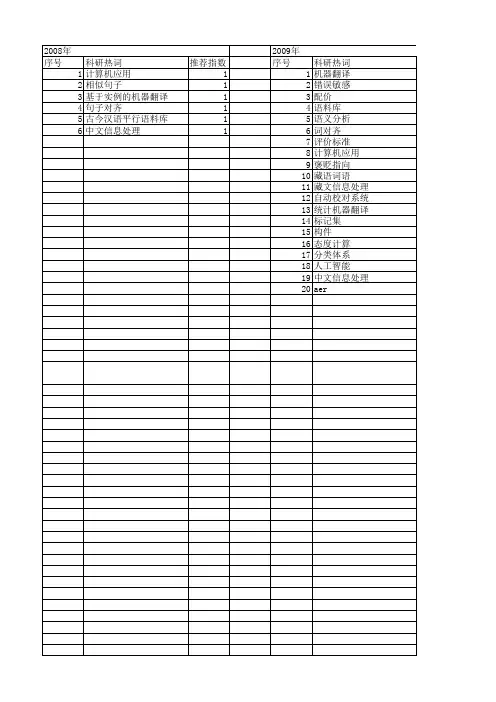
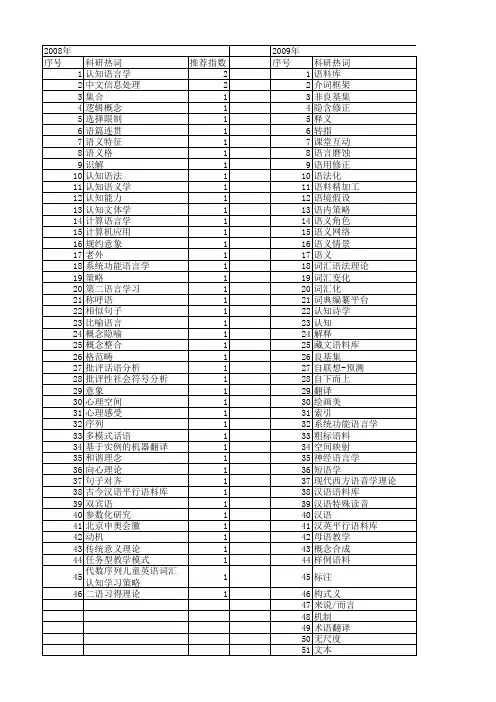
基于实例的机器翻译
- 格式:pdf
- 大小:82.41 KB
- 文档页数:6

easy_trans 使用实例-回复什么是easy_trans?Easy_trans是一个在线翻译工具,提供中文和英文之间的即时翻译服务。
它基于先进的人工智能技术,包括机器学习和自然语言处理,以提供高质量且准确的翻译结果。
Easy_trans不仅可以帮助用户实现快速翻译,还可以提供词汇和例句的详细解释,以帮助用户更好地理解翻译的含义。
使用Easy_trans的优势Easy_trans作为一个在线翻译工具,有许多使用它的优势。
首先,Easy_trans提供了快速的翻译服务,用户只需输入文本,即可获得秒级的翻译结果。
其次,Easy_trans采用了先进的人工智能技术,因此翻译质量非常高,准确度较大。
此外,Easy_trans还提供了丰富的辅助功能,包括语音输入、文本翻译、图片翻译等,用户可以根据需要选择不同的方式来翻译。
Easy_trans的使用示例下面是一些使用Easy_trans的使用示例,以帮助进一步理解其功能和用途。
1. 文本翻译假设你想要将一篇中文短文翻译成英文,你可以将这篇短文复制到Easy_trans的输入框中,然后选择源语言为中文,目标语言为英文,点击翻译按钮即可得到英文翻译结果。
Easy_trans会自动进行句子和词汇级别的翻译,并提供相应的解释和例句,以帮助你更好地理解翻译的含义。
2. 语音翻译假设你需要实时将中文口语转换成英文,你可以使用Easy_trans的语音输入功能。
只需点击语音输入按钮,然后用中文朗读你想要翻译的内容,Easy_trans会自动将其翻译成英文,并将结果显示在屏幕上。
这对于需要与外国人交流或在国外旅行的人来说非常方便。
3. 图片翻译假设你在海外旅行时看到一张中文的餐厅菜单,你可以使用Easy_trans 的图片翻译功能。
只需打开Easy_trans的相机功能,然后对准菜单拍照,Easy_trans会自动识别图片中的中文内容,并将其翻译成英文。
这对于在陌生的国家中理解菜单或标牌非常有帮助。

机器翻译工具英译汉译文质量评估、对比和改进建议——以有道翻译和金山快译为例发布时间:2022-01-06T07:11:37.445Z 来源:《教学与研究》2021年第24期作者:苏怡然[导读] 近年来,机器翻译发展成为大势所趋,苏怡然吉首大学摘要:近年来,机器翻译发展成为大势所趋,尤其当深入学习在机器翻译中的广泛应用后,对机器翻译而言更是如虎添翼。
而机器翻译软件的译文质量究竟如何呢?本文选取了国内市场上两家机器翻译平台——金山快译和有道翻译,从译文的准确性、格式规范、语言风格角度,对其译文质量进行评价、打分、比较和改善。
本次译文比较主要是聚焦于英译汉。
研究发现:从译文质量角度来看,在英译汉方面,有道翻译以66分远优于金山快译的37分。
从错误类型角度来说,句意错误、转换痕迹重、词汇错译这三方面是最为常见的共性问题。
本文也就存在的问题,为机器翻译软件提出了进一步改善的建议。
关键词:机器翻译;译文对比;有道翻译;金山快译;质量评估有道翻译、百度翻译、搜狗翻译、小牛翻译、腾讯翻译君、新译翻译、谷歌翻译等翻译平台遍地开花,成为了人们工作办公、外出旅行的“发声器”。
但是译文质量到底如何呢?能否准确传达意图呢?为了解决这一疑惑,本文选取了国内市场上两家机器翻译平台——有道翻译和金山快译进行对比研究,主要对英译汉译文进行对比研究。
主要依据“中译国青杯”联合国文件翻译大赛对两个翻译平台的英译汉质量进行对比和质量点评。
从而,客观、直观的展现机器翻译译文的质量,指出待改进的方面,以及改进的方法,以期为机器翻译进一步优化提出合理建议,也就机器翻译是否会替代人工翻译的这一辩题,提供笔者的思考。
1.机器翻译发展现状新世纪以来,各个互联网公司基于大数据和强大的统计方法,纷纷涉足机器翻译领域,研发出了基于大数据的翻译数据库和翻译平台。
如今,受限于语料库规模,基于实例(Example-based)的机器翻译很难达到较高的匹配率,往往只在个别限定的专业或是领域时,翻译效果才能达到使用要求。

英语翻译软件翻译准确性矫正算法设计黄登娴【摘要】传统机器翻译方法采用管道式逐次操作对原始语料实施词性标识以及句法分析,获取英语语言的句法结构,使得翻译任务间存在的错误迭代传递、结构化实例准确性降低,导致英语语言文学翻译准确性降低.因此,对英语语言文学中的机器翻译准确性方法进行校对研究.设计基于知网的词汇语义相似度以及对数线性模型,采用汉英依存树到串的方式保存对应的双语语料,对源语言端实施依存结构化处理,确保汉英双语的对应关系,通过知网运算输入需要翻译句子(依存树结构)同实例库内源语言(依存树结构)中词汇的语义相似度.描述了机器翻译中相似实例检索模块以及译文生成模块的实现过程,通过面向数据的翻译模型进一步校对英语语言的准确翻译.实验结果表明,所提方法可得到准确率高的译文,具有较高的准确性和稳定性.【期刊名称】《现代电子技术》【年(卷),期】2018(041)014【总页数】4页(P170-172,177)【关键词】英语翻译软件;机器翻译;翻译准确性;语义相似度;矫正算法;迭代传递;依存树结构【作者】黄登娴【作者单位】中国民用航空飞行学院,四川广汉 618300【正文语种】中文【中图分类】TN912.3-34;TP391.2机器翻译是自然语言操作范围中的关键,具有较高的应用价值。
依据实例的机器翻译是一种经验主义的英语语言文学翻译策略,其无需复杂的深层次语法以及语义的分析,提高了英语语言翻译的效率。
但是基于实例的机器翻译方法对实例库质量的要求较高[1]。
传统机器翻译方法采用管道式逐次操作对原始语料实施词性标识以及句法分析,获取英语语言的句法结构,使得翻译任务间存在的错误迭代传递、结构化实例准确性降低,导致英语语言文学翻译准确性降低。
针对该问题,本文研究了英语语言文学中的机器翻译准确性方法,塑造并实现基于汉英依存树串实例的机器翻译系统,提高了英语机器翻译的准确性。
1 基础算法与模型1.1 依存树到串模型依存树到串的模型为<D,S,A>,<D,S>是一个翻译对,D表示源语言的依存树,S表示源语言的目标词语串,A用于描述D与S间的词对齐关系[2-3],依据依存树到串双语对齐模型的实例如图1所示。

自然语言处理应用实例一、介绍自然语言处理(Natural Language Processing,NLP)是一种人工智能技术,它的目标是让计算机能够理解、分析、处理人类语言。
随着互联网和社交媒体的发展,NLP应用越来越广泛,包括机器翻译、情感分析、文本分类、信息抽取等。
本文将介绍几个常见的NLP应用实例,并详细说明其原理和实现方法。
二、机器翻译机器翻译(Machine Translation,MT)是NLP中最古老也是最重要的应用之一。
它的目标是将一种语言的文本自动转换为另一种语言的文本。
机器翻译有两种主要方法:基于规则和基于统计。
基于规则的机器翻译系统使用人工编写的规则来将源语言转换为目标语言。
这些规则通常由专家手动编写,并且需要耗费大量时间和精力。
这种方法通常适用于小规模的翻译任务,但对于复杂或大规模任务效果不佳。
基于统计的机器翻译系统则利用大量平行语料库进行训练,并使用概率模型来预测每个单词或短语的翻译。
这种方法不需要手动编写规则,但需要大量的训练数据和计算资源。
目前,基于神经网络的机器翻译系统已经成为主流,其效果比传统的基于统计方法更好。
三、情感分析情感分析(Sentiment Analysis)是一种NLP应用,它的目标是自动分析文本中包含的情感倾向,通常包括正面、负面和中性。
情感分析有很多实际应用场景,例如社交媒体监测、产品评论分析等。
情感分析主要有两种方法:基于规则和基于机器学习。
基于规则的情感分析系统使用人工编写的规则来判断文本中是否包含某种情感倾向。
这些规则通常由专家手动编写,并且需要不断更新以适应新的语言和文化背景。
这种方法具有较高的准确率,但对于复杂或不确定的情况效果不佳。
基于机器学习的情感分析系统则利用大量标注好的训练数据进行训练,并使用分类算法来预测文本中包含的情感倾向。
这种方法不需要手动编写规则,但需要大量标注好的训练数据和计算资源。
目前,基于深度学习的情感分析系统已经成为主流,其效果比传统的基于机器学习方法更好。




矿产资源开发利用方案编写内容要求及审查大纲
矿产资源开发利用方案编写内容要求及《矿产资源开发利用方案》审查大纲一、概述
㈠矿区位置、隶属关系和企业性质。
如为改扩建矿山, 应说明矿山现状、
特点及存在的主要问题。
㈡编制依据
(1简述项目前期工作进展情况及与有关方面对项目的意向性协议情况。
(2 列出开发利用方案编制所依据的主要基础性资料的名称。
如经储量管理部门认定的矿区地质勘探报告、选矿试验报告、加工利用试验报告、工程地质初评资料、矿区水文资料和供水资料等。
对改、扩建矿山应有生产实际资料, 如矿山总平面现状图、矿床开拓系统图、采场现状图和主要采选设备清单等。
二、矿产品需求现状和预测
㈠该矿产在国内需求情况和市场供应情况
1、矿产品现状及加工利用趋向。
2、国内近、远期的需求量及主要销向预测。
㈡产品价格分析
1、国内矿产品价格现状。
2、矿产品价格稳定性及变化趋势。
三、矿产资源概况
㈠矿区总体概况
1、矿区总体规划情况。
2、矿区矿产资源概况。
3、该设计与矿区总体开发的关系。
㈡该设计项目的资源概况
1、矿床地质及构造特征。
2、矿床开采技术条件及水文地质条件。

面向译者信息素养的教程《计算机辅助翻译》述评王少爽冯晓辉面向译者信息素养的教程——《计算机辅助翻译》述评_王少爽冯晓辉第11期英语教师____年11月书评面向译者信息素养的教程———《计算机辅助翻译》述评1王少爽冯晓辉钱多秀.____.计算机辅助翻译[M].北京:外语教学与研究出版社:vi+306pp. doi:10.3969/j.issn.1009-8852.____.11.012一、引言信息技术引发了翻译工作模式的变革,信息素养已成为现代译者的工作必备。
传统的作坊式翻译经营逐渐升级为基于信息技术的流程化现代企业经营模式。
机辅翻译工具的使用能力被视为翻译能力的一项不可或缺的子能力(PACTE____;Gpferich____;苗菊、王少爽____)。
可见,信息素养已成为现代译者所必备的职业品质。
翻译学习者信息素养的发展已成为当前翻译教育中的重要课题,亟须此方面相关教材的出版。
钱多秀主编的《计算机辅助翻译》作为全国翻译硕士专业学位(MTI)系列教材之一,于____年由外语教学与研究出版社出版,较为系统地介绍了当前翻译工作中所涉及的各种工具和软件,为翻译学习者提供了一本不可多得的信息素养教材。
本文首先简要介绍该书的主要内容,而后对其编写特点及不足予以评论,以飨读者。
教学互动,善于选择授课文本,鼓励学生之间合作,与校外教学和科研机构交流,保持与翻译软件供应商和翻译行业的联系。
第一章从机器翻译到计算机辅助翻译本章首先介绍了机器翻译技术研发的时代背景和需求,尤其是以欧盟对翻译的需求为例,突显了发展机译技术的必要性。
然后,叙述了机器翻译在西方和中文区的发展历程,介绍了基于规则的机器翻译、基于统计的机器翻译、基于实例的机器翻译、多引擎的机器翻译等四种类型机译原理的优点和不足。
机译技术研发进入瓶颈期后,计算机辅助翻译技术萌芽并蓬勃发展起来。
目前,翻译记忆是计算机辅助翻译工具的核心技术,与术语管理、语料对齐、翻译流程管理等工具结合使用。
第13卷第1O期 2014年1O月 软件导刊
Software Guide 、,o1.13NO.10
基于规则的多种策略句法分析 杨海涛 (银川能源学院计算机学院,宁夏银川750105) 摘 要:以英汉机器翻译为研究背景,提出一种基于多种策略的句子结构分析方法。针对不同情况以谓语动词为中 心采取不同策略分析简单句的结构,从而得到整个句子的语法语义结构。 关键词:机器翻译;多策略分析;模板 DOI:lO.11907/rjdk.143375 中图分类号:TP312 文献标识码:A 文章编号:1672—7800(2014)010—0063—02
0 引言 机器翻译指使用计算机将某种自然语言变成另一种 自然语言的过程 ]。大多数机器翻译系统采用基于规则 的方式进行分析转换,但由于自然语言具有复杂、多变等 特性,因此随意性较大,导致此类机器翻译系统既要建立 大量规则体系以描述各类不同的语言现象,还要添加大量 特殊规则以增强翻译系统的适用性。当各类规则数量累 加到一定程度后,极易引起冗余、冲突等现象,导致机译质 量降低、搭建及更新数据库难度提高、工程量增大。无限 语言现象和规则枚举性质间的矛盾使基于规则的机器翻 译存在一定局限性。而基于实例和基于统计的翻译在建 立语料库与统计模型、实例库建设、实例语言模式表示等 方面都需要大量工作。但如果有机结合几种翻译方法的 优点,以规则分析为主,其它策略为补充,采用多种翻译策 略并行处理后再择优选择,则能大大提高翻译质量与效 率。 1 机器翻译方法简介 现有的机器翻译方法主要分为基于规则、基于实例、 基于统计3种。 (1)常见的基于规则翻译的主要功能是:协助用户提 供一定程度的翻译参考,以完成对译文的初步理解。但其 准确性非常低,翻译出来的结果往往令人啼笑皆非。基于 规则翻译的关键技术有4个:单词分析、语法分析、意义分 析和文理分析口]。其工作原理为:首先读取原自然语言语 句,将语句中的字(词)提取出来,对照存放于数据库中的 电子词典查找目标自然语言相对应的字义(词义),再根据 相应的词法规则、句法规则分析整理出语句的基本意思, 最后借助数据库中的语言模型生成目标语言。从其工作 原理来看,这一系列过程的实现并不太困难,可是由于各 种自然语言具有多样性及特殊性的存在(谚语、俗语、歇后 语等),以及人工智能技术水平发展的制约,想要做到自然 语言之间正确互译几乎是不可能的事情。 (2)基于实例的机器翻译,以翻译记忆为核心,能够帮 助翻译人员提高翻译效率,降低成本,减少重复劳动。其 基本思想是:在对简单句子进行分析时,人们首先会将句 子分解成若干个部分,然后借助已有翻译,将分解的每个 部分翻译成目标字、词或短语,然后再将其组合起来形成 句子。翻译时100%匹配的句子进行自动替换,部分匹配 的句子则根据其匹配度,进行串替换、串删除或串增加等 操作实现翻译。 (3)基于统计的机器翻译把机器翻译看成一个信息传 递的过程,用一种信道模型对机器翻译进行解释口]。通过 对源语言的译码,再利用目标语言的编码,同时剔除噪声 干扰进行翻译。基于统计的机器翻译,直接依靠统计结果 消除歧义、选择译文,因此避开了语言理解中的许多难题。 基于统计和基于实例的机器翻译方法都使用语料库作为 翻译知识的来源。
基于实例的机器翻译 ——方法和问题 王厚峰(北京大学) 关键字:基于实例的机器翻译,双语对齐,相似度计算,模板获取 摘要:本文介绍了基于实例的机器翻译方法,并对基于实例的机器翻译的若干问题,如双语实例的加工对齐、实例的相似度计算和实例模板提取等问题作了说明。
Method and Issues of Example-Based Machine Translation
Wang Houfeng Keywords: EBMT, Bilingual Alignment, Similarity Measure, Template Acquisition. Abstract: The basic frame of Example based machine translation is concerned in this paper. Some key issues, such as bilingual alignment, similarity measure between input sentence and example, and template acquisition, are introduced.
引言 早期的机器翻译本质上都是基于语言规则或语言知识RBMT(Rule Based Machine Translation)的。如,词法规则,句法分析规则,转换规则,目标语生成规则等。这些规则都是根据语言专家的经验总结归纳出来的。直译法、转换生成方法、中间语言方法等都可以归为这一类。在上一世纪80年代中后期,这种纯粹基于语言知识的状况渐渐被基于语料库的机器翻译CBMT( Corpus-Based Machine Translation) 方法打破。 语料库方法中最有影响的是IBM公司的P.Brown 提出的基于统计的机器翻译SBMT (Statistics Based Machine Translation)。受语音处理的启发,P.Brown在1988年第二届TMI会议上提出了用隐马尔科夫模型HMM(Hidden Markov Model)进行机器翻译的想法,这一想法震惊了当时的与会者,并直接导致了语料库方法在自然语言处理上的迅速发展。 另一个影响更为广泛的机器翻译方法是日本的长尾真(Makoto Nagao)1981年提出的基于实例的机器翻译EBMT ( Example based Machine Translation),并于1984年发表[6]。
基本思想是在已经收集的双语实例库中找出与待翻译部分最相似的翻译实例(通常是句子),再对实例的译文通过串替换,串删除以及串增加等一系列变形操作,实现翻译。 基于实例的翻译方法受到广泛关注是在进入90年代之后。其中,Sato[7,8] 等人起到了很
好的推动作用。
EBMT的基本思想
长尾真认为,人们在翻译简单句子时并没有做语言的深层分析,而是先将句子分解为几个片断(短语),然后,借助于已有片断的翻译,将分解的每个片断翻译成目标短语,最后在将这些短语组合起来形成一个长的句子。 基于上述思想,长尾真提出了基于实例的机器翻译EBMT的思想。对应地,EBMT也分为三大部分:将实例划分为片断,确定各个片断的翻译以及重组片断。 例2.1. (a) 她 买 了 一 本 计算语言学 入门 书 假定计算机内已经存储了如下的实例对: (b) 她 买 了 一 件 时髦 的 夹克衫. She bought a sharp jacket. (c) 他 正在 读 一 本 计算语言学 入门 书 He has been reading a book on introduction to Computational Linguistics.例2.1(a) 可以通过 (b)中“他买了”对应的 She bought 和 (c) 中“一本计算语言学入门书”对应的 a book on introduction to Computational Linguistics 重组产生: She bought a book on introduction to Computational Linguistics. 一般来说,EBMT主要有如下部分构成:
双语语料库 相似实例检索语义辞典 重组与调整图2.1 EBMT基本结构图 翻译结果 双语辞典
待翻译句子 在EBMT 中,对齐的双语语料库是最重要的知识库之一。 实例的粒度越大,当翻译用到时,其效果则越理想;但另一方面,粒度越大,能够直接使用的可能性又越小。因此,在实例的粒度选择上,应该考虑到一定程度的平衡。 一般认为,实例的粒度定位在句子一级比较合适;也有大量的实验表明,其粒度要么定位在子句一级,要么以结构形式表示,这样才能使实例的引用达到更好的效果。 由上图可知,语义词典也是不可或缺的重要知识源。根据Somer[9]引入的长尾真的例子:
例2.2 (a) He eats potatoes 是待翻译的句子,同时,假定实例库中有如下的实例: (b) A man eats vegetables Hito-wa yasai-o taberu (c) Acid eats Metal. San-wa kinzoku-O ocasu. 这两个实例从形式上看都可以和 (a)匹配,但是结果只能选择(b),而不是 (c)。这一选择有赖于语义词典。通过语义词典可以判断He 能取代 “ A man ”,不能取代“Acid”,同样,“potato”和“vegetable”间的语义比“potato”与“metal”间的语义更相似。 在确定了相似的句子之后,紧接着的调整处理必须借助于双语词典。如 He—Kare替换man—Hito以及 potato——poteto替换 vegetable—yasai 都需要双语词典的支撑。 翻译实例的重组和调整一般包括替换、插入和删除等操作,上面的两个例子主要涉及到替换操作。最简单的插入操作如例2.3,反过来则为删除操作: 例2.3 (a) 她游览过北京的许多景点。 (b) 她随旅游团游览过北京的许多景点。 在EBMT 中,最为重要的操作是相似实例的检索,主要是相似性的量度标准。后面将详细讨论。 三、基于实例的机器翻译与翻译记忆的异同 翻译记忆TM ( Translation Memory)与EBMT有着千丝万缕的联系,甚至在很多情况下,两个术语不加区别地使用。根据 Somers[9],TM 的思想最初来自于 Martin Kay在1980年的著名文章“Proper Place”。Martin Kay对机器翻译始终是悲观的,但他认为,如果已经有相似的文档,则可以直接从中取出相似的部分来辅助翻译,这正是TM的核心。本质上讲,TM仅仅是辅助翻译,它从实例库中找出相似的例子(常常是多个例子),并提交给用户,让用户选择。TM所面对的用户通常是“专家”,既懂双语,又懂专业。但EBMT则属于机器翻译,翻译的结果由系统决定。用户可以只懂一种语言。 Eiichiro SUMITA 在2002年的TMI会上将机器翻译作了如下分类:
MT CBMTSBMT
EBMT
RBMTTM
图3.1 机器翻译分类 显然,TM并不属于 MT。但TM 与 EBMT 也存在许多相似的地方,主要表现在,都是对已有翻译实例的重用,都需要存储翻译实例,都需要检索相似的翻译实例。
四、基于实例的机器翻译的相关问题
基于实例的机器翻译很重要的一项工作就是构建知识库,其中,包括构建对齐的实例库,双语词典和语义词典。 4.1 双语实例库的构建 双语库的构建需要考虑三个问题: z 双语语料的加工 双语语料的加工包括双语语料的收集,不同文件格式(如 Word的文件格式、文本文件格式、HTML 文件格式以及 PDF 等文件的格式)的统一,不同粒度的对齐处理(包括篇章对齐、段落对齐、句子对齐、子句对齐和多词Multiword 及词汇的对齐)及其标注集的制定和对齐单位的表示。其中,句子(子句)的对齐、多词及词汇的对齐对基于实例的机器翻译有着直接的影响。后两者的对齐加工在常宝宝的论文中有详细的讨论[3];而句子的对齐主
要有如下的两种方法: 方法一,基于长度(或统计)的对齐方法。由Gale和 Church[5] 等人提出的基于符号串
长度的对齐方法是目前使用最为广泛的方法,该方法开始主要用于相似语系(如印欧语系)的句子对齐,如英语、法语、德语、西班牙语等之间的对齐。其基本假设是,长的原文句子对应着长的译文句子,短的原文句子对应着短的译文句子。由于对齐几乎没有使用到任何语言知识(完全将句子看成符号串),该方法具有很强的适应性。该方法在英语—西班牙语双语对其中,成功率达到了93.2%,在英语—法语双语对齐中,成功率达到了98%;然而,当该方法用于差异较大的语系时,效果则不理想,Wu等人[10]曾经用相同的算法进行汉语—英语的句子对齐,对新闻语料集测试,成功率仅为54.5%,对香港科技大学的预料(HKUST corpus)测试,成功率为 86.4% 。 方法二,基于锚点的对齐方法。其主要思想是寻找特殊标记进行对齐。如,双语中相同的数字(数值)、地名、人名、日期等。一旦原文有,译文也应该有。 z 双语的表示形式 双语的表示有多种形式,最简单的形式是符号串,这对于中文来说,就是汉字串。显然,这过于简单;因此,通常情况下,用词串表示。也可以对语料进一步加工,如附带上词性,甚至可以对对齐的语料进行结构分析,使之在结构上也对齐。但结构分析需要有好的分析器,这本身又非常困难。 z 双语的存储形式 为了覆盖更多的语言现象,就必需收集尽可能多的双语实例。但另一方面,当实例库足够大时,快速检索相似的例子就成为一个重要的问题。为了从大规模的实例库中检索到相似实例,大多采用倒排表技术。 4.2 相似实例的检索 相似实例的检索主要是相似性的判断,而相似性的判断与实例的表示形式有着密切的关系。根据表示形式的不同,相似性的判断主要可以分为如下几种: z 基于字符 (Character-based) 的匹配 基于字符的匹配纯粹是一种表层的匹配, 即,判断两个串中公共子串的相对长度(中文中的一个字符由两个字节表示),相同串必须是有序的。先看如下例子: 例 4.1 (a) 从 上海 到 美国 的 西部 城市 洛杉矶。
(b) 从 美国 的 西部 城市 洛杉矶 到 上海。 尽管例子 (a)(b) 包含完全相同的词,但从字符串的角度看,则不是完全相同的——相同部分已经用下划线表示。其长度可以以字符(汉字)为单位计数,也可以以词为单位计数。从上面的例子来看,这种方法显然存在问题。匹配的部分本来应该是“ 从 …… 到 ”。 基于字符匹配的相似性,主要通过编辑距离(edit distance)判断。这种方法最早是由 Wagner & Fisher 提出来的,它量度了一个字符串S=s1s2…sm变化为另一个字符串T=t1t2…tn所