AWS_AMI导入导出实例
- 格式:pdf
- 大小:335.92 KB
- 文档页数:7

oracle中imp命令详解Oracle的导入实用程序(Importutility)允许从数据库提取数据,并且将数据写入操作系统文件。
imp使用的基本格式:imp [username[/password[@service]]],以下例举imp常用用法。
1. 获取帮助imp help=y2. 导入一个完整数据库imp system/manager file=d:\daochu.dmp log=d:\daochu.log full=y ignore=y3. 导入一个或一组指定用户所属的全部表、索引和其他对象imp system/manager file=seapark log=seapark fromuser=seapark impsystem/manager file=seapark log=seapark fromuser=(seapark,amy,amyc,harold)4. 将一个用户所属的数据导入另一个用户imp system/manager file=tank log=tank fromuser=seapark touser=seapark_copy imp system/manager file=tank log=tank fromuser=(seapark,amy) touser=(seapark1,amy1)5. 导入一个表imp system/manager file=tank log=tank fromuser=seapark TABLES=(a,b)6. 从多个文件导入imp system/manager file=(paycheck_1,paycheck_2,paycheck_3,paycheck_4)log=paycheck, filesize=1G full=y7. 使用参数文件imp system/manager parfile=bible_tables.parbible_tables.par参数文件:#Import the sample tables used for the Oracle8i Database Administrator's Bible. fromuser=seapark touser=seapark_copy file=seapark log=seapark_import8. 增量导入imp system./manager inctype= RECTORE FULL=Y FILE=A Oracle imp/expC:Documentsand Settingsadministrator>exp help=yExport: Release 9.2.0.1.0 - Production on 星期三 7月 28 17:04:43 2004Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved. 通过输入 EXP命令和用户名/口令,您可以后接用户名/口令的命令:例程: EXPSCOTT/TIGER或者,您也可以通过输入跟有各种参数的 EXP命令来控制“导出”按照不同参数。

使用O RACLE D ATA P UMP 将ORACLE 数据库导入到A MAZON RDS数据库Author:Creation Date: 20-12, 2017Last Updated: 20-12, 2017Control Number:Version: 1Approvals:Project ManagerDocument Control Change RecordReviewersDistribution目录使用O RACLE D ATA P UMP 将ORACLE数据库导入到A MAZON RDS数据库 (1)Document Control (2)目录 (3)前言 (3)1具体步骤 (3)2说明 (8)前言在实施上汽拖内项目时,客户要求正式环境数据库需部署到AWS(亚马逊云服务器)中,我们就需要将开发环境的oracle数据库迁移到Amazon Relational Database Service (Amazon RDS)上,Amazon RDS可以托管MySQL、MariaDB、PostgreSQL、Oracle、Microsoft SQL Server等数据库,本次Amazon RDS对应安装的也是oracle 数据库。
1具体步骤createtablespacehecprod;[表空间create tablespace hecprod;创建表空间后RDSdbfcreateuserhecprodidentifiedbyhecproddefaulttablespacehecprod ; grantdbatohecprod ;[户DECLARE hdnlNUMBER ; BEGINhdnl :=DBMS_DATAPUMP.OPEN (operation =>'EXPORT', job_mode =>'SCHEMA', job_name =>null );DBMS_DATAPUMP.ADD_FILE (handle =>hdnl , filename =>'expdp_tndev20171218.dmp', directory =>'DATA_PUMP_DIR',filetype =>dbms_datapump.ku$_file_type_dump_file );[DBMS_DATAPUMP 储文件END ;select *fromdba_directoriesdwhered.DIRECTORY_NAME ='DATA_PUMP_DIR';[件用查出转储文件所在目录directory_path通过到转储文件大小在不断增加Ping 查出客户提供的数据库host 172.32.11.99jvtfvjy 客户提供的址createdatabaselinkto_rdsconnecttohecprodidentifiedbyhecprodusing '(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST =172.32.11.99)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = HECORCL)))'; --测试dblinkselect *fromv$instance @to_rds ;[dblink以便将开发环境转储文件通过环境BEGINDBMS_FILE_TRANSFER.PUT_FILE (source_directory_object =>'DATA_PUMP_DIR', source_file_name =>'expdp_tndev20171218.dmp', destination_directory_object =>'DATA_PUMP_DIR',destination_file_name =>'expdp_tndev20171218copy.dmp', destination_database =>'to_rds' ); END ;[DBMS_FILE_TRANSFER 将导出的转储文件复制到目标数据库实例此部分执行时间受网络传输速度和文件读写速度影响,可能时间会很长bymtime;DECLAREhdnlNUMBER;BEGINhdnl:=DBMS_DATAPUMP.OPEN(operation=>'IMPORT',job_mode=>'SCHEMA',job_name=>null);DBMS_DATAPUMP.ADD_FILE(handle=>hdnl,filename=>'expdp_tndev20171218copy.dmp',directory=>'DATA_PUMP_DIR',filetype=>dbms_datapump.ku$_file_type_dump_file);dbms_datapump.metadata_remap(hdnl,'REMAP_SCHEMA','TNDEV','HECPROD');dbms_datapump.metadata_remap(hdnl,'REMAP_TABLESPACE','TNDEV','HECPROD' );DBMS_DATAPUMP.START_JOB(hdnl);END;/[正式环境创建的用户在目标数据库实例上使用DBMS_DATAPUMP据文件selectcount(*)fromuser_objects;[句执行成功后,户对象可以发现数量在不断增加。

Glance组件详解⼀、Glance组件介绍1、概念Glance是OpenStack镜像服务,⽤来注册、登陆和检索虚拟机镜像。
Glance服务提供了⼀个REST API,使你能够查询虚拟机镜像元数据和检索的实际镜像。
通过镜像服务提供的虚拟机镜像可以存储在不同的位置,从简单的⽂件系统对象存储到类似OpenStack对象存储系统。
提供了对虚拟机部署的时候所能提供的镜像的管理,包含镜像的导⼊,格式,以及制作相应的模板。
2、镜像⽣命周期1. Queued:初始化镜像状态,在镜像⽂件刚刚被创建,在glance数据库中已经保存了镜像标⽰符,但还没有上传⾄glance中,此时的glance对镜像数据没有任何描述,其存储空间为0。
2. Saving:镜像的原始数据在上传中的⼀种过度状态,它产⽣在镜像数据上传⾄glance的过程中,⼀般来讲,glance收到⼀个image请求后,才将镜像上传给glance。
3. Active:镜像成功上传完毕以后的⼀种状态,它表明glance中可⽤的镜像。
4. Killed:镜像上传失败或者镜像⽂件不可读的情况下,glance将镜像状态设置成Killed。
5. Deleted:镜像⽂件马上会被删除,只是当前glance这种仍然保留该镜像⽂件的相关信息和原始镜像数据。
6. Pending_delete:镜像⽂件马上会被删除,镜像⽂件不能恢复。
3、磁盘格式1. RAW:RAW即常说的裸格式,它其实就是没有格式,最⼤的特点就是简单,数据写⼊什么就是什么,不做任何修饰,所以再性能⽅⾯很不错,甚⾄不需要启动这个镜像的虚拟机,只需要⽂件挂载即可直接读写内部数据。
并且由于RAW格式简单,因此RAW和其他格式之间的转换也更容易。
在KVM的虚拟化环境下,有很多使⽤RAW格式的虚拟机。
2. QCOW2:它是QEMU的CopyOn Write特性的磁盘格式,主要特性是磁盘⽂件⼤⼩可以随着数据的增长⽽增长。

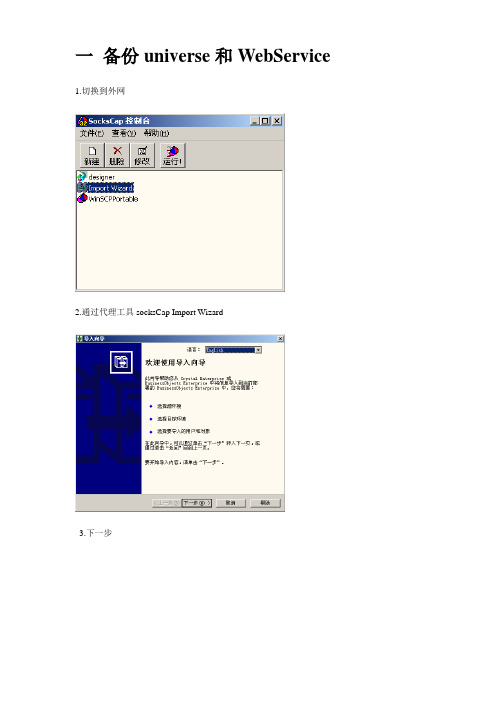
一备份universe和WebService 1.切换到外网
2.通过代理工具socksCap Import Wizard
3.下一步
Cms名称改为:
下一步
在“目标”选择存档资源(BIAR) 文件
导出biar文件
命名为20091010.biar 单击下一步
全部清楚之后,选择“导入应用程序文件夹和对象”导入universe 两项
下一步
单击“全选”之后下一步
是否要导出webi , 若无全部清楚, 下一步
导出webservice , 选择QaaWS Folder
选择第三项可以选择具体的Universe
备注: 如果有Universe名称和文件夹名称相同,选择全选会忽略相同名称Universe的选择
下一步
单击“完成”
单击“完成”
二导入universe和WebService 切换导内网
下一步
在来源中选择在存档资源(biar)文件
选择已备份文件
跟导出一样, 先全部清楚”导出应用程序文件夹和对象”及“导出Universe”
全选,下一步
关于webi文件不用导出, 直接单击下一步
选择QaaWs Folder ,下一步
选择第三项,导入选择对话框,下一步
全选别忘了相同名称的Universe 如: 多维分析
直接下一步
完成over。

AmazonS3功能介绍⼀ .Amazon S3介绍Amazon Simple Storage Service (Amazon S3) 是⼀种对象存储,它具有简单的 Web 服务接⼝,可⽤于在 Web 上的任何位置存储和检索任意数量的数据。
它能够提供 99.999999999% 的持久性,并且可以在全球⼤规模传递数万亿对象。
客户使⽤ S3 作为云原⽣应⽤程序的主要存储;作为分析的批量存储库或“”;作为以及灾难恢复的⽬标;并将其与配合使⽤。
使⽤ Amazon 的选项,客户可以轻松地将⼤量数据移⼊或移出 Amazon S3。
数据在存储到 S3 中之后,会⾃动采⽤成本更低、存储期限更长的类 (如 S3 Standard – Infrequent Access 和 ) 进⾏存档。
⼆.Java S3 Example准备⼯作:1.导⼊依赖包<dependency><groupId>com.amazonaws</groupId><artifactId>aws-java-sdk</artifactId><version>1.9.2</version></dependency>2.在s3服务中创建⽤户,获取⽤户的Access key和Secret Access Key,使⽤这个作为凭证连接s33.在s3服务中配置AWSConnector和AmazonS3FullAccess的连接权限。
可以通过这个配置,在访问的时候进⾏authenticate验证。
s3 api简单操作:1.创建凭证AWSCredentials credentials = new BasicAWSCredentials("YourAccessKeyID", "YourSecretAccessKey");2.创建S3 ClientAmazonS3 s3client = new AmazonS3Client(credentials);3.创建BucketString bucketName = "javatutorial-net-example-bucket";s3client.createBucket(bucketName);4.获取s3 Bucket的listfor (Bucket bucket : s3client.listBuckets()) {System.out.println(" - " + bucket.getName());}5.在s3 Bucket中创建⽂件public static void createFolder(String bucketName, String folderName, AmazonS3 client) {// create meta-data for your folder and set content-length to 0ObjectMetadata metadata = new ObjectMetadata();metadata.setContentLength(0);// create empty contentInputStream emptyContent = new ByteArrayInputStream(new byte[0]);// create a PutObjectRequest passing the folder name suffixed by /PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName,folderName + SUFFIX, emptyContent, metadata);// send request to S3 to create folderclient.putObject(putObjectRequest);}6.上传⽂件String fileName = folderName + SUFFIX + "testvideo.mp4";s3client.putObject(new PutObjectRequest(bucketName, fileName,new File("C:\\Users\\user\\Desktop\\testvideo.mp4")));7.删除Buckets3client.deleteBucket(bucketName);8.删除⽂件s3client.deleteObject(bucketName, fileName);完整实例import java.io.ByteArrayInputStream;import java.io.File;import java.io.InputStream;import java.util.List;import com.amazonaws.auth.AWSCredentials;import com.amazonaws.auth.BasicAWSCredentials;import com.amazonaws.services.s3.AmazonS3;import com.amazonaws.services.s3.AmazonS3Client;import com.amazonaws.services.s3.model.Bucket;import com.amazonaws.services.s3.model.CannedAccessControlList;import com.amazonaws.services.s3.model.ObjectMetadata;import com.amazonaws.services.s3.model.PutObjectRequest;import com.amazonaws.services.s3.model.S3ObjectSummary;public class AmazonS3Example {private static final String SUFFIX = "/";public static void main(String[] args) {// credentials object identifying user for authentication// user must have AWSConnector and AmazonS3FullAccess for// this example to workAWSCredentials credentials = new BasicAWSCredentials("YourAccessKeyID","YourSecretAccessKey");// create a client connection based on credentialsAmazonS3 s3client = new AmazonS3Client(credentials);// create bucket - name must be unique for all S3 usersString bucketName = "javatutorial-net-example-bucket";s3client.createBucket(bucketName);// list bucketsfor (Bucket bucket : s3client.listBuckets()) {System.out.println(" - " + bucket.getName());}// create folder into bucketString folderName = "testfolder";createFolder(bucketName, folderName, s3client);// upload file to folder and set it to publicString fileName = folderName + SUFFIX + "testvideo.mp4";s3client.putObject(new PutObjectRequest(bucketName, fileName,new File("C:\\Users\\user\\Desktop\\testvideo.mp4")).withCannedAcl(CannedAccessControlList.PublicRead));deleteFolder(bucketName, folderName, s3client);// deletes buckets3client.deleteBucket(bucketName);}public static void createFolder(String bucketName, String folderName, AmazonS3 client) { // create meta-data for your folder and set content-length to 0ObjectMetadata metadata = new ObjectMetadata();metadata.setContentLength(0);// create empty contentInputStream emptyContent = new ByteArrayInputStream(new byte[0]);// create a PutObjectRequest passing the folder name suffixed by /PutObjectRequest putObjectRequest = new PutObjectRequest(bucketName,folderName + SUFFIX, emptyContent, metadata);// send request to S3 to create folderclient.putObject(putObjectRequest);}/*** This method first deletes all the files in given folder and than the* folder itself*/public static void deleteFolder(String bucketName, String folderName, AmazonS3 client) { List fileList =client.listObjects(bucketName, folderName).getObjectSummaries();for (S3ObjectSummary file : fileList) {client.deleteObject(bucketName, file.getKey());}client.deleteObject(bucketName, folderName);}}参考:python版的s3 api:。
Atoll-LTE 仿真说明书目录1新建工程 (3)2导入地图 (4)3设置投影方式和投影带 (6)4设置传播模型 (7)4.1LTE 频率范围介绍 (7)4.2传播模型介绍 (7)5网络信息导入 (11)5.1导入 Sites 表 (11)5.2导入 Antennas 数据 (12)5.3Transmitters 导入 (13)5.4Cells 导入 (14)5.5添加基站 (15)5.5.1基站模板设置 (15)5.5.2逐个添加基站 (18)5.5.3添加一组基站 (19)5.6MIMO 的设置 (20)5.7Bearers 的设置 (24)6绘制 polygon (26)7设置 LTE PARAMETERS (28)8设置标准差和穿透损耗 . (33)9给 transmitter 赋传播模型 (34)10传播损耗预算 (38)11分配邻小区 (39)11.1手动分配功能 (39)11.2自动分配邻小区 (40)12分配频率 (43)12.1手动分配频率 (43)12.2自动分配频率 (43)13分配小区ID (47)13.1手动分配小区 ID (47)13.2自动分配小区 ID (47)14建立话务地图 (50)15用户列表 (54)15.1新建用户列表 (54)15.2计算用户列表 (57)16仿真 (60)17网络性能预测 (63)17.1生成仿真覆盖图 (63)17.2仿真统计性报表查看 (64)1新建工程打开 Atoll 程序后,在下图所示的界面中点击按钮,或选择菜单File->Open 。
Atoll 打开一个空白的LTE 模版工程。
工程模板中已经包含了缺省提供的天线数据库。
图1-1建立工程2导入地图把clutter, height 和 vector 文件夹下面的 index 文件分别导入 ,次序不限 .导入的时候注意选择对应的数据种类, 如下图所示 ,导入 clutter 的时候数据种类选择”clutterclasses”,导入 height 时数据种类选择”Altitudes”,导入vector的时候选择”vectors”.图中的 embed 选项表示是否把地图嵌入工程 ,如果嵌入 ,工程无论转移到哪台机器上打开都不需要地图 .图2-1 Data type其中 ,clutter 导入后 ,双击 Geo 下面的“clutter classes”项 , 打开 Clutter classesproperties 对话框,在其中“Description ”页面下点击“ Refresh”按钮 ,这样可以滤除掉地图中实际上没有的地物项。
AWS 入门AWS 入门Copyright © 2017 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon.Table of ContentsAWS 入门 (1)AWS 可以用来做什么? (1)如何入门? (1)如何访问 AWS? (1)定价 (2)AWS 概述 (3)地区和可用区域 (3)安全性 (4)AWS 产品类别 (4)计算与联网服务 (5)关键服务 (5)主要概念 (5)架构 (8)文档 (8)存储和内容传输服务 (9)关键服务 (9)主要概念 (9)使用方案 (11)文档 (11)安全和身份服务 (12)关键服务 (12)主要概念 (12)文档 (12)数据库服务 (12)关键服务 (12)主要概念 (13)使用方案 (14)文档 (14)分析服务 (14)关键服务 (15)文档 (15)应用程序服务 (15)关键服务 (15)主要概念 (16)文档 (17)管理工具 (17)关键工具 (17)主要概念 (18)文档 (18)AWS 教程 (20)运行虚拟服务器 (20)存储文件 (20)共享数字媒体 (21)部署网站 (21)托管网站 (Linux) (21)托管网站 (Windows) (21)运行数据库 (22)分析您的数据 (22)相关资源 (23)AWS 可以用来做什么?AWS 入门Amazon Web Services (AWS) 按需提供云中的计算资源和服务,并采用即付即用的定价模式。
云计算标准及性能评估云计算标准及性能评估从应用运行的角度来讲,云计算的性能就是网络性能、应用性能以及云计算基础架构性能的总和。
云供应商只能对最后一个因素负责,而不能对前两者负责。
因此,用户在衡量供应商云服务质量时必须遵循一个合适的标准。
本文介绍制定云计算服务标准必要性,为了满足这一标准而需要满足的配置,以及云计算服务等级(SLA)的制定和遵从问题。
云计算标准在部署和扩展云计算方面遵循标准非常重要,软件服务会从所有标准化开发中受益,因为它们能够确保应用程序间的互操作性良好,不过遗憾的是想要扩展功能,同样会受到供应商的锁定和限制。
云计算标准使部署和扩展服务更自由云计算性能对于希望削减硬件投资成本的公司来说,云计算是首当其冲的选择。
其收付自助型模式可应用于诸如Netflix和等在线业务,相关开发人员正在致力于这方面的测试和开发。
云计算所面临的性能问题如何评估云计算性能?云计算SLA在网络服务中服务等级协议(SLA)是很常见的,它们常常被用来表述网络服务的限制因素——通常被称为“QoS”(服务质量)。
但是,在云计算或平台服务中,我们就很难找到可用的指标来作为SLA谈判的标准。
关注云计算中的服务等级协议(SLA)满足云计算的性能标准和SLA云计算标准使部署和扩展服务更自由目前,已经有一系列机构在致力于研究软件即服务(SaaS)中服务之间的互操作,如Internet标准化团体(W3C)负责管理XML和WSDL等标准,OASIS负责定义WS-*标准过程,这些积极的举措有助于减少服务提供商及其客户的风险。
只要遵循这些标准,应用程序就不会被限死在一个特定的技术下,标准化促进了软件即服务模式的发展。
如果每个服务提供商都制定自己的标准,那用户也就会受限于这个提供商采用的技术。
反之,如果每个服务提供商都遵循统一的标准,那服务之间的互通就没有问题,购买或托管服务的用户也不会受限于一个单一的提供商。
一旦软件跨过服务这道屏障成为服务,应用程序间互操作问题就应备受重视。