聚类分析实例
- 格式:doc
- 大小:277.00 KB
- 文档页数:9
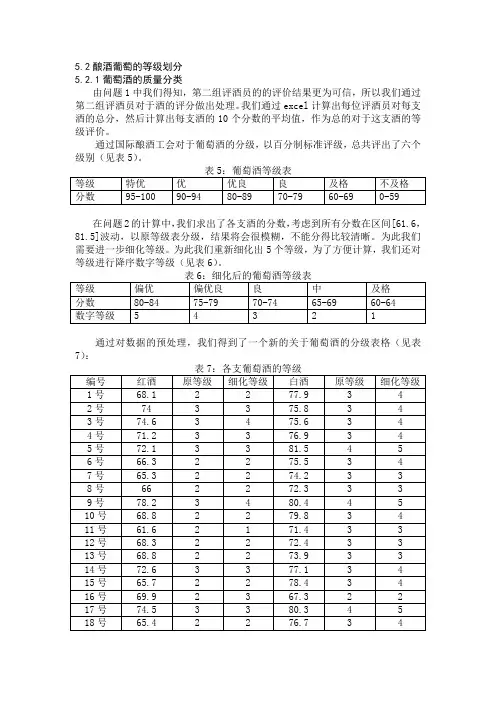
5.2酿酒葡萄的等级划分5.2.1葡萄酒的质量分类由问题1中我们得知,第二组评酒员的的评价结果更为可信,所以我们通过第二组评酒员对于酒的评分做出处理。
我们通过excel计算出每位评酒员对每支酒的总分,然后计算出每支酒的10个分数的平均值,作为总的对于这支酒的等级评价。
通过国际酿酒工会对于葡萄酒的分级,以百分制标准评级,总共评出了六个级别(见表5)。
在问题2的计算中,我们求出了各支酒的分数,考虑到所有分数在区间[61.6,81.5]波动,以原等级表分级,结果将会很模糊,不能分得比较清晰。
为此我们需要进一步细化等级。
为此我们重新细化出5个等级,为了方便计算,我们还对等级进行降序数字等级(见表6)。
通过对数据的预处理,我们得到了一个新的关于葡萄酒的分级表格(见表7):考虑到葡萄酒的质量与酿酒葡萄间有比较之间的关系,我们将保留葡萄酒质量对于酿酒葡萄的影响,先单纯从酿酒葡萄的理化指标对酿酒葡萄进行分类,然后在通过葡萄酒质量对酿酒葡萄质量的优劣进一步进行划分。
5.2.2建立模型在通过酿酒葡萄的理化指标对酿酒葡萄分类的过程,我们用到了聚类分析方法中的ward 最小方差法,又叫做离差平方和法。
聚类分析是研究分类问题的一种多元统计方法。
所谓类,通俗地说,就是指相似元素的集合。
为了将样品进行分类,就需要研究样品之间关系。
这里的最小方差法的基本思想就是将一个样品看作P 维空间的一个点,并在空间的定义距离,距离较近的点归为一类;距离较远的点归为不同的类。
面对现在的问题,我们不知道元素的分类,连要分成几类都不知道。
现在我们将用SAS 系统里面的stepdisc 和cluster 过程完成判别分析和聚类分析,最终确定元素对象的分类问题。
建立数据阵,具体数学表示为:1111...............m n nm X X X X X ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦(5.2.1) 式中,行向量1(,...,)i i im X x x =表示第i 个样品;列向量1(,...,)'j j nj X x x =’,表示第j 项指标。

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以帮助我们对数据进行分类和分组,发现数据中的潜在模式和规律。
在现实生活和工作中,聚类分析有着广泛的应用,下面我们将介绍几个聚类分析的应用案例。
首先,聚类分析在市场营销领域有着重要的应用。
在市场营销中,我们常常需要对顾客进行分类,以便针对不同类别的顾客制定不同的营销策略。
通过聚类分析,我们可以根据顾客的消费行为、偏好等特征将顾客进行分类,从而更好地理解顾客群体的特点,并针对性地开展营销活动,提高营销效果。
其次,聚类分析在医学领域也有着重要的应用。
在医学研究中,我们常常需要对疾病患者进行分类,以便更好地了解不同类型患者的病情特点和治疗效果。
通过聚类分析,我们可以根据患者的临床表现、病情指标等特征将患者进行分类,从而更好地指导临床诊断和治疗方案的制定,提高治疗效果和患者生存率。
此外,聚类分析还在推荐系统中有着重要的应用。
在电子商务平台和社交媒体平台上,推荐系统可以根据用户的行为和偏好向其推荐商品、信息等内容。
而聚类分析可以帮助推荐系统对用户进行分类,从而更好地理解用户的兴趣和偏好,提高推荐的准确性和个性化程度,增强用户体验。
最后,聚类分析还在金融领域有着重要的应用。
在金融风控和信用评估中,我们常常需要对客户进行分类,以便更好地评估客户的信用风险和制定个性化的信贷方案。
通过聚类分析,我们可以根据客户的财务状况、信用记录等特征将客户进行分类,从而更好地了解客户的信用状况,提高风险控制的精准度和效果。
总之,聚类分析在各个领域都有着重要的应用,它可以帮助我们更好地理解数据和问题的本质,发现数据中的潜在规律和价值信息,为决策提供科学依据。
随着数据科学和人工智能技术的不断发展,相信聚类分析的应用领域会越来越广泛,对我们的生活和工作产生越来越大的影响。

聚类分析案例范文聚类分析是一种无监督机器学习算法,它通过将数据集中的观测值分成不同的组或簇来发现数据之间的内在结构和相似性。
这种方法可以帮助我们理解数据集,发现隐藏的模式和关联性,并且可以应用于各种领域,包括市场细分、社交网络分析、生物信息学和图像处理等。
以下是一个关于使用聚类分析方法的案例研究,该案例介绍了如何使用聚类分析来帮助一家电商企业在众多商品中挖掘潜在的市场细分。
背景介绍:电商企业销售了大量商品,这些商品拥有不同的特征和属性。
该企业希望利用这些数据来了解他们的客户,并为不同的产品类型制定个性化的推广和营销策略。
为了实现这一目标,他们决定使用聚类分析方法来将客户细分成不同的群组,并理解他们的相似性和差异性。
数据收集:该企业从其销售系统中收集了一份包含多个属性的数据集。
这些属性包括:年龄、性别、购买历史、购买频率、平均订单金额等。
这些属性可以反映客户的购买行为和偏好。
数据预处理:在进行聚类分析之前,需要对数据进行预处理。
这包括对缺失值进行处理、进行数值归一化等。
然后,根据业务需求,选择适当的聚类算法和合适的距离度量方法。
聚类分析过程:在本案例中,采用了一种常见的聚类方法--K均值聚类算法,该算法通过计算数据点之间的欧氏距离来度量它们之间的相似度。
首先,选择合适的K值(聚类簇的个数)。
然后,在初始阶段,随机选择K个点作为聚类中心。
再通过计算每个数据点与聚类中心的距离,并将其归类到最近的聚类簇。
接下来,根据已经分配到每个聚类中的数据点,重新计算新的聚类中心。
这个过程将迭代,直到达到停止准则,如聚类中心不再变化或达到最大迭代次数。
聚类结果分析:在完成聚类过程后,可以根据每个聚类中心的特征和属性,对数据集进行可视化和解释。
这将帮助企业理解各个群组的特征和差异,并从中提取有价值的洞察力。
进而,企业可以根据不同群组的特征制定个性化的营销策略,提高销售和客户满意度。
总结:通过使用聚类分析方法,该电商企业成功地将其客户细分为几个不同的群组。

聚类分析案例聚类分析是一种常见的数据分析方法,它能够将数据集中的观测值划分为若干个类别,使得同一类别内的观测值相似度较高,不同类别之间的观测值相似度较低。
聚类分析在市场细分、社交网络分析、医学图像分析等领域都有着广泛的应用。
本文将以一个实际的案例来介绍聚类分析的应用过程。
案例背景:某电商平台希望对其用户进行细分,以便更好地了解用户需求,精准推荐商品。
为此,他们收集了用户的浏览、购买、评价等行为数据,希望通过聚类分析将用户分成不同的群体。
数据准备:首先,我们需要对数据进行清洗和整理。
去除缺失值、异常值,对数据进行标准化处理,以便消除不同维度之间的量纲影响。
然后,我们可以利用主成分分析(PCA)等方法对数据进行降维,以便更好地展现数据的内在结构。
模型选择:在数据准备完成后,我们需要选择合适的聚类算法。
常见的聚类算法包括K均值聚类、层次聚类、密度聚类等。
在本案例中,我们选择了K均值聚类算法,因为该算法简单易实现,并且适用于大规模数据。
聚类分析:经过数据准备和模型选择后,我们开始进行聚类分析。
首先,我们需要确定聚类的数量K。
这里我们可以采用肘部法则、轮廓系数等方法来确定最佳的K值。
然后,我们利用K均值聚类算法对数据进行分组,得到每个用户所属的类别。
结果解释:得到聚类结果后,我们需要对每个类别进行解释和分析。
通过对每个类别的特征进行比较,我们可以揭示出不同类别用户的行为特点和偏好。
比如,某一类用户可能更倾向于购买高价值商品,而另一类用户更注重商品的品质和口碑。
应用建议:最后,我们可以根据聚类结果给出相应的应用建议。
比如,对于高价值用户群体,电商平台可以加大对其的推荐力度,提供更多的个性化服务;对于偏好品质和口碑的用户群体,可以加强品牌营销和口碑传播,以吸引更多类似用户。
总结:通过本案例的介绍,我们可以看到聚类分析在用户细分和个性化推荐方面的重要作用。
通过对用户行为数据的聚类分析,电商平台可以更好地了解用户需求,提供更精准的推荐服务,从而提升用户满意度和交易量。


聚类分析应用案例
简介
聚类分析是一种无监督研究方法,旨在将数据样本划分为具有相似特征的群组或类别。
在许多领域中,聚类分析被广泛应用于数据分析、模式识别和信息检索等任务。
本文将介绍聚类分析在实际应用中的一些案例。
零售行业中的市场细分
零售行业需要了解其客户群体的特征以制定有效的营销策略。
通过聚类分析,可以将顾客细分为不同的群组,例如消费惯相似的群体、购买力相近的群体等。
基于这些细分结果,零售商可以有针对性地开展宣传活动、提供个性化服务,从而提高市场竞争力。
医疗领域中的疾病分类
在医疗领域,聚类分析可以用于疾病分类和诊断。
通过对患者的症状、体征和病史等信息进行聚类,可以将患者群体划分为具有相似疾病特征的子群。
这有助于医生进行更精确的诊断和制定个性化的治疗方案。
社交媒体分析中的用户群体划分
在社交媒体分析中,聚类分析可用于划分用户群体,了解不同用户的兴趣、行为模式和需求。
以这些群体为基础,企业可以更好地理解目标用户,并设计出更精准的推广活动和产品策略。
金融领域中的风险管理
在金融领域,聚类分析可以用于风险管理。
通过对客户的财务信息、投资偏好和风险承受能力等进行聚类,可以将客户划分为不同的风险群体。
这可以帮助金融机构识别高风险客户,并采取相应的风险控制措施。
总结
聚类分析是一种强大而灵活的数据分析工具,在各个领域都有广泛的应用。
本文介绍了其在零售行业、医疗领域、社交媒体分析和金融领域中的应用案例。
聚类分析可以帮助我们理解数据的内在结构、找到相似的群体,并基于这些群体进行个性化的决策和策略制定。

聚类分析的应用案例聚类分析是一种常用的数据分析方法,它可以将数据集中的对象分成不同的类别或簇,使得同一类内的对象相似度较高,而不同类别之间的对象相似度较低。
聚类分析广泛应用于市场分析、社交网络分析、生物信息学、医学诊断等领域。
本文将介绍几个聚类分析的应用案例,以便更好地理解聚类分析在实际问题中的应用。
首先,聚类分析在市场分析中的应用。
在市场营销中,企业需要了解消费者的偏好和行为,以便更好地制定营销策略。
通过对消费者数据进行聚类分析,可以将消费者分成不同的群体,从而更好地理解他们的需求和行为模式。
例如,一家零售商可以通过聚类分析将消费者分成价格敏感型、品牌忠诚型、功能导向型等不同的群体,从而有针对性地进行促销活动和产品定位。
其次,聚类分析在社交网络分析中的应用。
随着社交网络的兴起,人们在社交网络上的行为数据变得越来越丰富。
通过对社交网络数据进行聚类分析,可以发现不同的社交群体和用户行为模式。
例如,一家社交网络平台可以通过聚类分析将用户分成信息分享型、社交互动型、内容创作型等不同的群体,从而更好地满足用户需求,提高用户留存和活跃度。
再次,聚类分析在生物信息学中的应用。
生物信息学是研究生物学数据的计算机科学领域,其中大量的生物数据需要进行分析和挖掘。
通过对生物数据进行聚类分析,可以发现不同的基因型、蛋白质结构等生物特征。
例如,通过对癌症患者的基因数据进行聚类分析,可以发现不同的癌症亚型和治疗方案,为临床诊断和治疗提供重要参考。
最后,聚类分析在医学诊断中的应用。
在医学诊断中,医生需要根据患者的症状和检查数据进行疾病诊断。
通过对患者数据进行聚类分析,可以发现不同的疾病类型和临床表现。
例如,通过对心脏病患者的临床数据进行聚类分析,可以发现不同的心脏病亚型和治疗方案,为临床诊断和治疗提供重要参考。
综上所述,聚类分析在市场分析、社交网络分析、生物信息学、医学诊断等领域都有重要的应用价值。
通过对不同领域的应用案例进行分析,可以更好地理解聚类分析的原理和方法,为实际问题的解决提供重要参考。

聚类分析法经典案例
聚类分析是一种常用的数据分析方法,它能够将相似的观察对象分为一组,并将不相似的对象分为不同的组。
下面将介绍一个经典的聚类分析案例。
在电信行业,客户流失是一个非常重要的问题。
为了降低客户流失率,一家电信公司希望通过聚类分析来识别客户流失的特征,以便进行有针对性的营销策略。
首先,该公司收集了一些客户数据,如客户的年龄、性别、月平均消费金额、通话时长等。
然后,利用聚类分析方法,将客户分为不同的组。
在这个案例中,我们可以采用k-means聚类算法。
通过聚类分析,该公司发现了三个客户群体。
第一组客户是高消费高通话客户,他们的平均消费金额和通话时长都很高。
第二组客户是低消费低通话客户,他们的平均消费金额和通话时长都很低。
第三组客户是高消费低通话客户,他们的平均消费金额很高,但通话时长很低。
利用聚类分析的结果,该公司能够采取有针对性的营销策略。
对于高消费高通话客户,他们可能是该公司的忠诚客户,可以通过提供一些优惠或奖励来保持他们的忠诚度。
对于低消费低通话客户,可以通过提供更具吸引力的套餐或增加服务内容来激发他们的消费需求。
对于高消费低通话客户,可以通过了解他们的通话行为,推出更适合他们的通话套餐,以增加他们的通话时长。
通过这个案例,我们可以看到聚类分析在客户流失预测和营销策略中的重要作用。
它可以帮助企业快速识别不同类型的客户,有针对性地制定相应的营销策略,提高客户满意度和忠诚度,降低客户流失率。
聚类分析还可以应用于其他领域,如金融、医疗等,具有广泛的应用前景。

机器学习中的聚类分析应用案例在机器学习领域,聚类分析是一种无监督学习方法,用于发现数据中的隐藏结构和模式。
通过对数据进行分组,聚类分析可以帮助我们理解数据集的内在特性。
在本文中,我们将探讨机器学习中聚类分析的应用案例。
一、电商产品分类在电商行业中,存在大量的产品和商品信息,如何对这些产品进行有效的分类和组织是一个重要的问题。
聚类分析可以帮助我们将相似的产品分组,并为电商平台提供更好的用户体验。
例如,假设我们有大量的电子产品信息,包括手机、笔记本电脑、平板电脑等。
利用聚类分析,我们可以将这些产品根据其特征进行分组,比如处理器型号、内存大小、价格等。
通过这种方式,用户可以更方便地浏览和比较同一类别的产品,并找到最适合自己的商品。
二、社交媒体用户分析社交媒体平台上的用户数量庞大,而且用户间的兴趣和关系错综复杂。
聚类分析可以帮助我们理解不同用户之间的相似性,并为社交媒体平台提供个性化推荐和精准广告投放。
以微博为例,如果我们想要将用户分成不同的兴趣群体,可以使用聚类算法来发现用户之间的相似性。
通过分析用户的发帖内容、点赞和评论等信息,我们可以将用户分成运动爱好者、美食爱好者、电影迷等不同的类别。
这样,我们可以为不同兴趣群体提供个性化的内容推荐和广告投放。
三、医疗诊断在医疗领域,聚类分析可以帮助医生和研究人员对疾病进行分类和诊断。
通过对患者的病历和检查结果进行聚类分析,可以找出不同疾病之间的关联和区别。
举个例子,假设我们有一批乳腺癌患者的病历数据,包括肿瘤大小、淋巴结转移情况、年龄等特征。
通过聚类分析,我们可以将这些患者分成不同的组群,每个组群代表一种不同的乳腺癌类型。
这样,医生可以根据患者所属的组群来进行个性化的治疗和诊断。
四、客户细分在市场营销中,了解客户的需求和偏好对于提供定制化的产品和服务至关重要。
聚类分析可以帮助企业将客户分成不同的细分市场,以更好地满足客户的需求。
以银行业为例,通过对客户的消费行为、借贷记录、资产状况等数据进行聚类分析,可以将客户分成不同的细分市场,例如高净值客户、中产阶级客户、学生群体等。


聚类分析法经典案例聚类分析法是一种常用的数据分析方法,它通过对数据进行分类和分组,帮助我们发现数据中的内在规律和特征。
在实际应用中,聚类分析法被广泛运用于市场营销、社交网络分析、医学诊断、图像处理等领域。
下面,我们将介绍一些聚类分析法的经典案例,帮助大家更好地理解和应用这一方法。
首先,我们来看一个市场营销领域的案例。
某公司想要对其客户进行分类,以便更好地制定营销策略。
他们收集了客户的消费行为、年龄、性别、地理位置等数据,并利用聚类分析法对客户进行了分组。
通过分析,他们发现客户可以被分为三大类,高消费高端用户、中等消费稳定用户和低消费新用户。
有了这些分类信息,公司可以针对不同类型的客户制定不同的营销策略,提高市场营销效率。
其次,我们来看一个社交网络分析的案例。
一家社交媒体公司希望了解用户在平台上的行为和兴趣,以便更好地推荐内容和广告。
他们利用用户的浏览记录、点赞行为、评论信息等数据,通过聚类分析法将用户分为几个群体。
通过分析,他们发现用户可以被分为电影爱好者、音乐迷、美食达人等不同类型的群体。
有了这些分类信息,社交媒体公司可以更精准地为用户推荐内容和广告,提高用户满意度和广告点击率。
再次,我们来看一个医学诊断的案例。
医院收集了患者的临床症状、实验室检查结果、病史等数据,希望通过聚类分析法对患者进行分类,以便更好地制定治疗方案。
通过分析,他们发现患者可以被分为几个病情严重程度不同的群体。
有了这些分类信息,医生可以更好地制定个性化的治疗方案,提高治疗效果和患者生存率。
最后,我们来看一个图像处理的案例。
一家无人驾驶车辆公司希望通过图像识别技术对道路上的车辆和行人进行分类,以便更好地进行交通管理和安全预警。
他们利用摄像头采集的图像数据,通过聚类分析法将道路上的车辆和行人进行分类。
通过分析,他们可以更准确地识别不同类型的车辆和行人,并做出相应的交通管理和安全预警措施。
通过以上经典案例的介绍,我们可以看到聚类分析法在不同领域的广泛应用。
聚类分析实例一、聚类分析例1、为深入了解我国人口的文化程度状况,现利用1990年全国人口普查数据对全国30个省市自治区进行聚类分析。
分析选用了三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ);(2)初中文化程度的人口占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ),分别用来反映较高、中等、较低文化程度人口的状况,原始数据如下表:(%)例2、根据信息基础设施的发展状况,对世界20个国家和地区进行分类。
这里选取了发达国家、新兴工业化国家、拉美国家、亚洲发展中国家、转型国家等不同类型的20个国家作聚类分析。
描述信息基础设施的变量主要的有六个:call——千人拥有电话号码,movecall——每千户居民蜂窝移动电话,fee——高峰时期每三分钟国际电话成本,computer——每千人拥有的计算机数,mips——每千人中计算机功率,net——每千人互联网例3、为了研究1982年全国各地区农民家庭收支的分布规律,根据抽样调查资料进行分类处理,共抽取28个省、市、自治区的样本,每个样本有六个指标,这六个指标反映了平均每人生活消费的支出情况,其原始数据见表3。
例4为了研究世界各国森林、草原资源的分布规律,共抽取了21个国家的数据,每个国家例5 若要从沪市的蒲发银行、齐鲁石化、东北高速、武钢股份、东风汽车等53家上市公司中优选适合开放式基金组合投资的10只股票,我们以总股本和流通股本为分类标志,根据这53家公司的总股本和A股流通股本数据(见表5.3),用聚类分析法将它们分成若干类,再从各类公司中选出比较活跃的股票建立股票池。
表5.3 53家上市公司股本资料单位:十万股例6沪市上市公司2001年末总股本在10000—12000万股、流通股本在3600—5050万股之间共有23家(对于股本结构在其它范围内的上市公司,用雷同的方法,可以建立相应的每股收益预测模型),各公司2000年及2001年有关的财务数据见表。
K-Means聚类分析一、实验方法K-Means聚类分析二、实验目的根据2001年全国31省市自治区各类小康和现代化指数的数据,用Spass对地区进行K-Means 聚类分析。
三、实验数据综合指数社会结构经济与技术发展人口素质生活质量法制与治安北京93.2 100 94.7 108.4 97.4 55.5上海92.3 95.1 92.7 112 95.4 57.5天津87.9 93.4 88.7 98 90 62.7浙江80.9 89.4 85.1 78.5 86.6 58广东79.2 90.4 86.9 65.9 86.5 59.4江苏77.8 82.1 74.8 81.2 75.9 74.6辽宁76.3 85.8 65.7 93.1 68.1 69.6福建72.4 83.4 71.7 67.7 76 60.4山东71.7 70.8 67 75.7 70.2 77.2黑龙江70.1 78.1 55.7 82.1 67.6 71吉林67.9 81.1 51.8 85.8 56.8 68.1湖北65.9 73.5 48.7 79.9 56 79陕西65.9 71.5 48.2 81.9 51.7 85.8河北65 60.1 52.4 75.6 66.4 76.6山西64.1 73.2 41 73 57.3 87.8海南64.1 71.6 46.2 61.8 54.5 100重庆64 69.7 41.9 76.2 63.2 77.9内蒙古63.2 73.5 42.2 78.2 50.2 81.4湖南60.9 60.5 40.3 73.9 56.4 84.4青海59.9 73.8 43.7 63.9 47 80.1四川59.3 60.7 43.5 71.9 50.6 78.5宁夏58.2 73.5 45.9 67.1 46.7 61.6新疆64.7 71.2 57.2 75.1 57.3 64.6安徽56.7 61.3 41.2 63.5 52.5 72.6云南56.7 59.4 49.8 59.8 48.1 72.3甘肃56.6 66 36.6 66.2 45.8 79.4 四、分析方法与结果表一31个省市自治区小康和现代化指数的K-Means聚类分析结果(一)初始聚类中心聚类1 2 3综合指数79.20 92.30 51.10社会结构90.40 95.10 61.90经济与技术发展86.90 92.70 31.50人口素质65.90 112.00 56.00生活质量86.50 95.40 41.00法制与治安59.40 57.50 75.60ANOVA聚类误差均方自由度均方自由度F 显著性综合指数1633.823 2 22.518 28 72.556 .000 社会结构1539.872 2 47.312 28 32.547 .000 经济与技术发展4381.296 2 56.760 28 77.190 .000 人口素质1817.856 2 74.363 28 24.446 .000 生活质量3315.174 2 59.276 28 55.928 .000 法制与治安530.188 2 76.284 28 6.950 .004由于已选择聚类以使不同聚类中个案之间的差异最大化,因此 F 检验只应该用于描述目的。
聚类分析的应用案例聚类分析是一种常用的数据挖掘技术,它可以将数据集中的对象按照其相似性进行分类,从而找出数据中的潜在模式和结构。
聚类分析在各个领域都有着广泛的应用,例如市场营销、医学诊断、社交网络分析等。
本文将介绍几个聚类分析在实际应用中的案例,帮助读者更好地理解和应用这一技术。
首先,聚类分析在市场营销中的应用案例。
假设一个公司希望对其客户进行细分,以便更好地定制营销策略。
通过聚类分析,可以将客户按照其购买行为、偏好等特征进行分类,从而识别出不同的客户群体。
比如,通过聚类分析可以将客户分为价值型客户、潜在客户、忠诚客户等不同的群体,然后针对不同的群体制定相应的营销策略,提高营销效果。
其次,聚类分析在医学诊断中的应用案例也非常广泛。
医学领域的数据往往包含大量的特征和变量,通过聚类分析可以将患者按照其症状、生理指标等特征进行分类,从而辅助医生进行诊断和治疗。
例如,通过聚类分析可以将患者分为不同的疾病类型或病情严重程度,帮助医生更好地制定个性化的治疗方案,提高治疗效果。
另外,聚类分析在社交网络分析中也有着重要的应用价值。
随着社交网络的快速发展,人们在社交网络上产生了大量的数据,通过聚类分析可以将用户按照其兴趣、行为等特征进行分类,从而挖掘出不同的用户群体和社交圈子。
这对于社交网络平台来说,可以帮助他们更好地推荐好友、内容等,提高用户的粘性和使用体验。
综上所述,聚类分析在市场营销、医学诊断、社交网络分析等领域都有着重要的应用价值。
通过聚类分析,可以帮助人们更好地理解和利用数据,发现数据中的潜在模式和结构,为决策提供科学依据。
随着数据挖掘技术的不断发展,相信聚类分析在更多的领域将会有着更广泛的应用。
聚类分析实例讲解Lab 6 聚类分析一、分析背景Chrysler公司为了赢得市场竞争地位,打算推出新产品Viper,该种产品的目标客户是雅皮士阶层。
为了进一步了解这种人群的心理特征,定位自己的产品,吸引目标客户,Chrysler公司举行了一次市场调研。
讨论者使用九点量表测量400名被试者对30项陈述的态度,从而了解这些目标客户的心理特征。
调研还咨询被试者对Dodge Viper型汽车的态度来测量标准变量,标准变量的测量通过九点量表来测试消费者对“我情愿购买Chrysler公司生产的Dodge Viper型汽车”的态度。
本次分析的目的是:通过聚类分析,将原始变量分离聚成三类和四类,比较两种办法的效果。
同时,比较使用原始变量得到的聚类结果和使用因子得分得到的聚类结果,看哪一种办法能更好地解释数据。
二、分析结果1、按照原始变量举行的聚类分析首先按照原始变量举行聚类分析,因为样本数较大,采纳迭代聚类法,分离将样本聚为三类和四类,下面是聚类分析的结果比较。
表1 聚为三类后的组重心表2 聚为四类后的组重心表3 聚为三类的每组样本数表聚为四类的每组样本数表5 聚为三类后组重心之间的距离表6 聚为四类后组重心之间的距离由方差分析的结果(结果略)可知,在聚为三类和四类的分析中,V8,V9,V18,V19,V20和V27的组间差异均大于0.05,结果不显著。
2、按照因子得分举行的聚类分析以下是按照因子得分,采纳迭代法将样本聚为三类和四类的结果:表7 聚为三类后的组重心-.45298 .16364 .29950 .36038 -.22794 -.15239 .28739-.32881 .00765 .25444 .70915 -.87203 .52946 -.29355-.26021 .18363 .11953 -.28471 .00228 .20936 -.18616 .56772-.64844.01414消费因子时尚因子社会因子爱国因子期望因子偏好因子共性因子家庭因子12 3 Cluster表8 聚为三类时的样本数137.000 123.000 140.000400.000 .0001 2 3ClusterValidMissing以下是按照因子得分聚为四类的结果:从以上用因子得分的结果可以看出,聚为三类和四类时八个因子的组间差异都很显著。
聚类分析例子Word版案例数据源:有20种12盎司啤酒成分和价格的数据,变量包括啤酒名称、热量、钠含量、酒精含量、价格。
【一】问题一:选择那些变量进行聚类?——采用“R型聚类”1、现在我们有4个变量用来对啤酒分类2、先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,将来的相似性矩阵里的数字为相关系数。
若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
3、只输出“树状图”就可以了,从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。
至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。
(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。
)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
【二】问题二:20中啤酒能分为几类?——采用“Q型聚类”1、现在开始对20中啤酒进行聚类。
开始不确定应该分为几类,暂时用一个3-5类范围来试探,这一回用欧式距离平方进行测度。
2、主要通过树状图和冰柱图来理解类别。
最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。
我这里试着确定分为4类。
选择“保存”,则在数据区域内会自动生成聚类结果。
【三】问题三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”1、聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
2、这个过程一般用单因素方差分析来判断。
注意此时,因子变量选择聚为4类的结果,而将三个聚类变量作为因变量处理。
方差分析结果显示,三个聚类变量sig值均极显著,我们用于分类的3个变量对分类有作用,可以使用,作为聚类变量是比较合理的。
案例--聚类分析案场各岗位服务流程销售大厅服务岗:1、销售大厅服务岗岗位职责:1)为来访客户提供全程的休息区域及饮品;2)保持销售区域台面整洁;3)及时补足销售大厅物资,如糖果或杂志等;4)收集客户意见、建议及现场问题点;2、销售大厅服务岗工作及服务流程阶段工作及服务流程班前阶段1)自检仪容仪表以饱满的精神面貌进入工作区域2)检查使用工具及销售大厅物资情况,异常情况及时登记并报告上级。
班中工作程序服务流程行为规范迎接指引递阅资料上饮品(糕点)添加茶水工作要求1)眼神关注客人,当客人距3米距离时,应主动跨出自己的位置迎宾,然后侯客迎询问客户送客户注意事项15度鞠躬微笑问候:“您好!欢迎光临!”2)在客人前方1-2米距离领位,指引请客人向休息区,在客人入座后问客人对座位是否满意:“您好!请问坐这儿可以吗?”得到同意后为客人拉椅入座“好的,请入座!”3)若客人无置业顾问陪同,可询问:请问您有专属的置业顾问吗?,为客人取阅项目资料,并礼貌的告知请客人稍等,置业顾问会很快过来介绍,同时请置业顾问关注该客人;4)问候的起始语应为“先生-小姐-女士早上好,这里是XX销售中心,这边请”5)问候时间段为8:30-11:30 早上好11:30-14:30 中午好 14:30-18:00下午好6)关注客人物品,如物品较多,则主动询问是否需要帮助(如拾到物品须两名人员在场方能打开,提示客人注意贵重物品);7)在满座位的情况下,须先向客人致歉,在请其到沙盘区进行观摩稍作等待;阶段工作及服务流程班中工作程序工作要求注意事项饮料(糕点服务)1)在所有饮料(糕点)服务中必须使用托盘;2)所有饮料服务均已“对不起,打扰一下,请问您需要什么饮品”为起始;3)服务方向:从客人的右面服务;4)当客人的饮料杯中只剩三分之一时,必须询问客人是否需要再添一杯,在二次服务中特别注意瓶口绝对不可以与客人使用的杯子接触;5)在客人再次需要饮料时必须更换杯子;下班程序1)检查使用的工具及销售案场物资情况,异常情况及时记录并报告上级领导;2)填写物资领用申请表并整理客户意见;3)参加班后总结会;4)积极配合销售人员的接待工作,如果下班时间已经到,必须待客人离开后下班;1.3.3.3吧台服务岗1.3.3.3.1吧台服务岗岗位职责1)为来访的客人提供全程的休息及饮品服务;2)保持吧台区域的整洁;3)饮品使用的器皿必须消毒;4)及时补充吧台物资;5)收集客户意见、建议及问题点;1.3.3.3.2吧台服务岗工作及流程阶段工作及服务流程班前阶段1)自检仪容仪表以饱满的精神面貌进入工作区域2)检查使用工具及销售大厅物资情况,异常情况及时登记并报告上级。
k-means聚类”——数据分析、数据挖掘
一、概要
分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应。
但就是很多时候上述条件得不到满足,尤其就是在处理海量数据的时候,如果通过预处理使得数据满足分类算法的要求,则代价非常大,这时候可以考虑使用聚类算法。
聚类属于无监督学习,相比于分类,聚类不依赖预定义的类与类标号的训练实例。
本文介绍一种常见的聚类算法——k 均值与k 中心点聚类,最后会举一个实例:应用聚类方法试图解决一个在体育界大家颇具争议的问题——中国男足近几年在亚洲到底处于几流水平。
二、聚类问题
所谓聚类问题,就就是给定一个元素集合D,其中每个元素具有n 个可观察属性,使用某种算法将D 划分成k 个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。
其中每个子集叫做一个簇。
与分类不同,分类就是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类就是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,就是无监督学习的一种。
目前聚类广泛应用于统计学、生物学、数据库技术与市场营销等领域,相应的算法也非常的多。
本文仅介绍一种最简单的聚类算法——k 均值(k-means)算法。
三、概念介绍
区分两个概念:
hard clustering:一个文档要么属于类w,要么不属于类w,即文档对确定的类w就是二值的1或0。
soft clustering:一个文档可以属于类w1,同时也可以属于w2,而且文档属于一个类的值不就是0或1,可以就是0、3这样的小数。
K-Means就就是一种hard clustering,所谓K-means里的K就就是我们要事先指定分类的个数,即K个。
k-means算法的流程如下:
1)从N个文档随机选取K个文档作为初始质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至满足既定的条件,算法结束
在K-means算法里所有的文档都必须向量化,n个文档的质心可以认为就是这n 个向量的中心,计算方法如下:
这里加入一个方差RSS的概念:
RSSk的值就是类k中每个文档到质心的距离,RSS就是所有k个类的RSS值的与。
算法结束条件:
1)给定一个迭代次数,达到这个次数就停止,这好像不就是一个好建议。
2)k个质心应该达到收敛,即第n次计算出的n个质心在第n+1次迭代时候位置不变。
3)n个文档达到收敛,即第n次计算出的n个文档分类与在第n+1次迭代时候文档分类结果相同。
4)RSS值小于一个阀值,实际中往往把这个条件结合条件1使用
回过头用RSS讨论质心的计算方法就是否合理
为了取得RSS的极小值,RSS对质心求偏导数应该为0,所以得到质心
可见,这个质心的选择就是合乎数学原理的。
K-means方法的缺点就是聚类结果依赖于初始选择的几个质点位置,瞧下面这个例子:
如果使用2-means方法,初始选择d2与d5那么得到的聚类结果就就是
{d1,d2,d3}{d4,d5,d6},这不就是一个合理的聚类结果
解决这种初始种子问题的方案:
1)去处一些游离在外层的文档后再选择
2)多选一些种子,取结果好的(RSS小)的K个类继续算法
3)用层次聚类的方法选择种子。
我认为这不就是一个合适的方法,因为对初始N 个文档进行层次聚类代价非常高。
以上的讨论都就是基于K就是已知的,但就是我们怎么能从随机的文档集合中选择这个k值呢?
我们可以对k去1~N分别执行k-means,得到RSS关于K的函数下图:
当RSS由显著下降到不就是那么显著下降的K值就可以作为最终的K,如图可以选择4或9。
四、算法及示例
k 均值算法的计算过程非常直观:
1、从D 中随机取k 个元素,作为k 个簇的各自的中心。
2、分别计算剩下的元素到k 个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
3、根据聚类结果,重新计算k 个簇各自的中心,计算方法就是取簇中所有元素各自维度的算术平均数。
4、将D 中全部元素按照新的中心重新聚类。
5、重复第4 步,直到聚类结果不再变化。
6、将结果输出。
由于算法比较直观,没有什么可以过多讲解的。
下面,我们来瞧瞧k-means 算法一个有趣的应用示例:中国男足近几年到底在亚洲处于几流水平?
今年中国男足可算就是杯具到家了,几乎到了过街老鼠人人喊打的地步。
对于目前中国男足在亚洲的地位,各方也就是各执一词,有人说中国男足亚洲二流,有人说三流,还有人说根本不入流,更有人说其实不比日韩差多少,就是亚洲一流。
既然争论不能解决问题,我们就让数据告诉我们结果吧。
下图就是采集的亚洲15 只球队在2005 年-2010 年间大型杯赛的战绩(由于澳大利亚就是后来加入亚足联的,所以这里没有收录)。
其中包括两次世界杯与一次亚洲杯。
我提前对数据做了如下预处理:对于世界杯,进入决赛圈则取其最终排名,没有进入决赛圈的,打入预选赛十强赛赋予40,预选赛小组未出线的赋予50。
对于亚洲杯,前四名取其排名,八强赋予5,十六强赋予9,预选赛没出现的赋予17。
这样做就是为了使得所有数据变为标量,便于后续聚类。
下面先对数据进行[0,1]规格化,下面就是规格化后的数据:
其中包括两次世界杯与一次亚洲杯。
我提前对数据做了如下预处理:对于世界杯,进入决赛圈则取其最终排名,没有进入决赛圈的,打入预选赛十强赛赋予40,预选赛小组未出线的赋予50。
对于亚洲杯,前四名取其排名,八强赋予5,十六强赋予9,预选赛没出现的赋予17。
这样做就是为了使得所有数据变为标量,便于后续聚类。
下面先对数据进行[0,1]规格化,下面就是规格化后的数据:
从做到右依次表示各支球队到当前中心点的欧氏距离,将每支球队分到最近的簇,可对各支球队做如下聚类:
中国C,日本A,韩国A,伊朗A,沙特A,伊拉克C,卡塔尔C,阿联酋C,乌兹别克斯坦B,泰国C,越南C,阿曼C,巴林B,朝鲜B,印尼C。
第一次聚类结果:
A:日本,韩国,伊朗,沙特;
B:乌兹别克斯坦,巴林,朝鲜;
C:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼,印尼。
下面根据第一次聚类结果,调整各个簇的中心点。
A 簇的新中心点为: {(0、3+0+0、24+0、3)/4=0、21,(0+0、15+0、76+0、76)/4=0、4175,(0、19+0、13+0、25+0、06)/4=0、1575} = {0、21, 0、4175, 0、1575}
用同样的方法计算得到B 与C 簇的新中心点分别为{0、7, 0、7333, 0、4167},{1, 0、94,0、40625}。
用调整后的中心点再次进行聚类,得到:
第二次迭代后的结果为:
中国C,日本A,韩国A,伊朗A,沙特A,伊拉克C,卡塔尔C,阿联酋C,乌兹别克斯坦B,泰国C,越南C,阿曼C,巴林B,朝鲜B,印尼C。
结果无变化,说明结果已收敛,于就是给出最终聚类结果:
亚洲一流:日本,韩国,伊朗,沙特
亚洲二流:乌兹别克斯坦,巴林,朝鲜
亚洲三流:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼,印尼
瞧来数据告诉我们,说国足近几年处在亚洲三流水平真的就是没有冤枉她们,至少从国际杯赛战绩就是这样的。
其实上面的分析数据不仅告诉了我们聚类信息,还提供了一些其它有趣的信息,例如从中可以定量分析出各个球队之间的差距,例如,在亚洲一流队伍中,日本与沙特水平最接近,而伊朗则相距她们较远,这也与近几年伊朗没落的实际相符。
另外,乌兹别克斯坦与巴林虽然没有打进近两届世界杯,不过凭借预算赛与亚洲杯上的出色表现占据B 组一席之地,而朝鲜由于打入了2010 世界杯决赛圈而有幸进入B 组,可就是同样奇迹般夺得2007年亚洲杯的伊拉克却被分在三流,瞧来亚洲杯冠军的分量还不如打进世界杯决赛圈重啊。
其它有趣的信息,有兴趣的朋友可以进一步挖掘。