6_第六讲(关联规则分析)
- 格式:ppt
- 大小:1.01 MB
- 文档页数:54







关联规则分析近年来,数据挖掘技术越来越受到业界的关注,其中具有代表性的一项技术就是关联规则分析。
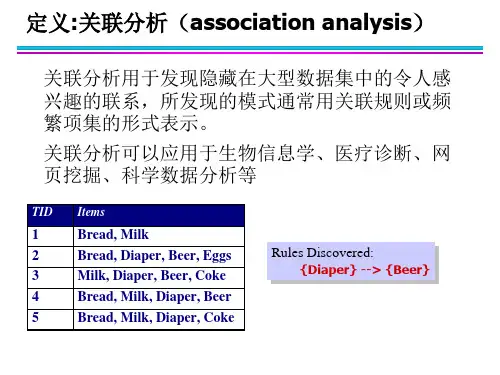
关联规则分析是一种可以挖掘数据中存在的关联关系的技术,通过挖掘数据中的规律,从而为企业的决策制定提供支持。
本文将对关联规则分析技术进行深入的阐述,并探讨其在实际应用中的意义和价值。
一、关联规则分析的原理关联规则分析的核心就是寻找数据集中项之间存在的频繁集合和规则。
所谓频繁集合,就是指出现频率达到一定阈值的项组合。
在寻找频繁项时,通常需要依靠支持度和置信度来作为衡量指标。
支持度是指该项集在整个数据集中出现的频率,而置信度则是指该项集中的某些项出现时,另一项也很可能出现的概率。
举个例子,假设我们有一组销售记录,其中有许多顾客购买了商品A,并且部分顾客还购买了商品B。
为了进一步挖掘数据集中的关联关系,我们可以通过关联规则分析来寻找商品A和商品B之间的关联关系。
我们可以设置一个支持度的阈值(比如说10%),并且只分析那些出现频率超过这一阈值的数据集合。
这样就可以找到所有同时购买A和B的顾客,也就是频繁项集。
在这个过程中,我们可以计算A和B同时出现的置信度,即出现A 就很可能会出现B的概率,这可以为我们后续的销售战略制定做出重要贡献。
二、关联规则分析的应用领域关联规则分析在实际应用中有着广泛的应用领域,其中最为显著的一个应该就是电子商务领域。
在电子商务平台中,很多商家会通过关联规则分析技术来寻找不同商品之间的关联关系,从而制定出更为有效的销售策略。
例如通过寻找数据中的频繁项集,我们可以找到顾客们在购买某件商品时,最可能还需要购买哪些其他商品,进而为顾客提供更加便捷的购物体验。
除此之外,在金融领域、医疗领域以及网络推荐系统等领域中,也都可以使用关联规则分析技术来寻找业务中的关联关系。
例如在医疗领域,我们可以通过关联规则分析找出不同疾病之间的关联关系,这对于医生的诊疗决策具有重要帮助。
三、关联规则分析技术的局限性虽然关联规则分析技术在应用中具有很大的价值,但是它也存在着一定的局限性。


数据挖掘关联规则简介数据挖掘是一种通过对大量数据进行分析和挖掘,发现其中隐藏的有价值信息的过程。
在数据挖掘的过程中,关联规则是其中一种重要的技术。
关联规则分析可以帮助我们发现数据集中不同项之间的相关性,从而帮助我们做出更好的业务决策。
关联规则挖掘的核心目标是发现数据集中的频繁项集和关联规则。
频繁项集指的是数据集中经常出现在一起的项的集合,而关联规则所描述的是这些项之间的关系,例如”如果买了A商品,那么也可能买B商品”。
关联规则的基本概念关联规则由两部分组成:前项和后项。
前项和后项分别是一个或多个项的集合。
•支持度(support):支持度是指某个项集在数据集中出现的频率。
支持度越高表示该项集出现的频率越大。
•置信度(confidence):置信度是指规则的前项和后项同时出现的概率,即在前项出现的情况下,后项也出现的概率。
根据支持度和置信度,可以使用以下公式计算关联规则的重要度:•支持度:support(A->B) = (出现A和B的次数) / (总事务数)•置信度:confidence(A->B) = (出现A和B的次数) / (出现A的次数)如何挖掘关联规则挖掘关联规则的过程通常分为以下几个步骤:1. 数据预处理在进行关联规则挖掘之前,需要对数据进行预处理。
预处理的步骤包括数据清洗(去除重复项、缺失值等),数据转换(将数据转换为适合关联规则挖掘的形式)等。
2. 挖掘频繁项集频繁项集指的是在数据集中出现频率较高的项集。
挖掘频繁项集的常用算法有Apriori算法和FP-growth算法。
Apriori算法是一种生成候选项集的算法。
它从频繁的1项集开始,通过逐层连接和剪枝的方式生成候选项集,最后得到频繁项集。
Apriori算法的思想是基于Apriori原理:如果一个项集是频繁的,那么它的所有子集也是频繁的。
FP-growth算法是一种利用频繁模式树进行挖掘的算法。
它通过构建一个树状结构(FP树)来存储频繁项集的信息,并利用树的性质来高效挖掘频繁项集。