哈夫曼编码系统优化设计及其FPGA硬件实现
- 格式:pdf
- 大小:1.16 MB
- 文档页数:3

图1 硬件总体框架计算信号。
计算模块进行计算,生成各字符对应的编码值,做成编码表,结束后向输出模块发送输出信号。
最后输出模块通过查表方式输出各字符的编码值以及哈夫曼编码结果。
FIFO模块用于接收原始数据和向输出模块提供数据源。
3 实现流程本文使用verilog语言在vivado平台上进行哈夫曼编码硬件模块的实现,选用器件为xc7a100tcsq324-1。
3.1 FIFO模块本文的FIFO模块使用vivado的IP核生成,设计时选择好相应参数配置,生成verilog文件后即可直接调用。
3.2 输入模块使用多个计数器对输入各字符频数以及输入字符总量进行计数,频数被存放在寄存器中,当字符输入结束个寄存器记录字符池的频数3.3.2 哈夫曼编码计算流程进行哈夫曼编码计算时作完成各字符编码的生成以及字符在字符池中的移动以图2中的实例描述计算流程图2中共有5种字符,“1”:10,“2”:20,“图2(a)为初始化效果,符,每个字符池的频数恰为那个字符的频数的编码值和编码长度清零循环操作,最终可以从图值和编码长度,“0”编码值为1011,“2”编码值为111编码值为0。
每次循环操作包含排序图2 硬件实现哈夫曼算法执行过程示例和、频数更新、字符移动、编码值更新及编码长度更新8步。
其中前4步按顺序完成,然后同时完成后4步。
总循环次数由字符种类数控制。
排序操作功能是将每个节点池的频数从小到大进行排序,本文借鉴了参考文献[5]中的方法,硬件实现时通过构建比较器阵列将每两个数两两比较,再通过加法器对每个字符频数的比较结果求和。
对一个字符频数,若它小于另一个字符的频数,则相应结果为0,否则为1。
那么通过指定字符频数与其他字符频数的比较结果之和可以得知它的频数在所有频数中的位置。
挑选操作是将排序操作中比较结果为0和1对应的字符频数选出,它们代表最小频数和次小频数,挑选操作同时挑选出这两个频数对应的字符池ID。
硬件实现时构字符池频数变成字符移动操作指将特定字符从一个字符池移动到另一个字符池中字符池的所有字符移动到次小频数对应字符池中图3 输入时序图4 输出时序图5 控制台输出本系统采用NI 公司的LabVIEW 软件进行开发。

v .. . ..安徽大学数据结构课程设计报告项目名称:哈弗曼编/译码系统的设计与实现姓名:鉏飞祥学号:E21414018专业:软件工程完成日期2016/7/4计算机科学与技术学院1 .需求分析1.1问题描述•问题描述:利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(解码)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发站设计一个哈夫曼编译码系统。
1.2基本要求(1)输入的形式和输入值的范围;(2)输出的形式;(3)程序所能达到的功能。
1.基本要求(1)初始化(Initialzation)。
从数据文件DataFile.data中读入字符及每个字符的权值,建立哈夫曼树HuffTree;(2)编码(EnCoding)。
用已建好的哈夫曼树,对文件ToBeTran.data中的文本进行编码形成报文,将报文写在文件Code.txt中;(3)译码(Decoding)。
利用已建好的哈夫曼树,对文件CodeFile.data中的代码进行解码形成原文,结果存入文件Textfile.txt中;(4)输出(Output)。
输出DataFile.data中出现的字符以及各字符出现的频度(或概率);输出ToBeTran.data及其报文Code.txt;输出CodeFile.data及其原文Textfile.txt;2. 概要设计说明本程序中用到的所有抽象数据类型的定义。
主程序的流程以及各程序模块之间的层次(调用)关系。
(1)数据结构哈夫曼树的节点struct huff{int weight;int parent;int l;int r;};哈夫曼编码的存储struct huff *hufftree;(2)程序模块选择1到i-1中parent为0且权值最小的两个下标void Select(struct huff *HT, int n, int &s1, int &s2)构建哈夫曼树:void huffmancoding(struct huff *ht,int *w,int n)对原文进行编码:void code(char *c)根据报文找到原文:void decoding(char *zifu)3. 详细设计核心技术分析:1:构建哈夫曼树及生成哈夫曼编码:根据每个字符权值不同,根据最优二叉树的构建方法,递归生成哈夫曼树,并且用数组存放哈夫曼树。
哈夫曼编/译码的设计与实现实验报告问题描述利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发编写一个哈夫曼码的编/译码系统。
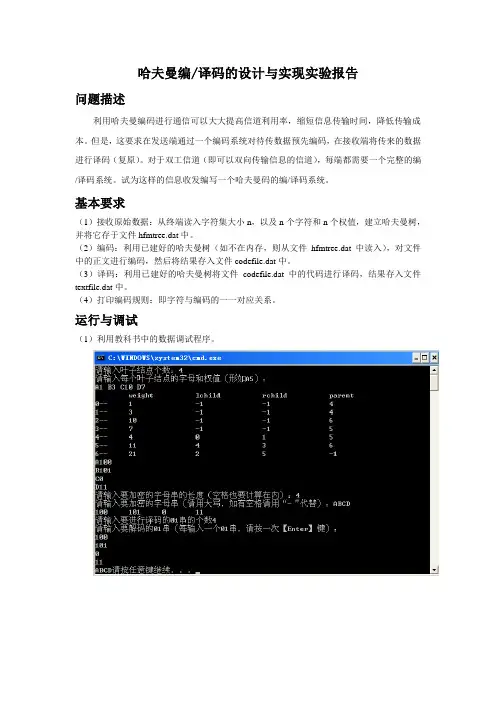
基本要求(1)接收原始数据:从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件hfmtree.dat中。
(2)编码:利用已建好的哈夫曼树(如不在内存,则从文件hfmtree.dat中读入),对文件中的正文进行编码,然后将结果存入文件codefile.dat中。
(3)译码:利用已建好的哈夫曼树将文件codefile.dat中的代码进行译码,结果存入文件textfile.dat中。
(4)打印编码规则:即字符与编码的一一对应关系。
运行与调试(1)利用教科书中的数据调试程序。
(2)用下表给出的字符集和频度的实际统计数据建立哈夫曼树,并实现以下报文的编码和译码:“THIS-PROGRAM-IS-MY-FA VORITE”。
字符 A B C D E F G H I J K L M 频度186 64 13 22 32 103 21 15 47 57 1 5 32 20 字符N O P Q R S T U V W X Y Z频度57 63 15 1 48 51 80 23 8 18 1 16 1实验小结通过这次实验,让我对于树的应用多了认识,在读取文件时,遇到的一些困难,不过在和同学交流的过程中,解决了这个问题,我觉的自己对于树及文件的应用又有了一些进步。
通过这次实验,感觉收获很大。
源程序// 哈夫曼编译码的设计与实现.cpp : 定义控制台应用程序的入口点。
//#include "stdafx.h"#include<iostream>#include<fstream>#include<string>#define Maxvalue 10000#define MAXBIT 200using namespace std;struct node{char letter;string num;};typedef struct{char letter;int weight; //结点权值int parent;int lchild;int rchild;}HnodeType;typedef struct{int bit[MAXBIT];int start;}HcodeType;HnodeType *HaffmanTree(int n){HnodeType *HuffNode;HuffNode=new HnodeType[2*n-1];int i,j;int m1,m2,x1,x2;for(i=0;i<2*n-1;i++) //数组HuffNode[]初始化{HuffNode[i].weight=0;HuffNode[i].parent=-1;HuffNode[i].lchild=-1;HuffNode[i].rchild=-1;}cout<<"请输入每个叶子结点的字母和权值(形如A5):"<<endl;for(i=0;i<n;i++)cin>>HuffNode[i].letter>>HuffNode[i].weight; //输入n个叶子结点的权值for(i=0;i<n-1;i++) //构造哈夫曼树{m1=m2=Maxvalue;x1=x2=0;for(j=0;j<n+i;j++) //选取最和次小两个权值{if(HuffNode[j].parent==-1&&HuffNode[j].weight<m1){m2=m1;x2=x1;m1=HuffNode[j].weight;x1=j;}else{if(HuffNode[j].parent==-1&&HuffNode[j].weight<m2){m2=HuffNode[j].weight;x2=j;}}}//将找出的两棵子树合并为一棵子树HuffNode[x1].parent=n+i;HuffNode[x2].parent=n+i;HuffNode[n+i].weight=HuffNode[x1].weight+HuffNode[x2].weight;HuffNode[n+i].lchild=x1;HuffNode[n+i].rchild=x2;}cout<<" weight"<<" lchild"<<" rchild"<<" parent"<<endl; for(i=0;i<2*n-1;i++)cout<<i<<"--"<<" "<<HuffNode[i].weight<<" "<<HuffNode[i].lchild<<" "<<HuffNode[i].rchild<<" "<<HuffNode[i].parent<<endl;ofstream outFile("hfmtree.dat",ios::out);if(!outFile)cerr<<"文件打开失败!"<<endl;else{outFile<<" weight"<<" lchild"<<" rchild"<<"parent"<<endl;for(i=0;i<2*n-1;i++)outFile<<i<<"--"<<" "<<HuffNode[i].weight<<""<<HuffNode[i].lchild<<" "<<HuffNode[i].rchild<<""<<HuffNode[i].parent<<endl;outFile.close();}return HuffNode;}void HaffmanCode(HnodeType *HuffNode,int n){HcodeType *HuffCode,cd;HuffCode=new HcodeType[2*n-1];int c,p,i,j;for(i=0;i<n;i++){cd.start=n-1;c=i;p=HuffNode[c].parent;while(p!=-1){if(HuffNode[p].lchild==c)cd.bit[cd.start]=0;elsecd.bit[cd.start]=1;cd.start--;c=p;p=HuffNode[c].parent;}for(j=cd.start+1;j<n;j++)HuffCode[i].bit[j]=cd.bit[j];HuffCode[i].start=cd.start;}for(i=0;i<n;i++){cout<<HuffNode[i].letter;for(j=HuffCode[i].start+1;j<n;j++)cout<<HuffCode[i].bit[j];cout<<endl;}ofstream outFile1("codefile.dat",ios::out|ios::binary);if(!outFile1)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<n;i++){outFile1<<HuffNode[i].letter;for(j=HuffCode[i].start+1;j<n;j++)outFile1<<HuffCode[i].bit[j];outFile1<<endl;}outFile1.close();}}int _tmain(int argc, _TCHAR* argv[]){HnodeType *HuffNode;int n,i;cout<<"请输入叶子结点个数:";cin>>n;if(cin.fail()){cout<<"输入有误!"<<endl;return 0;}HuffNode=HaffmanTree(n);HaffmanCode(HuffNode,n);int num;cout<<"请输入要加密的字母串的长度(空格也要计算在内):";cin>>num;char *l1;char l;node l2[27];l1=new char[num];cout<<"请输入要加密的字母串(请用大写,如有空格请用“-”代替):";for(int n=0;n<num;n++)cin>>l1[n];ofstream outFile2("bianma.dat",ios::out|ios::binary);if(!outFile2)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<num;i++)outFile2<<l1[i];outFile2.close();}ifstream inFile1("codefile.dat",ios::in|ios::binary);ifstream inFile2("bianma.dat",ios::in|ios::binary);cerr<<"读取文件失败!"<<endl;if(!inFile2)cerr<<"读取文件失败!"<<endl;else{while(inFile2.peek ()!=EOF){inFile2>>l;for(i=0;i<2*n-1;i++){inFile1>>l2[i].letter;inFile1>>l2[i].num;}for(i=0;i<n;i++){if(l2[i].letter==l)cout<<l2[i].num<<" ";}}inFile1.close();inFile2.close();}delete []l1;cout<<endl;int a;cout<<"请输入要进行译码的串的个数:";cin>>a;string *s;s=new string[a];cout<<"请输入要解码的串(每输入一个串,请按一次【Enter】键):"<<endl; for(i=0;i<a;i++)cin>>s[i];ofstream outFile4("yima.dat",ios::out);if(!outFile4)cerr<<"文件打开失败!"<<endl;else{for(i=0;i<a;i++)outFile4<<s[i]<<endl;outFile4.close();}ifstream inFile3("codefile.dat",ios::in|ios::binary);cerr<<"读取文件失败!"<<endl;else{for(i=0;i<2*n-1;i++){inFile3>>l2[i].letter;inFile3>>l2[i].num;}ifstream inFile4("yima.dat",ios::in);if(!inFile4)cerr<<"读取文件失败!"<<endl;else{for(int j=0;j<a;j++)inFile4>>s[j];}for(int j=0;j<a;j++){for(i=0;i<n;i++){if(l2[i].num==s[j])cout<<l2[i].letter;}}inFile3.close();}return 0;}。

哈夫曼编\译码的设计与实现一、简介1.设计目的:通过对简单哈夫曼编/译码系统的设计与实现来熟练掌握树型结构在实际问题中的应用。
2.问题的描述:利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码。
系统应该具有如下的几个功能:接收原始数据、编码、译码、打印编码规则。
二、数据结构的设计:1.哈夫曼结点结构体:typedef struct HtNode{int weight;int parent, lchild, rchild;}HtNode;2.哈夫曼树结构体:typedef struct HtTree{struct HtNode ht[MAXNODE+1];int root;}HtTree, *PHtTree;三、功能(函数)设计:总体上划分为四个模块,具体功能描述如下:1.初始化功能模块:接收输入信息,并正确输出2.建立哈夫曼树的功能模块:按照构造哈夫曼树的算法构造哈夫曼树,将HuffNode数组中的各个位置的各个域都添上相关的值3.哈夫曼编码的功能模块:根据输入的相关字符信息进行哈夫曼编码,然后将结果存入,同时将字符与0、1代码串的一一对应关系打印到屏幕上。
4.译码的功能模块:接收需要译码的0、1代码串,按照哈夫曼编码规则将其翻译成字符集中的字符所组成的字符串形式,将翻译的结果在屏幕上输出四、界面设计:该界面操做简单,内容详细,便于程序使用者根据提示轻松上手。
简洁明朗是该界面最大的特点。
哈夫曼编/译码请逐个输入结点和结点的权值>>>按Enter键开始根据此提示界面进入程序使用阶段。
请输入结点个数:根据用户输入结点个数,动态输入并存储字符及权值然后输出字符与0、1代码串的对应关系。
进入以下界面,进行后续操作1----------------------------编码2----------------------------译码3----------------------------重新输入权值;0----------------------------退出用户键入“0”,即可出编码译码操作五、程序设计:1.函数功能说明及其程序流程图的描述:1>:main函数:控制整个程序的整个流程。

关于哈夫曼编码的程序设计报告第一部分:引言1. 关于哈夫曼编码的程序设计报告在现代社会中,信息的传输和存储已经成为了我们生活中不可或缺的一部分。
在数字化时代,我们经常需要对数据进行编码和解码,以便有效地传输和存储信息。
而哈夫曼编码作为一种有效的数据压缩方式,被广泛应用于通信、计算机科学和信息处理领域。
在本篇文章中,我将从程序设计的角度进行深入探讨哈夫曼编码的原理、实现和应用。
我将带领你一起了解哈夫曼编码的本质,探讨其在实际应用中的价值,以及我个人对于哈夫曼编码的理解和观点。
第二部分:哈夫曼编码的原理与实现2. 原理概述哈夫曼编码是一种变长编码方式,通过统计文本中字符出现的频率,构建一颗最优二叉树,将出现频率高的字符用较短的编码表示,而出现频率低的字符用较长的编码表示,从而实现了对数据的高效压缩和解压缩。
3. 算法流程哈夫曼编码的算法流程主要包括构建哈夫曼树、生成编码表和进行编码解码三个步骤。
在构建哈夫曼树时,需要通过优先队列或堆来实现最小频率字符的选择和合并,然后生成编码表,最后进行编码和解码操作。
4. 实现技巧在实际的程序设计中,优化哈夫曼编码的实现是非常重要的。
例如采用树结构、位操作以及内存管理等技巧可以有效提高哈夫曼编码的性能和效率。
第三部分:哈夫曼编码的应用5. 通信领域在通信领域中,哈夫曼编码被广泛应用于数据传输和网络通信中。
通过哈夫曼编码可以实现对数据的高效压缩,从而节省带宽和传输成本。
6. 储存领域在储存领域中,哈夫曼编码也能够帮助我们实现对数据的高效压缩和解压缩,节省存储空间并提高储存效率。
特别是在大数据和云计算时代,哈夫曼编码的应用更是显得尤为重要。
第四部分:个人观点与理解7. 我的观点在我看来,哈夫曼编码作为一种高效的数据压缩算法,为我们在通信、计算机科学和信息处理领域带来了极大的便利。
它不仅可以帮助我们节省带宽和存储空间,还能够提高数据传输和存储的效率。
8. 我的理解通过对哈夫曼编码的深入学习和探讨,我不仅对其原理和实现有了更深入的理解,也对其在实际应用中的潜力和价值有了更深刻的认识。

高效数据压缩算法与硬件实现数据压缩算法是一种将数据压缩为更小文件大小的技术,以便在存储、传输和处理数据时节省空间和提高效率。
在当今大数据时代,高效的数据压缩算法和硬件实现变得尤为重要。
本文将介绍几种高效的数据压缩算法,并探讨它们在硬件实现中的应用。
一、哈夫曼编码算法哈夫曼编码是一种基于变长编码的数据压缩算法。
该算法通过根据出现频率来构建编码表,使得出现频率高的字符使用较短的编码,而出现频率低的字符使用较长的编码。
这样可以在保证压缩率的同时,提高数据的传输效率。
对于硬件实现来说,哈夫曼编码算法的特点是可以通过硬件电路来并行地进行编码和解码操作,从而提高压缩和解压缩的速度。
硬件实现可以采用专用的FPGA(现场可编程门阵列)芯片,通过并行计算来加速数据压缩和解压缩的过程。
此外,利用硬件实现还可以进一步减少功耗和空间占用。
二、LZ77算法LZ77是一种基于词典压缩的数据压缩算法。
该算法通过利用历史数据中的重复片段,提取出一个窗口范围内的最长匹配,并用指针和长度来表示该匹配,从而实现对数据的高效压缩。
在硬件实现中,LZ77算法可以借助硬件加速器来提高压缩和解压缩的速度。
硬件加速器可以采用专用芯片或者FPGA来实现,通过并行计算和高性能的硬件指令来加速数据处理过程。
此外,使用硬件实现可以减少主处理器的负载,并提高整体系统的性能。
三、LZ78算法LZ78是一种基于字典压缩的数据压缩算法。
该算法通过建立字典,即已经出现过的短语及其对应的编号,来实现对数据的压缩。
当新的短语出现时,只需要记录其在字典中的编号,从而实现对数据的高效编码。
在硬件实现中,LZ78算法可以通过硬件加速器来快速地处理数据。
硬件加速器可以通过并行计算和高带宽的存储器来加快压缩和解压缩的速度。
此外,硬件实现可以实现对多个通道的并行处理,进一步提高压缩和解压缩的效率。
四、算术编码算法算术编码是一种用于无损数据压缩的编码技术。
该算法通过根据数据频率动态调整编码区间,从而实现对数据的高效压缩。

长春建筑学院《数据结构》课程设计(论文)基于哈夫曼树的哈夫曼编/译码器设计与实现With the implementation of decoder design based on Huffman tree Huffman encoding年级:学号:姓名:专业:指导老师:二零一三年十二月摘要随着计算机应用技术的快速发展和日益普及,网络也遍及到我们生活的每个角落,为我们的学习和工作带来极大的方便。
很多人都使用过传统的文字输入聊天方式,与之不同的另外一种聊天方式就是语音聊天。
主要对那些不会使用键盘的老年用户和追求时尚的年轻人,语音聊天是一种非常好的聊天方式,它能增加聊天双方的亲切感和真实感,语音聊天就涉及到语音的传输。
本系统主要讨论了Windows系统下网络语音的传输,主要利用Windows系统下的API函数和SOCKET函数以及VC开发平台的强大功能来实现。
本系统可以实现网络间文字、语音信息的传输。
信息社会的高科技,商品经济化的高效益,使计算机的应用已普及到经济和社会生活的各个领域。
计算机虽然与人类的关系愈来愈密切,还有人由于计算机操作不方便继续用手工劳动。
为了适应现代社会人们高度强烈的时间观念,学生成绩管理系统软件为教学办公室带来了极大的方便。
该软件是以C语言为实现语言,其功能在系统内部有源代码直接完成。
通过操作目录,管理者和老师可以了解本软件的基本工作原理。
管理者和老师只需输入一些简单的汉字、数字,即可达到自己管理学生成绩的目标。
关键字:哈夫曼树编码解码数据压缩技术AbstractWith the rapid development of computer technology and popularization, network throughout each corner of ourlife, brings great convenience for our study and work.Many people use the traditional text input chat mode,unlike another chat mode is the voice chat. Mainly to the young people who do not use the keyboard to elderly users and the pursuit of fashion, voice chat is a very goodchat mode, it can increase the intimacy and realistic chatbetween the two sides, voice chat is involved in the transmission of voice. This system is mainly discussed under the Windows system transmission of voice, the main use of Windows system under the API function and SOCKET function as well as the powerful features of the VC platform to achieve. This system can realize thenetwork transmission of text, voice rmation society technology, high benefit of commodity economy, causes the computer the application to the economical and social life each domain.Although the computer and human relations more closely, it was inconvenient for computer operators continue to use manual labor. In order to adapt to modern society was highly strong concept of time, has brought great convenience to student achievement management system software for teachingoffice. The software is based on C language for the realization of language, its function within the system active code directly completed. Through the operation of the directory, administrators and teachers can understand the basic working principle of the software. Managers and teachers only need to input some simple Chinese characters, numbers, and can achieve their goal ofthe management of student achievement.Keywords: Huffman tree coding and decoding data compression目录摘要 (I)ABSTRACT .................................................................................................................... I I 第1章绪论.......................................................................................................... - 1 -1.1需求分析 (1)1.2实验目的 (2)1.3实验内容 (2)第2章系统总体设计 ........................................................................................... - 3 -2.1基本要求 (3)2.2算法设计思想 (3)2.3设计要求 (3)第三章系统详细设计............................................................................................ - 4 -哈夫曼编码/译码器源代码.. (4)第四章总体设计................................................................................................. - 14 -4.1设计概述 (14)4.2系统结构图 (15)第五章系统测试................................................................................................. - 15 -5.1实验结果 (16)实验总结................................................................................................................ - 20 -收获与心得............................................................................................................ - 21 -参考文献................................................................................................................ - 22 -第1章绪论引言:在当今信息爆炸时代,如何采用有效的数据压缩技术来节省数据文件的存储空间和计算机网络的传送时间已越来越引起人们的重视。

哈夫曼编码系统的设计与实现
哈夫曼编码是一种用于数据压缩的编码方式,通过将出现频率高的字符用较短的编码表示,从而实现对数据的压缩。
哈夫曼编码系统的设计与实现包括以下几个步骤:
1. 字符频率统计:根据待压缩的数据,统计每个字符出现的频率。
可以使用哈希表或数组来记录每个字符的频率。
2. 构建哈夫曼树:根据字符的频率构建哈夫曼树。
首先将每个字符及其频率作为叶子节点,并按照频率的大小构建一个最小堆。
然后,每次从最小堆中取出两个频率最小的节点,将它们作为子节点构建一个新的节点,频率为子节点频率之和。
将新的节点放回最小堆中,重复上述步骤,直到最小堆中只剩下一个节点,即为哈夫曼树的根节点。
3. 构建编码表:通过遍历哈夫曼树,可以得到每个字符对应的哈夫曼编码。
一种常用的方式是,从根节点开始,每次向左走为0,向右走为1,直到叶子节点,将走过的路径记录下来,即为该字符的哈夫曼编码。
可以使用哈希表来存储每个字符及其对应的哈夫曼编码。
4. 数据压缩:根据构建好的哈夫曼编码表,将待压缩的数据中的每个字符替换为对应的哈夫曼编码,并将编码后的数据保存起来。
由于哈夫曼编码的特性,编码后的数据长度会变短,从而实现对数据的压缩。
5. 数据解压缩:使用相同的哈夫曼树和哈夫曼编码表,将压缩后的数据中的每个哈夫曼编码替换为对应的字符,从而实现对数据的解压缩。
要注意的是,设计和实现哈夫曼编码系统需要考虑到字符频率统计的效率、哈夫曼树的构建算法选择、编码表的存储结构选择等问题。
此外,还需要注意对压缩后的数据进行合理的保存和传输,以便于解压缩时能够正确恢复原始数据。


吉林建筑大学电气与计算机学院信息理论与编码课程设计报告设计题目:哈夫曼编码的分析与实现专业班级:电子信息工程131学生姓名:学号:指导教师:设计时间:2016.11.21-2016.12.2第1章 概述1.1设计的作用、目的通过完成具体编码算法的程序设计和调试工作,提高编程能力,深刻理解信源编码、信道编译码的基本思想和目的,掌握编码的基本原理与编码过程,增强逻辑思维能力,培养和提高自学能力以及综合运用所学理论知识去分析解决实际问题的能力,逐步熟悉开展科学实践的程序和方法。
主要目的是加深对理论知识的理解,掌握查阅有关资料的技能,提高实践技能,培养独立分析问题、解决问题及实际应用的能力。
通过课程设计各环节的实践,应达到如下要求:1.理解无失真信源编码的理论基础,掌握无失真信源编码的基本方法; 2.根据哈夫曼编码算法,考虑一个有多种可能符号(各种符号发生的概率不同)的信源,得到哈夫曼编码和码树; 3.掌握哈夫曼编码的优缺点;4.通过完成具体编码算法的程序设计和调试工作,提高编程能力,深刻理解信源编码、信道编译码的基本思想和目的,掌握编码的基本原理与编码过程,增强逻辑思维能力,培养和提高自学能力以及综合运用所学理论知识去分析解决实际问题的能力,逐步熟悉开展科学实践的程序和方法。
1.2设计任务及要求1. 理解无失真信源编码的理论基础,掌握无失真信源编码的基本方法;2. 掌握哈夫曼编码/费诺编码方法的基本步骤及优缺点;3. 深刻理解信道编码的基本思想与目的,理解线性分组码的基本原理与编码过程;4. 能够使用MATLAB 或其他语言进行编程,编写的函数要有通用性。
1.3设计内容一个有8个符号的信源X ,各个符号出现的概率为:⎭⎬⎫⎩⎨⎧=⎥⎦⎤⎢⎣⎡04.005.006.007.01.012.017.039.0)(87654321x x x x x x x x X P X 进行哈夫曼编码,并计算平均码长、编码效率、冗余度。

哈夫曼编/译码系统的设计与实现一、实验项目简介:1.问题描述:利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。
但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(解码)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发站设计一个哈夫曼编/译码系统。
2.一个完整的系统应具有以下功能:1)初始化(Initialzation)。
从数据文件 DataFile.data 中读入字符及每个字符的权值,建立哈夫曼树HuffTree;2)编码(EnCoding)。
用已建好的哈夫曼树,对文件ToBeTran.data 中的文本进行编码形成报文,将报文写在文件 Code.txt 中;3)译码(Decoding)。
利用已建好的哈夫曼树,对文件CodeFile.data 中的代码进行解码形成原文,结果存入文件 Textfile.txt 中;4)输出(Output)。
输出 DataFile.data 中出现的字符以及各字符出现的频度(或概率);输出 ToBeTran.data 及其报文 Code.txt;输出 CodeFile.data 及其原文 Textfile.txt;要求:所设计的系统应能在程序执行的过程中,根据实际情况(不同的输入)建立DataFile.data、ToBeTran.data 和 CodeFile.data 三个文件,以保证系统的通用性。
二、实验目的:理解哈夫曼树的特征及其应用;在对哈夫曼树进行理解的基础上,构造哈夫曼树,并用构造的哈夫曼树进行编码和译码;通过该实验,使学生对二叉树的构建、遍历等以及哈夫曼编码的应用有更深层次的理解。
实验步骤:实验分 2 次完成第 1 次:完成程序的主框架设计,进行调试,验证其正确性;(2学时)第 2 次:详细设计,进行调试,对运行结果进行分析,完成实验报告。
实验五哈夫曼编码与译码的设计与实现一、问题描述利用哈夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本.但是,这要求在发送端通过一个编码系统对待传数据预先编码,在接收端将传来的数据进行译码(复原)。
对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。
试为这样的信息收发编写一个哈夫曼码的编/译码系统。
基本要求:(1)接收原始数据:从终端读入字符集大小n,以及n个字符和n个权值,建立哈夫曼树,并将它存于文件nodedata。
dat中。
(2)编码:利用已建好的哈夫曼树(如不在内存,则从文件nodedata。
dat中读入),对文件中的正文进行编码,然后将结果存入文件code.dat中.(3)译码:利用已建好的哈夫曼树将文件code.dat中的代码进行译码,结果存入文件textfile。
txt中。
(4)打印编码规则:即字符与编码的一一对应关系.(5)打印哈夫曼树:将已在内存中的哈夫曼树以直观的方式显示在终端上。
二、数据结构设计1、构造哈夫曼树时,使用静态链表作为哈夫曼树的存储。
在构造哈夫曼树时,设计一个结构体数组HuffNode保存哈夫曼树中各结点的信息,根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n—1个结点,所以数组HuffNode的大小设置为2n-1,描述结点的数据类型为:typedef struct{int weight;int parent;int lchild;int rchild;char inf;}HNodeType;2。
求哈夫曼编码时使用一维结构数组HuffCode作为哈夫曼编码信息的存储。
求哈夫曼编码实际上就是在已建立的哈夫曼树中,从叶子结点开始,沿结点的双亲链域回退到根结点,每回退一步,就走过了哈夫曼的一个分支,从而得到一位哈夫曼编码值。
由于一个字符的哈夫曼编码就是从根结点到相应叶子结点所经过的路径上各分支所组成的0、1序列,因此先得到的分支代码为所求编码的低位码,后得到的分支代码为所求的高位码。
图1 模块连接图1.4 编码模块如果码表模块无法对输入数据进行编码,则必须通过编码模块完成静态编码。
编码过程是由构建哈夫曼树和分配码长两个过程组成的[4],此模块中我们使用到3个存储器,一个是上文提到的seq,记录排序好的十个数据以及各自权值;另一个存储器是node,是由哈夫曼树中的非叶节点构成的;而最后一个存储器为result,保存整棵哈夫曼树。
10个叶结点组成的哈夫曼树应有19个结点,但是d)重复a。
3)第11个周期开始编码a)初始码长result[17]=result[16]=1b)根据标记位点:i.如果有子结点已经是树尾,则编码结束ii.如果没有子结点图2 哈夫曼编码工作波形图[1]Latha Pillai, “Huffman Coding” EXILINX, Virtex Series, XAPP616 (v1.0) Apr 22, 2003. [3]Matai, Janarbek, J. Y. Kim, and R. Kastner. "Energy efficient canonical huffman encoding." IEEE, International Conference on Application-Specific Systems, Architectures and Processors[4]李伟生,李域,王涛.一种不用建造Huffman树的高效Huffman编码算法[J].中国图像图形学报[5]林建英,伍勇,李建华,等.一种易于硬件实现的快速自适应哈夫曼编码算法[J].大连理工大学学报[6]张全伙,于洪斌,林榆.优化哈夫曼编码数据压缩技术及程序实现[J].华侨大学学报(自然科学版)。
图1 电路接口时序图将一段数字序列(256个0~9的数据元素)输入电路进行哈夫曼编码,data_in的数据宽度为4,输入需要256单级结构RTLdata为频数和对应元素的输入端图2 电路的总体结构功能框图图3 排序模块RTL电路设计结构图4 数据编码模块结构框图data分别对应频数和对应元素的输出端。
10个元素对应18个子节点,要完成对二叉树18个子节点的排序,则总的排序电路由18个单级排序结构组成,根据哈夫曼编码的性质,本设计将每次排序得到的最小两个元素的频数相加作为新元素的频数。
例如频数最小的两个元素为9和5,作为左右子节点,父节点对应的频数为9和5的频数之和,其对应的元素为10,生成的父节点依次为11、12....17,新生成的父结点与剩下的元素进行新一轮的排序,而已经比较出两个最小频数的元素,不再参与排序。
排序结构的各级输入通过计数器来控制。
排序完以后,取每级寄存器中的元素bit0~bit17,即18个节点按照频数由小到大排序的元素序列,输出给编码模块。
1.2 数据编码模块该部分设计主要包括编码FSM、状态控制模块、计数模块、数据编码模块和流水线译码输出模块,其中zero_flag为数据频数为0的标志信号。
数据编码模块结构框图如图4所示。
根据排序模块的规律,bit0和bit1的父节点是元素10,bit2和bit3的父节点是元素11,bit4和bit5的父节点是元素12,bit6和bit7的父节点是元素13,bit8和bit9的父节点是元素14,bit10和bit11的父节点是元素15,bit12和bit13的父节点是元素16,bit14和bit15的父节点是元素17,bit16和bit17的父节点是根节点。
根据哈夫曼树的特点,父节点的编码为xxxxxxxxx,则左节点的哈夫曼编码为xxxxxxxx0,右节点的哈夫曼编码为xxxxxxxx1。
编码FSM依次控制输出父节点17至父节点10,首先当输出父节点17时,它为根节点的左节点或右节点,通过查找到排序结果中的对应位置bit16或者bit17,假定bit16的编码为0,bit17的编码为1,则父节点17的编码可以确定,那么它左节点bit14,右节点bit15的编码图5 编码流水线单级结构图图6 哈夫曼输出模块结构图图7 245M时钟下post_inplementation timing simulation波形图8 系统时钟也就确定了。
基于FPGA的Huffman编码并行实现及高速存储系统设计目录第一章绪论 (1)1.1 研究的背景及意义 (1)1.2 研究现状 (2)1.3 论文工作及结构安排 (5)1.4 本章小结 (6)第二章基于FPGA的Huffman编码并行实现与高速存储系统设计方案 (7)2.1 Huffman编码 (7)2.2 系统总体设计 (9)2.3 本章小结 (11)第三章基于FPGA的Huffman编码并行实现及高速存储系统实现(12)3.1 Huffman编码模块设计 (12)3.1.1统计模块 (12)3.1.2排序模块 (14)3.1.3二叉树及编码模块 (16)3.2高速存储系统设计模块设计 (17)3.2.1读/写异步FIFO模块设计 (18)3.2.2DDR3 SDRAM控制器设计 (19)3.2.3基于FPGA的DDR3 SDRAM控制器IP核的设计 (22)3.2.4高速读写控制器及其时序 (24)3.3软件实现统计、排序模块 (27)3.4系统的软硬件平台与开发流程 (30)3.4.1FPGA系统开发流程 (30)3.4.2软硬件开发平台 (31)3.4.3硬件描述语言 (31)3.5系统时钟和全局复位 (32)3.5.1全局时钟和局部时钟设计 (32)3.5.2全局复位设计 (33)3.6本章总结 (35)V第四章基于FPGA的Huffman编码高速存储系统硬件平台搭建与测试分析 (37)4.1硬件平台检测 (37)4.2Huffman编码结果与分析 (38)4.3关键路径时间计算 (40)4.4存储效率测试 (41)4.5本章总结 (43)结论 (44)参考文献 (46)攻读硕士学位期间的研究成果 (49)致谢 (50)VI第一章绪论第一章绪论1.1 研究的背景及意义根据调查发现,随着通信技术和互联网技术的蓬勃发展,最近的这五年全世界新生产出的信息量同过去五年相比将近翻了一番。
这些新产生的信息,只有10%记录在纸张、胶片和光存储介质上,剩下的绝大多数都记录在硬盘等磁存储介质上。
Xilinx哈夫曼编码系统设计
孟欢;包海燕;潘飞
【期刊名称】《电子产品世界》
【年(卷),期】2017(24)11
【摘要】在图像处理、文件传真、视频压缩编码中,哈夫曼编码是最常用的一种编码方式.本文设计并实现了对一段数字序列进行哈夫曼编码并将编码结果串行输出的电路模块,电路由输入数据的排序、数据的哈夫曼编码、数据序列编码的结果输出三个核心模块组成,在Xilinx平台上通过硬件描述语言实现该电路.仿真结果表明,该电路编码正确,并具有较高的工作频率和编码效率.
【总页数】4页(P51-54)
【作者】孟欢;包海燕;潘飞
【作者单位】电子科技大学微电子与固体电子学院四川成都 610054;电子科技大学微电子与固体电子学院四川成都 610054;电子科技大学微电子与固体电子学院四川成都 610054
【正文语种】中文
【相关文献】
1.基于XILINX FPGA的图像边缘检测系统设计 [J], 郁素梅;戴丽莉;孙成祥
2.基于XILINX ISE平台的宽带接收机系统设计 [J], 贾一凡
3.ADI运用Xilinx的FPGA让无线基础设备系统设计更简单 [J],
4.基于Xilinx Zynq的物距测量系统设计与实现 [J], 杨晓安;罗杰;包文博
5.Xilinx FPGA处理器解决方案为嵌入式系统设计人员提供强大的性能优势独立测
试结果再次肯定了Xilinx业界最全面的基于FPGA的32位嵌入式处理解决方案的领先地位 [J],
因版权原因,仅展示原文概要,查看原文内容请购买。
1 哈夫曼编码算法的优化设计与系统实现
面向FPGA硬件实现的改进哈夫曼编码系统包括输入、排序、编码、输出和存储等模块,下面通过功能仿真和时序验证来评价其预期编码功能(编码效率)和所有性能指标(系统稳定性和时序问题)。
1.1 系统框架
核心模块为排序模块与编码模块,排序模块产生每个编码周期中频数最小与次小节点的地址(标号),将结果送入编码模块,并将编码后的节点进行合并;编码模块根据排序模块送来的结果对相应符号进行编码。
此外,系统还包括输入统计、输出及存储等其他功能模块。
哈夫曼编码系统实现过程包括输入、编码、0-9编码输出、测试数据编码输出和停机操作。
初始系统处于输入状态,在start信号作用下输入一个脉冲,开始读取256个数据,随后进入编码状态。
在编码过程中,排序模块与编码模块同步工作,其工作流程通过Top模块中产生的addrcount与encode_phase信号控制。
编码过程共包含9个编码周期(每个编码周期由7个时钟周期组成),编码周期结束后,系统进入0-9编码输出过程与数据编码输出过程。
一旦数据全部输出完毕,系统进入停机模式。
1.2 排序模块
哈夫曼编码算法编码速度取决于排序算法。
无论是快速排序还是插入排序,传统排序算法均针对串行工作的器件而设计;若采用并行工作特点的FPGA进行硬件实现,将面临时钟周期数多、逻辑复杂且难以优化等问题。
鉴于此,本文针对FPGA 并行处理结构设计一个并行排序算法。
若不考虑时序问题,仅采用组合逻辑实现,
这种算法在一个时钟周期内即可给出排序结果,且组合逻辑单元的数量尚可。
此外,根据需要拆分逻辑层数,插入多级流水线,使时序满足要求,时序优化处理相当灵活。
图1 哈夫曼编码系统流程图
并行排序原理如表1所示,若干个输入数据相互比较,将每个数据与其它数据的比较结果相加,得到每个数据在所有数据中的排名。
排名为0和1的两个数据分别为最小值和次小值,表1中对应为D和B。
输入:10个8bit数,为输入的10个符号的频数。
1个5bit数,为当前编码周期将要产生的新节点的地址(从10000开始,每个编码周期加1)。
输出:2个5bit数,每个编码周期中的最小值和次小值节点所对应的地址。
每个节点由地址与频数组成,地址是10个5bit的rank 寄存器。
to the maximum extent, and the parallel operation mode of sorting module and coding module is more conducive to the implementation of FPGA system. The coding technology can be extended to artificial intelligence chip design.
Keywords: Hoffman coding; FPGA hardware implementation; Data compression
应原来10个数据中的最小值和次小值)。
步骤5:将最小值与次小值对应的地址装入输出寄存器。
步骤6:将最小值对应节点置为无效(频数置为FF),将次小值对应节点的频数置为最小值与次小值频数之和,地址置为当前编码周期的新节点地址。
改进后哈夫曼编码系统的基本原理显示如下:
第1个周期内,8为频数最小节点(左节点),4为频数次小节点(右节点),给8和4的最后一位分别编码为0和1。
此时,8和4的父节点编码为10。
第2个周期内,2为左节点,10为右节点。
给2的最后一位编码为0,给10的所有子叶节点的最后一位(已被编码的位不算)编码为1。
此时,2、8、4的父节点编码为11。
以此类推,最后一个编码周期,16为左节点,17为右节点。
此时给7、2、8、4、3最后一位编码为0,给9、0、5、6、1最后一位编码为1。
9个编码周期即可完成编码。
显然,改进后的编码方式简单高效。
采用FPGA平台对编码算法进行硬件实现,简化了逻辑结构,减少了不必要的资源占用,避免了复杂逻辑导致的时序问题。
2 哈夫曼编码的系统仿真与性能验证
2.1 编码算法的实现与仿真
燕尾箭头指示对应符号在当前编码周期完成后的编码结果;加粗方框代表Parent_Addr与当前编码周期产生2.2 编码系统的稳定性测试
为了确保在各种输入数据下编码算法均能正确输出编码结果,需要哈夫曼编码系统进行稳定性测试,测试程序采用python编写,随机生成测试数据,运行仿真,将编码输出结果与软件编码结果进行比对,对解码后输出结果与输入数据进行比对,将所有结果记录到文件,使用脚本令计算机反复自动执行上述过程。
测试时,若直接生成256个0-9随机数据,则0-9频数接近均匀分布,不利于验证系统测试在输入数据各种频数分布下的稳定性。
因此,需要确保数据的随机性。
本方案先随机地产生数据分布的频数,再根据频数生成测试数据,保证稳定性测试全面覆盖所有情况下的输入数据。
测试5000组随机数据的编码正确率为100%,说明编码系统功能正常、性能稳定。
3 结论
为了提高数据压缩效率并降低系统成本,本文突破了传统哈夫曼编码规则和算法流程,提出了面向FPGA平台的哈夫曼编码系统优化设计框架和硬件实现方案,利用动态可重构计算技术有效提高编码效率和存储资源,通过大量仿真测试与性能验证对该编码系统进行全面评估。
在编码过程中,排序模块采取并行排序方式,充分兼顾FPGA并行工作特点,减少时钟周期数;编码模块避免传统二叉树建立过程,简化逻辑结构,提高了硬件资源利用率,减少了面积开销,完全避免由复杂逻辑导致的一系列时序问题。
该哈夫曼编码系统实现
(下转第79页)
以对现有的SDH网络进行升级,制定出DWDM波分复用技术以及RRR弹性分组环和MSTP多项业务数据传输平台。
对于已经完成建设的SDH地区,可以对现有的SDH网络进行升级使其可以适应IP业务的通信网络,对于没有建立SDH网络的地区应该集合当地实际发展,合理选择合适的技术措施。
另一方面,还可以对MSTP技术进行广泛的推广应用,这个技术在传统的SDH的基础上增添了数据处理的功能,可以很好的使用数据的变化,结合多个网络设备,对统一管控是十分有帮互助的。
MSTP既可以兼容TDM业务,又可以满足IP数据业务的需求,可以使得电力信息通信网络具有一定可靠特征。
2.4 拓宽网络技术的应用范围
在电力信息通信中,网络技术可以广泛应用于各个领域。
例如在调度电话与行政电话、发挥继电保护作用的信号灯业务和管理系统的指令与信息等。
在网络信息技术发展的推动下,电力信息通信系统得到进一步的完善,使得电力信息通信业务逐渐往多元化发展。
但传统的网络结构难以满足业务发展的需求,这会导致增加资源占用率。
所以电力企业需要进一步挖掘网络技术的其阿里,进一步拓展网络技术的应用范围,不断的融合和创新技术,慢慢的实现那不同业务之间的对接。
3 结语
当前我国电力行业在不断的发展,人们在生活和工作中对电力行业各项业务的需求也在不断的增加,其在社会中的重要性变得越来越重要,将网络技术应用到电力信息通信,对整个电力行业的发展都有着重要的作用。
其中的通电系统运行状态会直接影响到社会的日常稳定运行。
电力企业是比较特殊的服务行业,是确保其他行业正常运行的关键因素,所以电力通信系统需要不断的完善和创新,才能够顺应时代和社会的发展,满足各行各业的需求。
参考文献
[1]谢清宇,庞霞.浅议网络技术在电力信息通信中的应用[J].
科技与企业,2012(7):91-91.
[2]梁天乐.现代形势下网络技术在电力信息通信系统中的
应用[J].中国新通信,2014(23):79-79.
[3]刘飞鹏,张旭,王佳佳.浅论新形势下网络技术在电力信
息通信中的应用[J].通讯世界, 2016(20):136-137. [4]郭欣华.探究新形势下网络技术在电力信息通信中的应用
[J].信息与电脑(理论版),2018,No.406(12):174-175.
[5]董卫.简析新时期新网络技术在电力信息通信中的应用
[J].信息通信,2015(6):159-159.
了预期编码功能和所有性能指标,完全满足时钟周期数少、频率高、资源占用少等设计需求。
参考文献
[1]张红军,徐超.基于改进哈夫曼编码的数据压缩方法研究
[J].唐山师范学院学报,2014年第36卷第5期. [2]刘方明,潘晓中,杨晓元.数字图像DCT变换的FPGA实
现[J].计算机工程与应用,2012,48(6):65-68.
[3]张颖超.基于FPGA的 Huffman 编码并行实现及高速存
储系统设计[D].长安大学,2015年.
(上接第85页)。