音频数字化简单原理
- 格式:doc
- 大小:38.50 KB
- 文档页数:6


声音数字化过程及主要参数声音数字化是将声波转换成数字信号的过程,它是数字音频技术的基础。
声音数字化技术的发展,为音频录制、处理、存储和传输提供了重要的手段,极大地推动了音频产业的发展。
本文将围绕声音数字化过程及其主要参数展开阐述。
一、声音数字化的过程声音数字化是通过模拟到数字转换器(ADC)实现的。
其基本过程如下:1. 声音采样声音信号是一种连续的模拟信号,要进行数字化,首先需要将其进行采样。
采样是在规定的时间间隔内,对声音信号进行离散取样,获取一系列的采样点。
采样频率是决定声音数字化质量的关键参数,一般情况下,采样频率越高,数字化的声音质量越好,音频的频率响应也越宽。
2. 量化在采样后,需要对采样点的幅度进行量化。
量化是指将连续的信号幅度转换成离散的数字值。
量化的精度决定了数字化声音的分辨率,也就是声音的动态范围。
一般来说,量化位数越多,声音的动态范围越宽,音质也就越好。
3. 编码经过量化后,需要将量化得到的数字值编码成二进制数,以便存储和传输。
编码方式有许多种,常见的有脉冲编码调制(PCM)和压缩编码,其中PCM是最常用的编码方式。
以上三个步骤完成后,声音信号就被数字化了,可以被存储、处理和传输。
二、声音数字化的主要参数声音数字化的质量取决于多个参数,以下是一些重要的参数:1. 采样频率采样频率是指每秒钟采集的采样点数量,它决定了声音信号的频率范围。
常见的采样频率有8kHz、16kHz、44.1kHz、48kHz等,其中44.1kHz和48kHz是CD音质的标准采样频率。
2. 量化位数量化位数是指用来表示采样点幅度的二进制位数,它决定了声音的动态范围。
通常的量化位数有8位、16位、24位等,其中16位是CD 音质的标准量化位数。
3. 编码方式编码方式决定了声音数字化的压缩算法,不同的编码方式对声音质量和文件大小有不同的影响。
PCM编码是无损压缩的编码方式,压缩编码则可以在减小文件大小的同时保持较高的音质。

名词解释声音的数字化声音的数字化是指将声音信号转换为数字化的格式并进行存储、处理和传输的过程。
数字化技术的出现和发展在很大程度上改变了人们对声音的感知和交流方式,为音乐、广播、电影等领域带来了前所未有的发展机遇。
一、数字化技术的背景和原理在数字化技术出现之前,声音的存储和传输通常是通过模拟信号的方式进行的。
模拟信号是一种连续变化的电压或电流波形,它能够准确地描述声音的特征,但却难以长时间保存和远距离传输。
为了解决这个问题,人们开始研究将声音信号转换为数字信号的方法。
数字化技术的核心原理是采样和量化。
采样是指以一定的时间间隔对声音信号进行离散取样,将连续变化的模拟信号转换为一系列离散的抽样点。
量化是指将每个抽样点的幅度值转换为一系列数字值,通常使用二进制编码表示。
将采样和量化结合起来,就可以将声音信号转换为数字化的格式。
二、数字化技术的应用领域声音的数字化技术广泛应用于音乐、广播、电影等领域。
在音乐领域,数字化技术使得音乐作品的录制、编辑和创作更加方便和灵活。
音乐制作人可以通过数字化工具对音乐进行多次录制和编辑,从而达到更好的音质效果。
此外,数字化技术还为音乐播放器的发展提供了基础,人们可以通过智能手机、MP3等设备随时随地欣赏自己喜爱的音乐。
在广播和电影领域,数字化技术的应用也非常广泛。
通过数字化技术,广播和电视节目可以进行远程传输和播放,大大扩展了传媒的覆盖范围。
此外,数字化技术的应用使得广播和电视节目的制作更加高效和节省成本,提高了节目的质量和观赏性。
除了音乐、广播和电影,声音的数字化技术还应用于语音识别、语音合成等领域。
语音识别技术通过将人的语音信号转换为数字信息,实现机器自动识别和解析人的语音指令。
语音合成技术则是将文字信息转换为声音信号,使机器能够模拟人的语音进行交流。
三、声音数字化技术的挑战和改进声音数字化技术的发展也面临一些挑战。
最主要的挑战之一是保持音质的高保真性。
由于采样和量化过程的限制,数字化声音的音质通常会有一定的损失。

模拟声音数字声音原理一、模拟声音数字化原理声音是通过空气传播的一种连续的波,叫声波。
声音的强弱体现在声波压力的大小上,音调的高低体现在声音的频率上。
声音用电表示时,声音信号在时间和幅度上都是连续的模拟信号。
图1模拟声音数字化的过程声音进入计算机的第一步就是数字化,数字化实际上就是采样和量化。
连续时间的离散化通过采样来实现。
声音数字化需要回答两个问题:①每秒钟需要采集多少个声音样本,也就是采样频率(fs)是多少,②每个声音样本的位数(bit per sample,bps)应该是多少,也就是量化精度。
采样频率采样频率的高低是根据奈奎斯特理论(Nyquist theory)和声音信号本身的最高频率决定的。
奈奎斯特理论指出,采样频率不应低于声音信号最高频率的两倍,这样才能把以数字表达的声音还原成原来的声音。
采样的过程就是抽取某点的频率值,很显然,在一秒中内抽取的点越多,获取得频率信息更丰富,为了复原波形,一次振动中,必须有2个点的采样,人耳能够感觉到的最高频率为20kHz,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样,用40kHz表达,这个40kHz就是采样率。
我们常见的CD,采样率为44.1kHz。
电话话音的信号频率约为3.4 kHz,采样频率就选为8 kHz。
量化精度光有频率信息是不够的,我们还必须纪录声音的幅度。
量化位数越高,能表示的幅度的等级数越多。
例如,每个声音样本用3bit表示,测得的声音样本值是在0~8的范围里。
我们常见的CD位16bit的采样精度,即音量等级有2的16次方个。
样本位数的大小影响到声音的质量,位数越多,声音的质量越高,而需要的存储空间也越多。
压缩编码经过采样、量化得到的PCM数据就是数字音频信号了,可直接在计算机中传输和存储。
但是这些数据的体积太庞大了!为了便于存储和传输,就需要进一步压缩,就出现了各种压缩算法,将PCM转换为MP3,AAC,WMA等格式。
常见的用于语音(Voice)的编码有:EVRC(Enhanced Variable Rate Coder)增强型可变速率编码,AMR、ADPCM、G.723.1、G.729等。


数字广播原理数字广播是一种利用数字技术传输音频信息的广播方式。
它通过将音频信号转换为数字信号,并利用数字编码和压缩技术,将音频数据传输到接收设备中进行解码和播放。
数字广播相对于传统的模拟广播具有更高的音质和更强的抗干扰能力,成为广播行业的重要发展方向。
一、数字广播的基本原理数字广播的基本原理是将音频信号数字化,并采用压缩编码技术进行传输和解码。
具体来说,数字广播的原理包括以下几个步骤:1. 音频信号数字化:将模拟音频信号转换为数字信号是数字广播的第一步。
这一过程通过采样和量化实现。
采样是指将模拟音频信号在时间轴上等间隔地采集,将其转换为一系列离散的采样值。
量化是指将采样值映射为一系列离散的数字值,通常使用固定位数的二进制表示。
2. 压缩编码:由于音频数据庞大,传输和存储成本较高,数字广播采用压缩编码技术将音频信号进行压缩,以减小数据量。
常用的压缩编码算法包括MP3、AAC等。
这些算法通过剔除人耳听觉系统不敏感的音频信号,减少冗余信息,实现对音频数据的高效压缩。
3. 数据传输:压缩编码后的音频数据通过数字传输介质进行传输,例如通过广播电台的发射设备将数字信号转换为电磁波进行传播,或通过有线网络进行传输。
传输过程中,数字广播采用差错检测和纠错技术,以提高数据传输的可靠性。
4. 解码播放:接收设备接收到传输的数字信号后,进行解码和播放。
解码过程是将压缩编码的音频数据还原为原始的数字信号。
解码后的数字信号经过数模转换,再经过功放等环节,最终转换为模拟音频信号,供扬声器播放。
二、数字广播的优势相比传统的模拟广播,数字广播具有以下优势:1. 高音质:数字广播通过对音频信号进行数字化和高效压缩,能够提供更高的音质。
数字广播的音质清晰、细腻,能够还原原始音频信号的细节和动态范围,给听众带来更好的听觉体验。
2. 抗干扰能力强:数字广播采用数字信号传输,相比模拟信号,数字信号具有更强的抗干扰能力。
数字广播可以通过差错检测和纠错技术,自动修复传输中的错误,提供更稳定的广播服务。

数字音频网络IP化的原理及应用1. 引言在数字化时代,音频领域也迎来了数字化的浪潮。
数字音频网络IP化成为了音频行业的重要趋势。
本文将介绍数字音频网络IP化的原理和应用,并深入探讨其优势和挑战。
2. 数字音频网络IP化的原理数字音频网络IP化是指将音频信号通过网络传输,并利用IP协议进行管理和控制的过程。
它基于数字音频技术和计算机网络技术,实现了音频信号的数字化和网络化。
2.1 数字音频技术数字音频技术将模拟音频信号转换为数字数据。
通过采样、量化和编码等过程,将连续的模拟音频信号转换为数字音频数据。
这种数字音频数据可以更加稳定地在网络中传输,并且可以方便地进行处理和存储。
2.2 计算机网络技术计算机网络技术提供了音频信号在网络中传输的基础。
通过建立网络连接和使用网络协议,可以将数字音频数据传输到目标设备。
IP协议是网络传输中常用的协议之一,它提供了数据的分组传输和路由选择功能,非常适合用于音频信号的传输。
2.3 数字音频网络IP化的原理数字音频网络IP化的原理包括两个方面:音频数据的数字化和网络传输的管理和控制。
2.3.1 音频数据的数字化音频数据的数字化是将模拟音频信号转换为数字音频数据的过程。
这一过程包括三个主要步骤:采样、量化和编码。
•采样:采样是指对模拟音频信号进行离散化处理,将连续的模拟信号转换为离散的数字信号。
采样率决定了采样点的数量,常用的采样率有44.1kHz、48kHz等。
•量化:量化是指将采样后的离散信号映射到有限的离散值上。
通过量化,可以将模拟音频信号的连续取值转换为离散的数字取值。
常用的量化位数有16位、24位等。
•编码:编码是将量化后的数字信号表示为二进制数据的过程。
常用的音频编码算法有PCM、MP3等。
2.3.2 网络传输的管理和控制网络传输的管理和控制是使用网络协议将数字音频数据传输到目标设备的过程。
IP协议可以提供数据分组的传输和路由选择功能,将音频数据从发送端传输到接收端。
音频数字化简单原理[ 2007-3-13 9:41:00 | By: 林俊桂] 从字面上来说,数字化 (Digital) 就是以数字来表示,例如用数字去记录一张桌子的长宽尺寸,各木料间的角度,这就是一种数字化。
跟数位常常一起被提到的字是模拟 ( Analog/Analogue) ,模拟的意思就是用一种相似的东西去表达,例如将桌子用传统相机将三视图拍下来,就是一种模拟的记录方式。
两个概念:1、分贝(dB):声波振幅的度量单位,非绝对、非线性、对数式度量方式。
以人耳所能听到的最静的声音为1dB,那么会造成人耳听觉损伤的最大声音为100dB。
人们正常语音交谈大约为20dB。
10dB意味着音量放大10倍,而20dB却不是20倍,而是100倍(10的2次方)。
2、频率(Hz):人们能感知的声音音高。
男性语音为180Hz,女性歌声为600H z,钢琴上 C调至A调间为440Hz,电视机发出人所能听到的声音是17kHz,人耳能够感知的最高声音频率为20kHz。
将音频数字化,其实就是将声音数字化。
最常见的方式是透过 PCM(脉冲) 。
运作原理如下。
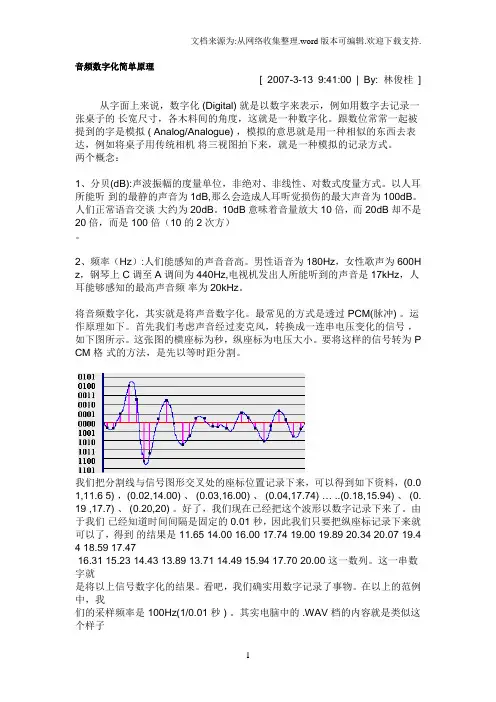
首先我们考虑声音经过麦克风,转换成一连串电压变化的信号,如下图所示。
这张图的横座标为秒,纵座标为电压大小。
要将这样的信号转为 P CM 格式的方法,是先以等时距分割。
我们把分割线与信号图形交叉处的座标位置记录下来,可以得到如下资料,(0.0 1,11.6 5) ,(0.02,14.00) 、 (0.03,16.00) 、 (0.04,17.74) … ..(0.18,15.94) 、 (0.19 ,17.7) 、 (0.20,20) 。
好了,我们现在已经把这个波形以数字记录下来了。
由于我们已经知道时间间隔是固定的 0.01 秒,因此我们只要把纵座标记录下来就可以了,得到的结果是 11.65 14.00 16.00 17.74 19.00 19.89 20.34 20.07 19.4 4 18.59 17.4716.31 15.23 14.43 13.89 13.71 14.49 15.94 17.70 20.00 这一数列。

mp3的工作原理
MP3的工作原理是基于音频数字化和压缩技术。
下面是MP3的工作原理的简要解释:
1. 采样: MP3是一种数字音频格式,它从模拟音频信号开始,通过采样将其转换为数字信号。
这就是通过在特定时间间隔内测量音频信号的振幅来实现的。
2. 数字化: 一旦采样完成,音频信号将被转换成一系列二进制数值。
这些数值代表了在特定时间点上记录的采样数据。
3. 压缩: 为了减小文件的大小,并方便存储和传输,MP3使用了一种称为音频压缩的技术。
它通过删除或降低不必要的音频数据来实现压缩。
这些不必要的数据可以是听觉上不明显的,比如较低的音频频率或较小的声音。
4. 帧化: MP3音频数据被分成一系列连续的帧。
每个帧都包含一些音频数据。
5. 哈夫曼编码: MP3使用一种称为哈夫曼编码的技术进行数据压缩。
该编码方法使用变长编码来表示经常出现的音频信号模式,以便更有效地存储数据。
6. 填充: MP3文件由固定大小的帧组成。
如果音频数据不足以填充整个帧,填充数据将被添加到最后一个帧中,以保持一致的文件结构。
7. 解码: 在播放MP3文件时,它需要使用MP3解码器来还原音频数据。
该解码器将应用与编码相反的过程,解压缩和恢复原始音频数据。
8. 播放: 解码后的音频数据被发送到扬声器或其他音频设备以产生声音。
总结起来,MP3的工作原理涉及音频信号的采样、数字化、压缩和解码等过程,从而最终实现音频播放。

简述声音数字化的原理及应用方法原理声音数字化是将声音信号转换为数字信号的过程。
声音信号是连续的模拟信号,通过数字化可以实现存储、处理和传输。
声音数字化的原理主要包括采样、量化和编码。
采样采样是指按照一定的时间间隔对声音信号进行抽样,将连续的模拟信号离散化为一系列离散的采样值。
采样频率是指每秒进行采样的次数,采样频率越高,更多的采样值能够准确地记录声音信号的细节。
量化量化是将采样得到的模拟信号值转换为离散的数字信号值。
量化过程中需要确定每个采样值的数值范围,将其映射为一个离散的数字值。
量化位数越高,数字化后的声音信号越接近原始模拟信号。
编码编码是指将量化后的数字信号表示为计算机能够识别和处理的二进制形式。
常用的编码方法包括脉冲编码调制(PCM)、压缩编码(如MP3)等。
应用方法声音数字化在音频领域有广泛的应用,以下列举了几种常见的应用方法:1.录音和音乐制作:声音数字化使得录音和音乐制作更加便捷,可以通过数字录音设备进行高质量的录制,并通过数字音频工作站进行后期处理、编辑和混音等操作。
2.电话通信:电话通信中的声音信号经过声音数字化后,可以通过数字通信网络进行传输,实现远程通信。
数字化的声音信号能够提供更好的声音质量和稳定的通信信号。
3.语音识别:声音数字化为语音识别提供了基础。
通过将声音信号转换为数字信号,计算机可以对语音进行识别和理解。
语音识别技术在智能助理、语音控制等领域有广泛的应用。
4.音乐存储和播放:声音数字化后,音乐可以以数字音频文件的形式进行存储,并通过数字设备进行播放。
数字音乐的存储和播放方便灵活,不受时间和空间的限制。
5.声音效果处理:数字化的声音信号可以通过声音效果处理器进行各种音效处理,如混响、均衡器、压缩等,来增强或修改声音的音质和效果。
6.声纹识别:声音数字化为声纹识别提供了基础。
声纹识别技术通过对声音信号进行分析和特征提取,可以识别个体的声音特征,应用于身份验证、安全防护等领域。

音频信号的数字化名词解释导言:随着科技的不断发展,数字化已经深入到我们生活的方方面面。
从音乐到电影,从电话到广播,数字化的影响无处不在。
而音频信号的数字化是其中一个重要的方面。
本文将深入解释音频信号的数字化,包括相关的技术原理和常见的名词解释,旨在帮助读者更好地了解数字化音频的概念与应用。
一、音频信号音频信号是指在一段时间内,传递声音信息的信号。
它是物理声波在电子设备中的电信号表示。
音频信号的传输可以通过电线、光纤或无线电波等介质进行。
二、数字化音频1. 采样率采样率是指在一秒钟内对连续音频信号进行离散取样的次数。
它决定了数字化音频信号的质量。
较高的采样率可以更准确地还原原始声音,提供更高的音频保真度。
2. 量化位数量化位数是指对声音的幅度进行离散化处理的位数。
一般用Bit表示,如8 Bit、16 Bit等。
较高的量化位数可以提供更高的动态范围,使得音频信号更加真实和细腻。
3. 声道数声道数表示同时传输的独立音频通道的数量。
单声道表示只有一个独立的音频通道,立体声表示有两个独立的音频通道。
在数字化音频中,常见的声道数有单声道、立体声和环绕声等。
4. 压缩编码为了减小音频文件的大小和传输带宽,音频信号通常会经过压缩编码处理。
常见的压缩编码算法包括MP3、AAC等,它们通过利用人耳听觉特性和音频信号冗余来实现对音频信号的压缩。
三、数字化音频的优势和应用1. 高保真度数字化音频通过增强采样率和量化位数,可以提供接近原始声音的还原效果。
这种高保真度使得数字化音频成为重要的音乐、电影和广播产业的基础。
2. 容易传输和存储与模拟音频信号相比,数字化音频信号可以更容易地通过计算机网路进行传输和存储。
数字化音频文件可以压缩为较小的大小,并且可以通过互联网进行传输和分享。
3. 多媒体应用数字化音频已经广泛应用于多媒体领域,如音乐制作、电影拍摄和游戏开发等。
数字化音频可以与图像、文字和视频等其他媒体元素进行组合,为用户提供更丰富的多媒体体验。
pcm编码实现语音数字化的原理
PCM编码是一种语音数字化的原理,它将连续的模拟语音信
号转换为离散的数字信号,以便能够在数字设备上储存和传输。
PCM编码的原理是通过采样和量化来实现的。
下面是PCM编码实现语音数字化的详细步骤:
1. 采样:在一段时间内,连续的模拟语音信号被周期性地采样,即在每个采样周期内选取一个采样点,记录模拟信号的振幅。
采样的频率称为采样率,常见的采样率有8 kHz、16 kHz、44.1 kHz等。
2. 量化:采样得到的模拟信号振幅是连续的,为了将其转换为离散的数字信号,需要进行量化。
量化将每个采样点的振幅值映射为一个固定的数字值。
采样点的振幅范围被划分为若干个离散级别,每个离散级别对应一个数字值。
量化的级别称为量化位数,常见的量化位数有8位、16位等。
3. 编码:量化后的数字信号需要进行编码,以便在数字设备上储存和传输。
采用的编码方式是使用二进制表示每个量化值。
编码可以使用直接二进制编码(直接将量化值转换为二进制形式)或差分编码(对量化值与前一采样点的差值进行编码)等方式。
4. 储存和传输:经过编码后的数字信号可以被储存和传输。
由于数字信号是离散的,其储存和传输非常方便,可以使用计算机文件、数字音频格式(如WAV、MP3等)进行储存,也可
以通过数字通信方式进行传输。
通过以上步骤,连续的模拟语音信号被转换为一系列离散的数字信号,实现了语音的数字化。
在解码时,可以通过逆过程将数字信号恢复为模拟信号,使其能够被再次听到。
数字音频原理数字音频是指通过数字化技术将模拟音频信号转换为数字信号的过程,数字音频的原理是基于数字信号处理的理论和技术,它在音频领域具有重要的应用价值。
本文将从数字音频的基本原理、数字音频的特点以及数字音频的应用等方面进行介绍。
首先,数字音频的基本原理是通过模数转换器(ADC)将模拟音频信号转换为数字信号,然后再通过数模转换器(DAC)将数字信号转换为模拟音频信号。
在这个过程中,模拟音频信号经过采样、量化和编码等步骤,最终转换为数字信号。
数字音频的采样率和位深度是影响音频质量的重要参数,采样率越高、位深度越大,音频质量越高。
其次,数字音频具有许多特点,例如数字音频可以进行精确的复制和传输,不受模拟信号受到的干扰和衰减影响;数字音频可以进行数字信号处理,实现音频的编辑、混音、特效处理等功能;数字音频可以实现音频信号的压缩,减小数据量,便于存储和传输等。
这些特点使得数字音频在音频处理、音乐制作、广播电视、通讯等领域得到广泛应用。
最后,数字音频在各个领域都有着重要的应用。
在音乐制作领域,数字音频技术可以实现音频的录制、编辑、混音、母带制作等功能,大大提高了音乐制作的效率和质量;在广播电视领域,数字音频技术可以实现音频信号的编码、传输和解码,提高了广播电视的音质和传输效率;在通讯领域,数字音频技术可以实现语音通信、视频通话、网络音频传输等功能,提高了通讯的质量和稳定性。
综上所述,数字音频是通过数字化技术将模拟音频信号转换为数字信号的过程,它具有精确、稳定、可编辑、可压缩等特点,广泛应用于音乐制作、广播电视、通讯等领域。
数字音频技术的发展将进一步推动音频产业的发展,为人们的生活和工作带来更多便利和乐趣。
数字音频处理器工作原理数字音频处理器(Digital Audio Processor)是一种专门用来处理数字音频信号的电子设备。
它能够对音频信号进行采样、量化、编码、解码、滤波、混响等处理,以达到音频信号的修复、增强、改变等效果。
本文将详细介绍数字音频处理器的工作原理。
一、数字音频处理器的基本原理数字音频处理器主要基于数学信号处理的原理,通过将连续的模拟音频信号转换成离散的数字信号,再对数字信号进行处理,最后再将数字信号重新转换成模拟音频信号输出。
下面将分别介绍数字音频处理器的几个基本处理环节。
1. 采样(Sampling)采样是指将模拟音频信号在时间上进行离散化,把连续的音频信号按照一定的时间间隔进行取样。
采样定理规定了采样频率必须大于两倍的信号最高频率,以保证采样后能够准确还原原始信号。
2. 量化(Quantization)量化是将采样后的音频信号幅度离散化,将连续的幅度取值映射到离散的幅度值。
量化过程中需要确定量化级别的数量,即确定最小的幅度间隔大小,决定了音频信号的动态范围和分辨率。
3. 编码(Encoding)编码是将量化后的音频信号转换为数字信号的过程。
常见的编码方式有脉冲编码调制(PCM)、压缩编码(MP3、AAC等)等。
编码可以有效降低音频数据的存储和传输所需的空间和带宽。
4. 解码(Decoding)解码是将编码后的数字信号还原为模拟音频信号的过程。
解码需要根据编码方式进行逆向操作,将数字信号恢复为量化后的音频信号。
5. 滤波(Filtering)滤波是对音频信号进行频率响应的调整和修复,以达到去除噪声、增强音频效果等目的。
滤波可以分为低通滤波、高通滤波、带通滤波等方式,根据不同的需求选择合适的滤波方式。
6. 增益控制(Gain Control)增益控制是对音频信号的增益进行调整,以达到音量的统一或调节的目的。
增益控制常常与滤波技术相结合,通过增大或减小特定频段的音量,来实现音频效果的改变。
音频数字化简单原理[ 2007-3-13 9:41:00 | By: 林俊桂] 从字面上来说,数字化 (Digital) 就是以数字来表示,例如用数字去记录一张桌子的长宽尺寸,各木料间的角度,这就是一种数字化。
跟数位常常一起被提到的字是模拟 ( Analog/Analogue) ,模拟的意思就是用一种相似的东西去表达,例如将桌子用传统相机将三视图拍下来,就是一种模拟的记录方式。
两个概念:1、分贝(dB):声波振幅的度量单位,非绝对、非线性、对数式度量方式。
以人耳所能听到的最静的声音为1dB,那么会造成人耳听觉损伤的最大声音为100dB。
人们正常语音交谈大约为20dB。
10dB意味着音量放大10倍,而20dB却不是20倍,而是100倍(10的2次方)。
2、频率(Hz):人们能感知的声音音高。
男性语音为180Hz,女性歌声为600H z,钢琴上 C调至A调间为440Hz,电视机发出人所能听到的声音是17kHz,人耳能够感知的最高声音频率为20kHz。
将音频数字化,其实就是将声音数字化。
最常见的方式是透过 PCM(脉冲) 。
运作原理如下。
首先我们考虑声音经过麦克风,转换成一连串电压变化的信号,如下图所示。
这张图的横座标为秒,纵座标为电压大小。
要将这样的信号转为 P CM 格式的方法,是先以等时距分割。
我们把分割线与信号图形交叉处的座标位置记录下来,可以得到如下资料,(0.0 1,11.6 5) ,(0.02,14.00) 、 (0.03,16.00) 、 (0.04,17.74) … ..(0.18,15.94) 、 (0.19 ,17.7) 、 (0.20,20) 。
好了,我们现在已经把这个波形以数字记录下来了。
由于我们已经知道时间间隔是固定的 0.01 秒,因此我们只要把纵座标记录下来就可以了,得到的结果是 11.65 14.00 16.00 17.74 19.00 19.89 20.34 20.07 19.4 4 18.59 17.4716.31 15.23 14.43 13.89 13.71 14.49 15.94 17.70 20.00 这一数列。
这一串数字就是将以上信号数字化的结果。
看吧,我们确实用数字记录了事物。
在以上的范例中,我们的采样频率是 100Hz(1/0.01 秒 ) 。
其实电脑中的 .WAV 档的内容就是类似这个样子,文件头中记录了采样频率和可容许最大记录振幅,后面就是一连串表示振幅大小的数字,有正有负。
常见CD唱盘是以PCM格式记录,而它的采样频率 (Sample R ate) 是 44100Hz ,振幅采样精度/数位是 16Bits ,也就是说振幅最小可达 -32768(-2^16/2) ,最大可达 +32767(2^16/2-1) 。
CD唱盘是以螺旋状由内到外储存资料,可以存储7 4分钟的音乐。
CD唱盘的规格为什么是 44.1kHz、16Bits呢?关于 44.1kHz 这个数字的选取分为两个层面。
首先人耳的聆听范围是 20Hz 到 20kHz ,根据 Nyquist s ,理论上只要用 40kHz 以上的采样频率就可以完整记录 20kHz 以下的信号。
那么为什么要用44.1kHz 这个数字呢?那是因为在 CD 发明前硬盘还很贵,所以主要将数字音频信号储存媒体是录像带,用黑白来记录 0 与 1 。
而当时的录像带格式为每秒 30 张,而一张图又可以分为 490 条线,每一条线又可以储存三个取样信号,因此每秒有 30*4 90*3=44100 个取样点,而为了研发的方便, CD唱盘也继承了这个规格,这就是 44.1 kHz 的由来。
在这里我们可以发现无论使用多么高的采样精度/数位,记录的数字跟实际的信号大小总是有误差,因此数字化无法完全记录原始信号。
我们称这个数字化造成失真称为量化失真。
数字化的最大好处是资料传输与保存的不易失真。
记录的资料只要数字大小不改变,记录的资料内容就不会改变。
如果我们用传统类比的方式记录以上信号,例如使用录音带表面的磁场强度来表达振幅大小,我们在复制资料时,无论电路设计多么严谨,总是无法避免杂讯的介入。
这些杂讯会变成复制后资料的一部份,造成失真,且复制越多次信噪比 ( 信号大小与噪音大小的比值 ) 会越来越低,资料的细节也越来越少。
如果多次复制过录音带,对以上的经验应该不陌生。
在数字化的世界里,这串数字转换为二进制,以电压的高低来判读1与0,还可以加上各种检查码,使得出错机率很低,因此在一般的情况下无论复制多少次,资料的内容都是相同,达到不失真的目的。
那么,数字化的资料如何转换成原来的音频信号呢?在计算机的声卡中一块芯片叫做 DAC(Digital to Analog Converter) ,中文称数模转换器。
DAC的功能如其名是把数字信号转换回模拟信号。
我们可以把DAC想像成 16 个小电阻,各个电阻值是以二的倍数增大。
当 DAC 接受到来自计算机中的二进制 PCM 信号,遇到 0 时相对应的电阻就开启,遇到 1 相对应的电阻不作用,如此每一批 16Bits 数字信号都可以转换回相对应的电压大小。
我们可以想像这个电压大小看起来似乎会像阶梯一样一格一格,跟原来平滑的信号有些差异,因此再输出前还要通过一个低通滤波器,将高次谐波滤除,这样声音就会变得比较平滑了。
从前面的内容可以看出,音频数字化就是将模拟的(连续的)声音波形数字化(离散化),以便利用数字计算机进行处理的过程,主要包参数括采样频率(Sample Rate)和采样数位/采样精度(Quantizing,也称量化级)两个方面,这二者决定了数字化音频的质量。
采样频率是对声音波形每秒钟进采样的次数。
根据这种采样方法,采样频率是能够再现声音频率的一倍。
人耳听觉的频率上限在2OkHz左右,为了保证声音不失真,采样频率应在4OkHz左右。
经常使用的采样频率有11.025kHz、22.05kHz和44.lkHz等。
采样频率越高,声音失真越小、音频数据量越大。
采样数位是每个采样点的振幅动态响应数据范围,经常采用的有8位、12位和16位。
例如,8位量化级表示每个采样点可以表示256个(0-255)不同量化值,而16位量化级则可表示65536个不同量化值。
采样量化位数越高音质越好,数据量也越大。
反映音频数字化质量的另一个因素是通道(或声道)个数。
记录声音时,如果每次生成一个声波数据,称为单声道;每次生成二个声波数据,称为立体声(双声道),立体声更能反映人的听觉感受。
除了上述因素外,数字化音频的质量还受其它一些因素(如扬声器质量,麦克风优劣,计算机声卡A/D与D/A(模/数、数/模)转换芯片品质,各个设备连接线屏蔽效果好坏等)的影响。
综上所述,声音数字化的采样频率和量化级越高,结果越接近原始声音,但记录数字声音所需存储空间也随之增加。
可以用下面的公式估算声音数字化后每秒所需的存储量(假定不经压缩):存储量=(采样频率*采样数位)/8(字节数)若采用双声道录音,存储量再增加一倍。
例如,数字激光唱盘(CD-DA,红皮书标准)的标准采样频率为44.lkHz,采样数位为16位,立体声,可以几乎无失真地播出频率高达22kHz的声音,这也是人类所能听到的最高频率声音。
激光唱盘一分钟音乐需要的存储量为:44.1*1000*l6*2*60/8=10,584,000(字节)=10.584MBytes这个数值就是微软Windows系统中WAVE(.WAV)声音文件在硬盘中所占磁盘空间的存储量。
由MICROSOFT公司开发的WAV声音文件格式,是如今计算机中最为常见的声音文件类型之一,它符合RIFF文件规范,用于保存WINDOWS平台的音频信息资源,被WI NDOWS平台机器应用程序所广泛支持。
另外,WAVE格式支持MSADPCM、CCIPTALAW、CC IPT-LAW和其他压缩算法,支持多种音频位数,采样频率和声道,但其缺点是文件体积较大,所以不适合长时间记录。
因此,才会出现各种音频压缩编/解码技术的出现,例如,MP3,RM,WMA,VQF,ASF等等它们各自有自己的应用领域,并且不断在竞争中求得发展。
WAVE、MIDI、MP3、RM常见音频格式简介WAVE--WINDOWS系统最基本音频格式---*.wav1、占用巨大硬盘空间,音质最好,支持音乐与语音2、通常采样使用44KHZ采样/秒,16位/采样,立体声,双声道,CD音质3、一分钟音乐占用大约10M硬盘空间,56K调制解调器需要30分钟才能完成网络传送MIDI--电子合成音乐---*.mid1、与WAVE格式截然不同,只有音乐,没有语音2、使用音色库回放,有软硬波表之分,3、十分节省磁盘空间,但是音质回放对声卡依赖较大4、无法使用Total Recorder录制mid音乐5、可以使用Wingroove软波表或其它软件转为waveMP3--最流行音频压缩格式---*.mp31、节省硬盘空间,有损压缩,无法复原2、音质与不同压缩编码软件有关3、音乐与语音,可以使用各种采样比率RM--网络流媒体压缩格式---*.rm/*.ra1、节省磁盘空间,有损压缩,无法复原2、在目前比较窄的网络带宽下,与Real Server服务器配合,使用Real Player 在客户端比较流畅地播放音视频媒体其它还有:1、微软的WMA编码--*.wma2、微软的ASF流媒体编码--*.asf3、Yamaha的VQF编码--*.vqf。