结构方程模型入门
- 格式:ppt
- 大小:4.55 MB
- 文档页数:67

★结构方程模型要点一、结构方程模型的模型构成1、变量观测变量:能够观测到的变量(路径图中以长方形表示)潜在变量:难以直接观测到的抽象概念,由观测变量推估出来的变量(路径图中以椭圆形表示)内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图会受外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量;路中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他变量影响,还可能对其他变量产生影响。
内生潜在变量:潜变量作为内生变量内生观测变量:内生潜在变量的观测变量外生潜在变量:潜变量作为外生变量外生观测变量:外生潜在变量的观测变量中介潜变量:潜变量作为中介变量中介观测变量:中介潜在变量的观测变量2、参数(“未知”和“估计”)潜在变量自身:总体的平均数或方差变量之间关系:因素载荷,路径系数,协方差参数类型:自由参数、固定参数自由参数:参数大小必须通过统计程序加以估计固定参数:模型拟合过程中无须估计(1)为潜在变量设定的测量尺度①将潜在变量下的各观测变量的残差项方差设置为1②将潜在变量下的各观测变量的因子负荷固定为1(2)为提高模型识别度人为设定限定参数:多样本间比较(半自由参数)3、路径图(1)含义:路径分析的最有用的一个工具,用图形形式表示变量之间的各种线性关系,包括直接的和间接的关系。
(2)常用记号:①矩形框表示观测变量②圆或椭圆表示潜在变量③小的圆或椭圆,或无任何框,表示方程或测量的误差单向箭头指向指标或观测变量,表示测量误差单向箭头指向因子或潜在变量,表示内生变量未能被外生潜在变量解释的部分,是方程的误差④单向箭头连接的两个变量表示假定有因果关系,箭头由原因(外生)变量指向结果(内生)变量⑤两个变量之间连线的两端都有箭头,表示它们之间互为因果⑥弧形双箭头表示假定两个变量之间没有结构关系,但有相关关系⑦变量之间没有任何连接线,表示假定它们之间没有直接联系(3)路径系数含义:路径分析模型的回归系数,用来衡量变量之间影响程度或变量的效应大小(标准化系数、非标准化系数)类型:①反映外生变量影响内生变量的路径系数②反映内生变量影响内生变量的路径系数路径系数的下标:第一部分所指向的结果变量第二部分表示原因变量(4)效应分解①直接效应:原因变量(外生或内生变量)对结果变量(内生变量)的直接影响,大小等于原因变量到结果变量的路径系数②间接效应:原因变量通过一个或多个中介变量对结果变量所产生的影响,大小为所有从原因变量出发,通过所有中介变量结束于结果变量的路径系数乘积③总效应:原因变量对结果变量的效应总和总效应=直接效应+间接效应4、矩阵方程式(1)和(2)是测量模型方程,(3)是结构模型方程 测量模型:反映潜在变量和观测变量之间的关系 结构模型:反映潜在变量之间因果关系 5x x ξδ=∧+ (1)y y ηε=∧+ (2) B ηηξζ=+Γ+ (3)三、模型修正1、参考标准模型所得结果是适当的;所得模型的实际意义、模型变量间的实际意义和所得参数与实际假设的关系是合理的;参考多个不同的整体拟合指数;2、修正原则①省俭原则两个模型拟合度差别不大的情况下,应取两个模型中较简单的模型;拟合度差别很大,应采取拟合更好的模型,暂不考虑模型的简洁性;最后采用的模型应是用较少参数但符合实际意义,且能较好拟合数据的模型。
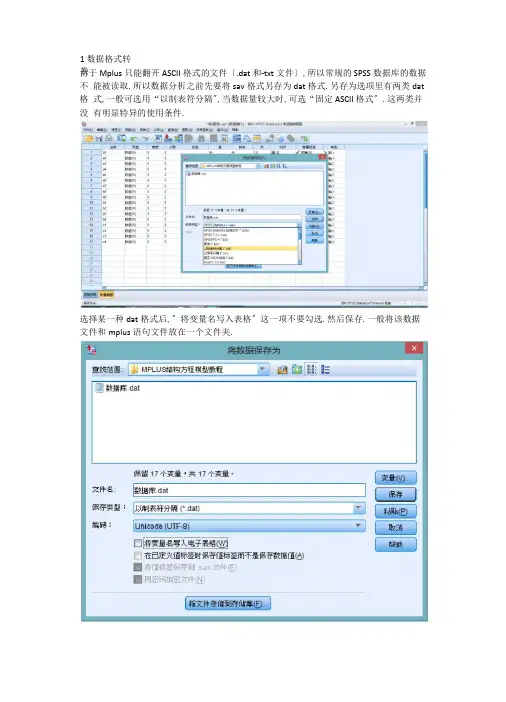
1数据格式转换由于Mplus只能翻开ASCII格式的文件〔.dat 和-txt文件〕,所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式.另存为选项里有两类dat 格式,一般可选用“以制表符分隔",当数据量较大时,可选“固定ASCII格式〞.这两类并没有明显特异的使用条件.选择某一种dat格式后,〞将变量名写入表格〞这一项不要勾选.然后保存.一般将该数据文件和mplus语句文件放在一个文件夹.2翻开mplus程序,建立新文件,即点击“new〞.当然,新翻开Mplus程序也会默认这个界面.3编辑命令.这是Mplus分析数据最核心的步骤3.1首先我们可以给该分析起个名字〔该步骤可有可无〕,例如:TITLE: example3.2然后说明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件.命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS 结构方程模型教程'数据库.dat;这里面需要注意的是:DATA: FILE IS 〔或者DATA: FILE=〕是固定句式,是必要的.之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程'数据库.dat〞这是DAT文件的保存路径.一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE IS数据库.dat;但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的.另外,一个命令结束后,必须必须加上“;〞即英文格式下的分号〔除外TITLE〕.3.3写出数据库中所有的变量名称以及本次分析需要的变量名称.这需要根据spss数据库中变量名称顺序来写.VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最根本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格.由于我们本次分析需要纳入该数据库所有变量,所以上下两行变量是一样的,否那么需要哪些变量,在USEVARIABLES里面纳入哪些变量.3.4分析方法由于MPLUS中针对连续型变量的结构方程模型的默认分析方法是最小二乘法即ML,所以如果使用的方法是这个,那么分析方法语句可以不写,当然也可以写,即ANALYSIS: ESTIMATOR = ML;如果采用其他方法,需要写出来,例如ANALYSIS: ESTIMATOR = MLR;或者ANALYSIS: ESTIMATOR = WLSMV;另外ANALYSIS中还有TYPE语句,MODEL语句,INFORMATION语句,如果没有特殊要求, 我们就根据Mplus的默认方式分析就可,故不用写出来.如果分析采用其他方式,那么需要写出来.命令举例:ANALYSIS: ESTIMATOR = ML; TYPE = GENERAL;MODEL=NOMEANSTRUCTURE; INFORMATION=EXPECTED;3.5模型语句比方我们预期的结构方程模型是这样的:首先我们要将各个观测变量使用“BY〞合并得出三个潜变量,也就是我们研究的自变量y2, 中介变量y1,和因变量y3.语句为:MODEL: y1 BY a1-a9;y2 BY b1-b4;y3 BY c1-c4;然后使用“ON〞来表示各潜变量之间的回归关系,即:y3 ON y1 y2;y1 ON y2;ON前面的是结局变量,后面的是预测变量.所以模型语句合并起来就是:MODEL: y1 BY a1-a9;y2 BY b1-b4;y3 BY c1-c4;y3 ON y1 y2;y1 ON y2;3.6最后一步是输出语句,如果没有特殊要求,我们需要的结构Mplus的默认程序都会呈现. 如果有特殊要求也可以写出来,例如:OUTPUT: SAMPSTAT TECH1 TECH4 STDYX MOD;所以将所有语句写出来就是:TITLE: exampleDATA: FILE IS C:\Users\dell\Desktop\MPLUS 结构方程模型教程'数据库.dat; VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4; MODEL: y1 BY a1-a9;y2 BY b1-b4;y3 BY c1-c4;y3 ON y1 y2;y1 ON y2;如图Mplus - [MptextlJ 药File Edit Wst Mplus Plot Diagr^rrii Windw Help口0 口;制剧善闻|凹坦回|巴 |如国园|小〈国圄| 7-TITLE, exanpleHATA- FILE IS C:培构方程植用强程;俄据反"共:UAKIAiLE: MANE3 IRE a]湛a3 a4 a5 a7 曲酬bL b2 b3 bd. cl c2 c3 3;VSEVAKIAflLES ARES AEE ZL!a2 a4 a5 a7 sB bl bE b3 b4 cl C2凸3;IKiBEL- yl B¥支BY b1-b4;y3 SY C]-E4;y:3 Off yl y2:yl ON y2 t然后点击RUN按钮它会提示你保存该语句保存完成后,结果就出来了.eK :urLpleSU1WAEY OF WITSIS Ni-unber of g roupsNumber of observationsNumber of defiendeirt. variables Number of independent. variablesNunb e r of cont iiiuiiiUE 1 1 at. ent var i ab 19 sEstiiTLatorInfurnation matrixMaximum number of iterations Convergence criterionMazimiiiTL iiLuribe r of st-eepest- descent it er at-ionsInput data file (s)C: XUsers'\del 1\Desktop\,MPLUS 结构方程模型救程 ’\数据库,datInput- data format- FREETHE MODEL ESTIMTION TEMINATED NOFJ1U1LLY(MODEL FIT INFOBJ I UTIONNuitber of Free Parameters5d52 4A B ContimiLiUEAl A2 门Ad A7 A8 A9 El E4 ClC2C3ontmuous latent v ariablesY1Y2叮bserved dependent variables如果想看我们得到的结构方程图的话,点击菜单栏的Diagram ,选择View diagram■ 1 File Edit View Mplus Plot Diagram Window HelpView diagramAlt+ DOpen Di a g rammer这需要JAVA 工具.如果电脑没有的话,会提示你安装安装完,既可以观看图示.1 2967 _uNL OBSERVEDinrn| 0.500D-C420RU Edit Mpkit Vim Diagram Mridow Help4"< 岭-«| U k、i DOQ(OQD:I】叫叫一f j112 5T4($54)\ /M3以y—I47阿/ '咏m)一>3厂1__14?57<P25)/X d 卜,5»(1W>1 174(,3101 0X( DOD:. |IJ C L—27«(ZTO) -、/一、/」gpl?11人… /人工嬴(二?\<nx. LIT、Z *—:3W(3J)I<310( 9«(0«).3 814c必“】为< »1)7 157( l»>2J73( 2]Q>3 皿力啦MRUaP3WC训387(加]319( CU J 157020。





结构方程这几年热度不减,有必要研究一下它的R语言实现过程,今天先复习一下结构方程的相关理论,参考吉林大学余翠林的ppt一、为什么使用SEM?1、回归分析有几方面的限制:(1)不允许有多个因变量或输出变量(2)中间变量不能包含在与预测因子一样的单一模型中(3)预测因子假设为没有测量误差(4)预测因子间的多重共线性会妨碍结果解释(5)结构方程模型不受这些方面的限制2、S EM的优点:(1)SEM程序同时提供总体模型检验和独立参数估计检验;(2)回归系数,均值和方差同时被比较,即使多个组间交叉;(3)验证性因子分析模型能净化误差,使得潜变量间的关联估计较少地被测量误差污染;(4)拟合非标准模型的能力,包括灵活处理追踪数据,带自相关误差结构的数据库(时间序列分析),和带非正态分布变量和缺失数据的数据库。
3、结构方程模型最为显著的两个特点是:(1)评价多维的和相互关联的关系;(2)能够发现这些关系中没有察觉到的概念关系,而且能够在评价的过程中解释测量误差。
同时具有联系信息技术吸纳能力:SEM能够反映模型中要素之间的相互影响;吸纳能力概念作为一个重要的模型要素,难以直接度量,结构方程模型技术能够更为充分地体现其蕴含的要素信息和影响作用。
二、SEM的基本思想与方法SEM是基于变量的协方差矩阵来分析变量之间关系的一种统计方法,实际上是一般线性模型的拓展,包括因子模型与结构模型,体现了传统路径分析与因子分析的完美结合。
SEM 一般使用最大似然法估计模型(Maxi-Likeliheod , ML)分析结构方程的路径系数等估计值,因为ML法使得研究者能够基于数据分析的结果对模型进行修正。
1、SEM术语(1 )观测变量可直接测量的变量,通常是指标(2)潜变量潜变量亦称隐变量,是无法直接观测并测量的变量。
潜变量需要通过设计若干指标间接加以测量。
(3)外生变量是指那些在模型或系统中,只起解释变量作用的变量。
它们在模型或系统中,只影响其他变量,而不受其他变量的影响。

结构方程模型知识点总结一、SEM的基本概念1.1 潜变量和观察变量SEM中的变量分为潜变量和观察变量两种。
潜变量是无法直接观测到的,但通过观察变量的测量可以间接反映出来的变量,比如抽象的概念、态度或行为。
观察变量是可以直接测量和观察到的变量,它通过对潜变量的测量可以间接反映出来的现象或特征。
1.2 路径图和模型图SEM通过路径图和模型图来表示变量之间的关系。
路径图用箭头表示变量之间的因果关系,箭头的方向表示因果关系的方向,箭头的粗细表示因果关系的强度。
模型图将观察到的变量和潜变量以及它们之间的关系用图形化的方式表达出来。
1.3 测量模型和结构模型SEM包括测量模型和结构模型两个部分。
测量模型用于描述观察变量和潜变量之间的关系,它通过因子分析或确认因素分析来检验观察变量和潜变量之间的关系。
结构模型用于描述潜变量之间的因果关系,它通过路径分析来检验和估计潜变量之间的因果关系。
1.4 模型拟合度和参数估计SEM通过拟合度指标(比如χ²值、RMSEA、CFI等)来检验模型的拟合程度。
拟合度指标可以用来评估模型对观测数据的解释程度。
参数估计则是用来估计模型中的参数,比如路径系数、测量误差和因子之间的协方差等。
二、SEM的应用领域2.1 社会科学研究在社会科学研究中,SEM广泛应用于心理学、教育学、管理学、政治学等领域。
研究者可以利用SEM来检验和估计变量之间的因果关系,比如影响人们行为的因素、组织管理的影响因素等。
2.2 经济学研究在经济学研究中,SEM可以用来检验和估计宏观经济模型或微观经济模型。
研究者可以利用SEM来分析不同变量之间的关系,比如GDP和通货膨胀之间的关系、利率变动对企业盈利的影响等。
2.3 公共卫生研究在公共卫生研究中,SEM可以用来检验和估计潜变量之间的关系,比如疾病和环境因素之间的关系、健康行为和健康状况之间的关系等。
研究者可以利用SEM来揭示潜在的影响因素,从而提出有效的干预措施。
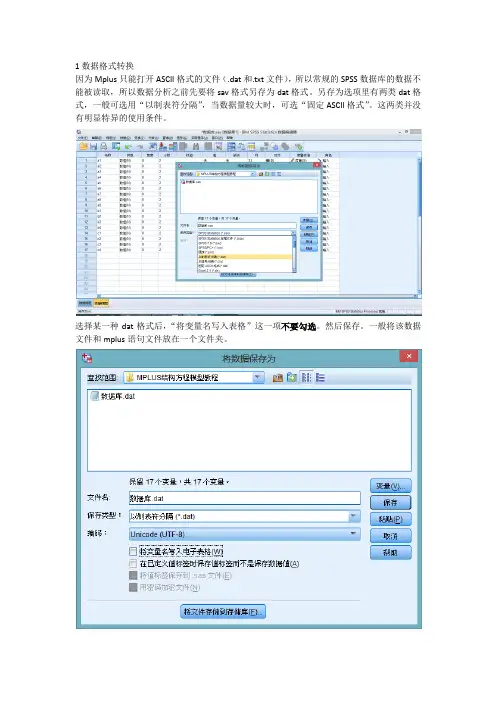
1数据格式转换因为Mplus只能打开ASCII格式的文件(.dat和.txt文件),所以常规的SPSS数据库的数据不能被读取,所以数据分析之前先要将sav格式另存为dat格式。
另存为选项里有两类dat格式,一般可选用“以制表符分隔”,当数据量较大时,可选“固定ASCII格式”。
这两类并没有明显特异的使用条件。
选择某一种dat格式后,“将变量名写入表格”这一项不要勾选。
然后保存。
一般将该数据文件和mplus语句文件放在一个文件夹。
2 打开mplus程序,建立新文件,即点击“new”。
当然,新打开Mplus程序也会默认这个界面。
3 编辑命令。
这是Mplus分析数据最核心的步骤3.1 首先我们可以给该分析起个名字(该步骤可有可无),例如:TITLE: example3.2 然后表明我们引用的数据库来自于哪里,也就是刚刚那个DAT文件。
命令为:DATA: FILE IS C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat;这里面需要注意的是:DATA: FILE IS (或者DATA: FILE=)是固定句式,是必要的。
之后“C:\Users\dell\Desktop\MPLUS结构方程模型教程\数据库.dat”这是DAT文件的保存路径。
一般情况下,如果mplus语句文件和dat文件在同一个文件夹中,只需要DATA: FILE IS数据库.dat; 但实际上很多情况下,两者即使在同一个文件中,也很可能读不出来,所以必要的话,可将该DAT文件的保存路径写全,这样肯定是没错的。
另外,一个命令结束后,必须必须加上“;”即英文格式下的分号(除外TITLE)。
3.3 写出数据库中所有的变量名称以及本次分析需要的变量名称。
这需要按照spss数据库中变量名称顺序来写。
VARIABLE: NAMES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;USEVARIABLES ARES ARE a1 a2 a3 a4 a5 a6 a7 a8 a9 b1 b2 b3 b4 c1 c2 c3 c4;当然这是最基本繁琐的写法,可以直接写为:VARIABLE: NAMES ARE a1-a9 b1-b4 c1-c4;USEVARIABLES ARES ARE a1-a9 b1-b4 c1-c4;不同变量间有空格。


结构⽅程模型⼊门(纯⼲货!)⼀、结构⽅程模型的概念结构⽅程模型(Structural Equation Model,简称SEM)是基于变量的协⽅差矩阵来分析变量之间关系的⼀种统计⽅法,因此也称为协⽅差结构分析。
结构⽅程模型属于多变量统计分析,整合了因素分析与路径分析两种统计⽅法,同时可检验模型中的显变量(测量题⽬)、潜变量(测量题⽬表⽰的含义)和误差变量直接按的关系,从⽽活动⾃变量对因变量影响的直接效果、间接效果和总效果。
结构⽅程模型基本上是⼀种验证性的分析⽅法,因此通常需要有理论或者经验法则的⽀持,根据理论才能构建假设的模型图。
在构建模型图之后,检验模型的拟合度,观察模型是否可⽤,同时还需要检验各个路径是否达到显著,以确定⾃变量对因变量的影响是否显著。
⽬前,结构⽅程模型的分析软件较多,如Lisrel、EQS、Amos、Mplus、 Smartpls等等,其中AMOS 的使⽤率甚⾼,因此我们重点了解⼀下使⽤AMOS软件进⾏结构⽅程模型分析的过程。
⼆、结构⽅程模型的相关概念在构建模型假设图,我们⾸先需要了解⼀些有关的基本概念1、显变量显变量有多种称呼,如“观察变量”、“测量变量”、“显性变量”、“观测变量”等等。
从这些称呼中可以看到,显变量的主要含义就是:变量是实际测量的内容,也就是我们问卷上⾯的题⽬。
在Amos中,显变量使⽤长⽅形表⽰。
2、潜变量潜变量也叫潜在变量,是⽆法直接测量,但是可以通过多个题⽬进⾏表⽰的变量。
在Amos中,潜变量使⽤椭圆表⽰。
在使⽤的过程中,我们可以通过这样的⽅式区分显变量和潜变量:在数据⽂件中有具体值的变量就是显变量,没有具体值但可通过多个题⽬表⽰的则是潜变量。
3、误差变量误差变量是不具有实际测量的变量,但必不可少。
在调查中,显变量不可能百分之百的解释潜变量,总会存在误差,这反映在结构⽅程模型中就是误差变量,每⼀个显变量都会有误差变量。
在Amos 中,误差变量使⽤圆形进⾏表⽰(与潜变量类似)。
结构方程模型的原理与应用一、什么是结构方程模型•结构方程模型(Structural Equation Modeling,简称SEM)是一种多变量统计方法,用于分析观测变量之间的关系以及变量与潜变量之间的关系。
•SEM通过建立数学模型来描述变量之间的关系,并基于数据对模型进行拟合和评估。
它可以帮助研究者探索和解释变量之间的复杂关系,以及验证理论模型是否与实际数据一致。
二、结构方程模型的基本原理•结构方程模型由测量模型和结构模型组成。
测量模型用于描述潜变量与观测变量之间的关系,结构模型则描述了变量之间的因果关系。
•在测量模型中,潜变量是无法直接观测到的,而观测变量是可以被测量到的。
通过观测变量与潜变量之间的关系,可以推断潜变量的存在和性质。
•结构模型描述了变量之间的因果关系,包括直接效应和间接效应。
直接效应表示一个变量对另一个变量的直接影响,而间接效应表示通过其他变量中介作用的影响。
•结构方程模型的参数可以使用最大似然估计或者最小二乘估计来进行估计。
估计得到的参数可以用于验证理论模型是否与实际数据拟合良好。
三、结构方程模型的步骤1.模型规范化:确定潜变量和观测变量,并选择合适的测量指标。
2.建立测量模型:通过测量指标与潜变量之间的关系建立测量模型。
3.建立结构模型:根据理论假设或先验知识,建立变量之间的结构模型。
4.模型拟合:对建立的模型进行拟合,通过比较实际数据和模型估计值,评估模型的拟合度。
5.参数估计:使用最大似然估计或最小二乘估计方法,对模型参数进行估计。
6.模型诊断:通过模型拟合度指标,对模型的各项指标进行诊断,判断模型是否合理。
7.模型修正:如果模型拟合不好,可以对模型进行修正,使用修正指数修正模型。
四、结构方程模型的应用•结构方程模型广泛应用于社会科学研究和教育评估领域。
下面列举一些常见的应用场景:1.教育研究:结构方程模型可以用于研究教育因素对学生学业成绩的影响,分析各个因素之间的关系,以及评估教育政策的有效性。
结构方程模型讲义结构方程模型(Structural Equation Modeling,SEM)是一种统计分析方法,多用于研究基于潜变量的复杂系统内在结构的定量关系。
其理论基础源于多元统计分析、因子分析和路径分析,通过建立观察变量与潜变量之间的关系模型,解析出潜变量对观察变量的影响,进而研究变量之间的内在结构关系。
一、SEM的基本概念和特点1.潜变量:潜变量是指无法直接观察或测量的变量,只能通过观察变量来间接反映。
它可以代表一些理论上的构念、心理特质或潜在特征。
2.观察变量:观察变量是可以直接观察和测量的变量,表现为定量或定性的实际测量结果。
3.模型设定:SEM基于研究者对潜变量和观察变量之间关系的理论假设,通过建立潜变量和观察变量之间的关系模型,定量研究变量之间的影响关系。
4.结构关系:SEM通过路径系数来描述潜变量和观察变量之间的关系,并使用结构方程模型来表示这些关系。
路径系数表示了变量之间的直接或间接影响。
二、结构方程模型的步骤1.模型设定:根据研究目的和理论依据,建立潜变量和观察变量之间的关系模型,并确定模型中的指标、因子和路径。
2.数据收集:收集样本数据,并根据所设定的模型变量进行测量,获得观察变量的观测值。
3.模型估计:利用SEM软件,通过最大似然估计等方法求解模型中的参数估计值,包括路径系数、因子载荷和误差项。
4.模型拟合:通过拟合度指标对模型的拟合程度进行评估,检验模型是否与观测数据一致。
如果拟合不理想,可能需要修改或调整模型。
5.结果解释和修正:对模型结果进行解释,解释模型中的路径系数和因子载荷,以及观察变量的解释力。
如果有必要,根据拟合结果调整模型,并进行相应修正。
6.结果验证:通过交叉验证、重测等方法验证模型的鲁棒性和稳定性,确保模型结果的可靠性和稳定性。
结构方程模型的应用领域非常广泛,包括心理学、社会学、教育学、市场营销、财务管理等。
它可以用于研究因果关系、探究复杂系统内在结构、验证理论模型等。