第3章分类与决策树
- 格式:ppt
- 大小:2.42 MB
- 文档页数:72



习题3(第三章 分类技术)1. 在决策树归纳中,选项有:(a)将决策树转化为规则,然后对结果规则剪枝,或(b)对决策树剪枝,然后将剪枝后的树转化为规则。
相对于(b),(a)的优点是什么? 解答:如果剪掉子树,我们可以用(b)将全部子树移除掉,但是用方法(a)的话,我们可以将子树的任何前提都移除掉。
方法(a)约束更少。
2. 在决策树归纳中,为什么树剪枝是有用的?使用分离的元组集评估剪枝有什么缺点?解答:决策树的建立可能过度拟合训练数据,这样就会产生过多分支,有些分支就是因为训练数据中的噪声或者离群点造成的。
剪枝通过移除最不可能的分支(通过统计学方法),来排除这些过度拟合的数据。
这样得到的决策树就会变得更加简单跟可靠,用它来对未知数据分类时也会变得更快、更精确。
使用分离的元组集评估剪枝的缺点是,它可能不能代表那些构建原始决策树的训练元组。
如果分离的元组集不能很好地代表,用它们来评估剪枝树的分类精确度将不是一个很好的指示器。
而且,用分离的元组集来评估剪枝意味着将使用更少的元组来构建和测试树。
3. 画出包含4个布尔属性A,B,C,D 的奇偶函数的决策树。
该树有可能被简化吗?解答:决策树如下,该树不可能被简化。
4. X 是一个具有期望Np 、方差Np(1-p)的二项随机变量,证明X/N 同样具有二项分布且期望为p 方差为p(1-p)/N 。
解答:令r=X/N ,因为X是二项分布,r同样具有二项分布。
期望,E[r] = E[X/N] = E[X]/N = (Np)/N = p; 方差,E[错误!未找到引用源。
] = E[错误!未找到引用源。
] = E[错误!未找到引用源。
]/错误!未找到引用源。
= Np(1-p)/错误!未找到引用源。
= p(1-p)/N5. 当一个数据对象同时属于多个类时,很难评估分类的准确率。
评述在这种情况下,你将A B C D Class T T T T T T T T F F T T F T F T T F F T T F T T F T F T F T T F F T T T F F F F F T T T F FTTFTF T F T TF T F F FF F T T TF F T F F F F F T F F F F F T使用何种标准比较对相同数据建立的不同分类器。
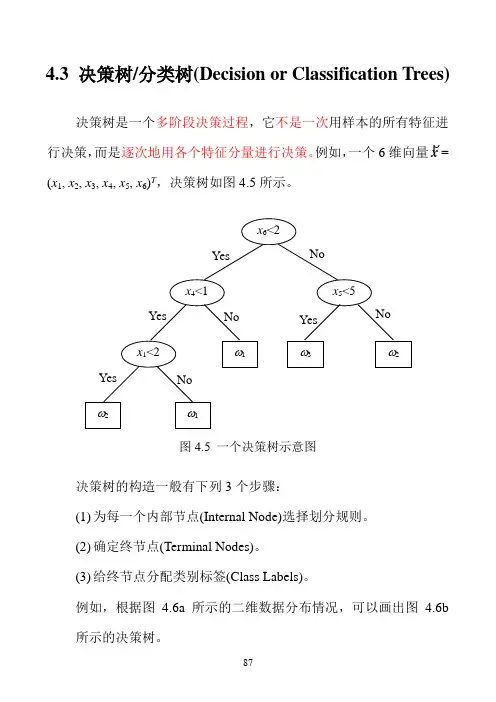
4.3 决策树/分类树(Decision or Classification Trees)
决策树是一个多阶段决策过程,它不是一次用样本的所有特征进
行决策,而是逐次地用各个特征分量进行决策。
例如,一个6维向量x
=
(x 1, x 2, x 3, x 4, x 5, x 6)T ,决策树如图4.5所示。
决策树的构造一般有下列3个步骤:
(1) 为每一个内部节点(Internal Node)选择划分规则。
(2) 确定终节点(Terminal Nodes)。
(3) 给终节点分配类别标签(Class Labels)。
例如,根据图 4.6a 所示的二维数据分布情况,可以画出图 4.6b 所示的决策树。
x 6<2
x 5<5
x 4<1 x 1<2
ω1 ω2
ω1
ω3 ω2 Yes No
Yes Yes
Yes No
No
No
图4.5 一个决策树示意图
我们可以利用决策树的原理来解决多类别问题,例如,用一个线性分类器(例如Fisher 分类器)解决多类别问题。
图4.6a 一个二维空间样本分布示例
图4.6b 对应的决策树
x k >b 2
x k <b 1
x i <a 2 x k >b 3 ω8
ω9 ω6
ω4
Yes No
Yes Yes
Yes
No
No No x i >a 1
ω10
ω1 Yes
No。

第3章分类与回归3.1简述决策树分类的主要步骤。
3.2给定决策树,选项有:(1)将决策树转换成规则,然后对结果规则剪枝,或(2)对决策树剪枝,然后将剪枝后的树转换成规则。
相对于(2),(1)的优点是什么?3.3计算决策树算法在最坏情况下的时间复杂度是重要的。
给定数据集D,具有m个属性和|D|个训练记录,证明决策树生长的计算时间最多为)⨯。
m⨯Dlog(D3.4考虑表3-23所示二元分类问题的数据集。
(1)计算按照属性A和B划分时的信息增益。
决策树归纳算法将会选择那个属性?(2)计算按照属性A和B划分时Gini系数。
决策树归纳算法将会选择那个属性?3.5证明:将结点划分为更小的后续结点之后,结点熵不会增加。
3.6为什么朴素贝叶斯称为“朴素”?简述朴素贝叶斯分类的主要思想。
3.7考虑表3-24数据集,请完成以下问题:(1)估计条件概率)|-C。
P)A(+|(2)根据(1)中的条件概率,使用朴素贝叶斯方法预测测试样本(A=0,B=1,C=0)的类标号;(3)使用Laplace估计方法,其中p=1/2,l=4,估计条件概率)P,)C(+|(-P,A||(+P,)P,)A(+B|(-P。
|C(-P,)|)B(4)同(2),使用(3)中的条件概率(5)比较估计概率的两种方法,哪一种更好,为什么?3.8考虑表3-25中的一维数据集。
表3-25 习题3.8数据集根据1-最近邻、3-最近邻、5-最近邻、9-最近邻,对数据点x=5.0分类,使用多数表决。
3.9 表3-26的数据集包含两个属性X 与Y ,两个类标号“+”和“-”。
每个属性取三个不同值策略:0,1或2。
“+”类的概念是Y=1,“-”类的概念是X=0 and X=2。
(1) 建立该数据集的决策树。
该决策树能捕捉到“+”和“-”的概念吗?(2) 决策树的准确率、精度、召回率和F1各是多少?(注意,精度、召回率和F1量均是对“+”类定义)(3) 使用下面的代价函数建立新的决策树,新决策树能捕捉到“+”的概念么?⎪⎪⎪⎩⎪⎪⎪⎨⎧+=-=+--=+===j i j i j i j i C ,,10),(如果实例个数实例个数如果如果(提示:只需改变原决策树的结点。