cabac原理及其实现
- 格式:doc
- 大小:749.50 KB
- 文档页数:17

cabac编码过程的解读cabac编码过程的解读CABAC是H.264/AVC标准中两种熵编码方法中的一种,是将自适应的二进制算术编码与一个设计精良的上下文模型结合起来得到的方法。
它很好地利用了语法元素数值之间的高阶信息,使得熵编码的效率得到了进一步提高。
它的主要特点有:利用每个语法元素的上下文关系,根据已编码元素为待编码元素选择概率模型,即上下文建模;根据当前的统计特性自适应地进行概率估计;使用算术编码。
[5] 在CABAC中编码一个单独的句法元素的通用方框图。
这个编码过程主要由三个基本步骤组成:1、二值化;2、上下文建模;3、基于表格的二进制算术编码。
在第一步,一个给出的非二进制值的句法元素唯一地对应到一个二进制序列,叫二进制串。
当给出一个二进制值的句法元素时,这一初始步骤将被跳过,如图1所示。
对于每个元素的二进制串或每个二进制值的句法元素,后面会根据编码模式有一两个子步骤。
接下来就是对二元数据进行编码,标准中有两种编码模式可供选择。
在常规编码模式(regular coding mode)中,一个句法元素的每一个二进值(bin)按其判决产生的顺序进入上下文模型器,在这里,模型器根据已经编码过的句法元素或二进值为每一个输入的二进值分配一个概率模型,这就是上下文模型化。
然后该二进值和分配给它的概率模型一起被送进常规算术编码器进行编码,此外编码器还要根据该二元位的值反馈一个信息给上下文模型器,用以更新上下文模型,这就是编码中的自适应;另一种模式是旁路编码模式(bypass coding mode),在该模式中,没有模型器为每个二进值分配一个特定的概率模型,输入的二元数据是直接用一个简单的旁路编码器进行编码的,这样做是为了加快整个编码(以及另一端解码)的速度,当然,该模式只用于某些特殊的二进值。
后面将更加详细地讨论二值化,上下文建模与基于表格的二进制算术编码这三个主要步骤以及它们之间的相互联系。
2.2二值化CABAC的二值化方案有四种基本类型:一元码,截断一元码,k 阶指数哥伦布编码,与定长编码。

视频会议的音视频编解码技术随着全球化的发展和工作场景的变迁,视频会议已经成为了我们日常工作和社交交流的必要方式。
而视频会议能够正常进行,离不开音视频编解码技术的支持。
本文将从编解码原理、编解码标准、编解码器选择、编解码效果等方面,探讨视频会议的音视频编解码技术。
一、编解码原理音视频编解码技术是通过压缩和解压缩实现的。
所谓压缩,是指通过算法等方式将音视频信号中的冗余内容去掉,从而降低信号的数据量,以达到传输、存储等目的;解压缩则是指将压缩后的音视频信号还原成原始信号。
在音视频编解码中,编码是通过将原始信号转换成数字信号,并将数字信号压缩来实现的。
解码则是对压缩后的信号进行还原,并将其转换为显示或播放所需的信号。
二、编解码标准编解码标准是指压缩和解压缩音视频信号所使用的数据格式、算法、参数等规范。
在视频会议中,常用的编解码标准包括H.264/AVC、H.265/HEVC、VP8、VP9等。
H.264/AVC是目前视频会议中最普及的编解码标准。
它采用了先进的压缩算法,可以在保证视频质量的前提下实现更小的数据传输量。
而H.265/HEVC则是H.264/AVC的升级版,它能够在不降低画质的情况下,实现更高的压缩比,进一步降低视频传输成本。
VP8和VP9则是由Google开发的开源编解码标准,在一些商业应用中得到一定应用。
它们的优势在于能够在低带宽情况下保证视频质量,同时在压缩比方面也有较高的表现。
三、编解码器的选择选择正确的编解码器对于视频会议的流畅程度和画质有着至关重要的影响。
目前,常见的编解码器包括x264、x265、ffmpeg 等。
x264是一款开源的H.264/AVC编码器,它的编码速度快,压缩比高,适合在较低带宽环境中进行视频会议。
x265则是x264的升级版,能够更高效地运用CPU的处理能力,同时在保证视频质量的前提下,实现更小的视频文件大小。
而ffmpeg则是一款集多种视频编解码器于一身的开源软件,能够对多种视频编码进行支持,能够应对各种视频会议场景。

算术编码流程:CABAC编码首先要说明的是CABAC的生命期是SLICE,因此本篇所讲的也是一个SLICE里CABAC的流程,其次对于我们来说场模式几乎用不到,所以本文的编码流程只使用帧模式,因此实际上用到的表只有277个, 当然如果我写成460, 不是说里面所有表都用到的. 这里只是声明一下这个问题, 如果大家实际操作的时候发现模型表序号始终不过276那是很正常的. 本文参考了T264的代码, 应此一帧里只有一个SLICE. 而本文用的变量则采用标准里的变量.本文不会讲CABAC的原理, 想要了解原理请参考FTP上的<<Context-based adaptive binary arithmetic coding in the H.264AVC video compression standard>>片级:即以下步骤在片期间只做1次1.初始化上下文模型先根据SliceQP算出460个模型表里的pStateIdx和valMPS, 构成一张初始表,根据标准9.3.1.1里的公式, 同时可以参考T264_cabac_context_init函数. 这张表不要和模型表弄混,虽然都是399维的, 但我们宏块级编码过程中实际用的只是这张表, 而不是标准里的那张模型表Table 9-23, 9-23这张表是用来算由pStateIdx和valMPS构成的初始表的.2.初始化概率的下限和区间然后就是初始化CABAC的初值, 下界指针,区间范围,可参考T264_cabac_encode_init函数.解:下界指针codILow为0,区间范围codIRange为(0x1FE)510宏块级:以下则是每个宏块都要做一次的, 这一级中会处理很多的语法元素, 这里我只用前2个语法元素做为例子:假设:mb_skip_flag = 1mb_type = 33.语法元素二值化H.264 通过二进制化把多维算术编码转化为二进制算术编码,提高了运算速度。

cabac 熵编码
Cabac(Context-Adaptive Bit Allocation Code,自适应比特分配编码)是一种熵编码方法,主要用于图像和视频压缩领域。
它是一种基于上下文的熵编码技术,能够根据图像或视频中的上下文信息自适应地分配比特资源,从而实现更高的压缩比和更好的图像质量。
Cabac编码的主要特点如下:
1. 自适应比特分配:Cabac编码根据图像块的纹理复杂度和边缘信息,自适应地分配比特资源,使得重要的图像细节得到更好的保护。
2. 上下文感知:Cabac编码利用前一帧或当前帧的其他相关像素的信息,为每个像素分配合适的比特数,从而提高编码效率。
3. 编码效率高:与传统的霍夫曼编码相比,Cabac编码具有更高的编码效率,能够在相同的压缩比下实现更好的图像质量。
4. 适应性强:Cabac编码能够适应不同的图像和视频内容,实现高质量的压缩效果。
5. 兼容性好:Cabac编码可以与其他熵编码方法相结合,如LZW、RLZ
等,形成混合编码方案,进一步提高压缩性能。
在我国,Cabac编码技术在数字电视、视频监控等领域得到了广泛应用。
随着压缩技术的不断发展和优化,Cabac编码在图像和视频压缩领域的优势将继续凸显。

拖尾系数指值为+1/-1的系数,最大数目为3。
如果超过3个,那么只有最后三个被视为拖尾系数。
拖尾系数的数目被赋值到变量TrailingOnes。
非零系数包括所有的拖尾系数,其数目被赋值到变量TotalCoeffs)。
2. 计算nC(numberCurrent,当前块值)。
nC值由左边块的非零系数nA和上面块非零系数nB来确定,计算公式为:nC=round((nA+nB)/2);若nA存在nB不存在,则nC=nA;若nA不存在而nB存在,则nC=nB;若nA和nB都不存在,则nC=0。
nC值用于选择VLC编码表,如下图所示。
这里体现了上下文相关(contextadaptive)的特性,例如当nC值较小即周围块的非零系数较少时,就会选择比较短的码,从而实现了数据压缩。
3. 查表获得coff_token的编码。
根据之前编码和计算过程所得的变量TotalCoeffs、TrailingOnes和nC值可以查H.264标准附录CAVLC码表,即可得出coeff_token编码序列。
4. 编码每个拖尾系数的符号,按zig-zag的逆序进行编码。
每个符号用1个bit位来表示,0表示―+‖,1表示―—‖。
当拖尾系数超过三个时只有最后三个被认定为拖尾系数,引词编码顺序为从后向前编码。
5. 编码除拖尾系数之外非零系数的level(Levels)。
每个非零系数的level包括sign和magnitude,扫描顺序是逆zig-zag序。
level的编码由前缀(level_prefix)和后缀(level_suffix)组成。
前缀的长度在0到6之间,后缀的长度则可通过下面的步骤来确定:将后缀初始化为0。
(若非零系数的总数超过10且拖尾系数不到3,则初始化为1)。
编码频率最高(即按扫描序最后)的除拖尾系数之外的非零系数。
若这个系数的magnitude超过某个门槛值(threshold),则增加后缀的长度。
下表是门槛值的列表:6. 编码最后一个非零系数之前0的个数(totalZeos)。

高效的CABAC解码器设计及FPGA实现的开题报告一、研究背景随着视频编码标准的不断升级,CABAC(Context-Adaptive Binary Arithmetic Coding)逐渐成为了现代视频编码中广泛使用的一种数据压缩技术。
基于CABAC的视频编码标准有H.264/AVC、HEVC等。
CABAC算法采用了上下文自适应二元算术编码,具有高压缩比、低码流和良好的可扩展性等优点,但是其解码过程需要大量的计算,因此设计高效的CABAC解码器对于提高视频传输性能具有重要意义。
二、研究目的和意义CABAC解码器是视频解码器中的重要组成部分,其运算需求较大,且占据解码器的大部分时间。
因此,设计高效的CABAC解码器,可以加快视频解码过程,提高解码性能,对于视频类应用的实时性、流畅性等方面具有重要意义。
三、研究内容和方案本文拟研究高效的CABAC解码器设计及FPGA实现,具体研究内容和方案如下:1. 分析CABAC解码器的流程和特点,确定解码器的整体结构和算法实现。
2. 优化解码器算法,提高解码效率、降低功耗等。
3. 设计CABAC解码器的硬件框架,并实现在FPGA上。
4. 对设计的CABAC解码器进行性能测试和实验验证,测试包括解码效率、功耗、资源占用等方面。
五、预期成果通过本论文的研究,预期获得以下成果:1. 设计一种高效的CABAC解码器,对CABAC算法进行优化,提高解码效率,降低功耗。
2. 实现CABAC解码器在FPGA平台上的硬件框架,验证解码器的正确性和可行性。
3. 给出CABAC解码器的性能测试结果和实验验证,涵盖解码效率、功耗、资源占用等方面。
六、论文结构安排本论文拟分为六个章节。
第一章:引言第二章:CABAC算法及其解码原理第三章:CABAC解码器硬件框架设计第四章:CABAC解码器算法优化第五章:CABAC解码器FPGA实现第六章:结论及展望七、参考文献[1] B. B. Zhou, G. J. Sullivan, J. W. Chen, T. Chen, and J. R. Ohm. A comparative study of context-based adaptive binary arithmetic coding(CABAC) engines for the H. 264/AVC baseline profile. In Circuits and Systems, 2005. ISCAS 2005. IEEE International Symposium on, volume 3, pages 1971–1974. IEEE, 2005.[2] K. R. K. Reddy, S. Mohan, and P. Subbarao. Design and implementation of CABAC decoding engine on FPGA. In VLSI Design and Test Symposium (VDAT), 2016 20th, pages 1–5. IEEE, 2016.。

CABAC混合编码一、引言CABAC(Context-based Adaptive Binary Arithmetic Coding)是一种基于上下文的自适应二进制算术编码方法,广泛应用于视频编码、音频编码等领域。
这种方法的主要优点是能够有效地压缩数据,提高编码效率。
二、CABAC的基本原理CABAC编码是一种基于上下文的自适应二进制算术编码方法。
它的基本思想是将每一个符号(Symbol)根据其出现的概率和上下文信息进行二进制算术编码。
这种方法能够有效地压缩数据,提高编码效率。
具体来说,在CABAC 算法中,为了进行上下文自适应编码,需要利用当前编码位置周围的像素值来确定编码上下文。
这些像素值可以通过预测、变换或其他方式来获取。
但在某些情况下,CABAC 算法可能无法提供足够准确的上下文信息,从而导致编码效率降低。
这时,可以采用混合编码的方法,将CABAC 算法与其他编码方式(例如VLC 编码)结合使用,以提高编码效率。
三、CABAC的工作流程1. 初始化:首先,需要对二进制算术编码器进行初始化,设置初始的概率值和上下文信息。
2. 编码:然后,对每一个符号进行编码。
编码的过程包括两个步骤:首先,根据符号的概率和上下文信息,计算出符号的二进制表示;然后,将这个二进制表示进行二进制算术编码。
3. 更新:在编码过程中,需要不断地更新概率值和上下文信息。
这样,可以使编码器更好地适应数据的统计特性,提高编码效率。
四、CABAC的特点1. 高效:CABAC编码是一种高效的编码方法,能够有效地压缩数据,提高编码效率。
2. 灵活:CABAC编码是一种灵活的编码方法,能够适应不同的数据特性和应用场景。
3. 精确:CABAC编码是一种精确的编码方法,能够准确地表示数据的语义信息。
五、CABAC的应用CABAC编码广泛应用于视频编码、音频编码等领域。
在这些领域,CABAC编码能够有效地压缩数据,提高编码效率,同时也能够准确地表示数据的语义信息。

H.264/AVC中的CABAC编码技术彭 芬(武汉职业技术学院电子信息工程系,湖北武汉430074)摘 要:CA BAC是新一代视频压缩算法标准H.264/A VC中采用的新熵编码技术,使用它可以有效提高编码效率,节约码流。
这里介绍了CA BAC编码中算术编码理论的原理和内容模型的基本类型,并以运动矢量差值M VD的编码方法为例详细分析了CABAC的编码过程。
关键词:CA BAC;二进制算术编码;内容模型;H.264/AV C中图分类号:T N919 文献标识码:A0 引言H.264/A VC标准是视频编码专家组(VCEG)和运动图像专家组(M PEG)组成的联合视频组(JV T)研究而成的,该标准于2003年3月正式获得批准。
H.264/A VC支持两种熵编码方法:可变长编码(VL C)和基于内容的自适应二进制算术编码(CA BAC)。
U VL C是从概率统计分布模型得出的,应用单一的码表,没有考虑编码符号间的相关性,不允许根据实际符号的统计特性进行调整。
而实际符号的统计特性会随着空间、时间、视频源、编码条件的变化而发生变化,U V LC用于编码中高比特率视频流信息时性能不理想。
然而高比特视频信息的低码率应用如因特网上的流媒体、无线网的视频传输及视频存储等呼之欲出,对视频压缩编码技术的编码效率提出了新的挑战。
基于内容的自适应二进制算术编码(CABAC)方法根据相邻块的情况进行当前块的编码,充分考虑编码符号间的相关性,可以达到更好的编码效率。
1 CABAC的编码原理1.1 二进制算术编码1.1.1 算术编码基本理论算术编码的基本原理是将编码的消息表示成实数0和1之间的一个区间,消息越长,编码表示它的区间就越小,表示这一区间所需的二进制位就越多。
算术编码机制由两个数区间下界和区间范围进行界定。
区间下界、区间范围的确定方法:新子区间的下界=前子区间的下界+当前符号的区间累计概率x前子区间的宽度。
新区间范围R新=R P(R新是新子区间的宽度,R是前子区间的宽度,P是当前符号的概率)对每一符号,算术编码器按步骤A和B进行处理。

上下文建模为基本的CABAC 编码过程,一种regular coding mode 另一种为 bypass coding mode.只有regular coding mode 应用了上下文模型,而直通模式用于加速编码流程,当概率近似为50%的时候。
这部分主要说明regular coding mode的进程。
这里,先说理论,再讲流程。
理论:1,CABAC 算术编码基础算术编码的复杂度主要体现在概率的估计和更新,CABAC建立了一个基于查表的概率模型,将0~0.5 划分为64个概率量化值,这些概率对应于LPS字符,而MPS的概率为(1-Plps),概率的估计值被限制在查表内,概率的刷新也是依据于查表。
如果当前出现的字符是MPS,则Plps 变小。
划分子区间的乘法运算 R=R x Px对于这里的乘法运算,CABAC首先建立了一个二维表格,存储预先计算好的乘法结果,表格的入口参数一个来自Px( 对应于theta,概率量化值),另一个来自R(R的量化为:p=(R>>6)&3 ),流程图:图中,灰色部分是概率的刷新部分,表TABRangeLPS存储预先计算好的乘法结果,表TransIDxLPS是与对应的概率表。
有三个值是比较特殊的,:theata=0 时,LPS的概率已达到了最大值0.5,如果下一个出现的是LPS,则此时LPS和MPS的字符交换位置.Theta=63对应着LPS的最小概率值,但它并没有纳入CABAC的概率估计和更新的范围,这个值被用做特殊场合,传递特殊信息,比如,当解码器检测到当前区间的划分依据是这个值时,认为表示当前流的结束.Theta=62 ,这是表中的最小值,它对应的刷新值是它自身,当MPS连续出现,LPS 的概率持续减小,到62保持不变。
2 CABAC 上下文模型CABAC将片作为算术编码的生命周期,h.264将一个片内可能出现的数据划分为399个上下文模型,每个模型均有自己的CtxIdx(上下文序号),每个不同的字符依据对应的上下文模型,来索引自身的概率查找表。
HEVC中CABAC解码器的硬件设计与实现袁星范;蔡敏【摘要】context based adaptive binary arithmetic encoding(CABAC) is a kind of high efficient entropy encoding used in HEVC, which has a high compression ratio, but it is complex and difficult to be parallel. In this paper, a high performance CABAC decoder is designed, and the hardware structure of the single cycle decoding 1bit is optimized, and the pipeline structure is used to improve the decoding performance. With the 0.18 μm CMOS process, the integrated area is 97K logic gates, the working frequency is 250MHz, the decoding speed reaches 1bit/cycle, which is suitable for the field of HD video.%基于上下文自适应二进制算术编码(CABAC)是HEVC中采用的一种高效熵编码,具有很高的压缩比,但实现结构复杂,且很难并行化。
本文设计了一个高性能的CABAC解码器,并对单周期解码1bit的硬件结构进行了优化,同时采用流水线结构,进一步提高了解码性能。
采用0.18μm CM OS工艺,综合后面积为48K个逻辑门,工作频率为250 MHz,解码速度达到1 bit/cycle,适用于高清视频领域。
cabac编码解析Cabac编码是一种基于上下文自适应二进制算术编码的编码方式,常被应用于视频编码、图像编码、音频编码等多媒体数据的压缩领域。
在视频编码中,Cabac编码是最主要的编码方式之一,其能够有效地压缩视频数据,提高视频文件的传输效率和存储效率。
本文将从以下几个方面介绍Cabac编码的解析过程。
一、编码原理Cabac编码的编码原理是通过对数据的发生概率进行建模,对每个数据进行二进制编码,从而将数据压缩。
编码时,需要使用已知数据的发生概率来指导编码器将数据编码成二进制数。
当发生概率高时,编码器将使用较短的二进制数进行编码;当发生概率低时,编码器将使用较长的二进制数进行编码。
通过这种方式,Cabac编码可以有效地减少数据的传输量,并提高传输效率。
二、上下文建模在Cabac编码中,上下文建模是非常重要的一环。
通过建立上下文模型,可以得到这个数据的发生概率,并决定使用何种二进制数进行编码。
上下文模型是基于周围数据的分布而建立的,因此,在进行Cabac编码时,需要考虑周围数据的分布,并对上下文模型进行建模。
不同的上下文模型有不同的建模方式,因此,编码器需要根据上下文模型的情况选择合适的编码方式。
三、二进制算术编码Cabac编码采用的是二进制算术编码方式。
算术编码的特点是通过对数据进行概率建模,使用非整数运算的方式来压缩数据。
在使用算术编码时,需要将数据转换成一个符号区间,同时,将符号区间按照概率划分成不同的区域。
编码时,输入的数据将不断逼近符号区间的概率范围,直到符号区间的范围足够小,可以输出编码结果。
四、Cabac编码过程Cabac编码的过程可以分为四个步骤:上下文建模、二进制算术编码、输出二进制码流和输出上下文模型。
首先,在进行Cabac编码时,需要建立上下文模型,以得到数据的概率分布。
然后,采用二进制算术编码方式,将数据转换成一个符号区间,并对符号区间进行概率划分。
接着,通过将符号区间的范围不断缩小,将数据编码成二进制码流输出。
CABAC(上下文自适应的二进制算术编码)是一种基于算术编码的方法,在HEVC(高效视频编码)中,除了参数集、SEI(序列参数集扩展信息)和切片头部之外,其余的所有数据都通过CABAC进行熵编码。
CABAC的工作过程主要包括三个步骤:初始化、二进制化和上下文建模。
- 初始化阶段,会构建上下文概率模型。
在这个过程中,会初始化和上下文模型有关的两个变量:MPS(Most Probable Symbol,最大概率符号)和δ(delta)。
MPS表示待编码符号可能出现的符号,对于二进制算术编码来说,MPS是0或者1;相反,LPS(Least Probable Symbol,最不可能出现的符号),对于二进制算术编码来说,LPS也是0或1。
δ表示概率的状态索引,它的值与LPS的概率值是相对应的,δ值随着LPS概率的更新而变化。
- 二进制化阶段,将连续的语法元素转化为二进制符号流。
这一步主要是为后续的算术编码做准备。
- 上下文建模阶段,根据上下文概率模型获取语法元素的概率,对语法元素进行熵编码。
这一阶段是实际进行编码的阶段。
最后,根据编码结果更新上下文概率模型。
在实际应用中,例如在FFmpeg中,CABAC的解码是由H.264和H.265解码器实现的。
具体来说,H.264解码器中的cabac.h和cabac.c文件实现了CABAC解码器,而H.265解码器中的hevc_cabac.h和hevc_cabac.c文件实现了HEVC标准下的CABAC解码器。
此外,还有研究针对高吞吐率HEVC CABAC残差语法元素的分析和对应的硬件结构设计,以及对CABAC编码中二进制算术编码器常规编码模式下的一种硬件流水线结构进行设计和优化。
Context-Based Adaptive Binary Arithmetic Coding in the H.264/A VC简称Cabac,H264中的一种熵编码方式:基于上下文的自适应二进制算术编码内容安排:1,介绍算术编码2,介绍二进制算术编码3介绍Cabac及其一些实用的实现方式(参考JSVM代码,也可以参考JM)一,算术编码算术编码是一种常用的变字长编码,它是利用信源概率分布特性、能够趋近熵极限的编码方法。
它与Huffman 一样,也是对出现概率大的符号赋予短码,对概率小的符号赋予长码。
但它的编码过程与Huffman 编码却不相同,而且在信源概率分布比较均匀的情况下其编码效率高于Huffman 编码。
它和Huffman 编码最大的区别在于它不是使用整数码。
Huffman 码是用整数长度的码字来编码的最佳方法,而算法编码是一种并不局限于整数长度码字的最佳编码方法。
算术编码是把各符号出现的概率表示在单位概率[0,1] 区间之中,区间的宽度代表概率值的大小。
符号出现的概率越大对应于区间愈宽,可用较短码字表示;符号出现概率越小对应于区间愈窄,需要较长码字表示。
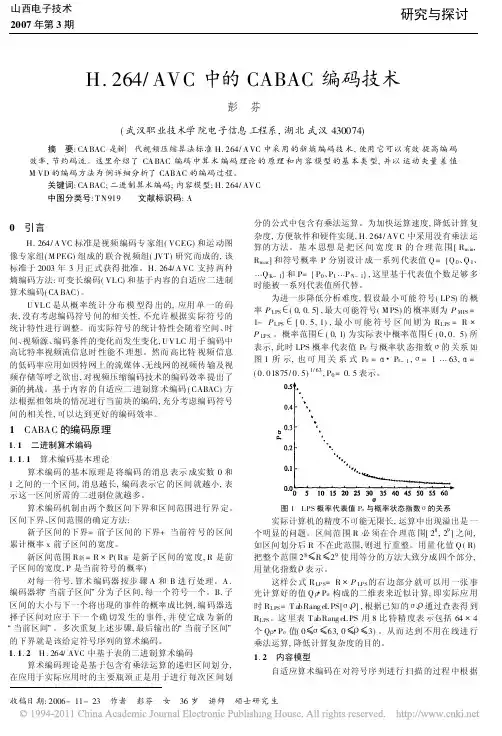
举例如下:S S S S为例以符号3324在算术编码中通常采用二进制分数表示概率,每个符号所对应的概率区间都是半开区间,即该区间包括左端点,而不包括右端点,如S1对应[0, 0.001),S2 对应[0.001, 0.01) 等。
算术编码产生的码字实际上是一个二进制数值的指针,指向所编的符号对应的概率区间。
S S S S…… 的第一个符号S3 用指向第3 个子区间的指针 符号序列3324来代表,可以用这个区间内的任意一个小数来表示这个指针,这里约定这个区间的左端点代表这个指针,因此得到第一个码字.011。
⏹后续的编码将在前面编码指向的子区间内进行,将[.011, .111] 区间再按概率大小划分为4 份,第二个符号S3 指向.1001 (S3 区间的左端),输出码字变为.1001。
⏹然后,S3 对应的子区间又被划分为4 份,开始对第三个符号S2 进行编码,…….⏹两个参量:编码点(指针所指处)C 和区间宽度A。
初始状态编码点(指针所指处)C = 0区间宽度A = 1.0新编码点C = 原编码点C +原区间A×Pi新区间A = 原区间A×pi⏹序列S3S3S2S4 …… 的编码过程:第1个符号(S3): C = 0 + 1×.011 = .011A = 1×.1 = .1第2个符号(S3): C = .011 + .1×.011 = .1001A = .1×.1 = .01第3个符号(S2): C = .1001 + .01×.001 = .10011A = .01×.01 = .0001第4个符号(S4): C = .10011 + .0001×.111 = .1010011 (输出的码字)A = .0001×.001 = .0000001解码过程⏹算法解码采取与编码过程相反的步骤把接收到的码字串指向其对应的子区间,得到此子区间对应的符号,即为解码后的符号。
即从码字串中减去已解码符号的子区间的左端点的数值(累积概率),并将差值除以该子区间的宽度(概率值),得到新的码字串。
⏹上述例子当收到字码串(.1010011) 时,其指向子区间[.011, .111],对应于S3,因此,得到第1 个符号为S3。
新码字串:(.1010011 - .011) ÷(.1) = 0.100011 ,新码字串仍然指向子区间[.011, .111],因此,第2 个符号仍为S3。
其它符号依次类推二,二进制算术编码二进制算术编码的输入的字符只有两种,如果信源字符集内包含有多个字符,则先将这些字符经过一系列的二进判决,变成二进制字符串。
这两个符号构成的序列的编码与算术编码基本原理相同,仍是不断划分概率子区间的递归过程。
在两个输入字符中,出现概率较大的为MPS (More Probable Symbol),MPS的概率为Pe;出现概率较小的为LPS (Less Probable Symbol),LPS 的概率为Qe,Pe=1-Qe。
编码初始化子区间为[0,1],MPS与LPS 分配如图所示:编码时,设置两个专用寄存器(C,A)C 寄存器的值为编码点(指针所指处),初时化为0A 寄存器的值为子区间的宽度(该宽度恰好是已输入符号串的概率),初时化为1 随着被编码数据源输入,C 和 A 的内容按以下编码规则修正:当低概率符号LPS 到来时:C=C ,A=AQe当高概率符号MPS到来时:C=C + AQe ,A=Ape = A(1-Qe)例: 信源符号序列110111110 为LPS Qe = 1/8 =(0.001)b1 为MPS Pe = 7/8 =(0.111)b初始状态:C=0 (子区间起始位置) A=1 (子区间宽度)1,第1个符号1为MPSC = C + AQe = 0 + 1 ⨯0.001 = 0.001A = APe = 1 ⨯0.111 = 0.1112,第2个符号1仍为MPSC=C+AQe = 0.001 + 0.111 ⨯0.001=0.001111A=APe= 0.111 ⨯0.111 =0.1100013,第3个符号0为LPSC=C=0.001111A=A Qe = 0.110001 ⨯0.001 =0.0001100014,继续下去……. 最后得C= 0.010001111110111100000001A= 0.000011001001000010111111此时区间的尾为C+A=0.010101000111111111000000,编码区间[C, C+A)编码输出可以是最后一个编码区间中的任意小数值,但为了取得最好的编码效率,选择的小数应有最短的比特长度。
上面区间我们可取0.0101,即输出为0101 解码过程按Qe、Pe 分成两个子区间,判断被解码的码字落在哪个区间,并赋予对应符号。
设c’ =(0.0101) b是被解码的值,初始值A=1 Qe = 0.001当c’ 落在0-QeA 之间,解码符号为D=0,则C’ = C’, A = Qe A当c’ 落在QeA-A 之间,解码符号为D=1,则C’ = C’-Qe A ,A = A(1-Qe)1,c’ = 0.0101落在Qe A -A 之间,解码符号为D = 1c’ = c’-QeA = 0.0101 - 0.001 = 0.0011 , A = A(1-Qe)= 0.1112,c’= 0.0011 落在Qe A -A 之间,解码符号为D=1c’=c’-QeA= 0.0011 -0.000111=0.000101 ,A=A(1-Qe)= 0.111⨯0.111=0.110001 3,c’ = 0.000101 落在0-QeA 之间,解码符号为 D = 0c’ = c’ = 0.000101 A = AQe = 0.110001 0.001 = 0.000110001三,CABAC原理及其实现CABAC是H264的一种熵编码方案,相比如H264的另外一种熵编码方案CA VLC而言,在可接受的视频质量(30dB到38dB之间)内变化时,前者可节约平均9%到14%的码流。
CABAC有以下几个特性:1,对多数符号使用了自适应概率模型。
2,通过使用上下文关系,利用了符号相关性。
3,限制为二进制算术编码(binary arithmetic coding),基于只用查表和移位方式的快速二进制算术编解码器。
4,399 种预定义的上下文模型,分成了各种不同的模型组,例如模型14-20 用于帧间宏块类型的编码,模型的选择基于前面编码的信息(上下文关系),每个上下文模型适应实验分布。
先大致介绍CABAC的实现过程,然后对一些技术做细节介绍下面是CABAC的编码流程图按上图可知,对一个符号编码有如下过程:1,转化成二进制(Binarization)CABAC使用二值算术编码,也就是说只对二进制的判决(0或者1)进行编码。
非二进制符号(例如转换后的系数或者运动矢量)在编码前先要进行二进制转换。
这一过程和变长编码(VLC)中将信息符号转化为变长编码一样,所不同的是,算术编码器在将信息送去传输之前还要进一步对这些二进制符号进行编码。
2, 选择基于内容的模型:“基于内容的模型”是二进制符号中一个或多个比特的概率模型。
根据对先前已编码符号的统计,从可选模型中选择适当的概率模型。
3, 算术编码:根据选择的概率模型对每个比特进行算数编码。
4, 更新模型上图中的bypass coding是指对于一些特定语法元素的二进制比特符号,为了加快编码速度而不使用上下文模型的形式。
使用CABAC的熵编码方式在时间耗费方面大于CA VLC,为了达到一个折中,在实际编码中,并不是对所有的语法元素都使用CABAC编码方案,有许多表征视频序列本身固有参数特征的语法元素的熵编码还是使用CA VLC。
下图是一些需要用CABAC编码的语法元素及对应的上下文模型索引。
下面来具体介绍编码过程1,二进制化为了降低算术编码的复杂度,提高编码速度,采用二进制算术编码,即进行熵编码的符号是一系列的二进制符号,这得首先需要把编码语法元素转化成二进制串,包括基本方案和串接方案。
Unary Binarization:对于x>=0的无符号整数值,由x个”1”和一个终结符合”0”组成。
Truncated Unary Binarization(TU):给定一个参数S,对于编码符号x,0<=x<=S 有效,如果x>S,则取x=S,对于x<S时,二进制串由Unary Binarization 方案给出,对于x=S,Unary Binarization 方案中的那个终结符号”0”被忽略,此时输出二进制串为x个”1”。
kth order Exp-Golom(EGK) Binarization :由一个前缀和一个后缀码字串接而成,对于给定x,下面是产生一个k 阶指数格雷码的算法while(1){//unary prfix part of EGKif (x>=(1<<k)){put(1)x=x-(1<<k)k++} else {put(0) //terminating “0” of prefix partwhile(k--) //binary suffix part of EGKput((x>>k)&0x01)break}}前缀是由对应值为2log (/21)k x ⎢⎥+⎣⎦的Unary Binarization 方案产生的二进制串组成,后缀由()2(12)k l x x +-这个十进制值对应的二进制串组成。