Boosting算法简介
- 格式:doc
- 大小:394.00 KB
- 文档页数:10

adaboost算法参数摘要:1.简介2.AdaBoost 算法原理3.AdaBoost 算法关键参数4.参数调整策略与技巧5.总结正文:1.简介AdaBoost(Adaptive Boosting)算法是一种自适应提升算法,由Yoav Freund 和Robert Schapire 于1995 年提出。
它通过组合多个弱学习器(决策树、SVM 等)来构建一个更强大的学习器,从而提高分类和回归任务的性能。
2.AdaBoost 算法原理AdaBoost 算法基于加权训练样本的概念,每次迭代过程中,算法会根据当前学习器的性能调整样本的权重。
在弱学习器训练过程中,权重大的样本被优先考虑,以达到优化学习器的目的。
3.AdaBoost 算法关键参数AdaBoost 算法有以下几个关键参数:- n_estimators:弱学习器的数量,影响模型的复杂度和性能。
- learning_rate:加权系数,控制每次迭代时样本权重更新的幅度。
- max_depth:决策树的深度,限制模型复杂度,防止过拟合。
- min_samples_split:决策树分裂所需的最小样本数,防止过拟合。
- min_samples_leaf:决策树叶节点所需的最小样本数,防止过拟合。
4.参数调整策略与技巧- 对于分类问题,可以先从较小的n_estimators 值开始,逐步增加以找到最佳组合。
- learning_rate 的选择需要平衡模型的拟合能力和泛化性能,可以采用网格搜索法寻找最佳值。
- 可以通过交叉验证来评估模型性能,从而确定合适的参数组合。
5.总结AdaBoost 算法是一种具有很高实用价值的集成学习方法,通过调整关键参数,可以有效地提高分类和回归任务的性能。

adaboostclassifier()介绍摘要:1.AdaBoost 简介2.AdaBoost 算法原理3.AdaBoost 应用实例4.AdaBoost 优缺点正文:1.AdaBoost 简介AdaBoost(Adaptive Boosting)是一种自适应的集成学习算法,主要用于解决分类和回归问题。
它通过组合多个基本分类器(弱学习器)来提高预测性能,可以有效地解决单个分类器准确率不高的问题。
AdaBoost 算法在机器学习领域被广泛应用,尤其是在图像识别、文本分类等任务中取得了很好的效果。
2.AdaBoost 算法原理AdaBoost 算法的核心思想是加权训练样本和加权弱学习器。
在每一轮迭代过程中,算法会根据样本的权重来调整训练样本,使得错误分类的样本在下一轮中拥有更高的权重。
同时,算法会根据弱学习器的权重来调整弱学习器的重要性,使得表现更好的弱学习器在下一轮中拥有更高的权重。
这个过程会一直进行,直到达到预设的迭代次数。
具体来说,AdaBoost 算法包括以下步骤:(1) 初始化:设置初始权重,通常为等权重。
(2) 迭代:a.根据样本权重,对训练样本进行加权抽样。
b.训练弱学习器,得到弱学习器的预测结果。
c.更新样本权重,将错误分类的样本权重增加,正确分类的样本权重减小。
d.更新弱学习器权重,将表现更好的弱学习器权重增加,表现较差的弱学习器权重减小。
(3) 终止条件:达到预设的迭代次数或满足其他终止条件。
(4) 集成:将多个弱学习器进行集成,得到最终的预测结果。
3.AdaBoost 应用实例AdaBoost 算法在许多领域都有广泛应用,例如:(1) 图像识别:在计算机视觉领域,AdaBoost 算法被广泛应用于图像识别任务,尤其是人脸识别、车牌识别等。
(2) 文本分类:在自然语言处理领域,AdaBoost 算法可以用于文本分类任务,例如情感分析、垃圾邮件过滤等。
(3) 语音识别:在语音识别领域,AdaBoost 算法可以用于声学模型的训练,提高语音识别的准确率。
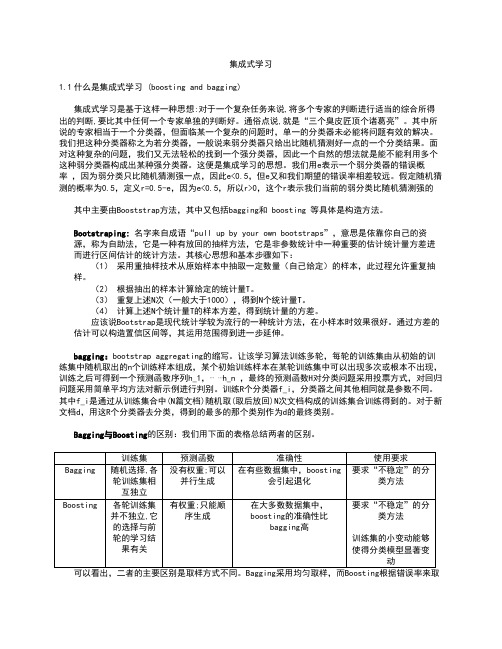
集成式学习1.1什么是集成式学习 (boosting and bagging)集成式学习是基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。
通俗点说,就是“三个臭皮匠顶个诸葛亮”。
其中所说的专家相当于一个分类器,但面临某一个复杂的问题时,单一的分类器未必能将问题有效的解决。
我们把这种分类器称之为若分类器,一般说来弱分类器只给出比随机猜测好一点的一个分类结果。
面对这种复杂的问题,我们又无法轻松的找到一个强分类器,因此一个自然的想法就是能不能利用多个这种弱分类器构成出某种强分类器。
这便是集成学习的思想。
我们用e表示一个弱分类器的错误概率,因为弱分类只比随机猜测强一点,因此e<0.5,但e又和我们期望的错误率相差较远。
假定随机猜测的概率为0.5,定义r=0.5-e,因为e<0.5,所以r>0,这个r表示我们当前的弱分类比随机猜测强的其中主要由Booststrap方法,其中又包括bagging和boosting 等具体是构造方法。
Bootstraping:名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法。
其核心思想和基本步骤如下:(1)采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样。
(2)根据抽出的样本计算给定的统计量T。
(3)重复上述N次(一般大于1000),得到N个统计量T。
(4)计算上述N个统计量T的样本方差,得到统计量的方差。
应该说Bootstrap是现代统计学较为流行的一种统计方法,在小样本时效果很好。
通过方差的估计可以构造置信区间等,其运用范围得到进一步延伸。
bagging:bootstrap aggregating的缩写。

集成学习之Boosting——GradientBoosting原理集成学习之Boosting —— Gradient Boosting原理上⼀篇介绍了AdaBoost算法,AdaBoost每⼀轮基学习器训练过后都会更新样本权重,再训练下⼀个学习器,最后将所有的基学习器加权组合。
AdaBoost使⽤的是指数损失,这个损失函数的缺点是对于异常点⾮常敏感,(关于各种损失函数可见之前的⽂章:),因⽽通常在噪⾳⽐较多的数据集上表现不佳。
Gradient Boosting在这⽅⾯进⾏了改进,使得可以使⽤任何损失函数 (只要损失函数是连续可导的),这样⼀些⽐较robust的损失函数就能得以应⽤,使模型抗噪⾳能⼒更强。
Boosting的基本思想是通过某种⽅式使得每⼀轮基学习器在训练过程中更加关注上⼀轮学习错误的样本,区别在于是采⽤何种⽅式?AdaBoost采⽤的是增加上⼀轮学习错误样本的权重的策略,⽽在Gradient Boosting中则将负梯度作为上⼀轮基学习器犯错的衡量指标,在下⼀轮学习中通过拟合负梯度来纠正上⼀轮犯的错误。
这⾥的关键问题是:为什么通过拟合负梯度就能纠正上⼀轮的错误了?Gradient Boosting的发明者给出的答案是:函数空间的梯度下降。
函数空间的的梯度下降这⾥⾸先回顾⼀下梯度下降 (Gradient Descend)。
机器学习的⼀⼤主要步骤是通过优化⽅法最⼩化损失函数L(θ),进⽽求出对应的参数θ。
梯度下降是经典的数值优化⽅法,其参数更新公式:θ=θ−α⋅∂∂θL(θ)Gradient Boosting 采⽤和AdaBoost同样的加法模型,在第m次迭代中,前m-1个基学习器都是固定的,即f m(x)=f m−1(x)+ρm h m(x)因⽽在第m步我们的⽬标是最⼩化损失函数L(f)=N∑i=1L(y i,f m(x i)),进⽽求得相应的基学习器。
若将f(x)当成参数,则同样可以使⽤梯度下降法:f m(x)=f m−1(x)−ρm⋅∂∂f m−1(x)L(y,f m−1(x))对⽐式 (1.2)和 (1.3),可以发现若将h m(x)≈−∂L(y,f m−1(x))∂f m−1(x),即⽤基学习器h m(x)拟合前⼀轮模型损失函数的负梯度,就是通过梯度下降法最⼩化L(f) 。

一种自适应的多类Boosting分类算法王世勋;潘鹏;陈灯;卢炎生【期刊名称】《计算机科学》【年(卷),期】2017(044)007【摘要】Many practical problems have involved classification technology which can effectively reduce the comprehension difference between users and computers.In the traditional multiclass Boosting methods,multiclass loss function does not necessarily have guess-aversion,and the combinations of multiclass weak learners are confined to linear weighted sum.To get a final classifier with high accuracy,multiclass loss function need contain three main properties,namely margin maximization,Bayes consistency and guess-aversion.Moreover,the weakness of weak learners may limit the performance of linear classifier,but their nonlinear combinations should provide strong discrimination.Therefore,we designed an adaptive multiclass Boosting classifier,namely SOHPBoost algorithm.At every iteration,our algorithm can add the best weak learner to the current ensemble according to vector addition or Hadamard product.This adaptive process can create the sum of Hadamard products of weak learners,and mine the hidden structure of dataset.The experi-ments show that SOHPBoost algorithm can provide more advantageous performance of multiclass classification.%许多实际问题涉及到多分类技术,该技术能有效地缩小用户与计算机之间的理解差异.在传统的多类Boosting方法中,多类损耗函数未必具有猜测背离性,并且多类弱学习器的结合被限制为线性的加权和.为了获得高精度的最终分类器,多类损耗函数应具有多类边缘极大化、贝叶斯一致性与猜测背离性.此外,弱学习器的缺点可能会限制线性分类器的性能,但它们的非线性结合可以提供较强的判别力.根据这两个观点,设计了一个自适应的多类Boosting分类器,即SOHPBoost算法.在每次迭代中,SOHPBoost算法能够利用向量加法或Hadamard乘积来集成最优的多类弱学习器.这个自适应的过程可以产生多类弱学习的Hadamard乘积向量和,进而挖掘出数据集的隐藏结构.实验结果表明,SOHPBoost算法可以产生较好的多分类性能.【总页数】6页(P185-190)【作者】王世勋;潘鹏;陈灯;卢炎生【作者单位】河南师范大学计算机与信息工程学院新乡453007;华中科技大学计算机科学与技术学院武汉430074;武汉工程大学智能机器人湖北省重点实验室武汉430205;华中科技大学计算机科学与技术学院武汉430074【正文语种】中文【中图分类】TP181【相关文献】1.一种半监督的多标签Boosting分类算法 [J], 赵晨阳;佀洁2.一种逆向样本分布的Boosting类新算法 [J], 高敬阳;陈程立诏;朱群雄3.基于Boosting的迭代加权集成分类算法 [J], 杜诗语;韩萌;申明尧;张春砚;孙蕊4.基于Boosting的深度学习图像分类算法设计 [J], 王志强;王先传5.一种基于Adaboost.M1的车型分类算法 [J], 卞建勇;徐建闽;杨洋;朱彩莲因版权原因,仅展示原文概要,查看原文内容请购买。

gradientboostingregressor原理Gradient Boosting Regressor是一种机器学习算法,属于集成学习方法中的增强学习(Boosting)算法。
本文将详细介绍Gradient Boosting Regressor的原理,从基本概念出发,一步一步回答关于这一算法的问题。
1. 什么是Gradient Boosting Regressor?Gradient Boosting Regressor是一种用于回归问题的机器学习算法。
它是以决策树为基分类器的增强学习算法。
该算法通过迭代地训练一系列决策树,每棵树都尝试纠正前一棵树的预测结果,最终获得更准确的预测模型。
2. Gradient Boosting Regressor的基本原理是什么?Gradient Boosting Regressor的基本原理是通过梯度下降法来最小化损失函数。
当损失函数对于当前模型的预测结果的梯度(gradient)为零时,说明当前模型的预测结果已经达到最佳,此时算法停止迭代。
算法的目标是找到使损失函数达到最小的预测模型。
3. Gradient Boosting Regressor的训练过程是怎样的?Gradient Boosting Regressor的训练过程分为多个阶段,每个阶段都训练一棵决策树。
首先,初始化模型为一个常数值,通常是训练集样本目标值的平均值。
然后,依次迭代每个阶段,每个阶段都要计算残差(target值与当前模型预测值之差),并将残差作为下一棵决策树的训练目标。
4. 每棵决策树如何拟合数据?每棵决策树的拟合过程可以看做是一个回归问题。
目标是寻找一个函数,能够最小化残差的平方和。
通常使用最小二乘法或最小平方残差法,通过选择每个决策树的分裂节点和划分规则,来最小化残差。
5. Gradient Boosting Regressor中如何纠正前一棵树的预测结果?在每个阶段,当前训练的决策树需要尝试纠正前一棵树的预测结果。
boosting算法建模流程English Answer:Boosting Algorithm Modeling Process.Boosting is a powerful machine learning technique that involves constructing a strong learner by combiningmultiple weak learners. The process of building a boosting model involves the following key steps:1. Initialize weights: Assign equal weights to all training data instances.2. Train a weak learner: Create a weak learner (e.g., a shallow decision tree) using the weighted training data.3. Calculate the weighted error: Determine the weighted error rate of the weak learner.4. Adjust weights: Increase the weights of instancesthat were misclassified by the weak learner, and decrease the weights of instances that were correctly classified.5. Normalize weights: Normalize the weights to ensure they sum to one.6. Repeat steps 2-5: Repeat the process of training a weak learner, calculating the error, and adjusting weights for a specified number of iterations.7. Create a strong learner: Combine the outputs of the weak learners to produce a weighted vote for the final classification or regression prediction.Types of Boosting Algorithms:AdaBoost (Adaptive Boosting): Focuses on boosting the instances that are harder to classify correctly.Gradient Boosting: Builds a sequence of weak learners, where each subsequent learner aims to minimize the loss of the previous learners.XGBoost (Extreme Gradient Boosting): An efficient implementation of gradient boosting that includes several optimizations for speed and accuracy.Advantages of Boosting:Improves accuracy by combining multiple weak learners.Can handle complex and nonlinear datasets.Provides an ensemble model that can generalize well to unseen data.Can be applied to both classification and regression tasks.Disadvantages of Boosting:Can be computationally expensive for large datasets.May suffer from overfitting if too many weak learnersare used.Can be sensitive to noisy data.中文回答:Boosting算法建模流程。
基于 AdaBoost 算法对海上失事船只的识别与定位屈 哲,姚行中,满芳芳(第二炮兵指挥学院 湖北 武汉 430012)摘 要:海上失事船只的识别与定位是军事应用中的重点、难点。
本文将 AdaBoost 算法应用于海上船舰移动目标 的识别与定位,基于 Harrtraining 对样本集进行特征提取,训练然后进行检测。
研究实例表明了算法的有效性。
关键词:遥感图像,AdaB oost 算法,目标识别,类 Harr 特征中图分类号:TP391.44 文献标识码:A 文章编号:1006-7973(2008)11-0115-02一、引言利用卫星等拍摄的遥感图像来实施对地面及海上目标的 监测与侦察是现代侦察技术的主要手段之一。
然而,如何从 海量的卫星图像中识别定位所期望的目标却是一个难题,目 前所采用的人工判读法存在着致命的弊端:工作量巨大导致 实时性差。
世界许多国家都在积极研究自动目标识别 (Automatic target recognition ,ATR )技术[1-3]。
但由于 海上目标的多样性及及周边环境的复杂性,其识别技术一直 是模式识别领域中的难点。
为了解决人眼识别海量卫星遥感图像的问题,减少了侦察人员的工作强度,为海上侦察增加了自动监测海上舰船目 标的功能,并能更加快速、有效地发现海上目标从而及时采 取相应措施,本文将 AdaBoost [4]算法应用于海上失事船只的识别与定位,以加快搜救时间为目的。
二、AdaBoost 算法简介Boosting 算法的思想起源于 Valiantlsl 提出的计算学 习理论-PAC (Probably Approximately Correct :概率近 似正确)学习模型。
PAC 是统计机器学习、集成机器学习等 方法的理论基础。
它是一种提高任意给定弱分类器的分类精 度的通用方法。
在众多 Boosting 算法中, Freund 和 Schapire 提出 的 AdaBoost [4] (Adaptive Boosting )最具实用价值, 它 较之早期 Boosting 算法具有以下优点:(1)它的最终判别 准则的精确度是依赖所有弱学习过程得出的弱假设值,因而 更能全面地挖掘弱学习算法的能力。
gradientboostingclassifier 梯度提升算法的原理摘要:一、梯度提升算法简介1.梯度提升算法定义2.算法原理简述二、梯度提升算法的核心思想1.弱学习器组合2.梯度下降优化3.加权训练样本三、梯度提升算法的应用场景1.数据不平衡问题2.特征选择3.模型可解释性四、梯度提升算法的优缺点1.优点a.强适应性b.无需特征选择c.可扩展性2.缺点a.计算复杂度高b.过拟合风险c.弱学习器选择困难正文:梯度提升算法(Gradient Boosting Classifier)是一种集成学习方法,通过组合多个弱学习器来提高预测性能。
该算法广泛应用于数据挖掘、机器学习和其他领域的分类问题。
接下来,我们将详细探讨梯度提升算法的原理、核心思想、应用场景及优缺点。
一、梯度提升算法简介梯度提升算法是一种基于梯度下降优化的集成学习方法。
其主要思想是通过加权训练样本不断迭代训练弱学习器,最终得到一个强大的集成学习模型。
二、梯度提升算法的核心思想1.弱学习器组合:梯度提升算法通过组合多个弱学习器来提高模型的预测性能。
这些弱学习器通常采用决策树、回归树等易于训练的模型。
2.梯度下降优化:梯度提升算法使用梯度下降优化策略来更新弱学习器的权重。
通过加权训练样本,算法可以更关注难以分类的样本,提高模型性能。
3.加权训练样本:梯度提升算法根据弱学习器的预测结果为训练样本分配权重。
预测正确的样本权重降低,而预测错误的样本权重增加,从而使模型更关注难以分类的样本。
三、梯度提升算法的应用场景1.数据不平衡问题:梯度提升算法可以有效地处理数据不平衡问题,提高模型在少数类样本上的预测性能。
2.特征选择:梯度提升算法可以自动选择对分类有用的特征,减少特征选择的工作量。
3.模型可解释性:由于梯度提升算法采用决策树作为弱学习器,因此具有较好的模型可解释性。
四、梯度提升算法的优缺点1.优点a.强适应性:梯度提升算法对数据分布和特征选择具有较强的适应性。
Boosting算法简介
2011-01-18 09:01:20
http://baidutech.blog.51cto.com/4114344/743809
一、Boosting算法的发展历史
Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生
之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrapping
方法和bagging方法。我们先简要介绍一下bootstrapping方法和bagging方法。
1)bootstrapping方法的主要过程
主要步骤:
i)重复地从一个样本集合D中采样n个样本
ii)针对每次采样的子样本集,进行统计学习,获得假设Hi
iii)将若干个假设进行组合,形成最终的假设Hfinal
iv)将最终的假设用于具体的分类任务
2)bagging方法的主要过程
主要思路:
i)训练分类器
从整体样本集合中,抽样n* < N个样本 针对抽样的集合训练分类器Ci
ii)分类器进行投票,最终的结果是分类器投票的优胜结果
但是,上述这两种方法,都只是将分类器进行简单的组合,实际上,并没有发挥出分类
器组合的威力来。直到1989年,Yoav Freund与 Robert Schapire提出了一种可行的将弱
分类器组合为强分类器的方法。并由此而获得了2003年的哥德尔奖(Godel price)。
Schapire还提出了一种早期的boosting算法,其主要过程如下:
i)从样本整体集合D中,不放回的随机抽样n1 < n 个样本,得到集合 D1
训练弱分类器C1
ii)从样本整体集合D中,抽取 n2 < n 个样本,其中合并进一半被 C1 分类错误的
样本。得到样本集合 D2
训练弱分类器C2
iii)抽取D样本集合中,C1 和 C2 分类不一致样本,组成D3
训练弱分类器C3
iv)用三个分类器做投票,得到最后分类结果
到了1995年,Freund and schapire提出了现在的adaboost算法,其主要框架可以描
述为:
i)循环迭代多次
更新样本分布
寻找当前分布下的最优弱分类器
计算弱分类器误差率
ii)聚合多次训练的弱分类器
在下图中可以看到完整的adaboost算法:
图1.1 adaboost算法过程
现在,boost算法有了很大的发展,出现了很多的其他boost算法,例如:logitboost
算法,gentleboost算法等等。在这次报告中,我们将着重介绍adaboost算法的过程和特
性。
二、Adaboost算法及分析
从图1.1中,我们可以看到adaboost的一个详细的算法过程。Adaboost是一种比较有
特点的算法,可以总结如下:
1)每次迭代改变的是样本的分布,而不是重复采样(re weight)
2)样本分布的改变取决于样本是否被正确分类
总是分类正确的样本权值低
总是分类错误的样本权值高(通常是边界附近的样本)
3)最终的结果是弱分类器的加权组合
权值表示该弱分类器的性能
简单来说,Adaboost有很多优点:
1)adaboost是一种有很高精度的分类器
2)可以使用各种方法构建子分类器,adaboost算法提供的是框架
3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单
4)简单,不用做特征筛选
5)不用担心overfitting!
总之:adaboost是简单,有效。
下面我们举一个简单的例子来看看adaboost的实现过程:
图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线
作为分类器,来进行分类。
第一步:
根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1
其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
第二步:
根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:
得到一个子分类器h3
整合所有子分类器:
因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的
分类效果,在例子中所有的。
Adaboost算法的某些特性是非常好的,在我们的报告中,主要介绍adaboost的两个特
性。一是训练的错误率上界,随着迭代次数的增加,会逐渐下降;二是adaboost算法即使
训练次数很多,也不会出现过拟合的问题。
下面主要通过证明过程和图表来描述这两个特性:
1)错误率上界下降的特性
从而可以看出,随着迭代次数的增加,实际上错误率上界在下降。
2)不会出现过拟合现象
通常,过拟合现象指的是下图描述的这种现象,即随着模型训练误差的下降,实际上,
模型的泛化误差(测试误差)在上升。横轴表示迭代的次数,纵轴表示训练误差的值。
而实际上,并没有观察到adaboost算法出现这样的情况,即当训练误差小到一定程度以后,
继续训练,返回误差仍然不会增加。
对这种现象的解释,要借助margin的概念,其中margin表示如下:
通过引入margin的概念,我们可以观察到下图所出现的现象:
从图上左边的子图可以看到,随着训练次数的增加,test的误差率并没有升高,同时
对应着右边的子图可以看到,随着训练次数的增加,margin一直在增加。这就是说,在训
练误差下降到一定程度以后,更多的训练,会增加分类器的分类margin,这个过程也能够
防止测试误差的上升。
三、多分类adaboost
在日常任务中,我们通常需要去解决多分类的问题。而前面的介绍中,adaboost算法
只能适用于二分类的情况。因此,在这一小节中,我们着重介绍如何将adaboost算法调整
到适合处理多分类任务的方法。
目前有三种比较常用的将二分类adaboost方法。
1、adaboost M1方法
主要思路: adaboost组合的若干个弱分类器本身就是多分类的分类器。
在训练的时候,样本权重空间的计算方法,仍然为:
在解码的时候,选择一个最有可能的分类
2、adaboost MH方法
主要思路: 组合的弱分类器仍然是二分类的分类器,将分类label和分类样例组合,
生成N个样本,在这个新的样本空间上训练分类器。
可以用下图来表示其原理:
3、对多分类输出进行二进制编码
主要思路:对N个label进行二进制编码,例如用m位二进制数表示一个label。然后
训练m个二分类分类器,在解码时生成m位的二进制数。从而对应到一个label上。
四、总结
最后,我们可以总结下adaboost算法的一些实际可以使用的场景:
1)用于二分类或多分类的应用场景
2)用于做分类任务的baseline
无脑化,简单,不会overfitting,不用调分类器
3)用于特征选择(feature selection)
4)Boosting框架用于对badcase的修正
只需要增加新的分类器,不需要变动原有分类器
由于adaboost算法是一种实现简单,应用也很简单的算法。Adaboost算法通过组合弱
分类器而得到强分类器,同时具有分类错误率上界随着训练增加而稳定下降,不会过拟合等
的性质,应该说是一种很适合于在各种分类场景下应用的算法。