关于强制降解试验的决策树
- 格式:doc
- 大小:29.50 KB
- 文档页数:8

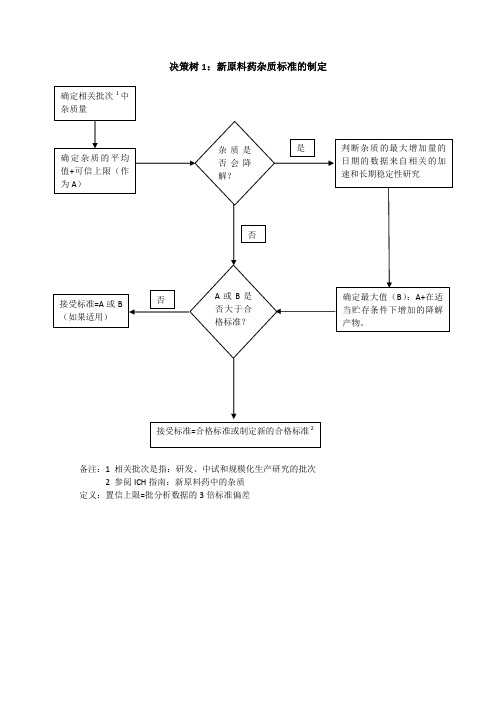
决策树1:新原料药杂质标准的制定
备注:1 相关批次是指:研发、中试和规模化生产研究的批次
2 参阅ICH指南:新原料药中的杂质
定义:置信上限=批分析数据的3倍标准偏差
决策树2:新药产品中降解产物的标准的制定
备注:1 相关批次是指:研发、中试和规模化生产研究的批次
2 指在决策树1中确定的A和B
3 参阅ICH指南:新药品杂质
决策树3:制定原料药粒度分布标准
原料药
药品:固体制剂或还有不溶性药物的液体制剂
注:只有能通过技术手段进行多晶型含量测定的药品进行下列步骤
决策树5:建立新手性原料和含有手性原料药品中原料手性鉴别、含
量和对映体杂质程序
1 天然手性物质不未收录在本指南
2.由其他杂质产生或合成原料引入杂质,手性的质量控制选择使用在开发研究中被证明的起始原料和中间体来进行。
这样的情况,在多手性中心(3个或更多)或在最终产品前一步进行控制时是被认可的。
3一个手性含量或一个对映体杂质程序代替手性鉴别程序是可以接受的
4. 一个非手性检测结合一个相反对映体控制方法替代手性检测是被认可的
5.原料药中相反异构体水平应该来自手性检测数据或一个独立的程序
6. 如果在原料贮存条件下外消旋化很微小,并已经被证实,那么不需要进行立构体测定
决策树6:原料药和辅料的微生物限度检查
被认可的药物释放度标准类型
怎样的特定试验条件和标准是被认可的?(快速释放)
什么是合格的可接受范围?(缓慢释放)
决策树8:非无菌药品的微生物检查。

决策树的三种算法一、决策树算法的简单介绍决策树算法就像是一个超级智能的树状决策指南。
你可以把它想象成一棵倒着长的树,树根在上面,树枝和树叶在下面。
它的任务呢,就是根据不同的条件来做出各种决策。
比如说,你想决定今天穿什么衣服,天气就是一个条件,如果天气冷,你可能就选择穿厚衣服;如果天气热,那薄衣服就比较合适啦。
决策树算法在很多地方都超级有用,像预测一个人会不会买某个商品,或者判断一个邮件是不是垃圾邮件之类的。
二、决策树的三种算法1. ID3算法这个算法就像是一个很会找重点的小机灵鬼。
它主要是根据信息增益来构建决策树的。
啥是信息增益呢?就是通过计算某个属性带来的信息量的增加。
比如说,在判断一个水果是苹果还是香蕉的时候,颜色这个属性可能就有很大的信息增益。
如果一个水果是红色的,那它是苹果的可能性就比较大。
ID3算法会优先选择信息增益大的属性来作为树的节点,这样就能更快更准地做出决策啦。
不过呢,这个算法也有个小缺点,就是它比较容易对噪声数据敏感,就像一个很敏感的小娃娃,稍微有点风吹草动就可能受到影响。
2. C4.5算法C4.5算法就像是ID3算法的升级版。
它在ID3算法的基础上做了一些改进。
它不仅仅考虑信息增益,还考虑了信息增益率。
这就好比是一个更加全面考虑的智者。
通过考虑信息增益率,它能够更好地处理那些属性值比较多的情况。
比如说,在一个数据集中有一个属性有很多很多不同的值,C4.5算法就能比ID3算法更好地处理这种情况,不会轻易地被这种复杂情况给弄晕。
而且C4.5算法还能够处理连续的属性值,这就像是它多了一项特殊的技能,让它在更多的情况下都能发挥作用。
3. CART算法CART算法又有自己的特点。
它使用的是基尼系数来选择属性进行划分。
基尼系数就像是一个衡量公平性的小尺子,在决策树这里,它是用来衡量数据的纯度的。
如果基尼系数越小,说明数据越纯,就越容易做出准确的决策。
CART算法既可以用于分类问题,就像前面说的判断水果是苹果还是香蕉这种,也可以用于回归问题,比如预测房价之类的。

药学质量研究中的强制降解试验强制降解试验通常也称为破坏试验,是分别对原料药、制剂或参比制剂进行强制降解的试验。
各破坏条件下样品的图谱应与空白溶液、空白辅料和未破坏样品的图谱进行对比,其目的是了解不同的破坏条件下,不同时间药物的降解产物和降解程度,对降解杂质产生的机理进行进一步的论证。
本文围绕强制降解条件的选择及结果判断展开探讨。
1、样品配制对于原料药的强制降解试验,我们一般需要配制4种样品进行对比试验:①放置于常规条件下的空白溶液;②放置于降解条件下的空白溶液;③放置于常规条件下的样品溶液;④放置于降解条件下的样品溶液。
对于制剂样品的强制降解试验,除考察上述原料药的强制降解试验中的4种样品之外,我们还需考察2种对比试验:①放置于常规条件下的空白辅料溶液;②放置于降解条件下的空白辅料溶液。
2、强制降解条件的选择典型的强制降解主要包括四种机制:酸碱水解、氧、光、热。
破坏试验的条件通常需要摸索以确定适当的破坏条件,如:酸碱和氧化剂的浓度、破坏温度和破坏时间等,对确定供试品最佳的降解程度至关重要。
若样品破坏程度不足,无法达到进行强制降解试验的目的,破坏过度又会产生药品稳定性研究过程和正常破坏条件下均不会产生的二次降解产物,影响强制降解试验结果的判断。
因此,强制降解试验过程中,控制样品降解程度使之达到预期的水平是十分必要的。
通常认为样品降解量应在5~20%之间是合适的。
2.1 酸碱水解原料药与制剂应在常温或更高温度条件下,以溶液状态进行酸碱水解破坏试验,酸碱的种类和浓度的选择取决于药物本身的特点。
酸破坏一般采用0.1mol/L~1.0mol/L的盐酸或硫酸,碱破坏通常采用0.1mol/L~1.0mol/L的氢氧化钠或氢氧化钾溶液,破坏时间根据降解程度选择,破坏程度建议应不高于15%。
了解并分析化合物的结构和理化性质对于选择合适的破坏条件也具有一定的参考作用,例如,某化合物含有酯基,则可知它对碱是不稳定的,应选择较低浓度的碱进行破坏。

决策树名词解释决策树(DecisionTree)是一种常见的数据挖掘技术,也称为决策树分类(Decision Tree Classification)。
决策树是一种以树状结构表示数据的模型,它可以用来描述一组数据集的概念,它可以用来作出决策。
策树是一种数据挖掘的常用算法,它可以用于分类、回归任务,以及关联规则建模,它可以帮助智能系统理解数据,从而实现更好的决策。
决策树的基本原理很简单,它是一种将每个属性值与实例的关联转换成树形结构的方法。
在这种树形结构中,每个节点存储关联属性的值,从而决定一个决策。
策树通常用于研究一组已知数据,它可以用来预测未知数据的结果,也可以用来归类数据,从而发现数据的规律性。
决策树的建立有很多步骤,但是大致可以分为以下几个步骤:(1)数据集准备:首先,需要对数据集进行预处理,将数据分成训练集和测试集。
(2)决策树划分:根据训练集中的特征属性,将数据集划分为不同的分支,并且不断划分,直到达到决策树模型所需要的精度或停止条件为止。
(3)估属性:根据训练集中的数据,选择最优的划分属性,用于对训练集进行划分。
(4)决策树剪枝:新建的决策树可能过度拟合训练数据,这会使训练出来的决策树在测试数据上的表现变差,因此,需要使用剪枝算法,来减少决策树的过拟合现象。
(5)测试:根据训练好的决策树,对测试集数据进行分类,统计测试集分类正确率,从而对决策树进行评估。
决策树在实际应用中可以用于社会决策分析、企业决策分析、关联规则挖掘等应用场景,但是决策树也有若干缺点。
其一,决策树生成过程中属性之间的关系可能非线性,而决策树假设属性之间的关系是线性的,因此可能导致决策树模型的准确性不足。
其二,决策树的剪枝操作可能会过度剪枝,也影响模型的准确性。
总之,决策树是一种常用的数据挖掘技术,它可以用于推理和预测数据,它可以用来帮助智能系统理解数据,从而改善决策效率。
但是,因为决策树的局限性,仍然需要其他的数据挖掘技术来提高决策的准确性。

决策树决策树法(Decision Tree)决策树(decision tree)一般都是自上而下的来生成的。
每个决策或事件(即自然状态)都可能引出两个或多个事件,导致不同的结果,把这种决策分支画成图形很像一棵树的枝干,故称决策树。
决策树就是将决策过程各个阶段之间的结构绘制成一张箭线图,我们可以用下图来表示。
选择分割的方法有好几种,但是目的都是一致的:对目标类尝试进行最佳的分割。
从根到叶子节点都有一条路径,这条路径就是一条“规则”。
决策树可以是二叉的,也可以是多叉的。
对每个节点的衡量:1) 通过该节点的记录数2) 如果是叶子节点的话,分类的路径3) 对叶子节点正确分类的比例有些规则的效果可以比其他的一些规则要好。
决策树的构成要素[1]决策树的构成有四个要素:(1)决策结点;(2)方案枝;(3)状态结点;(4)概率枝。
如图所示:总之,决策树一般由方块结点、圆形结点、方案枝、概率枝等组成,方块结点称为决策结点,由结点引出若干条细支,每条细支代表一个方案,称为方案枝;圆形结点称为状态结点,由状态结点引出若干条细支,表示不同的自然状态,称为概率枝。
每条概率枝代表一种自然状态。
在每条细枝上标明客观状态的内容和其出现概率。
在概率枝的最末稍标明该方案在该自然状态下所达到的结果(收益值或损失值)。
这样树形图由左向右,由简到繁展开,组成一个树状网络图。
决策树对于常规统计方法的优缺点优点:1)可以生成可以理解的规则;2)计算量相对来说不是很大;3) 可以处理连续和种类字段;4) 决策树可以清晰的显示哪些字段比较重要。
缺点:1) 对连续性的字段比较难预测;2) 对有时间顺序的数据,需要很多预处理的工作;3) 当类别太多时,错误可能就会增加的比较快;4) 一般的算法分类的时候,只是根据一个字段来分类。
决策树的适用范围[1]科学的决策是现代管理者的一项重要职责。
我们在企业管理实践中,常遇到的情景是:若干个可行性方案制订出来了,分析一下企业内、外部环境,大部分条件是己知的,但还存在一定的不确定因素。
如何利用决策树分析解决问题决策树是一种常见且有效的数据分析工具,它能够帮助我们理清问题的逻辑关系并做出准确的决策。
无论是在商业、科研还是日常生活中,决策树都具有广泛的应用。
本文将介绍如何利用决策树分析解决问题,并提供一些实用的技巧和案例分析。
一、决策树的基本概念决策树是一种以树状结构表示决策规则的模型。
它由根节点、内部节点和叶节点组成,其中根节点代表问题的提出,内部节点代表问题的判断条件,叶节点代表问题的解决方案。
通过依次对问题进行判断,最终到达叶节点得到问题的解决方案。
二、决策树的构建方法构建一棵决策树需要以下几个步骤:1. 收集数据:收集问题相关的数据,并整理成表格的形式。
表格的每一行代表一个样本,每一列代表一个特征。
2. 选择划分属性:根据数据的特征进行划分属性的选择,常用的指标有信息增益、信息增益率、基尼指数等。
3. 构建决策树:根据选择的划分属性,递归地对数据进行划分,直到所有的样本都属于同一个类别或者无法继续划分为止。
4. 剪枝处理:根据实际情况对决策树进行剪枝处理,避免过拟合问题。
三、决策树的应用案例1. 商业决策:决策树可以帮助企业根据过去的销售数据和市场情况,对不同的产品进行合理的定价策略、推广策略和促销策略的制定。
2. 医学诊断:决策树可以对疾病的症状和检测结果进行分析,并帮助医生判断疾病的类型和治疗方案。
3. 个人贷款:银行可以利用决策树对个人信用评级进行分析,从而判断是否给予贷款以及贷款的利率和额度。
4. 电子商务推荐系统:决策树可以根据用户的购买记录和兴趣偏好,为用户推荐相似的商品或服务。
四、决策树分析的注意事项1. 数据质量:决策树的准确性和稳定性依赖于数据的质量,因此需要对数据进行清洗和预处理,排除噪声和异常值。
2. 属性选择:划分属性的选择对构建决策树的准确性和效率有重要影响,需要根据具体问题选择合适的划分属性。
3. 过拟合问题:决策树容易过拟合训练数据,在构建决策树时需要进行剪枝处理或采用其他方法避免过拟合。
决策树算法实验总结
决策树算法是一种常用的机器学习算法,它通过对数据集进行递归划分,构建出一棵树状的决策模型。
在实验中,我们使用了决策树算法进行分类任务,并对实验结果进行总结。
首先,我们需要准备一个带有标签的训练数据集,其中包含了多个特征和对应的类别标签。
然后,我们可以使用决策树算法对训练数据集进行训练,构建出一棵具有判断条件的决策树。
在实验中,我们可以使用不同的指标来评估决策树算法的性能,例如准确率、精确率、召回率等。
这些指标可以帮助我们了解决策树算法在分类任务中的表现。
此外,我们还可以通过调整决策树算法的参数来提高其性能。
例如,可以通过限制树的最大深度、设置叶子节点的最小样本数等来控制决策树的复杂度,避免过拟合问题。
在实验总结中,我们可以描述决策树算法在实验中的表现,比较其与其他算法的优劣势,并提出进一步改进的方向。
此外,还可以讨论决策树算法在不同数据集上的适用性,并分析其在实际应用中可能遇到的问题和局限性。
总而言之,决策树算法是一种简单而有效的机器学习算法,可以用于分类任务。
通过实验总结,我们可以更好地理解决策树算法的原理和性能,为进一步的应用和改进提供指导。
决策树实验报告决策树实验报告引言决策树是一种常见的机器学习算法,被广泛应用于数据挖掘和预测分析等领域。
本文将介绍决策树的基本原理、实验过程和结果分析,以及对决策树算法的优化和应用的思考。
一、决策树的基本原理决策树是一种基于树形结构的分类模型,通过一系列的判断和决策来对数据进行分类。
决策树的构建过程中,首先选择一个特征作为根节点,然后根据该特征的取值将数据划分为不同的子集,接着对每个子集递归地构建子树,直到满足停止条件。
构建完成后,通过树的分支路径即可对新的数据进行分类。
二、实验过程1. 数据准备为了验证决策树算法的效果,我们选择了一个包含多个特征的数据集。
数据集中包含了学生的性别、年龄、成绩等特征,以及是否通过考试的标签。
我们将数据集分为训练集和测试集,其中训练集用于构建决策树模型,测试集用于评估模型的准确性。
2. 决策树构建在实验中,我们使用了Python编程语言中的scikit-learn库来构建决策树模型。
首先,我们导入所需的库和数据集,并对数据进行预处理,包括缺失值处理、特征选择等。
然后,我们使用训练集来构建决策树模型,设置合适的参数,如最大深度、最小样本数等。
最后,我们使用测试集对模型进行评估,并计算准确率、召回率等指标。
3. 结果分析通过实验,我们得到了决策树模型在测试集上的准确率为80%。
这意味着模型能够正确分类80%的测试样本。
此外,我们还计算了模型的召回率和F1值等指标,用于评估模型的性能。
通过对结果的分析,我们可以发现模型在某些特征上表现较好,而在其他特征上表现较差。
这可能是由于数据集中某些特征对于分类结果的影响较大,而其他特征的影响较小。
三、决策树算法的优化和应用1. 算法优化决策树算法在实际应用中存在一些问题,如容易过拟合、对噪声敏感等。
为了提高模型的性能,可以采取以下措施进行优化。
首先,可以通过剪枝操作减少决策树的复杂度,防止过拟合。
其次,可以使用集成学习方法,如随机森林和梯度提升树,来进一步提高模型的准确性和鲁棒性。
实验二决策树实验实验报告
一、实验目的
本实验旨在通过实际操作,加深对决策树算法的理解,并掌握
决策树的基本原理、构建过程以及应用场景。
二、实验原理
决策树是一种常用的机器学习算法,主要用于分类和回归问题。
其基本原理是将问题划分为不同的决策节点和叶节点,通过一系列
的特征测试来进行决策。
决策树的构建过程包括特征选择、划分准
则和剪枝等步骤。
三、实验步骤
1. 数据收集:从开放数据集或自有数据中选择一个适当的数据集,用于构建决策树模型。
2. 数据预处理:对收集到的数据进行缺失值处理、异常值处理
以及特征选择等预处理操作,以提高模型的准确性和可靠性。
3. 特征选择:采用合适的特征选择算法,从所有特征中选择对
分类或回归任务最重要的特征。
4. 构建决策树模型:根据选定的特征选择算法,以及划分准则(如信息增益或基尼系数)进行决策树模型的构建。
5. 模型评估:使用交叉验证等方法对构建的决策树模型进行评估,包括准确率、召回率、F1-score等指标。
6. 模型调优:根据评估结果,对决策树模型进行调优,如调整模型参数、采用剪枝技术等方法。
7. 模型应用:将得到的最优决策树模型应用于实际问题中,进行预测和决策。
四、实验结果及分析
在本次实验中,我们选择了某电商网站的用户购买记录作为数据集,利用决策树算法构建用户购买意愿的预测模型。
经过数据预处理和特征选择,选取了用户地理位置、年龄、性别和购买历史等特征作为输入。
利用信息增益作为划分准则,构建了一棵决策树模型。
关于强制降解试验的决策树降解试验目的“Stability testing of New Drug Substances and Products”ICH Q1A (R2)要求,原料药需进行强制降解试验以阐明其结构的稳定性,同时有助于识别其可能产生的降解产物。
2015年,CFDA发布的《化学药物(原料药和制剂)稳定性研究技术指导原则(修订)》中指出,原料药的稳定性研究需进行影响因素试验,即“通过给予原料药较为剧烈的试验条件,如高温、高湿、光照、酸、碱、氧化等,考察其在相应条件下的降解情况,以了解试验原料药对光、湿、热、酸、碱、氧化等的敏感性、可能的降解途径及产生的降解产物,并为包装材料的选择提供参考信息。
”下面是ANDAs 中的部分关于强制降解试验的缺陷:a. Your drug substance does not show any degradation under any of the stress conditions. Please repeat stress studies to obtain adequate degradation. If degradation is not achievable, please provide your rationale.b. Please note that the conditions employed for stress study are too harsh and that most of your drug substance has degraded. Please repeat your stress studies using milder conditions or shorter exposure time to generate relevant degradation products.c. It is noted that you have analyzed your stressed samples as per the assay method conditions. For therelated substances method to be stability indicating, the stressed samples should be analyzed using related substances method conditions.d. Please state the attempts you have made to ensure that all the impurities including the degradation products of the unstressed and the stressed samples are captured by your analytical method.e. Please provide a list summarizing the amount of degradation products (known and unknown) in your stressed samples.f. Please verify the peak height requirement of your software for the peak purity determination.g. Please explain the mass imbalance ofthe stressed samples.h. Please identify the degradation products that are formed due todrug-excipient interactions.i. Your photostability study shows that the drug product is very sensitive to light. Please explain how this is reflected in the analytical method, manufacturingprocess, product handling, etc.强制降解实际情况然而,指南中仅建议了温度(如50度、60度)、湿度(如75%RH或更高)、光(参见ICH Q1B)的降解试验条件,对于酸、碱、氧化试验没有做过多的描述。
因此,在具体试验过程中,我们常常会有这样的困惑:1)什么样的反应物能有助于降解试验?2)在进行氧化降解时,什么样的氧化剂最佳?3)进行酸降解时,能否使用硫酸代替盐酸?4)如果前一次的降解试验没有得到足够的降解产物,那么,我们该采用什么极端的条件以获得足够用于分离鉴别的降解产物?5)是否有这样或那样的条件,我们满足后就可停止或不需再进一步的试验?酸降解在进行酸降解时常用0.1N ~ 1.0N HCl,也有使用更浓的HCl;而除了使用盐酸外,也有使用不同浓度硫酸作为酸降解试剂。
同时,不同酸降解的反应条件也是多种多样,反应温度从40度到110度,甚者采用回流或沸腾条件,反应时间也从1小时到2个月不等。
有的药物,如奥美拉唑,选用0.5N的硫酸回流5min即完全降解,而头孢氨苄在同样条件下一点没有发生降解;有的药物在0.1N盐酸条件下回流1周也未发生降解。
碱降解NaOH是常用的碱降解试剂,浓度从0.1N到1.0N不等,有时也使用KOH,但使用得比较少。
与酸降解一样,对于碱降解的反应温度变化也很大,从30度到100度甚至沸腾或回流。
由于不同分子内部结构的差异,有些分子在0.1N氢氧化钠条件下沸腾一周未发生降解,而有些分子如三氟拉嗪在0.1N氢氧化钠、30度温度下放置24小时即可发生完全降解。
同理,当使用1N的NaOH时,有些分子如雷尼替丁,沸腾20min即可降解至84.4%,而诺氟沙星在100度下进行15小时也未发生降解。
氧破坏在进行氧破坏的氧化剂中,常用的氧化剂为双氧水,浓度为1%到30%。
有些药物比较容易发生氧降解,如盐酸雷尼替丁和盐酸西咪替丁,使用3%的浓度在室温下即可较快完成降解试验;而有的药物如盐酸舍曲林,在浓度为10%条件下回流6个小时也未发生一点的降解。
这表明,有些药物是易被氧化的,而有的药物则不易被氧化,甚至使用更高浓度的氧化剂也不会氧化降解。
光降解很多光降解试验表明,在进行光降解时,光降解条件也非一成不变的。
根据药物特点,药物可暴露于长波长或短波长的紫外灯下,也可暴露于400-1580fc的日光灯下,试验温度一般为室温或接近室温,试验周期为几个小时到几个月不等,依赖于光源强度。
盐酸西咪替丁在UV下进行几个月也未发生降解;维生素A酸在UV下2h即降解了一半。
决策树药物分类根据药物的稳定性情况,我们可以将它们分为六类:极不稳定、很不稳定、不稳定、稳定、非常稳定、极度稳定。
光降解中,根据ICH光降解条件将药物分为两类:对光敏感和对光不敏感,即如果药物在ICH推荐的光条件下(1.2*106 lux h)能充分分解或完全降解,那么该药物为对光敏感类药物;否则,将总照度改为6.0*106 lux h。
当我们拿到一个新药物时,我们一般首先将它默认为是第三类“不稳定”药物,然后根据反应结果来判断是否需要加大或弱化降解反应条件。
酸/碱降解为了研究药物在酸/碱条件下的水解过程,我们可以先从0.1NHCl/NaOH回流8小时开始,认为药物是不稳定的,见下图决策树:如果能够获得足够降解产物或者说能达到试验目的,那么就可不必再进行深究试验;如果药物没有发生降解,则可以增加酸/碱的浓度,同时增加反应时间;依次类推。
如果药物在5N浓度下回流24小时(苛刻条件)还未发生降解,则该药物为“极度稳定”一类。
另一方面,若药物在初始条件下即完全降解,那么,则应降低酸/碱浓度,同时降低反应温度;若浓度降低至0.01N、反应时间降低至2h、反应温度降低至25度(接近室温),药物仍能充分降解,则该药物为“极不稳定”一类,需探索更温和的反应温度和反应pH值。
从上图的酸/碱降解决策树中可发现,推荐的起始降解条件为0.1N酸/碱,回流8小时;假如起始降解条件不满足降解要求,则恶化降解条件。
不推荐直接采用恶化条件进行降解试验:1)直接采用更恶劣的降解条件,可能会改变药物降解的路径或反应机制;2)浓度过高的酸或碱对HPLC柱子有损伤。
在进行降解试验前了解一下药物分子的结构信息有时也是有帮助的,如,药物小分子上有一个酯基,酯基易于水解,那么我们可能使用低浓度的碱即可完成试验。
氧破坏为了研究药物氧破坏的难易程度,我们可以先将药物放置于3%H2O2在室温下反应6小时作为起始条件,见下图决策树:如果能够获得足够降解产物或者说能达到试验目的,那么就可不必再进行深究试验;如果药物没有发生降解,则可以先增加反应时间,由原来的6小时提高至24小时;如果药物仍未发生降解,则可以增加氧化剂浓度,由3%提高到10%;若还未降解,则氧化剂浓度可提高至30%;若药物在30%H2O2浓度下反应24小时仍不能发生降解,则该药物为“极度稳定”一类。
另一方面,若药物在初始条件下即完全降解,那么,则应降低H2O2的浓度,从3%降低至1%,同时缩短反应时间;若氧化剂浓度降低至1%、反应时间降低至30min,药物仍能完全降解,则需探索更低氧化剂浓度和更短的反应时间。
金属离子有助于氧化反应的进行,是氧化反应的催化剂,因此,有时额外补加一点金属离子,氧降解反应会增加几千倍,如铜有助于将维生素C的氧降解提高1万倍。
但并非所有的氧降解加金属离子均可以,有时加入金属离子会使原有的降解路线发生改变。
光降解光降解与其它条件有所不同,药物的起始反应条件与ICH推荐的一致,即1.2*106 lux h,若在此条件下未发生降解,则可将总照度提高至5倍,即6.0*106 lux h;若此条件下药物仍未发生降解,则该药物为“对光不敏感”一类。
对于光降解试验,建议主要还是遵从ICH Q1B指南,可采用任何输出相似于D65/ID65发射标准的光源,如具有可见-紫外输出的人造日光荧光灯、氙灯或金属卤化物灯,因此,可尝试符合ICH要求的不同灯源。
若采用氙灯,达到目标总照度(1.2*106Lux hr)一般需要4小时左右,如果采用荧光灯或近UV灯,按输出5000-10000lux 算需要5-10天才能达到目标总照度。
有时,我们可以直接将样品置于太阳光照下进行降解试验。
在炎热的夏天,样品置于太阳下光照4小时产生的降解程度与样品置于氙灯或金属卤化物灯下光照8天降解程度差不多。
但需要注意的是,一年中太阳光的照度随季节在变。