不确定性数据的分类方法研究综述
- 格式:pdf
- 大小:756.60 KB
- 文档页数:4


如何进行系统性综述步骤与方法介绍系统性综述(Systematic Review)是一种重要的研究方法,它通过系统地搜集、评估和整合已有的研究数据,以回答特定的研究问题。
本文将介绍系统性综述的步骤和方法,帮助读者了解如何进行一次高质量的系统性综述研究。
一、研究问题的明确与范围确定进行系统性综述的第一步是明确研究问题,并确定综述的范围。
一个明确的研究问题有助于指导综述的设计和实施,而范围确定可以帮助限定综述的内容和搜索策略。
二、搜索策略的设计与文献筛选在进行系统性综述之前,需要设计一个合适的搜索策略来搜集相关的研究文献。
搜索策略应该包括关键词的选择、数据库的选择以及筛选标准的确定。
一旦搜集到文献,还需要进行筛选,根据事先确定的纳入和排除标准对文献进行初步的筛选和评估。
三、数据的提取和分析在文献筛选的基础上,需要对选入综述的文献进行数据的提取和分析。
数据提取通常包括作者、样本量、实验设计、主要结果等信息的摘录。
而数据分析则可以采用统计学的方法,如计算效应量、进行荟萃分析等。
四、质量评估和风险偏倚的评估在进行综述的过程中,还需要对纳入的研究进行质量评估和风险偏倚的评估。
质量评估可以通过评估研究的方法学质量、统计分析的可信度等方面来进行。
而风险偏倚的评估则可以通过评估研究中的偏倚风险来源和影响等方面来进行。
五、综合分析和结果呈现最后,需要对提取和分析的数据进行综合分析,并将系统性综述的结果呈现出来。
综合分析可以通过定性或定量的方式来进行,如通过描述分析、元分析等。
结果呈现则可以通过表格、图表、文字等形式来展示。
六、讨论和结论在结果呈现的基础上,需要对综述的结果进行讨论和结论。
讨论可以对综述的限制、不确定性以及结果与现有理论或实践的一致性进行讨论。
结论则是对研究问题的回答和对整个综述的总结。
通过以上介绍的步骤和方法,读者可以了解到进行系统性综述的一般流程和关键要点。
然而,每个综述都可能具有特定的情境和要求,所以,具体的细节和注意事项仍然需要根据研究问题来确定。

不确定性可视化综述一、绪论A.研究背景与意义B.研究目的与任务C.研究方法与思路二、不确定性可视化概述A.不确定性定义与分类B.不确定性可视化介绍C.不确定性可视化的应用领域三、不确定性可视化技术A.基于统计的可视化方法B.基于模型的可视化方法C.基于混合可视化的方法四、不确定性可视化评价A.可视化效果评价指标B.可视化识别评价技术C.不确定性可视化性能分析五、不确定性可视化应用A.流体动力学模拟可视化中的不确定性可视化应用B.气象预测模拟中的不确定性可视化应用C.医学方面中的不确定性可视化应用六、总结与展望A.对不确定性可视化现状的总结B.不确定性可视化未来的展望C.不确定性可视化研究的进一步方向第一章:绪论随着科技的进步和数据的爆炸性增长,传统的数据处理和分析方法已经无法满足人们对数据的需求。
在现实生活中,我们面对的很多数据都是不确定的,例如石化厂的爆炸危险性分析、天气预报的准确性等问题都牵涉到一定程度的不确定性。
因此,对不确定性的处理和分析已成为一个重要的研究领域。
不确定性可视化可以帮助人们更好的理解和分析数据中的不确定性,它是一种将不确定性转化为可视化表示的技术手段,能够提供更直观和交互性的数据处理和分析方式。
它不仅能够展现数据的潜在规律和趋势,还能够展现数据的误差、偏差和不确定性等方面的特征,帮助人们更好地理解数据,并做出正确合理的决策。
本章主要从以下三个方面出发,介绍不确定性可视化的相关基础知识,包括研究背景与意义、研究目的与任务以及研究方法与思路。
一、研究背景与意义随着计算机科学和人工智能等技术的不断发展,数据爆炸式增长的时代已经到来。
大数据的出现给我们带来了许多机遇,同时也带来了很多挑战和问题。
大数据不仅包含非常丰富和复杂的信息,还包含大量的不确定性。
不确定性普遍存在于各种各样的领域中,如温度计量程误差、医学诊断精确度、交通拥堵程度等都存在不确定性。
因此,针对不确定性的可视化研究具有十分广泛的应用前景和应用价值。

共因失效分析中不确定性数据的处理方法
王学敏;谢里阳;周金宇
【期刊名称】《机械设计》
【年(卷),期】2004()z1
【摘要】共因失效分析中数据的处理常面临着诸多的不确定性,为此影响向量法得到了广泛的应用,然而如果一个系统没有实时监控装置,数据均来源于周期性的测试,那么发现的失效元件是由几次冲击造成的?对此影响向量法束手无策,针对这一问题本文提出了扩展影响向量法.
【总页数】2页(P73-74)
【关键词】系统可靠性;共因失效;不确定性
【作者】王学敏;谢里阳;周金宇
【作者单位】东北大学,机械工程与自动化学院,沈阳,110004 东北大学,机械工程与自动化学院,沈阳,110004 东北大学,机械工程与自动化学院,沈阳,110004
【正文语种】中文
【中图分类】TH122
【相关文献】
1.共因失效率的不确定性评估 [J], 王学敏;谢里阳;周金宇
2.概率安全分析中共因失效数据处理方法研究 [J], 马超
3.关于区间删失的失效时间数据处理方法的分析 [J], 肖丽丽;谷继品;翟晓;张健鑫;郭晓娴
4.遥感影像数据分类的不确定性分析及其处理方法综述 [J], 陈焕南;林红燕;邢海花
5.网络化测试体系中不确定性数据处理方法浅析 [J], 彭宇;罗清华;彭喜元
因版权原因,仅展示原文概要,查看原文内容请购买。

空间数据处理模型不确定性分析方法研究的开题报告一、选题背景及意义随着信息技术的快速发展,地理信息系统(GIS)的应用越来越广泛,空间数据处理模型的不确定性也越来越受到关注。
不确定性是指对系统内某些参数或状态无法完全确定的情况,也即存在不确定的概率分布。
在空间数据处理中,由于数据源的不同、数据获取的精度不同、算法的选择不同等因素的影响,处理结果可能存在一定的不确定性。
因此,空间数据处理中的不确定性分析尤为重要,它能够帮助我们更好地理解结果的可信度和局限性,从而更准确地进行数据分析和决策。
本文拟就空间数据处理模型不确定性分析方法进行研究,探讨其不确定性的来源和处理方法,为应用地理信息系统做出更准确的数据分析和决策提供理论和方法支持,也为相关领域的研究提供参考。
二、研究内容本研究拟从以下几个方面入手:1. 空间数据处理模型不确定性的来源;2. 常用的空间数据处理模型不确定性分析方法及其优缺点;3. 针对实际应用场景,建立基于贝叶斯理论的空间数据处理模型不确定性分析方法;4. 实验验证。
三、研究方法本研究主要采用文献综述和理论分析相结合的方式进行,通过对相关文献的查阅和分析,了解已有研究成果及其不足之处,构建研究框架和方法流程,提出相应的改进和优化方法。
同时,还需要结合实际数据,分析其不确定性来源和特点,根据实验结果对比不同方法表现,验证研究成果的有效性。
四、研究目标及预期成果本研究的目标是建立一种基于贝叶斯理论的空间数据处理模型不确定性分析方法,为应用地理信息系统做出更准确的数据分析和决策提供理论和方法支持。
预期成果包括:1. 空间数据处理模型不确定性产生的来源和本质的分析;2. 常见的空间数据处理模型不确定性分析方法的优缺点;3. 基于贝叶斯理论的空间数据处理模型不确定性分析方法的建立,并做出相应实验验证和分析;4. 提出改进和优化方法,为相关领域研究提供参考和借鉴。

0背景在核反应堆确定论安全分析中,利用热工水力程序对核电厂或核动力装置在事故下的瞬态响应进行预测,以评价其安全性。
这是自20世纪50年代核反应堆系统投入运行以来,热工水力安全分析研究领域的主要议题。
热工水力安全分析程序作为事故安全分析的主要手段和工具,其重要性不言而喻。
从20世纪60年代初期直至现在,随着对反应堆热工水力现象的不断认识和计算机技术的巨大发展,安全分析程序发生了深刻的变化,逐渐从保守粗放的评价模型程序(EM)发展到真实精细的最佳估算程序(BE)。
其中,著名的最佳估算程序如RELAP5(美国),TRAC(美国),ATHLET(德国)和CATHARE(法国)等,上述程序体系庞大,源程序多达10万行,描述了反应堆系统各个部分的70多种不同的热工水力现象,已广泛应用于各国核电厂或核反应堆装置的设计和事故安全分析中。
尽管现阶段的热工水力安全分析程序已达到相当高的成熟度,由于目前的科学认知水平以及程序在模型和数值计算近似等方面的局限性,不可能期望计算机程序对于核电厂响应进行完全准确的模拟。
一般来讲,程序预测的结果总是与试验数据存在一定的偏差。
产生偏差的原因来自于模型偏差,数值计算近似,节点划分效果,初始条件和边界条件描述的不充分等。
因此,有必要对结果的不确定性以及最重要参数的敏感性进行研究。
事实上,最佳估算程序加不确定性分析是核电厂安全分析技术发展的重要方向和热门问题,也是核电厂安全评审的趋势。
1不确定性分析方法的发展历史在核反应堆大破口失水事故分析的初期,采用符合NRC颁布的美国联邦法规导则(CFR)第50部分规定的保守评价模型方法,然而,通过大量试验对失水事故的认识不断深入,发现评价模型计算得到的最高包壳峰值温度比最佳估算结果高出400-500K,评价模型太过保守,而大破口失水事故是核电厂设计最为限制性的设计基准事故,过于保守的分析结果将限制核电厂提升功率以及运行灵活性。
因此,美国在长达约十年、投入约100亿美元的试验及理论研究基础上,在核工业界、研究机构以及NRC的共同推动下,1989年NRC修改了其管理导则[1],其重要特点为:允许在应急堆芯冷却系统(ECCS)分析中使用最佳估算模型,同时必须量化计算结果的不确定性。

大数据安全研究综述随着大数据技术的日益发展,大数据安全问题也越来越受到人们的关注。
本文将对近年来大数据安全研究领域的相关工作进行综述。
一、大数据安全威胁大数据安全威胁包括以下几个方面:数据泄露、数据篡改、数据丢失、隐私泄露、身份伪装等。
1.数据泄露大数据中存储的数据是企业或个人的重要信息,一旦被泄露,将会造成严重的经济和社会损失。
2.数据篡改大数据中的数据量极大,由于数据来源和数据质量的不确定性,难以确定数据的真实性和完整性。
因此,黑客或攻击者可以通过篡改数据来达到各种目的。
3.数据丢失大数据的存储方式和传输方式非常复杂,不可避免地会出现数据丢失的情况,特别是在数据备份方面存在巨大的难度。
5.身份伪装攻击者可以通过伪装身份来获取机密信息,并且很难被发现。
因此,在大数据环境下,身份验证和访问控制显得非常重要。
二、大数据安全技术目前,针对大数据安全威胁,研究者们提出了一系列解决方案。
1.加密技术加密技术是目前最基本的安全技术,可以保证数据在传输过程中的隐私性和机密性。
在大数据存储和传输方面,加密技术可以通过数据加密、会话加密、磁盘加密等方式来实现。
2.访问控制技术访问控制技术是大数据安全技术中非常重要的一部分,可以帮助用户进行身份验证和权限控制。
目前,常见的访问控制技术包括基于角色的访问控制、基于身份的访问控制、基于属性的访问控制等。
3.数据备份和恢复技术数据备份和恢复技术是保证大数据可靠性和稳定性的关键技术,可以帮助用户尽快从数据丢失或硬件损坏等情况中恢复数据,并且保障数据的一致性。
4.数据脱敏技术数据脱敏技术可以避免敏感数据的泄露,主要包括数据加密、数据掩码、数据消毒等方法。
5.远程监控技术远程监控技术可以对大数据系统进行全面监控,及时捕捉安全漏洞和攻击行为,保障大数据的安全性。
6.智能安全威胁分析技术智能安全威胁分析技术可以通过对大数据进行深度分析和挖掘,发现安全威胁和异常行为,提高安全防护的能力。

研究综述引言研究综述是在特定主题下对已有文献和研究成果进行全面梳理和综合分析的一种学术写作形式。
通过研究综述,可以系统地整理并评价该主题相关文献的研究方法、实验设计、数据分析和结果解释等方面的特点,总结出已有研究的优点、不足和不确定性,并提出进一步的研究方向和展望。
研究综述的意义研究综述在科学研究中具有重要的意义。
首先,通过对已有文献和研究成果的综合分析,研究综述能够揭示研究领域的研究热点和趋势,为后续的研究提供重要的参考。
其次,研究综述可以挖掘已有研究的不足和问题,为未来的研究提供改进和完善的方向。
此外,研究综述还可以推动学术交流和合作,促进学术进步和创新。
研究综述的流程研究综述的撰写一般可按如下流程进行:1.确定研究主题:选择一个明确的研究主题是进行研究综述的第一步。
研究主题应该具有一定的科学价值,同时要确保相关文献和研究成果的数量和质量足够。
2.收集文献和数据:在确定研究主题后,需要广泛收集相关文献和研究成果。
可通过图书馆、数据库、互联网等途径进行文献检索,并使用引文索引等工具追踪引用。
3.文献筛选和评估:在收集到大量的文献和研究成果后,需要对其进行筛选和评估,排除与研究主题关联度较低的内容,选择质量较高的研究进行进一步的分析和综合。
4.文献分析和综合:通过对选定的文献和研究成果进行深入分析和综合,总结已有研究的主要特点、方法和结果,并评价其优缺点和不确定性。
5.结果解释和展望:根据文献分析和综合的结果,对该领域已有研究的成果进行解释,提出进一步研究的方向和展望,以期推动该领域的发展和创新。
研究综述的写作技巧在撰写研究综述时,需要注意以下几点写作技巧:1.结构清晰:研究综述的结构应该清晰明了,包括引言、研究背景、研究目的、文献分析和综合、结果解释和展望等部分。
每个部分的内容都要逻辑连贯,有条理。
2.文献引用准确:在文中引用文献时,需要准确、规范地标注文献的来源和作者。
可以采用著者-年代制或数字标注法,根据具体的写作规范进行引用。

科学技术创新2020.10(转下页)化,所以,出风口和入风口的气体流量不受改造的影响。
5.2内部改造不足2微米的微尘是能够进入仪器设备内部的粉尘,将过滤网安装在仪器设备内部的自循环系统,可过滤不足2微米的微尘。
采用飞利浦空气净化器中的过滤网对粉尘进行过滤。
将过滤网在光路冷却进口和涡轮风机出口进入内部循环冷却气部位进行安装,适当裁剪采购的过滤网,在相应部位上进行安装。
经测试后,进风和出风口风速改造前达到2.8米/秒的风速,改造后达到2.8米/秒的风速,仪器设备内部的冷却气循环流量在改造前后未发生任何变化。
6研究结果及分析仪器设备经改造后,仪器设备内部冷却管路内的粉尘运行一段时间后能够明显减少。
比较内外部冷却循环系统中的粉尘在改造前后发生的变化,结果显示,外循环送风系统经改造后,送风口部位能够被过滤掉大颗粒的粉尘,每周只需清洗一次初过滤网,每周清洁一次的内部冷却循环管路减少到每月清洗一次。
将每周清洁一次的内部冷却风扇的页面减少到每月清洁一次,能够明显改善富集粉尘情况,从每周收集约0.2克的内部冷却循环管路部位减少到每月收集0.01克。
从每周收集约0.5克的内部冷却风扇页面减少到每月收集约0.02克,具有比较显著的效果。
电感耦合等离子体发射光谱仪仪器操作软件中改造后的空气冷却报警系统未再发生报警情况,仪器设备能够正常运转,此经验可用于改造供其它精密仪器设备的防尘工作。
7结论综上所述,在日常工作中电感耦合等离子体发射光谱仪的自动化程度最成熟,即使操作人员技术不熟练,采用电感耦合等离子体发射光谱仪专家制定的方法也可顺利完成相关工作。
对电感耦合等离子体发射光谱仪设备中粉尘的形态和粒径进行分析,对电感耦合等离子体发射光谱仪设备的外部和内部循环冷却系统进行改造,进而使粉尘明显减轻影响仪器设备运行的程度,电感耦合等离子体发射光谱仪设备有效降低日常维护成本及维护频率,电感耦合等离子体发射光谱仪设备的使用效率进一步提高,并对某苛刻的操作环境而言,电感耦合等离子体发射光谱仪设备不再受到限制,为将精密仪器日后在不同环境中的应用积累十分重要的实践经验。
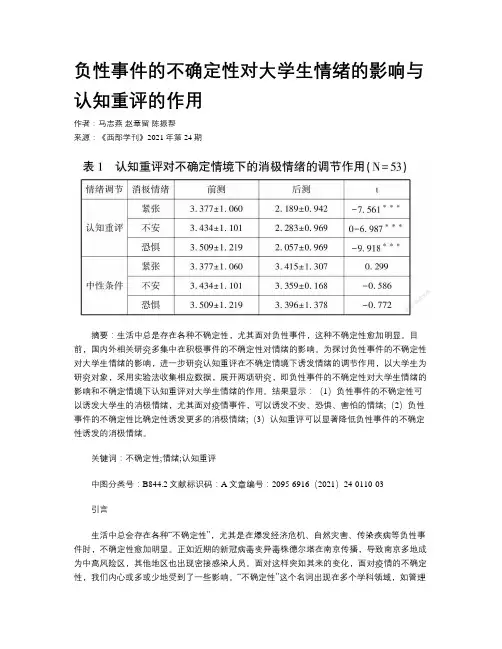
负性事件的不确定性对大学生情绪的影响与认知重评的作用作者:马志燕赵章留陈振帮来源:《西部学刊》2021年第24期摘要:生活中总是存在各种不确定性,尤其面对负性事件,这种不确定性愈加明显。
目前,国内外相关研究多集中在积极事件的不确定性对情绪的影响。
为探讨负性事件的不确定性对大学生情绪的影响,进一步研究认知重评在不确定情境下诱发情绪的调节作用,以大学生为研究对象,采用实验法收集相应数据,展开两项研究,即负性事件的不确定性对大学生情绪的影响和不确定情境下认知重评对大学生情绪的作用。
结果显示:(1)负性事件的不确定性可以诱发大学生的消极情绪,尤其面对疫情事件,可以诱发不安、恐惧、害怕的情绪;(2)负性事件的不确定性比确定性诱发更多的消极情绪;(3)认知重评可以显著降低负性事件的不确定性诱发的消极情绪。
关键词:不确定性;情绪;认知重评中图分类号:B844.2文献标识码:A文章编号:2095-6916(2021)24-0110-03引言生活中总会存在各种“不确定性”,尤其是在爆发经济危机、自然灾害、传染疾病等负性事件时,不确定性愈加明显。
正如近期的新冠病毒变异毒株德尔塔在南京传播,导致南京多地成为中高风险区,其他地区也出现密接感染人员。
面对这样突如其来的变化,面对疫情的不确定性,我们内心或多或少地受到了一些影响。
“不确定性”这个名词出现在多个学科领域,如管理学、经济学、物理学等。
人们经历着来自生活各个方面的不确定,李纲等人认为,不确定性的概念一般可以用概率来加以描述,即在某种环境状态下,某一特定事件的概率分布处于离散状态。
换句话说,不确定性可以通俗地理解为行为者对环境状态的无知程度,不知道接下来会发生什么。
不确定性的研究涉及多个领域,但是从心理学角度进行的研究相对较少。
一、不确定性的心理学研究综述(一)国外心理学者对不确定性的研究主要集中在不确定性对情绪的影响方面BADIA等人对不可预知的压力进行了实验研究,相对于不可预知的电击,被试者更倾向选择直接立即的电击;暴露在不可预知的电击下,被试者感到更多的焦虑和无助。

论文写作技巧分享文献综述的分类与整理方法在进行学术研究时,文献综述是不可或缺的一部分。
通过对已有研究的梳理和总结,文献综述有助于研究者了解某一领域的研究现状,发现研究空白,并为自己的研究提供理论支持。
然而,由于文献综述涉及大量的文献阅读和信息整理,对于初学者而言,往往会面临一定的困难。
本文将分享一些论文写作技巧,介绍文献综述的分类与整理方法,希望能够对学术研究者提供一些指导与帮助。
一、文献综述的分类方法对于文献综述的分类,学界并无统一的标准,不同领域、不同研究目的可能采用不同的分类方法。
这里,我们将文献综述分为两大类别:研究综述和理论综述。
1. 研究综述研究综述是指对一个特定主题或问题的研究现状进行总结与分析。
通过对已有研究的归纳、对比和总结,研究综述可以帮助研究者系统地评述之前的研究成果,提出自己的研究问题和研究方法,为自己的研究提供理论依据。
研究综述可以按时间顺序、研究方法、研究对象等多种方式进行分类。
按时间顺序分类时,可以将研究综述分为历史综述和最新综述,前者主要总结过去的研究成果,后者则关注最新的研究进展。
按研究方法分类时,可以将研究综述分为定量综述和定性综述,前者以统计数据和模型为基础,后者则以深入的访谈和观察为主要手段。
按研究对象分类时,可以将研究综述分为个体研究综述和群体研究综述,前者关注个体间的差异,后者则关注群体间的差异。
2. 理论综述理论综述是指对某一理论体系进行总结和阐述。
通过对已有理论的梳理和整理,理论综述可以帮助研究者了解某一领域的理论发展脉络和演变过程,明确自己的研究框架和理论取向。
理论综述可以按理论的发展阶段、研究角度和学科交叉等多种方式进行分类。
按发展阶段分类时,可以将理论综述分为起源综述、发展综述和应用综述,前者主要介绍理论的起源和基本概念,后者则关注理论的发展历程和应用前景。
按研究角度分类时,可以将理论综述分为实证综述和理论综合综述,前者重在分析与验证某一理论的实证研究,后者则强调整合不同理论的观点和主张。
类别不确定时特征推理新进展的研究综述摘要人们不能完全确定将事物归入某一类别的情境称为类别不确定情境。
国内外众多的学者对归类不确定条件下的特征推理情况进行了研究。
本文对研究的新进展进行综述,并对本领域的发展进行了展望。
关键词理性模型单类说中图分类号:b842 文献标识码:a推理是指对未知特征进行推测。
一般推理问题的研究已经相对成熟。
但现实中还存在类别不确定的情况,即人们不能完全确定将事物归入某一确定类别的情境。
国内学者莫雷等对此项专题进行了系列研究。
对原有理论完善的基础上提出了新的理论解释。
而国外则在原有理论基础上不断进行研究与创新,使得问题更加明确,提出了新的更具意义的研究方向,更好的揭示了归类不确定条件下特征推理的实质。
本文主要对新的研究进行综述。
1主要理论1.1 理性模型anderson最先提出了归类不确定情况下,人们通过联合使用每一类别的可能性来做出总体预测的理论。
该模型认为在归类不确定条件下,人们会综合考虑靶类别与非靶类别的信息。
靶类别是指目标物最可能归属的类别其余则为非靶类别。
其公式描述为:1.2单类说murphy等提出了归类不确定条件下的单类说。
单类说认为人们在进行特征推理时只考虑最可能的类别而不考虑非靶类别的信息。
2新理论的提出2.1对理性模型的修正此阶段进行的研究是围绕在什么条件下人们会考虑单一类别,在什么情况下人们会考虑多个类别。
早期对单类说的解释有两种:①为人们不能理解不确定问题的性质,不能在早期阶段意识到不确定性,这会在问题的后续阶段对预测或选择产生影响。
忽略不确定性使得他们选择靶类别进行推理。
②为两阶段理论:阶段1,当一个物体呈现并需要归类时,人们会考虑一系列它可能归属的类别,并且在类别判断时是明确已知的。
阶段2,只有关于靶类别的典型信息作为特征预测的因素进行计算。
单类说可能是预测准确性与认知努力的适当折中。
国外文献通过增加非靶类别的突显度,证实这种条件下人们会使用多类别。
基于数学的不确定理论方法综述:不确定性是人们认识世界的局限性导致的,它是人们根据现有知识的基础上对世界以及事物的看法、决定。
由于认识的局限性,就会导致对事物的看法存在不可预知性。
不确定性存在于生活的方方面面,大到人文系统,小到零件检测,如何更加准确的了解事物,不确定理论的发展起了重要的作用。
不确定性理论就是为了能够在现有知识的基础上来找出其规律,以求得到更合适的方法解决问题的途径。
不确定性理论用于数据融合中,有效的促进了信息融合理论的发展,相反,同样也促进了不确定性理论的发展。
自从上世纪统计力学的发展,不确定性理论随之出现并得到了学者重视。
曾经较长一段时间认为概率论为处理不确定信息的唯一方法和理论,但是随着应用的加深和人们对不确定性信息处理的更高要求,概率论在很多方面表现出它的局限性和不可描述性。
最近的几十年来,随着研究的深入,处理不确定信息方法也取得了较大的发展,主要有Zadeh的模糊集对经典集合论的推广,Choquet在容度理论中的单调测度论对经典测度论的推广等。
研究的成果不仅涉及到数学、物理等基础性理论,还拓展到了信息学科、航天技术等高科技领域。
基于不确定性智能芯片的开发是不确定性理论发展的见证,在工业领域已大量应用。
对于不确定性理论的研究,首先应该了解不确定测度(Uncertainty Measure)和不确定度(Measure of Uncertainty)的区别。
不确定测度是对事物本身不确定程度的描述,而不确定度是对不确定度的度量。
比如:一杯水加糖的概率是1/2和有1/2的概率这杯水加了糖,这个性质是不一样的,它反映了不确定测度和不确定度的关系。
不确定度的度量主要有熵的方法,如Information Shannon就提供了一个数量上的量度,即为一种典型的不确定度的度量。
为了能够很好地解释各种不确定性理论,对不确定性理论进行分类也是众多学者比较关注的问题。
从理论基础上讲不确定性理论分两大类:一类是基于数学的,另一类是基于逻辑学的,本章只介绍基于数学的一类不确定性理论,包括Bayes概率论、可能性理论,Dempster-Shafer理论,以使更好的了解不确定性问题。
核电厂最佳估算加不确定性分析方法研究综述【摘要】在核反应堆确定论安全分析中,利用热工水力程序对核电厂在事故下的瞬态响应进行预测,以评价其安全性。
这是自20世纪50年代核反应堆系统投入运行以来,热工水力安全分析研究领域的主要议题。
最佳估算加不确定性分析方法为国际原子能机构所推荐的安全分析方法,是核电厂执照申请安全分析技术的发展趋势,本文综述性的描述了最佳估算加不确定性分析方法的开发背景,发展历史和各类不确定性分析方法及其优缺点比较,为下阶段开发国内自主化的最佳估算加不确定性分析方法奠定基础.【关键词】事故分析;最佳估算;不确定性分析Overview in the Development of Best Estimate Plus Uncertainty Safety AnalysisRAN Xu ZHANG Xiao-hua LI Jie YANG Fan WU Peng(Science and Technology on Reactor System Design Technology Laboratory,Chengdu Sichuan 610213, China)【Abstract】In the deterministic safety analysis of nuclear power plant, the transient response of the nuclear power plant is predicted by the thermal—hydraulic code. It is the main issue in the nuclear thermal-hydraulic field from the first operation ofnuclear power plant in 50' last centuary。
Best Estimate plus uncertainty analysis is recommended by IAEA and is the safety analysis technology tendency。
第19卷第4期重庆科技学院学报(自然科学版)2017年8月不确定性数据的分类方法研究综述沈杰许高建杨阳李绍稳(安徽农业大学信息与计算机学院,合肥230036)摘要:传统的数据挖掘分类方法能够成功地应用于确定性数据分类,但却无法满足绝大多数领域中复杂的不确定性数据的分类需求,由此出现了一系列针对不确定性数据的分类方法。
通过大量研究,目前经典的分类算法及针对不确定数据分类的改进方法得到了很大发展,如改进后的支持向量机算法、朴素贝叶斯算法、决策树算法等日渐成熟。
关键词:不确定性数据;分类;支持向量机;朴素贝叶斯;决策树中图分类号:TP301 文献标识码:A文章编号=1673 -1980(2017)04 -0096 -04面临海量的、复杂的不确定性数据,针对不确定 性数据的数据挖掘成为智能分析数据并获取知识的 重要手段,分类算法成为其主要的研究方向之一。
2006年,第六届ffiEE数据挖掘国际会议(I C D M)评 选了最具影响的10个数据挖掘算法,其中分类算法 占据了 6 个:k - N N、Naive Bayes、C4. 5、C A R T、S V M、AdaB〇〇s t[1]。
分类的任务就是通过分析来建 立区分对象的分类模型,即分类器。
传统的分类算 法通常将精确数据作为研究背景,只考虑了精准数 据的输入和分类,因而不能直接应用于不确定性数 据分类,如支持向量机(S V M)、决策树、朴素贝叶斯 算法等。
针对此现象,基于这些算法的原有经典模 式加以改进,加入不确定性数据分析,可使得不确定 知识数据挖掘技术更加成熟。
1不确定性数据1.1不确定性数据的产生数据的不确定性源于数据本身。
数据不确定性 分以下几种情况:采集数据时出现缺省值、干扰值 等;在实验时受周围环境的影响而导致数据不确定; 在数据传输过程中的失真导致不确定性。
1.2不确定性数据的表示不确定性一般可分为存在(元组级)不确定性 和值(属性级)不确定性[2]。
其中,存在(元组级)不 确定性是指一个对象即有出现的可能性,也有不出 现的可能,如某天可能会下雨或者可能不会下雨;而值(属性级)不确定性是指这个对象取值的不确定 性。
在高维空间中,确定性数据对象表现为某些具 体的点,而不确定数据对象的表现形式为满足某种 分布的一个范围。
2常见的不确定性数据分类方法2.1支持向量机算法Vapnik等人提出的传统支持向量机是一种基 于统计学理论、以结构风险最小化为原则的判别式 分类器[>5]。
其基本思想是,在《维数据空间中寻 找一个超平面,可以极大化地将空间属于不同类别 的样本点分开,对于精确的小样本数据有很好的分 类效果。
孙喜晨等人对不确定数据作了预处理,在 属性均值聚类(A M C)与支持向量机(S V M)的基础 上,提出基于(属性)聚类的属性支持向量机(A M C -A S V M)算法[6]。
该算法对样本进行属性均值聚 类,然后将各个聚类中心及其属性作为新的样本点 来训练,进而得到分类器[7]。
但该方法本质上是将 数据的不确定性转化为确定性来处理,对不确定性 考虑得不够充分。
Jianqiang Y a n g等人在S V M中引入多维高斯分 布模型来描述不确定数据的,提出U S V C、A U S V C 及M P S V C支持向量机分类算法[8]。
U S V C的原始 问题通过引入约束得到,将机会约束的规划问题转 化为二次规划问题来求解。
而A U S V C以及M P S V C 是由U S V C算法改进而来,即通过调整U S V C中的收稿日期=2017 -03 -23基金项目:国家自然科学基金项目“农业领域(茶学)云本体建模与方法研究”(31271615)作者简介:沈杰(1990 —),女,合肥人,在读硕士研究生,研究方向为人工智能和数据挖掘• 96 •沈杰,等:不确定性数据的分类方法研究综述机会约束的置信参数来减小不确定性对构造分类器 的负面影响。
但该算法由于二次规划问题而导致计 算过程复杂、难以理解。
相对于区间的不确定,李文进等人提出了区间 不确定性超球支持向量机(I U H S V M)[9]。
该方法的 基本思想是:将不确定数据表示为球体凸集区域,形 成区间,找到一个超平面使得各类球体区域之间的 间隔尽可能大,使其能正确划分。
建立超球支持向 量机模型,将该模型转化为2层嵌套约束规划问题,使得其在寻找最优超平面的计算过程中,降低计算 难度。
大量的实验结果表明,I U H S V M算法相比其 他算法有较强的多分类处理能力,其球体凸集模型 能较好地描述不确定性。
2.2贝叶斯分类算法贝叶斯分类算法是基于贝叶斯定理的一种算法 统称。
在统计资料的基础上,依据某些特征,计算各 个类别的概率,以后验条件概率来判断是否属于该 类,从而实现分类。
朴素贝叶斯(Naive Bayes)法是 是基于贝叶斯定理和特征条件独立假设的分类方 法。
对于给定的训练数据集,首先基于特征条件独 立假设学习输入/输出的联合分布概率;然后基于此 模型,对给定的输入x,再利用贝叶斯定理求出其后 验概率最大的输出;T[W]。
对不确定性数据进行贝叶斯分类时,会使用概 率分布函数来表示该不确定区域[11]。
当数值型数 据属性是不确定的时候,称之为不确定性数值属性 (U N A)[12]。
有3种扩展的贝叶斯方法可以解决不 确定性数据分类,分别是均值的方法、基于分布的方 法及基于公式的方法[13]。
均值的方法是最为简单直接的一种方法。
用平 均值(期望)代替概率密度函数,从而使其变为点 值,实际上也是将不确定性数据转化为确定性数据,再使用原本的贝叶斯模型和核密度函数实现分类。
这个方法最大的优势就是简单明了,不需要使用新 的不确定性数据分类算法。
但其缺点也很明显:用 平均值代替区间同样对不确定性考虑得不够充分; 基于分布的方法重点在于对不确定性数据的类条件 分布进行估计,用概率密度函数来表示不确定数据,再将原本的核密度估计函数进行扩展,来进行不确 定性数据的分类。
相对而言,基于分布的方法对不 确定性数据的处理更完善;而基于公式的方法是通 过这些不确定性数据来确定新的核密度估计公式,再利用这个核密度估计公式完成分类。
该方法的 关键在于正确地生成核密度估计函数的公式,但 该方式仅仅适用于一些密度函数和概率分布函数的联合。
2.3决策树算法决策树,是一种用某种策略筛选条件而建立起来的树,利用递归的方式和分治的思想,自顶向下的分类方法。
决策树学习的目的是为了产生一颗范化能力强,即处理未见示例能力强的决策树,其基本流程遵循简单且直观的分而治之策略。
针对不确定性数据,目前有Dem pste和Shafe提 出的“证据理论”和经典决策树结合的D- S决策树算法[14]。
D-S决策树在不确定环境中(即目标所 在的类和属性的值是不确定的),通过证据理论决 策树分类模型中的置信度和似然函数来表达这个不 确定的值[1546]。
在该算法中利用不确定测量函数 (称为D- S熵)来选择划分属性,用经典决策树方 法生成决策树。
首先计算全集£»的不确定测量,假 设用£(£»)表示;然后求不确定区间的中心,即全集 的信任函数与全集的最大似然函数和的二分之一,假设用斤(£〇表示,最后求出的总不确定度测量函 数是两者之和,=£(£〇 +〜(£»)。
若要选择 属性4作为划分属性,且有F个可能取值,则要计算 4属性的D - S熵,最终求出平均互信息量[14]。
具 有最大互信息量的属性将作为划分属性。
在该算法 中,主要运用了置信度和最大似然函数来表达不确 定性,建树的过程参考经典决策树。
D T U[W]&是一种利用决策树处理不确定性数 据的算法,主要是通过扩展传统的信息熵和信息增 益来建立不确定性的决策树分类模型,当元组的概 率密度函数(probability density function, PD F)所在的域跨越分裂点时,P D F通过分数元组技术将元组 分裂到子集中[18_19]。
3不确定性数据的组合分类算法上述几种分类算法最终形成的分类器也只是单一的分类器,每一种分类器都有各自适用的场合。
在实际应用中,单一的分类器很难使其具有稳定性。
组合分类器可通过参考多个分类信息来提高分类精度,优化单一分类器的稳定性。
3.1基于期望值的A U G算法A U G(Average)算法处理不确定性问题的一般 思路是,将不确定性输入转化为确定性的输入。
在 高维空间中,不确定性表现为集中的一团数据。
在 这一团数据中有一个期望值,那么取这个期望值作 为新的样本,如此问题可转化为确定性分类,继而直 接使用传统的分类算法即可。
但该算法的严重缺点 在于,损失了大量的不确定信息,使得其分类结果不• 97 •沈杰,等:不确定性数据的分类方法研究综述够准确。
3.2基于采样的USM算法在上述AUG算法中,只取了一团数据样本中的 期望值作为一个确定的样本点,其结果导致分类不 准确。
为此,USM( Uniform Sampling M ethod)算法在 取样的时候并不再只取期望值一个样本,而是在期 望值的附近采样,这样一些样本也都接近期望值。
可以看出,这样的算法效率依赖于取样规模的大小,规模过大,消耗大,效率低,且规模过小也会出现分 类结果不准确。
3.3基于采样的EUS算法对于上述USM算法,规模大小影响分类结果,可以采用一种组合分类器策略:即对不确定性数据 进行规模大小一致的采样,但采样的点各不相同。
在若干次采样之后得到《个采样结果,对每一个采 样结果构建分类器,使得出现了《个分类器,将这《个分类器组合起来形成EUS ( Ensemble UniformSampling)算法。
该算法从原来的单一分类器变成 多分类器的组合,分类精度提高了,但与此同时也增 加了更多的消耗,效率问题仍有待解决。
3.4基于权重采样的EW S算法在上述EU S算法中,每个子分类器采样的规模 是相同的。
但在现实情况下,很多数据都会存在重 要性的问题,也就是权重大小的问题。
进行数据采 样时,应多采集权重大的数据,运用EWS ( Ensemble Weight Sampling)算法。
这就需要考虑,如何定义权 重的大小。
Schapire于1996年提出了 AdaBoost算 法,旨在通过寻找仅仅比随机猜测略好一些的弱学 习算法,就可以将其提升为强学习算法[M]。
该算法 的核心思想是,每分类一次得到一个分类器,每次 都会出现一些错分的情况。
将错分的点权值变大,迭代上述步骤,将这些分类器组合起来,会有 很好的分类效果。
4不确定性数据分类算法在各领域的研究上述分类算法在各领域经过了实验验证与应 用。