基于决策树的鸢尾花分类
- 格式:pdf
- 大小:1.21 MB
- 文档页数:3

浅析决策树在鸢尾花分类中的应用作者:段欣伸郭威侯婷婷刘雷来源:《环球市场》2019年第16期摘要:当今,机器学习在各个领域都有广泛的应用,特别在数据分析领域有着深远的影响。
而决策树是机器学习中最基础且应用最广泛的分类算法模型。
本文介绍了决策树的相关概念、决策树模型及简单应用。
通过对鸢尾花数据集进行决策树分类,并对分类结果与实际结果进行比对,进而分析其分类的准确率。
最后基于Python语言,设计与实现了决策树模型在对鸢尾花数据集分类中的应用实例。
关键词:鸢尾花;决策树;分类;信息熵;信息增益一、引言鸢尾花数据集包含150个样本,对应数据集的每行数据。
每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花尊宽度、花瓣长度、花瓣宽度四个特征(前4列)。
iris的每个样本都包含了品种信息,即目标属性(第5列)。
二、方法(一)决策树决策树是一个预测模型:其代表的是对象属性与对象值之间的一种映射关系。
树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。
数(二)信息熵“信息熵”(informationentropy)是度量样本集合纯度的一种常用指标。
若集合D中存在d 个类别的N个样本,令Pk=成为从集合D中随机选取一个样本属于第k类样本的概率,可用公式-1计算信息熵:Ent(D)=-S&=1Prlog2Pk公式-1(三)信息增益信息增益(informationgain),计算公式为公式-2:式中,D,为样本数据集D根据属性a进行划分而产生的V个分支节点中的第v个分支的样本数目,Ent(D)为根据公式-1计算得出的D,的信息熵。
求得的信息增益Gain(D,a)越大,则表明使用属性a进行划分获得的“纯度提升”越大。

决策树在鸢尾花亚属分类中的应用作者:金鑫来源:《商情》2015年第42期【摘要】随着信息技术的高速发展,人们积累的数据量急剧增长,利用数据挖掘方法从海量数据中提取有用的信息和知识已经成为社会各领域的普遍做法。
本文从iris数据集出发,利用C5.0分类技术对该数据集进行分类分析,找出隐藏在其中的关于鸢尾属下三个亚属的分类规则,达到对鸢尾属未知亚属进行分类并预测未知样本的类别的目的。
【关键词】数据挖掘,分类,决策树,C5.0算法一、引言随着计算机技术的迅猛发展,信息技术已经开始贯穿于人类活动的各个领域。
紧跟其后的便是信息技术的飞速发展和信息搜集能力的日益提高,继而产生了海量的数据。
为了挖掘这些激增的数据背后所隐藏的重要信息,机器学习、数据挖掘等技术应运而生。
数据挖掘源于20世纪80年代后期,包含着很多领域,分类就是其中之一,并且是数据挖掘中最有应用价值的技术之一,为工业、金融、通信、医疗、银行、商业等诸多行业的发展提供着重要的决策支撑作用,对人类的日常生活及社会的稳定快读发展产生了深远的影响。
二、分类分析在数据挖掘中可用于分类的算法很多,目前所采取的方法主要有:决策树、贝叶斯分类、粗糙集、遗传算法和神经网络等,决策树方法因其复杂度较小,速度快;抗噪声能力强;可伸缩性强,既可用于小数据集,也可用于海量数据集等优点而得到广泛的应用。
也正因为如此决策树算法成为了数据挖掘研究中最为活跃的领域之一。
故本文选择基于决策树的分类挖掘方法作为研究课题。
三、具体应用说明1.数据准备。
在UCI数据库中找到iris标准数据集。
Iris data set,也称鸢尾花卉数据集,是一类多重变量分析的数据集。
其数据集包含了150个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾(Iris setosa),变色鸢尾(Iris versicolor)和维吉尼亚鸢尾(Iris virginica)。
四个特征被用作样本的定量分析,分别是花萼和花瓣的长度和宽度。

python决策树经典案例以Python决策树经典案例为题,列举以下十个案例。
1. 预测鸢尾花品种鸢尾花数据集是一个经典的分类问题,其中包含了三个不同品种的鸢尾花的测量数据。
通过使用决策树算法,我们可以根据花瓣和花萼的长度、宽度等特征,预测鸢尾花的品种。
2. 判断信用卡申请的风险在信用卡申请过程中,银行需要评估申请人的信用风险。
使用决策树算法,我们可以根据申请人的个人信息(如年龄、收入、债务等),预测其信用卡申请是否有风险。
3. 识别垃圾邮件垃圾邮件是每个人都会遇到的问题,而决策树可以帮助我们自动识别垃圾邮件。
通过对邮件的主题、发送者、内容等特征进行分析,决策树可以判断一封邮件是否为垃圾邮件。
4. 预测房价房价预测是房地产市场中的一个重要问题。
通过使用决策树算法,我们可以根据房屋的各种特征(如面积、地理位置、卧室数量等),预测房屋的价格。
5. 识别植物病害农作物病害的及时识别对于农业生产非常重要。
使用决策树算法,可以根据植物叶片的形状、颜色、纹理等特征,判断植物是否受到病害的侵袭。
6. 预测股票涨跌股票市场的波动性很大,而决策树可以用来预测股票的涨跌。
通过分析股票的历史数据和各种市场指标,决策树可以预测股票的未来走势。
7. 判断病人是否患有某种疾病医疗诊断是决策树算法的另一个应用领域。
通过分析病人的症状、体征等信息,决策树可以帮助医生判断病人是否患有某种疾病,并给出相应的治疗建议。
8. 预测客户流失率对于一家公司来说,客户流失是一个重要的问题。
通过使用决策树算法,我们可以根据客户的消费行为、购买记录等信息,预测客户的流失率,并采取相应的措施来留住客户。
9. 判断某人是否适合借贷在金融行业中,决策树可以用来评估某个人是否适合借贷。
通过分析个人的收入、信用记录、职业等信息,决策树可以判断一个人是否有能力偿还借款。
10. 识别手写数字手写数字识别是机器学习领域中的一个经典问题。
通过使用决策树算法,可以根据手写数字的像素点信息,准确地识别出手写数字是哪个数字。

鸢尾花分类所用的算法
鸢尾花分类是机器学习领域中一个经典的问题,常用的算法包括K近邻算法(K-Nearest Neighbors, KNN)、支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree)、随机森林(Random Forest)、朴素贝叶斯(Naive Bayes)和神经网络等。
K近邻算法是一种基于实例的学习方法,它根据新样本与已知样本的距离来进行分类,选择距离最近的K个样本进行投票决定分类结果。
支持向量机是一种监督学习算法,它通过将数据映射到高维空间,找到一个最优的超平面来进行分类。
决策树是一种树形结构的分类器,通过一系列的规则对数据进行划分,最终得到分类结果。
随机森林是一种集成学习方法,它由多个决策树组成,通过对多个决策树的结果进行投票来进行分类。
朴素贝叶斯是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立,通过计算样本属于每个类别的概率来进行分类。
神经网络是一种模仿人脑神经元网络结构的算法,通过多层神经元的连接和权重调整来进行分类。
这些算法在鸢尾花分类问题中都有较好的表现,选择合适的算法取决于数据集的特征、样本量、计算资源和准确度要求等因素。
同时,也可以通过交叉验证等方法来评估不同算法的性能,以选择最适合的算法进行鸢尾花分类。

决策树算法对鸢尾花数据集进⾏分类①导⼊相关扩展包from sklearn.tree import DecisionTreeClassifierfrom sklearn.tree import export_graphviz②获取数据集iris = load_iris()③划分数据集x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=20)④决策树预估器(estimator)estimator=DecisionTreeClassifier(criterion="entropy") #criterion默认为'gini'系数,也可选择信息增益熵'entropy'estimator.fit(x_train,y_train) #调⽤fit()⽅法进⾏训练,()内为训练集的特征值与⽬标值⑤模型评估⽅法⼀:直接对⽐测试集的真实值和预测值y_predict=estimator.predict(x_test) #传⼊测试集特征值,预测所给测试集的⽬标值print("y_predict:\n",y_predict)print("直接对⽐真实值和预测值:\n",y_test==y_predict)⽅法⼆:计算准确率score=estimator.score(x_test,y_test) #传⼊测试集的特征值和⽬标值⑥决策树可视化(将结果写⼊tree.dot⽂件中,然后将tree.dot⽂件中的内容粘贴在中进⾏可视化展⽰export_graphviz(estimator, out_file="tree.dot", feature_names=iris.feature_names)主要代码:def decision_demo():# 1.获取数据集iris = load_iris()# 2.划分数据集x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=20)# 3.决策树预估器(estimator)estimator=DecisionTreeClassifier(criterion="entropy") #criterion默认为'gini'系数,也可选择信息增益熵'entropy'estimator.fit(x_train,y_train) #调⽤fit()⽅法进⾏训练,()内为训练集的特征值与⽬标值# 4.模型评估#⽅法⼀:直接对⽐真实值和预测值y_predict=estimator.predict(x_test) #传⼊测试集特征值,预测所给测试集的⽬标值print("y_predict:\n",y_predict)print("直接对⽐真实值和预测值:\n",y_test==y_predict)#⽅法⼆:计算准确率score=estimator.score(x_test,y_test) #传⼊测试集的特征值和⽬标值print("准确率为:\n",score)#决策树可视化export_graphviz(estimator,out_file="tree.dot",feature_names=iris.feature_names)return None代码运⾏结果:可视化展⽰结果:注:可视化展⽰中,feature_names=iris.feature_names缺省会出现特征值名称缺失现象,如下图所⽰:。

决策树DTC数据分析及鸢尾数据集分析在当今数据驱动的时代,数据分析技术变得越来越重要。
决策树(Decision Tree,DTC)作为一种强大而直观的数据分析方法,在各个领域都有着广泛的应用。
同时,鸢尾数据集作为经典的数据集之一,常被用于检验和展示各种数据分析方法的效果。
接下来,让我们深入探讨决策树在数据分析中的应用,并以鸢尾数据集为例进行详细分析。
决策树是一种类似于流程图的树形结构,通过对数据的特征进行逐步判断和分支,最终得出预测结果或分类结论。
它的基本思想是基于“分而治之”的原则,将复杂的问题逐步分解为更简单的子问题。
决策树的构建过程通常包括特征选择、分裂节点的确定以及树的修剪等步骤。
在特征选择阶段,需要找到能够最好地将数据划分成不同类别的特征。
这通常通过计算信息增益、信息熵等指标来实现。
分裂节点的确定则是根据所选特征的取值来将数据集分割成不同的子集。
而树的修剪则是为了防止过拟合,即避免决策树过于复杂而对训练数据过度拟合,导致对新数据的预测能力下降。
鸢尾数据集是一个非常经典的数据集,它包含了 150 个鸢尾花的样本,每个样本有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
同时,这些样本被分为三种不同的鸢尾花类别:山鸢尾(Iris setosa)、变色鸢尾(Iris versicolor)和维吉尼亚鸢尾(Iris virginica)。
为了使用决策树对鸢尾数据集进行分析,首先需要将数据集加载到数据分析环境中,并对数据进行预处理,例如检查数据的完整性和准确性,处理缺失值等。
然后,可以使用各种机器学习库(如scikitlearn)中提供的决策树算法来构建模型。
在构建决策树模型时,算法会自动选择最佳的特征和分裂点来构建树结构。
通过观察构建好的决策树,可以直观地了解到不同特征对于分类的重要性以及分类的决策过程。
例如,如果决策树首先根据花瓣长度进行分裂,那么说明花瓣长度在区分不同鸢尾花类别中起到了较为重要的作用。
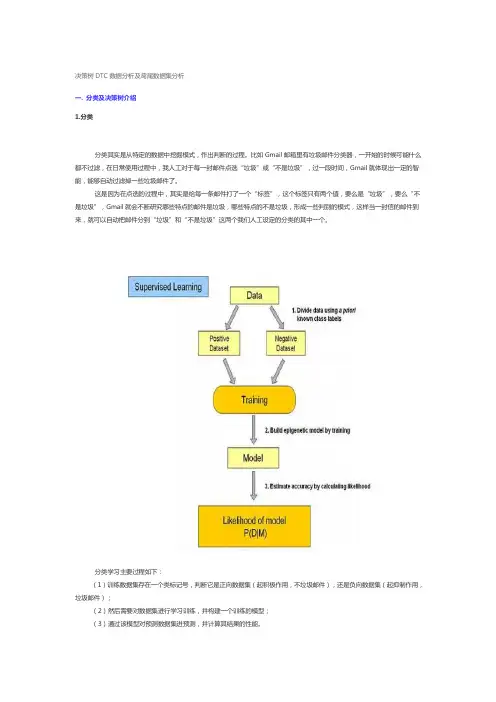
决策树DTC数据分析及鸢尾数据集分析一. 分类及决策树介绍1.分类分类其实是从特定的数据中挖掘模式,作出判断的过程。
比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选“垃圾”或“不是垃圾”,过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了。
这是因为在点选的过程中,其实是给每一条邮件打了一个“标签”,这个标签只有两个值,要么是“垃圾”,要么“不是垃圾”,Gmail就会不断研究哪些特点的邮件是垃圾,哪些特点的不是垃圾,形成一些判别的模式,这样当一封信的邮件到来,就可以自动把邮件分到“垃圾”和“不是垃圾”这两个我们人工设定的分类的其中一个。
分类学习主要过程如下:(1)训练数据集存在一个类标记号,判断它是正向数据集(起积极作用,不垃圾邮件),还是负向数据集(起抑制作用,垃圾邮件);(2)然后需要对数据集进行学习训练,并构建一个训练的模型;(3)通过该模型对预测数据集进预测,并计算其结果的性能。
2.决策树(decision tree)决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。
构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。
它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。
决策树算法根据数据的属性采用树状结构建立决策模型,决策树模型常用来解决分类和回归问题。
常见的算法包括:分类及回归树(Classification And Regression Tree,CART),ID3 (Iterative Dichotomiser 3),C4.5,Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest),多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine,GBM)。

利⽤Matlab对经典鸢尾花数据集实现决策树算法分类,并绘图最近在学习数据挖掘,其实决策树分类看过去好久了,但是最近慢慢的想都实现⼀下,加深⼀下理解。
知道决策树有很多现成的算法(ID3,C4.5、CART),但是毕竟核⼼思想就是那⼏点,所以本篇博客就是我随便实现的,没有参考现有的决策树算法。
考虑到实现分类起码需要⼀个数据集,所以我选择了经典的鸢尾花数据集,下载地址:选择iris.data点击右键连接另存为,即可下载,我是下载到桌⾯,⽂档为iris.data.txt5.1,3.5,1.4,0.2,Iris-setosa4.9,3.0,1.4,0.2,Iris-setosa4.7,3.2,1.3,0.2,Iris-setosa4.6,3.1,1.5,0.2,Iris-setosa5.0,3.6,1.4,0.2,Iris-setosa5.4,3.9,1.7,0.4,Iris-setosa4.6,3.4,1.4,0.3,Iris-setosa5.0,3.4,1.5,0.2,Iris-setosa4.4,2.9,1.4,0.2,Iris-setosa4.9,3.1,1.5,0.1,Iris-setosa5.4,3.7,1.5,0.2,Iris-setosa4.8,3.4,1.6,0.2,Iris-setosa4.8,3.0,1.4,0.1,Iris-setosa4.3,3.0,1.1,0.1,Iris-setosa5.8,4.0,1.2,0.2,Iris-setosa5.7,4.4,1.5,0.4,Iris-setosa5.4,3.9,1.3,0.4,Iris-setosa5.1,3.5,1.4,0.3,Iris-setosa5.7,3.8,1.7,0.3,Iris-setosa5.1,3.8,1.5,0.3,Iris-setosa5.4,3.4,1.7,0.2,Iris-setosa5.1,3.7,1.5,0.4,Iris-setosa4.6,3.6,1.0,0.2,Iris-setosa5.1,3.3,1.7,0.5,Iris-setosa4.8,3.4,1.9,0.2,Iris-setosa5.0,3.0,1.6,0.2,Iris-setosa5.0,3.4,1.6,0.4,Iris-setosa5.2,3.5,1.5,0.2,Iris-setosa5.2,3.4,1.4,0.2,Iris-setosa4.7,3.2,1.6,0.2,Iris-setosa4.8,3.1,1.6,0.2,Iris-setosa5.4,3.4,1.5,0.4,Iris-setosa5.2,4.1,1.5,0.1,Iris-setosa5.5,4.2,1.4,0.2,Iris-setosa4.9,3.1,1.5,0.1,Iris-setosa5.0,3.2,1.2,0.2,Iris-setosa5.5,3.5,1.3,0.2,Iris-setosa4.9,3.1,1.5,0.1,Iris-setosa4.4,3.0,1.3,0.2,Iris-setosa5.1,3.4,1.5,0.2,Iris-setosa5.0,3.5,1.3,0.3,Iris-setosa4.5,2.3,1.3,0.3,Iris-setosa4.4,3.2,1.3,0.2,Iris-setosa5.0,3.5,1.6,0.6,Iris-setosa5.0,3.5,1.6,0.6,Iris-setosa 5.1,3.8,1.9,0.4,Iris-setosa4.8,3.0,1.4,0.3,Iris-setosa5.1,3.8,1.6,0.2,Iris-setosa4.6,3.2,1.4,0.2,Iris-setosa5.3,3.7,1.5,0.2,Iris-setosa 5.0,3.3,1.4,0.2,Iris-setosa 7.0,3.2,4.7,1.4,Iris-versicolor6.4,3.2,4.5,1.5,Iris-versicolor 6.9,3.1,4.9,1.5,Iris-versicolor5.5,2.3,4.0,1.3,Iris-versicolor6.5,2.8,4.6,1.5,Iris-versicolor5.7,2.8,4.5,1.3,Iris-versicolor6.3,3.3,4.7,1.6,Iris-versicolor 4.9,2.4,3.3,1.0,Iris-versicolor 6.6,2.9,4.6,1.3,Iris-versicolor 5.2,2.7,3.9,1.4,Iris-versicolor 5.0,2.0,3.5,1.0,Iris-versicolor5.9,3.0,4.2,1.5,Iris-versicolor6.0,2.2,4.0,1.0,Iris-versicolor 6.1,2.9,4.7,1.4,Iris-versicolor5.6,2.9,3.6,1.3,Iris-versicolor6.7,3.1,4.4,1.4,Iris-versicolor 5.6,3.0,4.5,1.5,Iris-versicolor5.8,2.7,4.1,1.0,Iris-versicolor6.2,2.2,4.5,1.5,Iris-versicolor 5.6,2.5,3.9,1.1,Iris-versicolor5.9,3.2,4.8,1.8,Iris-versicolor6.1,2.8,4.0,1.3,Iris-versicolor 6.3,2.5,4.9,1.5,Iris-versicolor 6.1,2.8,4.7,1.2,Iris-versicolor 6.4,2.9,4.3,1.3,Iris-versicolor 6.6,3.0,4.4,1.4,Iris-versicolor 6.8,2.8,4.8,1.4,Iris-versicolor 6.7,3.0,5.0,1.7,Iris-versicolor 6.0,2.9,4.5,1.5,Iris-versicolor 5.7,2.6,3.5,1.0,Iris-versicolor 5.5,2.4,3.8,1.1,Iris-versicolor 5.5,2.4,3.7,1.0,Iris-versicolor5.8,2.7,3.9,1.2,Iris-versicolor6.0,2.7,5.1,1.6,Iris-versicolor5.4,3.0,4.5,1.5,Iris-versicolor6.0,3.4,4.5,1.6,Iris-versicolor 6.7,3.1,4.7,1.5,Iris-versicolor 6.3,2.3,4.4,1.3,Iris-versicolor 5.6,3.0,4.1,1.3,Iris-versicolor 5.5,2.5,4.0,1.3,Iris-versicolor5.5,2.6,4.4,1.2,Iris-versicolor6.1,3.0,4.6,1.4,Iris-versicolor 5.8,2.6,4.0,1.2,Iris-versicolor 5.0,2.3,3.3,1.0,Iris-versicolor 5.6,2.7,4.2,1.3,Iris-versicolor 5.7,3.0,4.2,1.2,Iris-versicolor5.7,2.9,4.2,1.3,Iris-versicolor6.2,2.9,4.3,1.3,Iris-versicolor 5.1,2.5,3.0,1.1,Iris-versicolor5.1,2.5,3.0,1.1,Iris-versicolor5.7,2.8,4.1,1.3,Iris-versicolor6.3,3.3,6.0,2.5,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica7.1,3.0,5.9,2.1,Iris-virginica 6.3,2.9,5.6,1.8,Iris-virginica6.5,3.0,5.8,2.2,Iris-virginica7.6,3.0,6.6,2.1,Iris-virginica 4.9,2.5,4.5,1.7,Iris-virginica 7.3,2.9,6.3,1.8,Iris-virginica6.7,2.5,5.8,1.8,Iris-virginica7.2,3.6,6.1,2.5,Iris-virginica 6.5,3.2,5.1,2.0,Iris-virginica 6.4,2.7,5.3,1.9,Iris-virginica 6.8,3.0,5.5,2.1,Iris-virginica 5.7,2.5,5.0,2.0,Iris-virginica5.8,2.8,5.1,2.4,Iris-virginica6.4,3.2,5.3,2.3,Iris-virginica6.5,3.0,5.5,1.8,Iris-virginica7.7,3.8,6.7,2.2,Iris-virginica 7.7,2.6,6.9,2.3,Iris-virginica 6.0,2.2,5.0,1.5,Iris-virginica 6.9,3.2,5.7,2.3,Iris-virginica 5.6,2.8,4.9,2.0,Iris-virginica 7.7,2.8,6.7,2.0,Iris-virginica 6.3,2.7,4.9,1.8,Iris-virginica6.7,3.3,5.7,2.1,Iris-virginica7.2,3.2,6.0,1.8,Iris-virginica 6.2,2.8,4.8,1.8,Iris-virginica 6.1,3.0,4.9,1.8,Iris-virginica6.4,2.8,5.6,2.1,Iris-virginica7.2,3.0,5.8,1.6,Iris-virginica 7.4,2.8,6.1,1.9,Iris-virginica 7.9,3.8,6.4,2.0,Iris-virginica 6.4,2.8,5.6,2.2,Iris-virginica 6.3,2.8,5.1,1.5,Iris-virginica6.1,2.6,5.6,1.4,Iris-virginica7.7,3.0,6.1,2.3,Iris-virginica 6.3,3.4,5.6,2.4,Iris-virginica 6.4,3.1,5.5,1.8,Iris-virginica 6.0,3.0,4.8,1.8,Iris-virginica 6.9,3.1,5.4,2.1,Iris-virginica 6.7,3.1,5.6,2.4,Iris-virginica 6.9,3.1,5.1,2.3,Iris-virginica5.8,2.7,5.1,1.9,Iris-virginica6.8,3.2,5.9,2.3,Iris-virginica 6.7,3.3,5.7,2.5,Iris-virginica 6.7,3.0,5.2,2.3,Iris-virginica 6.3,2.5,5.0,1.9,Iris-virginica 6.5,3.0,5.2,2.0,Iris-virginica 6.2,3.4,5.4,2.3,Iris-virginica 5.9,3.0,5.1,1.8,Iris-virginica将数据集载⼊matlab参考function [attrib]=Iris_tree_preprocess( )%数据预处理[attrib1, attrib2, attrib3, attrib4, class] = textread('C:\Users\Administrator\Desktop\iris.data', '%f%f%f%f%s', 'delimiter', ',');% delimiter , 是跳过符号“,”a = zeros(150, 1);a(strcmp(class, 'Iris-setosa')) = 1;a(strcmp(class, 'Iris-versicolor')) = 2;a(strcmp(class, 'Iris-virginica')) = 3;%% 导⼊鸢yuan尾花数据for i=1:150attrib(i,1)=attrib1(i);attrib(i,2)=attrib2(i);attrib(i,3)=attrib3(i);attrib(i,4)=attrib4(i);attrib(i,5)=a(i);endend完成这⼀步后,我们会得到四个属性集的矩阵和进⾏了类别转化的a矩阵。

实验名称:分类实验一、实验目的1. 理解分类的基本概念和方法。
2. 掌握分类算法的实现和应用。
3. 分析不同分类算法的优缺点,提高对分类问题的解决能力。
二、实验内容1. 数据集准备本实验使用鸢尾花(Iris)数据集进行分类实验。
鸢尾花数据集包含150个样本,每个样本有4个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和1个类别标签(3种鸢尾花之一)。
2. 分类算法本次实验主要介绍以下分类算法:(1)K最近邻(KNN)(2)支持向量机(SVM)(3)决策树(4)随机森林3. 实验步骤(1)导入数据集使用Python的pandas库读取鸢尾花数据集。
(2)数据预处理对数据进行标准化处理,使不同特征的数值范围一致。
(3)划分训练集和测试集将数据集划分为训练集和测试集,比例分别为7:3。
(4)模型训练使用训练集对KNN、SVM、决策树和随机森林模型进行训练。
(5)模型评估使用测试集对训练好的模型进行评估,计算准确率、召回率、F1值等指标。
(6)结果分析比较不同分类算法的评估指标,分析各算法的优缺点。
三、实验结果与分析1. 数据预处理将鸢尾花数据集的4个特征进行标准化处理,使其数值范围在0到1之间。
2. 划分训练集和测试集将数据集划分为7:3的训练集和测试集。
3. 模型训练与评估(1)KNN设置K值为3,使用训练集训练KNN模型,然后在测试集上进行评估。
准确率为0.9778,召回率为0.9778,F1值为0.9778。
(2)SVM设置SVM的核函数为径向基函数(RBF),C值为1,gamma值为0.001。
使用训练集训练SVM模型,然后在测试集上进行评估。
准确率为0.9778,召回率为0.9778,F1值为0.9778。
(3)决策树设置决策树的深度为3,使用训练集训练决策树模型,然后在测试集上进行评估。
准确率为0.9778,召回率为0.9778,F1值为0.9778。
(4)随机森林设置随机森林的树数量为100,使用训练集训练随机森林模型,然后在测试集上进行评估。

对鸢尾花数据进⾏分类的思路对鸢尾花数据进⾏分类1 数据集处理加载数据集,IRIS 数据集在 sklearn 模块中已经提供from sklearn import datasetsiris = datasets.load_iris()iris_feature = iris.datairis_target = iris.target将150个样本分割为90个训练集和60个测试集feature_train, feature_test, target_train, target_test = train_test_split(iris_feature, iris_target, test_size=0.4,random_state=40)2 决策树分类(实现)这⾥选⽤CART算法。
算法从根节点开始,⽤训练集递归构建分类树。
在决策树的构建中,有时会造成决策树分⽀过多,这是就需要去掉⼀些分⽀,降低过度拟合。
通过决策树的复杂度来避免过度拟合的过程称为剪枝。
创建决策树:步骤1:选择GiniIndex最⼩的维度作为分割特征。
(GiniIndex计算⽅式见PPT)步骤2:如果数据集不能再分割,即GiniIndex为0或只有⼀个数据,该数据集作为⼀个叶⼦节点。
步骤3:对数据集进⾏⼆分割步骤4:对分割的数据集1重复步骤1、2、3,创建true⼦树步骤5:对分割的数据集2重复步骤1、2、3,创建false⼦树明显的递归算法。
剪枝:需要从训练集⽣成⼀棵完整的决策树,然后⾃底向上对⾮叶⼦节点进⾏考察。
判断是否将该节点对应的⼦树替换成叶节点。
当节点的gain⼩于给定的 mini Gain时则合并这两个节点.。
测试:通过对测试集的预测来验证准确性。
对于不同的划分⽅式,即选取不同随机数种⼦且保持90:60的⽐例,训练集准确率为:100 %,测试集准确率为:91.67 %3 SVM分类(调库)⽀持向量机的基本模型是定义在特征空间上的间隔最⼤的线性分类器,即求⼀个分离超平⾯,这个超平⾯使得离它最近的点能够最远。

鸢尾花分类项目鸢尾花分类项目是一个经典的机器学习案例,也是数据科学的一个入门项目。
该项目主要通过收集不同种类的鸢尾花的数据特征,来训练机器学习模型,以分类鸢尾花的种类。
本文将讨论鸢尾花分类项目的背景、实现方式和优化方法。
项目背景鸢尾花是一种不同种类的花卉,如维基百科所述:"Iris是一个属名,包括275个品种,生长在北半球中温带区域。
"。
每个品种的鸢尾花都有不同的特征,这种特征可以帮助我们区分不同品种的鸢尾花。
鸢尾花分类项目就是要了解这些特征,并且训练模型来正确地识别每个品种的鸢尾花。
项目实现该项目的实现是通过`scikit-learn`机器学习库中的`load_iris()`函数,读取包含150个样本的数据集。
每个样本都包含4个特征:花瓣长度、花瓣宽度、萼片长度和萼片宽度。
将这些特征与标签一起用于监督式学习模型分类。
数据集中有三种类型的鸢尾花:Setosa、Versicolor和Virginica。
我们使用算法来训练模型并对新的鸢尾花进行分类。
分类算法下面介绍两个常用的分类算法:逻辑回归(Logistic Regression):逻辑回归是一个线性模型,可以用来预测具有二元结果的输出。
在鸢尾花分类项目中,可以将数据集分为两个类别,并在此基础上训练逻辑回归模型。
该模型将根据所提供的特征来预测一个给定的鸢尾花的种类。
决策树(Decision Tree):决策树是一种集成算法,可以处理特征之间的非线性关系,并能够处理多元回归问题。
在鸢尾花分类项目中,我们可以利用决策树来快速生成可视化分类器,查询数据的流程就像一个问题对话。
通过对问题的回答,可以判断鸢尾花的类别。
优化方法鸢尾花分类项目中的优化包括以下几个方面:数据集划分:将数据集分为测试集和训练集,并使用训练集来训练模型,测试集来验证模型的准确性。
例如通常要将数据集按80:20的比例进行划分。
网格搜索(Grid Search):网格搜索是一种用于确定模型参数设置的方法。
基于决策树的鸢尾花分类决策树技术是一种流行的分类算法,它能够将复杂的数据集根据一定的特征结构进行划分,这里我们尝试将决策树技术应用到鸢尾花的分类问题上。
首先介绍一下鸢尾花的基本信息,鸢尾花是一种典型的Iris属植物,这里我们将专注于它的三种品种,包括Setosa,Versicolor 和Virginica。
它们的主要特征有花瓣、花萼、花柄和叶片的长度和宽度,这些特征都是不可省略的分类属性。
接下来我们介绍一下使用决策树构建鸢尾花分类器的步骤:(1)获取鸢尾花的特征数据:根据鸢尾花的主要属性将数据集划分为训练集和测试集,使用熟悉的统计学方法,获取数据集中所有特征的概率分布,同时计算出训练集中各类鸢尾花的数量;(2)选择决策树算法:训练样本中各类鸢尾花的分布应该比较均衡,否则需要进行数据采样补偿,以保证模型具有较高的准确性;(3)建立决策树分类器模型:使用决策树算法构建决策树模型,即将特征的概率分布函数作为输入,根据每一步决策的信息熵值进行排序,一直迭代构建决策树,最后得到一个完整的决策树模型;(4)评估分类器模型的性能:将测试集中的样本经过决策树分类器进行分类,比较分类结果与真实标签的差异,以计算准确率,评估模型的性能;(5)确定最优参数:通过多次模型训练和评估,调节参数来寻求最优模型,使模型的性能达到最佳。
决策树的优点在于能够以清晰直观的方式建模生成结果,且参数调节相对较为容易。
由于鸢尾花的特征属性特征值差异不大,因此决策树技术能够较好地拟合出鸢尾花分类器模型。
最后,由于决策树模型可以以图形的方式进行可视化,从而可以更加直观地观察模型优缺点,找出改进模型的方向,以优化模型的性能。
因此,决策树技术在鸢尾花分类任务中应用较为成功,可以有效提高分类的性能。
总之,基于决策树的鸢尾花分类在实践中显示出较高的准确性和鲁棒性,可以有效和有效地将鸢尾花的特征属性分类。
一、实验背景与目的决策树是一种常用的机器学习分类算法,它通过树形结构对数据进行分类,具有直观、易于理解和解释的特点。
本实验旨在通过构建决策树模型,对某数据集进行分类,并评估模型性能。
二、实验环境与数据1. 实验环境:- 操作系统:Windows 10- 编程语言:Python- 数据处理库:Pandas、NumPy- 机器学习库:Scikit-learn2. 数据集:本实验采用鸢尾花数据集(Iris dataset),该数据集包含150个样本,每个样本有4个特征(花瓣长度、花瓣宽度、花萼长度、花萼宽度)和1个标签(类别:Iris-setosa、Iris-versicolor、Iris-virginica)。
三、实验步骤1. 数据预处理:- 加载数据集,并使用Pandas库进行数据清洗和预处理。
- 将数据集分为训练集和测试集,采用8:2的比例。
- 对数据进行归一化处理,使特征值在[0, 1]范围内。
2. 决策树模型构建:- 使用Scikit-learn库中的DecisionTreeClassifier类构建决策树模型。
- 设置模型参数,如树的深度、最大叶子节点数等。
3. 模型训练:- 使用训练集对决策树模型进行训练。
4. 模型评估:- 使用测试集对训练好的模型进行评估,计算分类准确率、召回率、F1值等指标。
5. 结果分析:- 分析模型的性能,并探讨不同参数设置对模型性能的影响。
四、实验结果与分析1. 模型参数设置:- 树的深度:10- 最大叶子节点数:202. 模型性能评估:- 分类准确率:0.9778- 召回率:0.9778- F1值:0.97783. 结果分析:- 决策树模型在鸢尾花数据集上取得了较好的分类效果,准确率达到97.78%。
- 通过调整模型参数,可以进一步提高模型性能。
- 决策树模型易于理解和解释,有助于分析数据特征和分类规则。
五、实验结论本实验通过构建决策树模型,对鸢尾花数据集进行分类,并取得了较好的分类效果。
基于R的决策树在鸢尾花分类上的应用附件1是150个鸢尾花样本数据:编号、Sepal.Length萼片长、Sepal.Width萼片宽、Petal.Length花瓣长、Petal.Width花瓣宽、以及Species种类。
其中121至150号样本种类数据可能存在错误。
试建立决策树模型,预测121至150号样本种类。
1)建立决策树模型,通过Sepal.Length,Sepal.Width,Petal.Length,Petal.Width,预测鸢尾花种类Species,并输出决策树规则;2)评估模型性能(给出上述模型预测正确率);3)使用上述模型,预测121至150号样本种类;附件1:鸢尾花样本数据编号Sepal.Length Sepal.Width Petal.Length Petal.Width Species1 5.7 4.4 1.50.4setosa2 5.5 4.2 1.40.2setosa3 5.2 4.1 1.50.1setosa4 5.84 1.20.2setosa5 5.4 3.9 1.30.4setosa6 5.4 3.9 1.70.4setosa7 5.1 3.8 1.50.3setosa8 5.1 3.8 1.60.2setosa9 5.7 3.8 1.70.3setosa10 5.1 3.8 1.90.4setosa117.9 3.8 6.42virginica127.7 3.8 6.7 2.2virginica13 5.1 3.7 1.50.4setosa14 5.3 3.7 1.50.2setosa15 5.4 3.7 1.50.2setosa16 4.6 3.610.2setosa175 3.6 1.40.2setosa18 4.9 3.6 1.40.1setosa197.2 3.6 6.1 2.5virginica205 3.5 1.30.3setosa21 5.5 3.5 1.30.2setosa22 5.1 3.5 1.40.3setosa23 5.1 3.5 1.40.2setosa24 5.2 3.5 1.50.2setosa255 3.5 1.60.6setosa26 4.6 3.4 1.40.3setosa27 5.2 3.4 1.40.2setosa28 5.4 3.4 1.50.4setosa295 3.4 1.50.2setosa30 5.1 3.4 1.50.2setosa315 3.4 1.60.4setosa32 4.8 3.4 1.60.2setosa33 5.4 3.4 1.70.2setosa34 4.8 3.4 1.90.2setosa356 3.4 4.5 1.6versicolor36 6.2 3.4 5.4 2.3virginica37 6.3 3.4 5.6 2.4virginica 385 3.3 1.40.2setosa39 5.1 3.3 1.70.5setosa40 6.3 3.3 4.7 1.6versicolor41 6.7 3.3 5.7 2.5virginica42 6.7 3.3 5.7 2.1virginica43 6.3 3.36 2.5virginica 445 3.2 1.20.2setosa45 4.4 3.2 1.30.2setosa46 4.7 3.2 1.30.2setosa47 4.6 3.2 1.40.2setosa48 4.7 3.2 1.60.2setosa49 6.4 3.2 4.5 1.5versicolor 507 3.2 4.7 1.4versicolor51 5.9 3.2 4.8 1.8versicolor52 6.5 3.2 5.12virginica53 6.4 3.2 5.3 2.3virginica54 6.9 3.2 5.7 2.3virginica55 6.8 3.2 5.9 2.3virginica 567.2 3.26 1.8virginica57 4.6 3.1 1.50.2setosa58 4.9 3.1 1.50.2setosa59 4.9 3.1 1.50.1setosa60 4.8 3.1 1.60.2setosa61 6.7 3.1 4.4 1.4versicolor62 6.7 3.1 4.7 1.5versicolor63 6.9 3.1 4.9 1.5versicolor64 6.9 3.1 5.1 2.3virginica65 6.9 3.1 5.4 2.1virginica66 6.4 3.1 5.5 1.8virginica67 6.7 3.1 5.6 2.4virginica68 4.33 1.10.1setosa69 4.43 1.30.2setosa70 4.83 1.40.3setosa71 4.93 1.40.2setosa72 4.83 1.40.1setosa 7353 1.60.2setosa74 5.63 4.1 1.3versicolor75 5.93 4.2 1.5versicolor76 5.73 4.2 1.2versicolor77 6.63 4.4 1.4versicolor78 5.43 4.5 1.5versicolor79 5.63 4.5 1.5versicolor80 6.13 4.6 1.4versicolor 8163 4.8 1.8virginica82 6.13 4.9 1.8virginica83 6.735 1.7versicolor84 5.93 5.1 1.8virginica85 6.73 5.2 2.3virginica86 6.53 5.22virginica87 6.83 5.5 2.1virginica88 6.53 5.5 1.8virginica89 6.53 5.8 2.2virginica 907.23 5.8 1.6virginica 917.13 5.9 2.1virginica 927.73 6.1 2.3virginica 937.63 6.6 2.1virginica94 4.4 2.9 1.40.2setosa95 5.6 2.9 3.6 1.3versicolor96 5.7 2.9 4.2 1.3versicolor97 6.2 2.9 4.3 1.3versicolor98 6.4 2.9 4.3 1.3versicolor 996 2.9 4.5 1.5versicolor 100 6.6 2.9 4.6 1.3versicolor 101 6.1 2.9 4.7 1.4versicolor 102 6.3 2.9 5.6 1.8virginica 1037.3 2.9 6.3 1.8virginica 104 6.1 2.84 1.3versicolor 105 5.7 2.8 4.1 1.3versicolor 106 5.7 2.8 4.5 1.3versicolor 107 6.5 2.8 4.6 1.5versicolor 108 6.1 2.8 4.7 1.2versicolor 109 6.2 2.8 4.8 1.8virginica 110 6.8 2.8 4.8 1.4versicolor 111 5.6 2.8 4.92virginica112 5.8 2.8 5.1 2.4virginica 113 6.3 2.8 5.1 1.5virginica 114 6.4 2.8 5.6 2.2virginica 115 6.4 2.8 5.6 2.1virginica 1167.4 2.8 6.1 1.9virginica 1177.7 2.8 6.72virginica 118 5.2 2.7 3.9 1.4versicolor 119 5.8 2.7 3.9 1.2versicolor 120 5.8 2.7 4.11versicolor 121 5.6 2.7 4.2 1.3versicolor 122 6.3 2.7 4.9 1.8virginica 123 5.8 2.7 5.1 1.9virginica 124 5.8 2.7 5.1 1.9virginica 1256 2.7 5.1 1.6versicolor 126 6.4 2.7 5.3 1.9virginica 127 5.7 2.6 3.51versicolor 128 5.8 2.64 1.2versicolor 129 5.5 2.6 4.4 1.2versicolor 130 6.1 2.6 5.6 1.4virginica 1317.7 2.6 6.9 2.3virginica 132 5.1 2.53 1.1versicolor 133 5.6 2.5 3.9 1.1versicolor 134 5.5 2.54 1.3versicolor 135 4.9 2.5 4.5 1.7virginica 136 6.3 2.5 4.9 1.5versicolor 137 5.7 2.552virginica 138 6.3 2.55 1.9virginica 139 6.7 2.5 5.8 1.8virginica 140 4.9 2.4 3.31versicolor 141 5.5 2.4 3.71versicolor 142 5.5 2.4 3.8 1.1versicolor 143 4.5 2.3 1.30.3setosa 1445 2.3 3.31versicolor 145 5.5 2.34 1.3versicolor 146 6.3 2.3 4.4 1.3versicolor 1476 2.241versicolor 148 6.2 2.2 4.5 1.5versicolor 1496 2.25 1.5virginica 15052 3.51versicolor使用R语言对鸢尾花数据建立决策树模型,结果如下:1)决策树如图所示2)上面的决策树模型不复杂,性能较好,预测准确率达97.5%3)根据上述模型对121号至150号样本种类预测结果如下121122123124125126 virginica virginica virginica versicolor vi 127128129130131132 versicolor versicolor versicolor virginica ver 133134135136137138 versicolor versicolor versicolor virginica vi 139140141142143144 virginica versicolor versicolor versicolor setosa vers 145146147148149150 versicolor versicolor versicolor versicolor ver setosa versicolor virginica附R代码:flower<-read.csv("鸢尾花数据.csv",header=T)#读取数据View(flower)#浏览表数据str(flower)#查看表结构1506123456789105.75.55.25.85.45.45.15.15.75. 14.44.24.143.93.93.83.83.83.81.51.41.51.21.31.71.51.61.71. 90.40.20.10.20.40.40.30.20.30. 431111111111summary(flower)#查看数据汇总1.000038.2560075.5035075.505810000library(rpart)#加载决策树包library(rpart.plot)#加载决策树绘图包train_flower<-flower[1:120,-1]#前120条数据作为训练数据集test_flower<-flower[121:150,-1]#121-150行数据作为测试数据集tree_flower<-rpart(Species~.,data=train_flower)#建立决策树模型summary(tree_flower)#查看决策树模型12010.549295801.000000001.00000000.07583649 20.408450710.450704230.45070420.06822874 30.010000020.042253520.11267610.038486203331231312029584932390.4080.2670.3252.750.85.553.350.85.553.354908333349001.0000.0000.00071507032390.0000.4510.5491.755.056.152.954.756.152.953303120.0000.9390.0613801370.0000.0260.974 rpart.plot(tree_flower,type=1,extra=1)#画出决策树#根据模型对训练数据集做预测predict_train_flower<-predict(tree_flower,train_flower,type="class")#查看预测结果前6项predict_train_flower[1:6]123456setosa setosa setosa setosa setosa setosaLevels:setosa versicolor virginica#根据预测结果与实际结果做列联表table(predict_train_flower,train_flower$Species)#行是预测结果,列是实际结果tbl_predXreal<-table(predict_train_flower,train_flower$Species)tbl_predXreal#行是预测结果,列是实际结果predict_train_flower setosa versicolor virginicasetosa4900versicolor0312virginica0137accuracy<-sum(diag(tbl_predXreal))/sum(tbl_predXreal)cat("模型准确率:",round(accuracy*100,digits=2),"%")模型准确率:97.5%#用该模型预测测试数据(121至150号样本)predict_test_flower<-predict(tree_flower,test_flower,type="class")predict_test_flower#预测结果121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150 test_flower$Species#实际结果#计算预测结果与实际结果不一样的数量sum(!predict_test_flower==test_flower$Species)3。
鸢尾花分类实验报告引言鸢尾花是一种常见的植物,由于其花朵形态的多样性,成为了许多植物分类学研究的对象。
本实验旨在通过机器学习算法对鸢尾花的特征进行分类,以提高对鸢尾花分类的准确性和效率。
实验设计与方法本实验使用了鸢尾花数据集,该数据集包含150个样本,每个样本具有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
同时,每个样本还有一个类别标签,分别对应三个鸢尾花的品种:山鸢尾(setosa)、变色鸢尾(versicolor)和维吉尼亚鸢尾(virginica)。
我们对数据集进行了预处理,包括数据清洗、缺失值处理和特征标准化。
接着,我们将数据集分为训练集和测试集,其中训练集占总样本数的70%,测试集占30%。
在实验中,我们采用了三种常见的机器学习算法进行鸢尾花分类:K 近邻算法、支持向量机算法和决策树算法。
结果与分析在使用K近邻算法进行鸢尾花分类时,我们选择了K值为3,即选择最近的3个邻居作为分类依据。
在测试集上进行分类准确率的评估,结果显示准确率达到了97%。
接下来,我们使用支持向量机算法进行分类。
通过调整核函数和正则化参数,我们得到了不同的分类结果。
最终,在测试集上,我们选择了径向基核函数和适当的正则化参数,分类准确率达到了95%。
我们使用决策树算法进行分类。
通过调整树的深度和节点划分准则,我们得到了不同的分类结果。
在测试集上,我们选择了树的深度为3和基尼系数作为节点划分准则,分类准确率达到了92%。
讨论与总结本实验通过机器学习算法对鸢尾花进行了分类实验。
结果显示,K 近邻算法在本实验中表现最好,其次是支持向量机算法和决策树算法。
这表明K近邻算法对于鸢尾花的特征分类具有较好的效果。
然而,本实验也存在一些不足之处。
首先,鸢尾花数据集的样本量相对较小,可能导致结果的泛化能力不强。
其次,我们只使用了部分特征进行分类,可能忽略了一些重要的特征信息。
因此,后续的研究可以尝试增加样本量,选择更多的特征进行分类,以提高分类的准确性和鲁棒性。
Python机器学习实战案例随着人工智能技术的不断发展和普及,机器学习作为其中一项重要的技术,受到了广泛的关注和应用。
Python作为一种编程语言,在机器学习领域也表现出色。
本文将基于Python语言,介绍一些实战案例,展示Python机器学习的强大功能和应用场景。
一、鸢尾花数据集分类鸢尾花数据集是机器学习中常用的数据集之一,包含了三个品种的鸢尾花的花萼和花瓣的尺寸数据。
我们可以利用Python中的scikit-learn库进行分类预测的实战。
首先,我们可以通过导入相关库,并加载鸢尾花数据集:```pythonfrom sklearn.datasets import load_irisiris = load_iris()```接下来,我们可以使用各种机器学习算法进行分类预测,比如决策树算法、支持向量机算法等。
以决策树算法为例,我们可以使用以下代码进行模型训练和预测:```pythonfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.model_selection import train_test_split# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=0)# 创建决策树分类器clf = DecisionTreeClassifier()# 拟合模型clf.fit(X_train, y_train)# 预测y_pred = clf.predict(X_test)```通过以上代码,我们可以使用决策树算法对鸢尾花数据集进行分类预测,并得到准确的预测结果。
二、手写数字识别手写数字识别是机器学习领域中的一个经典问题,我们可以利用Python中的scikit-learn库和MNIST数据集进行实战。
c4.5决策树算法例题例题:预测鸢尾花分类题目描述:给定鸢尾花的三种类型:山鸢尾(setosa)、杂色鸢尾(versicolor)和维吉尼亚鸢尾(virginica),以及鸢尾花的四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
使用这些特征来预测鸢尾花的类型。
数据集:以下是一个鸢尾花数据集的样例,每一行表示一个样本,每个特征用一个数字表示。
最后一列是鸢尾花的类型。
1.4 3.5 5.1 1.7 setosa5.0 3.6 5.5 2.6 versicolor4.9 3.05.1 1.8 virginica解题思路:使用C4.5决策树算法对鸢尾花数据集进行分类。
首先,我们需要将数据集分成训练集和测试集,然后使用训练集训练决策树模型。
在训练过程中,我们需要计算每个特征的信息增益率,选择信息增益率最大的特征作为划分标准。
在每个节点处,我们需要计算划分后的数据集的纯度,选择最优的划分标准。
最后,我们使用测试集对决策树模型进行评估,计算分类准确率。
C4.5决策树算法的具体步骤如下:1. 将数据集分成训练集和测试集。
2. 初始化根节点,选择一个特征作为划分标准,计算划分后的数据集的纯度。
3. 如果数据集的纯度已经达到要求,则将该节点标记为叶子节点,并将该节点的类标签作为最终分类结果。
4. 如果数据集的纯度未达到要求,则选择信息增益率最大的特征作为划分标准,将数据集划分为子数据集。
5. 对每个子数据集重复步骤2-4,直到满足停止条件。
6. 构建决策树,将每个节点的最优划分标准记录下来。
7. 使用测试集对决策树模型进行评估,计算分类准确率。
科技论坛0 引言图像识别技术,要运用目前流行的机器学习算法,而目前流行的机器学习算法就有十几种,比如支持向量机、神经网络、决策树。
机器学习是人工智能发展的重要一部分,它涉及的学科很多,应用也相当广泛,它通过分析、研究、设计让计算机学习知识,从而提高完善自身的性能。
但是神经网络学习的速度较慢,传统的支持向量机则不能解决分类多的问题。
本文针对鸢尾花的特征类别少以及种类少的特点,采用决策树算法对课题进行展开,对比与其他人利用支持向量机、神经元网络模型来进行研究,该系统具有模型简单、便于理解、计算方便、消耗资源少的优点。
1 决策树模型和学习本文采用决策树算法对鸢尾花进行分类,先建立决策树的模型并进行学习训练,在决策树的训练过程中采用是信息论的知识进行特征选择,对选定的特征采用分支的处理,然后再对分支过后的数据集如此反复的递归生成决策树,在一颗决策树生成完后对决策树进行剪枝,以减小决策树的拟合度,来达到一个对鸢尾花较高的分类准确率。
要对鸢尾花进行分类首先需要大量的鸢尾花数据集作为本文的实验数据,本文采用的数据集是来自加州大学欧文分校UCI数据库中的鸢尾花数据集。
该数据集中鸢尾花的属性有四个,分别是花萼长度、花萼宽度、花瓣长度和花瓣宽度,鸢尾花的类别则有三种,分别是Iris Setosa,Iris Versicolour,Iris Virginica,用简写Se、Ve和Vi表示这三种花,具体数据如图1所示。
■1.1 信息论美贝尔电话研究所的数学家香农是信息论的创始人,1948年香农发表了《通讯的数学理论》,成为信息论诞生的标志。
信息论的诞生对信息技术革命以及科学技术的发展起到重要作用。
信息论中有两个概念信息增益及信息增益率,都是用于衡量原始数据集在按照某一属性特征分裂之后整体信息量的变化值。
这样,本文就可以通过这种指标寻找出最优的划分属性,数据集在经过划分之后,节点的“纯度”越来越高,这里的纯度值得是花朵的类别,当某一节点中花朵全为一类时,该节点已经达到最纯状态,无需再进行划分,反之继续划分。
图1 鸢尾花数据集1.1.1 信息熵信息熵用于描述信源的不确定性。
即发生每个事件都有不确定性,为了使不确定性降低,我们需要引入一些相关的信息进行学习,引入信息越多,那么得到的准确率越高,信息熵越高,信源越不稳定。
例如一束鸢尾花,它可能是Se,可能是Vi,也有可能是Ve,我们利用数据库中的各种鸢尾花的花瓣长度、花瓣宽度、花萼长度和花萼宽度来预测鸢尾花的类别,引入的鸢尾花种类越多,信息熵就越高。
样本集合D的信息熵Ent(D)以下面的公式进行计算,其中集合里第k类样本所占的比例是k p,k的取值范围是从1到y,y值得是总共有y类样本,通过式(1)可以计算得到原始样本集的信息熵。
()21Ent Dyk kkp log p==−∑(1) 1.1.2 信息增益信息增益即在一个条件下,信源不确定性减少的程度。
信息增益用于度量节点的纯度。
信息增益对可取值数目较多的属性有所偏好。
在鸢尾花数据集的D集合中,属性a取到某一取值情况的概率乘该取值情况的信息熵得到的值记为v D,其中V指的是该属性a可以取值的个数,则属性a 的信息增益为:()()()1Gain D,a Ent D V v vvD Ent DD==−∑(2)基于决策树的鸢尾花分类徐彧铧(浙江省衢州第二中学,浙江衢州,324000)摘要:针对传统手工分类的不足,满足不了人们对图片分类的需求,本文利用机器学习算法中的决策树算法进行研究。
通过模型简单、便于理解、计算方便、消耗资源少的决策树算法模型,并利用现成的数据库,运用图像识别技术对鸢尾花进行分类,以求方便简单快速地识别出不同类别的鸢尾花。
在此过程中,学习到图像识别的一些基本分类操作,为我们实现更复杂的模型提供了帮助。
关键词:决策树信息论特征选择;C4.5算法;CART算法www ele169 com | 99100 | 电子制作 2018年10月()()(),Gain _ratio D,a Gain D a IV a =(3)其中 ()21IV a Vvvv D Dlog D D ==−∑。
通过信息增益率的计算同样可以得到原始的鸢尾花数据集中按照某一属性进行划分之后的信息增益率,选择产生最大值的属性作为分裂的标准。
同样地,分裂后的子集中也是采用相同的递归方式形成新的子集,直到所有末端分支的子集里所有的样本都为同一类型的花朵为止。
■1.2 决策树生成算法1.2.1 ID3算法与C4.5算法决策树生成常用的基本算法是ID3算法和C4.5算法。
ID3算法是一种采用信息增益的方法构造决策树,这种算法该算法开始时,所有的数据都在根节点上,属性都是离散的,停止分割的条件是一个节点上的数据都是属于同一个类别或者没有属性可以再对属性进行分割了。
C4.5算法是应用信息增益率进行的,克服了用信息增益选择属性时偏向选择取值多的属性的不足。
C4.5算法能够完成对连续属性的离散化处理,由于在本文所研究的对象中,对于萼片长度、萼片宽度、花瓣长度、花瓣宽度这些数据实际是上都是一些连续的小数值,因此如果不采用离散化的操作,这样直接进行处理就会导致属性的取值数量太多的情况,极易造成过拟合的现象。
若不是离散的就将它离散化,离散化采用的是一种设置区间的形式对数据离散化。
利用分裂信息计算,得到值越大,表示按照该属性值进行划分越优,根据计算出的值再对数据分区间。
数据的离散化是一个比较复杂的过程,一般都是设置一个阈值将其分成两部分。
首先对属性的取值进行升序排序,得到排序结果之后,任意两个属性取值之间都有可能的作为分裂点,计算每个可能的分裂点的分裂信息,即式(3)中 2GINI 1i i Ip ∈=−∑(4)()()11Gini D,A D Gini D D =+()22DGini D D(5)在鸢尾花数据集D 中,根据一类属性分为两类,分别是D1,D2。
在D 数据集中,A 属性的基尼值则为D1发生的概率乘D1的基尼值加D2发生的概率乘D2的基尼值,式5就表示了数据集D 按照某一属性值A 进行二分类之后的结果。
但是实际中,鸢尾花的所有属性值都不是只有两种值得取值情况,因此,需要对属性设置一个阈值,使其变成两类值,具体的阈值选取方法完全等同于C4.5中对连续属性值的处理方法。
■1.3 决策树的剪枝决策树的剪枝分为预剪枝和后剪枝。
剪枝的目的在于解决数据噪音、训练数据量少、过拟合等问题,使决策树更高效。
预剪枝就是在构造决策树的过程中,先对每个叶子节点统计里面每个样本类别的个数,选取该叶子节点中样本类别个数最多的类别作为该叶子节点的类别。
然后在节点划分前进行估计,先计算目前模型A 对新样本预测的准确率,若当前结点划分得到一个较为复杂的模型B 之后,模型B 对相同的新样本预测的准确率并没有提升,则不对当前结点进行划分并且将当前结点标记为叶结点,表示该节点纯度较高,不需要再进行划分,达到了预剪枝的效果,简化模型。
后剪枝是在决策树生成后进行的,自底向上对非叶子节点进行考察,如果原始模型是A,并计算目前模型对新样本预测的准确率。
在将这个非叶子结点的子节点去掉之后,即将该非叶子去掉之后得到的一个简单的模型B,再计算模型B 对相同的新样本预测的准确率,发现准确率提升了,就直接把该非叶子结点的子树都删掉,这样就达到了后剪枝的效果,简化模型提高正确率。
(下转第84页)84 | 电子制作 2018年10月下,确保重瓦斯保护取得理想效果。
4 变压器短路阻抗值与重瓦斯启动值间关系针对电力变压器有关技术参数已经提出要求,相关文件中对110kV 绕组有载变压器对应参数作出了明确规定,具体的额定负载损耗以及阻抗值等参数信息如表1所示,系统短路状况下的变压器负载损失以及油流速值如表2所示。
表1 各类变压器的负载损失与短路阻抗值装置额定容量/kVA装置额定负载损耗/kW系统短路阻抗4000015510.4%5000019310.4%表2 各类变压器短路故障下的负载损耗与最大油流速装置额定容量/kVA短路电流值负载损耗/kW最大油流速/(m/s)400009.5114137 1.14500009.51175811,42在110kV 变压器实际运行时,通常将风冷或者自冷类大了对变压器运行安全性的研究,其中重瓦斯保护对变压器装置稳定运行有一定影响,有必要在充分掌握短路阻抗对瓦斯保护产生影响的基础上,采取适当的应对措施。
如在调整110kV 变压器短路阻抗时,可利用油流速表达式推导出最小阻抗值,能做到对油流速的合理调节,从而避免流速过大而导致重瓦斯保护误动作。
参考文献* [1]黄炳源.110kV 变压器短路阻抗对重瓦斯保护的影响[J].农村电工,2018,26(02):42.* [2]吴院生.主变压器瓦斯保护简析[J].贵州电力技术,2016,19(05):63-66.* [3]赵全胜,胡伟.110kV 主变有载分接开关故障引起重瓦斯跳闸分析[J].变压器,2015,52(07):69-70.(上接第100页)2 总结与展望本文通过决策树的算法,将鸢尾花数据库中的数据进行学习来建立该模型,再通过信息论中的信息熵来描述信源的不确定性,信息增益与信息增益率来度量节点的纯度,从而进行特征选择,再生成决策树,在决策树生成过程中和生成后剪枝,对比分析了ID3算法、C4.5算法、以及CART 算法在鸢尾花分类任务上的可行性。
解决了传统手工分类效率低、准确率低等缺点。
针对鸢尾花数据集中属性值一般都是连续值得情况,本文讨论了如何采用分裂信息对某一种属性值得取值情况进行分析以计算获得一个最优的分裂点,并还分析了算法可能出现过拟合的问题,针对过拟合本文讨论了如果从源头以及结果解决过拟合的方法,分别是预剪枝和后剪枝,以达到决策树更高的准确率。
但由于客观条件以及时间的限制,本文还有以下几个方面需要改进:本文仅仅运用决策树算法通过鸢尾花的不同属性判断出了鸢尾花的类别,为未来更复杂的模型提供了帮助、奠定了基础。
但随着科技的进步与发展,本作者希望日后可以通过图片判断出鸢尾花的年龄等一系列更详细的信息。
参考文献* [1]张棪,曹健.面向大数据分析的决策树算法[J].计算机科学,2016,43(S1):374-379+383.* [2]李荣雨,程磊.基于SVM 最优决策面的决策树构造[J].电子测量与仪器学报,2016,30(03):342-351.* [3]张琪,周琳,陈亮,张晋昕,温兴煊,何贤英.决策树模型用于结核病治疗方案的分类和预判[J].中华疾病控制杂志,2015,19(05):510-513.。