基于本体知识库的自动语义标注
- 格式:pdf
- 大小:313.78 KB
- 文档页数:4

一种基于本体的语义标引方法
秦春秀;赵捧未;窦永香
【期刊名称】《情报理论与实践》
【年(卷),期】2005(028)003
【摘要】传统的采用主题词和关键词对文档进行标引的方法,由于不能提供语义推理而越来越不适合目前的网络环境.由于本体具有良好的概念层次结构和对逻辑推理的支持,在信息检索领域将有很大的应用价值.本文首先介绍本体的基本概念和领域本体的组成部分,然后提出了一种基于领域本体的语义标引方法,采用本体中的概念对文档进行语义层面的标引,为检索的智能推理提供基础.
【总页数】3页(P244-246)
【作者】秦春秀;赵捧未;窦永香
【作者单位】西安电子科技大学经济管理学院,陕西,710071;西安电子科技大学经济管理学院,陕西,710071;西安电子科技大学经济管理学院,陕西,710071
【正文语种】中文
【中图分类】G2
【相关文献】
1.一种基于本体论和潜在语义索引的文本语义处理方法 [J], 秦春秀;刘怀亮;赵捧未
2.基于本体和语义标引的地质资料服务与管理研究 [J], 闫东;王诚
3.基于本体语义标引中的存储与检索研究 [J], 王宏生;于晓巍
4.一种基于概率潜在语义分析的专利主题标引方法研究 [J], 包翔;刘桂锋
5.一种基于概率潜在语义分析的专利主题标引方法研究 [J], 包翔;刘桂锋
因版权原因,仅展示原文概要,查看原文内容请购买。

基于领域本体概念划分的语义标注方法
杨利;叶明全;郑诚
【期刊名称】《合肥学院学报(自然科学版)》
【年(卷),期】2013(023)001
【摘要】对当前的基于领域本体的语义标注方法进行了说明和分析,提出了基于领域本体概念划分的语义标注方法.该方法将领域本体中的概念分为特有概念和普通概念,先用一般的领域本体标注算法计算特征词的权值,再对普通概念特征词的权值进行调整,最后结合水稻领域进行试验.实验表明,该方法在保证查全率的基础上,提高了普通概念特征词的查准率.
【总页数】4页(P41-44)
【作者】杨利;叶明全;郑诚
【作者单位】皖南医学院,计算机教研室,安徽芜湖241002;皖南医学院,计算机教研室,安徽芜湖241002;安徽大学,计算机科学与技术学院,合肥230039
【正文语种】中文
【中图分类】TP391.3
【相关文献】
1.一种基于领域本体的数据服务语义标注方法 [J], 郭超;唐成务;陈彦萍
2.基于领域本体的语义标注方法研究 [J], 时念云;杨晨
3.基于领域本体的专业文档语义标注方法 [J], 魏墨济;于涛
4.一种基于OWL-S领域本体的Web服务语义标注方法研究 [J], 李建新;柯钢;杨
怀德
5.基于领域本体的自动化语义标注方法的研究 [J], 陈星光;张文通;汪霞
因版权原因,仅展示原文概要,查看原文内容请购买。

基于本体的语义信息检索研究共3篇基于本体的语义信息检索研究1随着互联网规模的不断扩大和人们对信息获取的需求不断增加,信息检索技术的研究和发展日益受到重视。
传统的文本检索方法主要关注于词汇的匹配,然而,随着语义网络的不断发展,人们更加关注语义信息检索。
基于本体的语义信息检索即是基于本体技术实现的语义信息检索。
本体是描述认识领域概念、属性和关系的模型,常常用于知识表示和语义信息的处理和检索。
基于本体的语义信息检索有别于传统的文本检索方法,它采用了语义计算技术将词汇转换为概念,然后利用本体进行语义匹配,从而实现精准的检索结果。
与传统的文本检索方法相比,基于本体的语义信息检索具有一些显著的优点:第一,实现了概念级别的检索。
传统的文本检索方法是基于关键字的匹配,而基于本体的语义信息检索是基于概念的匹配,搜索面更加广泛,可以进行满足需求的细粒度检索。
第二,提高了检索结果的准确性。
基于本体的语义信息检索不仅可以检索到与查询意图高度相关的信息,还可以同时检索到与查询意图相关但表述方式不同的信息,大大提高了检索结果的准确性。
第三,自动化程度高,能够自动地对查询语句进行语义分析和语义推理。
这一点在处理语言表述多样化的查询时尤为重要,规避了传统文本检索方法因语言多样化而给检索过程带来的不便。
基于本体的语义信息检索技术已经在多个领域得到了广泛的应用,如谷歌、百度等搜索引擎遵循这种检索模式,通过本体挖掘信息的关联性和语义,实现了搜索引擎的智能化。
此外,基于本体的语义信息检索还被应用于知识管理、智能问答系统、智能推荐等多个领域。
尽管基于本体的语义信息检索在理论和实践中取得了许多进展,但它仍面临着一些挑战:第一,本体的建立需要大量的领域知识和专业技能,光靠静态地建立本体往往难以适应快速变化的环境。
为此,研究者可以动态调整本体,将人工干预和自动学习相结合。
第二,理解查询语句需要具备高度的自然语言处理能力,而现有自然语言处理技术的表现通常无法让人满意。

数据库元数据的自动语义标注董国卿;童维勤【期刊名称】《计算机科学》【年(卷),期】2012(039)0z3【摘要】语义异构是异构数据库信息集成中要解决的关键问题.为了使关系数据库的表和字段具有语义信息,将数据库元数据自动标注成语义元数据成为研究的热点.基于概念名和概念结构的语义相似度计算,提出了一种数据库元数据自动语义标注方法.首先从关系数据库的元数据中提取隐含的语义信息,并据此创建领域本体,然后通过计算元数据与本体实体间的语义相似度对提取的元数据进行自动语义标注,提出的相似度算法综合考虑了概念名称和结构的相似性,并采取了必要的优化措施进行改进.经实验测试证明,该方法具有较高的标注正确率,是一种行之有效的语义标注方法.%The solution to semantic heterogeneity of the integrated data is a key point in the integration of heterogeneous databases. To aim at adding semantic information to tables and fields in relational databases, automatic semantic annotation for metadata in relational database is a hot spot. In this paper, a semantic annotation method was developed based on similarity algorithms. Firstly,implicit semantic information is extracted from metadata in relational databases, and domain ontologies are created based on the information. Then, the extracted information is annotated automatically by using name similarities and structural similarities between metadata and the ontology entity,and the similarity algorithms areimproved. The experiment shows that the method is effective for the task of automatic semantic annotation.【总页数】4页(P159-162)【作者】董国卿;童维勤【作者单位】上海大学计算机工程与科学学院上海200444;中国石油大学网络及教育技术中心青岛266555;上海大学计算机工程与科学学院上海200444【正文语种】中文【中图分类】TP3-0【相关文献】1.基于语义关联的视频元数据库构建 [J], 凌坚;蔡国炎;练益群2.语义标注元数据及其抽取技术 [J], 凌海云;左志宏;陈兰;段恩泽;袁军英3.基于语义标注的数据资源库元数据质量自动评估方法研究 [J], 郭晓明;马良荔;苏凯;孙煜飞4.基于模糊机制和语义密度聚类的汉语自动语义角色标注研究 [J], 王旭阳; 朱鹏飞5.矿山语义物联网自动语义标注方法 [J], 张楠; 谢国军; 叶青; 赵小虎因版权原因,仅展示原文概要,查看原文内容请购买。

语料库标记与标注以中国英语语料库为例一、本文概述本文旨在探讨语料库标记与标注的重要性及其在中国英语语料库中的应用。
我们将简要介绍语料库的定义和类型,以及标记与标注在语料库建设中的作用。
接着,我们将以中国英语语料库为例,详细阐述语料库的标记与标注过程,包括标记符号的选择、标注规则的制定以及标注质量的控制等方面。
在此基础上,我们将进一步探讨语料库标记与标注对于语言研究、自然语言处理以及机器翻译等领域的影响和应用价值。
我们将总结当前语料库标记与标注研究中存在的问题和挑战,并展望未来的发展趋势和研究方向。
通过本文的阐述,我们希望能够加深对语料库标记与标注的理解,推动中国英语语料库的建设和发展,为相关领域的研究提供有益的参考和启示。
二、语料库的基本概念与分类语料库(Corpus)是以电子形式存储的语言材料的集合,通常包括文本、音频或视频等形式的语言数据。
语料库语言学是语言学的一个分支,专注于利用语料库进行语言研究。
在语料库语言学中,语料库被视为一种研究工具,可用于描述语言的实际使用情况,揭示语言的规律,以及评估语言教学和自然语言处理的效果。
语料库可以按照不同的标准进行分类。
按照语料库的来源,可以分为原生语料库(native corpus)和编译语料库(compiled corpus)。
原生语料库是直接收集的自然语言文本,如新闻报道、文学作品、社交媒体帖子等。
编译语料库则是由多个不同来源的文本经过整理、清洗和标注后形成的。
按照语料库的内容,可以分为通用语料库(general corpus)和专用语料库(specialized corpus)。
通用语料库包含各种类型的文本,旨在反映语言的整体使用情况。
专用语料库则针对某一特定领域或主题,如医学、法律、科技等领域的语料库。
按照语料库的处理程度,可以分为生语料库(raw corpus)和标注语料库(annotated corpus)。
生语料库是未经处理的原始文本,而标注语料库则对文本进行了各种形式的标注,如词性标注、句法标注、语义标注等。
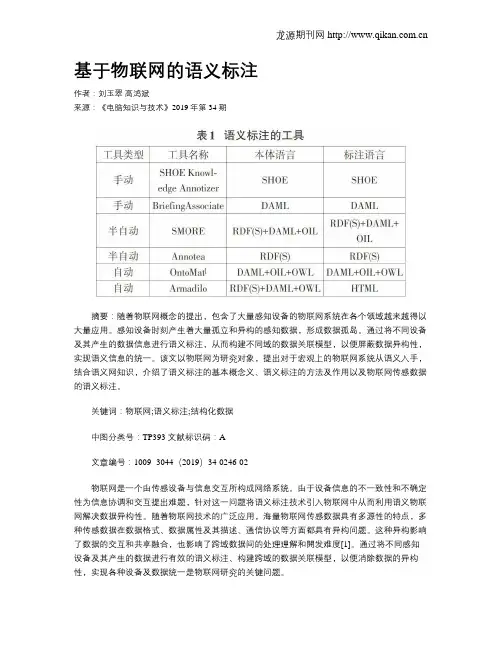
基于物联网的语义标注作者:刘玉翠高鸿斌来源:《电脑知识与技术》2019年第34期摘要:随着物联网概念的提出,包含了大量感知设备的物联网系统在各个领域越来越得以大量应用。
感知设备时刻产生着大量孤立和异构的感知数据,形成数据孤岛。
通过将不同设备及其产生的数据信息进行语义标注,从而构建不同域的数据关联模型,以便屏蔽数据异构性,实现语义信息的统一。
该文以物联网为研究对象,提出对于宏观上的物联网系统从语义入手,结合语义网知识,介绍了语义标注的基本概念义、语义标注的方法及作用以及物联网传感数据的语义标注。
关键词:物联网;语义标注;结构化数据中图分类号:TP393 文献标识码:A文章编号:1009- 3044(2019)34-0246-02物联网是一个由传感设备与信息交互所构成网络系统。
由于设备信息的不一致性和不确定性为信息协调和交互提出难题,针对这一问题将语义标注技术引入物联网中从而利用语义物联网解决数据异构性。
随着物联网技术的广泛应用,海量物联网传感数据具有多源性的特点,多种传感数据在数据格式、数据属性及其描述、通信协议等方面都具有异构问题。
这种异构影响了数据的交互和共享融合,也影响了跨域数据间的处理理解和開发难度[1]。
通过将不同感知设备及其产生的数据进行有效的语义标注、构建跨域的数据关联模型,以便消除数据的异构性,实现各种设备及数据统一是物联网研究的关键问题。
1 语义标注物联网的语义化为物联网领域资源提供了新的组织知识的方式,语义物联网的实现依赖于大量的、与各种形式化知识相关联的物联网内容元数据。
当前语义网的发展迫切需要特定的、明确的和容易理解的语义元数据的创建和使用,也就是需要对当前的物联网所有资源数据进行广泛可用的语义标注。
语义标注指的是通过语义元数据阮数据指的是描述数据的数据,通常指本体有XML、RDF、OWL等格式)为文档资源添加语义标记识别语义信息的过程,使其具有语义信息,不仅人可以理解,而且使机器也可以理解。

基于本体的语义检索[1]杨月华, 杜军平摘要:本文对基于本体的语义检索进行了综述。
从自然语言处理、基于概念的方法以及基于本体三个方面来实现语义在信息检索中的集成和应用。
关键词:本体;语义;检索;信息检索传统的信息检索方法或搜索引擎,无论是关键字符的匹配,还是结合布尔逻辑运算提供更为复杂的查询表达方式,都是以关键词匹配为基础的。
这种方法有两种缺陷:检索结果只是在字面上符合用户的要求,实际内容往往偏离用户的需要。
用户输入的查询稍有偏差,检索系统就无法确定用户的真正需要,因而无法提供正确的结果。
为了解决这些问题,研究者尝试从语义的角度进行考虑,提出了各种新的方法和技术,也取得了很多的成果。
通常的研究主要从自然语言处理、基于概念的方法以及基于本体的思路三个方面来实现语义在信息检索中的集成和应用。
1994年Voorhees就曾提出基于本体的查询扩展,使用了本体中的概念进行查询扩展,并得出最有效的方式是利用本体中的同义词和特定的子类关系进行扩展。
此后,基于本体的查询扩展研究侧重于两个方面——基于结构化的方法和基于注释的方法。
前者着重从本体的结构信息中抽取出相似度衡量的依据,而后者则通过计算本体术语的定义中的重叠次数来衡量语义相似度。
Maki在2003年提出了基于本体结构的方法,基本的思想是利用本体中的路径来进行用户查询的扩展。
在本体的结构图中,每个概念的节点都与其他节点有连通的路径,因此对用户查询进行扩展时,可以选择与该节点连通的路径上的概念。
在对概念选择时,Maki提出利用一系列的关系边和概念节点之间相似度的方法来进行排序,优先选择与被扩展概念相似度大者。
而计算相似度的方法依赖于本体的结构,例如进行比较的概念之间路径的数量、长度以及路径中存在关系种类数、路径中节点种类等,都可以作为衡量的标准。
2004年,Navigli提出了基于本体注释的查询扩展方法。
该方法假定了在本体中相似的概念或术语也具有相似的定义,使用了WordNet中的概念并对其进行扩充了注释。

基于本体的语义检索研究与实现的开题报告
一、研究背景
在信息化时代,“信息爆炸”已成为常态,而针对海量信息的语义
检索一直是信息检索领域的研究热点之一。
传统的检索方法往往只是基
于关键词的匹配,很难满足用户多样化的需求。
而基于本体的语义检索,可以结合领域知识,更好地理解用户的查询意图,从而精准地提供匹配
结果。
本体是一种描述概念、类别和实体之间关系的形式化方法,其构建
所需的知识表示、逻辑推理和元数据,可以更好地支持语义检索技术的
实现。
基于本体的语义检索涉及到多个领域知识,如自然语言处理、信
息检索、知识表示与推理等,各个领域的方法和技术的结合与优化,可
以实现更加准确的检索和推荐。
二、研究内容
本次研究的主要内容包括:
(1)本体的构建:从领域知识库中抽取实体、属性、概念等关键信息,构建本体。
(2)语义解析与分析:对用户输入的自然语言进行分析,从中提取出查询的关键词、实体、属性等。
(3)语义匹配算法的研究:基于本体的语义匹配算法的研究,包括基于语义相似度的匹配算法、基于语义路径的匹配算法等。
(4)语义检索系统的设计与实现:根据研究成果,设计并实现基于本体的语义检索系统,支持用户输入自然语言查询,输出相关内容。
三、研究意义
本次研究旨在提高信息检索系统的精准性和智能化水平,对于企业、文化教育机构和政府等信息化建设具有重要的实际应用价值。
同时,本
研究还将为相关领域的研究者提供开发基于本体的语义检索系统的理论和方法,并推动相关技术在学术和应用领域的发展。

基于本体的语义标引研究与实现
张功杰;黄穗
【期刊名称】《计算机工程与设计》
【年(卷),期】2008(029)008
【摘要】标引是资源管理与检索的基础.传统的标引方式仅停留在关键字异同的逻辑层面,忽略了文档语义层面上的信息.以本体的知识组织体系为基础,以抽取文档的语义向量为目标,提出了基于本体的语义标引思想,为基于概念匹配的语义检索创造条件.为了更清晰的描述标引过程,建立了基于本体的语义标引模型,并对模型中各环节进行详细的功能定义.参照具体的实例本体进行实验和分析.
【总页数】3页(P2078-2080)
【作者】张功杰;黄穗
【作者单位】暨南大学,计算机科学系,广东,广州,510632;徐州师范大学,计算机科学与技术学院,江苏,徐州,221116;暨南大学,计算机科学系,广东,广州,510632
【正文语种】中文
【中图分类】TP391
【相关文献】
1.一种基于本体的语义标引方法 [J], 秦春秀;赵捧未;窦永香
2.基于本体的语义Web服务匹配机制的研究与实现 [J], 杨力
3.基于本体和语义标引的地质资料服务与管理研究 [J], 闫东;王诚
4.基于本体的语义检索技术研究与实现 [J], 王继东;张瑜;李娜
5.基于本体语义标引中的存储与检索研究 [J], 王宏生;于晓巍
因版权原因,仅展示原文概要,查看原文内容请购买。

基于物联网的语义标注基于物联网的语义标注在实现智能化的物联网服务中扮演着重要角色,它可以对物联网设备中的数据进行精准的描述和分类,从而提高系统的智能化程度。
本文将介绍基于物联网的语义标注的相关概念、方法和应用场景。
物联网语义标注是指对物联网设备中的数据进行语义描述和标记的过程,通过给数据添加语义标签,以便系统能够理解和处理这些数据。
语义标注可以实现对物联网设备中数据的精准描述,为后续的数据挖掘、数据分析和决策提供有力支持。
物联网语义标注的方法主要包括基于规则的标注、基于本体的标注和基于机器学习的标注。
1. 基于规则的标注:通过定义一系列规则,对数据进行标注。
可以定义一条规则,如果数据中包含某个关键词,则添加相应的标签。
这种方法简单直观,但需要手动定义规则,对于数据量大、复杂的场景适用性较低。
2. 基于本体的标注:本体是一种用于描述现实世界概念和概念之间关系的形式化表示方法。
基于本体的标注通过将物联网设备中的数据与本体进行关联,将数据映射到本体中定义的概念上,从而实现对数据的标注。
这种方法可以利用本体中丰富的语义信息,实现对数据更精准的描述。
3. 基于机器学习的标注:通过机器学习算法,根据已有的标注数据训练模型,将模型应用于新的数据中,实现自动化的标注。
这种方法不依赖人工定义的规则和本体,能够适应数据的变化,并可以根据数据的分布特征进行较好的标注。
物联网语义标注广泛应用于智能家居、智能交通、智慧农业和智慧城市等领域。
1. 智能家居:物联网语义标注可以对家庭设备中的数据进行标注,实现智能控制和自动化。
通过对温度传感器数据进行标注,系统可以智能地自动调整室内温度,提升生活舒适度。
2. 智能交通:物联网语义标注可以对交通设备中的数据进行标注,实现交通流量监测和交通信号控制。
通过对车辆传感器数据进行标注,可以实时监控道路上的车辆数量和车速,从而合理调整交通信号,优化交通流量。
3. 智慧农业:物联网语义标注可以对农业设备中的数据进行标注,实现农作物生长监测和智能灌溉。

基于本体论的语义检索技术的研究与实现的开题报告一、研究背景及意义随着互联网信息量的急剧增长,传统的关键词搜索已经不能满足人们获取信息的需求,语义检索成为了一个热门领域。
语义检索不仅仅是对关键词的简单匹配,而是在理解搜索意图的基础上对语义进行精准匹配,从而实现更精准的搜索结果。
现阶段,大多数语义检索技术主要基于词袋模型和统计学习的方法,这种方法在文本相似性计算方面存在一定的局限性。
因此,基于本体论的语义检索技术逐渐受到关注。
基于本体论的语义检索技术是指将本体论的概念与概念之间的关系作为语义理解的基础,通过构建本体、利用本体间的语义关系进行搜索,并给出相应结果。
相比于传统语义检索方法,基于本体论的语义检索技术可以完全理解搜索意图,从而更精准地匹配查询条件,提高搜索结果的质量。
此外,本体库的构建也可以极大地促进知识的共享和普及。
二、研究内容本文旨在研究和实现基于本体论的语义检索技术,主要包括以下内容:1. 本体论基础知识的学习和掌握。
研究本体的定义、本体之间的关系以及基本术语等知识,为后续建立本体库做好铺垫。
2. 针对不同领域的本体库构建。
针对不同领域的本体库建立,使本体的概念和关系可以更准确地反映特定领域的知识,从而提高搜索结果的质量。
3. 基于本体的语义检索算法研究。
研究基于本体的语义检索算法,理解其原理,并选择适合本体库的算法进行实验。
比较不同算法的优缺点和效果,找出最适合本体库的算法。
4. 语义检索系统的设计和实现。
基于前述研究结果,设计并实现一个基于本体的语义检索系统,包括后端的本体库、算法以及前端的用户界面。
完成一个完整的语义检索系统。
三、研究方法1. 了解和学习本体论的基本概念和知识,包括概念、属性、关系等,研究不同领域的本体构建,并选择合适的工具。
比如 Protégé和 OWL API 等工具。
2. 掌握基于本体的语义检索算法,并研究现有的算法实现,比如基于相关度计算的检索算法、基于本体上下位关系的检索算法、基于本体关系路径的检索算法等。
知识图谱中的本体构建及语义检索技术研究随着信息时代的到来,海量的数据已经成为人们面临的一大挑战。
如果不能对数据进行有效地管理和处理,将会对人类生产和生活产生负面影响。
在这样的背景下,知识图谱应运而生。
知识图谱是指一种用于描述和组织关于现实世界中事物及其关系的计算机可读数据的图谱。
知识图谱促进了人工智能领域的发展,极大地推动了智能系统、机器学习、自然语言处理等技术的进步。
知识图谱的本质是将现实世界各种事物及其关系规范化为计算机可读的形式,这也就需要对现实世界进行精细化的建模。
在知识图谱中,本体构建是至关重要的一环。
本体是描述现实世界的一个形式化的结构,常用于储存和维护知识图谱中的信息,本体的作用是对现实世界的事物进行分类、属性描述和关系描述。
本体可以理解为描述知识背景的元数据,可以帮助我们更好地理解和组织所描述的知识图谱。
因此从本质上讲,本体是知识图谱的支撑和基础。
本体的构建是一个系统工程。
其主要目的是通过一系列的步骤,将人类对某一领域的知识和理论体系形式化为一个计算机可读的数据结构,以便于知识图谱的实现。
在本体构建的过程中,我们需要人工的进行领域知识的分析和挖掘,并将其转化为本体描述的形式。
本体描述是一个基于逻辑的语言,通常采用OWL语言进行描述。
在本体描述的过程中,需要对领域中的概念进行分类,定义这些概念的属性及其关系,并对这些关系进行规范化的描述。
在本体的构建过程中,我们通常会采用多种工具来辅助我们进行本体的构建和验证。
随着本体的构建和知识图谱的完善,如何有效地进行知识检索成为了研究的热点。
知识图谱中的语义检索技术则是解决这个问题的一个关键性的技术。
语义检索是一种基于语义知识进行检索的方法,其核心在于理解用户输入的询问,并基于本体和知识图谱进行推理并给出结果。
与传统的文本检索不同,语义检索能够克服语言语义鸿沟的问题,可以更加准确地响应用户的搜索请求。
语义检索技术的优点不仅体现在检索效果的提升,同时也可以帮助企业和机构提高业务流程的自动化水平。
基于物联网的语义标注物联网(Internet of Things,IoT)是指利用各种传感器、射频识别技术、无线通信技术等手段将现实世界的物体与网络连接起来,并通过网络进行交互和通信的技术体系。
随着物联网技术的不断发展和普及,越来越多的物体被连接到了互联网上,产生了大量的数据。
这些数据本身是没有语义信息的,需要进行语义标注才能更好地应用和分析。
语义标注是指为数据或文本添加语义信息以提高数据的可理解性和利用性的过程。
在物联网中,语义标注可以为物体、环境、传感器等添加语义信息,以实现对它们的更加智能化的管理和控制。
语义标注可以基于各种不同的技术和方法。
一种常见的方法是利用本体论(ontology)来对数据进行标注。
本体论是一种用于描述概念和事物之间关系的形式化技术。
通过将物体、环境、传感器等抽象为本体概念,并建立它们之间的关系,可以为这些实体添加丰富的语义信息。
可以为一个温度传感器添加本体类别“温度传感器”以及与其他实体的关系,如其检测的环境、所处的位置等等。
这样,就可以通过查询本体来获取关于温度传感器的语义信息,如其属性、功能、所属环境等。
另一种常见的方法是利用机器学习技术进行语义标注。
机器学习是一种通过训练模型从数据中学习知识的方法。
在物联网中,可以使用机器学习算法来对数据进行分析和学习,从而为数据添加语义信息。
可以使用聚类算法来识别和分类物体或环境的特征,如温度、湿度等等。
然后,通过将这些特征与已知的语义信息进行映射,可以为物体或环境添加相应的标记。
这样,就可以通过查询标签来获取关于物体或环境的语义信息。
语义标注在物联网中具有重要的应用价值。
通过语义标注可以实现物联网中数据的智能化处理和分析。
通过添加语义信息,可以更好地理解和利用数据,从而实现更加精确的数据分析和应用。
语义标注可以为物体、环境、传感器等添加更多的语义信息,从而实现更加智能化的管理和控制。
可以根据物体的语义信息来自动识别和控制物体,实现对物体的智能化管理和控制。
一种基于本体与描述文本的网络图像语义标注方法
陈叶旺;钟必能;王靖;李海波
【期刊名称】《计算机科学》
【年(卷),期】2012(039)B06
【摘要】网络图像语义自动标注是实现对互联网中海量图像管理和检索的有效途径,而自动有效地挖掘图像语义是实现自动语义标注的关键。
网络图像的语义蕴含于图像自身,但更多的在于对图像语义起不同作用的各种描述文本,而且随着图像和描述知识的变化,描述文本所描述的图像语义也随之变化。
提出了一种基于领域本体和不同描述文本语义权重的自适应学习的语义自动标注方法,该方法从图像的文本特征出发考查它们对图像语义的影响,先通过本体进行有效的语义快速发现与语义扩展,再利用一种加权回归模型对图像语义在其不同类型描述文本上的分布进行自适应的建模,进而实现对网络图像的语义标注。
在真实的Web数据环境中进行的实验中,该方法的有效性得到了验证。
【总页数】7页(P293-299)
【作者】陈叶旺;钟必能;王靖;李海波
【作者单位】华侨大学计算机科学学院,厦门361021
【正文语种】中文
【中图分类】TP301
【相关文献】
1.基于本体和自动标注的网络邮票图像语义检索研究——以南京邮电大学数字邮票库为例 [J], 张志武
2.一种基于GMM的图像语义标注方法 [J], 陈晓;张尤赛;邹维辰
3.一种基于区域特征关联的图像语义标注方法 [J], 陈世亮;李战怀;袁柳
4.基于个性化本体的图像语义标注和检索 [J], 史婷婷;闫大顺;沈玉利
5.图像语义相似性网络的文本描述方法 [J], 刘畅;周向东;施伯乐
因版权原因,仅展示原文概要,查看原文内容请购买。