最优二叉搜索树
- 格式:ppt
- 大小:422.00 KB
- 文档页数:51

#include<stdio.h>#include<stdlib.h>#define max 9999void OptimalBST(int,float*,float**,int**);void OptimalBSTPrint(int,int,int**);void main(){int i,num;FILE *point;//所有数据均从2.txt中获取,2.txt中第一个数据表示节点个数;从第二个数据开始表示各个节点的概率point=fopen("2.txt","r");if(point==NULL){printf("cannot open 2.txt.\n");exit(-1);}fscanf(point,"%d",&num);printf("%d\n",num);float *p=(float*)malloc(sizeof(float)*(num+1));for(i=1;i<num+1;i++)fscanf(point,"%f",&p[i]);//创建主表;float **c=(float**)malloc(sizeof(float*)*(num+2));for(i=0;i<num+2;i++)c[i]=(float*)malloc(sizeof(float)*(num+1));//创建根表;int **r=(int**)malloc(sizeof(int*)*(num+2));for(i=0;i<num+2;i++)r[i]=(int*)malloc(sizeof(int)*(num+1));//动态规划实现最优二叉查找树的期望代价求解。
OptimalBST(num,p,c,r);printf("该最优二叉查找树的期望代价为:%f \n",c[1][num]);//给出最优二叉查找树的中序遍历结果;printf("构造成的最优二叉查找树的中序遍历结果为:");OptimalBSTPrint(1,4,r);}void OptimalBST(int num,float*p,float**c,int**r){int d,i,j,k,s,kmin;float temp,sum;for(i=1;i<num+1;i++)//主表和根表元素的初始化{c[i][i-1]=0;c[i][i]=p[i];r[i][i]=i;}c[num+1][num]=0;for(d=1;d<=num-1;d++)//加入节点序列{for(i=1;i<=num-d;i++){j=i+d;temp=max;for(k=i;k<=j;k++)//找最优根{if(c[i][k-1]+c[k+1][j]<temp){temp=c[i][k-1]+c[k+1][j];kmin=k;}}r[i][j]=kmin;//记录最优根sum=p[i];for(s=i+1;s<=j;s++)sum+=p[s];c[i][j]=temp+sum;}}}//采用递归方式实现最优根的输出,最优根都是保存在r[i][j]中的。
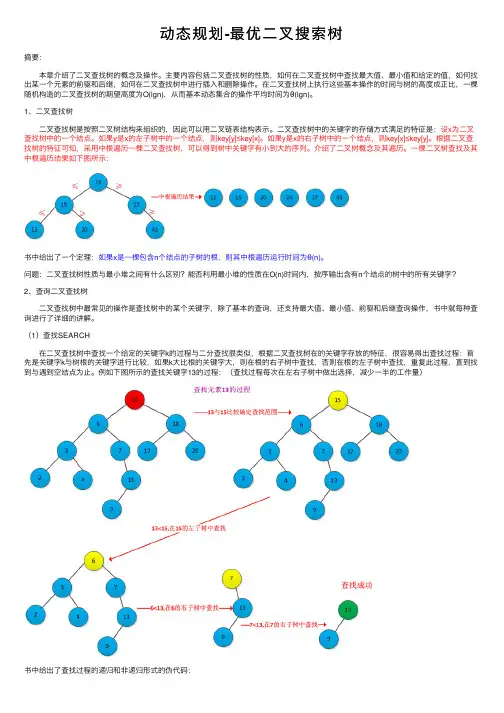
动态规划-最优⼆叉搜索树摘要: 本章介绍了⼆叉查找树的概念及操作。
主要内容包括⼆叉查找树的性质,如何在⼆叉查找树中查找最⼤值、最⼩值和给定的值,如何找出某⼀个元素的前驱和后继,如何在⼆叉查找树中进⾏插⼊和删除操作。
在⼆叉查找树上执⾏这些基本操作的时间与树的⾼度成正⽐,⼀棵随机构造的⼆叉查找树的期望⾼度为O(lgn),从⽽基本动态集合的操作平均时间为θ(lgn)。
1、⼆叉查找树 ⼆叉查找树是按照⼆叉树结构来组织的,因此可以⽤⼆叉链表结构表⽰。
⼆叉查找树中的关键字的存储⽅式满⾜的特征是:设x为⼆叉查找树中的⼀个结点。
如果y是x的左⼦树中的⼀个结点,则key[y]≤key[x]。
如果y是x的右⼦树中的⼀个结点,则key[x]≤key[y]。
根据⼆叉查找树的特征可知,采⽤中根遍历⼀棵⼆叉查找树,可以得到树中关键字有⼩到⼤的序列。
介绍了⼆叉树概念及其遍历。
⼀棵⼆叉树查找及其中根遍历结果如下图所⽰:书中给出了⼀个定理:如果x是⼀棵包含n个结点的⼦树的根,则其中根遍历运⾏时间为θ(n)。
问题:⼆叉查找树性质与最⼩堆之间有什么区别?能否利⽤最⼩堆的性质在O(n)时间内,按序输出含有n个结点的树中的所有关键字?2、查询⼆叉查找树 ⼆叉查找树中最常见的操作是查找树中的某个关键字,除了基本的查询,还⽀持最⼤值、最⼩值、前驱和后继查询操作,书中就每种查询进⾏了详细的讲解。
(1)查找SEARCH 在⼆叉查找树中查找⼀个给定的关键字k的过程与⼆分查找很类似,根据⼆叉查找树在的关键字存放的特征,很容易得出查找过程:⾸先是关键字k与树根的关键字进⾏⽐较,如果k⼤⽐根的关键字⼤,则在根的右⼦树中查找,否则在根的左⼦树中查找,重复此过程,直到找到与遇到空结点为⽌。
例如下图所⽰的查找关键字13的过程:(查找过程每次在左右⼦树中做出选择,减少⼀半的⼯作量)书中给出了查找过程的递归和⾮递归形式的伪代码:1 TREE_SEARCH(x,k)2 if x=NULL or k=key[x]3 then return x4 if(k<key[x])5 then return TREE_SEARCH(left[x],k)6 else7 then return TREE_SEARCH(right[x],k)1 ITERATIVE_TREE_SEARCH(x,k)2 while x!=NULL and k!=key[x]3 do if k<key[x]4 then x=left[x]5 else6 then x=right[x]7 return x(2)查找最⼤关键字和最⼩关键字 根据⼆叉查找树的特征,很容易查找出最⼤和最⼩关键字。

最优二叉搜索树问题经典练习题分类汇编
问题概述
最优二叉搜索树问题是一种经典的算法问题,涉及确定一个有序数列中的某些元素构成的二叉搜索树,使得其查找效率最高。
本文档旨在为您提供一些经典的练题分类汇编,帮助您更好地理解和解决最优二叉搜索树问题。
分类汇编
基础题目
1.问题描述:给定一组有序数列和每个元素的查找成功概率,求构建一棵二叉搜索树的最均查找时间。
2.相关算法:动态规划算法、递归算法。
进阶题目
1.问题描述:给定一组连续有序的数列和每个元素的权重,求构建一棵二叉搜索树的最均查找时间。
2.相关算法:动态规划算法、递归算法。
其他应用题目
1.问题描述:给定一组非有序的元素和其出现的频率,求构建一棵二叉搜索树的最均查找时间。
2.相关算法:动态规划算法、递归算法。
结论
最优二叉搜索树问题是一个重要且常见的算法问题,通过运用动态规划和递归算法,我们可以求解最优二叉搜索树的构建。
本文档提供了一些经典的练题分类汇编,希望能帮助您更好地掌握这个问题,并应用于实际场景中。

介绍二叉排序树的结构和特点二叉排序树,也称为二叉搜索树或二叉查找树,是一种特殊的二叉树结构,其主要特点是左子树上的节点都小于根节点,右子树上的节点都大于根节点。
在二叉排序树中,每个节点都存储着一个关键字,而且所有的关键字都不相同。
二叉排序树的结构如下:1.根节点:二叉排序树的根节点是整个树的起始点,其关键字是最大的。
2.左子树:根节点的左子树包含着小于根节点关键字的所有节点,且左子树本身也是一个二叉排序树。
3.右子树:根节点的右子树包含着大于根节点关键字的所有节点,且右子树本身也是一个二叉排序树。
二叉排序树的特点如下:1.有序性:二叉排序树的最重要特点是有序性。
由于左子树上的节点都小于根节点,右子树上的节点都大于根节点,所以通过中序遍历二叉排序树,可以得到一个有序的序列。
2.快速查找:由于二叉排序树是有序的,所以可以利用二叉排序树进行快速查找操作。
对于给定的关键字,可以通过比较关键字与当前节点的大小关系,逐步缩小查找范围,最终找到目标节点。
3.快速插入和删除:由于二叉排序树的有序性,插入和删除操作比较简单高效。
插入操作可以通过比较关键字的大小关系,找到合适的位置进行插入。
删除操作可以根据不同情况,分为三种情况处理:删除节点没有子节点、删除节点只有一个子节点和删除节点有两个子节点。
4.可以用于排序:由于二叉排序树的有序性,可以利用二叉排序树对一组数据进行排序。
将数据依次插入二叉排序树中,然后再通过中序遍历得到有序序列。
二叉排序树的优缺点如下:1.优点:(1)快速查找:通过二叉排序树可以提供快速的查找操作,时间复杂度为O(log n)。
(2)快速插入和删除:由于二叉排序树的有序性,插入和删除操作比较简单高效。
(3)可以用于排序:通过二叉排序树可以对一组数据进行排序,时间复杂度为O(nlog n)。
2.缺点:(1)受数据分布影响:如果数据分布不均匀,可能导致二叉排序树的高度增加,从而降低了查找效率。
(2)不适合大规模数据:对于大规模数据,二叉排序树可能会导致树的高度过高,从而影响了查找效率。

最优⼆叉搜索树背景:语⾔翻译,从英语到法语,对于给定的单词在单词表⾥找到该词⽅法:创建⼀棵⼆叉搜索树,以英语单词作为关键字构建树⽬标:尽快地找到英语单词,使总的搜索时间尽量少思路:频繁使⽤的单词,如the应尽可能的靠近根;⽽不经常出现的单词可以离根远⼀点前提假设:所有元素互异⼀些定义:⼆叉搜索树⼆叉搜索树T是⼀棵⼆元树,它或者为空,或者其每个结点含有⼀个可以⽐较⼤⼩的数据元素,且有:T的左⼦树的所有元素⽐根结点中的元素⼩;T的右⼦树的所有元素⽐根结点中的元素⼤;T的左⼦树和右⼦树也是⼆叉搜索树。
最优⼆叉搜索树给定含有n个关键字的已排序的序列K=<k1,k2,…,k n>(不失⼀般性,设k1<k2<…<k n),对每个关键字k i,都有⼀个概率p i表⽰其被搜索的频率。
根据k i和p i构建⼀个⼆叉搜索树T,每个k i对应树中的⼀个结点。
搜索对象x,在T中可能找到、也可能找不到:若x等于某个k i,则⼀定可以在T中找到结点k i,称为成功搜索。
成功搜索的情况⼀共有n种,分别是x恰好等于某个k i。
若x<k1或x>k n或k i<x<k i+1(1≤i<n), 则在T中搜索x将失败,称为失败搜索。
为此引⼊外部结点d0,d1,...,d n,⽤来表⽰不在K中的值,称为伪关键字。
伪关键字在T中对应外部结点,共有n+1个。
—扩展⼆叉树:内结点表⽰关键字k i,外结点(叶⼦结点)表⽰d i这⾥每个d i代表⼀个区间。
d0表⽰所有⼩于k1的值,d n表⽰所有⼤于k n的值,对于i=1,…,n−1,d i表⽰所有在k i和k i+1之间的值。
每个d i也有⼀个概率表⽰搜索对象x恰好落q i⼊区间d i的频率。
⼆叉搜索树的期望搜索代价⼀次搜索的代价等于从根结点开始访问结点的数量(包括外部结点)。
从根结点开始访问结点的数量等于结点在T中的深度+1。
记depth T(i)为结点i在T中的深度。

最优二叉树概念1.树的路径长度树的路径长度是从树根到树中每一结点的路径长度之和。
在结点数目相同的二叉树中,完全二叉树的路径长度最短。
2.树的带权路径长度(Weighted Path Length of Tree,简记为WPL)结点的权:在一些应用中,赋予树中结点的一个有某种意义的实数。
结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。
树的带权路径长度(Weighted Path Length of Tree):定义为树中所有叶结点的带权路径长度之和,通常记为:其中:n表示叶子结点的数目w i和l i分别表示叶结点k i的权值和根到结点k i之间的路径长度。
树的带权路径长度亦称为树的代价。
3.最优二叉树或哈夫曼树在权为w l,w2,…,w n的n个叶子所构成的所有二叉树中,带权路径长度最小(即代价最小)的二叉树称为最优二叉树或哈夫曼树。
【例】给定4个叶子结点a,b,c和d,分别带权7,5,2和4。
构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为:(a)WPL=7*2+5*2+2*2+4*2=36(b)WPL=7*3+5*3+2*1+4*2=46(c)WPL=7*1+5*2+2*3+4*3=35其中(c)树的WPL最小,可以验证,它就是哈夫曼树。
注意:①叶子上的权值均相同时,完全二叉树一定是最优二叉树,否则完全二叉树不一定是最优二叉树。
②最优二叉树中,权越大的叶子离根越近。
③最优二叉树的形态不唯一,WPL最小。
哈夫曼算法哈夫曼首先给出了对于给定的叶子数目及其权值构造最优二叉树的方法,故称其为哈夫曼算法。
其基本思想是:(1)根据给定的n个权值w l,w2,…,w n构成n棵二叉树的森林F={T1,T2,…,T n},其中每棵二叉树T i中都只有一个权值为w i的根结点,其左右子树均空。
(2)在森林F中选出两棵根结点权值最小的树(当这样的树不止两棵树时,可以从中任选两棵),将这两棵树合并成一棵新树,为了保证新树仍是二叉树,需要增加一个新结点作为新树的根,并将所选的两棵树的根分别作为新根的左右孩子(谁左,谁右无关紧要),将这两个孩子的权值之和作为新树根的权值。

第八节最优二叉树(哈夫曼树)一、概念在具有n个带权叶结点的二叉树中,使所有叶结点的带权路径长度之和(即二叉树的带权路径长度)为最小的二叉树,称为最优二叉树(又称最优搜索树或哈夫曼树),即最优二叉树使(W k—第k个叶结点的权值;P k—第k个叶结点的带权路径长度)达到最小。
二、最优二叉树的构造方法假定给出n个结点ki(i=1‥n),其权值分别为Wi(i=1‥n)。
要构造以此n个结点为叶结点的最优二叉树,其构造方法如下:首先,将给定的n个结点构成n棵二叉树的集合F={T1,T2,……,Tn}。
其中每棵二叉树Ti中只有一个权值为wi的根结点ki,其左、右子树均为空。
然后做以下两步⑴在F中选取根结点权值最小的两棵二叉树作为左右子树,构造一棵新的二叉树,并且置新的二叉树的根结点的权值为其左、右子树根结点的权值之和;⑵在F中删除这两棵二叉树,同时将新得到的二叉树加入F 重复⑴、⑵,直到在F中只含有一棵二叉树为止。
这棵二叉树便是最优二叉树。
三、最优二叉树的数据类型定义在最优二叉树中非叶结点的度均为2,为满二叉树,因此采用顺序存储结构为宜。
如果带权叶结点数为n个,则最优二叉树的结点数为2n-1个。
Const n=叶结点数的上限;m=2*n-1;{最优二叉树的结点数}Typenode=record{结点类型}data:<数据类型>;{权值}prt,lch,rch,lth:0‥m;{父指针、左、右指针和路径长度}end;wtype=array[1‥n] of <数据类型> ;{n个叶结点权值的类型}treetype=array[1‥m] of node;{最优二叉树的数组类型}Var tree:treetype;{其中tree [1‥n]为叶结点,tree [n+1‥2n-1]为中间结点,根为tree [2n-1]}四、构造最优二叉树的算法。


最优二叉树规则最优二叉树,也称为哈夫曼树,是一种特殊的二叉树结构,它的构建过程是基于一组权值的频率分布来进行的。
最优二叉树规则是指在构建最优二叉树时所遵循的一些基本规则,这些规则可以帮助我们更好地理解最优二叉树的构建过程,从而更好地应用它们来解决实际问题。
最优二叉树的构建过程最优二叉树的构建过程是基于一组权值的频率分布来进行的。
在构建最优二叉树时,我们需要按照以下步骤进行:1. 将所有的权值按照从小到大的顺序排列。
2. 选取两个权值最小的节点作为左右子节点,构建一个新的节点,其权值为这两个节点的权值之和。
3. 将新节点的权值插入到原来的序列中,并将原来的两个节点从序列中删除。
4. 重复步骤2和3,直到序列中只剩下一个节点为止。
最优二叉树规则在构建最优二叉树时,我们需要遵循以下规则:1. 权值越大的节点应该离根节点越近。
2. 在同一层次上,权值越小的节点应该在左边。
3. 在构建最优二叉树时,我们应该尽量使得树的深度最小。
这些规则的目的是为了使得最优二叉树的结构更加紧凑,从而减少树的深度,提高树的搜索效率。
在实际应用中,我们可以根据这些规则来构建最优二叉树,从而更好地解决实际问题。
最优二叉树的应用最优二叉树在实际应用中有着广泛的应用,例如在数据压缩、编码和解码、图像处理等领域中都有着重要的应用。
在数据压缩中,我们可以利用最优二叉树来构建哈夫曼编码,从而将数据压缩到最小的空间。
在编码和解码中,我们可以利用最优二叉树来实现高效的编码和解码算法。
在图像处理中,我们可以利用最优二叉树来实现图像的压缩和解压缩,从而减少图像的存储空间和传输带宽。
总结最优二叉树是一种特殊的二叉树结构,它的构建过程是基于一组权值的频率分布来进行的。
在构建最优二叉树时,我们需要遵循一些基本规则,例如权值越大的节点应该离根节点越近,权值越小的节点应该在左边等。
最优二叉树在实际应用中有着广泛的应用,例如在数据压缩、编码和解码、图像处理等领域中都有着重要的应用。

二叉检索树构造摘要:一、二叉检索树的定义和性质1.二叉检索树的定义2.二叉检索树的性质二、二叉检索树的构造方法1.顺序插入法2.二叉树转化法三、二叉检索树的应用1.查找2.插入3.删除正文:二叉检索树是一种特殊的二叉树,具有以下性质:若左子树不为空,则左子树上所有结点的值均小于根结点的值;若右子树不为空,则右子树上所有结点的值均大于根结点的值;左、右子树也分别为二叉检索树。
基于这些性质,二叉检索树可以用来实现高效的查找、插入和删除操作。
一、二叉检索树的定义和性质1.二叉检索树的定义二叉检索树,又称有序二叉树,是一种特殊的二叉树。
每个结点具有以下性质:若左子树不为空,则左子树上所有结点的值均小于根结点的值;若右子树不为空,则右子树上所有结点的值均大于根结点的值;左、右子树也分别为二叉检索树。
2.二叉检索树的性质二叉检索树具有以下几个基本性质:(1)若左子树不为空,则左子树上所有结点的值均小于根结点的值。
(2)若右子树不为空,则右子树上所有结点的值均大于根结点的值。
(3)左、右子树也分别为二叉检索树。
二、二叉检索树的构造方法1.顺序插入法顺序插入法是构建二叉检索树的最常用方法。
具体步骤如下:(1)将第一个结点插入到空树中,作为根结点。
(2)将后续结点依次插入到树中。
插入过程中,若当前结点的值小于根结点的值,插入到左子树上;若当前结点的值大于根结点的值,插入到右子树上。
(3)重复步骤(2),直到所有结点都插入完毕。
2.二叉树转化法二叉树转化法是一种更高效的构建方法,适用于已经存在一棵二叉树的场合。
具体步骤如下:(1)遍历二叉树,将每个结点的左子结点转化为一个新结点,并将原结点的值赋给新结点。
(2)将新结点插入到原结点的左子树上。
(3)重复步骤(2),直到所有结点都转化完毕。
三、二叉检索树的应用1.查找在二叉检索树中,查找某个结点的过程可以通过遍历树来完成。
具体步骤如下:(1)若要查找的值小于根结点的值,递归地遍历左子树。
最优二叉搜索树一、问题描述给定一个有序序列K={k1<k2<k3<,……,<kn}和他们被查询的概率P={p1,p2,p3,……,pn},要求构造一棵二叉查找树T,使得查询所有元素的总的代价最小。
二、解题思路最优二叉搜索树问题具有最优子结构性质。
证明:设Tij是有序集{xi,…,xj}关于存取概率分布(ai-1,bi,…,bj,aj)的一棵最优二叉搜索树,平均路长为pij。
Tij的根结点存储元素xk。
其左右子树Tl和Tr的平均路长分别为pl和pr。
由于Tl是关于集合{xi,…,xk-1}的一个二叉搜索树,故pl≥pi,k-1。
如果pl>pi,k-1,那么用Ti,k-1替换Tl可得到平均路长比Tij更小的二叉搜索树。
这与Tij是最优二叉搜索树相矛盾。
所以,左子树Tl是一棵最优二叉搜索树,同理可证右子树Tr也是一棵最优二叉搜索树,即最优二叉搜索树的子树也是最优二叉搜索树。
建立递归关系式若最优二叉搜索树Ti,j的根结点为k,最小平均路长为pi,j,m[i,j]表示Ti,j的开销,则有m[i,j]=wi,jpi,j,其中<E:\2008学术交流\200学术交流第四卷第八期(2008总第35期)\第1次96篇\1.3软件设计开发\tr01.tif>,可建立下列递归关系:M[i,j]=bk+(m[i,k-1]+wi,k-1)+ (m[k+1,j]+wk+1,j)而 wi,j=bk+wi,k-1+wk+1,j则m[i,j]=wi,j+m[i,k-1]+m[k+1,j](1)将k=i+1,i+2,…,j分别代入<1>式,选取使m[i,j]达到最小的K,这样递归关系式改为:m[i,j]=wi,j+min{m[i,k-1]+m[k+1,j]}m[i,i-1]=0,1≤i≤n解递归关系,m[1,n]就是所求的最优值。
将对应于m[i,j]的断开位置k 记录在s[i,j]中(也称为根表,记录子树的根),以便构造最优解。
最优⼆叉查找树最优⼆叉树也就是哈夫曼树,最优⼆叉树和最优⼆叉查找树是不⼀样的。
我们说⼀下他们的定义最优⼆叉树:给你n个节点,每⼀个节点有⼀个权值wi。
我们设⼀棵树的权值是所有节点的权值乘于每⼀个节点的深度,但是我们可以构造出来许多⼆叉树,我们称构造出来的那个权值最⼩的⼆叉树就是我们找的最优⼆叉树求解最优⼆叉树:(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有⼀个结点);(2) 在森林中选出两个根结点的权值最⼩的树合并,作为⼀棵新树的左、右⼦树,且新树的根结点权值为其左、右⼦树根结点权值之和;(3)从森林中删除选取的两棵树,并将新树加⼊森林;(4)重复(2)、(3)步,直到森林中只剩⼀棵树为⽌,该树即为所求得的哈夫曼树。
最优⼆叉查找树:给定n个节点的值key,假设x是⼆叉搜索树中的⼀个结点。
如果L是x的左⼦树的⼀个结点,那么L.key ≤ x.key。
如果R是x的右⼦树的⼀个结点,那么R.key ≥ x.key。
使⽤<key1,key2,key3....keyn>表⽰,且我们设定key1<key2<key3<keyn。
对于n个节点都有⼀个访问概率pi,使⽤<p1,p2,p3....pn>表⽰。
还有未找到访问点概率qi,我们使⽤<q0,q1,q2,q3....qn>表⽰。
例如访问到[-∞,key1)的概率是q0,访问到(key1,key2)的概率是q1,,,,访问到(keyn,∞)的概率是qn。
我们设定[-∞,key1)区间为d0,(key1,key2)区间为d1,,,,(keyn,∞)区间是dn。
所以是不会出现对于i,j(1<=i,j<=n)满⾜keyi==keyj的情况出现我们需要把2*n+1个节点放在⼀个⼆叉树上,其中n个节点是keyi,还有n+1个节点di。
最后形成的⼆叉树中叶节点肯定是di。
且∑n i=1pi+∑n i=0qi=1假定⼀次搜索的代价等于访问的结点数,也就是此次搜索找到的结点在⼆叉搜索树中的深度再加1。
二叉查找树(BST,Binary Search Tree),又名二叉搜索树或二叉检索树,是一颗满足如下条件的树:1、每个节点包含一个键值2、每个节点有最多两个孩子3、对于任意两个节点x和y,它们满足下述搜索性质:a、如果y在x的左子树里,则key[y] <= key[x]b、如果y在x的右子树里,则key[y] >= key[x]最优二叉查找树(Optimal BST,Optimal Binary Search Tree)最优二叉查找树是使查找各节点平均代价最低的二叉查找树。
具体来说就是:给定键值序列K = <k1, k2, . . . , kn>,k1 < k2 <.. <kn,其中键值ki,被查找的概率为pi,要求以这些键值构建一颗二叉查找树T,使得查找的期望代价最低(查找代价为检查的节点数)。
下面是对于查找期望代价的解释:对于键值ki, 如果其在构造的二叉查找树里的深度(离开树根的分支数)为depthT(ki),则搜索该键值的代价= depthT(ki) +1(需要加上深度为0的树根节点)。
由于每个键值被查找的概率分别为pi,i=1,2,3…,n。
所以查找期望代价为:E[T的查找代价] = ∑i=1~n(depthT(ki) +1)*pi时间复杂度1、穷举穷举构造最优二叉查找树,其实就是这样的一个问题:给一个拥有n个数的已排序的节点,可以将其构造成多少种不同的BST(用来找到一个最优的二叉查找树)?设可以构造成T(n)个,那么枚举每一个元素作为根节点的情况,当第一个元素作为根节点时,其余n-1个构成右子树,无左子树,是n-1情况时的子问题,共T(n-1)种;当第二个元素作为根节点时,左子树有1个元素,右子树有n-2个元素,根据乘法原理共有T(1)T(n-2)种情况……依此类推得到:T(n)= (0)T(n-1)+T(1)T(n-2)+T(2)T(n-3)+ ......+T(n-2)T(1)+T(n-1)T(0);此外,有T(0)=T(1)=1。