多元线性回归中多重共线性的处理
- 格式:pdf
- 大小:1.07 MB
- 文档页数:18


第6章多重共线性的情形及其处理思考与练习参考答案6.1 试举一个产生多重共线性的经济实例。
答:例如有人建立某地区粮食产量回归模型,以粮食产量为因变量Y,化肥用量为X1,水浇地面积为X2,农业投入资金为X3。
由于农业投入资金X3与化肥用量X1,水浇地面积X2有很强的相关性,所以回归方程效果会很差。
再例如根据某行业企业数据资料拟合此行业的生产函数时,资本投入、劳动力投入、资金投入与能源供应都与企业的生产规模有关,往往出现高度相关情况,大企业二者都大,小企业都小。
6.2多重共线性对回归参数的估计有何影响?答:1、完全共线性下参数估计量不存在;2、近似共线性下OLS估计量非有效;3、参数估计量经济含义不合理;4、变量的显著性检验失去意义;5、模型的预测功能失效。
6.3 具有严重多重共线性的回归方程能不能用来做经济预测?答:虽然参数估计值方差的变大容易使区间预测的“区间”变大,使预测失去意义。
但如果利用模型去做经济预测,只要保证自变量的相关类型在未来期中一直保持不变,即使回归模型中包含严重多重共线性的变量,也可以得到较好预测结果;否则会对经济预测产生严重的影响。
6.4多重共线性的产生于样本容量的个数n、自变量的个数p有无关系?答:有关系,增加样本容量不能消除模型中的多重共线性,但能适当消除多重共线性造成的后果。
当自变量的个数p较大时,一般多重共线性容易发生,所以自变量应选择少而精。
6.5 自己找一个经济问题来建立多元线性回归模型,怎样选择变量和构造设计矩阵X才可能避免多重共线性的出现?答:请参考第三次上机实验题——机场吞吐量的多元线性回归模型,注意利用二手数据很难避免多重共线性的出现,所以一般利用逐步回归和主成分回归消除多重共线性。
如果进行自己进行试验设计如正交试验设计,并收集数据,选择向量使设计矩阵X 的列向量(即X 1,X 2, X p )不相关。
6.6对第5章习题9财政收入的数据分析多重共线性,并根据多重共线性剔除变量。
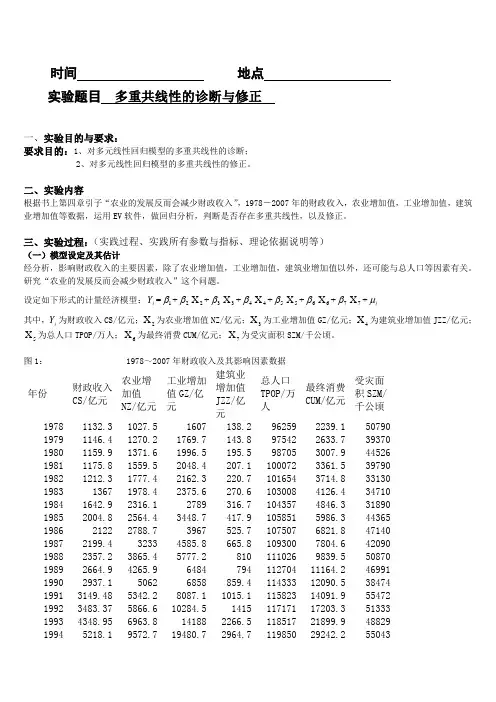
时间 地点 实验题目 多重共线性的诊断与修正一、实验目的与要求:要求目的:1、对多元线性回归模型的多重共线性的诊断;2、对多元线性回归模型的多重共线性的修正。
二、实验内容根据书上第四章引子“农业的发展反而会减少财政收入”,1978-2007年的财政收入,农业增加值,工业增加值,建筑业增加值等数据,运用EV 软件,做回归分析,判断是否存在多重共线性,以及修正。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)(一)模型设定及其估计经分析,影响财政收入的主要因素,除了农业增加值,工业增加值,建筑业增加值以外,还可能与总人口等因素有关。
研究“农业的发展反而会减少财政收入”这个问题。
设定如下形式的计量经济模型:i Y =1β+2β2X +3β3X +4β4X +5β5X +6β6X +7β7X +i μ其中,i Y 为财政收入CS/亿元;2X 为农业增加值NZ/亿元;3X 为工业增加值GZ/亿元;4X 为建筑业增加值JZZ/亿元;5X 为总人口TPOP/万人;6X 为最终消费CUM/亿元;7X 为受灾面积SZM/千公顷。
图1: 1978~2007年财政收入及其影响因素数据年份财政收入CS/亿元 农业增加值NZ/亿元 工业增加值GZ/亿元 建筑业增加值JZZ/亿元总人口TPOP/万人最终消费CUM/亿元受灾面积SZM/千公顷 1978 1132.3 1027.5 1607 138.2 96259 2239.1 50790 1979 1146.4 1270.2 1769.7 143.8 97542 2633.7 39370 1980 1159.9 1371.6 1996.5 195.5 98705 3007.9 44526 1981 1175.8 1559.5 2048.4 207.1 100072 3361.5 39790 1982 1212.3 1777.4 2162.3 220.7 101654 3714.8 33130 1983 1367 1978.4 2375.6 270.6 103008 4126.4 34710 1984 1642.9 2316.1 2789 316.7 104357 4846.3 31890 1985 2004.8 2564.4 3448.7 417.9 105851 5986.3 44365 1986 2122 2788.7 3967 525.7 107507 6821.8 47140 1987 2199.4 3233 4585.8 665.8 109300 7804.6 42090 1988 2357.2 3865.4 5777.2 810 111026 9839.5 50870 1989 2664.9 4265.9 6484 794 112704 11164.2 46991 1990 2937.1 5062 6858 859.4 114333 12090.5 38474 1991 3149.48 5342.2 8087.1 1015.1 115823 14091.9 55472 1992 3483.37 5866.6 10284.5 1415 117171 17203.3 51333 1993 4348.95 6963.8 14188 2266.5 118517 21899.9 48829 19945218.1 9572.7 19480.7 2964.7 11985029242.2550431995 6242.2 12135.8 24950.6 3728.8 121121 36748.2 45821 1996 7407.99 14015.4 29447.6 4387.4 122389 43919.5 46989 1997 8651.14 14441.9 32921.4 4621.6 123626 48140.6 53429 1998 9875.95 14817.6 34018.4 4985.8 124761 51588.2 50145 1999 11444.08 14770 35861.5 5172.1 125786 55636.9 49981 2000 13395.23 14944.7 40036 5522.3 126743 61516 54688 2001 16386.04 15781.3 43580.6 5931.7 127627 66878.3 52215 2002 18903.64 16537 47431.3 6465.5 128453 71691.2 47119 2003 21715.25 17381.7 54945.5 7490.8 129227 77449.5 54506 2004 26396.47 21412.7 65210 8694.3 129988 87032.9 37106 2005 31649.29 22420 76912.9 10133.8 130756 96918.1 38818 2006 38760.2 24040 91310.9 11851.1 131448 110595.3 41091 2007 51321.78 28095 107367.2 14014.1 132129 128444.6 48992利用EV 软件,生成i Y 、2X 、3X 、4X 、5X 、6X 、7X 等数据,采用这些数据对模型进行OLS 回归。

多重共线性的解决⽅法之——岭回归与LASSO 多元线性回归模型的最⼩⼆乘估计结果为如果存在较强的共线性,即中各列向量之间存在较强的相关性,会导致的从⽽引起对⾓线上的值很⼤并且不⼀样的样本也会导致参数估计值变化⾮常⼤。
即参数估计量的⽅差也增⼤,对参数的估计会不准确。
因此,是否可以删除掉⼀些相关性较强的变量呢?如果p个变量之间具有较强的相关性,那么⼜应当删除哪⼏个是⽐较好的呢?本⽂介绍两种⽅法能够判断如何对具有多重共线性的模型进⾏变量剔除。
即岭回归和LASSO(注:LASSO是在岭回归的基础上发展的)思想:既然共线性会导致参数估计值变得⾮常⼤,那么给最⼩⼆乘的⽬标函数加上基础上加上⼀个对的惩罚函数最⼩化新的⽬标函数的时候便也需要同时考虑到值的⼤⼩,不能过⼤。
在惩罚函数上加上系数k随着k增⼤,共线性的影响将越来越⼩。
在不断增⼤惩罚函数系数的过程中,画下估计参数(k)的变化情况,即为岭迹。
通过岭迹的形状来判断我们是否要剔除掉该参数(例如:岭迹波动很⼤,说明该变量参数有共线性)。
步骤:1. 对数据做标准化,从⽽⽅便以后对(k)的岭迹的⽐较,否则不同变量的参数⼤⼩没有⽐较性。
2. 构建惩罚函数,对不同的k,画出岭迹图。
3. 根据岭迹图,选择剔除掉哪些变量。
岭回归的⽬标函数式中,t为的函数。
越⼤,t越⼩(这⾥就是k)如上图中,相切点便是岭回归得出来的解。
是岭回归的⼏何意义。
可以看出,岭回归就是要控制的变化范围,弱化共线性对⼤⼩的影响。
解得的岭回归的估计结果为:岭回归的性质由岭回归的⽬标函数可以看出,惩罚函数的系数 (或者k)越⼤,⽬标函数中惩罚函数所占的重要性越⾼。
从⽽估计参数也就越⼩了。
我们称系数 (或者k)为岭参数。
因为岭参数不是唯⼀的,所以我们得到的岭回归估计实际是回归参数的⼀个估计族。
例如下表中:岭迹图将上表中回归估计参数与岭回归参数k之间的变化关系⽤⼀张图来表⽰,便是岭迹图当不存在奇异性是,岭迹应该是稳定地逐渐趋于0当存在奇异性时,由岭回归的参数估计结果可以看出来,刚开始k不够⼤时,奇异性并没有得到太⼤的改变,所以随着k的变化,回归的估计参数震动很⼤,当k⾜够⼤时,奇异性的影响逐渐减少,从⽽估计参数的值变的逐渐稳定。



丫= 1+ 8人-4人+ 3为=1 + 8人-(3X2+ 2)+ 3为=7+ 8人-9%(1.5)在(1.4)中,X2的系数为12,表示丫与为成正比例关系,即正相关;而在(1.5)中,X2的系数为-9,表示丫与X?成负比例关系,即负相关。
如此看来,同一个方程丫= 1+ 4片+ 3X2变换出的两个等价方程,由于不同的因式分解和替换,导致两个方程两种表面上矛盾的结果。
实际上,根据X1 = 3为+ 2式中的X1与为的共线性,X1约相当于3X2, 在(1.4)减少了3人,即需要用9个X2来补偿;而在(1.5)增加了4人, 需要用12个X2来抵消,以便保证两个方程的等价性,这样一来使得(1.5)中为的系数变为了负数。
从上述分析看来,由于X i与勺的共线性,使得同一个方程有不同的表达形式,从而使得丫与为间的关系难以用系数解释。
2•对多重线性关系的初步估计与识别如果在实际应用中产生了如下情况之一,则可能是由于多重共线性的存在而造成的,需作进一步的分析诊断。
①增加(或减去)一个变量或增加(或剔除)一个观察值,回归系数发生了较大变化。
②实际经验中认为重要的自变量的回归系数检验不显著。
③回归系数的正负号与理论研究或经验相反。
④在相关矩阵中,自变量的相关系数较大。
⑤自变量回归系数可信区间范围较广等。
3•对多重共线性本质的认识多重共线性可分为完全多重共线性和近似多重共线性(或称高度相关性),现在我们集中讨论多重共线性的本质问题。
多重共线性普遍被认为是数据问题或者说是一种样本现象。
我们认为,这种普遍认识不够全面,对多重共线性本质的认识,至少可从以下几方面解解。
(3)检验解释变量相互之间的样本相关系数。
假设我们有三个解释变量X i、X2、X3,分别以「12、「13、「23 来表示X i 与X2、X i 与X3、X2与X3之间的两两相关系数。
假设r i2 = 0.90,表明X i与X2之间高度共线性,现在我们来看相关系数「12,3,这样一个系数我们定义为偏相关系数,它是在变量X3为常数的情况下,X i与X2之间的相关系数。

⾃变量存在多重共线性,如何通过变量筛选来解决?多重线性回归要求各个⾃变量之间相互独⽴,不存在多重共线性。
所谓多重共线性,是指⾃变量之间存在某种相关或者⾼度相关的关系,其中某个⾃变量可以被其他⾃变量组成的线性组合来解释。
医学研究中常见的⽣理资料,如收缩压和舒张压、总胆固醇和低密度脂蛋⽩胆固醇等,这些变量之间本⾝在⼈体中就存在⼀定的关联性。
如果在构建多重线性回归模型时,把具有多重共线性的变量⼀同放在模型中进⾏拟合,就会出现⽅程估计的偏回归系数明显与常识不相符,甚⾄出现符号⽅向相反的情况,对模型的拟合带来严重的影响。
今天我们就来讨论⼀下,如果⾃变量之间存在多重共线性,如何通过有效的变量筛选来加以解决?⼀、多重共线性判断回顾⼀下前期讲解多重线性回归时,介绍的判断⾃变量多重共线性的⽅法。
1. 计算⾃变量两两之间的相关系数及其对应的P值,⼀般认为相关系数>0.7,且P<0.05时可考虑⾃变量之间存在共线性,可以作为初步判断多重共线性的⼀种⽅法。
2. 共线性诊断统计量,即Tolerance(容忍度)和VIF(⽅差膨胀因⼦)。
⼀般认为如果Tolerance<0.2或VIF>5(Tolerance和VIF呈倒数关系), 则提⽰要考虑⾃变量之间存在多重共线性的问题。
⼆、多重共线性解决⽅法:变量剔除顾名思义,当⾃变量之间存在多重共线性时,最简单的⽅法就是对共线的⾃变量进⾏⼀定的筛选,保留更为重要的变量,删除次要或可替代的变量,从⽽减少变量之间的重复信息,避免在模型拟合时出现多重共线性的问题。
对于如何去把握应该删除哪⼀个变量,保留哪⼀个变量,近期也有⼩伙伴在微信平台中问到这个问题,下⾯举个例⼦进⾏⼀个简单的说明。
表1. ⾃变量相关性如表1所⽰, X3和X4、X5之间相关系数>0.7,变量X4与X1、X3、X5之间相关系数>0.7,X5与X3、X4之间相关系数>0.7,说明X3、X4、X5之间存在⼀定的共线性,由于X4与X1的相关性也较⾼,故此时建议可以先将X4删除再进⾏模型拟合,当然也需要结合容忍度和VIF值及专业知识来进⾏判断。



浅析多元线性回归中多重共线性问题的三种解决方法
谢小韦
【期刊名称】《科技信息》
【年(卷),期】2009(000)028
【摘要】为了解决变量之间的多重共线性问题,本文提出了三种方法:岭回归、主成分回归和偏最小二乘回归.首先介绍了其基本思想和主要处理步骤,并通过具体实例验证出利用三种回归方法,可以消除多重共线性所带来的影响.最后,通过对结果的分析总结出三种方法的优劣.
【总页数】2页(P117-118)
【作者】谢小韦
【作者单位】南京铁道职业技术学院
【正文语种】中文
【中图分类】O1
【相关文献】
1.观测数据拟合分析中的多重共线性问题 [J], 杨杰;吴中如
2.改进SVM分类算法中多重共线性问题研究 [J], 冼广铭;齐德昱;方群;柯庆;曾碧卿;肖应旺
3.GDP预测模型中的多重共线性问题 [J], 杨振刚;郑更新
4.多元线性回归模型中处理多重共线性方法对比
——以人口迁移冲击教育资源模型为例 [J], 范圣岗;奚书静
5.局部线性估计中的多重共线性问题 [J], 吴相波;叶阿忠
因版权原因,仅展示原文概要,查看原文内容请购买。
第6章多重共线性的情形及其处理思考与练习参考答案6.1 试举一个产生多重共线性的经济实例。
答:例如有人建立某地区粮食产量回归模型,以粮食产量为因变量Y,化肥用量为X1,水浇地面积为X2,农业投入资金为X3。
由于农业投入资金X3与化肥用量X1,水浇地面积X2有很强的相关性,所以回归方程效果会很差。
再例如根据某行业企业数据资料拟合此行业的生产函数时,资本投入、劳动力投入、资金投入与能源供应都与企业的生产规模有关,往往出现高度相关情况,大企业二者都大,小企业都小。
6.2多重共线性对回归参数的估计有何影响?答:1、完全共线性下参数估计量不存在;2、近似共线性下OLS估计量非有效;3、参数估计量经济含义不合理;4、变量的显著性检验失去意义;5、模型的预测功能失效。
6.3 具有严重多重共线性的回归方程能不能用来做经济预测?答:虽然参数估计值方差的变大容易使区间预测的“区间”变大,使预测失去意义。
但如果利用模型去做经济预测,只要保证自变量的相关类型在未来期中一直保持不变,即使回归模型中包含严重多重共线性的变量,也可以得到较好预测结果;否则会对经济预测产生严重的影响。
6.4多重共线性的产生于样本容量的个数n、自变量的个数p有无关系?答:有关系,增加样本容量不能消除模型中的多重共线性,但能适当消除多重共线性造成的后果。
当自变量的个数p较大时,一般多重共线性容易发生,所以自变量应选择少而精。
6.5 自己找一个经济问题来建立多元线性回归模型,怎样选择变量和构造设计矩阵X才可能避免多重共线性的出现?答:请参考第三次上机实验题——机场吞吐量的多元线性回归模型,注意利用二手数据很难避免多重共线性的出现,所以一般利用逐步回归和主成分回归消除多重共线性。
如果进行自己进行试验设计如正交试验设计,并收集数据,选择向量使设计矩阵X 的列向量(即X 1,X 2, X p )不相关。
6.6对第5章习题9财政收入的数据分析多重共线性,并根据多重共线性剔除变量。
多重共线性问题的几种解决方式在多元线性回归模型经典假设中,其重要假定之一是回归模型的解释变量之间不存在线性关系,也就是说,解释变量X1,X2,……,X k中的任何一个都不能是其他解释变量的线性组合。
若是违背这一假定,即线性回归模型中某一个解释变量与其他解释变量间存在线性关系,就称线性回归模型中存在多重共线性。
多重共线性违背了解释变量间不相关的古典假设,将给普通最小二乘法带来严重后果。
这里,咱们总结了8个处置多重共线性问题的可用方式,大家在碰到多重共线性问题时可作参考:1、保留重要解释变量,去掉次要或可替代解释变量2、用相对数变量替代绝对数变量3、差分法4、慢慢回归分析5、主成份分析6、偏最小二乘回归7、岭回归8、增加样本容量这次咱们主要研究慢慢回归分析方式是如何处置多重共线性问题的。
慢慢回归分析方式的大体思想是通过相关系数r、拟合优度R2和标准误差三个方面综合判断一系列回归方程的好坏,从而取得最优回归方程。
具体方式分为两步:第一步,先将被解释变量y对每一个解释变量作简单回归:对每一个回归方程进行统计查验分析(相关系数r、拟合优度R2和标准误差),并结合经济理论分析选出最优回归方程,也称为大体回归方程。
第二步,将其他解释变量一一引入到大体回归方程中,成立一系列回归方程,按照每一个新加的解释变量的标准差和复相关系数来考察其对每一个回归系数的影响,一般按照如下标准进行分类判别:1.若是新引进的解释变量使R2取得提高,而其他参数回归系数在统计上和经济理论上仍然合理,则以为这个新引入的变量对回归模型是有利的,可以作为解释变量予以保留。
2.若是新引进的解释变量对R2改良不明显,对其他回归系数也没有多大影响,则没必要保留在回归模型中。
3.若是新引进的解释变量不仅改变了R2,而且对其他回归系数的数值或符号具有明显影响,则以为该解释变量为不利变量,引进后会使回归模型出现多重共线性问题。
不利变量未必是多余的,若是它可能对被解释变量是不可缺少的,则不能简单舍弃,而是应研究改善模型的形式,寻觅更符合实际的模型,从头进行估量。
第六章多重共线性第六章多重共线性前面两章所讲的异方差性和自相关性都是表现在随机误差项中的,我们下面所讲的多重共线性讨论的是模型中的解释变量违背基本假设的问题。
回忆以下我们在讲多元线性回归模型时,基本假定与简单线性回归模型不同的是哪一点?——就是无多重共线性假定:即假定各解释变量之间不存在线性关系,或者说各解释变量的观测值之间线性无关。
这一章我们讨论的多重共线性就是当解释变量违背了这一条基本假定的情形。
第一节多重共线性概念先看一个实例:我们研究某个地区家庭消费及其影响因素。
我们除了引入收入X1以外,还引入了消费者的家庭财产X2作为第2个解释变量。
根据抽样数据回归得到以下结果:Y^=24.7747+0.9415X1-0.0424X2t=(3.6690) (1.1442) (-0.5261)R2=0.9635 R2——=0.9531 F=92.4020这一回归结果说明什么?1、可决系数和修正可决系数都很理想2、F统计量高度显著,说明X1、X2联合对Y的影响显著3、各变量参数的t检验都不显著,不能否定等于零的假设4、财产变量的系数竟然与预期的符号相反。
为什么会出现这样的结果呢?再看一个例子:分析某地区汽车保养费用支出与汽车的行程数以及汽车拥有的时间建立模型,通过样本数据估计得:Y^=7.29+27.58X1-151.15X2t= (0.06) (0.958) (-7.06)R2——=0.946 F=52.53这个结果修正可决系数理想,F检验也显著,但X的T检验不显著,X2的T检验虽然显著,但系数符号与经济意义不符。
为什么也出现这种结果?一、多重共线性的概念:如果某两个或多个解释变量之间出现了相关性,则称为多重共线性。
完全共线性与不完全共线性表示的是一种线性相关程度。
比如我们在第一个例子中,发现可支配收入与家庭财富之间有明显的共线性关系,他们的相关系数高达0.9989,第二个例子中汽车的行程数与拥有汽车的时间的相关系数也为0.9960,表明两个变量之间存在一种不完全的线性相关关系,我们可以认为他们之间有程度很高的多重共线性.不存在多重共线性只说明解释变量之间没有线性关系,而不排除他们之间存在某种非线性关系。
多重共线性和非线性回归的问题(1)多重共线性问题我们都知道在进行多元回归的时候,特别是进行经济上指标回归的时候,很多变量存在共同趋势相关性,让我们得不到希望的回归模型。
这里经常用到的有三种方法,而不同的方法有不同的目的,我们分别来看看:第一个,是最熟悉也是最方便的——逐步回归法。
逐步回归法是根据自变量与因变量相关性的大小,将自变量一个一个选入方法中,并且每选入一个自变量都进行一次检验。
最终留在模型里的自变量是对因变量有最大显著性的,而剔除的自变量是与因变量无显著线性相关性的,以及与其他自变量存在共线性的。
用逐步回归法做的多元回归分析,通常自变量不宜太多,一般十几个以下,而且你的数据量要是变量个数3倍以上才可以,不然做出来的回归模型误差较大。
比如说你有10个变量,数据只有15组,然后做拟合回归,得到9个自变量的系数,虽然可以得到,但是精度不高。
这个方法我们不仅可以找到对因变量影响显著的几个自变量,还可以得到一个精确的预测模型,进行预测,这个非常重要的。
而往往通过逐步回归只能得到几个自变量进入方程中,有时甚至只有一两个,令我们非常失望,这是因为自变量很多都存在共线性,被剔除了,这时可以通过第二个方法来做回归。
第二个,通过因子分析(或主成分分析)再进行回归。
这种方法用的也很多,而且可以很好的解决自变量间的多重共线性。
首先通过因子分析将几个存在共线性的自变量合为一个因子,再用因子分析得到的几个因子和因变量做回归分析,这里的因子之间没有显著的线性相关性,根本谈不上共线性的问题。
通过这种方法可以得到哪个因子对因变量存在显著的相关性,哪个因子没有显著的相关性,再从因子中的变量对因子的载荷来看,得知哪个变量对因变量的影响大小关系。
而这个方法只能得到这些信息,第一它不是得到一个精确的,可以预测的回归模型;第二这种方法不知道有显著影响的因子中每个变量是不是都对因变量有显著的影响,比如说因子分析得到三个因子,用这三个因子和因变量做回归分析,得到第一和第二个因子对因变量有显著的影响,而在第一个因子中有4个变量组成,第二个因子有3个变量组成,这里就不知道这7个变量是否都对因变量存在显著的影响;第三它不能得到每个变量对因变量准确的影响大小关系,而我们可以通过逐步回归法直观的看到自变量前面的系数大小,从而判断自变量对因变量影响的大小。