MSSQL数据库各种语句学习资料
- 格式:doc
- 大小:76.50 KB
- 文档页数:17

mssql 查询语法
MSSQL(Microsoft SQL Server)是一种关系型数据库管理系统,其查询语法与标准SQL(Structured Query Language)类似。
以下是常用的MSSQL查询语法:
1. SELECT语句:用于从表中检索数据。
示例:SELECT 列名1, 列名2 FROM 表名WHERE 条件;
2. INSERT语句:用于向表中插入新的行数据。
示例:INSERT INTO 表名(列名1, 列名2) VALUES (值1, 值
2);
3. UPDATE语句:用于更新表中现有行的数据。
示例:UPDATE 表名SET 列名1 = 新值1, 列名2 = 新值2 WHERE 条件;
4. DELETE语句:用于从表中删除行数据。
示例:DELETE FROM 表名WHERE 条件;
5. JOIN语句:用于合并多个表的数据。
示例:SELECT 列名FROM 表名1 INNER JOIN 表名2 ON 表名1.列名= 表名2.列名;
6. GROUP BY语句:用于对结果进行分组统计。
示例:SELECT 列名, COUNT(*) FROM 表名GROUP BY 列名;
7. ORDER BY语句:用于对结果进行排序。
示例:SELECT 列名FROM 表名ORDER BY 列名
ASC/DESC;
8. WHERE语句:用于筛选满足条件的数据。
示例:SELECT 列名FROM 表名WHERE 条件;
以上是一些常用的MSSQL查询语法,希望对您有帮助。
如果有更具体的问题,请提供详细信息以便给出更精确的答案。

mssqlserver insert into 语句的三种写法MSSQLServer是一种常用的关系型数据库管理系统,它支持使用SQL语言进行数据的增删改查操作。
其中,insert into语句是用于向数据库表中插入新记录的语句。
本文将深入探讨MSSQLServer中insert into语句的三种写法,分别是使用完整列名、省略列名和使用子查询。
单表插入数据是数据库应用中最常见的操作之一,它允许我们将新的数据记录插入到已存在的表格中。
无论是新建的表格还是已经存在的表格,我们都可以使用insert into语句来实现插入操作。
下面,我们将详细介绍这三种写法。
# 第一种写法:使用完整列名第一种常见的insert into语句写法是使用完整列名。
这种写法适用于当我们要插入的数据与表格的列一一对应,并且按照表格中列的顺序依次插入。
示例:INSERT INTO 表名(列1, 列2, 列3, ...)VALUES (值1, 值2, 值3, ...)在上述示例中,我们首先指定了要插入数据的表名,然后在括号中列出了表中的所有列名。
紧接着,在VALUES关键字后面用逗号分隔列值。
这里的列值应与列名的顺序相对应。
例如,我们有一个名为"customers"的表,它包含"customer_id"、"customer_name"和"address"三个列。
如果我们要向该表中插入新的客户信息,可以使用以下命令:INSERT INTO customers (customer_id, customer_name, address) VALUES (1, 'John Smith', '123 Main St')这样就向表"customers"中插入了一条新纪录,该记录的"customer_id"为1,"customer_name"为'John Smith',"address"为'123 Main St'。
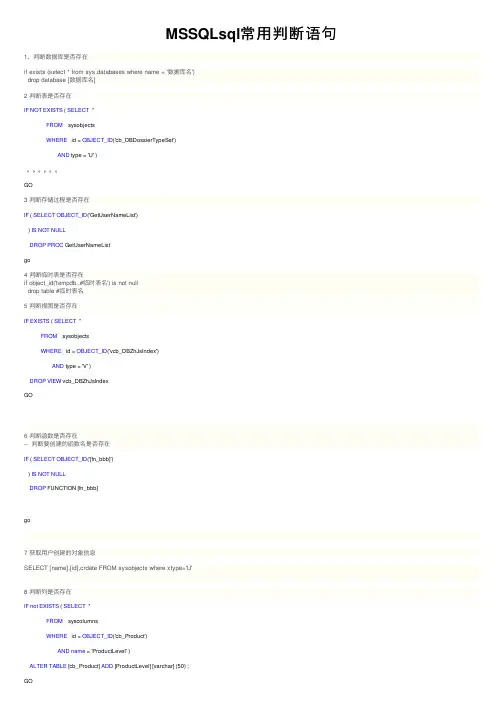
MSSQLsql常⽤判断语句1、判断数据库是否存在if exists (select * from sys.databases where name = '数据库名')drop database [数据库名]2 判断表是否存在IF NOT EXISTS ( SELECT *FROM sysobjectsWHERE id = OBJECT_ID('cb_DBDossierTypeSet')AND type = 'U' )。
GO3 判断存储过程是否存在IF ( SELECT OBJECT_ID('GetUserNameList')) IS NOT NULLDROP PROC GetUserNameListgo4 判断临时表是否存在if object_id('tempdb..#临时表名') is not nulldrop table #临时表名5 判断视图是否存在IF EXISTS ( SELECT *FROM sysobjectsWHERE id = OBJECT_ID('vcb_DBZhJsIndex')AND type = 'V' )DROP VIEW vcb_DBZhJsIndexGO6 判断函数是否存在-- 判断要创建的函数名是否存在IF ( SELECT OBJECT_ID('[fn_bbb]')) IS NOT NULLDROP FUNCTION [fn_bbb]go7 获取⽤户创建的对象信息SELECT [name],[id],crdate FROM sysobjects where xtype='U'8 判断列是否存在IF not EXISTS ( SELECT *FROM syscolumnsWHERE id = OBJECT_ID('cb_Product')AND name = 'ProductLevel' )ALTER TABLE [cb_Product] ADD [ProductLevel] [varchar] (50) ;GO9 判断列是否⾃增列if columnproperty(object_id('table'),'col','IsIdentity')=1print '⾃增列'elseprint '不是⾃增列'SELECT * FROM sys.columns WHERE object_id=OBJECT_ID('表名') AND is_identity=110 判断表中是否存在索引if exists(select * from sysindexes where id=object_id('表名') and name='索引名')print '存在'elseprint '不存在'11 查看数据库中对象SELECT * FROM sys.sysobjects WHERE name='对象名' SELECT * FROM sys.sysobjects WHERE name='对象名'。

一,SQL复习1,SQL语句分为两类:DDL(Data Definition Language)和DML(Dat Manipulation Languge,数据操作语言)。
前者主要是定义数据逻辑结构,包括定义表、视图和索引;DML 主要是对数据库进行查询和更新操作。
2,Create Table(DDL):Create Table tabName(colName1 colType1 [else],colName2 colType2 [else],...,colNamen colTypen [else]);例如:Cteate Table pJoiner(pno char(6) not null,eno char(6) nut null);char int varchar等等都是用来定义列数据类型的保留字,其中varchar表示可变字符类型。
3,Select <col1>,<col2>,...,<coln>From <tab1>,<tab2>,...,<tabm>[Where<条件>]条件中的子查询:Where Not Exists(Select * From tab2 Where col1=col2)//当查询结果为空时,条件为真。
4,INSERT INTO <tab1> VALUES(<col1>, ...<coln>)5,DELETE FROM <tab1> [WHERE<条件>]6,UPDATE <tab1>SET <tab1>=<vlu1><tabn>=<vlun>[WHERE<条件>]例如:Update exployeeSet age=27Where name=''赵一''二,JDBC 主要接口:java.sql.DriverManager类用于处理驱动程序的调入并且对新的数据库连接提供支持。

数据库常用sql语句有哪些数据库常用sql语句有哪些结构化查询语言简称SQL,是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
下面是店铺整理的数据库常用sql语句有哪些,欢迎大家分享。
数据库常用sql语句Student(S#,Sname,Sage,Ssex) 学生表Course(C#,Cname,T#) 课程表SC(S#,C#,score) 成绩表Teacher(T#,Tname) 教师表问题:1、查询“001”课程比“002”课程成绩高的所有学生的学号;select a.S# from (select s#,score from SC where C#='001') a,(select s#,scorefrom SC where C#='002') bwhere a.score>b.score and a.s#=b.s#;2、查询平均成绩大于60分的同学的学号和平均成绩;select S#,avg(score)from scgroup by S# having avg(score) >60;3、查询所有同学的学号、姓名、选课数、总成绩;select Student.S#,Student.Sname,count(SC.C#),sum(score)from Student left Outer join SC on Student.S#=SC.S#group by Student.S#,Sname4、查询姓“李”的老师的个数;select count(distinct(Tname))from Teacherwhere Tname like '李%';5、查询没学过“叶平”老师课的同学的学号、姓名;select Student.S#,Student.Snamefrom Studentwhere S# not in (select distinct( SC.S#) from SC,Course,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平');6、查询学过“001”并且也学过编号“002”课程的同学的学号、姓名;select Student.S#,Student.Sname from Student,SC where Student.S#=SC.S# and SC.C#='001'and exists( Select * from SC as SC_2 where SC_2.S#=SC.S# and SC_2.C#='002');7、查询学过“叶平”老师所教的所有课的同学的学号、姓名;select S#,Snamefrom Studentwhere S# in (select S# from SC ,Course ,Teacher where SC.C#=Course.C# and Teacher.T#=Course.T# and Teacher.Tname='叶平' group by S# having count(SC.C#)=(select count(C#) from Course,Teacher where Teacher.T#=Course.T# and Tname='叶平'));8、查询课程编号“002”的成绩比课程编号“001”课程低的所有同学的学号、姓名;Select S#,Sname from (select Student.S#,Student.Sname,score ,(select score from SC SC_2 where SC_2.S#=Student.S# and SC_2.C#='002') score2 from Student,SC where Student.S#=SC.S# and C#='001') S_2 where score2<score;9、查询所有课程成绩小于60分的同学的学号、姓名;select S#,Snamefrom Studentwhere S# not in (select Student.S# from Student,SC whereS.S#=SC.S# and score>60);10、查询没有学全所有课的同学的学号、姓名;select Student.S#,Student.Snamefrom Student,SCwhere Student.S#=SC.S# group by Student.S#,Student.Sname having count(C#) <(select count(C#) from Course);11、查询至少有一门课与学号为“1001”的同学所学相同的同学的学号和姓名;select S#,Sname from Student,SC where Student.S#=SC.S# and C# in select C# from SC where S#='1001';12、查询至少学过学号为“001”同学所有一门课的其他同学学号和姓名;select distinct SC.S#,Snamefrom Student,SCwhere Student.S#=SC.S# and C# in (select C# from SC where S#='001');13、把“SC”表中“叶平”老师教的课的成绩都更改为此课程的平均成绩;SC set score=(select avg(SC_2.score)from SC SC_2where SC_2.C#=SC.C# ) from Course,Teacher where Course.C#=SC.C# and Course.T#=Teacher.T# and Teacher.Tname='叶平');14、查询和“1002”号的同学学习的课程完全相同的其他同学学号和姓名;select S# from SC where C# in (select C# from SC where S#='1002')group by S# having count(*)=(select count(*) from SC where S#='1002');15、删除学习“叶平”老师课的SC表记录;Delect SCfrom course ,Teacherwhere Course.C#=SC.C# and Course.T#= Teacher.T# and Tname='叶平';16、向SC表中插入一些记录,这些记录要求符合以下条件:没有上过编号“003”课程的同学学号、2、号课的平均成绩;Insert SC select S#,'002',(Select avg(score)from SC where C#='002') from Student where S# not in (Select S# from SC where C#='002');17、按平均成绩从高到低显示所有学生的“数据库”、“企业管理”、“英语”三门的课程成绩,按如下形式显示:学生ID,,数据库,企业管理,英语,有效课程数,有效平均分SELECT S# as 学生ID,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='004') AS 数据库,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='001') AS 企业管理,(SELECT score FROM SC WHERE SC.S#=t.S# AND C#='006') AS 英语,COUNT(*) AS 有效课程数, AVG(t.score) AS 平均成绩FROM SC AS tGROUP BY S#ORDER BY avg(t.score)18、查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分SELECT L.C# As 课程ID,L.score AS 最高分,R.score AS 最低分FROM SC L ,SC AS RWHERE L.C# = R.C# andL.score = (SELECT MAX(IL.score)FROM SC AS IL,Student AS IMWHERE L.C# = IL.C# and IM.S#=IL.S#GROUP BY IL.C#)ANDR.Score = (SELECT MIN(IR.score)FROM SC AS IRWHERE R.C# = IR.C#GROUP BY IR.C#);19、按各科平均成绩从低到高和及格率的百分数从高到低顺序SELECT t.C# AS 课程号,max(ame)AS 课程名,isnull(AVG(score),0) AS 平均成绩,100 * SUM(CASE WHEN isnull(score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*) AS 及格百分数FROM SC T,Coursewhere t.C#=course.C#GROUP BY t.C#ORDER BY 100 * SUM(CASE WHEN isnull(score,0)>=60 THEN 1 ELSE 0 END)/COUNT(*) DESC20、查询如下课程平均成绩和及格率的百分数(用"1行"显示): 企业管理(001),马克思(002),OO&UML (003),数据库(004)SELECT SUM(CASE WHEN C# ='001' THEN score ELSE 0 END)/SUM(CASE C# WHEN '001' THEN 1 ELSE 0 END) AS 企业管理平均分,100 * SUM(CASE WHEN C# = '001' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '001' THEN 1 ELSE 0 END) AS 企业管理及格百分数,SUM(CASE WHEN C# = '002' THEN score ELSE 0END)/SUM(CASE C# WHEN '002' THEN 1 ELSE 0 END) AS 马克思平均分,100 * SUM(CASE WHEN C# = '002' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '002' THEN 1 ELSE 0 END) AS 马克思及格百分数,SUM(CASE WHEN C# = '003' THEN score ELSE 0 END)/SUM(CASE C# WHEN '003' THEN 1 ELSE 0 END) AS UML平均分,100 * SUM(CASE WHEN C# = '003' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '003' THEN 1 ELSE 0 END) AS UML及格百分数,SUM(CASE WHEN C# = '004' THEN score ELSE 0 END)/SUM(CASE C# WHEN '004' THEN 1 ELSE 0 END) AS 数据库平均分,100 * SUM(CASE WHEN C# = '004' AND score >= 60 THEN 1 ELSE 0 END)/SUM(CASE WHEN C# = '004' THEN 1 ELSE 0 END) AS 数据库及格百分数FROM SC21、查询不同老师所教不同课程平均分从高到低显示SELECT max(Z.T#) AS 教师ID,MAX(Z.Tname) AS 教师姓名,C.C# AS 课程ID,MAX(ame) AS 课程名称,AVG(Score) AS 平均成绩FROM SC AS T,Course AS C ,Teacher AS Zwhere T.C#=C.C# and C.T#=Z.T#GROUP BY C.C#ORDER BY AVG(Score) DESC22、查询如下课程成绩第 3 名到第 6 名的学生成绩单:企业管理(001),马克思(002),UML (003),数据库(004)[学生ID],[学生姓名],企业管理,马克思,UML,数据库,平均成绩SELECT DISTINCT top 3SC.S# As 学生学号,Student.Sname AS 学生姓名 ,T1.score AS 企业管理,T2.score AS 马克思,T3.score AS UML,T4.score AS 数据库,ISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0) as 总分FROM Student,SC LEFT JOIN SC AS T1ON SC.S# = T1.S# AND T1.C# = '001'LEFT JOIN SC AS T2ON SC.S# = T2.S# AND T2.C# = '002'LEFT JOIN SC AS T3ON SC.S# = T3.S# AND T3.C# = '003'LEFT JOIN SC AS T4ON SC.S# = T4.S# AND T4.C# = '004'WHERE student.S#=SC.S# andISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0)NOT IN(SELECTDISTINCTTOP 15 WITH TIESISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0)FROM scLEFT JOIN sc AS T1ON sc.S# = T1.S# AND T1.C# = 'k1'LEFT JOIN sc AS T2ON sc.S# = T2.S# AND T2.C# = 'k2'LEFT JOIN sc AS T3ON sc.S# = T3.S# AND T3.C# = 'k3'LEFT JOIN sc AS T4ON sc.S# = T4.S# AND T4.C# = 'k4'ORDER BY ISNULL(T1.score,0) + ISNULL(T2.score,0) + ISNULL(T3.score,0) + ISNULL(T4.score,0) DESC);23、统计列印各科成绩,各分数段人数:课程ID,课程名称,[100-85],[85-70],[70-60],[<60]SELECT SC.C# as 课程ID, Cname as 课程名称,SUM(CASE WHEN score BETWEEN 85 AND 100 THEN 1 ELSE 0 END) AS [100 - 85],SUM(CASE WHEN score BETWEEN 70 AND 85 THEN 1 ELSE 0 END) AS [85 - 70],SUM(CASE WHEN score BETWEEN 60 AND 70 THEN 1 ELSE 0 END) AS [70 - 60],SUM(CASE WHEN score < 60 THEN 1 ELSE 0 END) AS [60 -] FROM SC,Coursewhere SC.C#=Course.C#GROUP BY SC.C#,Cname;24、查询学生平均成绩及其名次SELECT 1+(SELECT COUNT( distinct 平均成绩)FROM (SELECT S#,AVG(score) AS 平均成绩FROM SCGROUP BY S#) AS T1WHERE 平均成绩 > T2.平均成绩) as 名次,S# as 学生学号,平均成绩FROM (SELECT S#,AVG(score) 平均成绩FROM SCGROUP BY S#) AS T2ORDER BY 平均成绩 desc;25、查询各科成绩前三名的记录:(不考虑成绩并列情况)SELECT t1.S# as 学生ID,t1.C# as 课程ID,Score as 分数FROM SC t1WHERE score IN (SELECT TOP 3 scoreFROM SCWHERE t1.C#= C#ORDER BY score DESC)ORDER BY t1.C#;26、查询每门课程被选修的学生数select c#,count(S#) from sc group by C#;27、查询出只选修了一门课程的全部学生的学号和姓名select SC.S#,Student.Sname,count(C#) AS 选课数from SC ,Studentwhere SC.S#=Student.S# group by SC.S# ,Student.Sname having count(C#)=1;28、查询男生、女生人数Select count(Ssex) as 男生人数 from Student group by Ssex having Ssex='男';Select count(Ssex) as 女生人数 from Student group by Ssex having Ssex='女';29、查询姓“张”的学生名单SELECT Sname FROM Student WHERE Sname like '张%';30、查询同名同性学生名单,并统计同名人数select Sname,count(*) from Student group by Sname having count(*)>1;;31、1981年出生的学生名单(注:Student表中Sage列的类型是datetime)select Sname, CONVERT(char (11),DATEPART(year,Sage)) asagefrom studentwhere CONVERT(11),DATEPART(year,Sage))='1981';32、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列Select C#,Avg(score) from SC group by C# order by Avg(score),C# DESC ;33、查询平均成绩大于85的所有学生的学号、姓名和平均成绩select Sname,SC.S# ,avg(score)from Student,SCwhere Student.S#=SC.S# group by SC.S#,Sname having avg(score)>85;34、查询课程名称为“数据库”,且分数低于60的`学生姓名和分数Select Sname,isnull(score,0)from Student,SC,Coursewhere SC.S#=Student.S# and SC.C#=Course.C# and ame='数据库'and score<60;35、查询所有学生的选课情况;SELECT SC.S#,SC.C#,Sname,CnameFROM SC,Student,Coursewhere SC.S#=Student.S# and SC.C#=Course.C# ;36、查询任何一门课程成绩在70分以上的姓名、课程名称和分数;SELECT distinct student.S#,student.Sname,SC.C#,SC.scoreFROM student,ScWHERE SC.score>=70 AND SC.S#=student.S#;37、查询不及格的课程,并按课程号从大到小排列select c# from sc where scor e<60 order by C# ;38、查询课程编号为003且课程成绩在80分以上的学生的学号和姓名;select SC.S#,Student.Sname from SC,Student where SC.S#=Student.S# and Score>80 and C#='003';39、求选了课程的学生人数select count(*) from sc;40、查询选修“叶平”老师所授课程的学生中,成绩最高的学生姓名及其成绩select Student.Sname,scorefrom Student,SC,Course C,Teacherwhere Student.S#=SC.S# and SC.C#=C.C# and C.T#=Teacher.T# and Teacher.Tname='叶平' and SC.score=(select max(score)from SC where C#=C.C# );41、查询各个课程及相应的选修人数select count(*) from sc group by C#;42、查询不同课程成绩相同的学生的学号、课程号、学生成绩select distinct A.S#,B.score from SC A ,SC B whereA.Score=B.Score and A.C# <>B.C# ;43、查询每门功成绩最好的前两名SELECT t1.S# as 学生ID,t1.C# as 课程ID,Score as 分数FROM SC t1WHERE score IN (SELECT TOP 2 scoreFROM SCWHERE t1.C#= C#ORDER BY score DESC)ORDER BY t1.C#;44、统计每门课程的学生选修人数(超过10人的课程才统计)。

SQL数据库基础语法SQL语句的概述SQL语⾔的分类 数据定义语⾔(Data Definition Language)主要⽤于修改、创建和删除数据库对象,其中包括CREATE ALTER DROP语句。
数据查询语⾔(Data Query Language)主要⽤于查询数据库中的数据,其主要是SELECT语句,SELECT语句包括五个⼦句,分别是FROM WHERE HAVING GROUP BY和WITH语句。
数据操作语⾔(Data Manipulation Language)主要⽤于更新数据库⾥数据表中的数据,包括INSERT UODATE DELETE语句。
数据控制语⾔(Data Control Language)主要⽤于授予和回收访问数据库的某种权限。
包括GRANT REVOKE等语句。
事物控制语⾔,主要⽤于数据库对事物的控制,保证数据库中数据的⼀致性,包括COMMIT ROLLBACK语句。
常⽤的数据类型 MYSQL: SQL语句的书写规范 SQL语句中不区分关键字的⼤⼩写 SQL语句中不区分列名和对象名的⼤⼩写 SQL语句对数据库中数据的⼤⼩写敏感 SQL语句中使⽤--注释时,--后⾯⾄少有⼀个空格,多⾏注释⽤/* */ 数据库的创建与删除 (1)数据库的创建: CREATE DATABASE database_name; 在中书写SQL语句时,在SQL语句后⾯都要加上分号 (2)数据库的删除 DROP DATABASE database_name;数据表的创建与更新 数据库中的表 (1)数据记录:在数据表中的每⼀⾏被称为数据记录 (2)字段:数据表中的每⼀列被称为字段 (3)主键(PRIMARY KEY):作为数据表中唯⼀的表⽰,保证了每⼀天数记录的唯⼀性。
逐渐在关系数据库中约束实体完整性。
所谓实体完整性,是指对数据表⾏的约束。
(4)外键(FOREIGN KEY):外键⽤来定义表与表之间的关系。

sql包含的语句SQL(Structured Query Language)是用于管理关系型数据库的标准化语言。
它可以用于查询、插入、更新和删除数据库中的数据。
下面将列举10个常见的SQL语句及其用途。
1. SELECT语句:SELECT语句用于从数据库中检索数据。
它可以检索特定的列或所有列,并可以进行条件筛选、排序和分组。
例如:SELECT * FROM employees;SELECT name, age FROM customers WHERE country='China';2. INSERT INTO语句:INSERT INTO语句用于向数据库中插入新的行。
可以指定要插入的表、要插入的列和要插入的值。
例如:INSERT INTO customers (name, age, country) VALUES ('Alice', 25, 'USA');3. UPDATE语句:UPDATE语句用于更新数据库中的现有行。
可以指定要更新的表、要更新的列和更新的值,还可以使用WHERE子句来指定更新的条件。
例如:UPDATE employees SET salary=5000 WHERE department='IT';4. DELETE FROM语句:DELETE FROM语句用于从数据库中删除行。
可以指定要删除的表和要删除的条件。
例如:DELETE FROM customers WHERE country='China';5. CREATE TABLE语句:CREATE TABLE语句用于创建新的数据库表。
可以指定表的名称、列的名称和数据类型以及其他约束。
例如:CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),age INT,department VARCHAR(50));6. ALTER TABLE语句:ALTER TABLE语句用于修改现有的数据库表。

mysql必背50条语句1. 创建数据库:```sqlCREATE DATABASE dbname;```2. 删除数据库:```sqlDROP DATABASE dbname;```3. 选择数据库:```sqlUSE dbname;```4. 显示所有数据库:```sqlSHOW DATABASES;```5. 创建表:```sqlCREATE TABLE tablename (column1 datatype,column2 datatype,...);```6. 查看表结构:```sqlDESC tablename;```7. 删除表:```sqlDROP TABLE tablename;```8. 插入数据:```sqlINSERT INTO tablename (column1, column2, ...) VALUES (value1, value2, ...);```9. 查询数据:```sqlSELECT * FROM tablename;```10. 条件查询:```sqlSELECT * FROM tablename WHERE condition;```11. 更新数据:```sqlUPDATE tablename SET column1 = value1, column2 = value2 WHERE condition;```12. 删除数据:```sqlDELETE FROM tablename WHERE condition;```13. 查找唯一值:```sqlSELECT DISTINCT column FROM tablename;```14. 排序数据:```sqlSELECT * FROM tablename ORDER BY column ASC/DESC;```15. 限制结果集:```sqlSELECT * FROM tablename LIMIT 10;```16. 分页查询:```sqlSELECT * FROM tablename LIMIT 10 OFFSET 20;```17. 计算行数:```sqlSELECT COUNT(*) FROM tablename;```18. 聚合函数:```sqlSELECT AVG(column), SUM(column), MIN(column), MAX(column) FROM tablename;```19. 连接表:```sqlSELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column;```20. 创建索引:```sqlCREATE INDEX indexname ON tablename (column);```21. 查看索引:```sqlSHOW INDEX FROM tablename;```22. 删除索引:```sqlDROP INDEX indexname ON tablename;```23. 备份整个数据库:```sqlmysqldump -u username -p dbname > backup.sql;```24. 恢复数据库:```sqlmysql -u username -p dbname < backup.sql;```25. 修改表结构:```sqlALTER TABLE tablename ADD COLUMN newcolumn datatype;```26. 重命名表:```sqlRENAME TABLE oldname TO newname;```27. 增加主键:```sqlALTER TABLE tablename ADD PRIMARY KEY (column);```28. 删除主键:```sqlALTER TABLE tablename DROP PRIMARY KEY;```29. 增加外键:```sqlALTER TABLE tablename ADD CONSTRAINT fk_name FOREIGN KEY (column) REFERENCES othertable(column);```30. 删除外键:```sqlALTER TABLE tablename DROP FOREIGN KEY fk_name;```31. 查看活动进程:```sqlSHOW PROCESSLIST;```32. 杀死进程:```sqlKILL process_id;```33. 给用户授权:```sqlGRANT permission ON dbname.tablename TO 'username'@'host';```34. 撤销用户权限:```sqlREVOKE permission ON dbname.tablename FROM 'username'@'host';```35. 创建用户:```sqlCREATE USER 'username'@'host' IDENTIFIED BY 'password';```36. 删除用户:```sqlDROP USER 'username'@'host';```37. 修改用户密码:```sqlSET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');```38. 查看用户权限:```sqlSHOW GRANTS FOR 'username'@'host';```39. 启用外键约束:```sqlSET foreign_key_checks = 1;```40. 禁用外键约束:```sqlSET foreign_key_checks = 0;```41. 启用查询缓存:```sqlSET query_cache_type = 1;```42. 禁用查询缓存:```sqlSET query_cache_type = 0;```43. 查看服务器版本:```sqlSELECT VERSION();```44. 查看当前日期和时间:```sqlSELECT NOW();```45. 查找匹配模式:```sqlSELECT * FROM tablename WHERE column LIKE 'pattern';```46. 计算平均值:```sqlSELECT AVG(column) FROM tablename;```47. 查找空值:```sqlSELECT * FROM tablename WHERE column IS NULL;```48. 日期比较:```sqlSELECT * FROM tablename WHERE date_column > '2022-01-01';```49. 将结果导出为CSV 文件:```sqlSELECT * INTO OUTFILE 'output.csv' FIELDS TERMINATED BY ',' FROM tablename;```50. 将结果导入其他表:```sqlLOAD DATA INFILE 'input.csv' INTO TABLE tablename FIELDS TERMINATED BY ',';。

mssql 分页查询语句MSSQL是一种常用的关系型数据库管理系统,支持分页查询语句。
在进行分页查询时,可以使用OFFSET FETCH或ROW_NUMBER 函数来实现。
下面列举了10个符合标题内容的MSSQL分页查询语句。
1. 使用OFFSET FETCH实现分页查询```SELECT *FROM table_nameORDER BY column_nameOFFSET (page_number - 1) * page_size ROWSFETCH NEXT page_size ROWS ONLY;```2. 使用ROW_NUMBER函数实现分页查询```SELECT *FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_name) AS subWHERE row_num BETWEEN ((page_number - 1) * page_size + 1) AND (page_number * page_size);```3. 使用CTE和ROW_NUMBER函数实现分页查询```WITH cte AS (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_name)SELECT *FROM cteWHERE row_num BETWEEN ((page_number - 1) * page_size + 1) AND (page_number * page_size);```4. 使用OFFSET FETCH和JOIN实现分页查询```SELECT t1.*FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_name) AS t1JOIN (SELECT column_nameFROM table_nameORDER BY column_nameOFFSET (page_number - 1) * page_size ROWSFETCH NEXT page_size ROWS ONLY) AS t2 ON t1.column_name = t2.column_name;```5. 使用OFFSET FETCH和子查询实现分页查询```SELECT *FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_name) AS subWHERE sub.column_name IN (SELECT column_nameFROM table_nameORDER BY column_nameOFFSET (page_number - 1) * page_size ROWSFETCH NEXT page_size ROWS ONLY);```6. 使用CTE和ROW_NUMBER函数实现分页查询(带条件)```WITH cte AS (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_nameWHERE condition)SELECT *FROM cteWHERE row_num BETWEEN ((page_number - 1) * page_size + 1) AND (page_number * page_size);```7. 使用OFFSET FETCH和子查询实现分页查询(带条件)```SELECT *FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_nameWHERE condition) AS subWHERE sub.column_name IN (SELECT column_nameFROM table_nameWHERE conditionORDER BY column_nameOFFSET (page_number - 1) * page_size ROWSFETCH NEXT page_size ROWS ONLY);```8. 使用OFFSET FETCH和JOIN实现分页查询(带条件)```SELECT t1.*FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_nameWHERE condition) AS t1JOIN (SELECT column_nameFROM table_nameWHERE conditionORDER BY column_nameOFFSET (page_number - 1) * page_size ROWSFETCH NEXT page_size ROWS ONLY) AS t2 ON t1.column_name = t2.column_name;```9. 使用OFFSET FETCH和子查询实现分页查询(带多个条件)```SELECT *FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name)AS row_numFROM table_nameWHERE condition1 AND condition2) AS subWHERE sub.column_name IN (SELECT column_nameFROM table_nameWHERE condition1 AND condition2ORDER BY column_nameOFFSET (page_number - 1) * page_size ROWSFETCH NEXT page_size ROWS ONLY);```10. 使用OFFSET FETCH和JOIN实现分页查询(带多个条件)```SELECT t1.*FROM (SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_numFROM table_nameWHERE condition1 AND condition2) AS t1JOIN (SELECT column_nameFROM table_nameWHERE condition1 AND condition2ORDER BY column_nameOFFSET (page_number - 1) * page_size ROWSFETCH NEXT page_size ROWS ONLY) AS t2 ON t1.column_name = t2.column_name;```以上是10个符合标题内容的MSSQL分页查询语句,可以根据具体需求选择适合的语句进行分页查询操作。

关系数据库常⽤SQL 语句语法⼤全创建表语法CREATE TABLE <表名>(<列名> <数据类型>[列级完整性约束条件][,<列名> <数据类型>[列级完整性约束条件]]…);列级完整性约束条件有NULL[可为空]、NOT NULL[不为空]、UNIQUE[唯⼀],可以组合使⽤,但是不能重复和对⽴关系同时存在。
⽰例-- 创建学⽣表CREATE TABLE Student ( Id INT NOT NULL UNIQUE PRIMARY KEY, Name VARCHAR(20) NOT NULL, Age INT NULL, Gender VARCHAR(4) NULL);删除表语法DROP TABLE <表名>;⽰例-- 删除学⽣表DROP TABLE Student;清空表语法TRUNCATE TABLE <表名>;⽰例-- 删除学⽣表TRUNCATE TABLE Student;修改表######语法-- 添加列ALTER TABLE <表名> [ADD <新列名> <数据类型>[列级完整性约束条件]]-- 删除列ALTER TABLE <表名> [DROP COLUMN <列名>]-- 修改列ALTER TABLE <表名> [MODIFY COLUMN <列名> <数据类型> [列级完整性约束条件]]⽰例-- 添加学⽣表`Phone`列ALTER TABLE Student ADD Phone VARCHAR(15) NULL;-- 删除学⽣表`Phone`列ALTER TABLE Student DROP COLUMN Phone;-- 修改学⽣表`Phone`列ALTER TABLE Student MODIFY Phone VARCHAR(13) NULL;SQL 查询语句语法SELECT [ALL|DISTINCT] <⽬标列表达式>[,<⽬标列表达式>]…FROM <表名或视图名>[,<表名或视图名>]…[WHERE <条件表达式>][GROUP BY <列名> [HAVING <条件表达式>]][ORDER BY <列名> [ASC|DESC]…]SQL 查询语句的顺序:SELECT 、FROM 、WHERE 、GROUP BY 、HAVING 、ORDER BY 。

MSSQL中的IF语句用于在查询中根据条件执行不同的逻辑。
下面将介绍MSSQL中IF语句的使用方法以及一些示例。
一、IF语句的基本语法MSSQL中IF语句的基本语法如下:```IF conditionBEGIN-- 当条件成立时执行的逻辑END```或者```IF conditionBEGIN-- 当条件成立时执行的逻辑ENDELSEBEGIN-- 当条件不成立时执行的逻辑END```其中,condition是一个逻辑表达式,当满足条件时,执行BEGIN和END之间的逻辑,否则执行ELSE之后的逻辑(如果有ELSE的话)。
二、IF语句的示例1. 示例一:根据条件判断返回不同的值假设有一个学生成绩表,现在需要根据学生的成绩判断其等级,可以使用IF语句来实现:```SELECTStudentName,Score,IF Score >= 90BEGIN'优秀'ENDELSE IF Score >= 80BEGIN'良好'ENDELSE IF Score >= 60BEGIN'及格'ENDELSEBEGIN'不及格'END AS LevelFROMStudent;```在这个示例中,根据学生的成绩不同,返回不同的等级,可以看到IF 语句的嵌套使用。
2. 示例二:根据条件判断执行不同的逻辑假设需要根据不同的条件执行不同的逻辑,可以使用IF语句来实现:```IF EXISTS (SELECT * FROM Student WHERE Score > 90) BEGIN-- 存在成绩大于90的学生INSERT INTO ExcellentStudent (StudentName, Score)SELECT StudentName, ScoreFROM StudentWHERE Score > 90;ENDELSEBEGINR本人SERROR ('No student has a score greater than 90', 16,1)END```在这个示例中,首先判断是否存在成绩大于90的学生,如果存在,则将其插入到优秀学生表中,否则抛出一个错误。
mssql 数据库查询语句
MSSQL数据库查询语句是用来从数据库中检索数据的命令。
在MSSQL中,常用的查询语句包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等关键字,这些关键字可以组合使用来实现不同
的数据查询需求。
首先,SELECT关键字用于指定要检索的列,可以是单个列或多
个列。
例如,SELECT column1, column2 FROM table_name; 这条查
询语句将从指定的表中检索column1和column2列的数据。
其次,FROM关键字用于指定要检索数据的表。
例如,SELECT column1, column2 FROM table_name; 这里的table_name就是要从
中检索数据的表名。
然后,WHERE关键字用于指定检索数据时的条件。
例如,SELECT column1, column2 FROM table_name WHERE condition; 这
里的condition可以是各种逻辑条件,比如column1 = 'value'或
者column2 > 100等,用来筛选出符合条件的数据。
除了基本的SELECT语句外,MSSQL还支持其他高级的查询语句,
比如GROUP BY用于对检索的数据进行分组,HAVING用于对分组后的数据进行筛选,ORDER BY用于对检索的数据进行排序等。
总之,MSSQL数据库查询语句是非常灵活且强大的,可以根据具体的数据查询需求来灵活组合使用各种关键字和条件,以实现精确的数据检索和分析。
希望这些信息能够帮助到你。
mssqlserver insert into 语句的三种写法-回复[MSSQLServer INSERT INTO语句的三种写法]( Server数据库中用来向表中插入数据的语句。
INSERT INTO语句可以在插入数据同时指定列名和插入值,也可以仅指定插入值而不指定列名。
插入数据是数据库中常用的操作之一,掌握INSERT INTO语句的三种写法对于SQL数据库的开发和管理是非常重要的。
下面我们将逐步回答关于[MSSQLServer INSERT INTO语句的三种写法]( INTO语句。
第一种写法:指定列名和插入值在INSERT INTO语句中,我们可以使用列名称和对应的插入值来插入数据。
这种写法可以指定要插入数据的列,然后为每一列指定插入值。
示例:INSERT INTO 表名(列1, 列2, 列3)VALUES (值1, 值2, 值3);这个示例中,我们使用INSERT INTO语句向表中插入数据,指定了三个列和对应的插入值。
在实际应用中,根据表结构和需要插入的数据进行对应的修改。
第二种写法:指定插入值,不指定列名在某些情况下,我们不需要指定列名,可以直接指定插入值。
这种写法需要确保插入值的顺序和目标表的列顺序一致。
示例:INSERT INTO 表名VALUES (值1, 值2, 值3);在这个示例中,我们没有指定具体的列名,只是根据目标表的列顺序指定插入值。
第三种写法:插入查询结果除了直接插入值,我们还可以使用查询语句作为插入值。
这种写法可以将查询语句的结果集作为插入值插入到表中。
示例:INSERT INTO 表名(列1, 列2, 列3)SELECT 列1, 列2, 列3FROM 另一个表名WHERE 条件;在这个示例中,我们使用INSERT INTO语句插入查询结果集。
我们首先指定要插入数据的列,然后使用SELECT语句从另一个表中获取插入值。
在使用INSERT INTO语句时,还需要注意以下几点:- 确保插入的数据类型与目标列的数据类型匹配,否则会导致插入失败。
首先,简要介绍基础语句:1、说明:创建数据库CREATE DATABASE database-name2、说明:删除数据库drop database dbname3、说明:备份sql server--- 创建备份数据的deviceUSE masterEXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat'--- 开始备份BACKUP DATABASE pubs TO testBack4、说明:创建新表create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)根据已有的表创建新表:A:create table tab_new like tab_old (使用旧表创建新表)B:create table tab_new as select col1,col2… from tab_old definition only5、说明:删除新表drop table tabname6、说明:增加一个列Alter table tabname add column col type注:列增加后将不能删除。
DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键:Alter table tabname add primary key(col)说明:删除主键:Alter table tabname drop primary key(col)8、说明:创建索引:create [unique] index idxname on tabname(col….)删除索引:drop index idxname注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement删除视图:drop view viewname10、说明:几个简单的基本的sql语句选择:select * from table1 where 范围插入:insert into table1(field1,field2) values(value1,value2)删除:delete from table1 where 范围更新:update table1 set field1=value1 where 范围查找:select * from table1 where field1 like ‟%value1%‟ ---like的语法很精妙,查资料!排序:select * from table1 order by field1,field2 [desc]总数:select count(*) as totalcount from table1求和:select sum(field1) as sumvalue from table1平均:select avg(field1) as avgvalue from table1最大:select max(field1) as maxvalue from table1最小:select min(field1) as minvalue from table111、说明:几个高级查询运算词A:UNION 运算符UNION 运算符通过组合其他两个结果表(例如TABLE1 和TABLE2)并消去表中任何重复行而派生出一个结果表。
MySQL(MariaDB)常⽤SQL语句详解DDL(Data Definition Language)数据定义语⾔这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象的定义。
常⽤的语句关键字主要包括 create、drop、alter等。
数据库管理--删除数据库drop database if exits bookDB;--创建数据库create database bookDB;--修改数据库alter database bookDB charset=utf8;表的管理(主要是各种约束的管理)--表的创建create table bookInfo(book_id int auto_increment unique, --⾃增长,唯⼀约束author_id int,book_name varchar(10) not null, --⾮空约束book_price decimal(10,2) check (book_price>0), --检查约束(mysql中不⽀持检查约束,但是加上并不报错)book_shelf bit default 0, --默认约束primary key (book_id), --主键key fk_author (author_id), --外键详细写法constraint fk_author foreign key (author_id) references authorInfo(author_id)--foreign key (author_id) references authorInfo (author_id)--主外键的建⽴也可以直接在字段上⾯添加,这种写法是为了⽅便管理);-- 拿到数据创建⼀个表格create table bookInfo as select * from book_table;--创建临时表create temporary table if not exists book_table(....);--删除表drop table bookInfo;--重命名alter table bookInfo rename [to] book_info;--修改表(列的管理)--添加列alter table bookInfoadd column book_press varchar(20); --column关键字可以省略alter table bookInfoadd book_press varchar(20) after book_price; --指定位置alter table bookInfoadd (book_press varchar(20),book_date datetime); --批量添加--修改列类型alter table bookInfomodify book_press varchar(200);--修改列名(同时也可修改列的类型)alter table bookInofchange book_press bookPress varchar(25);--删除列alter table bookInfodrop column book_press;--修改表(约束的管理)--使⽤modify关键字可以更改数据类型,使⽤change关键字可以更改列名和数据类型--添加约束alter table bookInfoadd primary key (book_id); --添加主键alter table bookInfoadd modify book_id int primary key; --使⽤modify关键字alter table bookInfoadd constraint fk_author foreign key (author_id)references authorInfo(author_id) --添加外键alter table bookInfoadd constraint unique (book_id); --添加唯⼀约束alter table bookInfomodify book_shelf int default 0; --添加默认约束--删除约束alter table bookInfomodify book_shelf int; --删除默认约束alter table bookInfochange book_id book_id int; --去除auto_incrementalter table bookInfodrop primary key; --删除主键(先删除⾃增长)alter table bookInfodrop foreign key (fk_author); --删除外键--设置⾃增长值alter table bookInfo auto_increment=13;--设置表的字节编码alter table bookInfo character set='utf8';DML(Data Manipulation Language)数据操作语⾔主要⽤于添加、删除、更新和查询数据库记录,并检查数据完整性,常⽤的语句关键字主要包括 insert、delete、udpate 和select 等。
sql常用手册以下是SQL常用手册的一些要点:1. 数据定义语言(DDL):用于创建和修改数据库和表的语句。
常见的DDL语句包括CREATE TABLE、ALTER TABLE和DROP TABLE。
2. 数据操作语言(DML):用于对数据库中的数据进行操作的语句。
常见的DML语句包括SELECT、INSERT、UPDATE和DELETE。
3. 数据查询语言(DQL):用于从数据库中检索数据的语句。
常见的DQL语句包括SELECT、FROM、WHERE和ORDER BY。
4. 数据控制语言(DCL):用于控制数据库用户权限和访问的语句。
常见的DCL语句包括GRANT和REVOKE。
5. 数据完整性约束:用于保护数据库中数据完整性的规则。
常见的完整性约束包括主键、唯一约束、外键和检查约束。
6. 数据库连接:用于将两个或多个表按照一定条件关联起来的操作。
常见的连接操作包括内连接、外连接和交叉连接。
7. 聚合函数:用于对数据进行汇总和计算的函数。
常见的聚合函数包括COUNT、SUM、AVG、MIN和MAX。
8. 子查询:在一个查询语句内嵌套另一个查询语句的操作。
常见的子查询包括IN、NOT IN、ANY和ALL。
9. 索引:用于提高查询效率的数据库对象。
常见的索引包括唯一索引、非唯一索引和聚簇索引。
10. 视图:用于简化复杂查询和保护数据的虚拟表。
常见的视图包括基本视图、可更新视图和联接视图。
11. 事务:用于对数据库进行一系列操作的单个逻辑单位。
常见的事务操作包括BEGIN TRANSACTION、COMMIT和ROLLBACK。
这只是SQL常用手册的一小部分内容,SQL语言非常广泛和强大,可以进行更多复杂的操作和功能。
如果您需要详细了解SQL语句和特性,请参考相关数据库的官方文档或专业数据库教材。
sql基础语句50条 curdate() 获取当前⽇期年⽉⽇curtime() 获取当前时间时分秒sysdate() 获取当前⽇期+时间年⽉⽇时分秒*/order by bonus desclimit (页码-1)*每页显⽰记录数, 每页显⽰记录数*/foreign key dept_id references dept(id)--指定外键-- ------------------------------------- ⼀、创建建数据库、创建建数据表、查看数据库、查看数据表-- ------------------------------------- 01.查看mysql服务器中所有数据库show databases;-- 02.进⼊某⼀数据库(进⼊数据库后,才能操作库中的表和表记录)use (库名) tast;-- 查看已进⼊的库select database();-- 03.查看当前数据库中的所有表-- 04.删除mydb1库-- 语法:drop database 库名;drop database (库名) test;-- 思考:当删除的表不存在时,如何避免错误产⽣?drop database (库名) if exists test;-- 05.重新创建mydb1库,指定编码为utf8-- 语法:create database 库名 charset 编码;create database mubatis12 charset utf8;-- 如果不存在则创建mydb1;create database if not exists mubatis12 charset utf8;-- 06.查看建库时的语句(并验证数据库库使⽤的编码)-- 语法:show create database 库名;show create database mybatis1;-- 07.进⼊mydb1库,删除stu学⽣表(如果存在)-- 语法:drop table 表名;drop table if exists stu;-- 08.创建stu学⽣表(编号[数值类型]、姓名、性别、出⽣年⽉、考试成绩[浮点型])/* 建表的语法:create table 表名(列名数据类型,列名数据类型,...); */create table stu(id int primary key auto_increment,name varchar(20),gender varchar(20),birthday date,score double );-- 09.查看stu学⽣表结构show create table stu;desc stu;-- ------------------------------------- ⼆、新增、修改、删除表记录 **********-- ------------------------------------- 10.往学⽣表(stu)中插⼊记录(数据)-- 插⼊记录:insert into 表名(列1,列2,列3...) values(值1,值2,值3...);insert into stu (id,name,gender,birthday,score) values(1,'Tony','⼥','1998-07-02',99.5);insert into stu values(2,'Ben','男','1998-07-03',90);insert into stu values(4,'张三','男','1998-07-08',70);insert into stu values(5,'李四','男','1998-07-09',59);insert into stu values(6,'桂花','⼥','1998-07-09',80);insert into stu values(7,'秀芹','⼥','1998-07-10',50);insert into stu values(8,'海燕','⼥','1999-5-4',91);/* 提⽰:设置编码:set names gbk;查看MySQL数据库使⽤的编码:show variables like 'char%';mysql --default-character-set=gbk -uroot -proot */-- 11.查询stu表所有学⽣的信息select*from stu;-- 12.修改stu表中所有学⽣的成绩,加10分特长分-- 修改语法: update 表名 set 列=值,列=值,列=值...;update stu set score=score+10;-- 13.修改stu表中王海涛的成绩,将成绩改为88分。
数据库(catalog)表(table)列(column)或叫字段(field)数据类型(datatype)记录(record)或叫行(row)主键(PrimaryKey)索引(index)表关联:这种将两张表通过字段关联起来的方式就被称为“表关联”,关联到其他表主键的字段被称为“外键”例子:select * from employees where age<18delete from employees where position=‘名誉总裁’create table T_person (FName Varchar(20),FAge int,FRemark Varchar(20),primarykey(FName));create table T_Debt(FNumber Varchar(20),FAmount Numeric(10,2) NOT NULL,FPerson varchar(20),PrimaryKey(FNumber),foreignkey(FPerson) references T_Person(FName));insert into T_person(FName,FAge,FRemark)values('tom',18,'USA') 注:在插入数据的时候某些字段没有值,我们可以忽略这些字段,例子:insert into T_Person(FAge,FName) values(22,'lxf')说明:Numeric(10,2) 指定字段是数字型,长度为10位,小数为两位foreignkey(FPerson)外部约束主键为FPerson说明:增加一个列Alter table tabname add columnname type例子:alter table dbo.T_Person add Fcity varchar(20)*非空约束对数据插入或更新的影响如果对一个字段添加了非空约束,那么我们是不能向这个字段中插入或更新为NULL值的。
*主键对数据插入或更新的影响主键是在同一张表中必须是唯一的,如果在进行数据插入或更新的时候指定的主键与表中已有的数据重复的话则会导致违反主键约束的异常。
*外键对数据插入或更新的影响外键是指向另一个表中已有的数据的约束,因此外键值必须是在目标表中存在的。
如果插入或更新的数据在目标表中不存在的话则会导致违反外键约束异常。
**UPDATEupdate T_Personset FRemark='sonin'update T_Personset FAge=12where FName='tom'update T_Personset FAge=22where FName='jim' or FName='LXF'**DELETEdelete from T_Person;删除T_Person表中的所有数据drop table T_Person;删除表中的所有数据,及把表结构全部删除。
delete from T_Person where FAge>20 or FRemark='Mars'********数据检索select * from T_Employeeselect FNumber,FName,FAge,FSalary from T_Employeeselect FNumber as 编号,FName as 姓名,FAge as 年龄from T_Employee (其中的‘as’不是必须的,是可以省略的)select * from T_Employeewhere FSalary<5000 or FAge>25;几种聚合函数:MAX 计算字段最大值MIN 计算字段最小值A VG 计算字段平均值SUM 计算字段合计值COUNT 统计数据条数select MAX(FSalary) from T_Employeewhere FAge>25 注:查询年龄大于25岁的员工的最高工资。
select MAX(FSalary) as MAX_SALARY from T_Employeewhere FAge>25select A VG(FAge) from T_Employeewhere FSalary>3800 注:统计工资大于3800元的员工的平均年龄。
select SUM(FSalary) from T_Employee; 注:统计应支出工资的总额。
select MIN(FSalary),MAX(FSalary) from T_Employee; 注:多次使用聚合函数,统计公司的最低工资和最高工资。
select COUNT(*),COUNT(FNumber) from T_Employee; 注:COUNT(*)统计的是结果集的总条数,而COUNT(FNumber)统计的则是除了结果集中FNumber字段不为空值(也就是不等于NULL)的记录的总条数。
*****排序select * from T_Employeeorder by FAge ASC 注:按升序排列,ASC是可以省略的select * from T_Employeeorder by FAge DESC 注:按降序排列,select * from T_Employeeorder by FAge DESC, FSalary DESC; 注:order by 允许指定多个排序列,首先按第一个排序,分不出的按第二个排序。
**** select * from T_Employeewhere FAge>23order by FAge DESC,FSalary DESC;注:ORDER BY 子句要放到where子句后,不能颠倒它们的顺序。
*******通配符过滤SQL中的通配符过滤使用LIKE关键字。
注:使用通配符时,数据库要对全表进行扫描,所以速度非常慢,不要过分使用通配符。
1.单字符匹配select * from T_Employeewhere FName LIKE '_erry'; 注:以任意字符开头,剩余部分为“erry”。
select * from T_Employeewhere FName LIKE '__n_' ; 注:检索长度为4,第三个字符为“n”,其他字符为任意字符的姓名。
2.多字符匹配select * from T_Employeewhere FName LIKE 'T%' ; 注:检索以“T”开头,长度任意,select * from T_Employeewhere FName LIKE '%n%' ; 注:检索姓名中包含字母“n”的员工信息select * from T_Employeewhere FName LIKE '%n_' ; 注:检索最后一个字符为任意字符,倒数第二个字符为“n”长度任意的字符串。
select * from T_Employeewhere FName LIKE '[SJ]%' ;注:检索的是以“S”或者“J”开头,长度任意的数据select * from T_Employeewhere FName LIKE '[^SJ]%' ;注:否定符“^”是来对集合取反,即检索的是不以“S”或者“J”开头,长度任意的数据******空值检测select * from T_Employeewhere FName IS NULL ; 注:不能使用普通的等于运算符进行判断,而要使用IS NULL 关键字。
select * from T_Employeewhere FName IS NOT NULL ; 注:检索FName字段不为空的数据。
select * from T_Employeewhere FName IS NOT NULL AND FSalary<5000; 注:查询所有姓名已知且工资小于5000的员工的信息。
*****反义运算符select * from T_Employeewhere FAge!=22 AND FSalary!<2000 ;注:检索所有年龄不等于22岁并且工资不小于2000员的信息。
<> 不等于<= 不大于>= 不小于NOT 运算符用来将一个表达式的值取反select * from T_Employeewhere NOT(FAge=22) AND NOT(FSalary<2000) ;注:检索所有年龄不等于22岁并且工资不小于2000元的信息。
“!”运算符只能运行MSSQL和DB2两种数据库上,统一运算符可以使用在所有数据库中,建议采用NOT运算符,能比较容易的表达要实现的需求。
*****多值检测select FAge,FNumber,FName from T_Employeewhere FAge IN(23,25,28) ; 注:为了解决进行多个离散值的匹配问题,SQL提供了IN语句。
检索年龄为23,25,28的数据。
select * from T_Employeewhere FAge between 23 and 60 ;注:检索年龄在23到60岁之间的数据,包括23和60。
select * from T_Employeewhere (FSalary between 2000 and 3000)OR (FSalary between 5000 and 8000) ; 注:检索所有工资介于2000元到3000元之间以及5000元到8000元的员工信息。
*******数据分组ALTER TABLE T_Employee ADD FSubCompany V ARCHAR(20);ALTER TABLE T_Employee ADD FDepartment V ARCHAR (20); 注:ALTER ADD 通过更改、添加、除去列和约束,或者通过启用或禁用约束和触发器来更改表的定义。
**GROUP BY 子句进行分组select FAge from T_Employeewhere FSubCompany='Beijing'group by FAge ; 注:采用分组以后的查询结果是以分组形式提供的。
select FSubCompany,FDepartment from T_Employeegroup by FSubCompany,FDepartment ; 注:先根据FSubCompany,再在每个小组内根据FDepartment进行二次分组,查询数据select FAge,COUNT(*) AS CountOfThisAge from T_EmployeeGROUP BY FAge ; 注:检索每个年龄段的员工的人数select FSubCompany,FAge,COUNT(*) AS CountOfThisSubCompAge from T_Employee group by FSubCompany,FAgeorder by FSubCompany ; 注:统计每个公司的年龄段的人数。