存储器地址映射
- 格式:doc
- 大小:26.00 KB
- 文档页数:2

S7-200 通过以下方式支持Modbus 通信协议:。
S7-200 CPU 上的通信口0(Port 0)通过指令库支持Modbus RTU 从站模式。
S7-200 CPU 上的通讯口0 和1 (Port 0 和Port 1)通过指令库支持Modbus RTU 主站模式。
S7-200 CPU 通过EM241 模块的Modem 接口支持Modbus RTU 模式通过S7-200 CPU 通信口的自由口模式实现Modbus 通信协议,可以通过无线数据电台等慢速通信设备传输。
这为组成S7-200 之间的简单无线通信网络提供了便利。
详细情况请参考《S7-200系统手册》(2002 年10 月或以后版本)的相应章节。
Modbus 是公开通信协议,其最简单的串行通信部分仅规定了在串行线路的基本数据传输格式,在OSI 七层协议模型中只到1,2 层。
Modbus 具有两种串行传输模式,ASCII 和RTU。
它们定义了数据如何打包、解码的不同方式。
支持Modbus 协议的设备一般都支持RTU 格式。
通信双方必须同时支持上述模式中的一种。
Modbus 是一种单主站的主/从通信模式。
Modbus 网络上只能有一个主站存在,主站在Modbus 网络上没有地址,从站的地址范围为0 - 247,其中0 为广播地址,从站的实际地址范围为1 - 247。
Modbus 通信标准协议可以通过各种传输方式传播,如RS232C、RS485、光纤、无线电等。
在S7-200 CPU 通信口上实现的是RS485 半双工通信,使用的是S7-200 的自由口能。
详细的协议和规范,请访问Modbus 组织的网站:西门子在Micro/WIN V4.0 SP5 中正式推出Modbus RTU 主站协议库(西门子标准库指令)。
注意:1. Modbus RTU 主站指令库的功能是通过在用户程序中调用预先编好的程序功能块实现的,该库对Port 0 和Port 1 有效。

MMU所起的作用
一、名词解释
①逻辑地址(虚拟地址)
用户程序经编译、链接以后形成的每条指令或数据单元的地址,这些地址都是相对于某个基地址来编制的。
②逻辑地址空间
某个用户程序的虚拟地址的集合。
③物理地址(绝对地址)
处理机能直接访问的存储器地址。
④物理地址空间
物理地址空间是指进程在内存中一系列存储信息的物理单元的集合。
物理地址空间也叫存储空间,存储空间与地址空间既相互关联,又相互独立,是内存管理的核心概念。
二、MMU所起的作用
1.内存分配和回收
使各作业或进程各得其所
2.内存保护
内存保护就是确保多个进程都在各自分配到内存区域内操作,互不干扰,防止一个进程破坏其他进程的信息。
3.内存扩充
内存“扩充”包含了存储器利用的提高和扩充两方面的内容。
为用户提供比内存物理空间大得多的地址空间。
比较典型的内存扩充是虚拟存储器。
4.地址映射
地址映射就是将进程的逻辑地址变换为内存中的物理地址。
我们需要实现从逻辑地址到物理地址的变换,即实现从虚地址到实地址的变换。
这种变换就是重定位。


简述直接映射,全相联映射,组相联映射的优缺点直接映射、全相联映射和组相联映射是计算机存储器中用于映射主存地址到缓存地址的三种主要技术。
这三种映射技术各有优缺点,下面将对它们进行简要说明。
1. 直接映射:直接映射是最简单的映射技术,将主存中的每个存储块映射到缓存中的固定位置。
例如,一个具有16个存储块的主存,可以被映射到一个具有8个存储块的缓存中。
在直接映射中,主存地址的一部分用于确定缓存中的位置,而另一部分用于确定在这个位置上存储的数据。
优点:- 简单易理解和实现。
- 可以利用处理器的局部性原理,减少缓存失效的概率。
缺点:- 缓存利用率低,因为可能会出现多个存储块映射到缓存中的同一个位置,导致缓存冲突。
- 缓存冲突可能会导致性能下降,因为处理器可能需要等待缓存读写操作完成。
2. 全相联映射:全相联映射将主存中的每个存储块映射到缓存中的任意位置。
在全相联映射中,主存地址的一部分用于确定缓存中的位置,而另一部分用于确定在这个位置上存储的数据。
优点:- 不存在缓存冲突,因为每个存储块都可以映射到缓存的任意位置。
- 缓存利用率高,因为存储块可以更灵活地映射到缓存中。
缺点:- 相对复杂,需要额外的硬件支持来实现全相联映射。
- 性能开销较大。
3. 组相联映射:组相联映射结合了直接映射和全相联映射的优点,将主存中的存储块划分为多个组,然后在每个组内进行全相联映射。
优点:- 兼具直接映射和全相联映射的优点。
- 较高的缓存利用率,减少缓存失效的概率。
缺点:- 较复杂,并需要更多的硬件支持。
- 某些特定的存储块可能会映射到同一个组中,导致缓存冲突。
总结:- 直接映射技术简单易实现,但缓存利用率较低且容易发生缓存冲突。
- 全相联映射技术不存在缓存冲突,但实现较为复杂,性能开销较大。
- 组相联映射技术结合了直接映射和全相联映射的优点,具有较高的缓存利用率和较低的冲突率,但也增加了一定的硬件开销。
参考内容:- 《计算机系统设计与优化》- 李春阳,机械工业出版社,2018年- 《计算机组成与设计:硬件/软件接口》- David A. Patterson、John L. Hennessy,机械工业出版社,2017年- 《计算机体系结构》- 现代教材编写组,清华大学出版社,2014年。

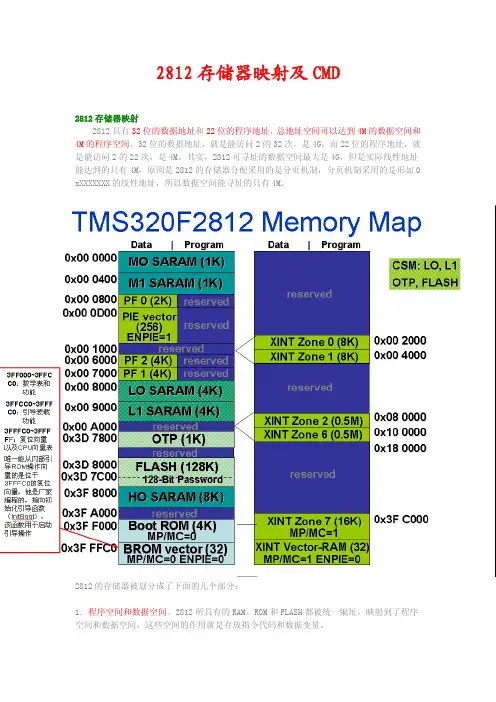
2812存储器映射及CMD2812存储器映射2812具有32位的数据地址和22位的程序地址,总地址空间可以达到4M的数据空间和4M的程序空间。
32位的数据地址,就是能访问2的32次,是4G,而22位的程序地址,就是能访问2的22次,是4M。
其实,2812可寻址的数据空间最大是4G,但是实际线性地址能达到的只有4M,原因是2812的存储器分配采用的是分页机制,分页机制采用的是形如0 xXXXXXXX的线性地址,所以数据空间能寻址的只有4M。
2812的存储器被划分成了下面的几个部分:1. 程序空间和数据空间。
2812所具有的RAM、ROM和FLASH都被统一编址,映射到了程序空间和数据空间,这些空间的作用就是存放指令代码和数据变量。
2. 保留区。
数据空间里面某些地址被保留了,作为CPU的仿真寄存器使用,这些地址是不向用户开放的。
3.CPU中断向量。
在程序空间里也保留了64个地址作为CPU的32个中断向量。
通过CPU寄存器ST1中的VMAP位来将这一段地址映射到程序空间的底部或者顶部。
映射和空间的统一编址F2 812内部的映射空间低地址空间高地址空间2812CMD详解CMD:command命令,顾名思义就是命令文件指定存储区域的分配.2812的CMD采用的是分页制,其中PAGE0用于存放程序空间,而PAGE1用于存放数据空间。
1.)#pragma ,CODE_SECTION和DATA_SECTION伪指令#pragma DATA_SECTION(funcA,"dataA"); ------ 函数外声明将funcA数据块定位于用户自定义的段"dataA"中 ------ 需要在CMD中指定dataA段的物理地址2.)MEMORY和SECTIONS是命令文件中最常用的两伪指令。
MEMORY伪指令用来表示实际存在目标系统中的可以使用的存储器范围,在这里每个存储器都有自己的名字,起始地址和长度。

主存与Cache的地址映射CPU对存储器的访问,通常是一次读写一个字单元。
当CPU访Cache不命中时,需将存储在主存中的字单元连同其后若干个字一同调入Cache中,之所以这样做,是为了使其后的访存能在Cache中命中。
因此,主存和Cache之间一次交换的数据单位应该是一个数据块。
数据块的大小是固定的,由若干个字组成,且主存和Cache的数据块大小是相同的。
从Cache-主存层次实现的目标看,一方面既要使CPU的访存速度接近于访Cache的速度,另一方面为用户程序提供的运行空间应保持为主存容量大小的存储空间。
在采用Cache-主存层次的系统中,Cache对用户程序而言是透明的,也就是说,用户程序可以不需要知道Cache的存在。
因此,CPU每次访存时,依然和未使用Cache的情况一样,给出的是一个主存地址。
但在Cache-主存层次中,CPU首先访问的是Cache,并不是主存。
为此,需要一种机制将CPU的访主存地址转换成访Cache地址。
而主存地址与Cache地址之间的转换是与主存块与Cache块之间的映射关系紧密联系的,也就是说,当CPU访Cache未命中时,需要将欲访问的字所在主存中的块调入Cache中,按什么样的策略调入,直接影响到主存地址与Cache地址的对应关系,这也就是本小节要解决的主存与Cache的地址映射问题。
主要有三种地址映射方式,分别为全相联映射、直接相联映射和组相联映射。
1. 全相联映射全相联映射是指主存中任一块都可以映射到Cache中任一块的方式,也就是说,当主存中的一块需调入Cache时,可根据当时Cache的块占用或分配情况,选择一个块给主存块存储,所选的Cache块可以是Cache中的任意一块。
例如,设Cache共有2C块,主存共有2M块,当主存的某一块j需调进Cache中时,它可以存入Cache的块0、块1、…、块i、… 或块2C -1的任意一块上。
如图4-28所示。

HMI和PLC地址映射关系PLC存储器和HMI地址映射关系 PLC HMI%MX0.7…%MX0.0 %MB0%MW0%MD0%MD0%MW0%MW0:X7…%MW0:X0%MX1.7…%MX1.0 %MB1 %MW0:X15…%MW0:X8%MX2.7…%MX2.0 %MB2%MW1%MD1%MW1%MW1:X7…%MW1:X0%MX3.7…%MX3.0 %MB3 %MW1:X15…%MW1:X8%MX4.7…%MX4.0 %MB4%MW2%MD1%MD2%MW2%MW2:X7…%MW2:X0%MX5.7…%MX5.0 %MB5 %MW2:X15…%MW2:X8%MX6.7…%MX6.0 %MB6%MW3%MW3%MW3:X7…%MW3:X0%MX7.7…%MX7.0 %MB7 %MW3:X15…%MW3:X8HMI Control存储器的双⼦与PLC存储的双字之⽐为2如:HMI Control的%MD2存储器区域与PLC的%MD1存储器区域对应HMI Control的%MD20存储器区域与PLC的%MD10存储器区域对应HMI Control的%MW0:9存储器区域与PLC的%MX1.1存储器区域对应,因为PLC存储器中的简单⼦分为2个不通同的字节。
最近有些“⼤虾”使⽤Somachine时,程序编写得特别有“个性”,PLC存储器出现了%MX0.119,%MX0.100,%MX0.319,%MX1.100,%MX2.100,编写到此时问题就出现了,这些变量所对应的HMI地址映射关系呢?经过试验测试,总结出以下“⾮官⽅”规律:1、%MX0.119所对应的HMI地址为=7…7 %MX0.119→%MW7:X7=6…4 %MX0.100→%MW6:X4=19…15 %MX0.319→%MW19:X152、%MX1.100所对应的HMI地址为=6…4 %MX1.100→%MW6:X4+1x(X8)= %MW6:X4+X8=%MW6:X12%MX1.100→%MW6:X123、%MX2.100所对应的HMI地址为=6…4 %MX2.100→%MW6:X4+2x(X8)= %MW6:X4+X16=%MW7:X4 %MX2.100→%MW7:X4。

1.内存管理和MMU当ARM 要访问存储器时,MMU 先查找TLB(Translation Lookaside Buffer,旁路转换缓冲)中的虚拟地址表。
如果TLB 中没有虚拟地址的入口,则转换表遍历硬件会从存放在内存的转换表中获得转换和访问器权限。
一旦取到,这些信息将被放到TLB 中,这时访问存储器的TLB 入口就拿到了。
在TLB 中其实包含了以下信息:1)控制决定是否使用高速缓冲2)访问权限信息3)在有cache 的系统中,如果cache 没有命中,那么物理地址作为线性获取(line fetch)硬件的输入地址。
如果命中了cache 那么数据直接从cache 中得到,物理地址被忽略。
ARM 的工作流程可用下图表示:这种机制是纯粹的高速硬件操作,并不需要操作系统来完成。
操作系统只要提供内存转换表就可以了,但是需要符合一定的格式。
ARM9 的MMU 映射表分为两种,一级页表的变换和二级页表变换。
两者的不同之处就是实现的变换地址空间大小不同。
一级页表变换支持1 M 大小的存储空间的映射,而二级可以支持64 kB,4 kB 和1 kB 大小地址空间的映射。
在LINUX 中最终使用了1 M 一级页表和4 kB 的二级页表(即 1M段区和4KB页面)内核中地址转换表建立过程地址转换表建立是和内核的启动一起完成的,页表的建立也可以分为三个阶段:第一阶段是发生在内核解压缩、自引导时,也就内核镜像zimage 的文件头部分。
相关代码从某种意义上来讲不属于内核,它是BSP 代码中的一部分,是需要根据不同的架构来分别实现的。
通过平面映射的方式建立了256M 空间节描述表。
但是,这个映射表是临时的,是为了提高内核解压缩时的速度而实现的。
在解压缩结束之后,进入内核代码之前,MMU 功能就被关闭了,随之的映射表也被废弃不用。
当decompress_kernel 函数实现内核的解压缩之后,那么内核启动的第一阶段工作就完成了。


s3c2440地址空间的分配s3c2440启动过程详解一:地址空间的分配1:s3c2440是32位的,所以可以寻址4GB空间,内存(SDRAM)和端口(特殊寄存器),还有ROM都映射到同一个4G空间里.2:开发板上一般都用SDRAM做内存flash(nor、nand)来当做ROM。
其中nand flash 没有地址线,一次至少要读一页(512B).其他两个有地址线3:norflash不用来运行代码,只用来存储代码,NORflash,SDRAM可以直接运行代码)4:s3c2440总共有8个内存banks6个内存bank可以当作ROM或者SRAM来使用留下的2个bank除了当作ROM 或者SRAM,还可以用SDRAM(各种内存的读写方式不一样)7个bank的起始地址是固定的还有一个灵活的bank的内存地址,并且bank大小也可以改变5:s3c2440支持两种启动模式:NAND和非NAND(这里是nor flash)。
具体采用的方式取决于OM0、OM1两个引脚OM[1:0所决定的启动方式OM[1:0]=00时,处理器从NAND Flash启动OM[1:0]=01时,处理器从16位宽度的ROM启动OM[1:0]=10时,处理器从32位宽度的ROM启动。
OM[1:0]=11时,处理器从Test Mode启动。
当从NAND启动时cpu会自动从NAND flash中读取前4KB的数据放置在片内SRAM里(s3c2440是soc),同时把这段片内SRAM映射到nGCS0片选的空间(即0x00000000)。
cpu 是从0x00000000开始执行,也就是NAND flash里的前4KB内容。
因为NAND FLASH 连地址线都没有,不能直接把NAND映射到0x00000000,只好使用片内SRAM做一个载体。
通过这个载体把nandflash中大代码复制到RAM(一般是SDRAM)中去执行当从非NAND flash启动时nor flash被映射到0x00000000地址(就是nGCS0,这里就不需要片内SRAM来辅助了,所以片内SRAM的起始地址还是0x40000000). 然后cpu从0x00000000开始执行(也就是在Norfalsh中执行)。
页式虚拟存储器的工作原理页式虚拟存储器是一种在计算机系统中使用的辅助存储器技术,它可以有效地扩展计算机系统的主存容量。
其工作原理是将主存划分成固定大小的块,称为页面(page),然后将实际使用的页面按需加载到主存中,形成逻辑上连续的地址空间。
当需要的数据不在主存中时,系统会将其从辅助存储器中加载到主存,并将不再使用的页面置换到辅助存储器中,从而实现了对大容量数据的透明访问。
页式虚拟存储器的工作原理可以分为三个主要的步骤:地址映射、页面替换和页面加载。
地址映射是页式虚拟存储器的核心机制之一。
在页式虚拟存储器中,虚拟地址空间被划分为固定大小的页面,主存被划分为相同大小的物理页面。
在每个页面中,最低的位数被用作页面内偏移量,用于访问页面中的具体数据。
而剩余的高位被用作页号,用于查找转换表(页表),将虚拟地址转换为物理地址。
页表是一个存储在主存中的数据结构,用于将虚拟地址映射到物理地址。
它将虚拟页面号与物理页面号进行映射,并存储一些附加信息,如页面是否被修改过等。
当处理器发出访问某个虚拟内存地址的指令时,操作系统会根据该虚拟地址的页号查找页表,将虚拟地址转换为对应的物理地址,然后将指令发往该物理地址。
页面替换是页式虚拟存储器的重要机制之一。
由于主存容量有限,当所有的页面都被占用时,需要选择一个替换页面来腾出空间。
页式虚拟存储器采用了多种页面置换算法,如最近最少使用(LRU)算法、先进先出(FIFO)算法等。
这些算法根据页面的使用频率或最后使用时间来决定替换页面。
当需要替换页面时,操作系统会选择一个最适合被替换的页面,并将其从主存中移到辅助存储器中。
页面加载是页式虚拟存储器的另一个重要机制。
当处理器需要访问的页面不在主存中时,操作系统会从辅助存储器中将其加载到主存中。
这个过程被称为页面调度(page-in)。
操作系统会选择一个被替换出的页面,将其交换到辅助存储器中,然后将需要访问的页面从辅助存储器中读取到主存中。
全相连映射、组相连映射和直接映射是计算机科学中常见的术语,它们在计算机存储器和缓存系统中扮演着重要的角色。
通过深入探讨这些映射方式的特点和应用,我们可以更好地理解计算机存储器和缓存系统的工作原理和优化方法。
1. 全相连映射全相连映射是一种常见的存储器映射方式,它的特点是任何给定的存储器块都可以映射到存储器缓存的任何一个位置上。
任何一个存储器块都可以放置在缓存中的任意一个位置,只要这个位置没有被其他块占用。
在全相连映射中,当需要访问存储器块时,系统会先计算存储器块的位置区域在缓存中的映射位置,然后检查这个位置是否已经被其他块占用。
如果该位置已经被其他块占用,就需要进行替换操作。
全相连映射的优点是实现简单、应用广泛,但缺点是替换算法相对复杂,性能可能不如其他映射方式。
2. 组相连映射组相连映射是全相连映射的一种改进方式,它将缓存划分为多个组,每个组包含多个缓存行。
存储器块的映射位置由该块的位置区域的一部分决定,这样可以将存储器块映射到特定的组中。
在组内部,采用全相连映射的方式进行存储器块的替换操作。
组相连映射的优点是减少了替换操作的复杂性,提高了替换算法的效率;缺点是需要对存储器位置区域进行分组,增加了硬件的复杂性。
但是,相比于全相连映射,组相连映射在实际应用中更为有效。
3. 直接映射直接映射是另一种常见的存储器映射方式,它的特点是将存储器块映射到缓存中的特定位置。
这意味着每个存储器块只能映射到缓存中的一个固定位置,当需要替换时,只能替换该位置上的存储器块。
直接映射的优点是实现简单、硬件成本低,但缺点是可能会出现替换频繁的情况,导致性能下降。
在实际应用中,直接映射往往作为全相连映射和组相连映射的一种辅助方式来使用。
通过对全相连映射、组相连映射和直接映射的深入探讨,我们可以看到它们在计算机存储器和缓存系统中的重要性和应用价值。
在实际应用中,不同的映射方式可以根据具体的需求来选择,以达到最佳的性能和效率。
MC9S12XS128 单片机简介1、HCS12X 系列单片机简介Freescale 公司的16 位单片机主要分为HC12 、HCS12、HCS12X 三个系列。
HC12核心是16 位高速CPU12 核,总线速度8MHZ;HCS12 系列单片机以速度更快的CPU12 内核为核心,简称S12 系列,典型的S12 总线速度可以达到25MHZ。
HCS12X 系列单片机是Freescale 公司于2005 年推出的HCS12 系列增强型产品,基于S12 CPU 内核,可以达到25MHz 的HCS12 的2-5 倍性能。
总线频率最高可达40 MHz。
S12X 系列单片机目前又有几个子系列:MC9S12XA 系列、MC9S12XB 系列、MC9S12XD 系列、MC9S12XE 系列、MC9S12XF系列、MC9S12XH 系列和MC9S12XS 系列。
MC9S12XS128 就是S12X 系列中的一个成员。
2、MC9S12XS128 性能概述MC9S12XS128 是16 位单片机,由16 位中央处理单元(CPU12X)、128KB 程序Flash(P-lash)、8KB RAM、8KB 数据Flash(D-lash)组成片内存储器。
主要功能模块包括:内部存储器内部PLL 锁相环模块2 个异步串口通讯SCI1 个串行外设接口SPIMSCAN 模块1 个8 通道输入/输出比较定时器模块TIM周期中断定时器模块PIT16 通道A/D 转换模块ADC1 个8 通道脉冲宽度调制模块PWM输入/输出数字I/O 口3、输入/输出数字I/O 口MC9S12XS128 有3 种封装,分别为64 引脚、80 引脚、112 引脚封装。
其全名分别为MC9S12XS128MAE、MC9S12XS128MAA、MC9S12XS128MAL。
MC9S12XS 系列具有丰富的输入/输出端口资源,同时集成了多种功能模块,端口包括PORTA、PORTB、PORTE、PORTK、PORTT、PORTS、PORTM、PORTP、PORTH、PORTJ 和PORTAD 共11 个端口。
嵌入式芯片的存储器映射和存储器重映射1. 引言很多嵌入式芯片都集成了多种存储器(RAM、ROM、Flash、……),这些存储器的介质、工艺、容量、价格、读写速度和读写方式都各不相同,嵌入式系统设计需根据应用需求巧妙地规划和利用这些存储器,使得存储系统既满足应用对容量和速度的需求,又有较强的价格竞争优势。
本文所讲的存储器映射就是对各种存储器的大小和地址分布的规划。
存储器重映射就是为了快速响应中断或者快速完成某个任务,将同一地址段映射到不同速度的两个存储块,然后将低速存储块中的代码段复制到高速存储块中,对低速存储块的访问将被重映射为对高速存储块的访问。
2. 存储器映射(Memory Mapping)对于具体的某款嵌入式芯片,它包含的各种存储器的大小、地址分布都是确定的。
存储器映射(Memory Mapping)就是指(物理)地址到存储单元的一一对应(注意,本文中所讲的存储器映射不是指虚拟地址到物理地址的映射。
更确切地讲,本文所讲的存储器映射是存储布局(Memory Layout))。
同一类型的存储器称为一个存储块(Memory Block),也有的地方称为一个存储区域(Memory Area,Memory Region),嵌入式系统设计者通常会为一个存储块分配一段连续的物理地址。
多种存储器按某种方式排列,形成整个存储空间。
存储器映射可以理解为这样一个函数:输入是地址总线上的地址编码,输出是被寻址单元中(或数据总线上)的数据。
该函数是一个逻辑概念,计算机系统上电复位后才建立起这种映射,当计算机系统掉电后,这个函数就不复存在,只剩下计算机系统中实现这个函数的物理基础——电路连接。
也可以这样认为:存储器映射是计算机系统上电复位时的预备动作,是一个将CPU所拥有的地址编码资源向系统内各个物理存储器块分配的自动过程。
3. 存储器重映射(Memory Remapping)3.1 为什么需要存储器重映射目前很多嵌入式系统中的Flash分为Code Flash和Data Flash。
地址译码方案一、引言在计算机体系结构中,地址译码是一个至关重要的步骤。
它负责将寻址过程中的逻辑地址转换为物理地址,并指导计算机系统按照正确的方式访问内存或外部设备。
本文将介绍地址译码的基本原理和常见的地址译码方案。
二、地址译码的基本原理地址译码的目标是根据逻辑地址的一部分来选择与之对应的设备或存储单元。
在这个过程中,地址译码器将逻辑地址与存储器中的相应位置进行比较,并选择需要操作的设备或存储单元。
1. 基于单一存储器的地址译码方案最简单的地址译码方案是基于单一存储器的方案。
在这种方案中,逻辑地址的一部分直接对应存储器的物理地址。
地址译码器通过比较逻辑地址的特定位来选择需要访问的存储单元。
例如,如果逻辑地址为16位,物理存储器的大小为64KB,则可以将高10位作为地址译码的选择信号,对应64个不同的存储单元。
2. 基于存储器映射的地址译码方案存储器映射是一种地址译码的常见方案。
在这种方案中,逻辑地址的一部分被用作存储器中的索引,指示需要操作的内存块或设备。
例如,如果逻辑地址有16位,物理存储器的大小为64KB,并且每个内存块的大小为4KB,则可以将高12位作为存储器索引,对应16个不同的内存块。
3. 基于设备选择的地址译码方案某些情况下,地址译码的目标是选择与之对应的外部设备,而不是存储单元。
在这种情况下,地址译码器将逻辑地址的一部分与设备编号进行比较,以选择需要操作的设备。
例如,如果逻辑地址有16位,共有8个外部设备,可以将高3位作为设备编号,对应不同的设备。
三、地址译码方案的选择与设计考虑因素在选择和设计地址译码方案时,需要考虑以下因素:1. 存储器的大小和结构地址译码方案必须适应存储器的大小和结构。
不同的存储器大小和结构可能需要不同的地址译码方案。
2. 设备的种类和数量如果需要操作多个外部设备,地址译码方案必须能够正确选择和控制这些设备。
不同的设备种类和数量可能需要不同的地址译码方案。
3. 系统性能要求地址译码方案应满足系统对性能的要求。
主存的基本功能和工作原理主存,也称为内存或内存储器,是计算机中用于临时存储数据和指令的一种存储器。
主存的基本功能和工作原理如下:1. 基本功能:主存的主要功能是用于存放中央处理器(CPU)在执行任务过程中需要的指令和数据。
与外存(如硬盘)相比,主存的读写速度更快,可以直接被CPU访问,因此对于CPU来说,主存是一个高效且快速的临时存储空间。
2. 工作原理:主存主要由半导体存储单元组成,包括随机存储器(RAM)、只读存储器(ROM)和高速缓存(Cache)。
RAM是主存中最重要的存储器,它允许数据在系统运行过程中被随机访问和修改。
ROM主要用于存储系统启动时所需的程序和数据,例如BIOS。
Cache是一种高速缓存存储器,用于暂存CPU频繁访问的数据和指令,以提高访问速度。
主存的工作原理主要包括以下几个方面:1. 地址映射:CPU通过地址总线向主存发送访问请求,主存根据地址总线上的地址信息将相应的数据或指令返回给CPU。
地址映射关系通常由内存管理单元(MMU)进行管理。
2. 读写操作:主存中的数据和指令可以被CPU随机访问,即CPU可以在任何时刻访问主存中的任意位置。
在读操作时,CPU会向主存发送一个地址信号,主存根据地址信号返回相应的数据;在写操作时,CPU会向主存发送一个地址信号和一个数据信号,主存根据地址信号将数据写入相应的存储单元。
3. 内存保护:主存中的数据和指令通常受到内存保护机制的监控,以确保CPU只能访问授权范围内的内存空间。
这通常通过内存管理单元(MMU)来实现,它可以根据CPU的访问权限将相应的内存空间映射到CPU的地址空间。
总之,主存是计算机中用于临时存储数据和指令的一种存储器,其主要功能是提供CPU快速访问的数据和指令存储空间。
主存的工作原理包括地址映射、读写操作和内存保护等方面。
通过赋予每个任务不同的虚拟–物理地址转换映射,支持不同任务之间的保护。
地址转换函数
在每一个任务中定义,在一个任务中的虚拟地址空间映射到物理内存的一个部分,而另一个任务的虚拟地址空间映射到物理存储器中的另外区域。
...
就是把一个地址连接到另一个地址。
例如,内存单元A的地址为X,把它映射到地址Y,这样访问Y时,就可以访问到A 了。
当然,访问原来的地址X,也可以访问到A。
再如,在C语言等高级语言里面没有访问IO的指令,所以那样的话在C里面就无法访问IO,只能通过嵌入汇编或者通过调用系统函数来访问IO了。
采用IO映射后就不同了,因为IO空间和内存空间本来不同,有不同的访问指令,那么,将IO空间映射到内存空间,就可以通过使用访问内存的方法来访问IO了,例如在C语言里面可以通过指针来访问内存
单元,从而访问到被映射的IO。
存储器映射是指把芯片中或芯片外的FLASH,RAM,外设,BOOTBLOCK等进行统
一编址。
即用地址来表示对象。
这个地址绝大多数是由厂家规定好的,用户只能用而不能改。
用户只能在挂外部RAM或FLASH的情况下可进行自定义。
ARM7TDMI的存储器映射可以有0X00000000~0XFFFFFFFF的空间,即4G的映射空间,但所有器件加起来肯定是填不满的。
一般来说,0X00000000依次开始存放FLASH——0X00000000,SRAM——0X40000000,BOOTBLOCK,外部存储器0X80000000,VPB(低速外设地址,如GPIO,UART)——0XE0000000,AHB(高速外设:向量中断控制器,外部存储器控制器)——从0XFFFFFFFF回头。
他们都是从固定位置开始编址的,而占用空间又不大,如AHB只占2MB,所以从中间有很大部分是空白区域,用户若使用这些空白区域,或者定义野指针,就可能出现取指令中止或者取数据中止。
由于系统在上电复位时要从0X00000000 开始运行,而第一要运行的就是厂家固化在片子里的BOOTBLOCK,这是判断运行哪个存储器上的程序,检查用户代码是否有效,判断芯片是否加密,芯片是否IAP(在应用编程),芯片是否ISP(在系统编程),所以这个BOOTBLOCK要首先执行。
而芯片中的BOOTBLOCK不能放在FLASH的头部,因为那要存放用户的异常向量表的,以便在运行、中断时跳到这来找入口,所以BOOTBLOCK只能放在FLSAH尾部才能好找到,呵呵。
而ARM7的各芯片的FLASH大小又不一致,厂家为了BOOTBLOCK在芯片中的位置固定,就在编址的2G靠前编址的位置虚拟划分一个区域作为BOOTBLOCK 区域,这就是重映射,这样访问<2G即<0X80000000的位置时,就可以访问到在FLASH尾部的BOOTBLOCK 区了。
BOOTBLOCK运行完就是要运行用户自己写的启动代码了,而启动代码中最重要的就是异常向量表,这个表是放在FLASH的头部首先执行的,而异常向量表中要处理多方面的事情,包括复位、未定义指令、软中断、预取指中止、数据中止、IRQ(中断) ,FIQ (快速中断),而这个异常向量表是总表,还包括许多分散的异常向量表,比如在外部存储器,BOOTBLOCK,SRAM中固化的,不可能都由用户直接定义,所以还是需要重映射把那些异常向量表的地址映到总表中。
为存储器分配地址的过程称为存储器映射,那么什么叫存储器重映射呢?为了增加系统的灵活性,系统中有部分地址可以同时出现在不同的地址上,这就叫做存储器重映射。
重映射主要包括引导块―Boot Block‖重映射和异常向量表的重映射。
1.引导块―Boot Block‖及其重映射Boot Block是芯片设计厂商在LPC2000系列ARM内部固化的一段代码,用户无法对其进行修改或者删除。
这段代码在复位时被首先运行,主要用来判断运行哪个存储器上面的程序,检查用户代码是否有效,判断芯片是否被加密,系统的在应用编程(IAP)以及在系统编程功能(ISP)等。
Boot Block存在于内部Flash,LPC2200系列大小为8kb,它占用了用户的Flash空间,但也有其他的LPC系列不占用FLash空间的,而部分没有内部Flash空间的ARM处理器仍然存在Boot Block。
重映射的原因:Boot
Block中有些程序可被用户调用,如擦写片内Flash的IAP代码。
为了增加用户代码的可移植性,所以最好把Boot Block的代码固定的某个地址上。
但由于各芯片的片内Flash大小不尽相同,如果把Boot Block的地址安排在内部Flash结束的位置上,那就无法固定Boot Block的地址。
为了解决上面的问题,于是芯片厂家将Boot Block的地址重映射到片内存储器空间的最高端,即接近2Gb的地方,这样无论片内存储器的大小如何,都不会影响Boot Block的地址。
因此当Boot Block中包含可被用户调用的IAP操作的代码时,不用修改IAP 的操作地址就可以在不同的LPC系列的ARM上运行了。
2.异常向量表及其重映射ARM 内核在发生异常后,会使程序跳转到位于0x0000~0x001C的异常向量表处,再经过向量跳转到异常服务程序。
但ARM单条指令的寻址范围有限,无法用一条指令实现4G范围的跳转,所以应在其后面的0x0020~0x003F地址上放置跳转目标,这样就可以实现4G范围内的任意跳转,因此一个异常向量表实际上占用了16个字的存储单元。