事件预测及因子识别动态模拟模型建模方法及系统与制作流程
- 格式:pdf
- 大小:450.20 KB
- 文档页数:21

预测模型研究利器-列线图(Logistic回归)背景Background在临床中,预测模型⼗分重要。
正如第⼀节(医⽣必备技能,万字长⽂让你明⽩临床模型研究应该如何做)所阐明的,如果我们能提前预测病⼈的病情,很多时候我们可能会做出完全不同的临床决定。
⽐如,对于肝癌患者,如果能提前预测是否有微⾎管浸润,可能有助于外科医⽣在标准切除和扩⼤切除之间做出选择。
术前新辅助放疗和化疗是T1-4 N+中低位直肠癌的标准治疗⽅法。
然⽽,在临床实践中发现,根据术前影像学检查判断淋巴结状态不够准确,假阳性或假阴性的⽐例很⾼。
那么我们是否有可能在放疗和化疗前根据已知的特征准确地预测患者的淋巴结状况?如果我们能够建⽴这样的预测模型,我们就可以更准确地做出临床决策,避免因误判⽽导致的不正确决策。
越来越多的⼈开始意识到这个问题的重要性。
⽬前,很多⼈已经付出了巨⼤的努⼒来构建预测模型或改进现有的预测⼯具,在这其中,Nomogram的构造是当前最热门的研究⽅向之⼀。
下⾯,我们再来说说Logistic回归。
什么时候选择Logistic回归来建⽴预测模型与建⽴的临床结果有关。
如果结果是⼆分类变量、⽆序分类变量或有序变量(总⽽⾔之就是分类变量),我们可以选择Logistic回归来构建模型。
⽆序Logistic回归和有序Logistic回归⼀般应⽤于⽆序、多分类或有序变量结果,其结果难以解释。
因此,我们通常将⽆序多分类或有序的变量转换为⼆分类变量,并使⽤⼆分Logistic回归来构建模型。
上述“肝癌是否有微⾎管浸润”和“直肠癌前淋巴结转移复发”均属于⼆分法结果。
⼆分Logistic回归最常⽤于构建、评估和验证预测模型。
⾃变量的筛选原则与第2节(【临床研究】⼀个你⽆法逃避的问题:多元回归分析中的变量筛选)描述的原则是⼀致的,另外需要考虑两点:⼀⽅⾯要权衡模型包含的样本量和⾃变量个数;另⼀⽅⾯还要权衡模型的准确性和使⽤模型的便捷性,最终确定进⼊预测模型的⾃变量个数。

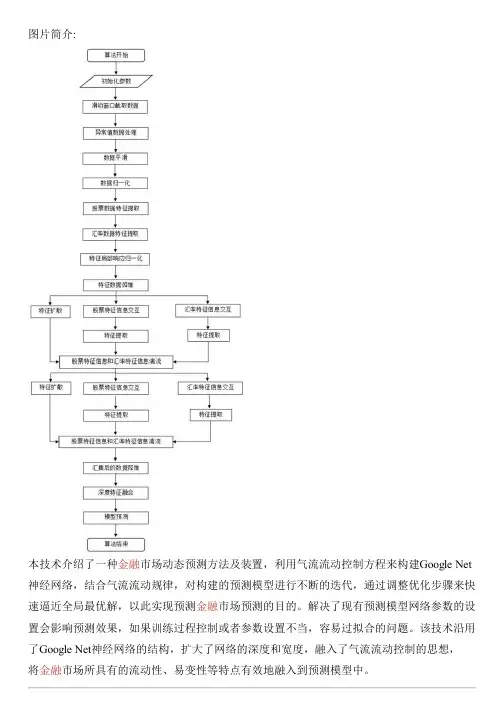
图片简介:本技术介绍了一种金融市场动态预测方法及装置,利用气流流动控制方程来构建Google Net 神经网络,结合气流流动规律,对构建的预测模型进行不断的迭代,通过调整优化步骤来快速逼近全局最优解,以此实现预测金融市场预测的目的。
解决了现有预测模型网络参数的设置会影响预测效果,如果训练过程控制或者参数设置不当,容易过拟合的问题。
该技术沿用了Google Net神经网络的结构,扩大了网络的深度和宽度,融入了气流流动控制的思想,将金融市场所具有的流动性、易变性等特点有效地融入到预测模型中。
技术要求1.一种金融市场动态预测方法,其特征在于:包括以下步骤:S1、由第一金融数据进行数据预处理得到第二金融数据;S2、由第二金融数据进行特征提取得到第一股票数据特征和第一汇率数据特征,由第一股票数据特征进行数据降维得到第一股票特征信息,由第一汇率数据特征进行数据降维得到第一汇率特征信息;S3、由第一股票特征信息和第一汇率特征信息进行特征扩散得到第一扩散特征,由第一股票数据特征进行信息交互得到股票交互数据,由第一汇率数据特征进行信息交互得到汇率交互数据;S4、由股票交互数据进行特征提取得到第二股票数据特征,由汇率交互数据进行特征提取得到第二汇率数据特征,由第一扩散特征、第二股票数据特征和第二汇率数据特征进行数据融合得到第一融合数据;S5、由第一融合数据降维得到第二融合数据;S6、由第二融合数据进行深度特征融合得到预测模型,根据预测模型输出预测结果。
2.根据权利要求1所述的一种金融市场动态预测方法,其特征在于:步骤S1中由第一金融数据进行数据预处理得到第二金融数据的方法包括以下步骤:S101、准备第一金融数据,将构建的预测模型中的超参数变量用高斯正态分布初始化,超参数常量初始化为0;S102、采用滑动窗口技术从第一金融数据中获取金融业务数据,金融业务数据对进行异常值处理和降噪处理;S103、由步骤S102进行异常值处理和降噪处理后的金融业务数据进行归一化处理得到数据范围为0到1的第二金融数据。

实用第一f智慧密集■BBaSEIEieSI3l3BBI3SeSBI3BBEIISBBBI3BI9@SI3eSI3aiSieEISeBI3ei3iaEIBBeBI3BaEIEII3SS@ieEl®灰色GM(1,N)预测模型编程实现及应用检验王成(江苏省阜宁县东沟病虫测报站,江苏盐城224400)摘要:灰色GM(1,N)预测模型在社会、经济、农业、生态等诸多领域应用十分广泛。
为推广使用该预测模型,依据邓聚龙教授的灰色理论,使用VC++编程实现GM(1,N)预测模型,实现了多个预测因子和多个关联因子同时进行分析,提高了使用效率,择优选择算法提高了分析精度。
使用参考文献中的数据和模拟数据,对系统预测模型正确性和预测精度进行了检验。
关键词:灰色系统;GM(1,N)模型;VC编程;多关联因子1概述在对社会、经济、农业、工业控制等灰色数据领域进行研究的主要任务是分析、建模、预测、决策和控制。
根据邓聚龙教授在20世纪80年代提出的灰色理论,其典型的灰色预测模型(GREY MODEL)是GM (1,1)模型和GM(1,N)模型。
而在实际研究中,往往对一个因子(研究对象)的研究会要考虑其他多个关联因子。
女口:农业领域中病虫害发生会与病虫害基数、雨量、日照、气温、耕作制度等密切相关。
因此灰色GM (1,N)模型的应用显得更加广泛。
假设研究对象是在一定范围分布的灰色量,同时其数据序列或经累加(AGO)生成后的数据序列是呈线性 分布的,或者在线性范围内是收敛的,对于单个变量,用GM(1,1)模型构建一阶微分方程,多个变量时使用GM(1,N)模型构建多阶一次微分方程。
通过现有数据序列,经过矩阵构造、矩阵计算等方法,求解各变量因子的参数,并将数据序列和参数带回到微分方程,得出模型计算值后,再通过累减(IAGO)生成还原数值,经与原始数据进行比较,得出模型预测值的精度。
这就是GM(1,N)模型。
2GM(1,N)模型假设「一为系统预测的个数据序列(子因子),上标用(0)表示原始值,用(1)表示1次累加值。


复杂系统建模与分析的方法与技术随着信息时代的到来,我们生活在的世界变得越来越复杂,人们需要处理的信息量日益增加,这些信息涉及到的系统也变得越来越复杂。
在这种情况下,对复杂系统的建模和分析越来越受到关注,因为它可以帮助我们更好地理解系统的本质和规律,以便更好地管理和优化它们的运作。
复杂系统建模与分析的方法和技术是一个广泛的领域,包括数学、物理、计算机科学、统计和工程等各种学科。
在建模和分析复杂系统时,我们需要考虑到很多因素,包括系统的结构、行为和环境等。
通常来说,我们可以把建模和分析复杂系统的方法分为以下几个方面:1. 系统辨识系统辨识是建模和分析复杂系统的第一步,它旨在确定系统的结构和行为。
在这个阶段,我们需要收集和分析系统的数据,以便确定系统的特征和模式。
常见的系统辨识方法包括因子分析、主成分分析、独立成分分析、小波分析等。
2. 系统建模系统建模是在系统辨识的基础上,将系统的结构和行为用数学模型表示出来。
常见的系统建模方法包括线性模型、非线性模型、稳态模型、动态模型等。
这些模型可以用于描述系统的状态、进程和结果,从而更好地理解系统的行为和规律。
3. 建模验证建模验证是验证系统模型是否能够准确地预测系统的行为和结果。
在建模验证阶段,我们将系统模型和实际数据进行比较,以检验模型的适用性和准确性。
建模验证的常见方法包括残差分析、交叉验证、信息准则等。
4. 模型优化当我们发现系统模型不能够很好地预测系统行为或结果时,就需要对模型进行优化。
模型优化的目标是提高模型的准确性和适用性,以更好地描述系统的结构和行为。
常见的模型优化方法包括参数估计、模型选择、正则化方法等。
5. 模型应用当我们建立了一个合适的模型,并且对其进行了验证和优化之后,就可以开始将模型应用于研究和决策。
模型应用可以帮助我们更好地理解和管理系统,从而提高其效率和可靠性。
常见的模型应用方法包括风险管理、决策分析、优化和控制等。
总的来说,建模和分析复杂系统的方法和技术是多种多样的,但是它们的目标都是帮助我们更好地理解和管理复杂系统。

灾害事件的情报分析与预测模型研究第一章灾害事件的背景介绍灾害事件是指不可预测的自然、人为或社会因素引起的、导致人员、财产等方面受到严重影响或破坏的事件。
灾害事件的发生对社会和个人都会带来不可估量的损失,如人员伤亡、经济损失等。
因此,如何及时准确地进行灾害事件情报分析和预测,对于应对灾害事件、减少损失具有重要意义。
第二章灾害事件情报分析灾害事件情报分析是基于收集的灾害事件信息,通过对数据分析、模式识别、因果分析等方法,进行分析和研判,从而为灾害事件的预测及应对提供科学的依据。
2.1 数据收集数据收集是灾害事件情报分析的第一步,目的是获取事件的基本信息和趋势,为后续分析提供数据基础。
数据来源可以从多个渠道获取,如政府部门、新闻媒体、社交媒体、应急机构等。
2.2 数据分析数据分析是灾害事件情报分析的核心内容,主要包括统计分析、模糊识别、异常检测、时间序列分析等。
在数据分析过程中,需要结合灾害事件的历史数据,进行综合分析。
同时,还需要针对不同的灾害类型,采用不同的分析方法。
2.3 模式识别模式识别是指通过对灾害事件的历史数据分析,寻找规律和模式,并将其应用于灾害事件的预测。
通过模式识别,可以为应对灾害事件提供科学的依据。
2.4 因果分析因果分析是指通过对灾害事件的各种因素进行分析,找出灾害事件产生的原因和影响因素。
在进行因果分析时,需要综合考虑各种因素和相互影响的关系。
第三章灾害事件预测模型灾害事件预测模型是指根据灾害事件情报分析的结果,利用数学及计算机技术进行建模,对灾害事件的发生、发展趋势进行预测。
3.1 统计模型统计模型是根据历史数据,采用数理统计学方法进行建模,并对未来可能出现的灾害事件进行预测。
统计模型包含时间序列模型、回归模型、决策树模型等。
3.2 机器学习模型机器学习模型是利用计算机技术和人工神经网络等模型,对灾害事件进行预测。
机器学习模型包含神经网络模型、支持向量机模型、集成学习模型等。

图片简介:本技术提供了一种事件预测及因子识别动态模拟模型建模方法及系统,包括:步骤S1:确立需要监测和评估的事件属性,以及相应的指标算式;步骤S2:建立动态数字模拟流程图;步骤S3:建立批次数据;步骤S4:形成配置文件;步骤S5:将数据和配置文件导入算法平台,进行运算,并生成结果;步骤S6:模型应
用。本技术的事件预测及因子识别动态模拟模型通过其独有的建模设计和算法,解决了对产品制造业的离散型随机序列数据进行分析和建模的疑难问题,从而是对建模方法的基础性创新,将在产品制造业获得广泛的应用。
技术要求1.一种事件预测及因子识别动态模拟模型建模方法,其特征在于,包括:
步骤S1:确立需要监测和评估的事件属性,以及相应的指标算式;步骤S2:建立动态数字模拟流程图;步骤S3:建立批次数据;步骤S4:形成配置文件;步骤S5:将批次数据和配置文件导入算法平台,进行运算,并生成模拟模型;步骤S6:应用生成的模拟模型。2.根据权利要求1所述的事件预测及因子识别动态模拟模型建模方法,其特征在于,所述步骤S1包括:
步骤S101:确立监测、预测和进行因子分析所针对的事件:步骤S102:确立目标指标的计算公式;所述监测、预测和进行因子分析所针对的事件包括:质检机质检过程中次品的出现;所述质检机质检包括:生产线上质检和生产线下批检;所述生产线上质检:工件按照在生产中被完成的时间顺序进入质检机;质检机被用来实时识别质差产品、质差类别,并对质差产品的数目以及良品的数目进行实时计数;最终的总产出数目=良品数目+次品数目;
所述生产线下批检:成批的已完成工件依次进入质检机,排序与生产顺序无关,并为非实时;工件进入质检机后,质检机被用来实时识别质差产品、质差类别,并对质差产品的数目以及良品的数目进行实时计数;最终的总产出数目=良品数目+次品数目;
所述目标指标的计算公式包括针对次品率的指标和算式:总体次品率=次品数目/总产出数目;分类次品率=分类次品数目/总产出数目。3.根据权利要求1所述的事件预测及因子识别动态模拟模型建模方法,其特征在于,所述步骤S2包括:
步骤S201:建立动态模拟流程图:步骤S202:建立特征分类格栅;所述步骤S201:以流程图的方式展示需要进行建模的指标以及数量或规模变量;所述指标是比率,包括:次品率;所述变量包括:次品数目,良品数目。步骤S202:格栅中对分类维度的选择有两个依据,包括:业务决策的需要、数据中可能对目标指标产生影响的其他变量;
所述其他变量包括:产品种类、生产线、班组、工艺、材料、添加剂、公差以及生产环境变量。
4.根据权利要求1所述的事件预测及因子识别动态模拟模型建模方法,其特征在于,所述步骤S3包括:步骤S301:建立初始表:步骤S302:建立指标表现跟踪表:步骤S303:数据采集、清洗和标准化;所述初始表对应于特征分类格栅表,记录每个批次与格栅的对应,以及批次的生产起始时间,计划产量或最终实际产量;
所述指标表现跟踪表记录每个批次在细分时间间隔上的表现;所述步骤S303:对流程图中所涉及的变量,原始字段需要从数据库或设备端获取;建模前进行数据的清洗和标准化。5.根据权利要求1所述的事件预测及因子识别动态模拟模型建模方法,其特征在于,所述步骤S4:
所述配置文件指将流程图中的信息发送给软件平台;软件平台是通用动态模拟工具,可以适配任何流程设计,而配置文件就是将通用动态模拟工具用于个性化流程图的媒介。
6.根据权利要求1所述的事件预测及因子识别动态模拟模型建模方法,其特征在于,所述步骤S5:
对于流程图中的任何一个指标,用两种时间形式来表达,即:rvi(otvi,t) (1)或者是rvi(otvi,avi) (2)其中avi=t-otvi表达式中使用r来表示目标指标,包括次品率;vi表示任何一个生产批次,即第i个批次;otvi用来标注这个批次的开始时间;
rvi(otvi,t)所显示的,是以日历时间t来计数时间的流逝,而rvi(otvi,avi)所显示的,是以增龄avi来计数时间
的流逝;
由于两个时间轴的转换对于任何既定的批次都是一对一的关系,即公式(2),即增龄(月份数)=日历时间-初始时间,所以公式(1)中的两个表述形式是等同的。
技术说明书事件预测及因子识别动态模拟模型建模方法及系统技术领域本技术涉及产品制造技术领域,具体地,涉及事件预测及因子识别动态模拟模型建模方法及系统。尤其地,涉及针对产品制造中随机离散序列变量的一种基本建模 方法。
背景技术Multiple Time-Dimension Simulation Models and Lifecycle DynamicScoring System是美国Dynamic SimulationSystems LTD公司的Ruizhi Bu和 YuanyuanPeng在美国共同申请并已公开的专利申请。
上述专利申请中创建的评分方法,所针对的是0/1型结果数据。本专利申请中 的建模方法,针对的是产品制造行业中最为常见的离散型随机序列数据。
技术内容针对现有技术中的缺陷,本技术的目的是提供一种事件预测及因子识别动态模拟模型建模方法及系统。根据本技术提供的一种事件预测及因子识别动态模拟模型建模方法,包括:步骤S1:确立需要监测和评估的事件属性,以及相应的指标算式;步骤S2:建立动态数字模拟流程图;步骤S3:建立批次数据;步骤S4:形成配置文件;步骤S5:将批次数据和配置文件导入算法平台,进行运算,并生成模拟模型;步骤S6:应用生成的模拟模型。优选地,所述步骤S1包括:步骤S101:确立监测、预测和进行因子分析所针对的事件:步骤S102:确立目标指标的计算公式;所述监测、预测和进行因子分析所针对的事件包括:质检机质检过程中次品的出现;所述质检机质检包括:生产线上质检和生产线下批检;所述生产线上质检:工件按照在生产中被完成的时间顺序进入质检机;质检机被用 来实时识别质差产品、质差类别,并对质差产品的数目以及良品的数目进行实时计数;最终的总产出数目=良品数目+次品数目;
所述生产线下批检:成批的已完成工件依次进入质检机,排序与生产顺序无关,并为非实时;工件进入质检机后,质检机被用来实时识别质差产品、质差类别,并对质差 产品的数目以及良品的数目进行实时计数;最终的总产出数目=良品数目+次品数 目;
所述目标指标的计算公式包括针对次品率的指标和算式:
总体次品率=次品数目/总产出数目;分类次品率=分类次品数目/总产出数目。优选地,所述步骤S2包括:步骤S201:建立动态模拟流程图:步骤S202:建立特征分类格栅;所述步骤S201:以流程图的方式展示需要进行建模的指标以及数量或规模变量;所述指标是比率,包括:次品率;所述变量包括:次品数目,良品数目。步骤S202:格栅中对分类维度的选择有两个依据,包括:业务决策的需要、数据中可能对目标指标产生影响的其他变量;
所述其他变量包括:产品种类、生产线、班组、工艺、材料、添加剂、公差以及生 产环境变量。优选地,所述步骤S3包括:步骤S301:建立初始表:步骤S302:建立指标表现跟踪表:步骤S303:数据采集、清洗和标准化;所述初始表对应于特征分类格栅表,记录每个批次与格栅的对应,以及批次的生产 起始时间,计划产量或最终实际产量;
所述指标表现跟踪表记录每个批次在细分时间间隔上的表现;所述步骤S303:对流程图中所涉及的变量,原始字段需要从数据库或设备端获取;建模前进行数据 的清洗和标准化。优选地,所述步骤S4:所述配置文件指将流程图中的信息发送给软件平台;软件平台是通用动态模拟工具, 可以适配任何流程设计,而配置文件就是将通用动态模拟工具用于个性化流程图的媒介。
优选地,所述步骤S5:对于流程图中的任何一个指标,用两种时间形式来表达,即:rvi(otvi,t)(1)或者是rvi(otvi,avi)(2)其中avi=t-otvi表达式中使用r来表示目标指标,包括次品率;vi表示任何一个生产批次,即第i个批次;otvi用来标注这个批次的开始时间;
rvi(otvi,t)所显示的,是以日历时间t来计数时间的流逝,而rvi(otvi,avi)所显 示的,是以增龄avi来计数时间
的流逝;
由于两个时间轴的转换对于任何既定的批次都是一对一的关系,即公式(2),即增龄(月份数)=日历时间-初始时间,所以公式(1)中的两个表述形式是等同的。
与现有技术相比,本技术具有如下的有益效果:本技术的事件预测及因子识别动态模拟模型通过其独有的建模设计和算法,解决了对产品制造业的离散型随机序列数据进行分析和建模的疑难问题,从而是对建 模方法的基础性创新,将在产品制造业获得广泛的应用。
附图说明通过阅读参照以下附图对非限制性实施例所作的详细描述,本技术的其它特征、目的和优点将会变得更明显:
图1为本技术提供的模型的功用示意图。图2为本技术提供的样本中对被解释变量的计算示意图。图3为本技术提供的样本中的解释变量示意图。图4为本技术提供的对样本数目的计算示意图。图5为本技术提供的对业绩指标和规模变量进行同时建模流程示意图。图6为本技术提供的特征分类格栅–决策的维度和各个维度中的选项示意图。图7为本技术提供的初始表的结构与内容示意图。图8为本技术提供的生产表现跟踪表的结构与内容示意图。图9为本技术提供的对事件预测及因子识别动态模拟模型建模方法的展示示意图。图10为本技术提供的批次数据过少的情形示意图。图11为本技术提供的批次数据充分的情形示意图。图12为本技术提供的将全(所有)维度建模降维到单一因素建模示意图。具体实施方式下面结合具体实施例对本技术进行详细说明。以下实施例将有助于本领域的技术人 员进一步理解本技术,但不以任何形式限制本技术。应当指出的是,对本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变化和改进。这些都属于 本技术的保护范围。
根据本技术提供的一种事件预测及因子识别动态模拟模型建模方法,包括:步骤S1:确立需要监测和评估的事件属性,以及相应的指标算式;步骤S2:建立动态数字模拟流程图;步骤S3:建立批次数据;步骤S4:形成配置文件;步骤S5:将数据和配置文件导入算法平台,进行运算,并生成结果;步骤S6:模型应用。具体地,所述步骤S1包括: