第三章3 核酸序列的基本分析 (2010)
- 格式:ppt
- 大小:296.50 KB
- 文档页数:22

核酸序列特征分析核酸序列特征分析是一种利用bioinformatics工具技术来探究生物体基因组DNA/RNA序列中的特征信息,以及基因组DNA/RNA序列之间存在的关联性。
核酸序列特征分析在生物医学研究中具有重要的应用价值。
一、核酸序列特征分析的背景1、DNA是生物体基因组的主要构成元素,有着极重要的意义。
DNA的构成分子是DNA的主要单位,其中含有许多信息。
包括基因的信息、细胞生物学过程的信息、发育过程的信息、衰老过程的信息等。
核酸序列特征分析就是基于这些信息,利用相关方法把DNA序列转化为特殊符号,进而探究基因组中DNA序列的特征信息及其与基因组DNA序列之间的关联性。
2、研究表明,基因组DNA/RNA序列中存在着丰富的特征信息,其中包括基因的结构信息、功能信息以及遗传物质的表达信息等。
此外,基因组DNA/RNA序列之间也存在着一定的关联性,比如伴随关系、控制关系等。
对这些特征信息和序列间关联性的深入研究和分析,可以为解决相关生物学问题提供有力的支持。
二、核酸序列特征分析的方法核酸序列特征分析包括DNA特征分析、RNA特征分析和DNA-RNA 互作特征分析三大类。
其中,DNA特征分析是探究基因组DNA序列中的特征信息,主要包括序列密度分析、保守区域检测、单碱基构象分析、内含子检测、集合核苷酸模式挖掘和保守元件的检测等。
而RNA特征分析是探究基因组RNA序列特征信息,主要包括序列特征分析、microRNA检测、可变剪接位点预测、次级结构模式挖掘等。
最后,DNA-RNA互作特征分析是以DNA序列为基础探究DNA和RNA序列之间的相互关联性,主要包括DNA-RNA互作互作特性检测、DNA和RNA序列的共鉴定等。
三、核酸序列特征分析的应用在生物医学研究中,核酸序列特征分析可以为研究基因组中基因的信息、发育过程、衰老过程和药物等相关生物医学问题提供有力的支持。
比如,利用核酸序列特征分析,可以进行miRNA-病毒序列特征鉴定、慢病毒检测等;可以进行病毒的毒性预测,探究病毒引发疾病的发生机制;可以预测蛋白质的功能,指导新药的研发;可以检测抗药性基因等。


核酸的序列测定
DNA序列是指携带遗传信息的DNA分子中的A、C、G、T的序列。
分析方法主要有两种,一种是Maxam-Gilbert化学法,另一种是Sanger的双脱氧法。
现在一般都采用后者,其基本原理是:
1.用凝胶电泳分离待测的DNA片段(用作模板)。
2.将模板、引物、4种dNTP、合适的聚合酶置于4个试管,每一试管按精确比例各加入一种ddNTP,用同位素或荧光物质标记。
3.利用ddNTP可特异地终止DNA链延长的特点,4个试管的聚合反应可以得到一系列大小不等、被标记的片段。
4.将4个反应管同时加到聚丙烯凝胶上电泳,标记片段按大小分离,放射自显影后可按谱型读出DNA序列。
在以上两种方法的基础上,通过与计算机技术和荧光技术的结合,发明了自动测序仪。
目前,常用的测序策略是“鸟枪法”,形象地说是将较长的基因片段打断,构建一系列的随机亚克隆,然后测定每个亚克隆的序列,用计算机分析以发现重叠区域,最终对大片段的DNA定序。
1。



核酸序列特征分析核酸序列特征分析是生物信息学研究中重要的一个方面。
它可以帮助我们更深入地理解基因组及基因表达研究。
本文旨在介绍核酸序列特征分析,其中包括核酸序列分析、核酸序列特征抽取和质粒抽取等内容。
首先,介绍核酸序列分析,其中包括特征分类、序列特征检测、序列分类和序列比对等。
核酸特征分类是将核酸序列分为有用的和无用的,从而排除噪声。
核酸序列特征检测包括对不同类型的基因、基因组表达、基因功能和结构等特征的检测,以及比较不同物种序列或不同基因组结构的检测。
核酸序列分类是用特征抽取技术分析序列长度,以确定序列的分类及特征。
序列比对是比较两个或多个序列的相似性,以发现可能的相似性或共同特征。
其次,介绍核酸序列特征抽取。
它分为特征抽取和质粒抽取两大类。
特征抽取的主要目的是抽取出序列的非特定特征,比如k-mer特征,基于序列单位的反向字典学习(RLD)等方法。
质粒抽取的目的是抽取出序列以及其表达周围的特定特征,比如突变、位点突变、基因连接等。
特征抽取是对序列的概括,抽取出重要的特征,而质粒抽取是对序列表达的概括,可以捕捉到序列的精细结构信息。
最后,介绍核酸序列特征分析的一些应用。
一方面,核酸序列特征分析可以用于揭示基因组结构和功能特征。
例如,可以利用序列比对技术对不同物种序列进行对比,揭示出不同物种的关键基因。
另一方面,核酸序列特征分析也可以用于揭示表达调控机制。
例如,可以用特征分类和序列特征抽取技术,结合表达评价结果,探索基因表达调控的内在机制。
综上所述,核酸序列特征分析是生物信息学研究中重要的一个方面。
它可以用来探索基因组结构和功能特征,揭示表达调控机制,改进基因调控机制,为临床实验提供分析指导,并帮助我们更加深入地了解基因组研究和基因表达研究。
因此,核酸序列特征分析的研究将给生物信息学领域带来许多新的机会。


核酸和蛋白质序列分析在获得一个基因序列后,需要对其进行生物信息学分析,从中尽量发掘信息,从而指导进一步的实验研究。
通过染色体定位分析、内含子/外显子分析、ORF分析、表达谱分析等,能够阐明基因的基本信息。
通过启动子预测、CpG岛分析和转录因子分析等,识别调控区的顺式作用元件,可以为基因的调控研究提供基础。
通过蛋白质基本性质分析,疏水性分析,跨膜区预测,信号肽预测,亚细胞定位预测,抗原性位点预测,可以对基因编码蛋白的性质作出初步判断和预测。
尤其通过疏水性分析和跨膜区预测可以预测基因是否为膜蛋白,这对确定实验研究方向有重要的参考意义。
此外,通过相似性搜索、功能位点分析、结构分析、查询基因表达谱聚簇数据库、基因敲除数据库、基因组上下游邻居等,尽量挖掘网络数据库中的信息,可以对基因功能作出推论。
上述技术路线可为其它类似分子的生物信息学分析提供借鉴。
本路线图及推荐网址已建立超级链接,放在北京大学人类疾病基因研究中心网站(htt p://gene.b .cn/science/b ioinfomati cs.htm),可以直接点击进入检索网站。
下面介绍其中一些基本分析。
值得注意的是,在对序列进行分析时,首先应当明确序列的性质,是m RNA序列还是基因组序列?是计算机拼接得到还是经过PCR扩增测序得到?是原核生物还是真核生物?这些决定了分析方法的选择和分析结果的解释。
(一)核酸序列分析1、双序列比对(pai rwise alig nment)双序列比对是指比较两条序列的相似性和寻找相似碱基及氨基酸的对应位置,它是用计算机进行序列分析的强大工具,分为全局比对和局部比对两类,各以N eedleman-W unsch算法和Sm ith-Waterm an算法为代表。
由于这些算法都是启发式(heuristic)的算法,因此并没有最优值。

核酸序列特征分析核酸序列特征分析是一个针对基因及其控制结构的重要研究课题,它可以帮助我们更好地理解遗传物质的结构和功能。
本文将介绍核酸序列特征分析的基本原理、步骤及分析方法,最后介绍可视化工具。
一、核酸序列特征分析的基本原理核酸序列特征分析是一种统计分析方法,用于全面分析核酸序列的某种特征,以发现和探索结构以及功能关系。
这种方法依赖于统计模型,以及不同特征度量标准,例如单碱基特征、二碱基特征、多碱基特征和序列分类等等。
可以选择不同特征的集合,用来发现序列的一些特殊结构,包括基因、调控序列、蛋白质结构和功能。
二、核酸序列特征分析的步骤核酸序列特征分析的步骤一般分为五个步骤:(1)获取输入数据,根据特征选择相应的特征计算库。
(2)利用统计模型以及参数,计算得出相应特征度量值,并将它们存储到计算机中。
(3)根据特征选择合适的建模方法,比如对数据进行聚类。
(4)根据模型参数,绘制特征分析图。
(5)根据图形结果做出结论,并给出相应的解释。
三、核酸特征分析中的分析方法1、基于核酸序列的单碱基特征分析:该方法的主要目的是分析单个碱基的分布,例如A/G,C/T,或者任意一对对立的碱基,通过比较单碱基出现次数的差异,来确定特定序列应该具有什么样的特征。
2、基于核酸序列的二碱基特征分析:该方法是针对两个或多个二碱基的比较,可以用来确定二碱基的组合的特征,以探究其中的影响因素。
3、基于核酸序列的多碱基特征分析:该方法是以一组碱基为单位进行分析,识别给定序列的多碱基特征,并评估它们之间的相关性。
4、基于核酸序列的序列分类:这是一种机器学习方法,通过特征选择,建立一个分类模型,然后将训练集中的序列分类为种类,利用这一模型,可以对未知序列进行预测。
四、可视化工具随着科技的发展,可视化工具也得到了极大的改进,它们可以帮助我们更好地理解核酸序列特征分析的结果。
例如Cytoscape,这是一个开源的网络可视化软件,可以帮助我们更直观地了解核酸序列中的二碱基关系;SeqView,这是一个基于web的序列可视化工具,提供了多种的可视化效果,例如3D结构、双向序列特征分析等;Circos,这是一个用于可视化大规模连接数据和关系的高效工具,可以帮助我们将序列特征分析结果可视化为动态图形。
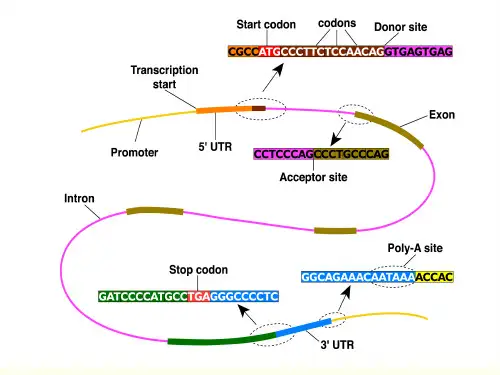

实验二核酸序列分析【实验目的】1、掌握已知或未知序列接受号的核酸序列检索的基本步骤;2、掌握使用BioEdit软件进行核酸序列的基本分析;1、熟悉基于核酸序列比对分析的真核基因结构分析(内含子/外显子分析);2、了解基因的电子表达谱分析。
【实验原理】针对核酸序列的分析就是在核酸序列中寻找基因,找出基因的位置和功能位点的位置,以及标记已知的序列模式等过程。
在此过程中,确认一段DNA序列是一个基因需要有多个证据的支持。
一般而言,在重复片段频繁出现的区域里,基因编码区和调控区不太可能出现;如果某段DNA片段的假想产物与某个已知的蛋白质或其它基因的产物具有较高序列相似性的话,那么这个DNA片段就非常可能属于外显子片段;在一段DNA序列上出现统计上的规律性,即所谓的“密码子偏好性”,也是说明这段DNA是蛋白质编码区的有力证据;其它的证据包括与“模板”序列的模式相匹配、简单序列模式如TATA Box等相匹配等。
一般而言,确定基因的位置和结构需要多个方法综合运用,而且需要遵循一定的规则:对于真核生物序列,在进行预测之前先要进行重复序列分析,把重复序列标记出来并除去;选用预测程序时要注意程序的物种特异性;要弄清程序适用的是基因组序列还是cDNA序列;很多程序对序列长度也有要求,有的程序只适用于长序列,而对EST这类残缺的序列则不适用。
1. 重复序列分析对于真核生物的核酸序列而言,在进行基因辨识之前都应该把简单的大量的重复序列标记出来并除去,因为很多情况下重复序列会对预测程序产生很大的扰乱,尤其是涉及数据库搜索的程序。
2. 数据库搜索把未知核酸序列作为查询序列,在数据库里搜索与之相似的已有序列是序列分析预测的有效手段。
在理论课中已经专门介绍了序列比对和搜索的原理和技术。
但值得注意的是,由相似性分析作出的结论可能导致错误的流传;有一定比例的序列很难在数据库里找到合适的同源伙伴。
对于EST序列而言,序列搜索将是非常有效的预测手段。