交叉汇总与关联分析Crosstabs的应用
- 格式:doc
- 大小:266.50 KB
- 文档页数:15


Kappa值的应用:交叉表分析(Crosstabs,Cross-tabulation,列联表分析)可计算Kappa(Cohen κ系数),此外诊断一致性检验还可以选用两相关样本非参数检验(Two-Related-Samples Test)中的McNemar检验(McNemar Test)(用于二分数据)和边际同质性检验(Marginal Homogeneity Test)(用于非二分数据)。
此外,向你推荐一本书:电子工业出版社出版的《PASW/SPSS Statistics中文版统计分析教程(第3版)(含CD光盘1张)》,该书有不少医学例子。
(如:Kappa系数,在列联表分析中评价一致性(agreement)程度的指标,适用于行与列有相同的分类,分为未加权和加权两种。
例:共40例数据,A和B两个观察者判断其结果阴性或者阳性,分析A与B判断的一致性。
据我说知,一般用于2人评价的契合度,若是3人及以上高维的数据很少见,可以考虑分别每次2人的对比,当然这样会引入误差。
)。

交叉分析法怎么分析交叉分析法是一种常用的数据分析方法,通过对不同因素之间的关系进行交叉比较和分析,帮助研究者发现变量之间的联系和差异。
本文将介绍交叉分析法的基本概念和步骤,并以具体案例进行说明。
一、交叉分析法概述交叉分析法(Cross-Tabulation Analysis)也被称为列联表分析(Contingency Table Analysis),是一种定量分析方法,用来研究两个或更多变量之间的关系。
通过构建列联表,对不同变量之间的交叉频数进行统计和比较,可以揭示变量之间的关联性和差异性。
二、交叉分析法步骤1. 确定研究问题:明确研究问题并选择需要分析的变量。
例如,假设我们想研究消费者对不同手机品牌的偏好与性别之间的关系。
2. 构建列联表:根据所研究的变量,构建列联表(也称为交叉表)。
横列为一个变量的不同水平(例如手机品牌),纵列为另一个变量的不同水平(例如性别)。
在交叉点上填写交叉频数。
3. 计算频数和比例:根据列联表,计算每个交叉点上的频数和比例。
频数表示各组别的数量,比例表示各组别所占比例。
4. 绘制图表:通过绘制图表,直观地展示不同变量之间的关系。
常用的图表包括堆叠柱状图、簇状柱状图、饼图等。
5. 进行统计检验:为了验证变量之间的关系是否显著,可以进行统计检验,如卡方检验。
卡方检验可以检验各组别之间的差异是否由随机因素引起。
6. 分析结果和讨论:根据交叉分析的结果,进行结果分析和讨论。
解释变量之间的关系和差异,并提出合理的解释和解决方案。
三、交叉分析方法案例以消费者对不同手机品牌的偏好与性别之间的关系为例,进行交叉分析。
我们调查了300名消费者,结果如下表所示:--------------------------------------------------| Apple | Samsung | Huawei | Others--------------------------------------------------男性 | 50 | 30 | 20 | 10--------------------------------------------------女性 | 20 | 40 | 50 | 20--------------------------------------------------根据上表,我们可以计算出各组别的频数和比例,如下所示:--------------------------------------------------| Apple | Samsung | Huawei | Others--------------------------------------------------男性 | 50 | 30 | 20 | 10--------------------------------------------------女性 | 20 | 40 | 50 | 20--------------------------------------------------| 70(23%) | 70(23%) | 70(23%) | 30(10%)--------------------------------------------------通过绘制堆叠柱状图,我们可以直观地看到不同手机品牌在不同性别中的偏好程度。


VBA中的数据透视表和交叉表的应用数据透视表和交叉表是VBA中非常有用的功能,可以帮助用户对数据进行分析和汇总。
在本文中,我将介绍如何使用VBA编写代码来创建、修改和操作数据透视表和交叉表。
首先,让我们来了解一下数据透视表和交叉表的定义和用途。
数据透视表是一种功能强大的数据分析工具,可用于快速总结和汇总大量数据。
它允许用户以不同的方式组织和展示数据,以便更好地理解数据的关系和趋势。
比如,我们可以通过透视表轻松地对销售数据进行汇总,以便了解哪个地区和哪个产品线的销售额最高。
交叉表是一种将数据以不同方式组织和显示的方法,通常用于数据的横向和纵向比较。
它将数据按照行和列分组,并在交叉点上进行分析。
例如,我们可以使用交叉表来比较不同销售人员的销售记录,以确定谁的业绩最好。
现在,让我们来看一些如何在VBA中使用数据透视表和交叉表的示例代码。
首先,我们需要创建一个数据透视表。
可以使用以下代码片段来创建一个新的数据透视表:```vbaSub CreatePivotTable()Dim ws As WorksheetDim rng As RangeDim pt As PivotTable'设置数据源范围Set ws = ThisWorkbook.Sheets("Sheet1")Set rng = ws.Range("A1:D10")'创建数据透视表Set pt = ws.PivotTableWizard(SourceType:=xlDatabase, SourceData:=rng, TableDestination:=ws.Range("F5"))End Sub```在上面的示例中,首先我们定义了一个工作表变量 `ws`,将其设置为需要创建数据透视表的工作表。
然后,我们定义一个 `rng`变量,并设置其为数据源范围。
接下来,我们使用`ws.PivotTableWizard` 方法创建了一个新的数据透视表,并将其放置在工作表的 F5 单元格中。


利用交叉分析进行市场数据关联交叉分析是一种常用的统计分析方法,也是市场研究中常用的一种技术手段。
它可以帮助我们分析市场数据之间的关联关系,并且通过对比不同维度数据的交叉组合,帮助我们发现市场中的一些隐含规律和趋势。
在本文中,我们将探讨交叉分析在市场数据关联方面的应用以及如何进行一次有效的交叉分析。
首先,我们需要明确研究的目的和问题。
在市场营销领域,交叉分析可以帮助我们探究不同变量之间的关系,例如产品销量与广告投放、消费者人群与购买行为等。
通过交叉分析,我们可以更好地理解市场中的细分群体,了解他们的需求和购买习惯,从而优化产品与服务的提供。
接下来,我们需要选择合适的数据集进行分析。
市场数据的种类繁多,包括销售数据、消费者调查数据、竞争对手数据等。
选择合适的数据集非常关键,数据集应当具有代表性,并且覆盖多个维度,以便我们能够进行综合的交叉分析。
在进行交叉分析之前,我们需要对数据进行预处理,以确保数据的准确性和一致性。
这包括数据清洗、数据整理和数据标准化等步骤。
例如,对于销售数据,我们需要处理缺失值、异常值和重复值,将数据转换为适合分析的形式,并确保不同数据源之间的单位一致。
接下来,我们可以利用适当的统计方法进行交叉分析。
常用的交叉分析方法包括卡方检验、相关系数分析和方差分析等。
这些方法可以帮助我们计算不同维度数据之间的相关性、差异性和影响程度。
在进行交叉分析时,我们需要根据具体的问题和研究目的选择合适的统计指标和分析工具。
例如,如果我们想要研究不同广告投放方式对产品销量的影响,可以使用方差分析来比较不同广告投放组别的销量差异是否显著。
而如果我们想要研究不同年龄段消费者的购买行为差异,可以使用卡方检验来比较不同年龄组别的购买偏好是否存在显著性差异。
进行交叉分析时,我们还需要注意样本大小和分组方式对结果的影响。
确保样本具有代表性,并且分组方式合理,以充分反映不同维度数据之间的关系。
同时,交叉分析结果的统计显著性并不代表因果关系,我们需要结合实际情况进行合理解读。
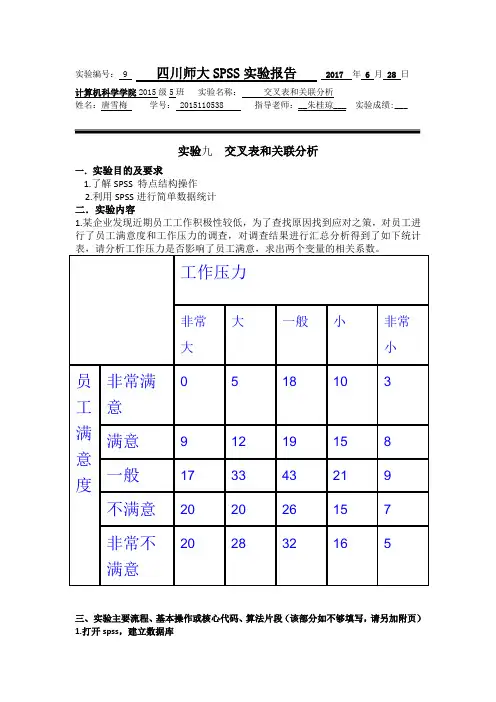
实验编号:9四川师大SPSS实验报告2017 年6 月28 日计算机科学学院2015级5班实验名称:交叉表和关联分析姓名:唐雪梅学号:2015110538 指导老师:__朱桂琼___ 实验成绩:___实验九交叉表和关联分析一.实验目的及要求1.了解SPSS 特点结构操作2.利用SPSS进行简单数据统计二.实验内容1.某企业发现近期员工工作积极性较低,为了查找原因找到应对之策,对员工进行了员工满意度和工作压力的调查,对调查结果进行汇总分析得到了如下统计三、实验主要流程、基本操作或核心代码、算法片段(该部分如不够填写,请另加附页)1.打开spss,建立数据库2.分析原假设:工作满意度和工作压力是独立的两个变量步骤:Analyze->Descriptive Statistics->Crosstabs选中Display clustered bar charts选项,在Statistics对话框中选择Chi-square选项,在Cells对话框中选择Observed、Expected选项。
3.结果分析皮尔逊卡方检验的Sig.=1,似然比卡方检验的Sig.=1,都大于0.05,应该接收原假设故认为工作满意度与工作压力之间没有关系。
线性关联检验的Sig.=1,大于0.05,表明两变量间不存在显著的线性关系。
四、实验结果的分析与评价(该部分如不够填写,请另加附页)1.交叉表(crosstabs):也称为交互表或列联表,主要用于定性变量进行统计描述和简单的统计推断,由行列组成。
其中行列分别对应定性变量。
列联表分析的主要任务有两个:(1)根据样本数据产生二维或多维交叉列联表。
(2)在交叉列联表的基础上,分析两变量之间是否具有独立性或一定的相关性。
2.为了理解列联表中行变量(Row)和列变量(Column)之间的关系,需要借助非参数检验方法。
通常采用的方法是卡方检验。
卡方检验主要包括的步骤:(1)建立原假设H0:行变量和列变量之间没有关系,或行变量和列变量相互独立。

天津市滨海新区2018-2020年三年中考二模英语试卷分类汇编阅读理解2021年天津市滨海新区九年级学业质量调查(二模)英语试题四、阅读理解(本大题共15小题,每小题2分,共30分)阅读下面的材料,从每小题所给的A、B、C、D四个选项中选出最佳选项。
(A)Dear editor,I am not a good-looking boy and I’m not good at studying, either. Some people don’t even want to talk to me. So I usually feel lonely. Sometimes I think if I want to leave home, nobody will care. How can I stop feeling like this?Peter Dear Peter,Without knowing more about you, it is hard for me to give you some good advice.But firstly, I am sure that it’s wro ng to think that nobody will care if you leave home. What about your parents? And other family members? It seems that you are very sad. You’d better go to see a doctor or talk to your parents. They will be able to help you.Secondly, I’m sure there must be someone in your class who feels lonely too. You never know how other people feel inside. Try to make friends with them.Or you can join a club to meet new people and keep yourself busy.Finally, you need to find happiness in yourself. Write a list of all the good things about yourself, learn to like yourself, and then others will see your confidence and like you, too.Editor46. What’s the trouble with Peter?A. He doesn’t like his parents.B. He doesn’t like others.C. His parents don’t like him.D. He isn’t good at studying and feels lonely.47. Why does Peter write to the editor?A. Because he wants to make friends with him.B. Because he wants to ask the editor to help him.C. Because he wants the editor to know about him.D. Because he wants to give the editor some advice.48. If Peter joins a club, he can _____.A. be a good-looking boyB. keep his friends busyC. study hard but never think about othersD. meet new people and make friends with them49. Peter will probably feel _____ when he reads the letter from the editor.A. happyB. lonelyC. sadD. afraid50. How many pieces of advice did the editor give to Peter?A. Two.B. Three.C. Four.D. Five.(B)At an early time, a paper ticket was necessary even for passengers who bought tickets online. But now people are saying goodbye to paper tickets.Passengers can swipe (刷) an ID card to pass through a gate before taking a high-speed train. This helps the railway operator (铁路运营公司) improve its e-ticket service.“It’s very convenient and fast,” said Wu Yuanzhen, a passenger from Guangxi. “I am a salesman and travel a lot by train. For us, time is money. E-tickets save time picking up (取票的时间) and improve travel efficiency (效率).”For passengers who need to change or return their tickets, they can change the tickets or get a refund (退款) through or the ticket office at the station.Since 2011, passengers have been able to swipe their ID cards at self-service machines (自助操作机) to take the Beijing-Tianjin high-speed railway and Beijing-Shanghai high-speed railway.Checking in (办理登乘手续) by swiping an ID card is now available (可用的) at high-speed railway stations in most big cities across China, especially in Guangzhou, Shenzhen and Wuhan. However, at stations in some remote areas, passengers still need a paper ticket to get on a train.51. Passengers have been able to swipe their ID cards to take the Beijing-Tianjin high-speedrailway since _____.A. 2011B. 2019C. 2020D. 202152. According to Paragraph 3, we know _____.A. Wu Yuanzhen is a teacherB. Wu Yuanzhen doesn’t like e-ticketsC. Wu Yuanzhen often needs to take a trainD. E-tickets cost less money than paper tickets53. Which of the following is NOT true about the e-ticket?A. It saves time picking up a ticket.B. It’s very convenient and fast.C. It improves travel efficiency.D. The price of an e-ticket is very high.54. What does the underlined word “remote” mean in Chinese?A. 繁华的B. 偏远的C. 移动的D. 发达的55. You may read the passage in _____.A. a health bookB. a newspaperC. a music bookD. a story book(C)Is the whale the world’s largest fish? No. It looks like a fish, but it is really a mammal (哺乳动物). Then what’s the world’s largest fish? It’s the whale shark (鲸鲨).Although the whale shark is the biggest fish and lives in many oceans around the world, few people have ever heard of it. Scientists have not been studying whale sharks for very long. Much more needs to be learned about them.A whale shark is sometimes called a “gentle giant (温柔的巨人)”. It likes to be alone and doesn’t care a bit about divers (潜水员) or humans. The biggest whale shark weighed 24, 250 pounds and was nearly 40 feet long. This makes it heavier and longer than a school bus.Inside its huge mouth are great numbers of very small teeth. To count all of them, you’ll need to do some maths. The whale shark’s teeth are in rows. There are between eleven and thirteenrows on each jaw (颚) and around three hundred teeth in each row.However, the whale shark rarely (很少) uses its teeth. It does not chew (咀嚼) or bite its food. Large amounts of water are pulled into its mouth and then pushed out through its gills (腮).For a few months every year, a group of whale sharks comes to Ningaloo Reef, off Western Australia. This gives scientists a wonderful chance to study the large fish. Whale sharks do live in other oceans of the world, but no one knows their population. It is possible that our biggest fish may need protecting. It is one of the reasons why scientists continue to learn all they can about these gentle giants.56. Few people know about whale sharks because scientists _____.A. are not interested in learning about themB. find them too difficult to catchC. do not know the best places to find themD. have not been studying them for a long time57. Which sentence can tell us that whale sharks are gentle?A. They have large mouths.B. They leave divers alone.C. They have small eyes.D. They live in many oceans.58. How does the writer help us know what the whale shar k’s mouth looks like?A. By giving reasons.B. By describing colors.C. By using numbers.D. By comparing sizes.59. The fifth paragraph is mainly about _____.A. how a whale shark eatsB. what a whale shark eatsC. how different fish use their gillsD. what’s inside a whale shark’s mouth60. Which is the best title of the article?A. Gentle GiantsB. The Diary of a SailorC. The Largest AnimalD. My Life on the Sea答案:46-50 DBDAC 51-55 ACDBB 56-60 DBCAA天津市滨海新区2020届九年级适应性训练(二模)英语试题四、阅读理解(本大题共15小题,每小题2分,共30分)阅读下面的材料,从每小题所给的A、B、C、D四个选项中选出最佳选项。
实验四交叉列表与等级相关分析(Crosstabs)主要知识点与功能交叉列表分析是对两个变量之间关系的分析方法。
被分析的变量可以是定类变量也可以是定序变量。
系统对两个变量进行交叉列表分析后生产交叉表和输出χ2检验结果。
调用此过程可进行计数资料和某些等级资料的列联表分析,在分析中,可对二维至n 维列联表(RC表)资料进行统计描述和χ2检验,并计算相应的百分数指标。
此外,还可计算四格表确切概率(Fisher’s Exact Test)且有单双侧( One-Tail、 Two-Tail),对数似然比检验(Likelihood Ratio)以及线性关系的Mantel-Haenszelχ2检验。
一、交叉列表分析(Crosstabs)(一)、执行命令:Analyze——Descriptive Statistics——Crosstabs,打开如下对话框(二)、确定交叉列表分析的变量从左侧窗口选择两个名义变量或顺序变量分别进入Row(s)(行)框和Column(s)(列)框。
Display clustered bar charts是在输出结果中显示聚类条形图。
Suppress tables是隐藏表格,如果选择此项,将不输出R*C交叉表。
(三)、选择统计分析内容单击Statistics按钮,打开如下对话框:(1)Chi-square是卡方(χ 2 )值选项,用以检验行变量和列变量之间是否独立。
适用于两个定类变量或一个定类变量一个定序变量之间的相关性分析。
(2)Correlations是相关系数的选项,用以测量变量之间的线性相关。
适用于两个定序变量或定距变量之间关系的分析。
(3)Nominal是定类变量选项栏,当分析的两个变量都是定类变量时可以选择的参数。
1、Contingency coefficient:列联相关的c系数,其值 =χχ22+N,界于0~1之间,其中N为总例数;2、Phi and Cramer's V:列联相关的V系数,V系数 = χ2N ,用于描述相关程度,在四格表χ 2 检验中界于-1~1之间,在RC表χ 2 检验中界于0~1之间;Cramer's V =χ2N(k-1),界于0~1之间,其中k为行数和列数较小的实际数;3、Lambda:λ值,在自变量预测中用于反映比例缩减误差,其值为1时表明自变量预测应变量好,为0时表明自变量预测应变量差;4、Uncertainty coefficient:不确定系数,以Z为标准的比例缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变量,其值接近0时表明后一变量的信息与前一变量无关。

交叉分析法怎么分析交叉分析法(Cross-Tabulation Analysis)是一种常用的数据分析方法,通过对两个或多个变量之间的关系进行交叉分析,帮助我们了解数据之间的共同特征以及相关性。
下面将介绍交叉分析法的具体步骤和应用。
一、确定分析目的在进行交叉分析之前,我们首先需要明确分析的目的。
是为了寻找变量之间的关联性,还是为了发现群体之间的差异性。
根据不同的目的,我们可以选择不同的交叉分析方法和指标。
二、选择合适的变量在进行交叉分析时,我们需要选择合适的变量进行分析。
这些变量应该是能够代表我们所研究的问题或主题的重要指标。
同时,这些变量之间应该存在一定的关联性,以确保分析的结果有一定的实际意义。
三、数据整理与处理在进行交叉分析之前,我们需要对原始数据进行整理和处理。
这包括数据清洗、数据转换、缺失值处理等。
确保数据的准确性和完整性,避免因为数据问题导致分析结果的误差。
四、交叉表制作交叉表是交叉分析的基础,用于展示不同变量之间的交叉关系。
我们可以使用Excel等工具制作交叉表。
将需要分析的变量作为行或列,将其它相关变量放置在表格内,以展示它们之间的关系。
五、分析结果解读在得到交叉表之后,我们需要对表格中的数据进行分析和解读。
我们可以计算各行、各列的比例、百分比等统计指标,以便更好地了解变量之间的关系。
同时,可以绘制图表来直观地展示交叉分析的结果。
六、推断和验证通过对交叉分析的结果进行推断和验证,我们可以进一步验证我们的分析结论是否合理和可靠。
这可以通过统计检验等方法进行,以确保我们的分析结果是具有统计意义的。
七、应用示例交叉分析法广泛应用于市场调研、社会科学、医学研究等领域。
例如,在市场调研中,我们可以使用交叉分析法来分析产品与消费者之间的关系;在社会科学研究中,可以利用交叉分析法来研究不同人群之间的差异性和共同点。
八、总结交叉分析法是一种简单而有效的数据分析方法,可以帮助我们深入了解变量之间的关系和特征。
1、crosstabs列联分析——相关分析在问卷调查、产品检验、医学统计等领域,长需对问题按两个或多个不同的特征进行分类,然后对样本进行交叉汇总后就得到了各种各样的列联表。
一般对列联表的统计分析只着重于分类特征之间是否相互依赖,或者说相互独立,此时可借助卡方检验,也可计算相关系数做相关分析,还可根据不同数据类型给出相应的关联系数。
卡方检验是统计判断是否相互依赖,计算相关系数和关联系数是判断和衡量相关或依赖关系的倾向和程度。
不同数据类型间的相关系数或关联系数合理选择列于下表:关于卡方检验、相关系数或关联系数的细节介绍可参考:列联表分析及在SPSS中的实现pdf文件和相关分析案例PPT文件。
SPSS中Crosstabs工具执行列联分析,其选项中Statistics如下图所示:上图指出:名义变量间、顺序变量间、名义变量和区间变量间可选的关联系数,可参考上面表理解。
对上图,Spss的帮助文件解释如下:Chi-square. 对2x2的列联表, 选Chi-square 来计算 Pearson 卡方值, 似然比卡方值, Fisher's 精确检验, and Yates' 修正后卡方值 (连续修正). 对 2 x 2 列联表, 当表中有一个单元格的期望频率少于5时,进行Fisher's 修正检验,其他情况计算 Yates' 修正卡方值。
对那些有任意数目的行和列的表,选择 Chi-square 计算 Pearson 卡方值和似然比卡方值。
当表的变量是数量型的, Chi-square 执行线线关联检验。
.Correlations. 当表的行列中的值都是可排序的, Correlations 计算 Spearman's 修正系数, rho (仅对数字数据). Spearman's rho 是变量秩序间的关联测度. 当变量都是数量型的, Correlations 计算Pearson 相关系数, r, 测度变量间线性相关系数。
作者简介刘爱玉,京大学社会学系副教授。
主要研究领域为劳动社会学、组织社会学、人力资源开发与管理。
主要学术成果有:《社会变迁过程中地区收入差异研究》、《社会变迁过程中的老年人家庭支持研究》、《政策、结构与人力资源》、《选择:国企变革与工人生存行动》、《劳动社会学教程》等。
本书简介本书介绍如何运用SPSS对通过问卷或其他手段收集的定量资料进行描述和分析。
作者力图以简明、扼要、直观的方式,展示SPSS分析的基本原理与操作,并在展示过程中将统计原理与SPSS数据分析相结合。
本书有易学易用、步步到位、重操作和实务三大特点,是统计学初学者的必备参考书。
目录前言第一章 SPSS与社会科学调查研究 一、问题的提出 二、提出研究假设 三、设计研究方案 (一)研究类型选择 (二)研究方法选择 (三)资料收集方法选择 (四)研究层次和分析单位选择 (五)概念和变量测量方法的确立 (六)问卷、观察表格与访问提纲的制定 (七)制定抽样方案 四、资料收集 (一)试点调查 (二)调查实施 五、SPSS和资料的整理与分析 (一)资料的校核与登录 (二)统计分析与假设的检验 思考和练习第二章 SPSS基本知识 一、SPSS的安装 二、SPSS的启动和退出 (一)启动SPSS (二)退出SPSS 三、SPSS主要窗口介绍 (一)数据编辑器窗口:Data:Editor (二)Syntax:编辑窗口 (三)0utput:结果输出窗口 四、SPSS的求助系统 (一)Topics主题帮助子菜单 (二)Tutorial在线帮助子菜单 (三)Case Studies帮助子菜单 (四)Statistics Coach统计分析帮助子菜单 思考和练习第三章 数据录入 一、问卷设计及编码 (一)问卷及编码样例 (二)编码应注意事项 二、数据录入方法 (一)在SPSS窗口录入数据 (二)用SPSS命令程序录入数据 (三)在EXCEL中录人数据 (四)利用EpiData小程序进行录入 思考和练习第四章 SPSS数据文件的编辑与管理 一、增加新的变量(Insert Variable) 二、增加新的个案(Insert Case) 三、删除变量或个案 四、查找个案(Go To Case) 五、数据的排序(Sort Case) 六、数据的行列对换(Transpose) 七、数据文件的合并(Merge Files) 八、数据文件的分类汇总(Aggregate) 九、数据的选择(Select Cases) 十、对变量进行加权(Weight Cases) 十一、Data中的其他菜单命令 思考和练习第五章 用Frequencies做数据汇总 一、如何得到一张频次表 (一)基本操作 (二)频次表的解释 二、频次统计及统计量的计算 (一)百分比计算 (二)集中趋势测量 (三)离散趋势测量 ……第六章 描述性统计——Descriptives与Explore的应用第七章 数据变换第八章 交互表与关联分析(Crosstabs的应用)第九章 引进其他变量后的交互分析第十章 子总体均值比较与检验(Means和T-Test应用)第十一章 方差分析(One Way ANOVA)第十二章 相关分析(Correlate过程分析)第十三章 线性回归分析(Linear Regression)第十四章 非参数检验(Nonparametric Tests)第十五章 SPSS统计图形参考资料下载后 点击此处查看更多内容。
第六讲交叉汇总与关联分析(Crosstabs的应用)主要用于研究两个变量之间是相互独立还是存在某种关系,有没有关系,关系程度怎么样。
最适合于分析两个定类变量之间的关系,但是通过对变量的处理,也可以适合于分析测量层次更高级别的变量。
一、变量及其测量层次变量:被操作化了的概念,是可以直接观察的,在经验研究中,在不同的状态下有不同的属性,科学研究一定要使用变量的语言,一定要有操作化。
变量从它测量的层次上看,可以区分为四种类型:定类变量(Nominal ):区分现象、事物的不同性质,而不能从规模大小等方面进行区分,=≠性别(男,女)收入(有收入,无收入)、民族等定序变量(Ordial):当变量不仅区分了对象的属性、特征,还区分出大小、强弱、高低次序时,就是定序变量。
=≠< >如社会地位、文化水平、社会态度、收入等定距变量(Interval):除了类别、次序属性以外,取值之间的距离还可以用标准化的距离去测量,可以进行加减的运算。
年龄定比变量(Ratio):除了以上三类变量提到的属性,定比变量取值可以构成一个有意义的比率。
如智商。
各个变量之间的关系及其测量:定类——定类——列联表、交互分析定序——定序——等级分析定距——定距——回归与相关(简单与多元)定类——定距——方差分析定类——定序——非参数检验二、交叉汇总表的一般形式及其特点的上面,因变量放在表的旁边条件分布:将其中一个变量控制起来,再看另外一个变量的分布,可以得到条件分布,如可以对自变量的同一取值作条件分布,进行分析。
三、如何获得交叉汇总表Analyze-----Descriptives----Crosstabs----出现对话框:●ROWS这个框中的变量作为交互表中的行变量(一般放因变量Y,y1, y2,y3--)●Column框,这个框中的变量作为交互表中的列变量(一般放自变量X,x1,x2,x3…)●Layer框:框中的变量作为控制变量,决定交互表的层,可以多个控制变量。
了解大数据中的关联分析与交叉分析方法随着大数据时代的到来,数据成为了人们生活中不可或缺的一部分。
同时,大数据分析和数据挖掘等领域也成为了当前科技发展的热点。
其中,关联分析和交叉分析方法是大数据中常用的两种分析方法。
本文将详细介绍这两个分析方法的概念、应用以及其在实际中的作用。
一、关联分析关联分析是大数据分析领域中最为重要的技术之一,它的目的是寻找数据集中不同变量之间的关联规则。
所谓的“关联规则”,指的是某些事件之间的“关系”或者说“相关性”,比如:“如果用户购买了A商品,那么也很有可能会购买商品B。
”在关联分析中,会使用频繁项集、强关联规则、支持度和置信度等概念进行计算和分析。
举个例子,假设要找到一些可能会同时出现的食品,可以通过关联分析的方法来发现可能的规律。
首先需要分析大量的数据集,找到在同一个购物篮子中被同时购买的食品。
通过对这些数据进行关联分析,就可以发现一些经常被同时购买的食品组合,比如牛奶和面包或者牛奶和饼干等等。
这种分析结果有助于商家调整产品组合、制定销售策略,提高营销收益。
另一个常见的例子是在线广告投放策略。
通过对用户的浏览数据进行关联分析,可以知道用户浏览了哪些网页,进而推测出用户可能感兴趣的商品,从而向用户投放相关广告。
这种方式相对于传统广告投放,可以更为精准地推送广告,提高广告点击率,达到最优化的广告媒介利用效果。
二、交叉分析交叉分析在大数据分析中同样占有重要的位置。
它与关联分析类似,也是寻找数据之间的相关性,不过着重点略有不同。
交叉分析的目的是通过比较不同的数据之间的差异性,进而找出数据之间的关系,使得数据集中的模式和趋势变得更加明确。
在交叉分析中,会使用数据透视表、趋势分析和聚类分析等概念进行计算和分析。
举个例子,假设要了解用户对手机品牌的评价,可以通过交叉分析来从多个角度对原始数据进行分析。
可以从不同手机品牌的评价数目、各项指标的平均得分、用户群体的画像等方面进行分析。
第六讲交叉汇总与关联分析(Crosstabs的应用)主要用于研究两个变量之间是相互独立还是存在某种关系,有没有关系,关系程度怎么样。
最适合于分析两个定类变量之间的关系,但是通过对变量的处理,也可以适合于分析测量层次更高级别的变量。
一、变量及其测量层次变量:被操作化了的概念,是可以直接观察的,在经验研究中,在不同的状态下有不同的属性,科学研究一定要使用变量的语言,一定要有操作化。
变量从它测量的层次上看,可以区分为四种类型:定类变量(Nominal ):区分现象、事物的不同性质,而不能从规模大小等方面进行区分,=≠性别(男,女)收入(有收入,无收入)、民族等定序变量(Ordial):当变量不仅区分了对象的属性、特征,还区分出大小、强弱、高低次序时,就是定序变量。
=≠< >如社会地位、文化水平、社会态度、收入等定距变量(Interval):除了类别、次序属性以外,取值之间的距离还可以用标准化的距离去测量,可以进行加减的运算。
年龄定比变量(Ratio):除了以上三类变量提到的属性,定比变量取值可以构成一个有意义的比率。
如智商。
各个变量之间的关系及其测量:定类——定类——列联表、交互分析定序——定序——等级分析定距——定距——回归与相关(简单与多元)定类——定距——方差分析定类——定序——非参数检验二、交叉汇总表的一般形式及其特点的上面,因变量放在表的旁边条件分布:将其中一个变量控制起来,再看另外一个变量的分布,可以得到条件分布,如可以对自变量的同一取值作条件分布,进行分析。
三、如何获得交叉汇总表Analyze-----Descriptives----Crosstabs----出现对话框:●ROWS这个框中的变量作为交互表中的行变量(一般放因变量Y,y1, y2,y3--)●Column框,这个框中的变量作为交互表中的列变量(一般放自变量X,x1,x2,x3…)●Layer框:框中的变量作为控制变量,决定交互表的层,可以多个控制变量。
●Display Clustered bar chats选中这个框,将显示每一组中各个变量的分类条形图●Suppress tables选中这个框,只输出统计量,不输出多维列联表●Statistics 统计量●Cell display对话框——确定要输出的列联表——观测量数、百分比、残差以自变量作为计算百分率的方向,是社会学研究的常规,当然,也有例外的情况:如果因变量在样本内的分布不能代表其在总体内的分布,则百分率的计算要根据因变量的方向(见李沛良书P74。
)比较时采用行百分比还是列百分比?原则上是没有自变量与因变量的区分。
如看职业流动表中的流出率,选Row百分比,得行的百分比,行加起来为100%若选column——列百分比,列若是儿子职业,则列百分比可以看某一职业类别到底由什么人构成,职业流动表中的流入率。
做目前职业身份与父亲从事职业的关系交互表Rows――父亲从事工作Columns――目前身份Cells――row――问:父亲是农民的那些被调查者,他们目前的身份与父亲是高级管理人员者比有什么特点?如果cells-column――问目前身份是一线工人的人,他们的父亲都是干什么的?四、如何看一张交叉汇总表(一)Cell功能键observed:观察值的实际数expected:如果行和列在统计上是独立的或不相关的,那么会在单元格中输出期望的观察值的数量。
Row:行百分比Column:列百分比Unstandardized:计算非标准化残差,残差是观察值与期望值之差,正的残差意味着在行列变量相互独立时,单元格中的观察值比期望值大。
Standardized:标准化残差, 它的值是残差除于标准差,其均值是0,标准差等于1。
Adj standardized调整后的残差。
以社会统计学教材P295表10-2为例1.联合分布、边缘分布与条件分布Analyze-----Descriptives----Crosstabs--- Cells ――Total――OK2.列联表中变量的相互独立性――社会统计学教材表10-15分析,可以通过SPSS的如下程序进行操作Analyze-----Descriptives----Crosstabs--- Cells ――Column(求列百分比)――OKAnalyze-----Descriptives----Crosstabs--- Cells ――Column(求行百分比)――OK期望分布―――Analyze-----Descriptives----Crosstabs--- Cells ――expected――Column(求列百分比)――OK五.定类——定类——列联表交互分析――是否相关 (一)交互表的检验——两个变量之间是否相关一般用x 2来检验,检验的原来假设是:两个变量之间没有关系,研究假设或称为备择假设是两个变量之间有关系。
检验的方法是: Pearson Chi-Squarex 2 的自由度是(r-1)(c-1)n ij 是观察的样本频次 如果x 2 检验sig <.05,拒绝原假设,即认为两个变量之间相关 如果x 2 检验sig >.05,接受原假设,即认为两个变量之间不相关 注意:对于2×2的列联表,格数过少,为减少偏差,对x 2 进行修正,x n E E ij ij ijj ri c 221105=--==∑∑(.)x 2检验适合于单变量二项总体或者多项总体的检验。
例子:看子辈职业与父辈职业之间是否相关1.数据2.检验结论:由于sig.小于.05,所以,子辈职业与父辈职业之间是相关的注意:在这些检验结果中,我们一般用Pearson Chi-SquareLikelihood Ratio对数似然比方法计算的卡方;Linear-by-Linear Association:线性相关的卡方值。
六、两个定类变量之间相关的强度(一)相关系数1.Phi系数描述2×2数据相关程度最常用的一种相关系数Φ=x n 2对于一个具体的2×2维列联表X1 X2Y1 a bY2 c dΦ=-++++ad bca b c d a c b d ()()()()2.列联系数当一张表格超过2维时,Phi的值不一定是在0---1之间,为了获得0≤Phi≤1,皮尔逊建议用列联系数Cxx N =+22C 的最高限取决于行数和列数,一般达不到上限1,对于一个4×4表格,最高限为0.873.Cramer’s V 系数)1(),1min[(2--Φ=c r VV 的最高上限可以达到1,但是不是很直观4.Lambda, Tau-y 系数(具有PRE 性质的系数)PRE 数值的意义:就是用一个现象(如变量X )来预测另一个现象(如变量Y )时能够减除百分之几的误差。
PRE=(E1—E2)/E1E1:当不知道X 变量去估计Y 变量时所产生的误差(全部误差) E2:知道X 变量再去估计Y 变量产生的误差 E1—E2为剩余的误差如果两个变量都是定类测量层次,可以用Lambda, Tau-y 系数 [1] Lambda 相关测量法这种相关测量法也叫做Cuttman’s coefficient of predictability ,它的基本的逻辑是计算以一个定类变量的值来预测另一个定类变量的值时,如果以众值作为预测的准则,可以减除多少误差。
消减的误差再全部误差中所占的比例越大,表示两个变量之间相关的程度越大。
Lambda 系数有两种形式: 对称形式(symmetrical version ):特点是两个变量之间的关系是对称的,也就是不分自变量与因变量λ =每列与每项最高频次之和边缘和边缘和中最高频次观察总数边缘和与边缘和中最高频次-⨯-X Y X Y 2(见李沛良书P81)不对称形式(asymmetrical version ):要求一个是自变量(X ),另一个是因变量(Y )。
λy Y Y =--每列最高频次之和边缘和中最高频次观察总数边缘和中最高频次当自变量与因变量位置互换时,Lambda 的值会不一样。
SPSS 给出的是不对称的Lambda 系数,有两个。
分子就是根据X 值来预测Y 的众值所能够消减的误差(E1-E2)分母就是在不知道X 值的情况下来预测Y 的众值时所产生的全部误差 Lambda 的取值是(0,1)Lambda 系数是以众值作为预测的准则,不理众值以外的次数的分布,如果全部众值集中在条件次数表的同一列或同一行,那么Lambda 系数可能等于0——而这往往并不表示两个变量之间没有关系,实际上我们发现是有关系的,当我们把频次转换为百分比计算的时候,可以清楚地看出他们之间的关系。
因此,Lambda 系数的敏感性有时候实际上是有问题的,因此社会学研究中有时采用Goodman 和 Kruskal 的 Tau-y 系数 [2] Goodman and Kruskal 的 Tau-y 系数这个系数的敏感度高于Lambda 系数,但只适合于分析不对称的关系,属于不对称相关测量法,要求两个定类变量中有一个是自变量,有一个是因变量,Tau-y 系数的值是界于0—1之间,具有消减误差比例的意义,这个系数的特色是在计算时会包括所有的边缘次数和条件次数Tau-y=E E E n nnn n nn ij ji i 12111222-=--∑∑∑∑***E nF F ny y1=-∑()E F f fF x x2=-∑() ()n F ny -表示如果不知道变量值(男或女),那么每次预测某个Y 变量的错误机率,再乘上F y ,表示预测这个Y 值的错误总数,Y 变量有多个值,把各个值的预测错误总数加起来,就是E1F y ——Y 变量的某个边缘次数F x ——X 变量的某个边缘次数f 某条件次数在那么多相关系数中,在进行研究时,一般选择哪一个比较好?在定类——定类关系中,如果是不对称关系,最好选择用的是 Tau-y ,如果是对称的关系,择最好选择用的是Lambda 系数,Phi 、C 、V 系数没有消减误差比例的意义,而且假定两个变量之间的关系是对称的。
在这三个系数中,由于V 不受表的大小的影响,因此用得比较多,也比较适合于进行社会学研究。
不确定系数:uncertainty coefficient :表示用一个变量来预测其他变量时降低误差的机率。
如不确定系数在83%时,表示已知一个变量知识在预测其他变量时,可以减少85%的误差。
是一个具有消减误差比例意义的系数。
SPSS 中给出的相关系数:Phi 系数、列联系数、Cramer V 系数、Lambda, Tau-y 系数(有两个)、uncertainty coefficient例子:社会统计学教材表10-34,求各类系数(二)对相关系数进行检验看相关系数的显著性就可以,如果显著性小于.05,则有统计意义,如果大于.05,则没有统计意义(三)统计意义与实际意义七、定序——定序列联表、交互分析(一)相关系数1. Kendall 的 tau 系数——适合于分析对称关系tau 系数的基本逻辑是计算同序对数与异序对数的差在全部可能对数中所占比例。