随概率为0,拒绝有单位根的原假设,说明序列是平稳的。
但模型3的时间趋势项的伴随概率为0.1789,常数项的伴随概率0.3504,在显著性水平0.05情况下不显著,故不选用。
而模型2的常数项的伴随概率为0.6608,也不显著,不选用。
因此模型1是最合适的模型,不含有常数项和时间趋势项。
(3)模型的参数估计及模型的诊断检验观察自相关图最后两列可以看到,Q检验的伴随概率均小于0.05,拒绝没有自相关性的原假设,因此该序列不是白噪声序列,没有把信息都提取出来。
接下来将尝试使用AR(1)、AR(2)、AR(3)、MA(1)、ARMA(1,1)、ARMA(2,1)模型进行拟合。
(1)AR(1):该模型各项显著,故对其进行残差项白噪声检验,观察Q检验及其伴随概率,在显著性水平为0.05时,拒绝没有自相关性的原假设,不是白噪声序列,不选用。
(2)AR(2):。
该模型各项显著,故对其进行残差项白噪声检验,观察Q检验及其伴随概率,在显著性水平为0.05时,接受没有自相关性的原假设,是白噪声序列,可以选用。
(3)AR(3):该模型各项不显著,不选用。
(4)MA(1):该模型各项显著,故对其进行残差项白噪声检验,观察Q检验及其伴随概率,在显著性水平为0.05时,接受没有自相关性的原假设,是白噪声序列,可以选用。

⽤R语⾔实现奶⽜⽉产奶量的时间序列分析奶⽜⽉产奶量的时间序列分析本⽂应⽤R软件对奶⽜⽉产奶量建⽴时间序列模型并进⾏预测。
⽂章主要从以下⼏个⽅⾯进⾏:1.描述性统计2.模型识别3.参数估计4.模型诊断5.预测6.其他建模⽅法及效果对⽐7.结论最终通过多⽅⾯对⽐,我们选择了ARIMA(0,1,1)×(0,1,1)12模型⽤于以后数据的预测。
⼀、描述性统计1.1数据的选取本⽂引⽤的是Data Market中的时间序列数据“Monthly milk production: pounds per cow. Jan 62 –Dec 75”,包括从1962年1⽉到1975年12⽉共168个⽉度数据,单位为pounds/month。
数据如下:从中我们将62-74年,共156条数据作为训练集,75年的12个⽉数据作为测试集,⽤于最后评价模型预测效果的参考。
1.2数据的描述性统计变量统计表1-1数据类型最⼩值下四分数中位数均值上四分数最⼤值数值型数据553.0 677.8 761.0 754.7 824.5 969.0时间序列的分布图和时间序列的分解如下:时间序列分解图1-1由图可以看出,时间序列含有明显的季节性和上升趋势,且没有波动集群现象,可以考虑季节模型,最常⽤的是ARIMA模型。
1.3乘法季节模型乘法季节模型是随机季节模型与 ARIMA 模型的结合。
统计学上纯 RIMA (p,d, q )模型记作:ΦΘ。
其中 t 代表时间,Xt 表⽰响应序列,B是后移算⼦, R=1-B,p、 d、 q 分别表⽰⾃回归阶数、差分阶数和移动平均阶数;Φ(B)表⽰⾃回归算⼦;Θ(B)表⽰滑动平均算⼦。
⼀个阶数为(P,d, q )×(P, D, Q ) s 的乘积季节模型可表为:ΦΘ代表独⽴⼲扰项或随机误差项, s 的值是⼀个季节循环中观测的个数,atΦ表⽰同⼀周期内不同周期点的相关关系,则描述了不同周期中对应时点上的相关关系,⼆者结合起来便同时刻画了 2 个因数的作⽤。

时间序列模型案例分析时间序列模型案例分析: 新冠疫情趋势预测背景:新冠疫情自2020年开始全球流行,给世界各国的医疗体系和经济造成了巨大冲击。
为了有效应对疫情,政府和医疗机构需要准确预测疫情未来的趋势,并做出相应的决策和应对措施。
数据:本案例使用了每天的新增确诊病例数作为时间序列数据。
数据包括了从疫情开始到某一时间点的每天新增病例数,以及历史病例数、疫情防控政策等其他相关因素。
目标:利用时间序列模型预测未来疫情的趋势,帮助政府和医疗机构制定合理的防控策略。
方法:我们采用了ARIMA模型(自回归移动平均模型)进行疫情趋势预测。
ARIMA模型是一种广泛应用于时间序列分析的经典模型,可对时间序列数据进行模拟和预测。
步骤:1. 数据预处理: 首先,我们进行了数据清洗和转换,确保数据的准确性和一致性。
我们还对数据进行了平稳性检验,如果数据不平稳,则需要进行差分操作。
2. 模型选择: 然后,我们选择了合适的ARIMA模型。
模型选择的关键是要找到合适的参数p、d和q,它们分别代表了自回归阶数、差分阶数和移动平均阶数。
3. 参数估计和模型拟合: 我们使用最大似然估计方法来估计模型的参数,并对模型进行拟合。
拟合后,我们对模型进行残差分析,以检验模型的拟合效果。
4. 模型评估和预测: 接下来,我们使用已有的数据来评估模型的预测效果。
我们将模型的预测结果与实际数据进行比较,并计算误差指标,如均方根误差(RMSE)和平均绝对误差(MAE)。
最后,我们使用拟合好的模型来进行未来疫情的趋势预测。
结果与讨论:经过模型拟合和评估,我们得到了一个较为准确的ARIMA模型来预测未来疫情的趋势。
根据模型的预测结果,政府和医疗机构可以制定对应的防控策略,以应对疫情的发展。
结论:时间序列模型在新冠疫情趋势预测中发挥了重要作用。
通过对历史疫情数据的分析和建模,我们可以预测未来疫情的走势,并相应地采取措施。
然而,需要注意的是,时间序列模型是一种基于过去数据的预测方法,其预测精度可能受到多种因素的影响。

传统的经济计量方法是以经济理论为基础来描述变量关系的模型。
但是,经济理论通常并不足以对变量之间的动态联系提供一个严密的说明,而且内生变量既可以出现在方程的左端又可以出现在方程的右端使得估计和推断变得更加复杂。
为了解决这些问题而出现了一种用非结构性方法来建立各个变量之间关系的模型。
本章所要介绍的向量自回归模型(vector autoregression ,VAR)和向量误差修正模型(vector error correction model ,VEC)就是非结构化的多方程模型。
向量自回归(VAR)是基于数据的统计性质建立模型,VAR 模型把系统中每一个内生变量作为系统中所有内生变量的滞后值的函数来构造模型,从而将单变量自回归模型推广到由多元时间序列变量组成的“向量”自回归模型。
VAR 模型是处理多个相关经济指标的分析与预测最容易操作的模型之一,并且在一定的条件下,多元MA 和ARMA 模型也可转化成VAR 模型,因此近年来VAR 模型受到越来越多的经济工作者的重视。
VAR(p ) 模型的数学表达式是t=1,2,…..,T其中:yt 是 k 维内生变量列向量,xt 是d 维外生变量列向量,p 是滞后阶数,T 是样本个数。
k ⨯k 维矩阵Φ1,…, Φp 和k ⨯d 维矩阵H 是待估计的系数矩阵。
εt 是 k 维扰动列向量,它们相互之间可以同期相关,但不与自己的滞后值相关且不与等式右边的变量相关,假设 ∑ 是εt 的协方差矩阵,是一个(k ⨯k )的正定矩阵。
11t t p t p t t --=+⋅⋅⋅+++y Φy Φy Hx ε注意,由于任何序列相关都可以通过增加更多的yt 的滞后而被消除,所以扰动项序列不相关的假设并不要求非常严格。
以1952一1991年对数的中国进、出口贸易总额序列为例介绍VAR 模型分析,其中包括;① VAR模型估计;②VAR模型滞后期的选择;③VAR模型平隐性检验;④VAR模型预侧;⑤协整性检验VAR模型佑计数据Lni(进口贸易总额), ,Lne的时间序列见图。
时间序列分析模型时间序列分析模型是一种通过对时间序列数据进行建模和分析的方法,旨在揭示数据中的趋势、季节性、周期和不规则波动等特征,并进行预测和决策。
时间序列分析模型在经济、金融、市场、气象、医学等领域都有广泛的应用。
本文将介绍几种常见的时间序列分析模型。
1. 移动平均模型(MA)移动平均模型是时间序列分析中最简单的模型之一。
它基于一个基本假设,即观察到的时间序列数据是对随机误差的线性组合。
该模型表示为:y_t = c + e_t + θ₁e_(t-1) + θ₂e_(t-2) + … + θ_qe_(t-q)其中,y_t 是观察到的数据,c 是常数,e_t 是随机误差,θ₁,θ₂,…,θ_q 是移动平均项的参数,q 是移动平均项的阶数。
2. 自回归模型(AR)自回归模型是基于一个基本假设,即观察到的时间序列数据是过去若干时间点的线性组合。
自回归模型表示为:y_t = c + ϕ₁y_(t-1) + ϕ₂y_(t-2) + … + ϕ_p y_(t-p) + e_t其中,y_t 是观察到的数据,c 是常数,e_t 是随机误差,ϕ₁,ϕ₂,…,ϕ_p 是自回归项的参数,p 是自回归项的阶数。
3. 自回归移动平均模型(ARMA)自回归移动平均模型将自回归模型和移动平均模型结合在一起,用于处理同时具有自相关和移动平均性质的时间序列数据。
自回归移动平均模型表示为:y_t = c + ϕ₁y_(t-1) + ϕ₂y_(t-2) + … + ϕ_p y_(t-p) + e_t +θ₁e_(t-1) + θ₂e_(t-2) + … + θ_qe_(t-q)其中,y_t 是观察到的数据,c 是常数,e_t 是随机误差,ϕ₁,ϕ₂,…,ϕ_p 是自回归项的参数,θ₁,θ₂,…,θ_q 是移动平均项的参数,p 是自回归项的阶数,q 是移动平均项的阶数。
4. 季节性自回归移动平均模型(SARIMA)季节性自回归移动平均模型是自回归移动平均模型的扩展,用于处理具有季节性和趋势变化的时间序列数据。