基于专家知识的决策树分类
- 格式:pdf
- 大小:819.33 KB
- 文档页数:4
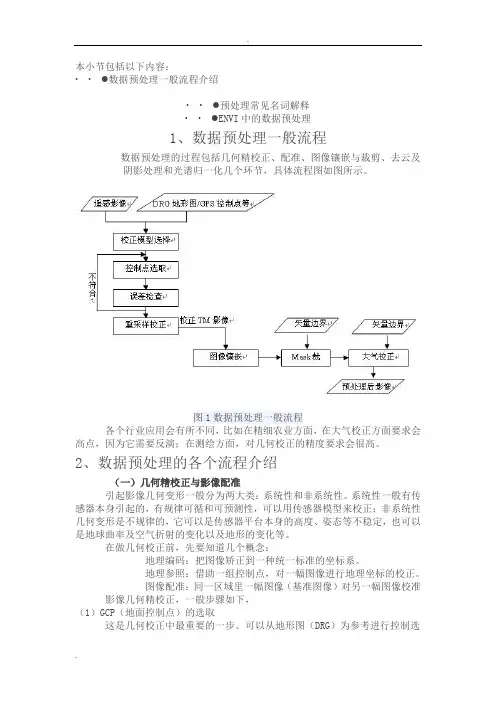
本小节包括以下内容:∙ ∙ ●数据预处理一般流程介绍∙ ∙ ●预处理常见名词解释∙ ∙ ●ENVI中的数据预处理1、数据预处理一般流程数据预处理的过程包括几何精校正、配准、图像镶嵌与裁剪、去云及阴影处理和光谱归一化几个环节,具体流程图如图所示。
图1数据预处理一般流程各个行业应用会有所不同,比如在精细农业方面,在大气校正方面要求会高点,因为它需要反演;在测绘方面,对几何校正的精度要求会很高。
2、数据预处理的各个流程介绍(一)几何精校正与影像配准引起影像几何变形一般分为两大类:系统性和非系统性。
系统性一般有传感器本身引起的,有规律可循和可预测性,可以用传感器模型来校正;非系统性几何变形是不规律的,它可以是传感器平台本身的高度、姿态等不稳定,也可以是地球曲率及空气折射的变化以及地形的变化等。
在做几何校正前,先要知道几个概念:地理编码:把图像矫正到一种统一标准的坐标系。
地理参照:借助一组控制点,对一幅图像进行地理坐标的校正。
图像配准:同一区域里一幅图像(基准图像)对另一幅图像校准影像几何精校正,一般步骤如下,(1)GCP(地面控制点)的选取这是几何校正中最重要的一步。
可以从地形图(DRG)为参考进行控制选点,也可以野外GPS测量获得,或者从校正好的影像中获取。
选取得控制点有以下特征:1、GCP在图像上有明显的、清晰的点位标志,如道路交叉点、河流交叉点等;2、地面控制点上的地物不随时间而变化。
GCP均匀分布在整幅影像内,且要有一定的数量保证,不同纠正模型对控制点个数的需求不相同。
卫星提供的辅助数据可建立严密的物理模型,该模型只需9个控制点即可;对于有理多项式模型,一般每景要求不少于30个控制点,困难地区适当增加点位;几何多项式模型将根据地形情况确定,它要求控制点个数多于上述几种模型,通常每景要求在30-50个左右,尤其对于山区应适当增加控制点。
(2)建立几何校正模型地面点确定之后,要在图像与图像或地图上分别读出各个控制点在图像上的像元坐标(x,y)及其参考图像或地图上的坐标(X,Y),这叫需要选择一个合理的坐标变换函数式(即数据校正模型),然后用公式计算每个地面控制点的均方根误差(RMS)根据公式计算出每个控制点几何校正的精度,计算出累积的总体均方差误差,也叫残余误差,一般控制在一个像元之内,即RMS<1。

1.几何校正:几何校正是利用地面控制点和几何校正数学模型来矫正非系统因素产生的误差,同时也是将图像投影到平面上,使其符合地图投影系统的过程。
2.图像镶嵌:指在一定的数学基础控制下,把多景相邻遥感影像拼接成一个大范围、无缝的图像的过程。
3.图像裁剪:图像裁剪的目的是将研究之外的区域去除。
常用方法是按照行政区划边界或自然区划边界进行图像裁剪。
在基础数据生产中,还经常要进行标准分幅裁剪。
按照ENVI 的图像裁剪过程,可分为规则裁剪和不规则裁剪。
4.图像分类:遥感图像分类也称为遥感图像计算机信息提取技术,是通过模式识别理论,分析图像中反映同类地物的光谱、空间相似性和异类地物的差异,进而将遥感图像自动分成若干地物类别。
5.正射校正:正射校正是对图像空间和几何畸变进行校正生成多中心投影平面正射图像的处理过程。
6.面向对象图像分类技术:是集合邻近像元为对象用来识别感兴趣的光谱要素,充分利用高分辨率的全色和多光谱数据的空间、纹理和光谱信息来分割和分类,以高精度的分类结果或者矢量输出。
7.DEM:数字高程模型是用一组有序数值阵列形式表示地面高程的一种实体地面模型。
8.立体像对:从两个不同位置对同一地区所摄取的一对相片。
9.遥感动态监测:从不同时间或在不同条件获取同一地区的遥感图像中,识别和量化地表变化的类型、空间分布情况和变化量,这一过程就是遥感动态监测过程。
10.高光谱分辨率遥感:是用很窄而连续的波谱通道对地物持续遥感成像的技术。
在可见光到短波红外波段,其波谱分辨率高达纳米数量级,通常具有波段多的特点,波谱通道多达数十甚至数百个,而且各波谱通道间往往是连续的,因此高光谱遥感又通常被称为"成像波谱遥感"。
11.端元波谱:端元波谱作为高光谱分类、地物识别和混合像元分解等过程中的参考波谱,与监督分类中的分类样本具有类似的作用,直接影响波谱识别与混合像元分解结果的精度。
12.可视域分析:可视域分析工具利用DEM数据,可以从一个或多个观察源来确定可见的地表范围,观测源可以是一个单点,线或多边形13.三维可视化:ENVI的三维可视化功能可以将DEM数据以网格结构、规则格网或点的形式显示出来或者将一幅图像叠加到DEM数据上。

应用ENVI软件目视解译TM影像土地利用分类一、本文概述随着遥感技术的不断发展,高分辨率卫星影像的获取与处理已经成为土地利用/覆盖分类研究的重要手段。
其中,TM(Thematic Mapper)影像,作为一种经典的中分辨率遥感数据源,具有广泛的应用前景。
然而,如何有效地从TM影像中提取土地利用信息,尤其是通过目视解译的方法,一直是遥感应用领域的研究热点。
本文旨在探讨利用ENVI软件对TM影像进行目视解译的方法,并对土地利用分类的过程进行详细阐述。
文章首先介绍了TM影像的特点及其在土地利用分类中的适用性,然后重点阐述了ENVI软件在目视解译过程中的优势和应用流程。
通过实例分析,本文展示了如何利用ENVI软件对TM影像进行预处理、特征提取、分类决策以及后处理,从而实现高精度的土地利用分类。
本文的研究不仅有助于提升TM影像在土地利用分类中的应用效果,同时也为其他遥感影像的目视解译提供了有益的参考。
通过本文的阐述,读者可以更好地理解ENVI软件在遥感影像处理中的重要作用,掌握土地利用分类的基本方法和技巧,为相关领域的实践和研究提供有力支持。
二、理论基础与技术方法土地利用分类是对地球表面土地利用类型进行划分和识别的过程,它是地理信息系统(GIS)和遥感(RS)技术的重要应用领域。
TM(Thematic Mapper)影像是由美国陆地卫星(Landsat)提供的多波段扫描影像,因其具有较高的空间分辨率和丰富的光谱信息,在土地利用分类中被广泛应用。
目视解译是一种基于专家知识和经验的影像解译方法,它通过人工观察和分析影像的纹理、色彩、形状等特征,结合地物的光谱特性,实现对地物类型的识别。
目视解译在土地利用分类中具有直观、准确和灵活等优点,尤其在处理复杂地物类型和细节信息时表现出色。
在ENVI软件中,目视解译可以充分利用其强大的图像处理和分析功能,如波段组合、色彩增强、空间滤波等,提高解译的精度和效率。
同时,ENVI软件还提供了丰富的地物分类工具和模型,如监督分类、非监督分类等,可以辅助用户进行自动化的土地利用分类。

基于遥感与GIS的城市绿地信息提取方法摘要:城市绿地是城市中唯一有生命的基础设施,必须客观、准确地掌握城市绿地信息及其变化情况。
遥感技术给城市绿地信息调查提供了更为有效而便捷的手段,植被有其特殊的光谱响应,使得其有别于其他物质。
城市绿地的遥感提取方法有监督分类、决策树分类、面向对象分类等方法,每一种方法都有它的适用条件。
利用GIS的空间叠加分析可以为遥感绿地信息的属性赋值,增强遥感绿地信息的可利用性。
关键字:城市绿地,遥感技术,高分辨率影像,ENVI,GISAbstract: The city green space is the only living infrastructure in the city, we must objectively and accurately grasp the city green land information and its changes. The remote sensing technology provides a more effective and convenient means for the city green land information investigation, the vegetation has its special spectral response, which is different from other substances. The remote sensing extraction method of the city green extraction is the supervised classification, decision tree classification and object-oriented classification method, and each method has its applicable conditions. Using the GIS spatial overlay analysis can assigns for the remote sensing vegetation information attribute, and enhance the remote sensing vegetation information availability. Keywords: city green space; remote sensing technology; high resolution images; ENVI; GIS0 引言城市绿地是城市中唯一有生命的基础设施,它在改善城市生态环境和人居环境起着积极的作用,城市绿地含量逐渐成为衡量城市生活质量的1个重要指标。

(人工智能)人工智能的文本分类方法简述人工智能的文本分类方法简述摘要:本文阐述了壹些基本的文本分类的方法,以及壹些改进的文本文类的方法,且包含了壹些文本分类的实际应用。
其中着重阐述了贝叶斯分类以及壹些其他的的文本分类方法。
最后提出了当下文本分类方法中存于的壹些问题。
关键词:文本分类;贝叶斯方法;数据挖掘;分类算法。
0引言文本分类是指于给定分类体系下,根据文本内容(自动)确定文本类别的过程。
20世纪90年代以前,占主导地位的文本分类方法壹直是基于知识工程的分类方法,即由专业人员手工进行分类。
目前于国内也已经开始对中文文本分类方法进行研究,相比于英文文本分类,中文文本分类的壹个重要的差别于于预处理阶段:中文文本的读取需要分词,不像英文文本的单词那样有空格来区分。
从简单的查词典的方法,到后来的基于统计语言模型的分词方法,中文分词的技术已趋于成熟。
且于信息检索、Web文档自动分类、数字图书馆、自动文摘、分类新闻组、文本过滤、单词语义辨析以及文档的组织和管理等多个领域得到了初步的应用。
人工智能的基本方法就是对人类智能活动的仿真。
小样本数据能够见作是壹种先验知识不完全的数据集。
人类于处理类似的决策问题时,通常采用的策略为:1,利用多专家决策来提高决策的可信度;2,专家的决策技能于决策的过程中能够得到不断的增强,即专家具有学习功能;3,于专家的技能得到增强的基础上,再进行决策能够提高决策的正确性。
这种方法同样适用于小样本数据的分类识别。
通过对上述方法的仿真,本文提出了智能分类器,它不仅能够对未知样本进行分类,同时它仍具有多专家决策、预分类和学习功能。
1分类的基本概念分类就是根据数据集的特点找出类别的概念描述,这个概念描述代表了这类数据的整体信息,也就是该类的内涵描述,且使用这种类的描述对未来的测试数据进行分类。
分类的过程壹般分为俩个步骤:第壹步,通过已知数据集建立概念描述模型;第二步,就是利用所获得的模型进行分类操作。

商业决策制定的决策模型商业决策是组织管理中至关重要的一部分。
制定有效的商业决策是成功的关键因素之一。
为了帮助组织高效地做出决策,决策者可以借助决策模型来分析和评估各种选择,以便做出最优的决策。
下面介绍几种常见的商业决策制定的决策模型:1. 传统决策树模型决策树是一种以树状图形式表示的决策模型。
在制定商业决策时,决策树模型可以帮助决策者根据不同的选择和条件,进行逐步的决策。
传统决策树模型包括以下核心要素:- 决策节点:表示需要做出的决策。
- 概率节点:表示不确定性因素,通常与各种可能的结果相关。
- 终止节点:表示决策的最终结果。
通过构建决策树模型,决策者可以清晰地看到不同选择的结果和潜在风险,从而做出更明智的商业决策。
2. 系统动力学模型系统动力学模型是一种用于分析和解决复杂问题的决策模型。
该模型基于系统思维,将问题看作是由相互影响的因素组成的动态系统。
制定商业决策时,系统动力学模型可以帮助决策者理解和量化各种因素之间的关系,以及决策对整个系统产生的影响。
系统动力学模型包括以下关键元素:- 带有相应参数和变量的方程。
- 模型的图形表示,包括流量图和图表。
通过系统动力学模型,决策者可以模拟不同决策对系统变量和行为的影响,从而更好地制定商业决策。
3. 经验法则模型经验法则模型是基于过去的经验和规则制定的决策模型。
该模型依赖于专家的知识和经验,以及历史数据的分析。
在商业决策制定中,经验法则模型可以帮助决策者利用已知的规则和经验来做出决策,特别是在面对相似情况时。
经验法则模型的关键要素包括:- 规则和指导方针。
- 非正式的决策流程。
通过经验法则模型,决策者可以根据过去的经验和知识,从而更快地做出决策,并减少决策过程中的不确定性。
4. 数据驱动模型数据驱动模型是基于数据收集和分析的决策模型。
这种模型通过收集和分析大量的数据,以发现模式和趋势,从而为决策提供支持。
在商业决策制定中,数据驱动模型可以帮助决策者基于实际数据来做出决策,从而降低决策的主观性和不确定性。

专家系统中的知识表示与推理机制分析随着人工智能领域的深入发展,专家系统作为其中的一种重要应用,已经得到了广泛的应用。
在专家系统中,知识表示和推理机制是其实现的核心技术,也是其成功与否的关键之一。
因此,对专家系统中知识表示和推理机制的深入分析和探讨,对于提高专家系统的应用水平具有重要的意义。
一、知识表示知识表示是指将复杂的领域知识转换成计算机程序能够理解和操作的形式,以便于专家系统能够利用这些知识进行推理和决策。
在专家系统中,知识表示有多种形式,包括规则表达式、框架、语义网络、决策树等。
这些不同的知识表示形式各有其优缺点,根据具体应用场景和需求选择合适的知识表示形式非常重要。
1.规则表达式规则表达式是专家系统中最早应用的一种知识表示形式,其基本思想是利用一系列的规则描述问题的因果关系和逻辑关系,以此来表达专家领域的知识。
规则表达式的表达形式简单,易于理解和修改,但是当问题变得复杂或规则越来越多时,规则表达式的管理和维护就会变得非常困难。
2.框架框架是一种常用的知识表示形式,用于描述事实之间的复杂关系。
它将一个事物的属性和关系组织为一个框架或者一个对象,如一个人的框架可以包括属性姓名、年龄、性别等,以及这些属性之间的关系。
框架的优点在于能够描述属性之间的复杂关系,也便于系统扩展和更新,但是一堆框架的组合可能会导致知识表示过于复杂。
3.语义网络语义网络是一种基于图形的知识表示形式,用于描述事物之间的语义关系。
它将事实或概念表示为节点,将它们之间的关系表示为边。
语义网络的好处在于它允许系统对知识进行更高层次的表示和推理,如关于概念间的层次结构和分类关系等,但是在构造语义网络时需要考虑节点的组织和表示,避免出现过于复杂的结构。
二、推理机制推理机制是指专家系统根据已有的知识以及推理规则,通过推理过程来生成新的知识或决策结果。
推理机制是专家系统中最核心的部分,其决定了系统的推理速度和推理准确率。
1.前向推理前向推理是指根据事实和规则,从前到后推导出结论的推理方式。



遥感的面向对象分类法传统的基于像素的遥感影像处理方法都是基于遥感影像光谱信息极其丰富,地物间光谱差异较为明显的基础上进行的。
对于只含有较少波段的高分辨率遥感影像,传统的分类方法,就会造成分类精度降低,空间数据的大量冗余,并且其分类结果常常是椒盐图像,不利于进行空间分析。
为解决这一传统难题,模糊分类技术应运而生。
模糊分类是一种图像分类技术,它是把任意范围的特征值转换为 0 到 1 之间的模糊值,这个模糊值表明了隶属于一个指定类的程度。
通过把特征值翻译为模糊值,即使对于不同的范围和维数的特征值组合,模糊分类能够标准化特征值。
模糊分类也提供了一个清晰的和可调整的特征描述。
对于影像分类来说,基于像元的信息提取是根据地表一个像元范围内辐射平均值对每一个像元进行分类,这种分类原理使得高分辨率数据或具有明显纹理特征的数据中的单一像元没有很大的价值。
影像中地物类别特征不仅由光谱信息来刻画的,很多情况下(高分辨率或纹理影像数据)通过纹理特征来表示。
此外背景信息在影像分析中很重要,举例来说,城市绿地与某些湿地在光谱信息上十分相似,在面向对象的影像分析中只要明确城市绿地的背景为城市地区,就可以轻松地区分绿地与湿地,而在基于像元的分类中这种背景信息几乎不可利用。
面向对象的影像分析技术是在空间信息技术长期发展的过程中产生的,在遥感影像分析中具有巨大的潜力,要建立与现实世界真正相匹配的地表模型,面向对象的方法是目前为止较为理想的方法。
面向对象的处理方法中最重要的一部分是图像分割。
随着对地观测任务逐渐精细化,高分辨率遥感卫星影像的应用越来越广泛。
这对遥感影像分类方法提出了挑战。
已有的研究表明:基于像元的高分辨率遥感影像分类存在明显的限制。
近年来,面向对象影像分析(Object-Based ImageAnalysis,OBIA)在高分辨率遥感影像处理中渐露头角,被认为是遥感与地理信息科学发展的重要趋势。
本文针对面向对象影像分类(Object-Based Image Classification,OBIC)方法中的若干问题开展研究。

决策树的发展历史1.引言1.1 概述决策树是一种常见的机器学习算法,被广泛应用于数据挖掘和预测分析领域。
它通过构建一颗树结构来模拟人类决策的过程,从而实现对未知数据的分类和预测。
决策树算法的思想简单直观,易于理解和解释,因此在实际应用中得到了广泛的应用。
决策树的起源可以追溯到上世纪五六十年代的人工智能领域。
早期的决策树算法主要依赖于手工编写的规则和判据来进行决策,这种方法是一种基于经验和专家知识的启发式算法。
随着计算机技术的发展和数据规模的增大,传统的基于规则的决策树算法逐渐暴露出规则冲突、效率低下和难以处理复杂问题等问题。
为了解决上述问题,决策树算法在上世纪八九十年代得到了显著的发展。
其中最著名的算法是ID3算法和C4.5算法,由机器学习领域的先驱Ross Quinlan提出。
这些算法通过信息熵和信息增益等概念,将决策树的构建过程形式化为一个优化问题,从而实现了自动化的决策树生成。
此外,这些算法还引入了剪枝操作和缺失值处理等技术,提高了决策树算法的鲁棒性和适用性。
随着机器学习算法的快速发展,决策树算法也得到了进一步的改进和扩展。
在二十一世纪初期,随机森林算法和梯度提升算法等集成学习方法的兴起,使得决策树在大规模数据和复杂场景下的应用问题得到了有效解决。
此外,基于决策树的深度学习模型如深度森林、决策树神经网络等也在近年来取得了显著的研究成果。
决策树的发展历程可以说是与机器学习算法的发展紧密相连的。
随着数据科学和人工智能领域的不断进步,决策树算法有望在更多的领域得到广泛应用,为解决实际问题提供更好的决策支持。
接下来的章节将对决策树的起源、发展历史以及应用前景进行详细的介绍和探讨。
1.2文章结构本文的文章结构如下:第一部分是引言,主要包括概述、文章结构和目的。
在概述中,将介绍决策树作为一种重要的机器学习算法,其在数据分析和预测中的应用越来越广泛。
随后,将详细介绍文章的结构,以便读者能够清楚地了解整篇文章的组织和内容。
基于专家知识的决策树分类概述基于知识的决策树分类是基于遥感影像数据及其他空间数据,通过专家经验总结、简单的数学统计和归纳方法等,获得分类规则并进行遥感分类。
分类规则易于理解,分类过程也符合人的认知过程,最大的特点是利用的多源数据。
如图1所示,影像+DEM就能区分缓坡和陡坡的植被信息,如果添加其他数据,如区域图、道路图土地利用图等,就能进一步划分出那些是自然生长的植被,那些是公园植被。
图1.JPG图1 专家知识决策树分类器说明图专家知识决策树分类的步骤大体上可分为四步:知识(规则)定义、规则输入、决策树运行和分类后处理。
1.知识(规则)定义规则的定义是讲知识用数学语言表达的过程,可以通过一些算法获取,也可以通过经验总结获得。
2.规则输入将分类规则录入分类器中,不同的平台有着不同规则录入界面。
3.决策树运行运行分类器或者是算法程序。
4.分类后处理这步骤与监督/非监督分类的分类后处理类似。
知识(规则)定义分类规则获取的途径比较灵活,如从经验中获得,坡度小于20度,就认为是缓坡,等等。
也可以从样本中利用算法来获取,这里要讲述的就是C4.5算法。
利用C4.5算法获取规则可分为以下几个步骤:(1)多元文件的的构建:遥感数据经过几何校正、辐射校正处理后,进行波段运算,得到一些植被指数,连同影像一起输入空间数据库;其他空间数据经过矢量化、格式转换、地理配准,组成一个或多个多波段文件。
(2)提取样本,构建样本库:在遥感图像处理软件或者GIS软件支持下,选取合适的图层,采用计算机自动选点、人工解译影像选点等方法采集样本。
(3)分类规则挖掘与评价:在样本库的基础上采用适当的数据挖掘方法挖掘分类规则,后基于评价样本集对分类规则进行评价,并对分类规则做出适当的调整和筛选。
这里就是C4.5算法。
4.5算法的基本思路基于信息熵来“修枝剪叶”,基本思路如下:从树的根节点处的所有训练样本D0开始,离散化连续条件属性。
计算增益比率,取GainRatio(C0)的最大值作为划分点V0,将样本分为两个部分D11和D12。
SCIENCE &TECHNOLOGY INFORMATION科技资讯基于Sentinel-1和Sentinel-2数据的衡水市冬小麦越冬前面积提取刘馨1江亚军2(1.饶阳县气象局河北衡水053900;2.阜城县气象局河北衡水053700)摘要:该文以9月上旬至12月下旬Sentinel-1A GRD 为主要数据,提取小麦等不同地物后向散射系数变化曲线,根据当地种植制度和农事活动分析其后向散射系数曲线变化特点,结合11月下旬NDVI 通过基于专家知识的决策树分类法进行冬小麦越冬前面积提取。
经过精度验证,分类精度88.52%,Kappa 系数为0.81。
结果表明,该方法可在目标区冬小麦进入分蘖期后较准确地提取种植面积,为越冬期相关服务提供基础。
关键词:Sentinel-1A 冬小麦面积提取决策树中图分类号:P237文献标识码:A文章编号:1672-3791(2021)11(c)-0092-03Extraction of Winter Wheat Area before Overwintering in Hengshui City Based on Sentinel-1and Sentinel-2DataLIU Xin 1JIANG Yajun 2(1.Raoyang County Meteorological Service,Hengshui,Hebei Province,053900China;2.Fucheng CountyMeteorological Service,Hengshui,Hebei Province,053700China)Abstract:Taking Sentinel-1A GRD from early September to late December as the main data,the backscattering coefficient change curves of different ground objects such as wheat are extracted.The variation characteristics of backscattering coefficient curve are analyzed according to local planting system and agricultural bined with NDVI in late November,the area of winter wheat before overwintering is extracted by expert-knowledge-based Decision Tree Classification.After accuracy verification,the classification accuracy is 88.52%,and the Kappa coefficient is 0.81.The results show that this method can accurately extract the planting area after the winter wheat enters the tillering stage in the target area,and provide the basis for relevant services in the overwintering period.Key Words:Sentinel-1a;Winter wheat;Area extraction;Decision Tree冬小麦是衡水市主要农作物之一,其种植面积占全市粮食播种面积一半以上,在当地农业生产中占有重要比重[1]。
人工智能基础知识考试题库300题(含答案)一、单选题1.若一个属性可以从其他属性中推演出来,那这个属性就是()A、结构属性B、冗余属性C、模式属性D、集成属性答案:B2.模型训练的目的是确定预测变量与()之间的推理方式。
A、目标值B、结果C、自变量D、因变量答案:A3.2016年5月,在国家发改委发布的《"互联网+"人工智能三年行动实施方案》中明确提出,到2018年国内要形成()的人工智能市场应用规模.A、千万元级B、亿元级C、百亿元级D、千亿元级答案:D4.数据审计是对数据内容和元数据进行审计,发现其中存在的()A、缺失值B、噪声值C、不一致、不完整值D、以上都是答案:D5.下列哪项不是机器学习中基于实例学习的常用方法()A、K近邻方法B、局部加权回归法C、基于案例的推理D、Find-s算法答案:D6.云计算提供的支撑技术,有效解决虚拟化技术、()、海量存储和海量管理等问题A、并行计算B、实际操作C、数据分析D、数据研发答案:A7.利用计算机来模拟人类的某些思维活动,如医疗诊断、定理证明,这些应用属于()A、数值计算B、自动控制C、人工智能D、模拟仿真答案:C8.知识图谱中的边称为?A、连接边B、关系C、属性D、特征答案:B9.人工神经网络在20世纪()年代兴起,一直以来都是人工智能领域的研究热点A、50B、60C、70D、80答案:D10.下面哪一句话是正确的A、人工智能就是机器学习B、机器学习就是深度学习C、人工智能就是深度学习D、深度学习是一种机器学习的方法答案:D11.()是指数据减去一个总括统计量或模型拟合值时的残余部分A、极值B、标准值C、平均值D、残值答案:D12.()是人工智能地核心,是使计算机具有智能地主要方法,其应用遍及人工智能地各个领域。
A、深度学习B、机器学习C、人机交互D、智能芯片答案:B13.贝叶斯学习是一种以贝叶斯法则为基础的,并通过()手段进行学习的方法。
遥感图像分类遥感图像的分类就是通过对遥感图像中地物的光谱信息和空间信息进行分析,选择特征,将图像中每个象元按照某种规则或算法划分为不同的类别,然后获得遥感图像与实际地物的对应信息,从而实现遥感图像的分类。
一般的分类方法可分为两类:监督分类和非监督分类。
将多源数据应用于图像分类中,发展成基于专家知识的决策树分类。
一、监督分类监督分类(supervised),又称训练分类法,即用被确认的样本象元去识别其他未知象元的过程。
已经被确认类别的样本象元是指那些位于训练区的象元。
在这种分类中,分析者在图像上对每一种类别选取一定数量的训练区,计算机计算每种训练样区的统计或其他信息,每个象元和训练样本作比较,按照不同规则将其划分到其最相似的样本类。
监督分类的算法主要有:平行算法、最小距离法、最大似然法等。
这里采用最大似然法作为监督分类的算法。
原理:最大似然法假设遥感图像的每个波段数据都是正态分布。
其基本思想是:地物类数据在空间中构成特定的点群;每一类的每一维数据都在自己的数轴上成正态分布,该类的多维数据就构成了一个多维正态分布;各类多维正态分布模型各有其分布特征。
根据各类已有的数据,可以构造出各类的多维正态分布模型,在此基础上,对于任何一个像素,可反过来求出它属于各类的概率,取最大概率对应的类为分类结果。
步奏:第一步:分析图像①打开图像,将图像以5、4、3波段合成RGB显示在#1中。
②通过目视分析,可以定义6类样本:水体、建筑、耕地、草地、荒地、其他。
第二步:选择训练样本①在主图像窗口选择Overlay-----Region of Interest,打开ROI Tool对话框。
②在ROI Tool对话框中设置相关样本的名称、颜色等。
③选择ROI_Type—Polygon,在window中选择image,在图像上绘制训练区。
④重复②、③步奏,最终完成以下结果:第三步:评价训练样本①在ROI Tool对话框中,选择Options——Compute ROI Separability,打开目标图像。
基于ENVI的遥感图像分类方法研究比较(聊城大学环境与规划学院GIS专业2010级4班学号:2010203***)摘要基于监督分类方法在遥感图像分类中已经普遍应用,本文将介绍了几种ENVI 提供的常用的监督分类方法和ENVI EX提供的面向对象的分类方法。
对同一遥感图像运用这几种方法进行分类,并对分类结果进行对比,从而分析这几种方法分类精度之间的差异。
关键词遥感图像分类平行六面体最小距离法最大似然法面向对象第一章绪论1.1、研究的背景和意义随着遥感技术的发展,遥感已逐步成为采集地球数据及其变化信息的重要技术手段和重要的信息来源,并在世界范围内以及我国的许多政府部门、科研单位和公司得到广泛的应用。
由于不同领域遥感图像的应用对遥感图像处理提出了不同的要求,所以图像处理中重要的环节——图像分类也就显得尤为重要。
遥感图像通过亮度值或像元值的高低差异( 反映地物的光谱信息) 及空间变化( 反映地物的空间信息) 来表示不同地物的差异。
这是区分不同图像地物的物理基础。
遥感图像分类就是利用计算机通过对遥感图像中各类地物的光谱信息和空间信息进行分析,选择特征,将图像中每个像元按照某种规则或算法划分为不同的类别,然后获得遥感图像中与实际地物的对应信息,从而实现遥感图像的分类。
目前随着各种新理论新方法的相继涌现,遥感图像存在多种分类方法,所以本文主要是选取几种常用的监督分类方法和ENVI EX提供的面向对象分类方法用实验结果表明它们之间存在的差异。
1.2、研究方法(1)、本文从遥感图像解译的基本原理出发,阐述了ENVI软件在遥感图像解译中使用的原理,并对其提供的方法进行了详细的解读。
(2)、详细叙述了ENVI EX提供的Feature Extraction工具即面向对象分类方法的使用。
(3)、根据得到的分类结果,采用混淆矩阵和kappa系数对分类结果进行精度评价。
从中得出一些结论,并对ENVI软件在遥感图像分类方法中提出可行性建议。