Hadoop源码
- 格式:doc
- 大小:5.85 MB
- 文档页数:83

hadoop源码编译问题(Hadoop source code compiler problem)[错误]执行失败的目标组织Apache Maven。
插件:Maven窦插件:1.6:运行(编译原)项目Hadoop常见:发生了一个蚂蚁buildexception:exec返回:1 -> [ 1 ]帮助org.apache.maven.lifecycle.lifecycleexecutionexception:未能执行目标组织Apache Maven。
插件:Maven窦插件:1.6:运行(编译原)项目Hadoop常见:发生了一个蚂蚁buildexception:exec返回:1在牛津。
Apache Maven。
生命周期内。
mojoexecutor。
执行(mojoexecutor。
java:217)在牛津。
Apache Maven。
生命周期内。
mojoexecutor。
执行(mojoexecutor。
java:153)在牛津。
Apache Maven。
生命周期内。
mojoexecutor。
执行(mojoexecutor。
java:145)在牛津。
Apache Maven。
生命周期内。
lifecyclemodulebuilder。
buildproject(lifecyclemodulebuilder。
java:84)在牛津。
Apache Maven。
生命周期内。
lifecyclemodulebuilder。
buildproject(lifecyclemodulebuilder。
java:59)在牛津。
Apache Maven。
生命周期内。
lifecyclestarter。
singlethreadedbuild(lifecyclestarter。
java:183)在牛津。
Apache Maven。
生命周期内。
lifecyclestarter。
执行(lifecyclestarter。
java:161)在牛津。
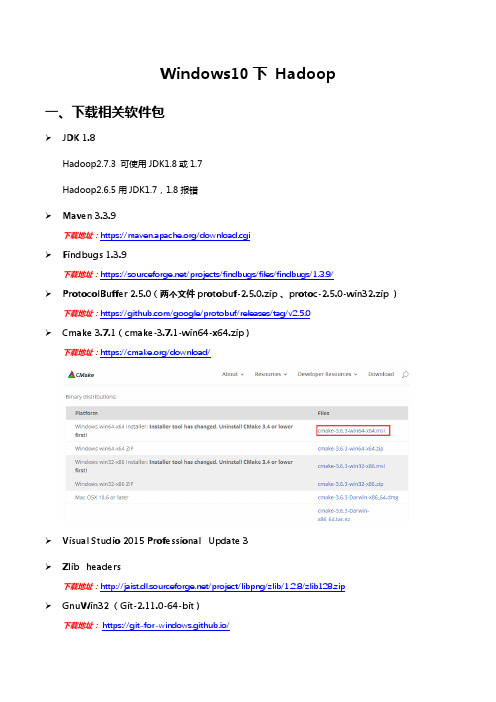
Windows10下Hadoop一、下载相关软件包JDK 1.8Hadoop2.7.3 可使用JDK1.8或1.7Hadoop2.6.5用JDK1.7,1.8报错Maven 3.3.9下载地址:https:///download.cgiFindbugs 1.3.9下载地址:https:///projects/findbugs/files/findbugs/1.3.9/ProtocolBuffer 2.5.0(两个文件protobuf-2.5.0.zip 、protoc-2.5.0-win32.zip )下载地址:https:///google/protobuf/releases/tag/v2.5.0Cmake 3.7.1(cmake-3.7.1-win64-x64.zip)下载地址:https:///download/Visual Studio 2015 Professional Update 3Zlib headers下载地址:/project/libpng/zlib/1.2.8/zlib128.zip GnuWin32 (Git-2.11.0-64-bit)下载地址:https://git-for-windows.github.io/Ant 1.9.8下载地址:/bindownload.cgi二、软件安装1、安装Visual Studio2、Git 安装验证安装成功方法:输入Linux命令ls 即可列出当前文件夹列表3、CMake 安装直接安装运行cmake-3.7.1-win64-x64.msi,采用默认配置即可4、配置环境变量◆配置JAVA_HOME◆配置Maven解压Maven到指定目录(D:\ apache-maven-3.3.9)新建系统变量M2_HOME=D:\apache-maven-3.3.9编辑系统变量Path,新建%M2_HOME%\bin◆Findbugs解压Findbugs到D:\findbugs-1.3.9编辑系统变量Path,新建D:\findbugs-1.3.9\bin◆ProtocolBuffer解压ProtocolBuffer到D:\protobuf-2.5.0\解压protoc-2.5.0-win32.zip,将protoc.exe复制到D:\protobuf-2.5.0\src目录下安装ProtocolBuffer,打开命令行cd D:\protobuf-2.5.0\javamvn testmvn install将protoc.exe所在路径D:\protobuf-2.5.0\src,添加到系统变量Pathprotoc–version验证是否安装成功◆Zlib解压Zlib到D:\zlib-1.2.8新建环境变量ZLIB_HOME=D:\zlib-1.2.8◆Ant解压Ant到D: \apache-ant-1.9.8新建环境变量ANT_HOME=D: \apache-ant-1.9.8Path中加入%ANT_HOME%\bin三、编译准备1、下载Hadoop源码并解压2、用VisualStudio 2015 分别打开,升级项目信息到2015E:\hadoop\hadoop-*-src\hadoop-common-project\hadoop-common\src\main\native\native.sln E:\hadoop\hadoop-*-src\hadoop-common-project\hadoop-common\src\main\winutils\winutils.sln3、E:\hadoop\hadoop-*-src\hadoop-hdfs-project\hadoop-hdfs\pom.xml将其中所有Visual Studio 10替换成Visual Studio 144、开始编译第一步、用管理员身份打开“VS2015 开发人员命令提示”第二步、命令行里面执行批处理"vcvarsx86_amd64.bat"切换进入D:\Program Files\Microsoft Visual Studio 14.0\VC\bin\x86_amd64目录执行vcvarsx86_amd64.bat,如下图:第三步、编译Hadoop切换进入Hadoop源码目录执行命令mvn package -Pdist,native-win -DskipTests–Dtar等待编译,出现如下提示,代表编译成功(maven有些包下不下来,可考虑搞个VPN)编译完成后的包在如下目录中注,hadoop2.6.5编译时会报一个错需修改一个类文件E:\hadoop\hadoop-2.6.5-src\hadoop-common-project\hadoop-annotations\src\main\java\org\apache\had oop\classification\InterfaceStability.java删掉红框部分。

dragonfly源码编译Dragonfly是一款基于Apache Hadoop MapReduce的大数据处理系统。
本文将以编译Dragonfly源码为例,介绍整个过程。
1. 下载源码首先,需要在官方网站上下载Dragonfly的源码包,压缩文件格式可以选择zip或tar.gz。
下载完成后,将源码解压到本地。
2. 安装依赖在编译Dragonfly之前,需要先安装一些依赖库和开发工具,以确保编译顺利完成。
具体的安装步骤因不同操作系统而异,下面是Ubuntu 16.04操作系统下的安装方法:sudo apt-get updatesudo apt-get install build-essentialsudo apt-get install openjdk-8-jdksudo apt-get install mavensudo apt-get install protobuf-compiler3. 配置环境变量为了方便编译和运行Dragonfly,需要添加一些环境变量。
可以将以下语句添加到~/.bashrc文件中:export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export MAVEN_HOME=/usr/share/mavenexport PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin然后执行source ~/.bashrc,使这些环境变量生效。
4. 编译源码进入到解压后的Dragonfly源码目录,执行以下命令编译:mvn clean install -Pdist -DskipTests上述命令的含义是,在不执行测试的情况下,生成一个可以部署和运行的Dragonfly发行版。
编译完成后,在target目录下可以找到生成的发行版文件。
5. 部署和运行将生成的Dragonfly发行版文件解压到任意的目录下,可以看到其中包含了bin、conf、lib等目录。

hadoop3 源码编译
编译hadoop 3源码需要以下几个步骤:
1. 确认编译环境
Hadoop 3要求使用JDK 8或更高版本进行编译。
同时需要安装Maven 3.3或更高版本作为构建工具.
2. 下载源代码
从Apache官方网站下载最新的Hadoop v3源代码包并解压缩。
3. 修改配置文件
进入hadoop-3.x-src/hadoop-project-dist/hadoop-common目录,编辑pom.xml文件,将hadoop.version属性设置为当前版本号。
4. 编译代码
在hadoop-3.x-src目录下使用以下命令编译源代码:
```
mvn clean install -DskipTests
```
这将编译hadoop的所有模块,并将构建的JAR文件安装到本地Maven存储库中。
5. 配置环境变量
将以下环境变量添加到你的~/.bashrc文件中:
```
export HADOOP_HOME=/path/to/hadoop-3.x-src/hadoop-
dist/target/hadoop-3.x.x
export PATH=PATH:HADOOP_HOME/bin:HADOOP_HOME/sbin
```
替换/path/to/为你的Hadoop源代码目录。
6. 测试安装
重启终端后,使用以下命令验证Hadoop安装是否成功:
```
hadoop version
```
如果一切顺利,你应该能够看到安装的版本号。
以上是Hadoop 3源代码的编译流程。

Hadoop大数据技术基础 python版随着互联网技术的不断发展和数据量的爆炸式增长,大数据技术成为了当前互联网行业的热门话题之一。
Hadoop作为一种开源的大数据处理评台,其在大数据领域的应用日益广泛。
而Python作为一种简洁、易读、易学的编程语言,也在大数据分析与处理中扮演着不可或缺的角色。
本文将介绍Hadoop大数据技术的基础知识,并结合Python编程语言,分析其在大数据处理中的应用。
一、Hadoop大数据技术基础1. Hadoop简介Hadoop是一种用于存储和处理大规模数据的开源框架,它主要包括Hadoop分布式文件系统(HDFS)和MapReduce计算框架。
Hadoop分布式文件系统用于存储大规模数据,而MapReduce计算框架则用于分布式数据处理。
2. Hadoop生态系统除了HDFS和MapReduce之外,Hadoop生态系统还包括了许多其他组件,例如HBase、Hive、Pig、ZooKeeper等。
这些组件形成了一个完整的大数据处理评台,能够满足各种不同的大数据处理需求。
3. Hadoop集群Hadoop通过在多台服务器上构建集群来实现数据的存储和处理。
集群中的各个计算节点共同参与数据的存储和计算,从而实现了大规模数据的分布式处理。
二、Python在Hadoop大数据处理中的应用1. Hadoop StreamingHadoop Streaming是Hadoop提供的一个用于在MapReduce中使用任意编程语言的工具。
通过Hadoop Streaming,用户可以借助Python编写Map和Reduce的程序,从而实现对大规模数据的处理和分析。
2. Hadoop连接Python除了Hadoop Streaming外,Python还可以通过Hadoop提供的第三方库和接口来连接Hadoop集群,实现对Hadoop集群中数据的读取、存储和计算。
这为Python程序员在大数据处理领域提供了更多的可能性。

Hadoop、Zookeeper、Hbase、Hive集群安装配置手册运行环境机器配置虚机CPU E5504*2 (4核心)、内存 4G、硬盘25G进程说明QuorumPeerMain ZooKeeper ensemble member DFSZKFailoverController Hadoop HA进程,维持NameNode高可用 JournalNode Hadoop HA进程,JournalNode存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,保证数据高可用 NameNode Hadoop HDFS进程,名字节点DataNode HadoopHDFS进程, serves blocks NodeManager Hadoop YARN进程,负责 Container 状态的维护,并向 RM 保持心跳。
ResourceManager Hadoop YARN进程,资源管理 JobTracker Hadoop MR1进程,管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作。
TaskTracker Hadoop MR1进程,manages the local Childs RunJar Hive进程HMaster HBase主节点HRegionServer HBase RegionServer, serves regions JobHistoryServer 可以通过该服务查看已经运行完的mapreduce作业记录应用 服务进程 主机/hostname 系统版本mysql mysqld10.12.34.14/ Centos5.810.12.34.15/h15 Centos5.8 HadoopZookeeperHbaseHiveQuorumPeerMainDFSZKFailoverControllerNameNodeNodeManagerRunJarHMasterJournalNodeJobHistoryServerResourceManagerDataNodeHRegionServer10.12.34.16/h16 Centos5.8 HadoopZookeeperHbaseHiveDFSZKFailoverControllerQuorumPeerMainHMasterJournalNodeNameNodeResourceManagerDataNodeHRegionServerNodeManager10.12.34.17/h17 Centos5.8 HadoopZookeeperHbaseHiveNodeManagerDataNodeQuorumPeerMainJournalNodeHRegionServer环境准备1.关闭防火墙15、16、17主机:# service iptables stop2.配置主机名a) 15、16、17主机:# vi /etc/hosts添加如下内容:10.12.34.15 h1510.12.34.16 h1610.12.34.17 h17b) 立即生效15主机:# /bin/hostname h1516主机:# /bin/hostname h1617主机:# /bin/hostname h173. 创建用户15、16、17主机:# useraddhduser密码为hduser# chown -R hduser:hduser /usr/local/4.配置SSH无密码登录a)修改SSH配置文件15、16、17主机:# vi /etc/ssh/sshd_config打开以下注释内容:#RSAAuthentication yes#PubkeyAuthentication yes#AuthorizedKeysFile .ssh/authorized_keysb)重启SSHD服务15、16、17主机:# service sshd restartc)切换用户15、16、17主机:# su hduserd)生成证书公私钥15、16、17主机:$ ssh‐keygen ‐t rsae)拷贝公钥到文件(先把各主机上生成的SSHD公钥拷贝到15上的authorized_keys文件,再把包含所有主机的SSHD公钥文件authorized_keys拷贝到其它主机上)15主机:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys16主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'17主机:$cat ~/.ssh/id_rsa.pub | ssh hduser@h15 'cat >> ~/.ssh/authorized_keys'15主机:# cat ~/.ssh/authorized_keys | ssh hduser@h16 'cat >> ~/.ssh/authorized_keys'# cat ~/.ssh/authorized_keys | ssh hduser@h17 'cat >> ~/.ssh/authorized_keys'5.Mysqla) Host10.12.34.14:3306b) username、passwordhduser@hduserZookeeper使用hduser用户# su hduser安装(在15主机上)1.下载/apache/zookeeper/2.解压缩$ tar ‐zxvf /zookeeper‐3.4.6.tar.gz ‐C /usr/local/配置(在15主机上)1.将zoo_sample.cfg重命名为zoo.cfg$ mv /usr/local/zookeeper‐3.4.6/conf/zoo_sample.cfg /usr/local/zookeeper‐3.4.6/conf/zoo.cfg2.编辑配置文件$ vi /usr/local/zookeeper‐3.4.6/conf/zoo.cfga)修改数据目录dataDir=/tmp/zookeeper修改为dataDir=/usr/local/zookeeper‐3.4.6/datab)配置server添加如下内容:server.1=h15:2888:3888server.2=h16:2888:3888server.3=h17:2888:3888server.X=A:B:C说明:X:表示这是第几号serverA:该server hostname/所在IP地址B:该server和集群中的leader交换消息时所使用的端口C:配置选举leader时所使用的端口3.创建数据目录$ mkdir /usr/local/zookeeper‐3.4.6/data4.创建、编辑文件$ vi /usr/local/zookeeper‐3.4.6/data/myid添加内容(与zoo.cfg中server号码对应):1在16、17主机上安装、配置1.拷贝目录$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.16:/usr/local/$ scp ‐r /usr/local/zookeeper‐3.4.6/ hduser@10.12.34.17:/usr/local/2.修改myida)16主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1 修改为2b)17主机$ vi /usr/local/zookeeper‐3.4.6/data/myid1修改为3启动$ cd /usr/local/zookeeper‐3.4.6/$./bin/zkServer.sh start查看状态:$./bin/zkServer.sh statusHadoop使用hduser用户# su hduser安装(在15主机上)一、安装Hadoop1.下载/apache/hadoop/common/2.解压缩$ tar ‐zxvf /hadoop‐2.4.0.tar.gz ‐C /usr/local/二、 编译本地库,主机必须可以访问internet。
YARN(Yet Another Resource Negotiator)是Hadoop生态系统中的资源管理系统,负责集群资源管理和调度。
在YARN 中,ApplicationMaster负责应用程序的生命周期管理,每个节点上都有一个NodeManager来管理该节点的资源。
如果你想深入了解YARN的源码并进行调试解析,可以按照以下步骤进行:阅读YARN的源码:首先,你需要阅读YARN的源码,了解各个组件的职责和工作原理。
YARN的源码主要使用Java编写,因此你需要具备一定的Java基础。
设置开发环境:为了方便调试和解析YARN的源码,你需要设置好开发环境。
你可以使用IntelliJ IDEA或Eclipse等集成开发环境(IDE),并安装相应的插件来支持Hadoop和YARN的开发和调试。
调试YARN应用程序:你可以编写一个简单的YARN应用程序,并使用IDE的调试功能来逐步执行代码。
通过设置断点、观察变量值和单步执行代码,你可以深入了解YARN的工作原理和代码逻辑。
分析YARN的组件:YARN主要由ResourceManager、NodeManager、ApplicationMaster等组件组成。
你可以分别分析这些组件的实现原理和代码逻辑,了解它们如何协同工作来管理集群资源和应用程序的生命周期。
阅读社区文档和讨论:Hadoop和YARN是一个活跃的开源社区,有许多文档、博客、论坛和邮件列表可供参考。
通过阅读社区文档和参与讨论,你可以了解其他开发者对YARN的理解和使用经验,以及社区对YARN未来的发展方向。
贡献开源项目:如果你对YARN有深入的理解,并且希望进一步提高自己的技能,你可以考虑为YARN开源项目做出贡献。
通过参与社区讨论、提交问题和修复bug,你可以与其他开发者交流经验,并提高自己的技能水平。
总之,要深入理解YARN的源码并进行调试解析,需要花费一定的时间和精力。
通过阅读源码、设置开发环境、调试应用程序、分析组件、阅读社区文档和参与讨论,你可以逐步提高自己对YARN的理解和使用经验。
libhdfs是Hadoop 的一个库,用于与HDFS (Hadoop Distributed File System) 进行交互。
如果你想编译libhdfs,你需要遵循以下步骤:
安装依赖库:
libhdfs需要libcurl和libyaml。
确保你已经安装了这些库。
获取Hadoop 源码:
你需要从Hadoop 的官方网站或其GitHub 仓库获取源码。
配置Hadoop:
在Hadoop 的源码目录中,运行configure脚本。
这会为你的系统生成适当的Makefile 和其他配置文件。
编译Hadoop:
使用make命令编译Hadoop。
编译libhdfs:
进入到hadoop-tools/libhdfs目录。
编译libhdfs: make
安装:
使用sudo make install将编译好的libhdfs安装到系统目录中。
测试:
在一个简单的程序中测试libhdfs是否正常工作。
注意事项:
在编译过程中,可能会遇到各种依赖问题或配置问题。
确保检查任何错误消息,并根据需要进行调整。
如果你使用的是特定的发行版或版本,可能需要考虑该发行版的特定包管理工具或库,以及可能的版本冲突。
如果你遇到任何具体的问题或错误,提供错误消息和更详细的描述可以帮助更准确地诊断问题。
大数据实例代码大数据在各行各业中的应用越来越广泛,并且通过实例代码的使用,我们可以更好地理解和应用大数据技术。
本文将介绍几个常见的大数据实例代码,以帮助读者更好地掌握和应用这些技术。
一、MapReduce 实现 Word CountMapReduce 是一种用于处理大数据集的编程模型,它将数据分为若干个小块进行并行处理,并最终合并结果。
下面是一个使用MapReduce 实现的 Word Count 实例代码:```javaimport java.io.IOException;import org.apache.hadoop.fs.Path;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");for (String w : words) {word.set(w);context.write(word, one);}}}public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}context.write(key, new IntWritable(sum));}}public static void main(String[] args) throws Exception { Configuration conf = new Configuration();Job job = new Job(conf, "wordcount");job.setJarByClass(WordCount.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);}}```二、Spark 实现数据清洗Spark 是一种快速、通用的大数据处理引擎,支持在大规模数据集上进行高效的数据处理。
大数据技术专业代码查询
随着大数据技术的迅速发展,越来越多的企业和机构开始应用大数据技术来处理和分析海量数据。
在大数据领域,编写高效且规范的代码是至关重要的。
本文将介绍一些常用的大数据技术专业代码查询方法,帮助读者更好地学习和应用大数据技术。
1. Hadoop
Hadoop是一个开源的分布式存储和计算框架,被广泛用于大数据处理。
在Hadoop中,MapReduce是最常用的编程模型,用于编写分布式计算任务。
以下是一个简单的WordCount示例代码:
```java public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf,。
关键字: 分布式云计算Google的核心竞争技术是它的计算平台。
Google的大牛们用了下面5篇文章,介绍了它们的计算设施。
GoogleCluster: /archive/googlecluster.htmlChubby:/papers/chubby.htmlGFS:/papers/gfs.htmlBigTable:/papers/bigtable.htmlMapReduce:/papers/mapreduce.html很快,Apache上就出现了一个类似的解决方案,目前它们都属于Apache的Hadoop项目,对应的分别是:Chubby-->ZooKeeperGFS-->HDFSBigTable-->HBaseMapReduce-->Hadoop目前,基于类似思想的Open Source项目还很多,如Facebook用于用户分析的Hive。
HDFS作为一个分布式文件系统,是所有这些项目的基础。
分析好HDFS,有利于了解其他系统。
由于Hadoop的HDFS和MapReduce 是同一个项目,我们就把他们放在一块,进行分析。
下图是MapReduce整个项目的顶层包图和他们的依赖关系。
Hadoop包之间的依赖关系比较复杂,原因是HDFS提供了一个分布式文件系统,该系统提供API,可以屏蔽本地文件系统和分布式文件系统,甚至象Amazon S3这样的在线存储系统。
这就造成了分布式文件系统的实现,或者是分布式文件系统的底层的实现,依赖于某些貌似高层的功能。
功能的相互引用,造成了蜘蛛网型的依赖关系。
一个典型的例子就是包conf,conf用于读取系统配置,它依赖于fs,主要是读取配置文件的时候,需要使用文件系统,而部分的文件系统的功能,在包fs中被抽象了。
Hadoop的关键部分集中于图中蓝色部分,这也是我们考察的重点。
下面给出了Hadoop的包的功能分析。
Hadoop源代码分析(三)由于Hadoop的MapReduce和HDFS都有通信的需求,需要对通信的对象进行序列化。
Hadoop并没有采用Java的序列化,而是引入了它自己的系统。
org.apache.hadoop.io中定义了大量的可序列化对象,他们都实现了Writable接口。
实现了Writable接口的一个典型例子如下:Java代码1.public class MyWritable implements Writable {2.// Some data3.private int counter;4.private long timestamp;5.6.public void write(DataOutput out) throws IOException {7.out.writeInt(counter);8.out.writeLong(timestamp);9.}10.11.public void readFields(DataInput in) throws IOException {12.counter = in.readInt();13.timestamp = in.readLong();14.}15.16.public static MyWritable read(DataInput in) throws IOException {17.MyWritable w = new MyWritable();18.w.readFields(in);19.return w;20.}21.}其中的write和readFields分别实现了把对象序列化和反序列化的功能,是Writable接口定义的两个方法。
下图给出了庞大的org.apache.hadoop.io中对象的关系。
这里,我把ObjectWritable标为红色,是因为相对于其他对象,它有不同的地位。
当我们讨论Hadoop的RPC时,我们会提到RPC上交换的信息,必须是Java的基本类型,String和Writable接口的实现类,以及元素为以上类型的数组。
ObjectWritable 对象保存了一个可以在RPC上传输的对象和对象的类型信息。
这样,我们就有了一个万能的,可以用于客户端/服务器间传输的Writable对象。
例如,我们要把上面例子中的对象作为RPC请求,需要根据MyWritable创建一个ObjectWritable,ObjectWritable往流里会写如下信息对象类名长度,对象类名,对象自己的串行化结果这样,到了对端,ObjectWritable可以根据对象类名创建对应的对象,并解串行。
应该注意到,ObjectWritable依赖于WritableFactories,那存储了Writable子类对应的工厂。
我们需要把MyWritable的工厂,保存在WritableFactories中(通过WritableFactories.setFactory)。
Hadoop源代码分析(五)介绍完org.apache.hadoop.io以后,我们开始来分析org.apache.hadoop.rpc。
RPC采用客户机/服务器模式。
请求程序就是一个客户机,而服务提供程序就是一个服务器。
当我们讨论HDFS的,通信可能发生在:∙Client-NameNode之间,其中NameNode是服务器∙Client-DataNode之间,其中DataNode是服务器∙DataNode-NameNode之间,其中NameNode是服务器∙DataNode-DateNode之间,其中某一个DateNode是服务器,另一个是客户端如果我们考虑Hadoop的Map/Reduce以后,这些系统间的通信就更复杂了。
为了解决这些客户机/服务器之间的通信,Hadoop 引入了一个RPC框架。
该RPC框架利用的Java的反射能力,避免了某些RPC解决方案中需要根据某种接口语言(如CORBA的IDL)生成存根和框架的问题。
但是,该RPC框架要求调用的参数和返回结果必须是Java的基本类型,String和Writable接口的实现类,以及元素为以上类型的数组。
同时,接口方法应该只抛出IOException异常。
(参考自/blog/86306)既然是RPC,当然就有客户端和服务器,当然,org.apache.hadoop.rpc也就有了类Client和类Server。
但是类Server是一个抽象类,类RPC封装了Server,利用反射,把某个对象的方法开放出来,变成RPC中的服务器。
下图是org.apache.hadoop.rpc的类图。
Hadoop源代码分析(六)既然是RPC,自然就有客户端和服务器,当然,org.apache.hadoop.rpc也就有了类Client和类Server。
在这里我们来仔细考察org.apache.hadoop.rpc.Client。
下面的图包含了org.apache.hadoop.rpc.Client中的关键类和关键方法。
由于Client可能和多个Server通信,典型的一次HDFS读,需要和NameNode打交道,也需要和某个/某些DataNode通信。
这就意味着某一个Client需要维护多个连接。
同时,为了减少不必要的连接,现在Client的做法是拿ConnectionId(图中最右侧)来做为Connection的ID。
ConnectionId包括一个InetSocketAddress(IP地址+端口号或主机名+端口号)对象和一个用户信息对象。
这就是说,同一个用户到同一个InetSocketAddress的通信将共享同一个连接。
连接被封装在类Client.Connection中,所有的RPC调用,都是通过Connection,进行通信。
一个RPC调用,自然有输入参数,输出参数和可能的异常,同时,为了区分在同一个Connection上的不同调用,每个调用都有唯一的id。
调用是否结束也需要一个标记,所有的这些都体现在对象Client.Call中。
Connection对象通过一个Hash表,维护在这个连接上的所有Call:Java代码1.private Hashtable<Integer, Call> calls = new Hashtable<Integer, Call>();一个RPC调用通过addCall,把请求加到Connection里。
为了能够在这个框架上传输Java的基本类型,String和Writable接口的实现类,以及元素为以上类型的数组,我们一般把Call需要的参数打包成为ObjectWritable对象。
Client.Connection会通过socket连接服务器,连接成功后回校验客户端/服务器的版本号(Client.ConnectionwriteHeader()方法),校验成功后就可以通过Writable对象来进行请求的发送/应答了。
注意,每个Client.Connection会起一个线程,不断去读取socket,并将收到的结果解包,找出对应的Call,设置Call并通知结果已经获取。
Call使用Obejct的wait和notify,把RPC上的异步消息交互转成同步调用。
还有一点需要注意,一个Client会有多个Client.Connection,这是一个很自然的结果。
Hadoop源代码分析(七)聊完了Client聊Server,按惯例,先把类图贴出来。
需要注意的是,这里的Server类是个抽象类,唯一抽象的地方,就是Java代码1.public abstract Writable call(Writable param, long receiveTime) throws IOException;这表明,Server提供了一个架子,Server的具体功能,需要具体类来完成。
而具体类,当然就是实现call方法。
我们先来分析Server.Call,和Client.Call类似,Server.Call包含了一次请求,其中,id和param的含义和Client.Call是一致的。
不同点在后面三个属性,connection是该Call来自的连接,当然,当请求处理结束时,相应的结果会通过相同的connection,发送给客户端。
属性timestamp是请求到达的时间戳,如果请求很长时间没被处理,对应的连接会被关闭,客户端也就知道出错了。
最后的response是请求处理的结果,可能是一个Writable的串行化结果,也可能一个异常的串行化结果。
Server.Connection维护了一个来之客户端的socket连接。
它处理版本校验,读取请求并把请求发送到请求处理线程,接收处理结果并把结果发送给客户端。