Eviews数据统计与分析教程5章 基本回归模型OLS估计-普通最小二乘法
- 格式:ppt
- 大小:333.50 KB
- 文档页数:41

Glossa ry:ls(leastsquare s)最小二乘法R-sequar ed样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaur ed()S.E of regres sion回归标准误差Log likeli hood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean depend ent var因变量的均值S.D. depend ent var因变量的标准差Akaike info criter ion赤池信息量(AIC)(越小说明模型越精确)Schwar z ctiter ion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statis tic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同g d p肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。

[经验分享] 使用eview s做线性回归分析Glossa ry:ls(least square s)最小二乘法R-sequar ed样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaur ed()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criter ion赤池信息量(AIC)(越小说明模型越精确)Schwar z ctiter ion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statis t ic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同g dp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p 值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
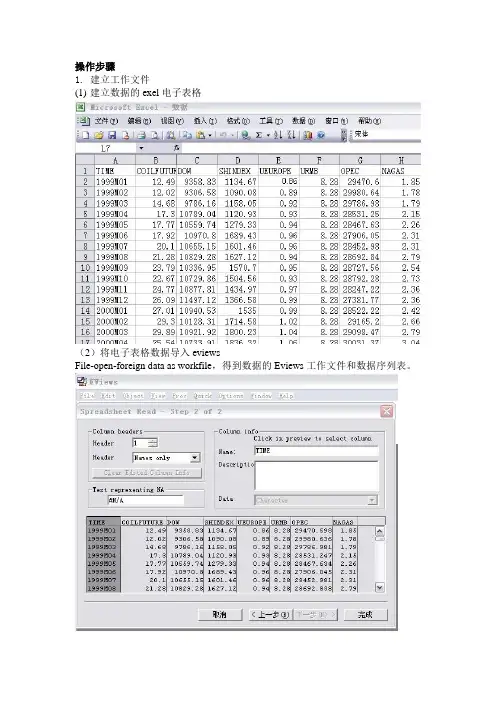
操作步骤1.建立工作文件(1)建立数据的exel电子表格(2)将电子表格数据导入eviewsFile-open-foreign data as workfile,得到数据的Eviews工作文件和数据序列表。
2.计算变量间的相关系数在窗口中输入命令:cor coilfuture dow shindex nagas opec ueurope urmb,点击回车键,得到各序列之间的相关系数。
结果表明Coilfuture数列与其他数列存在较好的相关关系。
3.时间序列的平稳性检验(1)观察coilfuture序列趋势图在eviews中得到时间序列趋势图,在quick菜单中单击graph,在series list对话框中输入序列名称coilfuture,其他选择默认操作。
图形表明序列随时间变化存在上升趋势。
(2)对原序列进行ADF平稳性检验quick-series statistics-unit root test,在弹出的series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择level,得到原数据序列的ADF检验结果,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值0.97大于所有临界值,则表明序列不平稳。
以此方法,对各时间序列依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均大于临界值,表明各原序列都是非平稳的。
(3)时间序列数据的一阶差分的ADF检验quick-series statistics-unit root test,在series name对话框中输入需要检验的序列的名称,在test for unit root in 选择框中选择1nd difference,对其一阶差分进行平稳性检验,其他保持默认设置。
得到序列的ADF平稳性检验结果,检测值-7.8远小于所有临界值,则表明序列一阶差分平稳。
以此方法,对各时间序列的一阶差分依次进行ADF检验,将检验值与临界值比较,发现所有序列的检验值均小于临界值,表明各序列一阶差分都是平稳的。





Glossary:ls(least squares)最小二乘法R-sequared样本决定系数(R2):值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,解决这个问题使用来调整Adjust R-seqaured()S.E of regression回归标准误差Log likelihood对数似然比:残差越小,L值越大,越大说明模型越正确Durbin-Watson stat:DW统计量,0-4之间Mean dependent var因变量的均值S.D. dependent var因变量的标准差Akaike info criterion赤池信息量(AIC)(越小说明模型越精确)Schwarz ctiterion:施瓦兹信息量(SC)(越小说明模型越精确)Prob(F-statistic)相伴概率fitted(拟合值)线性回归的基本假设:1.自变量之间不相关2.随机误差相互独立,且服从期望为0,标准差为σ的正态分布3.样本个数多于参数个数建模方法:ls y c x1 x2 x3 ...x1 x2 x3的选择先做各序列之间的简单相关系数计算,选择同因变量相关系数大而自变量相关系数小的一些变量。
模型的实际业务含义也有指导意义,比如m1同gdp肯定是相关的。
模型的建立是简单的,复杂的是模型的检验、评价和之后的调整、择优。
模型检验:1)方程显著性检验(F检验):模型拟合样本的效果,即选择的所有自变量对因变量的解释力度F大于临界值则说明拒绝0假设。
Eviews给出了拒绝0假设(所有系统为0的假设)犯错误(第一类错误或α错误)的概率(收尾概率或相伴概率)p值,若p小于置信度(如0.05)则可以拒绝0假设,即认为方程显著性明显。
2)回归系数显著性检验(t检验):检验每一个自变量的合理性|t|大于临界值表示可拒绝系数为0的假设,即系数合理。
t分布的自由度为n-p-1,n为样本数,p为系数位置3)DW检验:检验残差序列的自相关性,检验基本假设2(随机误差相互独立)残差:模型计算值与资料实测值之差为残差0<=dw<=dl 残差序列正相关,du<dw<4-du 无自相关, 4-dl<dw<=4负相关,若不在以上3个区间则检验失败,无法判断demo中的dw=0.141430 ,dl=1.73369,du=1.7786,所以存在正相关模型评价目的:不同模型中择优1)样本决定系数R-squared及修正的R-squaredR-squared=SSR/SST 表示总离差平方和中由回归方程可以解释部分的比例,比例越大说明回归方程可以解释的部分越多。

Eviews估计方法汇总来源:计量经济学01最小二乘法(1)普通最小二乘估计(OLS):这是使用的最为普遍的模型,基本原理就是估计残差平方和最小化,不予赘述。
(2)加权最小二乘估计(WLS)Eviews路径:LS模型设定对话框-----optionsOLS的假设条件最为严格,其他的估计方法往往是在OLS的某些条件无法满足的前提下进行修正处理的。
WLS就是用来修正异方差问题的。
在解释变量的每一个水平上存在一系列的被解释变量值,每一个被解释变量值都有自己的分布和方差。
在同方差性假设下,OLS对每个残差平方ei^2都同等看待,即采取等权重1。
但是,当存在异方差性时,方差δi^2越小,其样本值偏离均值的程度越小,其观测值越应受到重视,即方差越小,在确定回归线时的作用应当越大;反之方差δi^2越大,其样本值偏离均值的程度越大,其在确定回归线时的作用应当越小。
WLS的一个思路就是在拟合存在异方差的模型的回归线时,对不同的δi^2区别对待。
在利用样本估计系数时依旧是使得总体残差最小化,但是WLS会给每个残差平方和一个权重wi=1/δi。
这样,当δi^2越小,wi越大;反之,δi^2越大,wi越小。
Eviews的WLS没有要求权重因子必须是1/δi。
一般纠正异方差性的方法还包括模型变换法,这种方法假定已知Var(ui)=δi^2=δ^2*f(Xi),令权重wi=f(Xi)^(1/2),用f(Xi)^(1/2)去除原模型,可知随机干扰项转换为ui/f(Xi)^(1/2),这时Var(ui)=δi^2=δ^2,即实现了同方差。
由上面的分析可知,WLS核心就是找到一个等式:Var(ui)=δi^2=δ^2*f(Xi)。
这个等式经过调整更容易理解:δ^2=δi^2/f(Xi)或δ=δi/f(Xi)^(1/2)。
δ为某一常数,权重wi=1/f(Xi)^(1/2),经过wi的加权便实现了同方差。
前面提到的特殊权重wi=1/δi,即f(Xi)=1/δi^2,这时δ=δi/f(Xi)^(1/2)=1。

Eviews期中实验报告一、实验任务上机内容:基本统计和OLS、稳健方差要点∙描述性统计∙简单假设检验∙季节调整:移动平均法∙多元统计分析:齐性检验;主成分分析∙方程对象:方程设定,估计结果,系数,成员函数∙方差稳健估计:HC和HAC∙哑变量和交互项二、实验内容1.简单统计分析与描述性统计数据查看:m1.sheetm1StatsM1Mean 378.1643Median 274.0275Maximum 1089.475Minimum 129.8910Std. Dev. 265.4934Skewness 1.012404Kurtosis 2.765155Jarque-Bera 27.70001Probability 0.000001Sum 60506.30Sum Sq. Dev. 11207393Observations 160从而显示出了m1的各种统计信息,包括均值,中位点,最大值最小值,以及二到四阶矩观测数目和正态分布检验等的统计概要。
M1.line则显示出了这一组数据的图形描述freeze(gk) G(1).distplot kernel 'G(1).kdensity'V6 -> G(1).distplot kernel'画出对象g中第一个变量的直方图,命名为gh freeze(gh) G(1).hist 'hist log(m1)'将g中的所有变量画入一张线性图中,改图命名为gfa graph gfa.line G'将g中所有的变量分别画出一张图并合并入gfg这一个对象中graph gfg.line(m) G 'multiple graphs'生成列表tbgsi,该列表中包含了g中所有变量单独的统计值freeze(tbGsi) G.stats(i) 'individual samples回归模型估计smpl 1952Q1 1992Q4equation eq1.ls log(m1) c log(gdp) rs dlog(pr)Dependent Variable: LOG(M1)Method: Least SquaresDate: 12/07/12 Time: 15:41Sample (adjusted): 1952Q2 1992Q4Included observations: 163 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.C 1.312383 0.032199 40.75850 0.0000LOG(GDP) 0.772035 0.006537 118.1092 0.0000RS -0.020686 0.002516 -8.221196 0.0000 DLOG(PR) -2.572204 0.942556 -2.728967 0.0071R-squared 0.993274 Mean dependent var 5.692279Adjusted R-squared 0.993147 S.D. dependent var 0.670253S.E. of regression 0.055485 Akaike info criterion -2.921176Sum squared resid 0.489494 Schwarz criterion -2.845256Log likelihood 242.0759 Hannan-Quinn criter. -2.890354F-statistic 7826.904 Durbin-Watson stat 0.140967Prob(F-statistic) 0.000000这里我们使用smpl来设定估计样本的观测区间,而equation语句则创建了方程对象eq1并进行最小二乘估计,其中的c代表回归方程的常数项,得到模型估计的结果如上图所示。

例题中国居民人均消费支出与人均GDP(1978-2000),数据(例题1-2),预测,2001年人均GDP为4033.1元,求点预测、区间预测。
(李子奈,p50)解答:一、打开Eviews软件,点击主界面File按钮,从下拉菜单中选择Workfile。
在弹出的对话框中,先在工作文件结构类型栏(Workfile structure type)选择固定频率标注日期(Dated – regular frequency),然后在日期标注说明栏中(Date specification)将频率(Frequency)选为年度(Annual),再依次填入起止日期,如果希望给文件命名(可选项),可以在命名栏(Names - optional)的WF项填入自己选择的名称,然后点击确定。
此时建立好的工作文件如下图所示:在主界面点击快捷方式(Quick)按钮,从下拉菜单中选空白数据组(Empty Group)选项。
此时空白数据组出现,可以在其中通过键盘输入数据或者将数据粘贴过来。
在Excel文件(例题1-2)中选定要粘贴的数据,然后在主界面中点击编辑(Edit)按钮,从下拉菜单中选择粘贴(Paste),数据将被导入Eviews软件。
将右侧的滚动条拖至最上方,可以在最上方的单元格中给变量命名。
二、估计参数在主界面中点击快捷方式(Quick)按钮,从下拉菜单中选择估计方程(Estimate Equation)在弹出的对话框中设定回归方程的形式。
在方程表示式栏中(Equation specification ),按照被解释变量(Consp )、常数项(c )、解释变量(Gdpp )的顺序填入变量名,在估计设置(Estimation settings )栏中选择估计方法(Method )为最小二乘法(LS – Least Squares ),样本(Sample )栏中选择全部样本(本例中即为1978-2000),然后点击确定,即可得到回归结果。