SPSS的聚类案例
- 格式:pptx
- 大小:199.21 KB
- 文档页数:28
六、聚类分析(一)概述1.聚类分析的目的根据已知数据,计算样本或者变量之间亲疏关系的统计量(距离或相关系数)。
根据某种准则(最短距离法、最长距离法、中间距离法、重心法),使同一类内的差别较小,而类与类之间的差别较大,最初达到的就是将样本或变量分成若干类。
2.聚类分析的分类3.距离与相似性为了对样本或者变量进行分类,就需要研究样本之间的关系,最常用的方法有两个。
(二)系统聚类1.系统聚类的步骤距离的具体定义及计算方式计算n各样本两两之间的距离将距离接近的数据依次合并为一类,再计算,再合并 画聚类图,解释类与类之间的关系2.亲疏程度度量方法3.系统聚类的分类4.SPSS操作及实例SPSS采用的是凝聚法。
案例:根据30个省的23个主要行业的平均工资情况,通过聚类分析来判断哪些地区平均工资水平高。
SPSS操作及结果:打开SPSS上方菜单栏中的分析->分类->系统聚类选择变量->勾选统计量->在绘制里选择树状图和冰柱图勾选方法(通常使用组间联接)->度量区间->选择标准化方式(全距从0到1)下图为近似矩阵表,标注了相关系数,数值越大,距离越接近下图为聚类分析结果表,第一类表示这是聚类分析的第几步,第二三列表示该步中那几个样本或者小类聚成一类,第四列表示距离,第五六列表示本步骤中参与的是个体还是小类(0表示样本,非0表示第n步生成的小类),第七列表示本步骤的聚类结果将在以下第几步中用到。
下面是冰柱图和树状图的结果,根据树状图可以看出,如果分为三类的话,第一类包括北京上海,第二类包括天津、广东、浙江、江苏、西藏,剩下的归为一类。
(三)快速聚类(适合大样本聚类)1.快速聚类的步骤指定聚类数目K确定K个初始类的中心(自定义或者根据数据中心初步确定)根据距离最近的原则进行分类根据新的中心位置,重新计算每一记录距离新的类别中心的的距离,并重新分类重复步骤4,直到达到标准2.SPSS操作及实例打开SPSS上方菜单栏中的分析->分类->K-均值聚类选择变量->勾选统计量->定义变量值选择迭代次数->选项(勾选初始聚类中心、每个个案的聚类信息)->定义变量值->保存(勾选聚类成员、聚类中心距离)下图为输出的初始聚类中心下图为最终距离中心,第一类平均工资最高,第二类次之,第三类最低下图为每个聚类中的案例数和聚类成员。

SPSS聚类分析实例讲解SPSS是一款功能强大的统计分析软件,可用于数据清洗、描述统计分析、假设检验和聚类分析等。
聚类分析是一种无监督学习方法,其目标是按照数据的相似性度量,将样本数据划分为多个不同的群组。
下面将以一个实例来讲解如何使用SPSS进行聚类分析。
实例描述:假设有一个超市的销售数据,包含了不同商品的销售额、销售量和利润等信息。
我们希望将商品进行聚类分析,找出相似销售特征的商品群组。
步骤一:数据准备首先,将销售数据保存为一个.SP文件,然后打开SPSS软件。
在主界面上选择“文件”-“打开”-“数据库”-“从SPSS文件”,打开数据文件。
步骤二:变量选择在数据文件中,选择出要进行聚类分析的变量。
在“数据视图”中,选择那些代表销售特征的变量,例如“销售额”、“销售量”和“利润”。
在变量列上按住“Ctrl”键,同时点击这些变量名,选中它们。
步骤三:聚类分析点击菜单上的“数据”-“服务”-“聚类分析”进行聚类分析操作。
会弹出“聚类分析”对话框。
在对话框中,将选中的变量移到右侧的“变量”框中,并选择“K均值聚类”作为聚类方法。
K值是指要分成的群组数量,可以根据实际情况设定。
这里假设将商品分成3个群组,因此设置为3步骤四:聚类结果解读点击“确定”按钮,SPSS将自动进行聚类分析。
完成后,SPSS会在数据文件中生成一个新的变量,用于表示每个样本所属的群组。
在下方的“结果视图”中,可以看到聚类结果的统计数据、聚类中心和变量间的距离。
此外,在“分类变量资料”中,还可以看到每个样本所属的群组编号。
步骤五:聚类结果可视化为了更好地理解聚类结果,可以进行可视化展示。
点击菜单上的“图形”-“散点图”,在对话框中依次选择所属群组变量和销售额、销售量这两个变量。
点击“确定”按钮,即可生成散点图。
散点图可以清楚地显示出不同群组之间的差异和相似性。
根据散点图,可以对聚类结果进行解读。
例如,如果不同群组之间的点比较分散,则说明聚类效果较差;而如果不同群组之间的点比较集中,则说明聚类效果较好。

SPSS聚类分析:用于筛选聚类变量的一套方法聚类分析是常见的数据分析方法之一,主要用于市场细分、用户细分等领域。
利用SPSS进行聚类分析时,用于参与聚类的变量决定了聚类的结果,无关变量有时会引起严重的错分,因此,筛选有效的聚类变量至关重要。
案例数据源:在SPSS自带数据文件plastic.sav中记录了20中塑料的三个特征,分别是tear_res(抗拉力)、gloss(光滑度)、opacity(透明度),相关经验表面这20中塑料可以分为3个种类,如果用这三个变量进行聚类,请判断和筛选有效聚类变量。
一套筛选聚类变量的方法一、盲选将根据经验得到的、现有的备选聚类变量全部纳入模型,暂时不考虑某些变量是否不合适。
本案例采用SPSS系统聚类方法。
对话框如下:统计量选项卡:聚类成员选择单一方案,聚类数输入数字3;绘制选项卡:勾选树状图;方法选项卡:默认选项,不进行标准化;保存选项卡:聚类成员选择单一方案,聚类数输入数字3;二、初步聚类这是盲选得到的初步聚类结果,并且在数据视图我们可以看到已经自动生成了一个聚类结果变量,这个变量非常有用。
三、方差分析是不是每一个纳入模型的聚类变量都对聚类过程有贡献?利用已经生成的初步聚类结果,我们可以用一个单因素方差分析来判断分类结果在三个变量上的差异是否显著,进而判断哪些变量对聚类是没有贡献的。
分析——比较均值——单因素方差分析:选项选项卡:勾选均值图由方差分析我们很明确的得知,纳入模型的三个聚类变量,其中只有“透明度”指标在各个分类上有显著的差异,也就是说分类有效果,让每个分类的差异很大,而两外两个变量则在三个分类上没有显著差异,没有很好的类别区分度,所以,我们可以认为,这两个变量对聚类无作用或者无贡献,可考虑踢出模型。
我们还想从可视化的角度来查看和判断,单因素方差分析为我们提供了均值图,可惜,这三个图却最容易误导我们的判断,因为spss在自动生产均值图时为每一个变量单独制图,而且分配不同的纵轴坐标,导致每个图看起来都有非常大的差异,从视觉上迷惑我们做出错误的判断。

spss聚类分析案例SPSS聚类分析案例。
在统计学中,聚类分析是一种常用的数据分析方法,它可以将数据集中的个体或变量进行分组,使得同一组内的个体或变量之间的相似度较高,而不同组之间的相似度较低。
聚类分析在市场分析、社会学调查、医学研究等领域有着广泛的应用。
而SPSS作为一款专业的统计分析软件,提供了丰富的聚类分析功能,能够帮助研究者对数据进行深入的分析和挖掘。
在本案例中,我们将以一个实际的数据集为例,介绍SPSS中如何进行聚类分析,并对分析结果进行解读和讨论。
首先,我们需要加载数据集,然后选择合适的变量进行聚类分析。
在选择变量时,需要考虑变量之间的相关性,避免出现多重共线性的情况。
在本案例中,我们选择了A、B、C三个变量进行聚类分析。
接下来,我们需要进行聚类分析的设置。
在SPSS软件中,可以选择不同的聚类算法和距离度量方法,以及设置聚类的个数。
在本案例中,我们选择了K均值聚类算法,并设置聚类的个数为3。
同时,我们还可以对聚类结果进行验证和评价,以确保聚类结果的准确性和稳定性。
在进行聚类分析后,我们需要对聚类结果进行解读和讨论。
首先,我们可以通过聚类中心和聚类图表来直观地展示不同组之间的差异和相似度。
然后,我们可以对每一组的特征进行分析,找出不同组之间的显著性差异和共性特征。
最后,我们可以将聚类结果与实际情况进行比较,验证聚类结果的有效性和可解释性。
通过本案例的介绍,相信读者对SPSS中的聚类分析方法有了更深入的了解。
在实际应用中,聚类分析可以帮助研究者发现数据中潜在的规律和结构,为决策提供科学依据。
同时,SPSS作为一款功能强大的统计分析软件,为用户提供了丰富的数据分析工具和可视化功能,能够满足不同领域的研究需求。
总之,聚类分析是一种重要的数据分析方法,能够帮助研究者理解数据的内在结构和规律。
而SPSS作为一款专业的统计分析软件,为用户提供了便捷的聚类分析工具,能够帮助用户快速准确地进行数据分析和挖掘。

spss聚类分析案例在进行SPSS聚类分析时,我们通常会遵循一系列步骤来确保分析的准确性和有效性。
以下是一个典型的聚类分析案例,展示了如何使用SPSS软件进行数据分析。
首先,我们需要收集数据。
数据可以是定量的,也可以是定性的,但必须与研究问题相关。
例如,如果我们正在研究消费者购买行为,我们可能会收集关于消费者年龄、收入、购买频率和偏好的数据。
接下来,我们将数据导入SPSS。
这可以通过直接输入数据、从Excel文件导入或使用SPSS的数据导入向导来完成。
一旦数据在SPSS中,我们需要检查数据的准确性和完整性,确保没有缺失值或异常值。
在进行聚类分析之前,我们通常需要对数据进行预处理。
这可能包括标准化变量、处理缺失值和异常值,以及可能的变量转换。
标准化是重要的,因为它确保了所有变量在聚类分析中具有相同的权重。
然后,我们选择聚类方法。
SPSS提供了几种聚类方法,包括K-means聚类、层次聚类和双向聚类。
选择哪种方法取决于数据的特性和研究目的。
例如,如果我们有明确的类别数量,K-means聚类可能是合适的;如果我们希望看到数据的层次结构,层次聚类可能更合适。
在选择了聚类方法后,我们需要确定聚类的数量。
这可以通过多种方法来确定,包括肘部方法、轮廓系数或基于信息准则的方法。
确定聚类数量后,我们可以运行聚类算法,并将数据点分配到不同的聚类中。
聚类完成后,我们需要评估聚类的质量。
这可以通过查看聚类的内部一致性和聚类之间的差异来完成。
我们还可以进行统计测试,如ANOVA或卡方检验,来检验聚类是否在统计上显著。
最后,我们解释聚类结果。
这包括识别每个聚类的特征,以及这些特征如何与研究问题相关。
例如,如果我们发现一个聚类主要由高收入、频繁购买的消费者组成,这可能表明这是一个高价值的市场细分。
在整个聚类分析过程中,我们可能会进行多次迭代,调整聚类方法、聚类数量或数据预处理步骤,以获得最佳的聚类结果。
聚类分析是一个动态的过程,需要根据数据和研究目的进行调整。

各地区各行业工资水平的分析(2009年数据)小组成员:张艺伟、赵月、陈媛、邹莉、朱海龙、曾磊、胡瑛、候银萍1.研究背景及意义1.1 研究背景工资水平是指一定区域和一定时间内劳动者平均收入的高低程度。
生产决定分配,只有经济发展才能提供更多的可分配的社会产品,因此一个地区的工资水平在一定程度上反映了其经济发展的水平。
1.2 研究意义1. 通过多元统计分析方法,探究一个地区的工资水平与其经济发展水平之间的内在联系。
2. 将平均工资水平划分为3类,分析哪些地区、哪些行业的工资水平较高,可以为大学生就业提供宏观上的方向指引。
2.数据来源与描述2.1 数据来源——《中国劳动统计年鉴─2010》(URL:/Navi/YearBook.aspx?id=N2011010069&floor=1###)主编单位:国家统计局人口和就业统计司,人力资源和社会保障部规划财务司出版社:中国统计出版社简介:《中国劳动统计年鉴─2010》是一部全面反映中华人民共和国劳动经济情况的资料性年刊。
本刊收集了2009年全国和各省、自治区、直辖市、香港特别行政区、澳门特别行政区的有关劳动统计数据。
本书资料的取得形式主要有国家和部门的报表统计、行政记录和抽样调查。
2.2 数据描述本数据集记录了全国31个省市(港、澳、台除外)的工资状况,各省市分别记录了其23个主要行业的平均工资水平,这23个主要行业包括:企业、事业、机关、金融业、制造业、建筑业、房地产业、农林牧渔业等等,具体数据格式参见图-0。
图-03.分析方法及原理3.1 通过描述统计分析方法,判断哪些行业平均工资水平较高描述统计分析方法主要是从基本统计量(诸如均值、方差、标准差、极大/小值、偏度、峰度等)的计算和描述开始的,并辅助于SPSS提供的图形功能,能够把握数据的基本特征和整体的分布特征。
在本案例中,通过比较不同行业(诸如企业、事业、机关、建筑业、制造业……)工资的均值、极大/小值,可以从总体上判断哪些行业的平均工资水平较高,哪些行业的较低。
作业2:城镇居民消费结构的K-means聚类模型
本次作业为基于IBM SPSS Statistics 24的K-means聚类运算
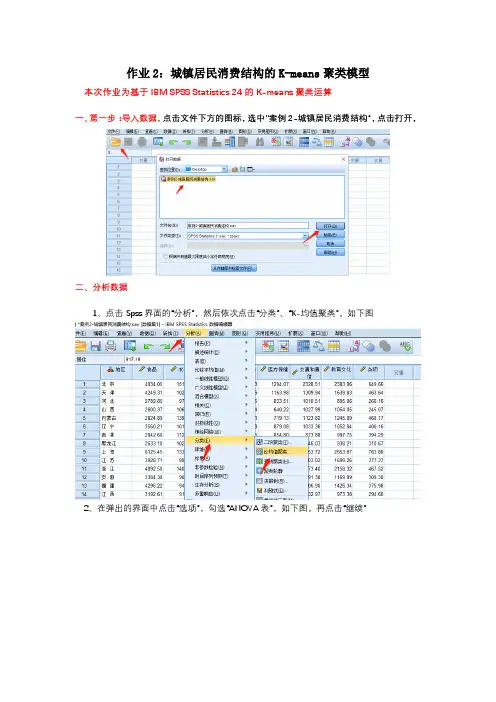
一、第一步:导入数据,点击文件下方的图标,选中”案例2-城镇居民消费结构“,点击打开,
二、分析数据
1、点击Spss界面的“分析”,然后依次点击“分类”、“K-均值聚类”,如下图
2、在弹出的界面中点击“选项”,勾选“ANOVA表”,如下图,再点击“继续”
3、在弹出的界面中点击“保存”,勾选“聚类成员”、“与聚类中心距离”,如下图所示,点击“继续”
4、最后在弹出的界面中,把“地区”放入“个案标注依据”,其余的放入“变量”中,如下图所示,点击“确定”。
三、结果展示
ANOVA。


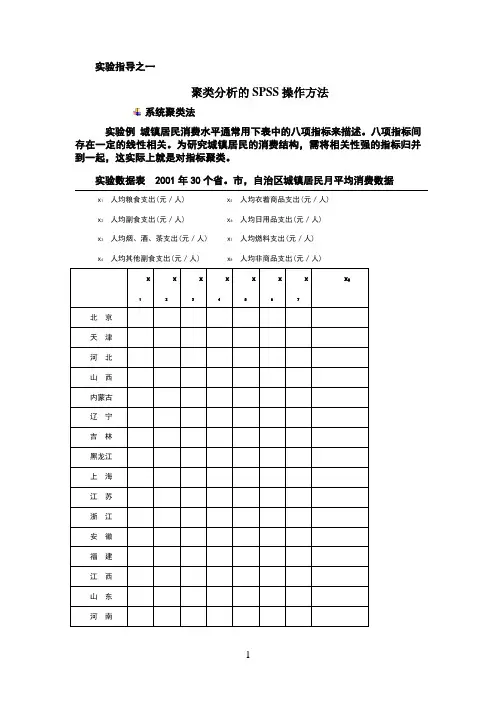
实验指导之一聚类分析的SPSS操作方法系统聚类法实验例城镇居民消费水平通常用下表中的八项指标来描述。
八项指标间存在一定的线性相关。
为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际上就是对指标聚类。
实验数据表 2001年30个省。
市,自治区城镇居民月平均消费数据x1人均粮食支出(元/人) x5人均衣着商品支出(元/人)x2人均副食支出(元/人) x6人均日用品支出(元/人)x3人均烟、酒、茶支出(元/人) x7人均燃料支出(元/人)x4人均其他副食支出(元/人) x8人均非商品支出(元/人)x 1x2x3x4x5x6x7x8北京天津河北山西内蒙古辽宁吉林黑龙江上海江苏浙江安徽福建江西山东河南湖北湖南13.23广东广西海南四川贵州云南西藏陕西甘肃青海宁夏新疆系统聚类法的SPSS操作:1. 从数据编辑窗口点击Analyze →Classify →Hierachical Cluster , (见图1)图1 系统聚类法打开层次聚类法对话如图2。
图2 系统聚类法对话框选择需要进行聚类分析的变量进入Variable框内后,在Cluster栏中选择聚类类型,SPSS有两种层次聚类方法:Cases 对样品聚类(Q型;系统默认),Variable 对指标变量聚类(R型),本例选择。
在Display栏中选择默认的输出项。
2. 点击Statistics按钮,打开对话框如图3.图3 Statistics对话框Agglomeration schedule输出凝聚状态表(聚类进度表);本例选择。
Ploximity matrix 输出个体间的距离矩阵,本例选择。
Cluster Membership栏中显示每个观测量被分派到的类。
None 不输出。
本例选择。
Simple solution 指定分类数,并输出样本所属类,单一解。
Renge of solution 指定输出从m到n类的各样本所属类。
多个解。
选好后返回主对话框。

IBM SPSS Modeler 实验一、聚类分析在数据挖掘中,聚类分析关注的内容是一些相似的对象按照不同种类的度量构造成的群体。
聚类分析的目标就是在相似的基础上对数据进行分类。
IBM SPSS Modeler提供了多种聚类分析模型,其中主要包括两种聚类分析,K-Mean 聚类分析和Kohonen聚类分析,下面对各种聚类分析实验步骤进行详解。
1、K-Means聚类分析实验首先进行K-Means聚类实验。
(1)启动SPSS Modeler 14.2。
选择“开始”→“程序”→“IBM SPSS Modeler 14.2”→“IBM SPSS Modeler 14.2”,即可启动SPSS Modeler程序,如图1所示。
图1 启动SPSS Modeler程序(2)打开数据文件。
首先选择窗口底部节点选项板中的“源”选项卡,再点击“可变文件”节点,单击工作区的合适位置,即可将“可变文件”的源添加到流中,如图2所示。
右键单击工作区的“可变文件”,选择“编辑”,打开如图3的编辑窗口,其中有许多选项可供选择,此处均选择默认设定。
点击“文件”右侧的“”按钮,弹出文件选择对话框,选择安装路径下“Demos”文件夹中的“DRUG1n”文件,点击“打开”,如图4所示。
单击“应用”,并点击“确定”按钮关闭编辑窗口。
图2 工作区中的“可变文件”节点图3 “可变文件”节点编辑窗口图4 文件选择对话框图5 工作区中的“表”节点(3)借助“表(Table)”节点查看数据。
选中工作区的“DRUG1n”节点,并双击“输出”选项卡中的“表”节点,则“表”节点出现在工作区中,如图5所示。
运行“表”节点(Ctrl+E或者右键运行),可以看到图6中有关病人用药的数据记录。
该数据包含7个字段(序列、年龄(Age)、性别(Sex)、血压(BP)、胆固醇含量(Cholesterol)、钠含量(Na)、钾含量(K)、药类含量(Drug)),共200条信息记录。
spss软件聚类分析案例案例一:选择那些变量进行聚类?——采用“R型聚类”1、现在我们有4个变量用来对啤酒分类,是否有必要将4个变量都纳入作为分类变量呢?热量、钠含量、酒精含量这3个指标是要通过化验员的辛苦努力来测定,而且还有花费不少成本,如果都纳入分析的话,岂不太麻烦太浪费?所以,有必要对4个变量进行降维处理,这里采用spss R型聚类(变量聚类),对4个变量进行降维处理。
输出“相似性矩阵”有助于我们理解降维的过程。
2、4个分类变量量纲各自不同,这一次我们先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,此时,涉及到相关,4个变量可不用标准化处理,将来的相似性矩阵里的数字为相关系数。
若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
只输出“树状图”就可以了,个人觉得冰柱图很复杂,看起来没有树状图清晰明了。
从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。
至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。
(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。
)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
案例二:20中啤酒能分为几类?——采用“Q型聚类”现在开始对20中啤酒进行聚类。
开始不确定应该分为几类,暂时用一个3-5类范围来试探。
Q型聚类要求量纲相同,所以我们需要对数据标准化,这一回用欧式距离平方进行测度。
2、主要通过树状图和冰柱图来理解类别。
最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。
我这里试着确定分为4类。
选择“保存”,则在数据区域内会自动生成聚类结果。
案例三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”1、聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
1.打开数据文件后,在数据编辑窗口中,从菜单栏中选择“分析”—“分类”—“k-均值
聚类”命令。
2.在该对话框中选择变量城市进入“个案标记依据”文本框,作为标签变量。
把聚类数标
记为4次。
3.选择变量一至十二月份的日照时数进入“变量”列表框作为观测变量。
4.单击“迭代”按钮,迭代次数为10次,收敛性标准为0.
5.单击“保存”按钮,选择“聚类成员”。
6.单击“选项”按钮,选择“初始聚类中心”和“ANOVA表”,要求输出方差分析表,单
击“继续”。
7.单击“确定”按钮,执行快速聚类分析。
[数据集1] C:\Documents and Settings\Administrator\桌面\ch9\主要城市日照时数.sav
每个聚类中的案例数。
我国各地区农村居民消费结构分析数学B1202 黄晓兰 2012016431一、前言居民消费是实现国民经济良性循环的关键,而消费结构是否合理,又是消费的关键问题,因此居民消费结构作为反映居民消费状况的主要因素。
本文选取了2012年中国31个农村地区居民家庭平均人均消费支出的数据,对其采用SPSS软件进行聚类分析,提出平衡我国城镇居民消费水平、改善城镇居民消费结构、提高城镇居民消费水平的对策建议。
根据2012年中国统计年鉴得到我国各地区农村居民消费支出状况,考虑到各项支出的比重为指标的话,我选取了以下8个变量:食品、衣着、居住、家庭设备及用品、交通通信、文教娱乐、医疗保健及其他来进行分析。
考察消费结构是研究和衡量居民生活水平、生活质量的一条重要途径,可以从侧面反映一个区域宏观经济发展的基本状况。
消费结构是一种客观存在,消费结构的分类则是人们主观的产物。
人们可以根据实际需要对消费结构进行不同的分类。
从其定义上来讲,居民消费结构是指在一定社会经济条件下居民各项消费支出在消费总支出所占的比重,它不但能反映居民消费的具体内容,更能反映居民消费需求的满足情况,近年来随着经济的发展,社会生产力水平迅速提高,人民的生活水平也显著得到提高,消费质量和结构不断优化,相对于过去而言,居民对衣、食、住的消费需求已从追求数量转到追求质量,居民食品支出比重不断下降,而交通通信、文教娱乐、医疗保健及其他比重不断增加。
消费结构变化反映了需求的变动,因此分析消费结构的变动及其成因对合理引导消费、促进经济的发展都有重要的意义。
注:以下数据来源于中国统计年鉴2012年二、数据分析聚类案例处理汇总a,b案例有效缺失总计N 百分比N 百分比N 百分比31 100.0 0 .0 31 100.0a. 平方Euclidean 距离已使用b. 平均联结(组之间)平均联结(组之间)聚类表阶群集组合系数首次出现阶群集下一阶群集 1 群集 2 群集 1 群集 21 12 17 15812.985 0 0 112 29 31 18798.951 0 0 93 3 30 26251.212 0 0 44 3 4 34450.926 3 0 75 24 28 49554.842 0 0 236 7 8 52033.781 0 0 167 3 16 53706.678 4 0 98 14 20 69551.264 0 0 119 3 29 80466.160 7 2 1710 5 6 80937.213 0 0 1611 12 14 85815.099 1 8 1812 21 23 99922.108 0 0 1413 13 19 108425.092 0 0 2714 18 21 152222.417 0 12 1915 22 25 152739.341 0 0 1916 5 7 169054.627 10 6 2217 3 27 186596.903 9 0 1818 3 12 246368.676 17 11 2419 18 22 260667.112 14 15 2520 2 10 325251.759 0 0 2721 1 11 353495.754 0 0 2822 5 15 369923.624 16 0 2423 24 26 381145.245 5 0 2624 3 5 442501.916 18 22 2525 3 18 476733.957 24 19 2626 3 24 861845.040 25 23 2927 2 13 980190.931 20 13 2928 1 9 1063411.550 21 0 3029 2 3 2476743.614 27 26 3030 1 2 7444712.108 28 29 0树状图C A S E 0 5 10 15 20 25Label Num +---------+---------+---------+---------+---------+安徽 12 -+湖北 17 -+江西 14 -+广西 20 -+青海 29 -+-+新疆 31 -+ |河北 3 -+ |宁夏 30 -+ |山西 4 -+ |河南 16 -+ |陕西 27 -+ |吉林 7 -+ |黑龙江 8 -+-+内蒙古 5 -+ +-+辽宁 6 -+ | |山东 15 ---+ |海南 21 -+ | |四川 23 -+ | +-----------+湖南 18 -+-+ | |重庆 22 -+ | |云南 25 -+ | |贵州 24 -+-+ | +-------------------------------+甘肃 28 -+ +-+ | |西藏 26 ---+ | |福建 13 -+-----+ | |广东 19 -+ +---------+ |天津 2 ---+---+ |江苏 10 ---+ |北京 1 ---+---+ |浙江 11 ---+ +-----------------------------------------+上海 9 -------+三、结果分析聚类分析结果如下:类别地区1—经济高度发达地区上海;2—经济发达地区江苏、北京、浙江;3—经济较发达地区福建、广东、天津;4—经济发展一般地区安徽、湖北、江西、广西、青海、新疆、河北、宁夏、山西、河南、陕西、吉林、黑龙江、内蒙古、辽宁、山东、海南、四川、湖南;5—经济发展落后地区西藏、贵州、甘肃、重庆、云南;聚类结果的五大类,基本上是根据区域经济发展环境的相似性相聚成类,并按照发展环境的优越程度由高到低排列的。
X4人均家庭设备及服务支出(元/人)X8其他商品及服务支出(元/人)图表1注:上图截取了31个地区一部分数据数据来源:中国统计年鉴(二)数据分析以上选择的8个指标都很好的从衣、食、住、行四个方面反映了31个地区的人均消费水平,在一定程度了反映了不同地区的发展水平情况,通过运用欧式距离,将它们之间距离最近的两类合并为新类,然后计算新类与当前各类之间的距离,直至类的个数等于1时,画出聚类图,决定类的个数和最终分类数。
二、SPSS的聚类分析结果(一)分类数的确定图表2聚合系数随分类数变化曲线将SPSS输出的聚合系数值导入EXCEL中,做出聚合系数随分类数变化曲线,由图表2看出分类数3到5类是最合适的,但由于分类数过多不利于分析,所以我们选择分为3类对31个地区进行统计分析。
将数据导入SPSS软件,在“分析”菜单中选择“分类”,选择其中的系统聚类分析,将X1到X8八个变量选入变量框中,标注个案中选择地区,再点击右侧“方法”,聚类方法选择组内连接,区间测量采取平方Euclidean距离,并将其采用Z分数标准化,最后,单机确定按钮,SPSS则输出图表3。
图表3是对每一个阶段不同聚类结果的反映,其中第四列为聚合系数,其值越大,代表其相似性越大,聚合损失量则会越少。
(二)具体分类情况如上图所示是树状聚类图,由上面分析可知将其分为三类,易得分为北京、浙江、上海、其他地区,三类情况。
结束语:将上海分为第一类,北京、浙江分为第二类,其他分为第三类,根据经验易得第一类为最发达地区,拥有各种机遇,主要发展高新技术产业;第二类为较发达地区,其经济上也有很大的突破,其应主要发展制造业,不断升级改进;第三类为经济欠发达地区,应该借用各地区的优势,积极发展自己特色的产业,提升经济实力。
参考文献:[1]吕卫平,张晓梅.基于SPSS的聚类分析应用[J].福建电脑,2013 (09):20-23.[2]薛薇.统计分析与SPSS的应用[M].北京:中国人民大学出版社,2011.作者简介:刘雪敏(1998-),女,汉族,河北省张家口市人,本科,河北大学经济学院。