同济大学_运筹学_层次分析法例题
- 格式:docx
- 大小:27.56 KB
- 文档页数:2
第六章层次分析法决策是人们选择或进行判断的一种思维活动,在人们的实践活动中,常常要对某些系统的重要性作出恰当的评价,以便列出它们的轻重缓急,从而集中解决重要的问题。
有些决策是简单易断的,而有些决策则是复杂困难的,因此常常先把复杂问题分解成因素,然后把这些因素按支配关系分组形成有序的递阶层次结构,并衡量各方面的影响,最后综合人的判断,以决定决策诸因素相对重要性的先后优劣次序,这就是层次分析法的基本思路。
层次分析法的(Analytic Hierarchy Process 简记为AHP)是美国著名的运筹学家T.L.Saaty 教授于70年代初首先提出的一种定性与定量分析相结合的多准则决策方法。
该方法是社会、经济系统决策的有效工具,目前在工程计划、资源分配、方案排序、政策制定、冲突问题、性能评价等方面都有广泛的应用。
6.1 层次分析法的基本原理层次分析法的核心问题是排序,包括递阶层次结构原理、测度原理和排序原理。
下面分别予以介绍。
1.递阶层次结构原理。
一个复杂的结构问题可分解为它的组成部分或因素,即目标、准则、方案等。
每一个因素称为元素。
按照属性的不同把这些元素分组形成互不相交的层次,上一层次的元素对相邻的下一层次的全部或部分元素起支配作用,形成按层次自上而下的逐层支配关系。
具有这种性质的层次称为递阶层次。
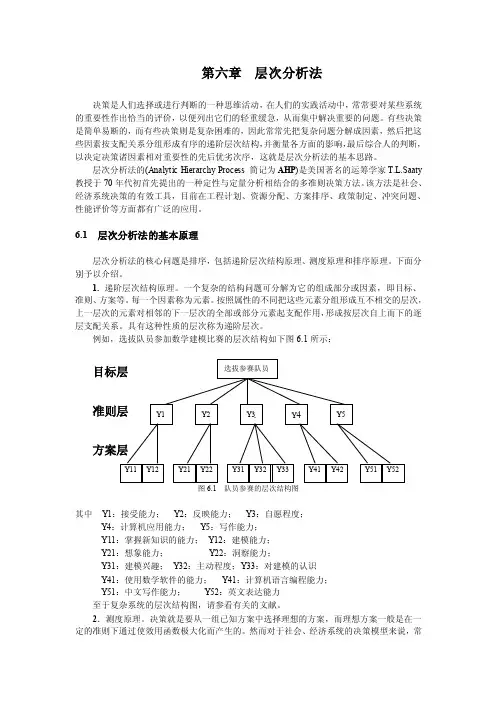
例如,选拔队员参加数学建模比赛的层次结构如下图6.1所示:图6.1 队员参赛的层次结构图其中Y1:接受能力;Y2:反映能力;Y3:自愿程度;Y4:计算机应用能力;Y5:写作能力;Y11:掌握新知识的能力;Y12:建模能力;Y21:想象能力;Y22:洞察能力;Y31:建模兴趣;Y32:主动程度;Y33:对建模的认识Y41:使用数学软件的能力;Y41:计算机语言编程能力;Y51:中文写作能力;Y52:英文表达能力至于复杂系统的层次结构图,请参看有关的文献。
2.测度原理。
决策就是要从一组已知方案中选择理想的方案,而理想方案一般是在一定的准则下通过使效用函数极大化而产生的。

专题:层次剖析法一般情形下,物流体系的评价属于多目标.多判据的体系分解评价.假如仅仅依附评价者的定性剖析和逻辑断定,缺少定量剖析根据来评价体系计划的好坏,显然是十分艰苦的.尤其是物流体系的社会经济评价很难作出准确的定量剖析.层次剖析法(Analytical Hierarchy Process )由美国有名运筹学家萨蒂(T .L .Saaty )于1982年提出,它分解了人们主不雅断定,是一种简明.适用的定性剖析与定量剖析相联合的体系剖析与评价的办法.今朝,该办法在国内已得到普遍的推广运用,普遍运用于能源问题剖析.科技成果评选.地区经济成长计划比较,尤其是投入产出剖析.资本分派.计划选择及评选等方面.它既是一种体系剖析的好办法,也是一种新的.简练的.适用的决议计划办法.◆ 层次剖析法的基起源基础理人们在日常生涯中经常要从一堆同样大小的物品中遴选出最重的物品.这时,一般是运用两两比较的办法来达到目标.假设有n 个物品,其真实重量用w 1,w 2,…w n 暗示.要想知道w 1,w 2,…w n 的值,最简略的就是用秤称出它们的重量,但假如没有秤,可以将几个物品两两比较,得到它们的重量比矩阵A .假如用物品重量向量W =[w 1,w 2,…w n ]T右乘矩阵A ,则有:由上式可知,n 是A 的特点值,W 是A 的特点向量.根据矩阵理论,n 是矩阵A 的独一非零解,也是最大的特点值.这就提醒我们,可以运用求物品重量比断定矩阵的特点向量的办法来求得物品真实的重量向量W.从而肯定最重的物品.将上述n 个物品代表n 个指标(要素),物品的重量向量就暗示各指标(要素)的相对重要性向量,即权重向量;可以经由过程两两身分的比较,树立断定矩阵,再求出其特点向量就可肯定哪个身分最重要.依此类推,假如n 个物品代表n 个计划,按照这种办法,就可以肯定哪个计划最有价值.◆ 运用层次剖析法进行体系评价的重要步调如下:(1)将庞杂问题所涉及的身分分成若干层次,树立多级递阶的层次构造模子(目标层.断定层.计划层).(2)标度及描写.统一层次随意率性两身分进行重要性比较时,对它们的重要性之比做出断定,赐与量化.(3)对同属一层次的各要素以上一级的要素为准则进行两两比较,根据评价尺度肯定其相对重要度,据此构建断定矩阵A .(4)盘算断定矩阵的特点向量,以此肯定各层要素的相对重要度(权重).(5)最后经由过程分解重要度(权重)的盘算,按照最大权重原则,肯定最优计划.★例题:某物流企业须要倾销一台设备,在倾销设备时须要从功效.价钱与可保护性三个角度进行评价,斟酌运用层次剖析法对3个不合品牌的设备进行分解剖析评价和排序,从中选出能实现物流计划总目标的最优设备,效.解题步调:1.标度及描写人们定性区分事物的才能习习用5个属性来暗示,即同样重要.稍微重要.较强重要.强烈重要.绝对重要,当须要较高精度时,可以取两个相邻属性之间的值,如许就得到9个数值,即9个标度.为了便于将比较判断定量化,引入1~9比率标度办法,划定用1.3.5.7.9分离暗示根据经验断定,要素i与要素j比拟:同样重要.稍微重要.较强重要.强烈重要.绝对重要,而2.4.6.8暗示上述两断定级之间的调和值.标度界说(比较身分i与j)1 身分i与j同样重要3 身分i与j稍微重要5 身分i与j较强重要7 身分i与j强烈重要9 身分i与j绝对重要2.4.6.8 两个相邻断定身分的中央值倒数身分i与j比较得断定矩阵a ij,则身分j与i比拟的断定为a ji=1/a ij 注:aij暗示要素i与要素j相对重要度之比,且有下述关系:aij=1/aji ;aii=1; i,j=1,2,…,n显然,比值越大,则要素i的重要度就越高.2.构建断定矩阵A断定矩阵是层次剖析法的根本信息,也是进行权重盘算的重要根据.目标层断定层计划层图设备倾销层次构造图根据构造模子,将图中各身分两两进行断定与比较,构造断定矩阵:即相对于物流体系总目标,断定层各身分相对重要性比较)如表1所示;相对功效,各计划的相对重要性比较)如表2所示; 相对价钱,各计划的相对重要性比较)如表3所示; 相对可保护性,各计划的相对重要性比较)如表4所 示.一般来讲,在AHP 法中盘算断定矩阵的最大特点值与特点向量,必不须要较高的精度,用乞降法或求根法可以盘算特点值的近似值.●乞降法1)将断定矩阵A 按列归一化(即列元素之和为1):b ij = a ij /Σa ij ; 2)将归一化的矩阵按行乞降:c i =Σb ij (i=1,2,3….n );3)将c i 归一化:得到特点向量W =(w 1,w 2,…w n )T,w i =c i /Σc i , W 即为A 的特点向量的近似值;4)求特点向量W 对应的最大特点值: ●求根法1)盘算断定矩阵A每行元素乘积的n次方根i =1,2, …, n)2,=(w1,w2,…wn)T即为A的特点向量的近似值;3)求特点向量W对应的最大特点值:(1).特点向量与一致性磨练①.各行元素的乘积并求其方根,如,,相似地,②③一致性磨练.现实评价中评价者只能对A进行粗略断定,如许有时会犯不一致的错误.如,已断定C1比C2重要,C2比C3较重要,那么,C1应当比C3更重要.假如又断定C1比C3较重要或一致重要,这就犯了逻辑错误.这就须要进行一致性磨练.根据层次法道理,运用A的理论最大特点值λmax与n之差磨练一致性.查同阶平均随机可以接收,不然从新两两进行比较).表5平均随机一致性指标阶数 3 4 5 6 7 8 9 10 11 1213 14 RI(2).相似于第(1)步的盘算进程,.特点向量相似于第(1)步的盘算进程,可以得到矩阵刀:—C的特点根.特点向相似于第(1)步的盘算进程,.特点向量与获得统一层次各要素之间的相对重要度后,就可以自上而下地盘算各级要素对总体的分解重要度.设二级共有m 个要素c 1, c 2,…,c m ,它们对总值的重要度为w 1, w 2,…, w m ;她的下一层次三级有p 1, p 2,…,p n 共n 个要素,令要素p i 对c j 的重要度(权重)为v ij ,则三级要素p i 的分解重要度为:计划C 1 计划C 2的重要度(权重)=0.230×0.258+0.648×0.333+0.122×0.066=0.283计划C 3的重要度(权重)=0.230×0.637+0.648×0. 075+0.122×0.785=0.291根据各计划分解重要度的大小,可对计划进行排序.决议计划. 层次总排序如表6所示.由表5可以看出,3且品牌1显著优于其他两种品牌的设备.功课:某配送中间的设计中要对某类物流设备进行决议计划,现初步选定三种设备配套计划,运用层次剖析法对优先斟酌的计划进行排序.解:对设备计划的断定重要可以从设备的功效.成本.保护性三方面进行评价.当然,若何评价功效.保护性等,还会用更细一级的指标来权衡.这里为剖析的轻便,省略了更具体的指标.如许,可树立对设备计划进行比较的层次剖析构造图,如图:根据以往经验和相干查询拜访成果显示:相干指标两两比较的成果。


学号系统工程与运筹学课程设计设计说明书层次分析法应用系统最优化问题起止日期:2013年11月25 日至2013 年11月29日学生姓名班级成绩指导教师经济与管理学院2013年11月29日成绩评定表目录Ⅰ研究报告 (1)课程设计题目1:改革新形式下的大学生形象评价 (1)1.问题的提出 (1)2.分层递阶结构模型 (2)3.判断矩阵及相关计算结果 (2)4.单排序及总排序计算过程及结果 (6)5.结果分析 (6)5.1结果 (6)5.2分析 (6)课程设计题目2:人员合理分配问题 (7)1.问题的提出 (7)2.问题分析 (7)3.基本假设与符号说明 (7)4.模型的建立及求解结果 (8)5.模型评价 (9)课程设计题目3:生产调运问题 (10)1.问题的提出 (10)2.问题分析 (11)3.基本假设与符号说明 (11)4.模型的建立及求解结果 (12)5.模型评价 (18)II工作报告 (19)III 参考文献 (20)附件一:人员合理分配问题lingo程序及结果 (21)附件二:生产调运问题lingo程序及结果 (22)Ⅰ研究报告课程设计题目1:改革新形式下的大学生形象评价摘要:大学生如何塑造个人形象?首先我们要了解形象这个概念以及它的重要性,得体的塑造和维护形象,会给初次见面的人以良好第一印象。
塑造大学生形象还要关注社会,放眼世界,注重群体性,同时作为大学生形象塑造最重要主体的大学生,在平时学习、生活中就应该有意识地培养、塑造自身形象,为自己在人际交往过程中、特别是未来就业求职道路上增加重要的竞争砝码。
有的人说青春就是最好的包装,天生丽质、潇洒帅气就是大学生的理想形象。
但是,我们觉得所谓的形象,并不能简单地理解为人的外表特征,更应是人的精神和内在素质通过外表的一种自然流露和表现;大学生必须在学习和实践中不断扩展自己的知识面,掌握一定的技能,如果只重外表,不重内涵构造出来的形象,则只能是肤浅和苍白无力的。

一、填空题:(每空格2分,共16分)1、线性规划的解有唯一最优解、无穷多最优解、 无界解 和无可行解四种。
2、在求运费最少的调度运输问题中,如果某一非基变量的检验数为4,则说明 如果在该空格中增加一个运量运费将增加4 。
3、“如果线性规划的原问题存在可行解,则其对偶问题一定存在可行解”,这句话对还是错? 错4、如果某一整数规划: MaxZ=X 1+X 2X 1+9/14X 2≤51/14 -2X 1+X 2≤1/3 X 1,X 2≥0且均为整数所对应的线性规划(松弛问题)的最优解为X 1=3/2,X 2=10/3,MaxZ=6/29,我们现在要对X 1进行分枝,应该分为 X1≤1 和 X1≥2 。
5、在用逆向解法求动态规划时,f k (s k )的含义是: 从第k 个阶段到第n 个阶段的最优解 。
6. 假设某线性规划的可行解的集合为D ,而其所对应的整数规划的可行解集合为B ,那么D和B 的关系为 D 包含 B7. 已知下表是制订生产计划问题的一张LP 最优单纯形表(极大化问题,约束条问:(1)写出B -1=⎪⎪⎪⎭⎫ ⎝⎛---1003/20.3/1312(2)对偶问题的最优解: Y =(5,0,23,0,0)T8. 线性规划问题如果有无穷多最优解,则单纯形计算表的终表中必然有___某一个非基变量的检验数为0______;9. 极大化的线性规划问题为无界解时,则对偶问题_无解_________;10. 若整数规划的松驰问题的最优解不符合整数要求,假设X i =b i 不符合整数要求,INT (b i )是不超过b i 的最大整数,则构造两个约束条件:Xi ≥INT (b i )+1 和 Xi ≤INT (b i ) ,分别将其并入上述松驰问题中,形成两个分支,即两个后继问题。
11. 知下表是制订生产计划问题的一张LP 最优单纯形表(极大化问题,约束条问:(1)对偶问题的最优解: Y =(4,0,9,0,0,0)T (2)写出B -1=⎪⎪⎪⎭⎫ ⎝⎛611401102二、计算题(60分)1、已知线性规划(20分)MaxZ=3X 1+4X 2 1+X 2≤5 2X 1+4X 2≤12 3X 1+2X 2≤81,X 2≥02)若C 2从4变成5,最优解是否会发生改变,为什么?3)若b 2的量从12上升到15,最优解是否会发生变化,为什么?4)如果增加一种产品X 6,其P 6=(2,3,1)T ,C 6=4该产品是否应该投产?为什么? 解:1)对偶问题为Minw=5y1+12y2+8y3 y1+2y2+3y3≥3y1+4y2+2y3≥4 y1,y2≥02)当C 2从4变成5时, σ4=-9/8 σ5=-1/4由于非基变量的检验数仍然都是小于0的,所以最优解不变。

一、思考题1. 什么是线性规划模型,在模型中各系数的经济意义是什么? 2. 线性规划问题的一般形式有何特征?3. 建立一个实际问题的数学模型一般要几步?4. 两个变量的线性规划问题的图解法的一般步骤是什么?5. 求解线性规划问题时可能出现几种结果,那种结果反映建模时有错误?6. 什么是线性规划的标准型,如何把一个非标准形式的线性规划问题转化成标准形式。
7. 试述线性规划问题的可行解、基础解、基础可行解、最优解、最优基础解的概念及它们之间的相互关系。
8. 试述单纯形法的计算步骤,如何在单纯形表上判别问题具有唯一最优解、有无穷多个最优解、无界解或无可行解。
9. 在什么样的情况下采用人工变量法,人工变量法包括哪两种解法?10.大M 法中,M 的作用是什么?对最小化问题,在目标函数中人工变量的系数取什么?最大化问题呢? 11.什么是单纯形法的两阶段法?两阶段法的第一段是为了解决什么问题?在怎样的情况下,继续第二阶段? 二、判断下列说法是否正确。
1. 线性规划问题的最优解一定在可行域的顶点达到。
2. 线性规划的可行解集是凸集。
3. 如果一个线性规划问题有两个不同的最优解,则它有无穷多个最优解。
4. 线性规划模型中增加一个约束条件,可行域的范围一般将缩小,减少一个约束条件,可行域的范围一般将扩大。
5. 线性规划问题的每一个基本解对应可行域的一个顶点。
6. 如果一个线性规划问题有可行解,那么它必有最优解。
7. 用单纯形法求解标准形式(求最小值)的线性规划问题时,与0>j σ对应的变量都可以被选作换入变量。
8. 单纯形法计算中,如不按最小非负比值原则选出换出变量,则在下一个解中至少有一个基变量的值是负的。
9. 单纯形法计算中,选取最大正检验数k σ对应的变量k x作为换入变量,可使目 标函数值得到最快的减少。
10. 一旦一个人工变量在迭代中变为非基变量后,该变量及相应列的数字可以从单纯形表中删除,而不影响计算结果。


旅游业发展水平评价问题摘要为了研究比较两个旅游城市Q、Y的旅游业发展水平,建立层次分析法]3[数学模型,对两个旅游城市Q、Y的旅游业发展水平进行了评价.首先,通过对题目中的图1、表1进行了分析与讨论,根据层次分析法,建立了目标层A、准则层B和子准则层C、方案层D四个层次,通过同一层目标之间的重要性的两两比较,得出判断矩阵,利用]1[MATLAB编程对每个判断矩阵进行求解.其次,用MATLAB软件算出决策组合向量,再比较决策组合向量的大小,由“决策组合向量最大”为目标,得出城市Y的决策组合向量为0.4325,城市Q组合向量为0.5675.最后,通过城市Q旅游业发展水平与旅游城市Y旅游业发展水平的决策组合向量比较,得出城市Q的旅游业发展水平较高.关键词层次分析法MATLAB旅游业发展水平决策组合向量1.问题重述本文要求分析QY,两个旅游城市旅游业发展水平,并且给出了两个城市各方面因素的对比,如城市规模与密度,经济条件,交通条件,生态环境条件,宣传与监督,旅游规格,空气质量,城市规模,人口密度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP,外贸依存度,市内外交通,人均拥有绿地面积,污水集中处理率,环境噪音,国内外旅游人数,理赔金额,立案数量,A级景点数量,旅行社数量,星级饭店数量.建立数学模型进行求解.2.问题分析本文要求分析QY,两个城市的分析Y,两个旅游城市旅游业发展水平,在对Q中,发现需要考虑因素较多,第一、城市规模与密度,包括城市规模与人口密度.第二、经济条件,包括外贸依存度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP.第三、交通条件,包括市内外交通.第四,生态环境条件包括空气质量,人均绿地面积,污水处理能力,环境噪音.第五、宣传与监督,包括国内外旅游人数,游客投诉立案件数.第六、旅游规格,包括A级景点个数,旅行社个数,星级饭店个数,这就涉及到层次分析法来估算各个指标的权重,评出最优方案.具体内容如下:(1)本文选择了对QY,两个旅游城市旅游业发展水平有影响的19个指标作为评价要素,指标规定如下:城市规模:城市的人口数量.人口密度:单位面积土地上居住的人口数.是反映某一地区范围内人口疏密程度的指标.人口影响城市规模.人口密度越大城市规模也就越大.人均GDP:即人均国内生产总值.人均城建资金:即用于城市建设的资金总投入.第三产业增加值:增加值率指在一定时期内单位产值的增加值.即第三产业增加值越高越能带动城市经济的发展.税收GDP:税收是国家为实现其职能,凭借政治权力,按照法律规定,通过税收工具强制地、无偿地征收参与国民收入和社会产品的分配和再分配取得财政收入的一种形式.外贸依存度:即城市对于外贸交易的依赖程度.市内交通:即城市市区交通情况.市外交通:即城市郊区交通情况.市内交通与市外交通对于城市交通条件具有同等的重要性.空气质量:即城市总体空气质量情况.空气质量越好对于城市生态环境就越好.人均绿地面积:即反应城市绿化面积以及人口密度的比值关系.污水处理能力:城市污水处理水平.环境噪音:城市环境噪音情况.国内外旅客人数:国内外来旅客一年总人数.人数越多说明宣传与监督就越好.理赔金额:即立案后需要赔付的资金数.立案件数:即在旅游时发生违法事件后公安部立案的件数.A 级景点数量:即A 级景点的个数.A 级景点越多,越能带动旅行社数量以及星级饭店数量,则旅游规格越大.旅行社数量:即旅行社的个数.星级饭店数量:即星级饭店在旅游景点的个数.(2)用层次分析法建立模型,根据判断矩阵,利用MATLAB 软件,算出每个判断矩阵的特征向量W 、最大特征根c 、一次性指标CI ,再结合随机一次性指标,得出每个指标的特征向量.(3)用(2)得出的数据,运用MATLAB 软件算出两个城市的决策组合向量,做比较.3.模型假设1.假设两个城市Q 、Y 的人口流动不大.2.假设两个城市Q 、Y 的各项指标短期内不会发生太大的改变.4.符号说明A : 表示目标层;j B : 表示准则层第j 个指标的名称)6,,2,1( =j ;i C : 表示子准则层第i 个指标的名称()19,,2,1 =i ; q D : 表示方案层第q 个指标的名称()2,1=q ;1w : 表示准则层对目标层的特征向量组成的矩阵; 2w : 表示子准则层对准则层的特征向量组成的矩阵; 3w : 表示方案层对子准则层的特征向量组成的矩阵;CI : 表示一次性指标;CR : 表示随机一次性指标; Z : 表示决策组合向量.5.模型建立与求解5.1 根据层次分析法分析以及题目中的图1可以建立如下表5-1的层次分析结构,并构造两两比较判断矩阵在递阶层次结构中,设上一层元素B 为准则层,所支配的下一层元素为1C ……19C ,要确定元素1C ……n C 对于准则层B 相对的重要性即权重,可分为两种情况:(1)如果1C 2C ……n C 对B 的重要性可定量,其权重可直接确定; (2)如果问题复杂,1C 2C ……n C 对B 的重要性无法直接定量,而是一些定性的,确定权重用两两比较方法.(3)其方法是,对于准则层C ,元素i C 和j C 哪一个更重要,重要多少,按1-9比例标度对重要性程度赋值.表5-2中列出了1-9标度的含义.对于准则B ,n 个元素之间相对重要性的比较得到一个两两比较判断矩阵P =()mxn ij P ,表示其中ij P 表示i P 和j P 对B 的影响之比,显然ij P >0,ij P =ijP 1,ij P =1,由ij P 的特点,P 称为正互反矩阵.通过两两判断矩阵用方根法求出他们的最大特征根和特征向量,求法如下: 1. 判断矩阵每一行元素的乘积,其中ij n1j 1p m =∏=,i =1,2…,n .2. 计算i m 的n 次方根_i w ,_i w =n i m .3. 对向量Tn w w w ⎪⎭⎫ ⎝⎛=__1,...,归一化,即∑==n j ji w 1__i w w ,则Tn w w w ⎪⎭⎫⎝⎛=__1,.为所求的特征向量.4. 计算判断矩阵的最大特征跟max λ,()∑==n1max i iinw pw λ,式中()i pw 表示pw 的第i 个元素.5. 定义⎪⎭⎫ ⎝⎛--=1max n n CI CI λ为矩阵A 的一致性指标,为了确定A 的不一致性程度的容许范围,需要找出衡量A 的一致性指标CI 的标准.引入随机一致性指标RI .平均随机一致性指标RI 是这样得到的;对于固定的n ,随机构造正互反矩阵A ,其中ij a 是从1,2,……9,91......31,21中随机抽取的,这样的A 是最不一致的,取充分大的样子(500个样本)得到A 的最大特征跟的平均值max λ,定义⎪⎭⎫ ⎝⎛--=1max n n RI λ,对于不同的n 得出随机一致性指标RI 的数值如下表5-3表中n =1,2时RI =0,是因为1,2阶的正互反矩阵总是一致阵.令RICICR =,称CR 为一致性比率,当CR <0.1时,本文认为判断矩阵具有满意的一致性,否则就需要调整判断矩阵,使之具有满意的一致性.最后通过计算得出下表5-4(其中n B 表示准则层的特征向量中的第n 个数值,in C 表示指标层的特征向量第n 个准则对第j 个指标的数值)层次总排序一致性检验的方法j n1CI c CI j j ∑==j n 1c RI RI j j ∑==RICI CR =若1.0CR时,所以认为判断矩阵具有满意的一致性,否则就需要调整判断.矩阵,使之具有满意的一致性.5.2根据层次分析法求出各个指标的权重依据题目中的表1分析,对本题做出其中一种假设:(1)经济条件和交通条件重要性相当,生态环境条件最重要,旅游规格、宣传与监督、城市规模与密度依次次之.(2)在城市规模与密度中,城市人口比人口密度重要一点.(3)在经济条件中,第三产业增加值GDP第一重要,其次是人均GDP,税收GDP、外贸依存度、人均城建资金依次次之.(4)在交通条件中,市内交通和市外交通的重要性相当.(5)在生态环境条件中,空气质量第一重要,其次是人均绿地面积,污水处理能力、环境噪音依次次之.(6)在宣传与监督中,国内外旅游人数第一重要,理赔金额、游客投诉立案件数重要性相当.(7)在旅游规格中,A级景点个数第一重要,星级饭店个数、旅行社个数依次次之.(8)对于城市规模,城市Q比城市Y的重要性小一些;对于人口密度,城市Y比城市Q的重要性明显重要;对于人均GDP,城市Q比城市Y的重要性稍重要;对于人均城建资金,城市Q比城市Y的重要性稍微重要;对于第三产业增加值GDP,城市Q比城市Y的重要性小一些;对于税收GDP,城市Q比城市Y的重要性稍小一点;对于外贸依存度,城市Q比城市Y的重要性稍重要;对于市内交通,城市Y比城市Q的重要性稍重要一点;对于市外交通,城市Y比城市Q的重要性比稍重要小一点;归于空气质量,城市Q比城市Y的重要性相当;对于人均绿地面积,城市Y比城市Q的重要性稍重要;对于污水处理能力,城市Y比城市Q的重要性稍重要一些;对于环境噪音,城市Q比城市Y的重要性相当;对于国内外旅游人数,城市Q比城市Y的重要性稍重要;对于理赔金额,城市Q比城市Y的重要性稍重要一些;对于游客投诉立案件数,城市Q比城市Y的重要性稍重要;对于A级景点个数,城市Y比城市Q的重要性稍重要小一些;对于旅行社个数,城市Y比城市Q的重要性稍重要小一些;对于星级饭店个数,城市Q比城市Y的重要性相当.根据上述分析,按1-9比例标度对准则层对目标层、子准层对准则层、目标层对子准则层的重要程度进行赋值,构造准则层对目标层的判断矩阵、子准则层对准则层的判断矩阵、方案层对子准则层的判断矩阵.准则层()6,,2,1 =j B j 对目标层A 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=12312121321141313123412252321114232111431215141411A 利用MATLAB 软件(附录1)求得 最大特征值0719.6m ax =λ特征向量⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=1219.00753.03422.02057.02057.00492.01w一致性检验比率1.00116.0<=CR所以矩阵满足一致性检验.子准则层21,C C 对准则层1B 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=131311B利用MATLAB 软件(附录2)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层76543,,,,C C C C C 对准则层2B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=121412312131321431522131511413221412B 利用MATLAB 软件(附录3)求得 最大特征值0681.5m ax =λ特征向量⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=0973.01599.04185.00618.02625.0w一致性检验比率1.00152.0<=CR所以矩阵满足一致性检验.子准则层98,C C 对准则层3B 的判断矩阵⎥⎦⎤⎢⎣⎡=11113B 利用MATLAB 软件(附录4)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层13121110,,,C C C C 对准则层4B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎣⎡=1121311121312212133214B 利用MATLAB 软件(附录5)求得最大特征值0104.4m ax =λ特征向量⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=1409.01409.02628.04554.0w 一致性检验比率1.00038.0<=CR所以矩阵满足一致性检验.子准则层161514,,C C C 对准则层5B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211212215B 利用MATLAB 软件(附录6)求得最大特征值0536.3m ax =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=3108.01958.04934.0w 一致性检验比率1.00462.0<=CR所以矩阵满足一致性检验.子准则层191817,,C C C 对准则层6B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211312316B 利用MATLAB 软件(附录7)求得最大特征值0092.3m ax =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=2970.01634.05396.0w 一致性检验比率1.00079.0<=CR所以矩阵满足一致性检验.方案层对子准则层的判断矩阵 方案层21,D D 对子准则层1C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层2C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155112C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=1667.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层3C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133113C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层4C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=144114C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层5C 的判断矩阵:⎥⎥⎦⎤⎢⎢⎣⎡=122115C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎢⎣=3333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层6C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层7C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=141417C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层8C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155118C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=8333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层9C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122119C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层10C 的判断矩阵⎥⎦⎤⎢⎣⎡=111110C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层11C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1313111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=7500.02500.0w因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层12C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1414112C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2000.08000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层13C 的判断矩阵⎥⎦⎤⎢⎣⎡=111113C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层14C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331114C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2115⎥⎥⎦⎤⎢⎢⎣⎡=1441115C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层16C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层17C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331117C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2118⎥⎥⎦⎤⎢⎢⎣⎡=1221118C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子19C 的判断矩阵: ⎥⎦⎤⎢⎣⎡=111119C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 通过准则层()6,,2,1 =j B j 对目标层A 的判断矩阵、子准则层()19,,2,1 =i C i 对准则层()6,,2,1 =j B j 的判断矩阵得出特征向量,建立层次总表5-5层次总排序一致性检验如下:0073.061==∑=j j j CI B CI65274.0j 61j j ==∑=RI B RI0111.065274.00073.0===RI CI CR 由于1.00111.0<=CR ,所以认为层次总排序的结果具有满意的一致性,因此不需要重新调整判断矩阵的元素取值.5.3 利用MATLAB 进行决策组合向量的运算(附录9)⋅⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=⋅⋅=Tw w w Z 2970.0001634.0000005396.00000003108.0000001958.0000004934.00000001409.0000001409.0000002628.0000004554.00000005000.0000005000.00000000973.0000001599.0000004185.0000000618.0000002625.00000002500.0000007500.0132⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡5000.05000.06667.03333.06667.03333.02500.07500.08000.02000.02500.07500.05000.05000.02000.08000.07500.02500.05000.05000.06667.03333.01667.08333.08000.02000.02500.07500.06667.03333.02000.08000.02500.07500.08333.01667.03333.06667.0⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡⋅1219.00753.03422.02057.02057.00492.0 Z ⎥⎦⎤⎢⎣⎡=5675.04325.0 比较Z 值大小可知,12Z Z >,表明城市Q 的旅游发展也水平最高,城市Y 的旅游业发展水平次之,所以城市Q 的旅游发展也水平高.6模型的评价优点:(1) 本文选择了计算比较简单的层次分析法,经过计算得到了相应的综合发展旅游业的估计值,为城市旅游业的发展提供了依据.(2) 使用了MATLAB 软件,减少了计算工作量,大大降低了运算的困难.缺点:判断的结果具有一定的主观性,不能比较切实的结合当地的具体情况,做出科学的决策方案.7参考文献[1] 姜启源等,数学建模(第四版)北京:高等教育出版社.2011年[2] 马莉,数学实验与建模,北京:清华大学出版2010年[3] 王莲芬,层次分析法引论,北京:中国人民大学出版社,1990年附录:附录1x=[1 1/4 1/4 1/5 1/2 1/3;4 1 1 1/2 3 2;4 1 1 1/2 3 2;5 2 2 1 4 3;2 1/3 1/3 1/4 1 1/2;3 1/2 1/2 1/3 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-6)/5 %一致性指标CR=CI/1.24 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =6.0719W =0.04920.20570.20570.34220.07530.1219B =0.04670.21410.21410.29180.08810.1452CI =0.0144CR =0.0116C =0.2146附录2:>> x=[1 3;1/3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250附录3:x=[1 4 1/2 2 3;1/4 1 1/5 1/3 1/2;2 5 1 3 4;1/2 3 1/3 1 2;1/3 2 1/4 1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-5)/4 %一致性指标CR=CI/1.12 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =5.0681W =0.26250.06180.41850.15990.0973B =0.27340.05940.36640.18730.1135CI =0.0170CR =0.0152C =0.2698附录4:x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录5:x=[1 2 3 3;1/2 1 2 2;1/3 1/2 1 1;1/3 1/2 1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-4)/3 %一致性指标CR=CI/0.90 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =4.0104W =0.45540.26280.14090.1409B =0.43950.27870.14090.1409CI =0.0035CR =0.0038C =0.3131附录6:x=[1 2 2;1/2 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0536W =0.49340.19580.3108B =0.46060.18790.3515CI =0.0268CR =0.0462C =0.3733附录7:x=[1 3 2;1/3 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0092W =0.53960.16340.2970B =0.51990.16200.3181CI =0.0046CR =0.0079C =0.4015附录8:% 目标层Q,Y对子准则层C1的赋值>> x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C2的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.83330.1667B =0.83330.1667CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C3的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C4的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C5的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.66670.3333B =0.66670.3333CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C6的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C7的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C8的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.16670.8333B =0.16670.8333CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C9的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C10的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =NaNC =0.5000% 目标层Q,Y对子准则层C11的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.25000.7500B =0.25000.7500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C12的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C13的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000% 目标层Q,Y对子准则层C14的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C15的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C16的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C17的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C18的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C19的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录9:% 最终组合权向量:x=[0.75 0 0 0 0 0;0.25 0 0 0 0 0;0 0.2625 0 0 0 0;0 0.0618 0 0 0 0;0 0.4185 0 0 0 0;0 0.1599 0 0 0 0;0 0.0973 0 0 0 0;0 0 0.5 0 0 0;0 0 0.5 0 0 0;0 0 0 0.4554 0 0;0 0 0 0.2628 0 0;0 0 0 0.1409 0 0;0 0 0 0.1409 0 0;0 0 0 0 0.4934 0;0 0 0 0 0.1958 0;0 0 0 0 0.3108 0;0 0 0 0 0 0.5396;0 0 0 0 0 0.1634;0 0 0 0 0 0.2970]x =0.7500 0 0 0 0 00.2500 0 0 0 0 00 0.2625 0 0 0 00 0.0618 0 0 0 00 0.4185 0 0 0 00 0.1599 0 0 0 00 0.0973 0 0 0 00 0 0.5000 0 0 00 0 0.5000 0 0 00 0 0 0.4554 0 00 0 0 0.2628 0 00 0 0 0.1409 0 00 0 0 0.1409 0 00 0 0 0 0.4934 00 0 0 0 0.1958 00 0 0 0 0.3108 00 0 0 0 0 0.53960 0 0 0 0 0.16340 0 0 0 0 0.2970y=[0.0492;0.2057;0.2057;0.3422;0.0753;0.1219]y =0.04920.20570.20570.34220.07530.1219z=x*y运算结果:z =0.03690.01230.05400.01270.08610.03290.02000.10290.10290.15580.08990.04820.04820.03720.01470.02340.06580.01990.0362a=[0.3333 0.8333 0.75 0.2 0.3333 0.75 0.2 0.1667 0.3333 0.5 0.25 0.8 0.5 0.75 0.2 0.75 0.3333 0.3333 0.5;0.6667 0.1667 0.25 0.8 0.6667 0.250.8 0.8333 0.6667 0.5 0.75 0.2 0.5 0.25 0.8 0.25 0.6667 0.6667 0.5]a =Columns 1 through 70.3333 0.8333 0.7500 0.2000 0.3333 0.7500 0.20000.6667 0.1667 0.2500 0.8000 0.6667 0.2500 0.8000Columns 8 through 140.1667 0.3333 0.5000 0.2500 0.8000 0.5000 0.75000.8333 0.6667 0.5000 0.7500 0.2000 0.5000 0.2500Columns 15 through 190.2000 0.7500 0.3333 0.3333 0.50000.8000 0.2500 0.6667 0.6667 0.5000c=a*z运算结果:c =0.43250.5675。


《运筹学》试题及答案(六)《运筹学》试题及答案第⼆章线性规划的基本概念⼀、填空题1.线性规划问题是求⼀个线性⽬标函数_在⼀组线性约束条件下的极值问题。
2.图解法适⽤于含有两个变量的线性规划问题。
3.线性规划问题的可⾏解是指满⾜所有约束条件的解。
4.在线性规划问题的基本解中,所有的⾮基变量等于零。
5.在线性规划问题中,基可⾏解的⾮零分量所对应的列向量线性⽆关6.若线性规划问题有最优解,则最优解⼀定可以在可⾏域的顶点(极点)达到。
7.线性规划问题有可⾏解,则必有基可⾏解。
8.如果线性规划问题存在⽬标函数为有限值的最优解,求解时只需在其基可⾏解_的集合中进⾏搜索即可得到最优解。
9.满⾜⾮负条件的基本解称为基本可⾏解。
10.在将线性规划问题的⼀般形式转化为标准形式时,引⼊的松驰数量在⽬标函数中的系数为零。
11.将线性规划模型化成标准形式时,“≤”的约束条件要在不等式左_端加⼊松弛变量。
12.线性规划模型包括决策(可控)变量,约束条件,⽬标函数三个要素。
13.线性规划问题可分为⽬标函数求极⼤值和极⼩_值两类。
14.线性规划问题的标准形式中,约束条件取等式,⽬标函数求极⼤值,⽽所有变量必须⾮负。
15.线性规划问题的基可⾏解与可⾏域顶点的关系是顶点多于基可⾏解16.在⽤图解法求解线性规划问题时,如果取得极值的等值线与可⾏域的⼀段边界重合,则这段边界上的⼀切点都是最优解。
17.求解线性规划问题可能的结果有⽆解,有唯⼀最优解,有⽆穷多个最优解。
18.如果某个约束条件是“≤”情形,若化为标准形式,需要引⼊⼀松弛变量。
19.如果某个变量X j为⾃由变量,则应引进两个⾮负变量X j′,X j〞,同时令X j=Xj ′-Xj。
20.表达线性规划的简式中⽬标函数为max(min)Z=∑c ij x ij。
21..(2.1 P5))线性规划⼀般表达式中,a ij表⽰该元素位置在i⾏j列。
⼆、单选题1.如果⼀个线性规划问题有n个变量,m个约束⽅程(mA.m个 B.n个 C.Cn m D.Cmn个2.下列图形中阴影部分构成的集合是凸集的是 A3.线性规划模型不包括下列_ D要素。

专题:层次分析法一般情况下,物流系统的评价属于多目标、多判据的系统综合评价。
如 果仅仅依靠评价者的定性分析和逻辑判断,缺乏定量分析依据来评价系统 方案的优劣,显然是十分困难的。
尤其是物流系统的社会经济评价很难作 出精确的定量分析。
层次分析法(Analytical Hierarchy Process )由美国著名运筹学家萨蒂(T . L . Saaty )于1982年提出,它综合了人们主观判断,是一种简明、实 用的定性分析与定量分析相结合的系统分析与评价的方法。
目前,该方法 在国内已得到广泛的推广应用,广泛应用于能源问题分析、科技成果评比、 地区经济发展方案比较,尤其是投入产出分析、资源分配、方案选择及评 比等方面。
它既是一种系统分析的好方法,也是一种新的、简洁的、实用 的决策方法。
♦层次分析法的基本原理人们在日常生活中经常要从一堆同样大小的物品中挑选出最重的物品。
这时,一般是利用两两比较的方法来达到目的。
假设有 n 个物品,其真实重 量用w 1 , w 2,…W n 表示。
要想知道w 1 , w 2,…w n 的值,最简单的就是用秤称 出它们的重量,但如果没有秤,可以将几个物品两两比较,得到它们的重 量比矩阵A 。
由上式可知,n 是A 的特征值,W 是A 的特征向量。
根据矩阵理论,n 是 矩阵A 的唯一非零解,也是最大的特征值。
这就提示我们,可以利用求物品 重量比判断矩阵的特征向量的方法来求得物品真实的重量向量 W 。
从而确 定最重的物品。
将上述n 个物品代表n 个指标(要素),物品的重量向量就表示各指标(要/ivs ...爲严/如果用物品重量向量 W=[w 1,W J W2 …W J W n_w 2,…w n ]T 右乘矩阵A ,则有:AW^/ W]W 2 / W]A ■ ■叫/W] / 叫nw l叫/ %1 H—叫/W] / w 2 / w 2素)的相对重要性向量,即权重向量;可以通过两两因素的比较,建立判断矩阵,再求出其特征向量就可确定哪个因素最重要。
运筹学习题答案一、名词解释树:无圈连通图线性规划:解决在线性约束条件追求最大或最小的线性目标函数值的方法整数规划:决策变量至少有一个要求取整的线性规划0—1规划:决策变量只能取0或1的整数规划线性规划可行解:线性规划中满足所有约束条件的解最优解:使目标函数值最大(即利润最大)的可行解凸函数:函数图像上任意两点的连线上的点都在图像或图像上方的函数对偶价格:当约束条件的常数项增加一个单位时目标函数最优解改进的价格影子价格:当约束条件的常数项增加一个单位时目标函数最优解增加的价格灵敏度分析:在数学建模和求得最优解之后,研究线性规划的一些系数的变化对最优解产生什么影响逗留时间:顾客从进入系统到服务完毕离开系统的平均停留时间纳什均衡:对策的局中人都不能单方面改变自己的策略使自己处境更优最短路:在网络图中给定两点权数最小的通路最大流:在流量网络图中从发送点到接收点能承载的最大流割集:满足下列两个条件:(1)把网络分成两个相互不连接的部分,加上该边集的一个边则为连通(2)权数最小二、选择题1、目标线性规划中的约束条件()A、都有偏差变量B、绝对约束条件有偏差变量C、目标约束条件有偏差变量D、最低优先级的约束条件无偏差变量2、一般在应用线性规划建立模型时要经过四个步骤)()(1)明确问题,确定目标,列出约束因素(2)收集资料,确定模型(3)模型求解与检验(4)优化后分析以上图步的正确顺序是A、(1)(2)(3)(4)B、(2)(1)(3)(4)C、(1)(2)(4)(3)D、(2)(1)(4)(3)3、在运输问题的表上作业法确定初始基可行解时,如果采用Vogel法,则罚数的计算规则是()A、同行(列)的最大运价减去最小运价B、选取同行(列)的最大运价C、同行(列)的次小运价减去最小运价D、选取同行(列)的最小运价4、以下对层次分析法的认识中,不正确的是(C )A、对问题的准确界定及合理分层是层次分析法的前提和基础B、对各层次的各个判断矩阵的获取决定着决策的效果C、层次分析法必然涉及贝叶斯决策过程D、层次分析法涉及计算判断矩阵的特征值与特征向量5、线性规划问题中对人工变量的描述,不正确的是(B )A、在约束条件为“≥”时,为构造初始基可行解需要在该约束条件中添加人工变量B、在约束条件为“=”时,为构造初始基可行解需要在该约束条件中添加人工变量C、添加人工变量后,需要在目标函数中减去M乘以该人工变量(M为足够大的正数)D、人工变量本质上就是松弛变量6、循环存储策略是()A、有订货提前期的存贮策略B、每隔一个固定时间,采购固定数量货物的存贮策略C、每隔一个固定时间,采购最高库存减去现有存货量的存贮策略D、随机存贮策略7、线性规划灵敏度分析中,改变价值系数C,在原最终单纯形表中反映为()A、约束条件右端向量b的变化B、工艺系数矩阵A的变化C、基变量的改变D、检验数的变化8、库存管理的目的是()。
济南大学继续教育学院运筹学试卷(A)学年:学期:年级:专业:学习形式:层次:(本试题满分100分,时间90分钟)一、判断题(每小题2分,共20分)1.用层次分析法解决问题,构造好问题的层次结构图是解决问题的关键.()A.正确B.错误2.目标规划模型中的目标函数按问题要求分别表示为求min或max.()A.正确B.错误3.所谓主观概率基本上是对事件发生可能性做出的一种主观猜想和臆测,缺乏必要科学依据.()A.正确B.错误4.在任一图G中,当点集V确定后,树图是G中边数最少的连通图.()A.正确B.错误5.对于一个动态规划问题,应用顺推或者逆推解法可能会得出不同的最优解.()A.正确B.错误6.排队系统中,顾客等待时间的分布不受排队服务规则的影响.()A. 正确B. 错误7.在折中主义准则中,乐观系数a的确定与决策者对风险的偏好有关.()A.正确B.错误8.求目标函数最小值问题不可能转换为求目标函数最大值问题.()A.正确B.错误9.不平衡运输问题不一定有最优解.()A.正确B.错误10.部分变量要求是整数的规划问题称为纯整数规划.()A.正确B.错误二、单选题(每小题3分,共30分)1.关于互为对偶的两个模型的解的存在情况,下列说法不正确的是().A. 都有最优解B. 都无可行解C. 都为无界解D. 一个为无界解,另一个为无可行解2.有6个产地4个销地的平衡运输问题模型具有特征().A. 有10个变量24个约束B. 有24个变量10个约束C. 有24个变量24约束D. 有9个基变量10个非基变量3.人数大于任务数的指派问题中,应该采取的措施是().A. 虚拟人B. 虚拟任务C. 都可以D. 不需要4.容量网络的条件包括().A. 网络中有一个始点和一个终点B. 流过网络的流量都具有一定方向C. 每边(弧)都赋予了一个容量,表示容许通过该弧的最大流量D. 以上都是5.用逆序法求解资源分配问题时,为保证独立性,状态变量取值一般为().A. 各阶段分配的资源数B. 当前阶段开始时前部过程已分配的资源数C. 当前阶段开始时剩余给后部过程的资源数D. 资源的总数6.设有一单人打字室,顾客的到达为普阿松流,平均到达时间间隔为20分钟,打字时间服从指数分布,平均时间为15分钟,打字室内顾客的平均数为().A.1/4B.1/3C.4D.37.对于不确定型的决策,某人采用乐观主义准则进行决策,则应在收益表中().A. 大中取大B. 大中取小C. 小中取大D. 小中取小8.为了使各因素之间进行两两比较得到量化的判断矩阵,引入()的标度.A. 1~7B. 1~8C. 1~9D. 随便9.下列线性规划与目标规划之间错误的关系是().A. 线性规划的目标函数由决策变量构成,目标规划的目标函数由偏差变量构成第 1 页共 9 页。
层次分析法在水环境规划中的应用1 层次分析法的原理层次分析法是70年代由美国运筹学家T.L.Saaty提出的,经过多年的发展现已成为一种较为成熟的方法。
其基本原理是:将要评价系统的有关替代方案的各种要素分解成若干层次,并以同一层次的各种要素按照上一层要素为准则,进行两两判断比较并计算出各要素的权重,根据综合权重按最大权重原则确定最优方案。
它是在简单加性加权法的基础上推导得出的。
2 流域规划中层次分析法研究在流域环境质量评价中,为相对精确地比较不同断面污染程度,必须对其不同污染物的超标情况加以评价并得出综合性结论,然后根据各断面所在水域的保护类别,确定其重要性,最后对流域各断面环境质量状况进行排序。
因此,根据层次分析法的基本原理,按如下步骤对流域水环境质量进行评价。
(1)建立层次结构模型将流域环境质量评价作为层次分析的目标层(A),将各断面作为层次分析的资源层(B),将各污染物的单因子指数作为层次分析的方案层,建立流域环境质量层次结构模型如图1。
图1流域内水质综合评价层次图(2)构造判断矩阵并求最大特征根和特征向量由于层次结构模型确定了上下层元素间的隶属关系,这样就可针对上一层的准则构造不同层次的两两判断矩阵。
若两两判断矩阵设为(a ij)n×n,则有a ij>0;各层次具体判断矩阵构造方法是:在流域环境质量综合评价目标层(A)下,根据各断面所在区域的保护类别以及是否有饮用水源地等因素,两两比较断面的重要性,类别越高,其重要性越高,即Ⅱ类保护区比Ⅲ类保护区重要,有饮用水源地地区又比没有饮用水源地地区重要等等,如此类推,构造该级别判断矩阵(A—B)。
这里可引用1-9标度对重要性判断结果进行量化,标度如表1。
构造(B-C)判断矩阵则是用各断面各污染物单因子指数的两两比值作为矩阵中元素。
表1 相对重要性标度*标度定义1 i因素与j因素相同重要3 i因素与j因素略重要5 i因素与j因素较重要7 i因素与j因素非常重要9 i因素与j因素绝对重要2,4,6,8 为以上两判断之间的中间状态对应的标度值倒数若i因素与j因素比较,得到判断值为aij =1/aji,aii=1*表中i和j因素是指水体保护区类别、饮用水源地分布等。
层次分析法(Analytical Hierarchy Process , AHP )是美国运筹学家沙旦(T.L.Saaty )于20世 纪70年代提出的,是一种定性与定量分析相结合的多目标决策方法。
AHP 通过对多准则决策
问题构造层次结构模型,在每一层次上将决策者的主观判断进行数量化,然后进行逐层加权处 理,最后得到各备选方案相对于总目标的权重,从而实现多准则 (目标)下对备选方案的排序。
优点:AHP 具有思路清晰、方法简单、适用面广、便于推广应用等特点,是目前解决多准 则决策问题有效的方法之一 .
层次分析法的基本步骤和要点
结合一个具体例子,说明层次分析法的基本步骤和要点。
【案例分析】市政工程项目建设决策:层次分析法问题提出
市政部门管理人员需要对修建一项市政工程项目进行决策,可选择的方案是修建通往旅游 区的高速路(简称建高速路)或修建城区地铁(简称建地铁) 。
除了考虑经济效益外,还要考虑 社会效益、环境效益等因素,即是多准则决策问题,考虑运用层次分析法解决。
1.建立递阶层次结构
应用AHP 解决实际问题,首先明确要分析决策的问题,并把它条理化、层次化,理出递 阶层次结构。
AHP 要求的递阶层次结构一般由以下三个层次组成:
:指问题的预定目标;
:指影响目标实现的准则;
:指促使目标实现的措施; 首先明确决策的目标,将该目标作为 这个目标要
求是唯一的,即目标层只有一个元素。
然后找出影响目标实现的准则,作为目标层下
的 准则层因素,在复杂问题中,影响目标
实现的准则可能有很多,这时要详细分析各准则因素间的相互关系,即有些是主要的准则,有 些是隶属于主要准则的次准则,然后根据这些关系将准则元素分成不同的层次和组,不同层次 元素间一般存在隶属关系,即上一层元素由下一层元素构成并对下一层元素起支配作用,同一 层元素形成若干组,同组元素性质相近,一般隶属于同一个上一层元素(受上一层元素支配) 不同组元素性质不同,一般隶属于不同的上一层元素。
在关系复杂的递阶层次结构中,有时组的关系不明显,即上一层的若干元素同时对下一 层的若干元素起支配作用,形成相互交叉的层次关系,但无论怎样,上下层的隶属关系应该是 明显的。
最后分析为了解决决策问题(实现决策目标) 、在上述准则下,有哪些最终解决方案(措
施),并将它们作为措施层因素,放在递阶层次结构的最下面(最低层)。
明确各个层次的因素及其位置,并将它们之间的关系用连线连接起来,就构成了递阶层
次结构。
【案例分析】市政工程项目进行决策:建立递阶层次结构
在市政工程项目决策问题中,市政管理人员希望通过选择不同的市政工程项目,使综合 效益最高,即决策目标是“合理建设市政工程,使综合效益最高” 。
目标层(最高层) 准则层(中间层) 措施层(最低层) 通过对复杂问题的分析, 目标层(最高层)的元素,
为了实现这一目标,需要考虑的主要 _______________________________________________________ 但问题绝不这么简单。
通过深入思考,决策人员认为还必须考虑直接经济效益、间接经济效益、 方便日常出行、方便假日出行、减少环境污染、改善城市面貌等因素(准则)
,从相互关系上分 析,这些因素隶属于主要准则,因此放在下一层次考虑,并且分属于不同准则。
假设本问题只考虑这些准则,接下来需要明确为了实现决策目标、在上述准则下可以有
哪些方案。
根据题中所述,本问题有两个解决方案,即建高速路或建地铁,这两个因素作为措 施层元素放在递阶层次结构的最下层。
很明显,这两个方案于所有准则都相关。
将各个层次的因素按其上下关系摆放好位置,并将它们之间的关系用连线连接起来。
同
时,为了方便后面的定量表示,一般从上到下用 A 、B 、C 、D 。
代表不同层次,同一层次从 左到右用1、2、3、4。
代表不同因素。
这样构成的递阶层次结构如下图。
目标层A 合理建设市政工程,使综合效益最高 (A )
图1递阶层次结构示意图
2.构造判断矩阵并赋值
根据递阶层次结构就能很容易地构造判断矩阵。
构造判断矩阵的方法是:每一个具有向下隶属关系的元素(被称作准则)作为判断矩阵 的第一个元素(位于左上角),隶属于它的各个元素依次排列在其后的第一行和第一列。
重要的是填写判断矩阵。
填写判断矩阵的方法有:
大多采取的方法是:向填写人(专家)反复询问:针对判断矩阵的准则,其中两个元素
准则层B 准则层C 1 1 1
方便日
方便假 常出行 日出行 (C3)
措施层D
经济效益(B1) 直接经
间接带 济效益
动效益 (C1) (C2) 社会效益(B2)。