中文命名实体识别及关系提取
- 格式:ppt
- 大小:1.36 MB
- 文档页数:18

中⽂电⼦病历命名实体识别(CNER)研究进展中⽂电⼦病历命名实体识别(CNER)研究进展中⽂电⼦病历命名实体识别(Chinese Clinical Named Entity Recognition, Chinese-CNER)任务⽬标是从给定的电⼦病历纯⽂本⽂档中识别并抽取出与医学临床相关的实体提及,并将它们归类到预定义的类别。
最近把之前收集整理的⼀些CNER相关的研究进展放在了github 上。
主要内容包括Chinese-CNER的相关论⽂列表,以及⽬前各个主要数据集上的⼀些先进结果,希望对CNER感兴趣的读者有所帮助。
中⽂电⼦病历实体识别研究相关论⽂在中⽂电⼦病历实体识别任务上,已经有不少研究⽅法被提出,这些研究主要集中在对领域特征的探索上,即在通⽤领域NER⽅法的基础上,研究中⽂汉字特征和电⼦病历知识特征等来提升模型性能。
综述论⽂1. 电⼦病历命名实体识别和实体关系抽取研究综述. 杨锦锋, 于秋滨, 关毅等. ⾃动化学报, 2014, 40(8):1537-1561.2. 中⽂电⼦病历的命名实体识别研究进展. 杨飞洪,张宇,覃露等.中国数字医学,2020,15(02):9-12.3. Overview of CCKS 2018 Task 1: Named Entity Recognition in Chinese Electronic Medical Records. Zhang J, Li J, Jiao Z, et al. InChina Conference on Knowledge Graph and Semantic Computing, Springer, 2019:158-164.4. Overview of the CCKS 2019 Knowledge Graph Evaluation Track: Entity, Relation, Event and QA. Han X, Wang Z, Zhang J, etal. arXiv preprint, 2020, arXiv:2003.03875.⽅法论⽂1. HITSZ_CNER: a hybrid system for entity recognition from Chinese clinical text. Hu J, Shi X, Liu Z, et al. Proceedings of theEvaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing (CCKS 2017), Chendu, China, 2017:1-6. .2. Clinical named entity recognition from Chinese electronic health records via machine learning methods. Zhang Y, Wang X, Hou Z, etal. JMIR medical informatics. 2018;6(4):e50.3. A BiLSTM-CRF Method to Chinese Electronic Medical Record Named Entity Recognition. Ji B, Liu R, Li S, et al. In Proceedings ofthe 2018 International Conference on Algorithms, Computing and Artificial Intelligence, 2018:1-6.4. A multitask bi-directional RNN model for named entity recognition on Chinese electronic medical records. Chowdhury S, Dong X,Qian L, et al. BMC bioinformatics. 2018, 19(17):75-84.5. A Conditional Random Fields Approach to Clinical Name Entity Recognition. Yang X, Huang W. Proceedings of the EvaluationTasks at the China Conference on Knowledge Graph and Semantic Computing (CCKS 2018). Tianjin, China, 2018:1-6.6. DUTIR at the CCKS-2018 Task1: A Neural Network Ensemble Approach for Chinese Clinical Named Entity Recognition. Luo L, Li N,Li S, et al. Proceedings of the Evaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing (CCKS 2018). Tianjin, China, 2018:1-6.7. Incorporating dictionaries into deep neural networks for the chinese clinical named entity recognition. Wang Q, Zhou Y, Ruan T, etal. Journal of biomedical informatics, 2019, 92: 103133.8. A hybrid approach for named entity recognition in Chinese electronic medical record. Ji B, Liu R, Li S, et al. BMC medical informaticsand decision making. 2019 Apr;19(2):149-58.9. Chinese Clinical Named Entity Recognition Using Residual Dilated Convolutional Neural Network with Conditional Random Field.Qiu J, Zhou Y, Wang Q, et al. IEEE Transactions on NanoBioscience. 2019, 18(3):306-315.10. An attention-based deep learning model for clinical named entity recognition of Chinese electronic medical records. Li L, Zhao J, HouL, et al. BMC medical informatics and decision making. 2019, 19(5):1-1.11. Chinese clinical named entity recognition with word-level information incorporating dictionaries. Lu N, Zheng J, Wu W, et al. In 2019International Joint Conference on Neural Networks (IJCNN), 2019,1-8.12. Fine-tuning BERT for joint entity and relation extraction in Chinese medical text. Xue K, Zhou Y, Ma Z, et al. In 2019 IEEEInternational Conference on Bioinformatics and Biomedicine (BIBM), 2019, 892-897.13. Chinese clinical named entity recognition with radical-level feature and self-attention mechanism. Yin M, Mou C, Xiong K, etal. Journal of biomedical informatics. 2019, 98:103289.14. Adversarial training based lattice LSTM for Chinese clinical named entity recognition. Zhao S, Cai Z, Chen H, et al. Journal ofbiomedical informatics. 2019, 99:103290.15. 基于句⼦级 Lattice-长短记忆神经⽹络的中⽂电⼦病历命名实体识别. 潘璀然, 王青华, 汤步洲等. 第⼆军医⼤学学报. 2019,40(05):497-507.16. 基于BERT与模型融合的医疗命名实体识别. 乔锐,杨笑然,黄⽂亢. Proceedings of the Evaluation Tasks at the China Conference onKnowledge Graph and Semantic Computing (CCKS 2019)17. Noisy Label Learning for Chinese Medical Named Entity Recognition Based on Uncertainty Strategy. Li Z, Gan Z, Zhang B, etal. Proceedings of the Evaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing (CCKS 2020) 18. 基于BERT与字形字⾳特征的医疗命名实体识别. 晏阳天, 赵新宇, 吴贤. Proceedings of the Evaluation Tasks at the China Conferenceon Knowledge Graph and Semantic Computing (CCKS 2020)19. Cross domains adversarial learning for Chinese named entity recognition for online medical consultation. Wen G, Chen H, Li H, etal. Journal of Biomedical Informatics. 2020 Dec 1;112:103608.20. Chinese medical named entity recognition based on multi-granularity semantic dictionary and multimodal tree. Wang C, Wang H,Zhuang H, et al. Journal of Biomedical Informatics. 2020, 111:103583.21. Chinese Clinical Named Entity Recognition in Electronic Medical Records: Development of a Lattice Long Short-Term MemoryModel With Contextualized Character Representations. Li Y, Wang X, Hui L, et al. JMIR Medical Informatics. 2020;8(9):e19848. 22. Chinese clinical named entity recognition with variant neural structures based on BERT methods. Li X, Zhang H, Zhou XH. Journal ofbiomedical informatics. 2020, 107:103422.23. 融⼊语⾔模型和注意⼒机制的临床电⼦病历命名实体识别. 唐国强,⾼⼤启,阮彤等. 计算机科学,2020,47(03):211-216.24. 基于笔画ELMo和多任务学习的中⽂电⼦病历命名实体识别研究. 罗凌, 杨志豪, 宋雅⽂等. 计算机学报, 2020, 43(10): 1943-1957.中⽂电⼦病历实体识别现存⽅法性能中⽂电⼦病历实体识别任务的数据集以及相应数据集上系统模型性能表现。

文本件中的实体命名识别与关系提取技术综述实体命名识别(Named Entity Recognition,简称NER)与关系提取(Relation Extraction)是自然语言处理(Natural Language Processing,简称NLP)中的重要任务,它们在信息提取、知识图谱构建、问答系统等领域有着广泛的应用。
本文将对实体命名识别和关系提取的技术综述进行介绍。
一、实体命名识别技术综述实体命名识别是指从文本中识别出具有特定意义的实体,如人名、地名、组织机构名等。
常用的实体命名识别方法主要包括基于规则的方法、基于统计机器学习的方法和基于深度学习的方法。
基于规则的方法是指通过预定义的规则来识别实体。
这种方法需要手工制定规则,因此对领域和语言的适应性较差。
基于规则的方法虽然简单易实现,但在复杂的语境下表现不佳。
基于统计机器学习的方法是指利用统计模型来识别实体。
常用的统计机器学习算法包括最大熵模型、隐马尔可夫模型和条件随机场等。
这些方法依赖于大量的标注数据,通过学习文本中的特征和上下文信息来判断实体类型。
基于统计机器学习的方法在准确率上有较好的表现,但需要大量的标注数据来训练模型,并且对于新的领域和语言需要重新训练。
基于深度学习的方法是指利用深度神经网络来进行实体命名识别。
常见的深度学习模型包括循环神经网络(Recurrent Neural Network,简称RNN)和卷积神经网络(Convolutional NeuralNetwork,简称CNN)。
这些模型通过捕捉文本中的上下文信息和语义特征来进行实体命名识别,相对于传统方法具有更好的泛化性能。
二、关系提取技术综述关系提取是指从文本中提取出实体之间的关系。
关系提取可以分为两个子任务:实体对齐和关系分类。
实体对齐是指将文本中的实体与知识库或语料库中的实体进行对应,关系分类是指将实体对之间的关系进行分类。
常用的关系提取方法主要包括基于规则的方法、基于统计机器学习的方法和基于深度学习的方法。
![[nlp]命名实体识别中的中文名识别算法](https://uimg.taocdn.com/ee12cc5668eae009581b6bd97f1922791688be61.webp)
[nlp]命名实体识别中的中⽂名识别算法⽬录命名实体识别命名实体识别是⾃然语⾔处理中的⼀项基础性⼯作,需要把⽂本中出现的命名实体包括⼈名、地名、组织机构名、⽇期、时间、和其他实体识别出来并加以归类。
特征模板⼀般采⽤当前位置的前后n(n≥1)个位置上的字(或词、字母、数字、标点等,不妨统称为“字串”)及其标记表⽰,即以当前位置的前后n个位置范围内的字串及其标记作为观察窗⼝:(…w-n/tag-n,…,w-1/tag-1w0/tag0,w1/tag1,…,wn/tagn,…)。
考虑到,如果窗⼝开得较⼤时,算法的执⾏效率会太低,⽽且模板的通⽤性较差,但窗⼝太⼩时,所涵盖的信息量⼜太少,不⾜以确定当前位置上字串的标记,因此,⼀般情况下将n值取为2~3,即以当前位置上前后2~3个位置上的字串及其标记作为构成特征模型的符号。
由于不同的命名实体⼀般出现在不同的上下⽂语境中,因此,对于不同的命名实体识别⼀般采⽤不同的特征模板。
例如,在识别汉语⽂本中的⼈名时,考虑到不同国家的⼈名构成特点有明显的不同,⼀般将⼈名划分为不同的类型:中国⼈名、⽇本⼈名、俄罗斯⼈名、欧美⼈名等。
同时,考虑到出现在⼈名左右两边的字串对于确定⼈名的边界有⼀定的帮助作⽤,如某些称谓、某些动词和标点等,因此,某些总结出来的“指界词”(左指界词或右指界词)也可以作为特征。
特征函数确定以后,剩下的⼯作就是训练CRF模型参数λ。
⼤量的实验表明,在⼈名、地名、组织机构名三类实体中,组织机构名识别的性能最低。
⼀般情况下,英语和汉语⼈名识别的F值都可以达到90%左右,⽽组织机构名识别的F值⼀般都在85%左右,这也反映出组织机构名是最难识别的⼀种命名实体。
当然,对于不同领域和不同类型的⽂本,测试性能会有较⼤的差异。
基于多特征的命名实体识别⽅法、专家知识的评测结果混合模型的⼈名、地名、机构名识别性能(F-测度值)⽐单独使⽤词形特征模型时的性能分别提⾼了约5.4%,1.4%,2.2%,⽐单独使⽤词性特征模型时分别提⾼了约0.4%,2.7%,11.1%。

自然语言处理中的命名实体识别与关系抽取命名实体识别与关系抽取是自然语言处理中的重要技术。
它们分别用于识别文本中的命名实体和抽取命名实体之间的关系,对于自然语言处理领域的信息抽取、文本分类和知识图谱构建等任务具有重要意义。
本文将分别介绍命名实体识别和关系抽取的基本概念、技术方法和应用场景,并讨论它们在自然语言处理领域的发展和挑战。
一、命名实体识别命名实体识别是自然语言处理中的一项基础任务,它主要是识别文本中具有特定意义的实体,如人名、地名、机构名、日期、时间等。
命名实体识别通常在信息抽取、知识图谱构建、问答系统等任务中起着重要作用。
1.1命名实体识别的基本概念命名实体识别的主要目标是从文本中识别出具有特定名称的实体,并将其分类为不同的类别。
常见的命名实体包括人名、地名、组织机构名、时间、日期等。
命名实体识别的结果通常是一个实体序列,每个实体都有对应的类别标签。
1.2命名实体识别的技术方法命名实体识别的技术方法主要包括基于规则的方法、基于统计的方法和基于深度学习的方法。
基于规则的方法通过设计一系列规则来识别文本中的命名实体,但这种方法依赖于语言专家对规则的设计,难以覆盖所有的情况。
基于统计的方法通过训练统计模型来识别命名实体,如隐马尔可夫模型、条件随机场等。
基于深度学习的方法则是通过神经网络模型来学习文本中的命名实体特征,进而识别命名实体。
1.3命名实体识别的应用场景命名实体识别在自然语言处理领域有着广泛的应用场景,如信息抽取、文本分类、知识图谱构建、问答系统等。
在信息抽取任务中,命名实体识别能够帮助抽取文本中的实体关系,从而构建结构化的知识库。
在文本分类任务中,命名实体识别能够帮助识别文本中的关键实体,从而提高分类性能。
在知识图谱构建任务中,命名实体识别能够帮助从大规模文本中抽取实体及其关系,从而构建知识图谱。
在问答系统任务中,命名实体识别能够帮助识别问题中的关键实体,从而提高问题解析的性能。
1.4命名实体识别的发展和挑战随着深度学习技术的发展,命名实体识别在自然语言处理领域取得了一些重要的进展。

chinese-annotator用法概述及解释说明1. 引言1.1 概述在当今信息爆炸的时代,自然语言处理(Natural Language Processing, NLP)技术的发展越来越受到关注。
其中,中文标注工具(Chinese-annotator)作为一种重要的自然语言处理工具,在文本标注、实体识别、关系抽取等任务中发挥着重要作用。
本文旨在对Chinese-annotator的使用方法进行概述和解释说明,帮助读者更好地理解和应用该工具。
1.2 文章结构本文共分为五个部分。
首先是引言部分,介绍了本文的目的和结构。
第二部分是对Chinese-annotator的介绍,包括其简介、使用场景和主要功能。
第三部分是对各个功能进行详细解释说明。
第四部分通过示例应用来展示在不同场景下如何使用Chinese-annotator解决问题。
最后一部分是结论,总结了文章中的主要观点和发现,并展望了未来研究方向或应用前景。
1.3 目的本文旨在提供一个清晰、全面的Chinese-annotator 的用法概述,帮助初学者更快速上手并有效利用该工具进行中文文本处理。
通过深入了解Chinese-annotator 的不同功能和使用场景,读者将能够在各种实际应用中更好地应用该工具,并提升处理文本数据的效率和准确性。
同时,本文也将展示Chinese-annotator 在特定领域下的实例应用,为读者提供具体操作指导和灵感思路。
通过本文的阐述,读者将对Chinese-annotator有一个全面且清晰的认识,从而为自然语言处理相关项目或研究提供有力支持和指导。
2. Chinese-annotator用法:2.1 简介Chinese-annotator是一个功能强大的中文注释器工具,它可以帮助用户分析和理解中文文本。
通过使用Chinese-annotator,用户可以对中文文本进行实体命名识别、关键词提取、情感分析等一系列智能处理。

机器翻译中的命名实体识别和实体关系抽取方法机器翻译(Machine Translation, MT)是一项涉及自然语言处理(Natural Language Processing, NLP)和人工智能(Artificial Intelligence, AI)的重要技术,旨在将源语言文本自动翻译成目标语言文本。
命名实体识别(Named Entity Recognition, NER)和实体关系抽取(Entity Relationship Extraction)是机器翻译中的两个关键任务,本文将详细介绍这两个方法及其在机器翻译中的应用。
一、命名实体识别(Named Entity Recognition, NER)命名实体识别是一种识别文本中特定类别实体(如人名、地名、组织机构名等)的技术。
NER在机器翻译中具有重要意义,因为命名实体在句子中往往具有特殊的语义和语法作用,对翻译结果起到重要影响。
1.传统方法传统的命名实体识别方法主要基于规则和词典匹配。
规则匹配方法依赖于手工编写的规则来识别命名实体,例如,利用正则表达式来匹配人名的特定模式。
词典匹配方法则利用已有的命名实体词典,通过查找词典中的实体词来识别命名实体。
这些方法在一定程度上能够识别命名实体,但对于未知的实体和词义消歧等问题表现不佳。
2.基于机器学习的方法随着机器学习的发展,基于机器学习的命名实体识别方法逐渐兴起。
常用的机器学习方法包括:最大熵(Maximum Entropy)、支持向量机(Support Vector Machine)、条件随机场(Conditional Random Field)等。
这些方法通过在标注数据上进行训练,学习到命名实体识别的模式和规律,并能够识别未知的实体。
3.深度学习方法近年来,深度学习方法在命名实体识别中逐渐崭露头角。
其中,基于循环神经网络(Recurrent Neural Network, RNN)的模型如长短时记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(GatedRecurrent Unit, GRU)等,以及基于卷积神经网络(Convolutional Neural Network, CNN)的模型在命名实体识别任务上表现出色。

基于深度学习的中文命名实体识别研究的开题报告1.研究背景目前,由于互联网技术的不断发展和普及,文本信息的数量呈指数增长。
然而,大量的文本信息中包含着各种实体,例如人名、地名、组织机构等。
对这些实体进行自动识别并抽取出有用信息,不仅可以大大提高人们的信息检索效率,而且对于自然语言处理、知识图谱构建等领域也具有重要意义。
因此,中文命名实体识别(Chinese Named Entity Recognition,CNER)成为了自然语言处理研究中的一个核心问题。
该问题的解决对于机器理解文本的能力有很大帮助。
随着深度学习技术的兴起,其在该领域中也取得了很多进展。
因此,本研究将重点基于深度学习技术对中文命名实体识别算法进行研究和探讨。
2.研究目的本研究旨在探究基于深度学习的中文命名实体识别算法,通过对中文文本中的命名实体进行自动识别提取出有用信息,提高文本信息检索的效率和精度。
3.研究内容(1)中文命名实体识别的基本概念和算法;(2)深度学习技术在中文命名实体识别中的应用现状和发展趋势;(3)基于深度学习的中文命名实体识别算法的研究和探讨,包括基于循环神经网络(Recurrent Neural Networks,RNN)的模型和基于卷积神经网络(Convolutional Neural Networks,CNN)的模型;(4)基于公开数据集的实验和分析,对比不同模型在中文命名实体识别任务上的效果;(5)对研究结果进行总结和分析,提出未来研究的方向和深度学习在自然语言处理领域的应用前景。
4.研究方法本研究将主要采用如下方法:(1)数据预处理:收集、清洗并进行标注的数据集;(2)模型设计:基于深度学习方法,设计一些常用模型,如RNN、CNN等等;(3)模型训练:通过已经标注好的数据集进行训练,并结合优化方法进行模型的快速迭代;(4)模型评估:通过公开数据集进行模型的效果评估,比较不同模型在中文命名实体识别任务中的表现;(5)结果分析:分析研究结果,发掘深度学习在中文命名实体识别中的应用前景。
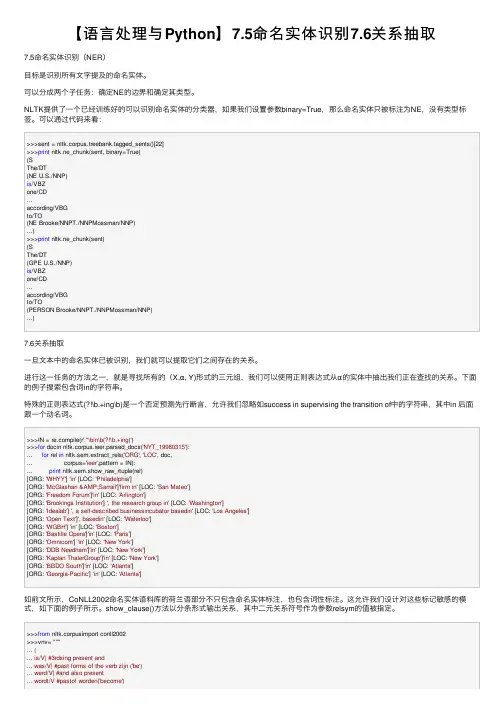
【语⾔处理与Python】7.5命名实体识别7.6关系抽取7.5命名实体识别(NER)⽬标是识别所有⽂字提及的命名实体。
可以分成两个⼦任务:确定NE的边界和确定其类型。
NLTK提供了⼀个已经训练好的可以识别命名实体的分类器,如果我们设置参数binary=True,那么命名实体只被标注为NE,没有类型标签。
可以通过代码来看:>>>sent = nltk.corpus.treebank.tagged_sents()[22]>>>print nltk.ne_chunk(sent, binary=True)(SThe/DT(NE U.S./NNP)is/VBZone/CD...according/VBGto/TO(NE Brooke/NNPT./NNPMossman/NNP)...)>>>print nltk.ne_chunk(sent)(SThe/DT(GPE U.S./NNP)is/VBZone/CD...according/VBGto/TO(PERSON Brooke/NNPT./NNPMossman/NNP)...)7.6关系抽取⼀旦⽂本中的命名实体已被识别,我们就可以提取它们之间存在的关系。
进⾏这⼀任务的⽅法之⼀,就是寻找所有的(X,α, Y)形式的三元组,我们可以使⽤正则表达式从α的实体中抽出我们正在查找的关系。
下⾯的例⼦搜索包含词in的字符串。
特殊的正则表达式(?!\b.+ing\b)是⼀个否定预测先⾏断⾔,允许我们忽略如success in supervising the transition of中的字符串,其中in 后⾯跟⼀个动名词。
>>>IN = pile(r'.*\bin\b(?!\b.+ing)')>>>for docin nltk.corpus.ieer.parsed_docs('NYT_19980315'):... for rel in nltk.sem.extract_rels('ORG', 'LOC', doc,... corpus='ieer',pattern = IN):... print nltk.sem.show_raw_rtuple(rel)[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia'][ORG: 'McGlashan &Sarrail']'firm in' [LOC: 'San Mateo'][ORG: 'Freedom Forum']'in' [LOC: 'Arlington'][ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington'][ORG: 'Idealab'] ', a self-described businessincubator basedin' [LOC: 'Los Angeles'][ORG: 'Open Text']', basedin' [LOC: 'Waterloo'][ORG: 'WGBH'] 'in' [LOC: 'Boston'][ORG: 'Bastille Opera']'in' [LOC: 'Paris'][ORG: 'Omnicom'] 'in' [LOC: 'New York'][ORG: 'DDB Needham']'in' [LOC: 'New York'][ORG: 'Kaplan ThalerGroup']'in' [LOC: 'New York'][ORG: 'BBDO South']'in' [LOC: 'Atlanta'][ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']如前⽂所⽰,CoNLL2002命名实体语料库的荷兰语部分不只包含命名实体标注,也包含词性标注。


基于深度学习的中文命名实体识别与关系抽取技术研究概述中文命名实体识别(Chinese Named Entity Recognition, CNER)和关系抽取(Relation Extraction, RE)是自然语言处理中的重要任务。
命名实体识别旨在从文本中识别出具有特定意义的实体,如人名、地名、组织机构等。
关系抽取则是从文本中提取出实体之间的关系,如雇佣、拥有等。
本文将基于深度学习探讨中文命名实体识别与关系抽取的技术研究。
1. 中文命名实体识别技术研究中文命名实体识别是信息提取、问答系统、机器翻译等自然语言处理任务的重要基础。
随着深度学习的兴起,基于神经网络的方法成为了命名实体识别的主流。
常见的深度学习模型包括循环神经网络(Recurrent Neural Network, RNN)和卷积神经网络(Convolutional Neural Network, CNN)。
其中,循环神经网络通过遍历输入序列,保留上下文信息,逐步学习并预测每个字的标签。
长短期记忆网络(Long Short-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)是两种经典的循环神经网络结构,能更好地捕捉长距离依赖关系。
卷积神经网络则通过卷积操作在局部观察下提取特征,并通过池化层减少参数数量。
针对中文命名实体识别,可以使用卷积神经网络对字向量进行卷积操作,然后将得到的特征输入到全连接层进行分类。
此外,还可以结合预训练的字向量模型,如Word2Vec、GloVe等,来进一步提升命名实体识别的性能。
通过在大规模语料上预训练词向量,并将其作为输入特征传递给深度学习模型,可以更好地捕捉词语的语义信息。
2. 中文关系抽取技术研究中文关系抽取旨在从文本中提取出实体之间的关系,为自然语言处理任务中的重要环节。
与中文命名实体识别类似,深度学习方法也在中文关系抽取中取得了显著的效果。
目前,常用的深度学习模型包括基于卷积神经网络的方法和基于循环神经网络的方法。

基于深度学习的中文命名实体识别与关系抽取方法研究标题:基于深度学习的中文命名实体识别与关系抽取方法研究摘要:命名实体识别和关系抽取是自然语言处理中的两个重要任务。
传统的基于规则和模板的方法在中文命名实体识别和关系抽取的效果上受限,因此,本文采用基于深度学习的方法进行研究。
具体而言,本文构建了一个深度学习模型,并使用现有的中文命名实体与关系数据集对模型进行训练和测试。
实验结果表明,本文构建的深度学习模型在中文命名实体识别和关系抽取任务上取得了较好的性能表现。
关键词:深度学习,命名实体识别,关系抽取,中文1. 引言命名实体识别和关系抽取是自然语言处理中的两个重要任务,在信息抽取、知识图谱构建等应用中具有广泛的应用。
传统的基于规则和模板的方法在中文命名实体识别和关系抽取的效果上受限,因此,研究如何利用深度学习方法提升中文命名实体识别和关系抽取的效果是很有意义的。
2. 相关工作2.1 传统方法传统方法主要利用规则、模板和特征工程等手段进行命名实体识别和关系抽取。
这些方法依赖于领域专家的知识和人工设计的规则,因此鲁棒性较低,且在处理复杂语义关系时效果不佳。
2.2 深度学习方法深度学习方法在各个自然语言处理任务中取得了显著的性能提升,因此也被引入到命名实体识别和关系抽取任务中。
深度学习方法利用神经网络模型自动学习特征表示,具有较好的鲁棒性和泛化能力。
3. 方法设计本文采用了一种基于卷积神经网络(CNN)和长短时记忆网络(LSTM)的深度学习模型进行中文命名实体识别与关系抽取任务。
具体而言,模型的输入是以字符级别表示的句子和对应的标签,经过多层卷积层和LSTM层进行特征提取和序列学习,最后通过softmax层进行实体类别和关系的分类。
4. 实验设置本文使用了现有的中文命名实体与关系数据集对模型进行训练和测试。
选择合适的数据集是保证模型性能的关键因素。
在实验中,我们对模型进行了优化,并使用了交叉验证等技术来评估模型的性能。
基于自然语言处理技术的中文命名实体识别与关系抽取研究与应用自然语言处理(Natural Language Processing, NLP) 是一种涉及计算机科学、人工智能和语言学的交叉学科,目的是使计算机能够处理和理解人类语言。
其中,中文命名实体识别与关系抽取是NLP领域中的重要研究方向之一。
本文将深入探讨基于自然语言处理技术的中文命名实体识别与关系抽取的研究与应用。
一、中文命名实体识别的研究与应用中文命名实体识别是指从中文文本中识别出各种命名实体,如人名、地名、机构名等。
命名实体识别是NLP中的一个基础任务,具有广泛应用价值。
在文本挖掘、社交网络分析、搜索引擎优化等领域,中文命名实体识别能够帮助系统理解和处理大量文本信息。
当前,主流的中文命名实体识别方法主要包括基于规则的方法、基于统计的方法和基于深度学习的方法。
基于规则的方法通常依靠人工制定的规则和正则表达式来进行识别,但对于不同实体类型的识别效果有较大局限性。
基于统计的方法利用机器学习算法,通过训练语料库提取特征,构建分类模型来识别命名实体,其精度较高。
而基于深度学习的方法则利用神经网络结构,通过大规模语料的无监督或半监督训练,能够在无需人工规则的情况下实现对命名实体的高效识别。
中文命名实体识别的应用领域非常广泛。
例如,在搜索引擎优化中,识别文本中的命名实体可以帮助搜索引擎更准确地理解用户查询意图,提高搜索结果的质量和准确性。
在舆情分析中,通过识别文章中的人名、地名等实体,可以更好地洞察公众舆论动态,为决策者提供参考依据。
二、中文关系抽取的研究与应用中文关系抽取是指从中文文本中自动识别出实体之间的语义关系。
关系抽取是自然语言处理中的一个重要任务,能够帮助分析文本中实体之间的联系和交互,进一步深化文本理解的层次。
目前,中文关系抽取主要采用基于机器学习的方法。
这些方法通常利用标注好的语料库,通过训练学习的方式,构建分类模型来判定实体间是否存在某种关系。
基于深度学习的中文命名实体识别与实体关系抽取研究一、引言中文命名实体识别(Named Entity Recognition,简称NER)和实体关系抽取(Relation Extraction,简称RE)是自然语言处理中两个重要的任务。
NER是指从文本中识别出具有特定意义的实体,如人名、地名、时间等,而RE则是指通过分析文本中的语义特征,提取出实体之间的关系。
近年来,随着深度学习技术的迅速发展,尤其是基于神经网络的方法,中文NER和RE的研究也取得了显著进展。
本文旨在综述基于深度学习的中文NER和RE的研究现状,并探讨其中的方法和挑战。
二、中文命名实体识别研究中文NER的目标是从文本中识别出实体并将其分类为预定义的类别,如人名、地名、组织机构名等。
传统的方法通常基于规则和特征工程,具有一定的局限性。
而深度学习的方法通过利用大量标注的数据进行端到端的训练,克服了传统方法的缺点。
基于深度学习的中文NER方法主要分为两种:基于循环神经网络(Recurrent Neural Networks,RNN)和基于转换器模型(Transformer)。
RNN方法通过应用长短期记忆网络(Long Short-Term Memory,LSTM)或门控循环单元(Gated Recurrent Unit,GRU)等结构,对句子进行逐字或逐词的序列建模,从而提取实体信息。
而Transformer方法则通过引入自注意力机制,对整个句子进行并行计算,实现了更高效的特征提取。
此外,还有一些基于深度学习的中文NER方法结合了多种模型和技术,如多任务学习、迁移学习和注意力机制等。
这些方法通过对文本的层次化建模、共享参数和自适应特征学习等手段,进一步提高了NER的性能。
三、实体关系抽取研究实体关系抽取的目标是识别文本中实体之间的语义关系,并将其分类为预定义的关系类别。
传统的方法主要依赖于人工设计的特征和规则,对于复杂的语义结构往往效果不佳。
基于自然语言处理的中文命名实体识别与关系抽取技术研究自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的重要研究方向之一。
中文命名实体识别与关系抽取技术是NLP中的一个重要任务,旨在从大规模的文本数据中自动识别出文本中具有特定意义的实体信息,并进而抽取出实体之间的关系。
本文将围绕基于自然语言处理的中文命名实体识别与关系抽取技术进行研究,详细讨论相关的算法、应用场景和挑战。
中文命名实体是指在文本中具有独特标识的实体,如人名、地名、组织机构名等。
中文命名实体识别是在中文文本中自动标识出这些实体的过程。
传统的中文命名实体识别方法主要基于规则、字典或模式匹配等方式,存在对语义信息的依赖性强、领域特定等问题。
而基于自然语言处理的中文命名实体识别技术,常常基于机器学习和深度学习算法,以训练模型从文本中学习特征并进行实体识别。
中文关系抽取是指从文本中识别出不同实体之间的关系,以发现实体之间的联系。
关系抽取可以用于构建知识图谱、智能问答系统等应用。
传统的中文关系抽取方法主要基于语义角色标注、依存句法分析等技术,但在大规模文本数据中存在着歧义性、标注困难等问题。
基于自然语言处理的中文关系抽取技术通过深度学习方法,使得计算机能够从大规模的文本数据中学习关系的表示,并自动进行关系抽取。
中文命名实体识别与关系抽取技术在多个实际应用场景中发挥着重要作用。
例如,在信息抽取任务中,可以通过识别出文本中的人名、地名等命名实体,并进一步抽取这些实体之间的关系,构建出具有语义信息的知识图谱。
在智能问答系统中,利用中文命名实体识别与关系抽取技术,可以更好地理解用户提问的语义,并提供准确的回答。
然而,中文命名实体识别与关系抽取技术仍然面临一些挑战。
首先,中文的特点使得命名实体识别和关系抽取更加复杂。
中文词汇存在词义歧义,同一个词可能具有多个不同的实体类别,这增加了命名实体识别的难度。
其次,中文的语法结构复杂,关系抽取需要考虑到不同句子结构和语法成分之间的关系。
基于自然语言处理的中文信息抽取系统设计与实现自然语言处理(Natural Language Processing, NLP)是人工智能领域中的一个重要分支,旨在使计算机能够理解和处理自然语言。
中文信息抽取是NLP中的一个关键任务,其目标是从给定的中文文本中提取出有用的信息。
本文将介绍一个基于自然语言处理的中文信息抽取系统的设计与实现。
一、引言随着互联网的发展和信息爆炸式的增长,中文文本逐渐成为人们获取信息的重要来源。
然而,海量的中文文本给人们带来了信息过载的困扰,如何从中获取有用的信息成为了一个亟待解决的问题。
中文信息抽取系统的设计与实现旨在解决这一问题,帮助用户从海量的中文文本中快速、准确地提取出所需的信息。
二、系统架构设计基于自然语言处理的中文信息抽取系统的设计可以分为四个主要模块:文本预处理、实体识别、关系抽取和结果展示。
1. 文本预处理文本预处理是信息抽取系统中的基础环节,其目的是将原始的中文文本转化为计算机可以识别和处理的形式。
在文本预处理模块中,首先需要进行文本分词,将连续的中文文本切分成单个词语。
然后,需要进行中文文本的词性标注,即对每个词语进行词性的标记。
最后,还需要进行停用词过滤,将一些无意义的常用词语过滤掉,以减少文本处理过程中的噪声。
2. 实体识别实体识别是信息抽取系统中的核心环节,其目的是识别出中文文本中的实体,如人名、地名、组织机构等。
实体识别可以分为命名实体识别和实体类型分类两个子任务。
命名实体识别是指从文本中识别出具有特定名称的实体,如人名、地名等。
实体类型分类则是将识别出的实体按照一定的分类体系进行分类,如将人名识别为人物、将地名识别为地点等。
3. 关系抽取关系抽取是信息抽取系统中的重要环节,其目的是从中文文本中提取出实体之间的关系。
关系抽取可以分为两类:句子级关系抽取和篇章级关系抽取。
句子级关系抽取是指从单个句子中提取出实体之间的关系。
篇章级关系抽取则是在整个语料库中寻找实体之间的关系,并进行关系的推断和归纳。