(完整版)8086汇编语言速成秘籍
- 格式:docx
- 大小:43.22 KB
- 文档页数:13


8086/8088指令系统记忆表数据寄存器分为:AH&AL=AX(accumulator):累加寄存器,常用于运算;在乘除等指令中指定用来存放操作数,另外,所有的I/O指令都使用这一寄存器与外界设备传送数据.BH&BL=BX(base):基址寄存器,常用于地址索引;CH&CL=CX(count):计数寄存器,常用于计数;常用于保存计算值,如在移位指令,循环(loop)和串处理指令中用作隐含的计数器.DH&DL=DX(data):数据寄存器,常用于数据传递。
他们的特点是,这4个16位的寄存器可以分为高8位: AH, BH, CH, DH.以及低八位:AL,BL,CL,DL。
这2组8位寄存器可以分别寻址,并单独使用。
另一组是指针寄存器和变址寄存器,包括:SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置;BP(Base Pointer):基址指针寄存器,可用作SS的一个相对基址位置;SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针;DI(Destination Index):目的变址寄存器,可用来存放相对于ES 段之目的变址指针。
指令指针IP(Instruction Pointer)标志寄存器FR(Flag Register)OF(overflow flag)DF(direction flag)CF(carrier flag)PF(parity flag)AF(auxiliary flag)ZF(zero flag)SF(sign flag)IF(interrupt flag)TF(trap flag)段寄存器(Segment Register)为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。



“哎哟,哥们儿,还捣鼓汇编呢?那东西没用,兄弟用VB"钓"一个API就够你忙活个十天半月的,还不一定搞出来。
”此君之言倒也不虚,那吾等还有无必要研他一究呢?(废话,当然有啦!要不然你写这篇文章干嘛。
)别急,别急,让我把这个中原委慢慢道来:一、所有电脑语言写出的程序运行时在内存中都以机器码方式存储,机器码可以被比较准确的翻译成汇编语言,这是因为汇编语言兼容性最好,故几乎所有跟踪、调试工具(包括WIN95/98下)都是以汇编示人的,如果阁下对CRACK颇感兴趣……;二、汇编直接与硬件打交道,如果你想搞通程序在执行时在电脑中的来龙去脉,也就是搞清电脑每个组成部分究竟在干什么、究竟怎么干?一个真正的硬件发烧友,不懂这些可不行。
三、如今玩DOS的多是“高手”,如能像吾一样混入(我不是高手)“高手”内部,不仅可以从“高手”朋友那儿套些黑客级“机密”,还可以自诩“高手”尽情享受强烈的虚荣感--#$%& “醒醒!”对初学者而言,汇编的许多命令太复杂,往往学习很长时间也写不出一个漂漂亮亮的程序,以致妨碍了我们学习汇编的兴趣,不少人就此放弃。
所以我个人看法学汇编,不一定要写程序,写程序确实不是汇编的强项,大家不妨玩玩DEBUG,有时CRACK出一个小软件比完成一个程序更有成就感(就像学电脑先玩游戏一样)。
某些高深的指令事实上只对有经验的汇编程序员有用,对我们而言,太过高深了。
为了使学习汇编语言有个好的开始,你必须要先排除那些华丽复杂的命令,将注意力集中在最重要的几个指令上(CMP LOOP MOV JNZ……)。
但是想在啰里吧嗦的教科书中完成上述目标,谈何容易,所以本人整理了这篇超浓缩(用WINZIP、WINRAR…依次压迫,嘿嘿!)教程。
大言不惭的说,看通本文,你完全可以“不经意”间在前辈或是后生卖弄一下DEBUG,很有成就感的,试试看!那么――这个接下来呢?――Here we go!(阅读时看不懂不要紧,下文必有分解)因为汇编是通过CPU和内存跟硬件对话的,所以我们不得不先了解一下CPU和内存:(关于数的进制问题在此不提)CPU是可以执行电脑所有算术╱逻辑运算与基本I/O 控制功能的一块芯片。



8086汇编语⾔学习(六)8086处理结构化数据(模拟⾼级语⾔结构体、数组)⼀、8086汇编定义数据 要处理结构化数据,必须先定义数据。
8086汇编作为⼀门编程语⾔,定义数据的⽅式⽐起复杂的⾼级语⾔要简单不少。
汇编语⾔贴近机器底层,所处理的数据逻辑上都可以视为⼆进制数据,按照对不同⼤⼩内存单元的处理,分为三种:db、dw、dd。
1.db db 即define byte,定义⼀个字节变量。
例如 db 1h,代表着db指令后的值占⽤⼀个字节的内存空间 1h=>01h。
特别的,使⽤db可以⽐较简单的定义字符串数据,例如db "ABC",代表着定义A、B、C三个连续的字符。
2.dw db 即define word,定义⼀个字变量。
例如 dw 1h,代表着dw指令后的值占⽤⼀个字/两个字节的内存空间 1h=>0001h。
3.dd dd 即define doubleword,定义⼀个双字变量。
例如 dd 1h,代表着dw指令后的值占⽤两个字/四个字节的内存空间 1h=>0000 0001h。
在连续定义数据时,可以通过逗号进⾏缩写。
例如 db 1h,2h,3h等价与db 1h;db 2h;db 3h。
同时上述三种⽅式都可以与dup关键字(duplicate)使⽤。
例如,定义3个值为1h的字形数据,可以写为dw 3 dup(1h),其等价于dw1h,1h,1h。
在定义复数个相同的数据时,可以简化程序,增强可读性。
db、dw、dd、dup都属于8086汇编的伪指令,由汇编器在编译时进⾏处理,并没有对应的机器指令。
⼆、8086汇编处理结构化数据 之前介绍了8086各种不同⽅式的内存寻址⽅式,下⾯介绍8086如何利⽤这些多样的寻址⽅式来处理结构化的数据。
举⼀个简单的例⼦,假设存在⼀个结构化的数据(公司),拥有五个属性。
公司属性: 公司名称: BLZ 总裁名称: Deckard Cain 公司排名: 15 年收⼊(亿元): 50 产品: WOW 需求是,在内存中定义该数据并且对其中的部分属性进⾏修改,将公司排名修改为10,年收⼊修改为80,产品名称修改为OWO。


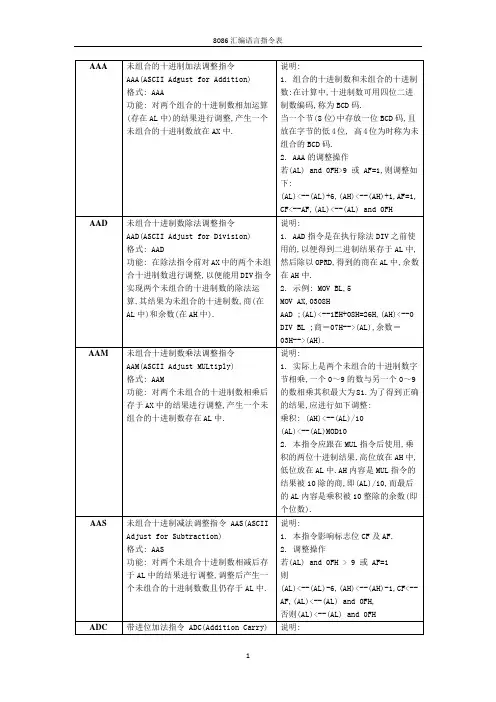
8086汇编指令大全标志寄存器: 9个有效位,分6个状态寄存器和3个控制寄存器CF 当执行一个加法(减法)使最高位产生进位(借位)时CF=1 否则CF=0PF 指令执行的结果低8位有偶数个一时,CF=1 否则CF=0AF 当执行一个加法(减法)使运算结果低4位向高4位有进位(借位)时AF=1 否则 AF+0ZF 当前运算结果为零,ZF=1 否则ZF=0SF 符号标志位OF 溢出标志位DF 方向标志位IF 中断允许位 IF=1时响应外部中断TF 跟踪标志位操作数:[目的操作数(OPD),源操作数(OPS)] ;立即操作数,寄存器操作数,存储器操作数。
寻址方式:1) 寄存器寻址例: INC AX; MOV AX,BX2) 寄存器间接寻址(寄存器只能是BX,DI,SI,BP);[PA=(BX、DI、SI)+DS》4)或BP+SS》4]3) 寄存器相对寻址4) 基址变址寻址5) 相对基址变址寻址6) 直接寻址7) 立即数寻址i. 立即数寻址立即数寻址不能用在单操作数指令中ii. 在双操作数中,立即数寻址方式不能用于目的操作数字段指令系统:1) 数据传送指令 mov注意:不允许在两个存储单元之间直接传送数据不允许在两个段寄存器之间传送数据不允许用立即数直接为段寄存器赋值不影响标志位不允许寄存器或存储单元到除CS外的段寄存器2) 入栈(出栈)指令PUSH(POP)注意:PUSH操作数不能是“立即数”POP操作数不能是段寄存器CS 不影响标志位先进后出单操作符3) 交换指令XCHG注意:只允许寄存器与存储单元之间的交换不影响标志位4) 换码指令 XLAT5) 地址传送指令LEA(load effective address):偏移地址()6) 数据段指针送寄存器LDS :低地址的字送指定的通用寄存器(SI)、高地址的字送DS7) 附加段指针送寄存器指令LES :与LDS相似,低地址的字送通用寄存器(DI)、高地址送ES上三指令不影响标志位8) 标志寄存器传送指令LAHF :标志寄存器低八位送AHSAHF :AH送标志寄存器低八位PUSHF:标志寄存器压入堆栈POPF :栈顶内容送标志寄存器9) 加法指令 ADD目的操作数只能是寄存器或存储单元对CF,OF,SF,PF,ZF,AF有影响10) 加1指令 INC对OF,SF,PF,ZF,AF有影响11) 带位加法指令 ADC在进行单精度运算时用ADD指令,在高精度低位运算时用ADD、高位用ADCOPD=OPD+OPS+CF12) 减法指令 SUB对CF,OF,SF,PF,ZF,AF有影响13) 带借位减法指令 SBBOPD=OPD—OPS—CF对CF,OF,SF,PF,ZF,AF有影响对CF,OF,SF,PF,ZF,AF有影响14) 减1指令 DEC15) 比较指令 CMP16) 求补指令 NEG17) 无符号乘法指令 MUL字节操作:AX=AL*OPS字操作:DX,AX=AX*OPS18) 有符号乘法指令 IMUL19) 无符号除法指令 DIV字节的操作:AL=AX/(OPS)的商AH=AX/(OPS)的余数字的操作:20) 有符号除法 IDIV21) 字节转换为字指令 CBW把AL中的符号位扩展到AH中,如果AL的最高位为0,则AH=00H,如果最高位为1,则AH=FFH22) 字转换为双字指令 CWD23) 压缩的BCD码调整指令DAA 加法的十进制调整指令DAS 减法的十进制调整指令24) 非压缩的BCD码调整指令AAA 加法的ASCII调整指令AAS 减法的ASCII调整指令AAM 乘法的ASCII调整指令AAD 除法的ASCII调整指令25) 逻辑与运算指令ADDORNOTTEST(OPD和OPS的内容不变)26) 移位指令逻辑左移与算术左移SHL、SAL(低位补0)算术右移 SAR(高位不变、CF为最后移入的值)逻辑右移 SHR(高位补0、CF为最后移入的值)27) 循环移位左移 ROL (CF为最后移入的值)右移 ROR (CF为最后移入的值)带进位循环左移 RCL(CF+OPD 一起左循环)带进位循环右移 RCR(OPD+CF 一起右循环)28) 无条件转移指令下JMPJMP SHORT OPD(IP=IP+8位位移量)JMP NEAR PTR OPD(IP=IP+16位位移量)上二条指令目的地址是IP=OPD+IPJMP WORD PTR OPD(IP=EA)JMP FAR PTR OPD(IP=OPD的段内偏移地址 CS=OPD段地址)JMP DWORD PTR OPD(IP=EA CS=EA+2)29) 条件转移指令JZ(JE)结果为0则转移(ZF=1)JNZ(JNE)结果不为0则转移(ZF=0)JS 结果为负则转移(SF=1)JNS 结果为正则转移(SF=0)JO 溢出则转移(OF=1)JNO 不溢出则转移(OF=0)JP(JPE)奇偶位为1则转移(PF=1)JNP(JPO)奇偶位不为1则转移(PF=0)JC(JNAE,JB)低于且不等于或进位位为1则转移(CF=1)JNC(JNE,JNB)高于或等于或进位位为0则转移(CF=0)30)。
8086汇编语⾔学习(⼀)8086汇编介绍1. 学习汇编的⼼路历程 进⾏8086汇编的介绍之前,想先分享⼀下我学习汇编的⼼路历程。
rocketmq的学习 其实我并没有想到这么快的就需要进⼀步学习汇编语⾔,因为汇编对于我的当前的⼯作内容来说太过底层。
但在⼏个⽉前,当时我正尝试着阅读rocketmq的源码。
和许多流⾏的java中间件、框架⼀样,rocketmq底层的⽹络通信也是通过netty实现的。
但由于我对netty并不熟悉,在⼯作中使⽤spring-cloud-gateway的时候甚⾄写出了⼀些导致netty内存泄漏的代码,却不太明⽩个中原理。
出于我个⼈的习惯,在学习源码时,抛开整体的程序架构不论,希望⾄少能对其中涉及到的底层内容有⼀个⼤致的掌握,能让我像⿊盒⼦⼀样去看待它们。
趁热打铁,我决定先学习netty,这样既能在⼯作时更好的定位、解决netty相关的问题,⼜能在研究依赖netty的开源项⽬时更加得⼼应⼿。
netty的学习 随着对netty学习的深⼊,除了感叹netty统⼀规整的api接⼝设计,内部交互灵活可配置、同时⼜提供了⾜够丰富的开箱即⽤组件外;更进⼀步的,netty或者说java nio涉及到了许多更底层的东西,例如:io多路复⽤,零拷贝,事件驱动等等。
⽽这些底层技术在redis,nginx,node-js等以⾼效率io著称的应⽤中被⼴泛使⽤。
扪⼼⾃问,⾃⼰在多⼤程度上理解这些技术?为什么io多路复⽤在io密集型的应⽤中,效率能够⽐之传统的同步阻塞io显著提⾼?⼀次⽹络或磁盘的io传输内部到底发⽣了什么,零拷贝到底快在了哪⾥? 如果没有很好的弄明⽩这些问题,那么我的netty学习将是不完整的。
我有限的知识告诉我,答案就在操作系统中。
操作系统作为软硬件的⼤管家,对上提供应⽤程序接⼝(程序员们通常使⽤⾼级语⾔提供的api间接调⽤);对下控制硬件(cpu、内存、磁盘⽹卡等外设);依赖硬件提供控制并发的系统原语;其牵涉的许多模块内容都已经独⽴发展了(多系统进程间通信->计算机⽹络、⽂件系统->数据库)。
8086汇编语⾔学习(四)8086汇编程序的编译与链接1、8086汇编源程序从编写到执⾏的过程 前⾯介绍过通过debug模式来进⾏汇编程序的编写和调试。
但是随着深⼊学习,所编写的汇编程序会越来越复杂,⽽通过debug的A命令去逐条编写汇编指令是⾮常低效的。
因此,这⾥将要介绍8086汇编源程序这⼀概念,使得我们可以通过⽂本的⽅式编写汇编程序,并通过⼀系列的措施将其转化为最终的⼆进制可执⾏程序。
⼀个汇编源程序从编写到执⾏⼤概可以分为⼏个阶段: 1. 开发者编写⽂本形式的汇编源程序 2. 对汇编源程序进⾏编译并⽣成⽬标⽂件、对⽬标⽂件进⾏链接并⽣成可执⾏⽂件 3. 运⾏可执⾏⽂件下⾯通过⼀个简单例⼦来详细说明(以windows操作系统下的masm5环境举例):1. 编写汇编源程序 通过系统⾃带的记事本或者更⾼级的⽂本编辑器编写⽂本形式的汇编源程序,将其命名为demo.asm,程序内容如下:assume cs:codesgcodesg segmentmov ax,0123Hmov bx,0456Hadd ax,bxadd ax,axmov ax,4c00Hint 21H ;中断退出程序codesg endsend2. 对汇编源程序进⾏编译、链接编译: 通过命令⾏运⾏masm.exe,先让⽤户输⼊需要编译的汇编源⽂件的本地⽂件地址(Source filename :)。
如果⽂件在当前⼯作路径下可以仅输⼊⽂件名(例如 demo.asm),否则就需要输⼊绝对地址路径(例如 c:\MASM\ASM\demo.asm)。
另外,如果源程序⽂件的默认后缀拓展名为[.ASM],如果是.txt之类的⽂件,则需要输⼊全名(例如 c:\MASM\ASM\demo.txt)。
接着会让⽤户输⼊所⽣成的.obj⽬标⽂件的存放路径以及名称(Object filename :),例如 c:\MASM\ASM\demo.obj。
后⾯的Source listing和Cross-reference能够让masm编译器⽣成编译过程中的中间结果⽂件,这⾥可以直接回车跳过,不去让编译器⽣成。
8086汇编语⾔学习(⼆)8086汇编开发环境搭建和Debug模式介绍1. 8086汇编开发环境搭建 在上篇博客中简单的介绍了8086汇编语⾔。
⼯欲善其事,必先利其器,在8086汇编语⾔正式开始学习之前,先介绍⼀下如何搭建8086汇编的开发环境。
汇编语⾔设计之初是⽤于在没有操作系统的裸机上直接操作硬件的,但对于⼤部分⼈来说,在8086裸机上直接进⾏编程将会⾯临各种困难。
好在我们可以使⽤软件模拟器来模拟硬件进⾏8086的学习实践。
在《汇编语⾔》中作者推荐通过windows环境下的masm和debug进⾏学习。
masm介绍: masm是⼀款DOS下的汇编⼯具包,在8086汇编的学习中我们需要其中的⼏个⽂件,分别是masm.exe,link.exe。
masm.exe 汇编器,⽤于将⽂本格式的汇编语⾔源⽂件编译为.obj结尾的⼆进制⽂件,其⽣成的.obj结尾的⼆进制⽬标⽂件是被编译的源⽂件的对应的机器码。
单独的源程序⽬标⽂件通常是⽆法直接运⾏的,还需要和互相依赖的其它同样编译完成的⼆进制⽂件链接在⼀起才能⽣成最终的可执⾏⽂件(⽐如所需要的静态库函数) 。
因此,obj⽂件通常也被叫做中间⽂件。
link.exe 链接器,obj⽂件需要通过链接才能转换成可执⾏程序,⽽链接器就是负责完成这⼀任务的。
链接器能将多个obj⽬标⽂件以及其所依赖的库程序进⾏统⼀处理(例如多个⽬标⽂件中指令、数据内存地址的偏移处理),并⽣成可执⾏⽂件。
debug介绍: debug.exe 调试器,windows提供了⼀个在dos中调试8086汇编程序的⼯具debug.exe,提供了展⽰程序运⾏时CPU中各寄存器、内存中数据,指令级的单步调试等功能。
debug程序的使⽤会在本篇博客的后半段进⾏详细介绍。
64位操作系统兼容性问题: 由于《汇编语⾔》⼀书出版较早,当时的windows系统还是32位的,32位windows系统都默认安装了masm与debug,能打开dos窗⼝直接使⽤。
8086汇编指令汇总一、基本指令集1.MOV:用于将一个值从一个位置复制到另一个位置。
2.ADD:将两个操作数相加,并将结果存储在第一个操作数中。
3.SUB:将第二个操作数从第一个操作数中减去,并将结果存储在第一个操作数中。
4.INC:将指定的寄存器或内存位置的值加一5.DEC:将指定的寄存器或内存位置的值减一6.MUL:将两个操作数相乘,并将结果存储在累积寄存器中。
7.DIV:将累积寄存器的值除以指定的操作数,并将商存储在累积寄存器中,余数存储在另一个寄存器中。
二、数据传送指令1.MOVSB:从指定内存位置复制一个字节到另一个位置。
2.MOVSW:从指定内存位置复制一个字到另一个位置。
3.MOVSBW:从指定内存位置复制一个字节到另一个位置,并将其扩展为字。
4.LODSB:从指定内存位置加载一个字节到累积寄存器中。
5.LODSW:从指定内存位置加载一个字到累积寄存器中。
6.STOSB:将累积寄存器中的值存储到指定内存位置。
7.STOSW:将累积寄存器中的值存储到指定内存位置。
8.XCHG:交换两个操作数的值。
三、算术与逻辑指令1.AND:对两个操作数执行逻辑与操作,并将结果存储在第一个操作数中。
2.OR:对两个操作数执行逻辑或操作,并将结果存储在第一个操作数中。
3.XOR:对两个操作数执行逻辑异或操作,并将结果存储在第一个操作数中。
4.NOT:对指定的操作数执行逻辑非操作。
5.SHR:将指定操作数的位向右移动指定的位数。
6.SHL:将指定操作数的位向左移动指定的位数。
7.CMP:比较两个操作数的值,并设置相应的条件码。
四、控制转移指令五、字符串操作指令1.REP/REPE/REPZ:用于重复执行一些指令,并且在条件满足时继续执行,直到满足特定的条件。
2.MOVSB/MOVSW:从一个内存位置复制一个字节或字到另一个位置。
3.CMPSB/CMPSW:将两个内存位置的值进行比较。
4.SCASB/SCASW:在累积寄存器中查找指定的字节或字,并设置相应的条件码。
8086汇编语⾔学习(七)8086跳转指令8086跳转指令 ⽬前为⽌,我们的程序的指令执⾏都是线性的,从上到下,由CPU⾃动的增加IP的值,顺序的执⾏指令。
但对于复杂的需求,只有线性的指令执⾏⽅式是远远不够的。
对于⾼级语⾔,有着如if/else的逻辑跳转分⽀,如for/while的循环结构,还有函数⼦程序的调⽤与返回等等。
正是有了这些能够控制程序执⾏指令的不同⽅式,才能具有⾜够的表达能⼒,满⾜⾜够复杂的需求,成为⼀门图灵完备的语⾔。
那么上述的逻辑跳转、循环,在基于图灵机的CPU硬件上是如何实现的呢?通过8086汇编的跳转指令的学习,我们得以⼀窥究竟。
CPU是通过CS:IP来获取下⼀条指令的值,那么通过指令修改CS、IP这两个寄存器的值,便可以控制CPU所执⾏的指令了。
可由于控制CPU执⾏指令的CS、IP⼗分的关键,因此8086并不允许像其它普通的寄存器⼀般使⽤mov等指令对CS、IP修改(mov IP,1000H是⾮法的),⽽是提供了专门的指令来控制CS、IP的值,这⼀类指令被称为8086跳转指令。
跳转指令按照类型可以分为五种:⽆条件跳转指令、有条件跳转指令、循环指令、过程调⽤与返回指令以及中断指令。
⽆条件跳转指令(jmp) jmp既可以只修改IP,也可以同时修改CS和IP。
作为跳转指令,在编程时需要指定跳转的位置,进⽽修改CS/IP的值。
段内转移 段内短转移(IP 变化-128~127):段内短转移的格式为 jmp short [标号]。
assume cs:codesgcodesg segmentstart:mov ax,0jmp short sadd ax,1s:inc axcodesg endsend start 段内近转移(IP 变化-32768~32767):当所要跳转的间隔⼤于短转移的时候,就需要使⽤段内近转移。
段内近转移和短转移类似,格式为 jmp near ptr [标号]。