第七章 虚拟变量回归
- 格式:doc
- 大小:1.07 MB
- 文档页数:22
第七章 虚拟变量和随机解释变量本章将讨论两种不同的模型:虚拟变量模型和随机解释变量模型,以及模型设定的其它问题。
第一节 虚拟变量模型在我们以前考虑的模型中,解释变量都是定量变量(如成本、价格、收入、产出等),但在经济研究中,因变量经常受到一些定性变量的影响(如性别、种族、季节、不同历史时期等),我们把这类定性变量称为虚拟变量。
习惯上用D表示虚拟变量,虚拟变量的取值通常为0和1。
0表示变量具备某种属性,1表示变量不具备某种属性。
一、包含一个虚拟变量的模型如果我们要研究的问题中解释变量只分为两类。
则需引入一个模拟变量。
例9.1建立模型研究中国妇女在工作中是否受到歧视。
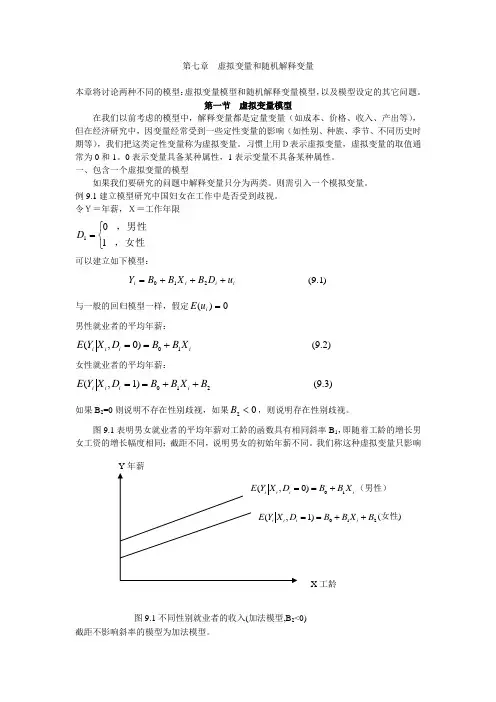
令Y=年薪,X=工作年限⎩⎨⎧=,女性,男性101D 可以建立如下模型:i i i i u D B X B B Y +++=210 )1.9( 与一般的回归模型一样,假定0)(=i u E 男性就业者的平均年薪:i i i i X B B D X Y E 10)0,(+== )2.9(女性就业者的平均年薪:210)1,(B X B B D X Y E i i i i ++== )3.9(如果B 2=0则说明不存在性别歧视,如果02<B ,则说明存在性别歧视。
图9.1表明男女就业者的平均年薪对工龄的函数具有相同斜率B 1,即随着工龄的增长男女工资的增长幅度相同;截距不同,说明男女的初始年薪不同。
我们称这种虚拟变量只影响截距不影响斜率的模型为加法模型。
图9.1不同性别就业者的收入(加法模型,B 2<0)如果随着工龄增加,男性与女性的年薪差距也发生变化,则模型(9.1)就变为i i i i i u X D B X B B Y +++=210 )4.9(图9.2描绘了男性年薪增加较快的情况。
我们称虚拟变量只影响斜率而不影响截距的模型为乘法模型如(9.4)如果男性与女性的初始年薪和年薪增加速度都有差异,我们可以将加法模型和乘法模型结合起来,得到如下模型i i i i i i u D B X D B X B B Y ++++=3210 )5.9(模型(9.5)可以用来表示截距和斜率都发生变化的模型。

第七章虚拟变量第一节虚拟变量的引入一、什么是虚拟变量前面几章介绍的解释变量都是可以直接度量的,称为定量变量。
如收入、支出、价格、资金等等。
但在现实经济生活中,影响应变量变动的因素,除了这些可以直接获得实际观测数据的定量变量外,还包括一些无法定量的解释变量的影响,如性别、民族、国籍、职业、文化程度、政府经济政策变动等因素,他们只表示某种特征的存在与不存在,所以称为属性变量或定性变量。
属性变量:不能精确计量的说明某种属性或状态的定性变量。
在计量经济模型中,应当包含属性变量对应变量的影响作用。
那怎么才能把定性变量包括在模型中呢?属性变量通常是非数值变量,直接纳入回归方程中进行回归,显然是很困难的。
为此,人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与定量变量一样在回归模型中得以应用。
由于定性变量通常是表明某种特征或属性是否存在,如性别变量中以男性为分析基础的话,那就只有男性、非男性;政策变动变量中以政策不变为基准,则有政策不变,和政策变动;至于有两种以上的状态的话,比如学历分高中,本科,本科以上等等,我们又怎么办呢?把疑问留到后面去解决。
既然定性变量只有存在或不存在两种状态,所以量化的一般方法是取值为0或1。
称为虚拟变量。
虚拟变量:人工构造的取值为0或1的作为属性变量代表的变量。
一般常用D表示。
D=0,表示某种属性或状态不存在D=1,表示某种属性或状态存在比如前面说的性别变量,以男性为基准,则当样本为男性时,虚拟变量取0,当样本为女性时,则虚拟变量取1。
当虚拟变量作为解释变量引入计量经济模型时,对其回归系数的估计和统计检验方法都与定量解释变量相同。
二、虚拟变量的作用1、作为属性因素的代表,如,性别、种族等2、作为某些非精确计量的数量因素的代表,如:受教育程度、年龄段等;3、作为某些偶然因素或政策因素的代表,如战争、911等。
4、时间序列分析中作为季节(月份)的代表(比如对某些明显有淡季、旺季之分的产品)5、分段回归,研究斜率、截距的变动;6、比较两个回归模型;7、虚拟应变量概率模型,应变量本身是定性变量(比如你研究某产品的购买率,应变量本身就是买或不买)三、虚拟变量的设置规则1、虚拟变量D取值为0,还是取值为1,要根据研究的目的决定。




伍德里奇《计量经济学导论》(第5版)笔记和课后习题详解-第7章含有定性信息的多元回归分析:二值(或第7章含有定性信息的多元回归分析:二值(或虚拟)变量7.1复习笔记一、对定性信息的描述定性信息通常以二值信息的形式出现。
在计量经济学中,二值变量最常见的称呼是虚拟变量。
二、只有一个虚拟自变量1.只有一个虚拟自变量的简单模型考虑如下决定小时工资的简单模型:001wage female educ uβδβ=+++用0δ表示female 的参数,以强调虚拟变量参数的含义。
假定零条件均值假定() 0E u female educ =,成立,那么:()()0| 1 |0 E wage female educ E wage female educ δ==-=,,由于female=1对应于女性且female=0对应于男性,所以可以简单的把模型写为:()()0| | E wage female educ E wage male educ δ=-,,这种情况可以在图形上描绘成男性与女性之间的截距变化。
男性线的截距是0β,女性线的截距是00βδ+。
由于只有两组数据,所以只需要两个不同的截距。
这意味着,除了0β之外,只需要一个虚拟变量。
因为female +male=1,意味着male 是female 的一个完全线性函数,如果使用两个虚拟变量就会导致完全多重共线性,这就是虚拟变量陷阱。
2.当因变量为log(y)时,对虚拟解释变量系数的解释在应用研究中有一个常见的设定,当自变量中有一个或多个虚拟变量时,因变量则以对数形式出现。
在这种情况下,此系数具有一种百分比解释。
当log(y)是一个模型的因变量时,将虚拟变量的系数乘以100,可解释为y 在保持所有其他因素不变情况下的百分数差异。
当一个虚拟变量的系数意味着y 有较大比例的变化时,可以得到精确的百分数差异。
一般地,如果1β是一个虚拟变量(比方说x 1)的系数,那么,当log(y)是因变量时,在x 1=1时预测的y 相对于在x 1=0时预测的y,精确的百分数差异为:()1?100exp 1β-??三、使用多类别虚拟变量1.在方程中包括虚拟变量的一般原则如果回归模型具有g 组或g 类不同截距,那就需要在模型中包含g-1个虚拟变量和一个截距。





虚拟变量回归
虚拟变量回归是指将一个分类变量转化为虚拟变量(也称为哑变量或指示变量),并将其作为解释变量在回归模型中使用。
虚拟变量是一种二元变量,其中一个变量用1表示某个类别,另一个变量用0表示不属于该类别。
例如,当一个分类变量有三个类别时,可以创建两个虚拟变量来表示这三个类别,分别是0-1变量A和0-1变量B,它们满足如下条件:
- 当分类变量属于A类时,变量A为1,变量B为0;
- 当分类变量属于B类时,变量A为0,变量B为1;
- 当分类变量属于C类时,变量A和变量B均为0。
在回归模型中使用虚拟变量可以使我们将分类变量的不同类别彼此对比,并推断它们对应的不同的回归系数,从而更好地解释和预测因变量。
虚拟变量回归在经济学、社会学、医疗保健等领域中很常见,可以用来研究诸如性别、种族、政治党派、行业等分类变量对某一因变量的影响。
第七章 虚拟变量回归第一节 虚拟变量的性质在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。
例如需要考虑性别、民族、不同历史时期、季节差异、政府的更迭(工党-保守党)、经济体制的改革、固定汇率变为浮动汇率、从战时经济转为和平时期经济等。
这些因素也应该包括在模型中。
一、基本概念由于定性变量通常表示的是某种特征的有和无,所以量化方法可采用取值为1或0。
这种变量称作虚拟变量(dummy variable )。
虚拟变量也称:哑元变量、定性变量等等。
通常用字母D 或DUM 加以表示(英文中虚拟或者哑元Dummy 的缩写)。
用1表示具有某一“品质”或属性,用0表示不具有该“品质”或属性。
虚拟变量使得我们可以将那些无法定量化的变量引入回归模型中。
虚拟变量应用于模型中,对其回归系数的估计与检验方法和定量变量相同。
虚拟变量表示两分性质,即“是”或“否”,“男”或“女”等。
下面给出几个可以引入虚拟变量的例子。
例1:你在研究学历和收入之间的关系,在你的样本中,既有女性又有男性,你打算研究在此关系中,性别是否会导致差别。
例2:你在研究某省家庭收入和支出的关系,采集的样本中既包括农村家庭,又包括城镇家庭,你打算研究二者的差别。
例3:你在研究通货膨胀的决定因素,在你的观测期中,有些年份政府实行了一项收入政策。
你想检验该政策是否对通货膨胀产生影响。
上述各例都可以用两种方法来解决,一种解决方法是分别进行两类情况的回归,然后看参数是否不同。
另一种方法是用全部观测值作单一回归,将定性因素的影响用虚拟变量引入模型。
二、虚拟变量设置规则虚拟变量的设置规则涉及三个方面: 1.“0”和“1”选取原则虚拟变量取“1”或“0”的原则,应从分析问题的目的出发予以界定。
从理论上讲,虚拟变量取“0”值通常代表比较的基础类型;而虚拟变量取“1”值通常代表被比较的类型。
“0”代表基期(比较的基础,参照物);“1”代表报告期(被比较的效应)。
例如,比较收入时考察性别的作用。
当研究男性收入是否高于女性时,是将女性作为比较的基础(参照物),故有男性为“1”,女性为“0”。
2.属性(状态、水平)因素与设置虚拟变量数量的关系定性因素的属性既可能为两种状态,也可能为多种状态。
例如,性别(男、女两种)、季节(4种状态),地理位置(东、中、西部),行业归属,所有制,收入的分组等。
虚拟变量数量的设置规则 1.若定性因素具有 m (m ≥2) 个相互排斥属性(或几个水平),当回归模型有截距项时,只能引入m 个虚拟变量;2.当回归模型无截距项时,则可引入m 个虚拟变量;否则,就会陷入“虚拟变量陷阱”。
(0,1) (0,0)D D ⎧⎪⎨⎪⎩12(1,0)天气阴如:(,)=天气雨其 他例 (虚拟变量陷阱)研究居民住房消费支出 和居民可支配收入x i 之间的数量关系。
回归模型的设定为: 现在要考虑城镇居民和农村居民之间的差异,如何办? 为了对 “城镇居民”、“农村居民”进行区分,分析各自在住房消费支出 上的差异,设 为城镇; 为农村。
,则模型为(模型有截距,“居民属性”定性变量只有两个相互排斥的属性状态( m=2),故只设定一个虚拟变量。
)若对两个相互排斥的 “居民属性” ,引入m=2个虚拟变量,则有则模型(1)为则对任一家庭都有: D 1+D 2=1即产生完全共线,陷入了“虚拟变量陷阱”。
“虚拟变量陷阱”的实质是:完全多重共线性。
第二节 虚拟解释变量的回归在计量经济学中,通常引入虚拟变量的方式分为加法方式和乘法方式两种:即原模型实质:加法方式引入虚拟变量改变的是截距;乘法方式引入虚拟变量改变的是斜率。
一、加法类型(1)一个两种属性定性解释变量而无定量变量的情形011i i i Y =+X +u αβ()i Y 1=1i D 1=0iD 01112i i i Y =+X +D +u αβα()Dependent Variable: Y Method: Least SquaresDate: 11/23/11 Time: 22:19Sample: 1 10Included observations: 10VariableCoefficientStd. Error t-StatisticProb. C 18.00000 0.31176957.735030.0000D 3.2800000.440908 7.4391910.0001R-squared 0.873701 Mean dependent var 19.6400Adjusted R-squared0.857913S.D. dependent var 1.849444S.E. of regression0.697137 Akaike info criterion 2.293187Sum squared resid3.888000 Schwarz criterion 2.353704Log likelihood -9.465934 F-statistic55.34156Durbin-Watso n stat0.667284Prob(F-statistic)0.000073Yi = 18 + 3.28 Di(2)包含一个定量变量,一个定性变量模型设有模型,女教授 男教授y t = β0 + β1 x t + β2D + u t ,其中y t ,x t 为定量变量;D 为定性变量。
当D = 0 或1时,上述模型可表达为,β0 + β1x t + u t , (D = 0) y t = (β0 + β2) + β1x t + u t , (D = 1)0204060204060X YD = 1或0表示某种特征的有无。
反映在数学上是截距不同的两个函数。
若β2显著不为零,说明截距不同;若β2为零,说明这种分类无显著性差异。
例:中国成年人体重y (kg )与身高x (cm )的回归关系如下: –105 + x D = 1 (男) y = - 100 + x - 5D =– 100 + x D = 0 (女) 注意:① 关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果。
但解释模型时一定注意1,0是怎样分配的。
②定性变量中取值为0所对应的类别称作基础类别(base category )。
③ 对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。
如:1 (大学) D = 0 (中学) -1 (小学)。
(3)一个定性解释变量(两种以上属性)和一个定量解释变量的情形(4)两个定性解释变量(均为两种属性)和一个定量解释变量的情形例:研究大学教师的年薪是否受到性别、学历的影响。
性别和学历是两个不同的标准。
按性别标准教师可以分成男、女两类,应该引入一个虚拟变量;按学历标准大学教师可以分为大学本科学历、硕士学历、博士学历三类,应该引入两个虚拟变量,共引入三个虚拟变量:令Y 代表年薪, X 代表教龄,建立模型:可以看出基准类是本科女教师,B0为刚参加工作的本科女教师的工资;B1为参加工作时间对工资的影响;B2是性别差异系数;B3和B4为学历差异系数,B3是硕士学历与本科学历的收入差异,B4是博士学历与本科学历的收入差异;通过上述分析,我们可以确定Bi 的符号。
在这个问题中,一共有六个类别,但是我们只引入了三个虚拟变量,而不是五个。
在就多个标准引入虚拟变量时,应该注意每一标准下引入虚拟变量个数应该是这一标准下类别数目减一,所以我们在本例中只引入三个虚拟变量而不是五个。
如果引入五个虚拟变ii i i i i u D B D B D B X B B Y +++++=44332210量就会陷入虚拟变量陷阱。
运用OLS 得到回归结果,再用t 检验讨论因素 是否对模型有影响。
加法方式引入虚拟变量的主要作用为: 1.在有定量解释变量的情形下,主要改变方程截距; 2.在没有定量解释变量的情形下,主要用于方 差分析。
二、乘法类型 基本思想以乘法方式引入虚拟变量时,是在所设立的模型中,将虚拟解释变量与其它解释变量的乘积,作为新的解释变量出现在模型中,以达到其调整设定模型斜率系数的目的。
或者将模型斜率系数表示为虚拟变量的函数,以达到相同的目的。
乘法引入方式:(1)截距不变;(2)截距和斜率均发生变化; 分析手段:仍然是条件期望。
以上只考虑定性变量影响截距,未考虑影响斜率,即回归系数的变化。
当需要考虑时,可建立如下模型:y t = β0 + β1 x t + β2 D + β3 x t D + u t ,其中x t 为定量变量;D 为定性变量。
当D = 0 或1时,上述模型可表达为,β0 + β2 ) + (β1 + β3)x t + u t , (D = 1) y t =β0 + β1 x t + u t , (D = 0) 通过检验 β3是否为零,可判断模型斜率是否发生变化。
020406080100204060X Y010203040506070204060T Y情形1(不同类别数据的截距和斜率不同) 情形2(不同类别数据的截距和斜率不同)例:用虚拟变量区别不同历史时期(file:dummy2)中国进出口贸易总额数据(1950-1984)见下表。
试检验改革前后该时间序列的斜率是否发生变化。
定义虚拟变量D 如下0 (1950 - 1977)D =1 (1978 - 1984)中国进出口贸易总额数据(1950-1984)(单位:百亿元人民币)年trade time D time D年trade timeD timeD1950 0.415 1 0 0 1968 1.085 19 0 01951 0.595 2 0 0 1969 1.069 20 0 01952 0.646 3 0 0 1970 1.129 21 0 01953 0.809 4 0 0 1971 1.209 22 0 01954 0.847 5 0 0 1972 1.469 23 0 01955 1.098 6 0 0 1973 2.205 24 0 01956 1.087 7 0 0 1974 2.923 25 0 01957 1.045 8 0 0 1975 2.904 26 0 01958 1.287 9 0 0 1976 2.641 27 0 01959 1.493 10 0 0 1977 2.725 28 0 01960 1.284 11 0 0 1978 3.550 29 1 291961 0.908 12 0 0 1979 4.546 30 1 301962 0.809 13 0 0 1980 5.638 31 1 311963 0.857 14 0 0 1981 7.353 32 1 321964 0.975 15 0 0 1982 7.713 33 1 331965 1.184 16 0 0 1983 8.601 34 1 341966 1.271 17 0 0 1984 12.010 35 1 351967 1.122 18 0 0以时间time为解释变量,进出口贸易总额用trade表示,估计结果如下:trade = 0.37 + 0.066 time - 33.96D + 1.20 time D(1.86) (5.53) (-10.98) (12.42)0.37 + 0.066 time (D = 0, 1950 - 1977)=- 33.59 + 1.27 time(D = 1, 1978 - 1984) 上式说明,改革前后无论截距和斜率都发生了变化。