异常数据取舍的准则
- 格式:docx
- 大小:11.76 KB
- 文档页数:2

8个判断异常的检验准则引言:在日常生活和工作中,我们常常会遇到各种异常情况,无论是在个人生活还是工作中,准确判断异常并采取相应措施是非常重要的。
在这篇文章中,我们将介绍8个判断异常的检验准则,帮助您更好地识别和解决异常情况。
一、观察准则:观察是判断异常的基本方法之一,通过观察可以发现异常的迹象和特征。
在判断异常时,我们应该注重细节,观察异常出现的时间、地点、频率、程度等方面的变化。
只有通过仔细观察,才能准确判断异常的性质和原因。
二、比较准则:通过比较不同时间、不同地点、不同情况下的数据,可以发现异常的存在。
比较准则可以帮助我们识别出数据中的异常值,并进一步分析异常的原因和影响。
在进行比较时,要注意数据的可比性,确保比较的数据具有相同的参考标准。
三、经验准则:经验准则是一种基于经验和常识的判断方法,通过积累和总结以往的经验,可以快速识别和判断异常情况。
在应对异常时,我们可以利用已有的经验进行判断,并根据经验采取相应的应对措施。
但是,经验准则也存在一定的局限性,因此需要不断学习和更新知识,以应对新的异常情况。
四、逻辑准则:逻辑准则是一种基于逻辑推理的判断方法,通过分析异常与正常情况之间的逻辑关系,可以推断出异常的存在。
在判断异常时,我们需要运用逻辑思维,分析异常与正常之间的差异和联系,并根据逻辑推理得出合理的结论。
五、统计准则:统计准则是一种基于统计学原理的判断方法,通过对数据进行统计分析,可以发现异常的存在。
在判断异常时,我们可以利用统计方法计算数据的均值、方差、偏度等指标,进而判断数据是否存在异常。
但是,在使用统计准则时,需要注意数据的分布和样本的大小,以保证结果的准确性。
六、专家准则:专家准则是一种基于专家经验和知识的判断方法,通过请教专家或专业人士,可以获取专业的意见和建议。
在判断异常时,我们可以向相关领域的专家咨询,借鉴他们的经验和知识,以提高判断的准确性和可靠性。
七、模型准则:模型准则是一种基于数学模型和实验数据的判断方法,通过建立模型并利用实验数据进行验证,可以判断异常的存在。
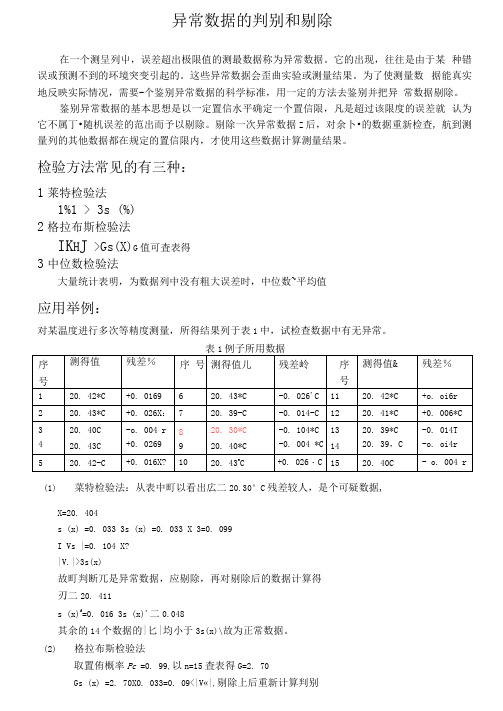
异常数据的判别和剔除在一个测呈列屮,误差超出极限值的测最数据称为异常数据。
它的出现,往往是由于某种错误或预测不到的环境突变引起的。
这些异常数据会歪曲实验或测量结果。
为了使测量数据能真实地反映实际情况,需要-个鉴别异常数据的科学标准,用一定的方法去鉴别并把异常数据剔除。
鉴别异常数据的基本思想是以一定置信水平确定一个置信限,凡是超过该限度的误差就认为它不属丁•随机误差的范出而予以剔除。
剔除一次异常数据Z后,对余卜•的数据重新检查, 航到测量列的其他数据都在规定的置信限内,才使用这些数据计算测量结果。
检验方法常见的有三种:1莱特检验法1%1 > 3s (%)2格拉布斯检验法IK H J >Gs(X)G值可査表得3中位数检验法大量统计表明,为数据列中没有粗大误差时,中位数~平均值应用举例:对某温度进行多次等精度测量,所得结果列于表1中,试检查数据中有无异常。
1(1)菜特检验法:从表中町以看出広二20.30°C残差较人,是个可疑数据,X=20. 404s (x) =0. 033 3s (x) =0. 033 X 3=0. 099I Vs |=0. 104 X?|V.|>3s(x)故町判断兀是异常数据,应剔除,再对剔除后的数据计算得刃二20. 411s (x)f=0. 016 3s (x)'二0.048其余的14个数据的|匕|均小于3s(x)\故为正常数据。
(2)格拉布斯检验法取置侑概率Pc =0. 99,以n=15査表得G=2. 70Gs (x) =2. 70X0. 033=0. 09<|V«|,剔除上后重新计算判别得n=14, Pc =0. 99 下的G 值为 2. 66Gs (x)'=2. 66X0.016=0. 04 余卜墩据中无异常值。
(3)中位数检验法20. 30, 20. 39, 20. 39, 20. 39, 20. 40, 20. 40. 20. 40, 20.41, 20. 42, 20. 42, 20. 42,通过此例及以往经验我们应该注意几个问题:(1)所仃的检验法都是人为主观拟定的,至今尚未令统一的规定。

在实验室中,异常值的取舍是一个重要的数据处理步骤。
通常,这些异常值可能是由于测量误差、设备故障或其他未知因素引起的。
取舍异常值应遵循以下几个原则:
1. 可疑数据的判断:可疑数据是指与其它数据相比明显不一致的数据。
通常,这些数据可能是由于仪器故障、操作错误或其他异常情况引起的。
判断可疑数据时,可以采用一些统计方法,如格鲁布斯检验法等。
2. 判断依据:判断异常值的标准通常基于数据的分布特性和统计规律。
例如,在正态分布中,异常值通常被定义为远离平均值的数据点,可以根据标准偏差来判定。
3. 处理方法:一旦确定了异常值,应采取适当的处理方法。
常用的方法包括删除异常值、对异常值进行修正或用平均值等方法替代。
在进行处理时,应考虑数据的可靠性和完整性。
4. 记录和解释:在处理异常值时,应详细记录处理的理由和依据。
这有助于确保结果的可靠性和可重复性,也有助于对实验结果进行解释和评估。
总之,实验室中异常值的取舍应基于数据的分布特性和统计规律,采取合适的处理方法,确保数据的可靠性和完整性。
同时,应详细记录处理的过程和依据,以供后续研究和解释使用。

目录摘要...................................................... 错误!未定义书签。
关键词................................................... 错误!未定义书签。
1 引言...................................................... 错误!未定义书签。
2 异常值的判别方法..................................... 错误!未定义书签。
检验(3S)准则........................................ 错误!未定义书签。
狄克松(Dixon)准则.................................. 错误!未定义书签。
格拉布斯(Grubbs)准则.............................. 错误!未定义书签。
指数分布时异常值检验................................. 错误!未定义书签。
莱茵达准则(PanTa).................................. 错误!未定义书签。
肖维勒准则(Chauvenet)............................. 错误!未定义书签。
3 实验异常数据的处理 .................................. 错误!未定义书签。
4 结束语................................................... 错误!未定义书签。
参考文献.................................................... 错误!未定义书签。
试验数据异常值的检验及剔除方法摘要:在实验中不可避免会存在一些异常数据,而异常数据的存在会掩盖研究对象的变化规律和对分析结果产生重要的影响,异常值的检验与正确处理是保证原始数据可靠性、平均值与标准差计算准确性的前提.本文简述判别测量值异常的几种统计学方法,并利用DPS软件检验及剔除实验数据中异常值,此方法简单、直观、快捷,适合实验者用于实验的数据处理和分析.关键词:异常值检验;异常值剔除;DPS;测量数据1 引言在实验中,由于测量产生误差,从而导致个别数据出现异常,往往导致结果产生较大的误差,即出现数据的异常.而异常数据的出现会掩盖实验数据的变化规律,以致使研究对象变化规律异常,得出错误结论.因此,正确分析并剔除异常值有助于提高实验精度.判别实验数据中异常值的步骤是先要检验和分析原始数据的记录、操作方法、实验条件等过程,找出异常值出现的原因并予以剔除.利用计算机剔除异常值的方法许多专家做了详细的文献[1]报告.如王鑫,吴先球,用Origin 剔除线形拟合中实验数据的异常值;严昌顺.用计算机快速剔除含粗大误差的“环值”;运用了统计学中各种判别异常值的准则,各种准则的优劣程度将体现在下文.2 异常值的判别方法判别异常值的准则很多,常用的有t 检验(3S )准则、狄克松(Dixon )准则、格拉布斯(Grubbs )准则等准则.下面将一一简要介绍. 2.1 检验(3S )准则t 检验准则又称罗曼诺夫斯基准则,它是按t 分布的实际误差分布范围来判别异常值,对重复测量次数较少的情况比较合理.基本思想:首先剔除一个可疑值,然后安t 分布来检验被剔除的值是否为异常值.设样本数据为123,,n x x x x ,若认j x 为可疑值.计算余下1n -个数据平均值1n x -及标准差1n s -,即2111,1,1n n i n i i j x x s n --=≠=-∑.然后,按t 分布来判别被剔除的值j x 是否为异常值.若1(,)n j x x kn a -->,则j x 为异常值,应予剔除,否则为正常值,应予以保留.其中:a 为显著水平;n 数据个数;(,)k n a 为检验系数,可通过查表得到.2.2 狄克松(Dixon )准则设有一组测量数据123nx x x x ≤≤≤,且为正态分布,则可能为异常值的测量数据必然出现在两端,即1x 或n x .狄克松给出了不同样本数量n 时检验统计量的计算公式(见表1).当显著水平a 为1%或5%时,狄克松给出了其临界值1()a n D -.如果测量数据的检验统计量1()a n D D ->,则1x 为异常值,如果测量数据的检验统计量'1()a n D D ->,则n x 为异常值.2.3 格拉布斯(Grubbs )准则设有一组测量数据为正态分布,为了检验数据中是否存在异常值,将其按大小顺序排列,即123n x x x x ≤≤≤,可能为异常值的测量数据一定出现在最大或最小的数据中.若最小值1x 是可疑的,则检验统计量1()/G x x s =-.式中x 是均值、s 是标准差,即211,n i i x xs n ==∑. 对于检验统计量G ,格拉布斯导出了其统计分布,并给出了当显著水平a 为1%或5%时的临界值(1)()n G n -.(1)()n G n -称格拉布斯系数,可通过抽查表得到.当最小值1x 或最大值n x 对应的检验统计量G 大于临界值时,则认为与之对应的1x 或n x 为可疑异常值,应予以剔除.2.4 指数分布时异常值检验设一组测量数据为指数分布,为了检验数据中是否存在异常值,将其按大小顺序排列,即123n x x x x ≤≤≤.检验最小值或最大值是否为异常值的检验方法如下:当样本量100n ≤时,计算统计量()1/nn n n i i T x x ==∑及(1)11/nn i i T x x ==∑对于给定的显著水平a (通常取)和样本数量n ,通过查表得到()n n T 及(1)n T 分别对应的临界值()(1)n n T a -和(1)()n T a .若()()(1)n n n n T T a >-时,认为n x 为异常值;若(1)(1)()n n T T a <时,认为1x 为异常值. 当样本容量100n >时,计算统计量()111(1)()/()nn n n n i n i E n x x x x --==--+∑及(1)111(1)/()nn i i E n n x x n x ==-+∑. 对于给定显著水平a 和样本数量n ,若11()2,2~2,1(1)(1)n n n n aE F n a --->=--,则判断n x 为异常值;若11(1)2,22,(1)[(1)1]n n n a E F n a --->=---,则判断1x 为异常值. 2.5 莱茵达准则(PanTa )对于实验数据测出值123,,,,nx x x x ,求取其算术平均值11/ni i x n x ==∑及剩余误差值i i v x x =-,然后求出其均方根偏差21/2(/1)i v n σ=-∑. 判别依据(假设v 服从正态分布):3i x x σ->,则i x 相对而言误差较大,应舍去; 3i x x σ-≤,i x 为正常数据,应该保留.有概率论统计可知,如果误差服从正要分布,误差大于3σ的观测数据出现的概率小于,相当大于300次观测中有一次出现的可能.莱茵达准则只是进行粗略的剔除,取舍的概率较小,可能将不合理的异常值保留.2.6 肖维勒准则(Chauvenet )次准则也是建立在实验数据服从正态分布.假设多次测量的n 个测量值中,数据的参与误差i c v Z σ>,则剔除该数据.其中21/2(/1)i v n σ=-∑,样品容量为n 时的判别系数3c Z <,弥补了莱茵达准则的不足,故此准则优胜于莱茵达准则,但条件更为苛刻.3 实验异常数据的处理对于测定中异常数据的处理,必须慎重考虑,不能凭预感任意删除或添加.应该从所学知识上考虑,异常值有时能反映试验中的某些新现象.这类“异常值”正深化人们对客观事物的认识,如果随意删除它,可能深入了解和发现新事物的一次机会,那么对学者深入研究非常可惜.所以对任何异常数据都因首先在技术上寻找原因,如果在技术上发现原因,理应舍去.如在技术上无法作出判断,却可在上述准则中发现其高度异常,也因舍弃.其中,运用DPS 软件进行异常数据的检验与剔除特别方便,而且不许编写程序,它融合了SPSS 表格和EXCELL 表格,操作简单,实用性强.如图一下为DPS 数据处理系统对话框.图一 数据处理系统对话框只要执行菜单命令下的“数据分析——异常值检验”弹出如图二下图的窗口,然后进行选择检验分析方法及显著水平,点击确定即可.图二用户对话框在测定中,有时发现个别数据离群严重,上述检验原则为异常值,但它与其他测定值的差异在仪器的精度范围内,这种数据不应舍去,应予保留.而对于一些分析而言,需要估计总体参数,异常数据一般都要舍去.对于不同的之心度应作相应的处理,则要据实际情况而定.4结束语由上述可知,用DPS软件进行异常值检验和剔除的过程简单、直观、快捷,适用于大众学生进行各实验数据的处理和分析.将此软件运用于实验教学,可以使学生快速准确判断实验结果,也可以提高教学质量.参考文献[1] 王鑫,吴先球.用Origin剔除线形拟合中实验数据的异常值[J].山西师范大学学报,2003,17(1),56—57.[2] 严昌顺.用计算机快速剔除含粗大误差的“环值”[J].计量技术,1994(5),45—47.[3] 苏金明,傅荣华,周建斌.统计软件SPSS系列应用实战篇[M].电子工业出版社,2002[4] 唐起义.DPS数据处理系统——实验设计、统计分析及数据挖掘[M].科学出版社,2006[5] 何国伟等编著.误差分析方法.北京:国防工业出版社,1978。


剔除异常值的方法拉依达准则法,肖维勒准则法,狄克逊准则法,罗马诺夫斯基(t检验)准则法,格拉布斯准则法(Grubbs)各类剔除异常值方法的比较。
1.拉依达准则法(3δ):简单,无需查表。
测量次数较多或要求不高时用。
是最常用的异常值判定与剔除准则。
但当测量次数《=10次时,该准则失效。
如果实验数据值的总体x是服从正态分布的,则式中,μ与σ分别表示正态总体的数学期望和标准差。
此时,在实验数据值中出现大于μ+3σ或小于μ―3σ数据值的概率是很小的。
因此,根据上式对于大于μ+3σ或小于μ―3σ的实验数据值作为异常值,予以剔除。
在这种情况下,异常值是指一组测定值中与平均值的偏差超过两倍标准差的测定值。
与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。
在处理数据时,应剔除高度异常的异常值。
异常值是否剔除,视具体情况而定。
在统计检验时,指定为检出异常值的显著性水平α=0.05,称为检出水平;指定为检出高度异常的异常值的显著性水平α=0.01,称为舍弃水平,又称剔除水平(reject level)。
标准化数值(Z-score)可用来帮助识别异常值。
Z分数标准化后的数据服从正态分布。
因此,应用Z分数可识别异常值。
我们建议将Z分数低于-3或高于3的数据看成是异常值。
这些数据的准确性要复查,以决定它是否属于该数据集。
2.肖维勒准则法(Chauvenet):经典方法,改善了拉依达准则,过去应用较多,但它没有固定的概率意义,特别是当测量数据值n无穷大时失效。
3.狄克逊准则法(Dixon):对数据值中只存在一个异常值时,效果良好。
担当异常值不止一个且出现在同侧时,检验效果不好。
尤其同侧的异常值较接近时效果更差,易遭受到屏蔽效应。
4.罗马诺夫斯基(t检验)准则法:计算较为复杂。
5.格拉布斯准则法(Grubbs):和狄克逊法均给出了严格的结果,但存在狄克逊法同样的缺陷。
朱宏等人采用数据值的中位数取代平均值,改进得到了更为稳健的处理方法。
用格拉布斯准则判断异常数据一、实验目的1.通过实验加深对格拉布斯准则的理解。
2.掌握实验中异常数据的处理方法。
二、实验要求用C语言或其它高级语言编写一程序,输入一组测量数据(9~15个,程序可设定),根据格拉布斯准则判断有无异常数据。
如有,则剔除异常数据并重新计算,直到无异常数据为止。
具体要求如下:1.数据个数可输入;2.格拉布斯系数g以表的形式存于数组中;3.显示均值、标准偏差等中间结果、被剔除的异常数据、显示无异常数据的测量数据等。
三、实验原理在无系统误差的情况下,测量中大误差出现的概率是很小的。
在正态分布下,误差绝对值超过2.57的概率仅为1%,误差绝对值超过3的概率仅为0.27%≈1/370。
对于误差绝对值较大的测量数据,就值得怀疑,可以列为可疑数据。
可疑数据对测量值的平均值及实验标准偏差都有较大的影响,造成测量结果的不正确,因此在这种情况下要分清可疑数据是由于测量仪器、测量方法或人为错误等因素造成的异常数据,还是由于正常的大误差出现的可能性。
首先,要对测时过程进行分析,是否有外界干扰,如电力网电压的突然跳动,是否有人为错误,如小数点读错等。
其次,可以在等精度条件下增加测量次数,以减少个别离散数据对最终统计估值的影响。
在不明原因的情况下,就应该根据统计学的方法来判别可疑数据是否是粗差。
这种方法的基本思想是:给定一置信概率,确定相应的置信区间,凡超过置信区间的误差就认为是粗差,并予以剔除。
用于粗差剔除的常见方法有莱特检验方法和格拉布斯检验方法。
1. 莱特检验方法莱特检验法是一种正态分布情况下判别异常值的方法。
判别方法如下:假设在一列等精度测量结果中,第i项测量值x i所对应的残差v i的绝对值,则该误差为粗差,所对应的测量值x i为异常数值,应剔除不用。
此处,残差,标准偏差估计(贝塞尔公式),均值。
本检验方法简单,使用方便,当测量次数n较大时,是比较好的方法。
一般适用于n>10的情况,n<10时,莱特检验法失去判别能力。
可疑数据的取舍21.3.3.1 可疑数据的取舍为了使分析结果更符合客观实际,必须剔除明显歪曲试验结果的测定数据。
正常数据总是有一定的分散性,如果人为删去未经检验断定其离群数据(Outliers)的测定值(即可疑数据),由此得到精密度很高的测定结果并不符合客观实际。
因此对可疑数据的取舍必须遵循一定原则。
1. 取舍原则(1)测量中发现明显的系统误差和过失错误,由此而产生的分析数据应随时剔除。
(2)可疑数据的取舍应采用统计学方法判别,即离群数据的统计检验。
2. 大样本离群数据的取舍(三倍标准差法):根据正态分布密度函数,设测定值为Xi,可表示为Xi+3S ³μ³ Xi -3S。
若Xi在Xi±3S范围内,此数据可用;若在Xi±3S范围外,此数据不可用,须舍弃(亦称莱特准则)。
该判断的置信度在99.7%以上,但测定次数增多时,出现可疑值机会就随之增加,应将取舍标准改变如下。
先计算多次测定结果的平均值X和标准差S,再计算Z值:X=X1 + X2+ … +Xn/ n (n 为包括可疑值尾数在内的测定次数)S = [∑X2 -(∑X)2/n] / (n-1)Z= (X - X ) / S (X 为可疑值)然后查正态分布表,得对应于Z值的a值。
如 n a<0.1,则舍弃,>0.1,则不舍弃。
例如:土壤全氮的5次平行测定结果(g·kg-1)为1.52,1.48,1.65,1.85,1.45。
其中1.85为可疑值,需判断取舍。
计算平均值X=1.59;S=±0.164;Z=(1.85-1.59)/0.164=1.585。
查正态分布表a=0.0565,na=5×0.0565=0.2825,因na>0.1,可疑值1.85g·kg-1不予舍弃。
3. 小样本离群数据取舍(n为有限数):有几个统计检验方法来估测可疑数据,包括Dixon,Grubbs,Cochran和Youden检验法。
异常数据取舍的准则
在数据分析和机器学习领域中,我们经常会面对大量的数据集。
然而,这些数据集中往往存在着一些异常数据,即与其他数据点不一致或者错误的数据。
这些异常数据可能会对我们的分析结果产生负面影响,因此在数据分析的过程中,我们需要制定一些准则来判断和处理异常数据。
1. 什么是异常数据
异常数据,也称为离群点(outliers),是指在数据集中与其他数据点存在显著差异或者不符合预期模式的数据。
异常数据可能是由于测量误差、数据收集错误、系统故障等原因导致的。
异常数据与正常数据相比,往往具有较大的偏离程度,可能会严重影响数据分析的结果。
2. 异常数据的影响
异常数据的存在可能对数据分析和机器学习产生以下几个方面的影响:
•扭曲统计量:异常数据会对统计量产生严重影响,如平均值、标准差等。
如果异常数据没有正确处理,可能导致统计结果失真。
•引发误导性结论:异常数据可能导致误导性的结论。
在一些领域,如金融风险评估、医学诊断等,异常数据的存在可能造成严重的错误判断。
•对模型表现产生影响:在训练机器学习模型时,异常数据可能对模型的性能产生负面影响。
模型可能过于拟合异常数据,导致泛化能力下降。
3. 判断异常数据的准则
判断数据是否为异常数据的准则旨在帮助我们将异常数据从数据集中分离出来,以便更好地进行数据分析。
以下是一些常用的判断异常数据的准则:
•统计方法:使用统计方法判断数据点是否偏离了正常范围。
例如,可以基于离群值得统计测度,如Z-Score、箱线图等来判断异常数据。
•专家知识:利用相关领域的专业知识来判断异常数据。
专家可以根据经验和领域内的规则,判断数据是否异常。
•数据可视化:通过绘制数据图表来观察数据分布情况,识别其中的异常点。
对于多维数据,可以绘制散点图、箱线图等来发现异常数据点。
•预测模型:使用机器学习算法来预测数据的值,然后与实际观测值进行比较。
如果预测值与观测值差异较大,则有可能是异常数据。
4. 异常数据的处理策略
一旦发现了异常数据,我们需要根据具体情况采取相应的处理策略,以保证数据分析结果的准确性和可靠性。
以下是一些常用的异常数据处理策略:
•删除异常数据:如果确定该数据是异常数据,且对分析结果的影响较大,可以选择直接删除异常数据。
然而,需要谨慎操作,以免删除了重要的信息。
•替换异常数据:对于一些偶然或者明显错误的异常数据,可以选择将其替换为合理的值。
替换方式可以基于平均值、中位数、众数等。
•创建新特征:有时,异常数据可能包含有用的信息,可以将其作为新特征加入到数据集中。
这样可以增加模型的表达能力,提高对异常数据的鲁棒性。
•使用建模方法:使用异常检测算法,如聚类、回归、离群点检测算法等,来自动识别和处理异常数据。
5. 异常数据取舍的注意事项
在处理异常数据时,需要注意以下几点:
•数据来源可靠性:需要对数据来源进行验证,确保数据的准确性和可信度。
如果数据本身存在缺陷,可能导致错误的判断和处理。
•领域知识的重要性:在判断异常数据时,领域知识是至关重要的。
专家可以提供更准确的判断和处理策略,避免盲目处理异常数据。
•影响评估:在处理异常数据时,需要对可能的影响进行评估。
有时,异常数据可能包含有用的信息,直接删除可能会损失重要的数据。
•频繁检查:异常数据并非一劳永逸,需要定期检查和更新异常数据判断的准则和处理策略,以适应数据和业务的变化。
结论
异常数据在数据分析和机器学习中是一个重要的问题,对数据分析结果和模型性能都有很大的影响。
通过准确判断和合理处理异常数据,可以提高数据分析的准确性和可靠性。
在处理异常数据时,我们需要结合领域知识、统计方法和数据可视化等手段,并考虑数据来源和影响评估,最终选择合适的处理策略。
同时需要不断更新和优化异常数据的判断和处理准则,以应对不断变化的数据和业务需求。