第四章不相交集数据结构Union-Find分析
- 格式:ppt
- 大小:260.00 KB
- 文档页数:69

并查集解决元素分组及连通性问题并查集(Disjoint-set Union)是一种常用的数据结构,主要用于解决元素分组及连通性问题。
它将n个元素划分为若干个不相交的集合,每个集合通过一个代表来标识。
在该数据结构下,我们可以高效地进行合并集合和查询某个元素所属的集合操作。
一、并查集的基本原理并查集主要由两个操作组成:合并(Union)和查找(Find)。
其中,合并操作将两个集合合并为一个集合,查找操作则用于确定某个元素所属的集合。
在并查集中,每个元素都有一个指向父节点的指针,初始时每个元素自成一个集合,其父节点指向自己。
合并操作就是将两个元素所在集合的根节点合并为一个根节点,即将其中一个集合的根节点指向另一个集合的根节点。
查找操作通过递归地向上查找父节点,最终找到根节点,从而确定该元素所属的集合。
二、并查集的具体实现并查集的具体实现可使用数组或树结构。
数组实现简单直观,树结构实现更加高效。
以下是树结构实现的代码示例:```pythonclass UnionFind:def __init__(self, n):self.parent = list(range(n))def union(self, a, b):self.parent[self.find(a)] = self.find(b)def find(self, x):if self.parent[x] != x:self.parent[x] = self.find(self.parent[x])return self.parent[x]```在这个实现中,parent数组记录了每个元素的父节点,初始时每个元素的父节点为自己。
合并操作通过将某个元素的根节点指向另一个元素的根节点来实现。
查找操作递归地向上查找父节点,直到找到根节点。
三、应用场景举例1. 图的连通性判断:利用并查集可以判断图中的两个节点是否连通。
假设图中有n个节点,我们可以用并查集来维护这些节点的连通情况。


数据结构union函数-回复数据结构中的union函数是一种常见的操作,它用于合并两个集合或者查找两个元素所属的集合。
本文将详细介绍union函数的实现原理以及其在数据结构中的应用。
一、union函数概述在数据结构中,union函数的主要作用是将两个不相交的集合合并为一个集合,从而构建一个更大的集合。
具体来说,union函数的输入是两个集合以及它们的代表元素,输出是合并后的集合。
二、union函数的实现原理对于union函数的实现,常见的方法是使用并查集(disjoint set)数据结构。
并查集是一种用于处理不相交集合的数据结构,它支持合并集合和查询元素所属集合的操作。
在并查集中,每个集合用一棵树来表示,树的根节点指向自身,其他节点指向它的父节点。
每个集合由一个代表元素来表示,代表元素是根节点。
假设有两个集合A和B,分别由代表元素a和b表示,union函数的目标就是将集合A和B合并为一个集合。
具体而言,union函数的实现可以分为以下步骤:1. 首先,找到集合A和B的代表元素a和b。
2. 将代表元素b的父节点设置为a,即将集合B合并到集合A中。
3. 如果集合B的规模比集合A大,则更新集合A的代表元素为b。
可以通过路径压缩来优化union函数的性能。
路径压缩是一种在查找代表元素的过程中优化树形结构的方法,它通过将路径上的每个节点直接连接到根节点,减少树的高度,提高查找效率。
三、union函数的应用union函数在数据结构中有广泛的应用,下面分别介绍两个典型的应用场景。
1. 连通性问题在图论中,连通性问题是指判断两个节点是否存在路径连接的问题。
利用union函数可以高效地解决这个问题。
具体而言,可以使用一个并查集来表示图中的节点集合,每个节点用一个元素来表示。
当两个节点之间存在边时,可以使用union函数将它们所属的集合合并。
最后,利用find函数来判断两个节点是否属于同一个连通分量。
2. 集合合并在某些场合,需要将多个集合合并为一个更大的集合。


算法与数据结构基础-合并查找(UnionFind)Union Find算法基础Union Find算法⽤于处理集合的合并和查询问题,其定义了两个⽤于并查集的操作:Find: 确定元素属于哪⼀个⼦集,或判断两个元素是否属于同⼀⼦集Union: 将两个⼦集合并为⼀个⼦集并查集是⼀种树形的数据结构,其可⽤数组或unordered_map表⽰:Find操作即查找元素的root,当两元素root相同时判定他们属于同⼀个⼦集;Union操作即通过修改元素的root(或修改parent)合并⼦集,下⾯两个图展⽰了id[6]由6修改为9的变化:图⽚来源Union Find算法应⽤Union Find可⽤于解决集合相关问题,如判断某元素是否属于集合、两个元素是否属同⼀集合、求解集合个数等,算法框架如下://261. Graph Valid Treebool validTree(int n, vector<pair<int, int>>& edges) {vector<int> num(n,-1);for(auto edge:edges){//find查看两点是否已在同⼀集合int x=find(num,edge.first);int y=find(num,edge.second);if(x==y) return false; //两点已在同⼀集合情况下则出现环//union让两点加⼊同⼀集合num[x]=y;}return n-1==edges.size();}int find(vector<int>&num,int i){if(num[i]==-1) return i;return find(num,num[i]); //id[id[...id[i]...]]}⼀些情况下为清晰和解偶会将Uinon Find实现为⼀个类,独⽴出明显的Union和Find两个操作。


程序设计中常用的数据结构在程序设计中,数据结构是许多算法和程序的基础。
以下是程序设计中常用的几种数据结构:1. 数组(Array):数组是一组有序的数据元素,可以通过索引值来访问和修改数组中的元素。
数组的主要优点是支持随机访问,但插入和删除操作的效率相对较低。
2. 栈(Stack):栈是一种后进先出(LIFO)的数据结构,只能从栈顶插入和删除数据。
栈的主要应用场景包括函数调用、表达式求值和内存分配等。
3. 队列(Queue):队列是一种先进先出(FIFO)的数据结构,只能从队列尾插入数据并从队列头删除数据。
队列的主要应用场景包括广度优先搜索和任务调度等。
4. 链表(Linked List):链表是一种递归的数据结构,由若干个节点组成,每个节点包含当前元素的值和指向下一个节点的指针。
链表支持快速插入和删除操作,但访问特定位置的元素需要顺序查找,效率相对较低。
5. 哈希表(Hash Table):哈希表是一种基于哈希函数实现的数据结构,可以快速地插入、删除和查找元素。
在哈希表中,元素的存储位置是通过哈希函数计算得到的,因此访问特定位置的元素效率很高。
6. 树(Tree):树是一种层次结构,由若干个节点和连接这些节点的边组成。
常见的树形数据结构包括二叉搜索树、红黑树、AVL 树和 B 树等。
树的主要应用场景包括搜索、排序和存储等。
7. 图(Graph):图是由一组节点和连接这些节点的边组成的数据结构。
图常用来表示实体之间的关系,如社交网络、路线图等。
在计算机科学中,图的主要应用包括最短路径算法、网络流等。
8. 堆(Heap):堆是一种特殊的树形数据结构,它满足某些特定的性质。
被称为“最小堆”的堆中,每个父节点的值都小于或等于其子节点的值,而被称为“最大堆”的堆中,每个父节点的值都大于或等于其子节点的值。
堆可以用来实现优先队列和堆排序等算法。
9. 字典树(Trie):字典树是一种用于字符串处理的树形数据结构。


山东大学软件学院数据结构课程设计报告设计题目: 树形等价类的Union,Find学号姓名年级专业软件工程班级学期12-13学年第二学期日期: 2013年3 月5日1.需求描述1)准确演示算法的实现思想,把算法的过程思想一步步展示出来。
让一个不懂数据结构的人,看了演示程序,就能对算法的思路大体了解。
2)能单步演示。
3)软件要能用、易用。
界面友好。
4)软件可以对输入用例案例重复演示。
不能演示完成就自动退出。
5)输入的用例数据可编辑。
6)软件要健壮,对非法的输入能给出合适的提示,不能直接导致软件崩溃。
2.实现思想1)有一个Leaf类,每个Leaf对象有一个父亲节点(初始化时为null),有一个链表里面有这个节点的所有孩子节点。
当添加等价关系时,其实添加的是节点间的父子关系,代码举例:l1.getChild().add(l2);l2.setParent(l1);2)其实程序开始时,初始化了72个Leaf元素,当用户输入元素个数n,则把num变量设为n,把num个元素设为可见。
当然用户输入的数据大于72时异常处理会提醒用户输入0到72之间的数。
3)每个Leaf对象都有一个height属性,当需要显示树的时候,统计每个height上有多少个Leaf对象,根据Leaf的个数来确定间隔,则画出的节点不易重叠。
用链表来盛放所有从当前元素到根节点经过的所有节点。
4)当用户点击元素个数后面的提交按钮时,将所有的等价关系清空,来实现可重复使用.5)程序里已经设计好一组等价关系,如果点自动按钮,屏幕上会出现两个等价类,用户可以据此做出查找,合并等操作.6)利用链表来盛放从文本框中元素到根节点的所有元素,利用线程来控制每个节点变化的时间间隔,实现动画效果.另外写了一个sign类,声明“有父亲”和“根”两个对象,通过设置这两个对象的位置来对动画进行说明。
7)每次获取文本框中的元素后,会用一个链表来放从该元素到根节点的所有元素,然后每次点击单步时,判断链表是否为空,如果为空则下一步按钮失效.以此实现单步查找.3.数据结构设计1)每个节点的孩子用链表来放.2)用一个集合来盛放屏幕上所有的节点for (int i = 0; i < 72; i++) {int x = i % 24 * 35;int y = i / 24 * 35;Leaf lf = new Leaf(i + 1, newArrayList<Leaf>(), false);al.add(lf);}3)利用链表来放每层的元素,默认设为9层,如果树太高,超过9层,则提示用户.4)用already集合来盛放所有已经添加过等价关系的节点5)而画树的时候则仿照二叉树的层次遍历,利用队列LinkedList<Leaf> q = new<Leaf> LinkedList();q.add(l);LinkedList<Leaf> list = new<Leaf> LinkedList();while (q.peek() != null) {Leaf leaf1 = q.poll();leaf1.setVisible(true);4.功能设计1)基本功能:a)元素个数后面的文本框用来给用户输入数字,即元素的个数.如果输入的数字不在0到72的范围内,那么会提示用户,请用户输入0到72之间的正整数.b)等价关系后面的两个文本框用来让用户输入有等价关系的两个数,如果用户输入的数字比前面元素个数大,那么会提示用户说输入的数字太大. 当用户点击等价关系后面的提交时,右面的面板上就会有对应的演示,先演示如何寻找两个元素对应的根,再演示添加这组等价关系.同时右面屏幕的上方会显示对应的说明.c)查找后面的数字可以更改,也可以用自带的,来查找某个元素所在的等价类.同时右边会有对应的动画演示,右面上方也会有对应的解释.d)合并用来合并两个等价类.分别查找两个文本框中元素所在等价类,如果已经在同一个等价类,则提醒用户已经是等价的,如果不在同一个等价类,则默认把右边文本框中元素的根,添加为左边文本框中元素根的孩子.2)扩展功能:a)实现自动,即程序本身自带一组数据,如果用户不想输入,可以用程序自带的数据来演示.b)实现可重复使用,用户可以重复输入数据来演示c)实现单步查找.d)实现动画效果,5.运行环境说明6.操作说明如果用户不想手动输入数据,那么可以点击左下方最后一行的自动按钮,这时候屏幕上会出现两棵树,用户可以进行等价关系的添加,查找,合并,单步查找等操作.如果用户想自己操作,那么先输入元素个数,并提交,再进行等价关系的添加,查找,合并,单步查找等操作,可以重复进行.7.系统测试用例元素个数16等价关系:1和3,5和7,3和5,2和8(每输入一组等价关系要点击提交按钮) 查找:7合并:7和8,2和88.收获及体会1)先做好规划,做好总体的设计,再开始写代码,这次写程序急着写,结果后来需要不断修改,延误了时间,代码也比较乱2)写代码一定要规范,变量声明,取名要统一,多添加注释3)遇到bug不要着急,更不能放弃,有些时候往往最简单的错误导致很难找的bug4)尽量地节省内存9.改进说明1)在演示区域的上方添加了说明来解释程序的动画2)当用户添加等价关系时会有对应的动画来显示添加的过程3)查找的文本框由开始的两个变为一个。

unionfind算法unionfind算法是一种用于解决动态连通性问题的算法,它的数据结构是一组以节点表示的数据集合,用于保存每个节点的父节点索引(有时也称为代表)。
unionfind算法使用一组连接来表示节点之间的关系,可以将不同节点连接在一起,也可以从两个节点之间断开连接。
unionfind算法最主要的操作是 Union(连接)和 Find(查找),它们可以用来检查两个节点是否连接,以及将不同的节点连接在一起。
unionfind算法是一种支持快速查找和连接的数据结构,用于动态解决连接问题,如寻找网络中所有连通分量、基于关键路径分析等。
unionfind算法可以帮助我们在不知道节点之间的具体联系下,快速地进行查找和连接。
unionfind算法的实现具有两个关键步骤:Find和Union,它们的功能分别是查找和连接。
具体而言,Find操作可以用来查找节点的父节点,如果两个节点的父节点是相同的,则说明两个节点是连通的;而Union操作则可以用来将两个节点连接起来。
unionfind算法也有自己的优点和不足之处。
它的优点在于,它可以有效地检查两个节点之间是否连通,以及将不同节点连接起来,可以显著缩短查找和连接的时间;而它的不足之处则是查询父节点的Find作可能会随着树的层数而变慢,且由于每次连接操作都要改变所有节点的父节点,因此union操作的时间复杂度也会随着树的层数而变高。
因此,要想有效利用 unionfind法,就必须要有良好的实现,并且需要考虑如何改进算法的时间复杂度,以提高效率。
例如,使用并查集结构时可以采用加权和路径压缩等优化算法,以提高unionfind运行效率。
总之,unionfind算法是一种非常有用的算法,它可以帮助我们在不知道节点之间具体的联系的情况下快速查找和连接节点,提高查找和连接的效率。
但unionfind算法也有它的不足之处,因此,如果要有效地利用它,就需要对算法进行相应的优化,以提高unionfind 算法的效率。
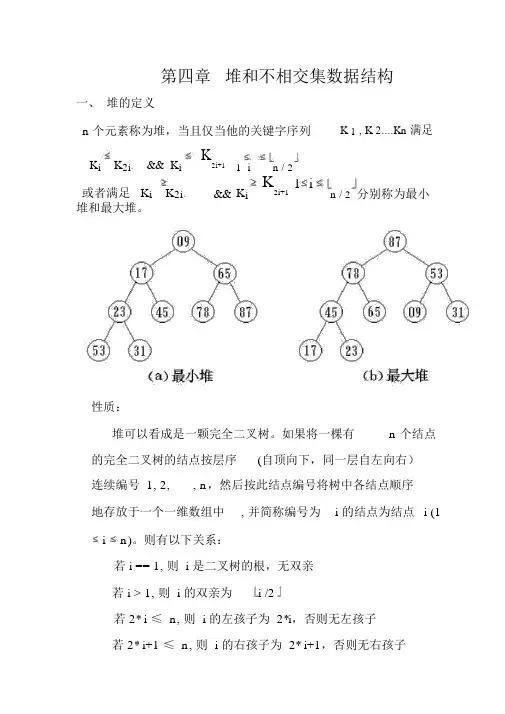
第四章堆和不相交集数据结构一、堆的定义n 个元素称为堆,当且仅当他的关键字序列K 1 , K 2....Kn 满足K i K2i。
&& K i K2i+1 1 i n / 2或者满足 K i K2i。
&&K i K2i+11 in / 2 分别称为最小堆和最大堆。
性质:堆可以看成是一颗完全二叉树。
如果将一棵有n 个结点的完全二叉树的结点按层序(自顶向下,同一层自左向右)连续编号 1, 2, , n,然后按此结点编号将树中各结点顺序地存放于一个一维数组中, 并简称编号为i 的结点为结点i (1i n)。
则有以下关系:若 i == 1, 则 i 是二叉树的根,无双亲若 i > 1, 则 i 的双亲为i /2若 2* i ≤ n, 则 i 的左孩子为 2*i,否则无左孩子若 2* i+1 ≤ n, 则 i 的右孩子为 2* i+1,否则无右孩子i 所在层次为log i +1若设二叉树的深度为h,则共有 h 层。
除第 h 层外,其它各层 (0 h-1)的结点数都达到最大个数,第h层从右向左连续缺若干结点具有n个结点的完全二叉树的深度为logn +1二、堆上运算在此考虑最大堆。
1.Sift-up: 把堆上的第i 个元素上移;2.Sift-down: 把堆上的第i 个元素下移;3.Insert: 把元素 x 插入堆中;4.Delete:删除堆中第i 个元素;5.删除最大元素6.Makeheap: 创建堆;7.Heapsort:对排序;1.过程Sift-up输入:数组H[1..n] 和位于 1 和 n 之间的索引i输出:上移 H[i](如果需要),以便使他不大于父结点(大堆)Done ← falseIf i=1 then exitRepeatIf key(H[i])>key(H i / 2 ) then 互换 H[i] 和 (H i / 2 elsedone ←truei←i / 2until i=1 or done例 :分析:执行时间O( logn) ,空间(1)2.过程Sift-down输入:数组H[1..n] 和位于 1 和 n 之间的索引i输出:下移H[i] (如果需要),以便使他不小于子结点Done ← falseIf 2i 〉 n then exit{节点是叶节点 }Repeati←2iIf If i+1 n andkey (H i / 2key(H[i+1])>key(H[i]))<key(H[i]) then互换(Hthen i←i+1i / 2 )和H[i]else done ←trueendifuntil 2i>n or done例 :分析:执行时间O( logn) ,空间(1)算法 4.1 insert思想:先插到最后,然后上移输入:堆 H[1..n] 和元素 x输出:新的堆H[1 n+1],x 为其元素之一1.n←n+1 {增加H的大小}2.H[n] ←x3.Sift-up(H,n)例 :分析:执行时间O( logn) ,空间(1)算法 4.2 delete思想:先将最后元素替代H[i] ,然后调整输入:非空堆 H[1..n] 和位于 1 和 n 之间的索引 i 输出:删除 H[i] 之后的新堆 H[1..n-1]1.x←H[i] ;y← H[n] ;2.n←n-1 {减小H的大小}3. if i=n+1 then exit {完成 }4.H[i] ←y5. if key(y)key(x) then sift-up(H,i)6.else Sift-down(H,i)7.end if例 :分析:执行时间O( logn) ,空间(1)deleteMAX输入:非空堆H[1..n]输出:返回最大键值元素x 并从堆中删除1.x←H[1]2.Delete(H,1)3.Return x创建堆n 个元素,连续方法一:假设从一个空堆开始,对数组中的地使用 insert 操作插入堆中。
并查集--学习详解文章作者:yx_th000文章来源:Cherish_yimi (/cherish_yimi/) 转载请注明,谢谢合作。
昨天和今天学习了并查集和trie树,并练习了三道入门题目,理解更为深刻,觉得有必要总结一下,这其中的内容定义之类的是取自网络,操作的说明解释及程序的注释部分为个人理解。
并查集学习:●并查集:(union-find sets)一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数等。
最完美的应用当属:实现Kruskar算法求最小生成树。
●并查集的精髓(即它的三种操作,结合实现代码模板进行理解):1、Make_Set(x) 把每一个元素初始化为一个集合初始化后每一个元素的父亲节点是它本身,每一个元素的祖先节点也是它本身(也可以根据情况而变)。
2、Find_Set(x) 查找一个元素所在的集合查找一个元素所在的集合,其精髓是找到这个元素所在集合的祖先!这个才是并查集判断和合并的最终依据。
判断两个元素是否属于同一集合,只要看他们所在集合的祖先是否相同即可。
合并两个集合,也是使一个集合的祖先成为另一个集合的祖先,具体见示意图3、Union(x,y) 合并x,y所在的两个集合合并两个不相交集合操作很简单:利用Find_Set找到其中两个集合的祖先,将一个集合的祖先指向另一个集合的祖先。
如图●并查集的优化1、Find_Set(x)时路径压缩寻找祖先时我们一般采用递归查找,但是当元素很多亦或是整棵树变为一条链时,每次Find_Set(x)都是O(n)的复杂度,有没有办法减小这个复杂度呢?答案是肯定的,这就是路径压缩,即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find_Set(x)时复杂度就变成O(1)了,如下图所示;可见,路径压缩方便了以后的查找。
简单不相交集的合并算法本节的假定前提:1、为算法书写方便起见,设任一集合都是{1,2,…n}的子集;2、任意两个被合并的集合都是不相交的;3、集合上的运算只有Union和Find。
Union(I,J,K):把名为I与J的集合进行合并,合并后的集合名为K。
∵初始总共有n个单元素集,故Union最多可执行n-1次。
Find(a):给出a所在的集合名(算法中大多用数字表示集合名)。
通常Find指令的执行也有O(n)次,故此类问题通常都是讨论执行O(n)条Union和Find指令所需要的时间。
可以用来表示集合的数据结构很多,用什么样的算法和结构才能使得完成上述任务的时间最少? Union(I,J,K) 算法中的数组说明为加快处理速度,每个集合给予一个内部名和一个外部名。
内部名与外部名1-1对应。
例如:External-Name[S]:内部名为S(数字)的集合所对应的外部名。
Internal-Name[L]:外部名为L(数字)的集合所对应的内部名。
R[i]:给出元素i所属集合的内部名。
(Find指令O(1)时间完成)Next[i]:给出与元素i同在一个集合中的下一个元素,内容为0时,表示无下一元素(即元素i是该集合的最后一个元素)。
List[S]:给出内部名为S的集合中的第一个元素。
Size[S]:给出内部名为S的集合中的元素个数。
1.A←Internal-Name[I]; /*将集合外部名I,J转为内部名A和B*/2.B←Internal-Name[J];3.wlg assume Size[A] ≤ Size[B] /* A为小集合,B为大集合*/4.otherwise interchange roles of A and B in5.{ELEMENT←List[A]; /*找出集合A的第一个元素*/6.while ELEMENT ≠ 0 do/*不断把A中元素的所在集合名改为B,直到全部改完为止*/7.{R[ELEMENT]←B; /*改名*/ST←ELEMENT; /*记下当前元素*/9.ELEMENT←Next[ELEMENT]; /*当前元素更新*/}/*循环结束时,LAST中记录了原集合A中的最后一个元素*/ 10.Next[LAST]←List[B];/*置该元素的下一个元素为原B中的第一个元素,*//*从而实现A和B的合并*/11.List[B]←List[A]; /*置合并后的首元素为原A中首元素*/12.Size[B]←Size[A] + Size[B];/*置集合大小为2集合的规模之和*/ 13.Internal-Name[K]←B;/*建立新集合的内部名与外部名的对应关系*/ 14.External-Name[B]←K} Union算法除6-9行以外,其余均为常数时间。
union-find抽象数据结构UNION - FIND算法是简单不相交集的合并算法。
在一些应用问题中,需要将n个不同的元素划分成若干组,每一组元素构成一个集合。
这种问题的---个解决办法是:开始时,让每个元素组成一个单元素集合,然后按一定顺序将属于同一组的元素所在集合合并,其间要反复用到查找--个元素在哪个集合的运算。
它涉及到的操作主要有UNION和FIND两种:UNION(S1,S2,S3)——-并操作,将集合S1与集合S2合并,形成新的集合S3;FIND(a)——搜索操作,搜索元素a所在的集合,并返回该集合的名字。
算法的复杂度是算法效率的度量,是评价算法优劣的重要依据。
一个算法的复杂度的高低体现在运行该算法所需要的计算机资源的多少上面,所需的资源越多,我们就说该算法的复杂度越高;反之,所需的资源越低,则该算法的复杂度越低。
计算机的资源,最重要的是时间和空间(即存储器)资源。
因而,算法的复杂度有时间复杂度和空间复杂度之分。
在这里,我们主要研究算法的时间复杂度,它是算法所求解问题规模n的函数。
UNION - FIND问题主要涉及到UNION和FIND 两种操作,解决该问题需要考虑的重要因素就是如何同时保证在最短时间内完成UNION 和FIND操作。
在UNION - FIND 算法设计中选择不同的数据结构和相应的优化策略,将直接影响算法执行的效率。
采用数组结构的算法设计与分析解决UNION - FIND问题可以选择最简单的数据结构——数组。
假设R是一个数组,用R[i]表示元素i所在的集合的名字。
开始时令每个元素所在的集合名字与元素名字相同,即,R[1 ] =1,R[ 2]=2,R[3] = 3,. . .... ,R[n] = n 。
执行FIND(i)操作非常方便,只需返回R[il的值即可。
执行n 条FIND操作只需O(n)时间。
但执行UNION(i,j、k )时,需要依次检查每个数组的下标变量的值,比较是否为i或j,若是i或j,则就将其下标变量改为k,即将R{i]和R[j]合并为R[k],如此执行一条UNION(i,j,k)操作就需要O(n)时间,从而执行n-1条UNION指令就需O(n)时间。
【转载】Union-Find算法详解【声明】本⽂转载⾃Union-Find 算法,也就是常说的并查集算法,主要是解决图论中「动态连通性」问题的。
问题描述简单说,动态连通性其实可以抽象成给⼀幅有 N 个结点的图连线,其中结点按 0~N 编号。
Union-Find 算法主要需要实现以下API:class UnionFind {public:/* 将 a 和 b 连接(连通) */void connect(int a, int b);/* 判断 a 和 b 是否连通 */bool isConnected(int a, int b);/* 返回图中的连通分量 */int getCount();}这⾥所说的「连通」是⼀种等价关系,也就是说具有如下三个性质:1、⾃反性:结点 a 和 a 是连通的。
2、对称性:如果结点 a 和 b 连通,那么 b 和 a 也连通。
3、传递性:如果结点 a 和 b 连通, b 和 c 连通,那么 a 和 c 也连通。
基本思路假定我们使⽤森林(若⼲棵树)来表⽰图的动态连通性,⽤数组来具体实现这个森林。
怎么⽤森林来表⽰连通性呢?我们设定树的每个节点有⼀个指针指向其⽗节点,如果是根节点的话,这个指针指向⾃⼰。
class UnionFind {public:UnionFind(int n);/* 将 a 和 b 连接(连通) */void connect(int a, int b);/* 判断 a 和 b 是否连通 */bool isConnected(int a, int b);/* 返回图中的连通分量 */int getCount() { return count; }private:/* 返回结点 x 的根节点 */int findRoot(int x);/** 其他函数 **/private:int count; // 连通分量vector<int> parent; // parent[i]: 结点 i 的⽗节点};如果某两个节点被连通,则让其中的(任意)⼀个节点的根节点接到另⼀个节点的根节点上:UnionFind::UnionFind(int n) : count(n) {// 初始时所有结点互不连通// ⽗节点指向⾃⼰for (int i = 0; i < n; ++i){parent.push_back(i);}}/* 判断 a 和 b 是否连通 */void UnionFind::connect(int a, int b) {int rootA = findRoot(a);int rootB = findRoot(b);if (rootA == rootB)return ;// 将⼀棵树接在另⼀棵树上parent[a] = rootB;// 连通分量 -1--count;}/* 判断 a 和 b 是否连通 */bool UnionFind::isConnected(int a, int b) {return findRoot(a) == findRoot(b);}/* 返回结点 x 的根节点 */int UnionFind::findRoot(int x) {// 根结点有 x == parent[x]while (x != parent[x])x = parent[x];return x;}我们发现,主要 API isConnected 和 connect 中的复杂度都是 findRoot 函数造成的,所以说它们的复杂度和 findRoot ⼀样。